
分布式事務(wù)解決方案
1. 基礎(chǔ)知識
1)?事務(wù)
事務(wù)由一組操作構(gòu)成,我們希望這組操作能夠全部正確執(zhí)行,如果這一組操作中的任意一個步驟發(fā)生錯誤,那么就需要回滾之前已經(jīng)完成的操作。也就是同一個事務(wù)中的所有操作,要么全都正確執(zhí)行,要么全都不要執(zhí)行。
2)?事務(wù)的四大特性ACID
原子性:事務(wù)是一個不可分割的執(zhí)行單元,事務(wù)中的所有操作那么全部執(zhí)行,要么全部不執(zhí)行;
隔離性:事務(wù)的執(zhí)行是相互獨(dú)立的,它們不會相互干擾,一個事務(wù)不會看到另一個正在運(yùn)行過程中的事務(wù)的數(shù)據(jù);
持久性:持久性要求,一個事務(wù)完成之后,事務(wù)的執(zhí)行結(jié)果必須是持久化保存的。即使數(shù)據(jù)庫發(fā)生崩潰,在數(shù)據(jù)庫恢復(fù)后事務(wù)提交的結(jié)果仍然不會丟失;
一致性:事務(wù)在開始前和結(jié)束后,數(shù)據(jù)庫的完整性約束沒有被破壞。
3)?臟讀、幻讀、虛讀及不可重復(fù)讀
臟讀:如果一個事務(wù)中對數(shù)據(jù)進(jìn)行了更新,但事務(wù)還沒有提交,另一個事務(wù)可以“看到”該事務(wù)沒有提交的更新結(jié)果,這樣造成的問題就是,如果第一個事務(wù)回滾,那么,第二個事務(wù)在此之前所“看到”的數(shù)據(jù)就是一筆臟數(shù)據(jù)。
不可重復(fù)讀:包括幻讀和虛讀兩種情況
幻讀:事務(wù)1在兩次查詢的過程中,事務(wù)2對該表進(jìn)行了插入、刪除操作,從而事務(wù)1第二次查詢的結(jié)果發(fā)生了變化。
虛讀:在事務(wù)1兩次讀取同一記錄的過程中,事務(wù)2對該記錄進(jìn)行了修改,從而事務(wù)1第二次讀到了不一樣的記錄。
4)?數(shù)據(jù)庫的四種隔離級別
讀未提交(read uncommitted): 在該級別下,一個事務(wù)對一行數(shù)據(jù)修改的過程中,不允許另一個事務(wù)對該行數(shù)據(jù)進(jìn)行修改,但是允許另一個事務(wù)對該行數(shù)據(jù)讀。因此在本級別下,不會出現(xiàn)更新丟失,但會出現(xiàn)臟讀,不可重復(fù)讀。
讀提交(Read Committed): 在該隔離級別下,不允許兩個未提交的事務(wù)之間并行執(zhí)行,但它允許在一個事務(wù)執(zhí)行的過程中,另外一個事務(wù)得到執(zhí)行并提交。這樣,會出現(xiàn)一種情況,第一個事務(wù)前后兩次select出來的某行數(shù)據(jù),值可能不一樣。值改變的原因是,穿插執(zhí)行的事務(wù)2對該行數(shù)據(jù)進(jìn)行了update操作。在同一個事務(wù)中,兩次select出來的值不相同的問題稱為不可重復(fù)讀問題。要解決不可重復(fù)讀問題,需要把數(shù)據(jù)的隔離級別設(shè)置為可重復(fù)讀。
重復(fù)讀(Repeatable read): 在該隔離級別下,在一個事務(wù)使用某行數(shù)據(jù)的過程中,不允許別的事務(wù)再對該行數(shù)據(jù)進(jìn)行操作。可重復(fù)讀應(yīng)該是給數(shù)據(jù)庫的行加上了鎖。這種隔離級別下,依舊允許別的事務(wù)在該表中插入和刪除數(shù)據(jù),于是就會出現(xiàn),在事務(wù)1執(zhí)行的過程中,如果先后兩次select出符合某個條件的行,如果在這兩次select過程中另一個事務(wù)得到了執(zhí)行,insert或者delete了某些行,就會出現(xiàn)先后兩次select出來的符合同一條件的結(jié)果不一樣,第一次select好像出現(xiàn)了幻覺一樣,因此這個問題也被稱為
幻讀。要解決幻讀問題,需要將數(shù)據(jù)庫的隔離級別設(shè)置為串行化。序列化(serializable):該級別要求所有事務(wù)都必須串行執(zhí)行,因此能避免一切因并發(fā)引起的問題,但效率很低。
注:mysql默認(rèn)的隔離級別是重復(fù)讀級別,oracle是讀提交
5)?樂觀鎖和悲觀鎖
樂觀鎖:總是假設(shè)最好的情況,每次去拿數(shù)據(jù)的時候都認(rèn)為別人不會修改,所以不會上鎖,但是在更新的時候會判斷一下在此期間別人有沒有去更新這個數(shù)據(jù),可以使用版本號機(jī)制和CAS算法實(shí)現(xiàn)。樂觀鎖適用于多讀的應(yīng)用類型,這樣可以提高吞吐量。
悲觀鎖:總是假設(shè)最壞的情況,每次去拿數(shù)據(jù)的時候都認(rèn)為別人會修改,所以每次在拿數(shù)據(jù)的時候都會上鎖,這樣別人想拿這個數(shù)據(jù)就會阻塞直到它拿到鎖(共享資源每次只給一個線程使用,其它線程阻塞,用完后再把資源轉(zhuǎn)讓給其它線程)。傳統(tǒng)的關(guān)系型數(shù)據(jù)庫里邊就用到了很多這種鎖機(jī)制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖。Java中synchronized和ReentrantLock等獨(dú)占鎖就是悲觀鎖思想的實(shí)現(xiàn)。
2. mysql如何保證持久性和原子性
在數(shù)據(jù)庫系統(tǒng)中,既有存放數(shù)據(jù)的文件,也有存放日志的文件。日志在內(nèi)存中也是有緩存Log buffer,也有磁盤文件log file。
MySQL中的日志文件,有這么兩種與事務(wù)有關(guān):undo日志與redo日志。
2.1 undo日志
數(shù)據(jù)庫事務(wù)具備原子性(atomicity),如果事務(wù)執(zhí)行失敗,需要把數(shù)據(jù)回滾。事務(wù)同時還具備持久性(durability),事務(wù)對數(shù)據(jù)所做的變更需要保存到硬盤,不能因?yàn)楣收隙鴣G失。
事務(wù)的原子性可以利用undo日志來實(shí)現(xiàn)。
undo log的原理很簡單,為了滿足事務(wù)的原子性,在操作任何數(shù)據(jù)之前,首先將數(shù)據(jù)備份到undo log,然后進(jìn)行數(shù)據(jù)的修改。如果出現(xiàn)了錯誤或者用戶執(zhí)行了rollback語句,系統(tǒng)可以利用undo log中的備份將數(shù)據(jù)恢復(fù)到事務(wù)開始之前的狀態(tài)。
數(shù)據(jù)庫寫入數(shù)據(jù)到磁盤之前,會把數(shù)據(jù)先緩存到內(nèi)存中,事務(wù)提交時才會寫入磁盤中。用undo log實(shí)現(xiàn)原子性和持久化的事務(wù)的簡化過程如下:
假設(shè)有A、B兩個數(shù)據(jù),值分別為1、2:
1) 事務(wù)開始
2) 記錄A=1到undo log buffer
3) 修改A=3
4) 記錄B=2到undo log buffer
5) 修改B=4
6) 將undo log寫到磁盤
7) 將數(shù)據(jù)寫到磁盤
8) 事務(wù)提交
如何保證持久性?
事務(wù)提交前,會把修改數(shù)據(jù)刷到磁盤,也就是說只要事務(wù)提交了,數(shù)據(jù)肯定持久化了。
如何保證原子性?
每次對數(shù)據(jù)庫修改,都會把修改前數(shù)據(jù)記錄在undo log中,那么需要回滾時,可以讀取undo log,恢復(fù)數(shù)據(jù)。
若系統(tǒng)在7) 和8) 之間崩潰,如何處理?
此時事務(wù)并未提交,需要回滾。而undo log已經(jīng)被持久化,可以根據(jù)undo log來恢復(fù)數(shù)據(jù)。
若系統(tǒng)在7)之前崩潰,如何處理?
此時數(shù)據(jù)并未持久化到硬盤,依然保持在事務(wù)之前的狀態(tài)。
缺陷:?每個事務(wù)提交前將數(shù)據(jù)和undo log寫入磁盤,這樣會導(dǎo)致大量的磁盤IO,因此性能很低。
如果能夠?qū)?shù)據(jù)緩存一段時間,就能減少IO提高性能,但是這樣就會喪失事務(wù)的持久性,因此引入了另外一種機(jī)制來實(shí)現(xiàn)持久化,即redo log。
2.2 redo log
和undo log相反,redo log記錄的是新數(shù)據(jù)的備份。在事務(wù)提交前,只要將redo log持久化即可,不需要將數(shù)據(jù)持久化,減少了IO的次數(shù)。
先來看一下基本原理,undo + redo事務(wù)的簡化過程:
假設(shè)有A、B兩個數(shù)據(jù),值分別為1,2:
1) 事務(wù)開始;
2) 記錄A=1到undo log buffer;
3) 修改A=3;
4) 記錄A=3到redo log buffer;
5) 記錄B=2到undo log buffer;
6) 修改B=4;
7) 記錄B=4到redo log buffer;
8) 將undo log寫入磁盤;
9) 將redo log寫入磁盤;
10) 事務(wù)提交
2.2.1 安全性和性能問題
如何保證原子性?
如果在事務(wù)提交前故障,通過undo log日志恢復(fù)數(shù)據(jù)。如果undo log都還沒寫入,那么數(shù)據(jù)就尚未持久化,無需回滾。
如何保證持久化?
大家會發(fā)現(xiàn),這里并沒有出現(xiàn)數(shù)據(jù)的持久化。因?yàn)閿?shù)據(jù)已經(jīng)寫入redo log,而redo log持久化到了硬盤,因此只要到了步驟9)以后,事務(wù)是可以提交的。
內(nèi)存中的數(shù)據(jù)庫數(shù)據(jù)何時持久化到磁盤?
因?yàn)閞edo log已經(jīng)持久化,因此數(shù)據(jù)庫數(shù)據(jù)寫入磁盤與否影響不大,不過為了避免出現(xiàn)臟數(shù)據(jù)(內(nèi)存中與磁盤不一致),事務(wù)提交后也會將內(nèi)存數(shù)據(jù)刷入磁盤(也可以按照設(shè)定的頻率刷新內(nèi)存數(shù)據(jù)到磁盤中)。
redo log何時寫入磁盤?
redo log會在事務(wù)提交之前,或者redo log buffer滿了的時候?qū)懭氪疟P。
2.2.2 存在的問題
這里存在兩個問題:
1)?問題1:之前是寫undo和數(shù)據(jù)庫數(shù)據(jù)到硬盤,現(xiàn)在是寫undo和redo到磁盤,似乎沒有減少IO次數(shù)
數(shù)據(jù)庫數(shù)據(jù)寫入是隨機(jī)IO,性能很差;
redo log在初始化時會開辟一段連續(xù)的空間,寫入是順序IO,性能很好;
實(shí)際上undo log并不是直接寫入磁盤,而是先寫入到undo log buffer中,當(dāng)redo log持久化時,undo log就同時持久化到硬盤了。
因此事務(wù)提交前,只需要對redo log持久化即可。
另外,redo log并不是寫入一次就持久化一次,redo log在內(nèi)存中也有自己的緩沖池redo log buffer。每次寫redo log都是寫入到buffer,在提交時一次性持久化到磁盤,減少IO次數(shù)。
2)?問題2:redo log數(shù)據(jù)是寫入內(nèi)存buffer中,當(dāng)buffer滿或者事務(wù)提交時,將buffer數(shù)據(jù)寫入磁盤。redo log中記錄的數(shù)據(jù),有可能包含尚未提交的事務(wù),如果此時數(shù)據(jù)庫崩潰,那么如何完成數(shù)據(jù)恢復(fù)?
數(shù)據(jù)恢復(fù)有兩種策略:
恢復(fù)時,只重做已經(jīng)提交了的事務(wù)
恢復(fù)時,重做所有事務(wù), 包括未提交的事務(wù)和回滾了的事務(wù)。然后通過undo log回滾那些未提交的事務(wù)。
InnoDB引擎采用的是第二種方案,因此undo log要在redo log前持久化。
2.3 總結(jié)
undo log記錄更新前數(shù)據(jù),用于保證事務(wù)原子性
redo log記錄更新后數(shù)據(jù),用于保證事務(wù)的持久性
redo log有自己的內(nèi)存buffer,先寫入到buffer,事務(wù)提交時寫入磁盤
redo log持久化之后,意味著事務(wù)是可提交的
3. 分布式事務(wù)
3.1 應(yīng)用場景
當(dāng)我們的系統(tǒng)采用了微服務(wù)架構(gòu)后,一個電商系統(tǒng)往往被拆分成如下幾個子系統(tǒng):商品系統(tǒng)、訂單系統(tǒng)、支付系統(tǒng)、積分系統(tǒng)等。整個下單的過程如下:
1) 用戶通過商品系統(tǒng)瀏覽商品,他看中了某一項(xiàng)商品,便點(diǎn)擊下單
2) 此時訂單系統(tǒng)會生成一條訂單
3) 訂單創(chuàng)建成功后,支付系統(tǒng)提供支付功能
4) 當(dāng)支付完成后,由積分系統(tǒng)為該用戶增加積分
上述2)、3)、4) 需要在一個事務(wù)中完成。對于傳統(tǒng)單體應(yīng)用而言,實(shí)現(xiàn)事務(wù)非常簡單,只需將這三個步驟放在一個方法A中,再用spring的@Transactional注解標(biāo)識該方法即可。Spring通過數(shù)據(jù)庫的事務(wù)支持,保證這些步驟要么全部執(zhí)行完成,要么全都不執(zhí)行。但在這個微服務(wù)架構(gòu)中,這三個步驟涉及三個系統(tǒng),涉及三個數(shù)據(jù)庫,此時我們必須在數(shù)據(jù)庫和應(yīng)用系統(tǒng)之間,通過某項(xiàng)黑科技,實(shí)現(xiàn)分布式事務(wù)的支持。
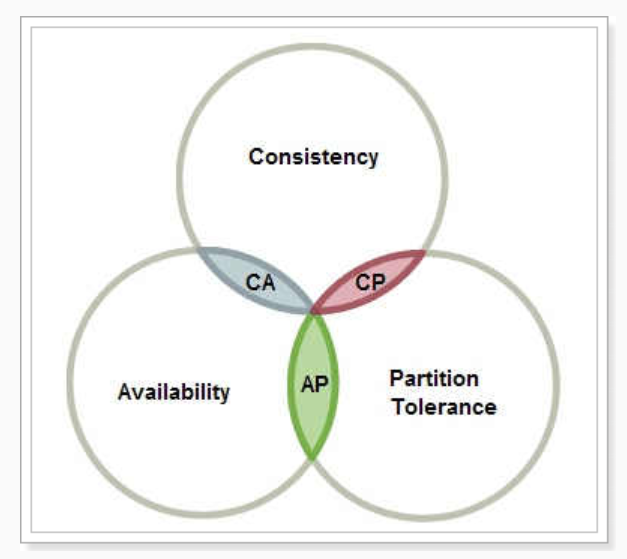
3.2 CAP理論
在一個分布式系統(tǒng)中,最多只能滿足C、A、P中的兩個需求:
C–Consistency: 一致性,同一數(shù)據(jù)的多個副本是否實(shí)時相同
A–Availability: 可用性,一定時間內(nèi),系統(tǒng)返回一個明確的結(jié)果,則稱為該系統(tǒng)可用
P–Partition tolerance: 分區(qū)容錯性,將同一服務(wù)分布在多個系統(tǒng)中,從而保證某一個系統(tǒng)宕機(jī),仍然有其他系統(tǒng)提供相同的服務(wù)。
3.3 BASE理論
BASE是三個單詞的縮寫:
Basically Available(基本可用)
Soft state(軟狀態(tài))
Eventually consistent(最終一致性)
如下圖所示,訂單服務(wù)、庫存服務(wù)、用戶服務(wù)及他們對應(yīng)的數(shù)據(jù)庫就是分布式應(yīng)用中的三個部分。
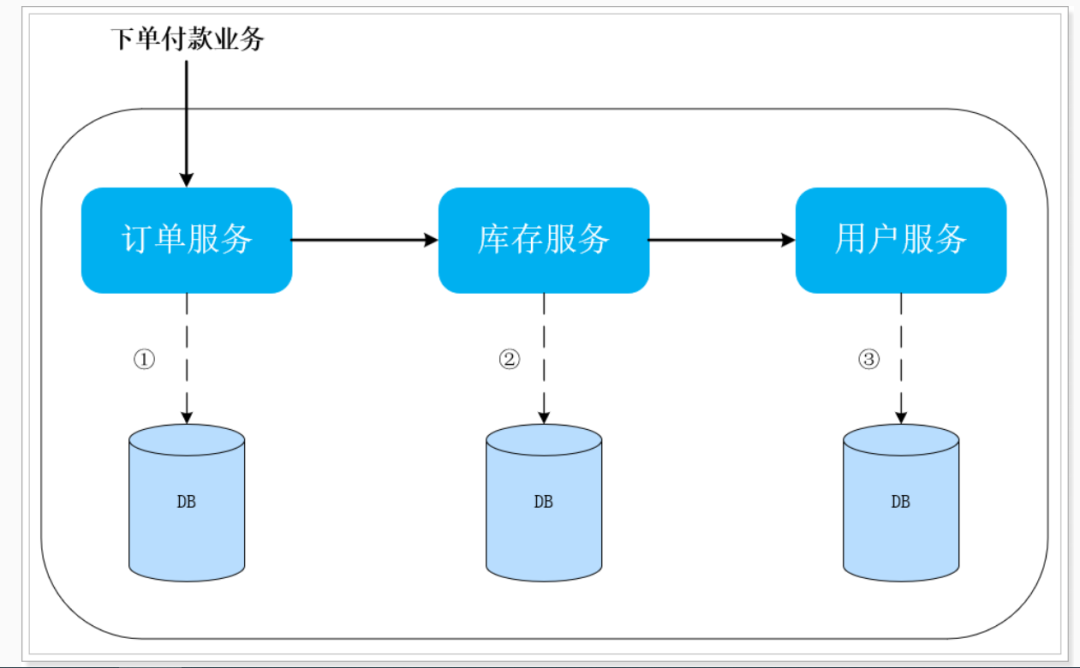
CP方式:現(xiàn)在如果要滿足事務(wù)的強(qiáng)一致性,就必須在訂單服務(wù)數(shù)據(jù)庫鎖定的同時,對庫存服務(wù)、用戶服務(wù)數(shù)據(jù)資源同時鎖定。等待三個服務(wù)業(yè)務(wù)全部處理完成,才可以釋放資源。此時如果有其他請求想要操作被鎖定的資源就會被阻塞,這樣就是滿足了CP。(這就是強(qiáng)一致性,弱可用)
AP方式:三個服務(wù)的對應(yīng)數(shù)據(jù)庫各自獨(dú)立執(zhí)行自己的業(yè)務(wù),執(zhí)行本地事務(wù),不要求相互鎖定資源。但是這個中間狀態(tài)下,我們?nèi)ピL問數(shù)據(jù)庫,可能遇到數(shù)據(jù)不一致的情況,不過我們需要做一些后補(bǔ)措施,保證在經(jīng)過一段時間后,數(shù)據(jù)最終滿足一致性(這就是高可用,但弱一致: 最終一致性)。
由上面的兩種思想,延伸出了很多的分布式事務(wù)解決方案:
XA
TCC
可靠消息最終一致性
AT
3.4 二階段提交
1)?正常情況
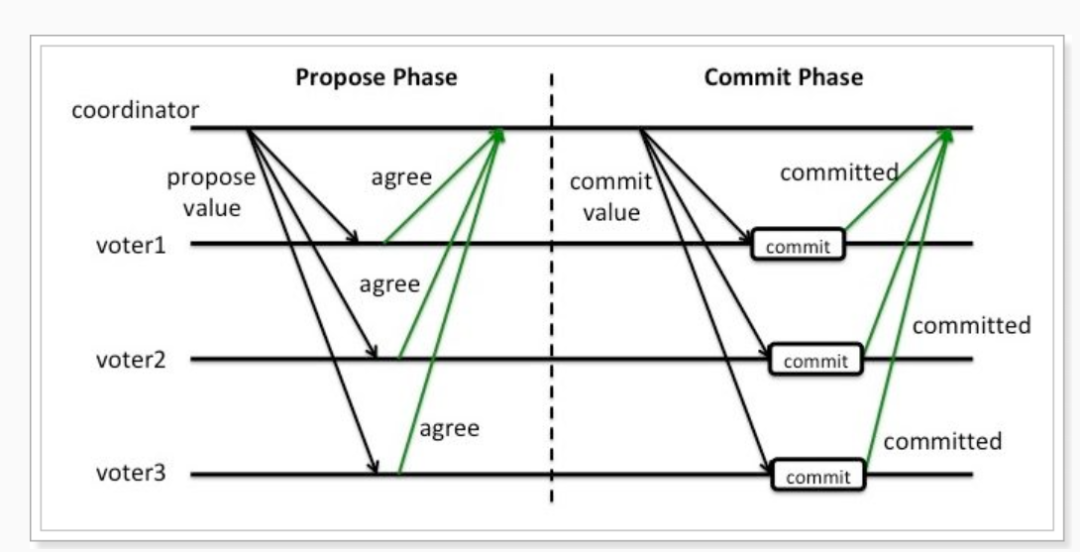
如上圖所示,正常情況下可分為兩階段:
投票階段
協(xié)調(diào)組詢問各個事務(wù)參與者,是否可以執(zhí)行事務(wù)。每個事務(wù)參與者執(zhí)行事務(wù),寫入redo和undo日志,然后反饋事務(wù)執(zhí)行成功的信息(agree)。
提交階段
協(xié)調(diào)組發(fā)現(xiàn)每個參與者都可以執(zhí)行事務(wù)(agree),于是向各個事務(wù)參與者發(fā)出commit指令,各個事務(wù)參與者提交事務(wù)。
2)?異常情況
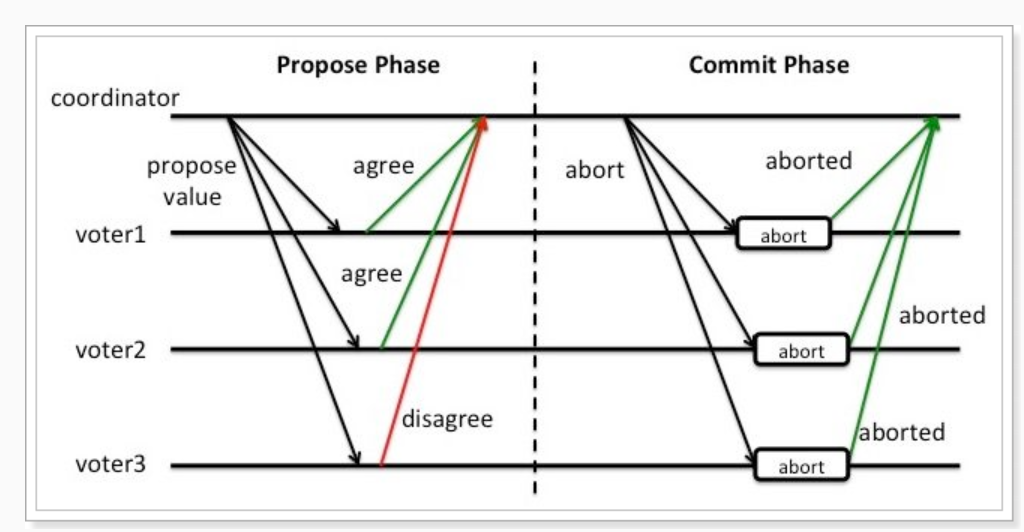
如上圖所示,異常情況的處理方式為:
投票階段:協(xié)調(diào)組詢問各個事務(wù)參與者,是否可以執(zhí)行事務(wù)。每個事務(wù)參與者執(zhí)行事務(wù),寫入redo和undo日志,然后反饋事務(wù)執(zhí)行結(jié)果。但只要有一個參與者返回的是Disagree,則說明執(zhí)行失敗。
提交階段:協(xié)調(diào)組發(fā)現(xiàn)一個或多個參與者返回的是Disagree,認(rèn)為執(zhí)行失敗。于是向各個事務(wù)參與者發(fā)出abort指令,各個事務(wù)參與者回滾事務(wù)。
3)?缺點(diǎn)
2PC的缺點(diǎn)在于不能處理Fail-stop形式的節(jié)點(diǎn)failure。比如下圖這種情況:

假設(shè)cordinator和voter3都在commit這個階段crash了,而voter1和voter2沒有收到commit消息。這時候voter1和voter2就陷入了一個困境。因?yàn)樗麄儾⒉荒芘袛喱F(xiàn)在是兩個場景中的哪一種:
上輪全票通過,然后voter3第一個收到了commit消息并在commit操作之后crash了
上輪voter3反對,所以干脆沒有通過;
4)?阻塞問題
在準(zhǔn)備階段、提交階段,每個事物參與者都會鎖定本地資源,并等待其它事務(wù)的執(zhí)行結(jié)果,阻塞時間較長,資源鎖定時間太久,因此執(zhí)行的效率就比較低了。
3.5 TCC模式
TCC模式可以解決2PC中的資源鎖定和阻塞問題,減少資源鎖定時間。它本質(zhì)是一種補(bǔ)償?shù)乃悸罚聞?wù)運(yùn)行過程包括三個方法:
Try: 資源的檢測和預(yù)留
Confirm: 執(zhí)行的業(yè)務(wù)操作提交。要求Try成功,Confirm一定要成功;
Cancel: 預(yù)留資源釋放
執(zhí)行分兩個階段:
準(zhǔn)備階段(try): 資源的檢測和預(yù)留
執(zhí)行階段(confirm/cancel):根據(jù)上一步結(jié)果,判斷下面的執(zhí)行方法。如果上一步中所有事務(wù)參與者都成功,則這里執(zhí)行confirm;反之,執(zhí)行cancle

粗看似乎與兩階段提交沒什么區(qū)別,但其實(shí)差別很大:
try、confirm、cancel都是獨(dú)立的事務(wù),不受其他參與者的影響,不會阻塞等待他人;
try、confirm、cancel由程序員在業(yè)務(wù)層編寫,鎖力度由代碼控制;
以下單業(yè)務(wù)中的扣減余額為例來看下怎么編寫,假設(shè)賬戶A原來余額是100,需要余額扣減30元。如圖:

1) 一階段(try)
- 余額檢查,并凍結(jié)用戶部分金額,此階段執(zhí)行完畢,事務(wù)已經(jīng)提交。
- 檢查用戶余額是否充足,如果充足,凍結(jié)部分余額
- 在賬戶表中添加凍結(jié)金額字段,值為30,余額不變
2) 二階段
- 提交(Confirm):真正的扣款,把凍結(jié)金額從余額中扣除,凍結(jié)金額清空
- 修改凍結(jié)金額為0,修改余額為100-30 = 70元
- 補(bǔ)償(Cancel):釋放之前凍結(jié)的金額,并非回滾
- 余額不變,修改賬戶凍結(jié)金額為0
3.5.1 TCC優(yōu)缺點(diǎn)及使用場景
1)?優(yōu)勢
TCC執(zhí)行的每一個階段都會提交本地事務(wù)并釋放鎖,并不需要等待其它事務(wù)的執(zhí)行結(jié)果。而如果其它事務(wù)執(zhí)行失敗,最后不是回滾,而是執(zhí)行補(bǔ)償操作。這樣就避免了資源的長期鎖定和阻塞等待,執(zhí)行效率比較高,屬于性能比較好的分布式事務(wù)方式。
2)?缺點(diǎn)
代碼侵入:需要人為編寫代碼實(shí)現(xiàn)try、confirm、cancel,代碼侵入較多
開發(fā)成本高:一個業(yè)務(wù)需要拆分成3個步驟,分別編寫業(yè)務(wù)實(shí)現(xiàn),業(yè)務(wù)編寫比較復(fù)雜
安全性考慮:cancel動作如果執(zhí)行失敗,資源就無法釋放,需要引入重試機(jī)制,而重試可能導(dǎo)致重復(fù)執(zhí)行,還要考慮重試時的冪等問題
3)?使用場景
對事務(wù)有一定的一致性要求(最終一致)
對性能要求較高
開發(fā)人員具備較高的編碼能力和冪等處理經(jīng)驗(yàn)
3.6 可靠消息服務(wù)
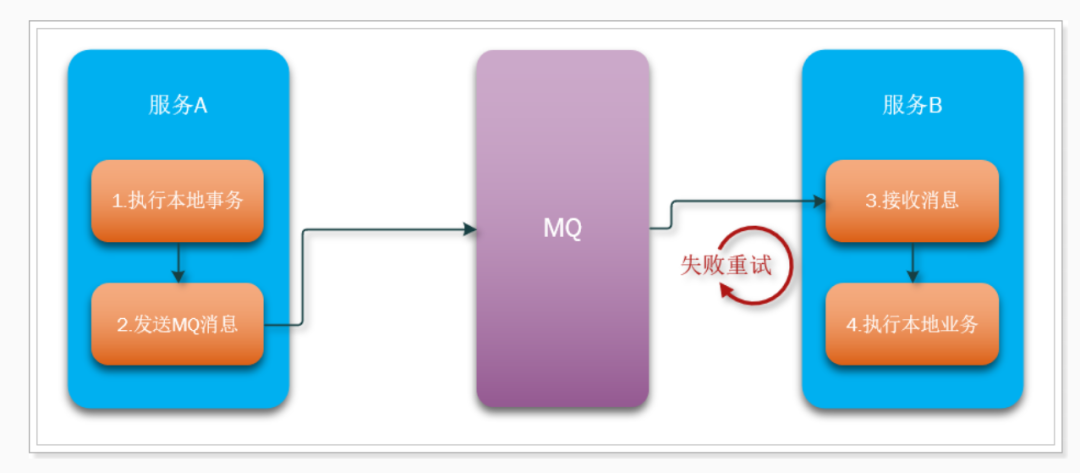
一般分為事務(wù)的發(fā)起者A和事務(wù)的其它參與者B:
事務(wù)發(fā)起者A執(zhí)行本地事務(wù)
事務(wù)發(fā)起者A通過MQ將需要執(zhí)行的事務(wù)信息發(fā)送給事務(wù)參與者B
事務(wù)參與者B接收到消息后執(zhí)行本地事務(wù)
這個過程有點(diǎn)像你去學(xué)校食堂吃飯:
拿著錢去收銀處,點(diǎn)一份紅燒牛肉面,付錢
收銀處給你發(fā)一個小票,還有一個號牌,你別把票弄丟!
你憑小票和號牌一定能領(lǐng)到一份紅燒牛肉面,不管需要多久
幾個注意事項(xiàng):
事務(wù)發(fā)起者A必須確保本地事務(wù)成功后,消息一定發(fā)送成功
MQ必須保證消息正確投遞和持久化保存
事務(wù)參與者B必須確保消息最終一定能消費(fèi),如果失敗需要多次重試
事務(wù)B執(zhí)行失敗,會重試,但不會導(dǎo)致事務(wù)A回滾
那么問題來了,我們?nèi)绾伪WC消息發(fā)送一定成功?如何保證消費(fèi)者一定能收到消息?
3.6.1 本地消息表
參看如下簡化圖:
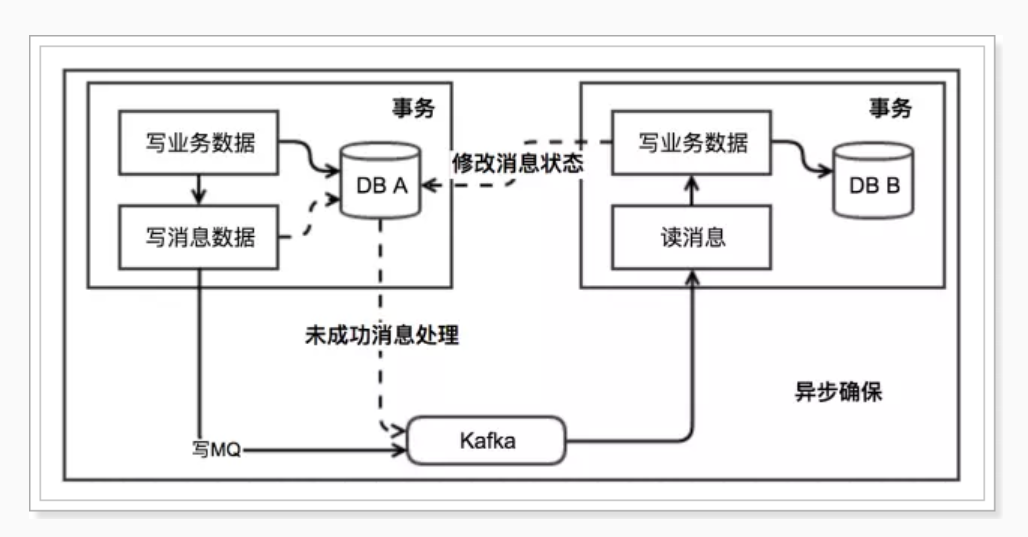
事務(wù)發(fā)起者
開啟本地事務(wù)
執(zhí)行事務(wù)相關(guān)業(yè)務(wù)
發(fā)送消息到MQ
把消息持久化到數(shù)據(jù)庫,標(biāo)記為已發(fā)送
提交本地事務(wù)
事務(wù)接收者
接收消息
開啟本地事務(wù)
處理事務(wù)相關(guān)業(yè)務(wù)
修改數(shù)據(jù)庫消息狀態(tài)為已消費(fèi)
提交本地事務(wù)
額外的定時任務(wù)
定時掃描表中超時未消費(fèi)的消息,重新發(fā)送
優(yōu)點(diǎn)
與tcc相比,實(shí)現(xiàn)方式較為簡單,開發(fā)成本低。
缺點(diǎn)
數(shù)據(jù)一致性完全依賴于消息服務(wù),因此消息服務(wù)必須是可靠的。
需要處理被動業(yè)務(wù)方的冪等問題
被動業(yè)務(wù)失敗不會導(dǎo)致主動業(yè)務(wù)的回滾,而是重試被動的業(yè)務(wù)
事務(wù)業(yè)務(wù)與消息發(fā)送業(yè)務(wù)耦合、業(yè)務(wù)數(shù)據(jù)與消息表要在一起
3.6.2 獨(dú)立消息服務(wù)
為了解決上述問題,我們會引入一個獨(dú)立的消息服務(wù),來完成對消息的持久化、發(fā)送、確認(rèn)、失敗重試等一系列行為,大概的模型如下:

一次消息發(fā)送時序圖:
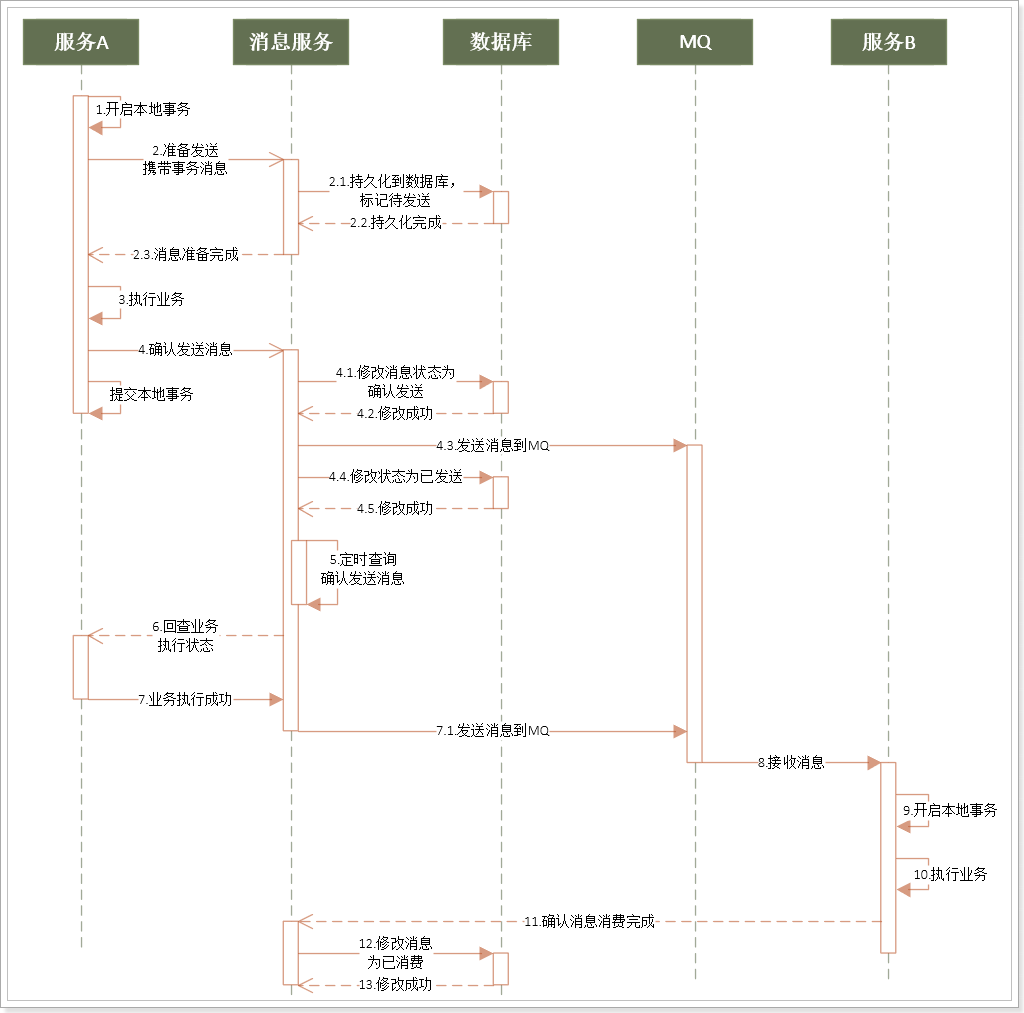
事務(wù)發(fā)起者A的基本執(zhí)行步驟:
開啟本地事務(wù)
通知消息服務(wù),準(zhǔn)備發(fā)送消息(消息服務(wù)將消息持久化,標(biāo)記為準(zhǔn)備發(fā)送)
執(zhí)行本地業(yè)務(wù):執(zhí)行失敗則終止,通知消息服務(wù),取消發(fā)送(消息服務(wù)修改訂單狀態(tài));執(zhí)行成功則繼續(xù),通知消息服務(wù),確認(rèn)發(fā)送(消息服務(wù)發(fā)送消息、修改訂單狀態(tài))
提交本地事務(wù)
消息服務(wù)本身提供下面的接口:
準(zhǔn)備發(fā)送:把消息持久化到數(shù)據(jù)庫,并標(biāo)記狀態(tài)為準(zhǔn)備發(fā)送
取消發(fā)送:把數(shù)據(jù)庫消息狀態(tài)修改為取消
確認(rèn)發(fā)送:把數(shù)據(jù)庫消息狀態(tài)修改為確認(rèn)發(fā)送。嘗試發(fā)送消息,成功后修改狀態(tài)為已發(fā)送
確認(rèn)消費(fèi):消費(fèi)者已經(jīng)接收并處理消息,把數(shù)據(jù)庫消息狀態(tài)修改為已消費(fèi)
定時任務(wù):定時掃描數(shù)據(jù)庫中狀態(tài)為確認(rèn)發(fā)送的消息,然后詢問對應(yīng)的事務(wù)發(fā)起者,事務(wù)業(yè)務(wù)執(zhí)行是否成功,結(jié)果:業(yè)務(wù)執(zhí)行成功,則嘗試發(fā)送消息,成功后修改狀態(tài)為已發(fā)送;業(yè)務(wù)執(zhí)行失敗,則把數(shù)據(jù)庫消息狀態(tài)修改為取消
事務(wù)參與者B的基本步驟:
接收消息
開啟本地事務(wù)
執(zhí)行業(yè)務(wù)
通知消息服務(wù),消息已經(jīng)接收和處理
提交事務(wù)
優(yōu)點(diǎn):
解除了事務(wù)業(yè)務(wù)與消息相關(guān)業(yè)務(wù)的耦合
缺點(diǎn):
實(shí)現(xiàn)起來比較復(fù)雜
3.6.3 RabbitMQ的消息確認(rèn)
RabbitMQ確保消息不丟失的思路比較奇特,并沒有使用傳統(tǒng)的本地表,而是利用了消息的確認(rèn)機(jī)制:
生產(chǎn)者確認(rèn)機(jī)制:確保消息從生產(chǎn)者到達(dá)MQ不會有問題
消息生產(chǎn)者發(fā)送消息到RabbitMQ時,可以設(shè)置一個異步的監(jiān)聽器,監(jiān)聽來自MQ的ACK
MQ接收到消息后,會返回一個回執(zhí)給生產(chǎn)者:
消息到達(dá)交換機(jī)后路由失敗,會返回失敗ACK
消息路由成功,持久化失敗,會返回失敗ACK
消息路由成功,持久化成功,會返回成功ACK
生產(chǎn)者提前編寫好不同回執(zhí)的處理方式
失敗回執(zhí):等待一定時間后重新發(fā)送
成功回執(zhí):記錄日志等行為
消費(fèi)者確認(rèn)機(jī)制:確保消息能夠被消費(fèi)者正確消費(fèi)
消費(fèi)者需要在監(jiān)聽隊(duì)列的時候指定手動ACK模式
RabbitMQ把消息投遞給消費(fèi)者后,會等待消費(fèi)者ACK,接收到ACK后才刪除消息,如果沒有接收到ACK消息會一直保留在服務(wù)端,如果消費(fèi)者斷開連接或異常后,消息會投遞給其它消費(fèi)者。
消費(fèi)者處理完消息,提交事務(wù)后,手動ACK。如果執(zhí)行過程中拋出異常,則不會ACK,業(yè)務(wù)處理失敗,等待下一條消息
經(jīng)過上面的兩種確認(rèn)機(jī)制,可以確保從消息生產(chǎn)者到消費(fèi)者的消息安全,再結(jié)合生產(chǎn)者和消費(fèi)者兩端的本地事務(wù),即可保證一個分布式事務(wù)的最終一致性。
3.7 AT模式
基本原理:

有沒有感覺跟TCC的執(zhí)行很像,都是分兩個階段:
一階段:執(zhí)行本地事務(wù),并返回執(zhí)行結(jié)果
二階段:根據(jù)一階段的結(jié)果,判斷二階段做法:提交或回滾
但AT模式底層做的事情可完全不同,而且第二階段根本不需要我們編寫,全部有Seata自己實(shí)現(xiàn)了。也就是說:我們寫的代碼與本地事務(wù)時代碼一樣,無需手動處理分布式事務(wù)。
3.7.1 詳細(xì)處理流程
1)?一階段
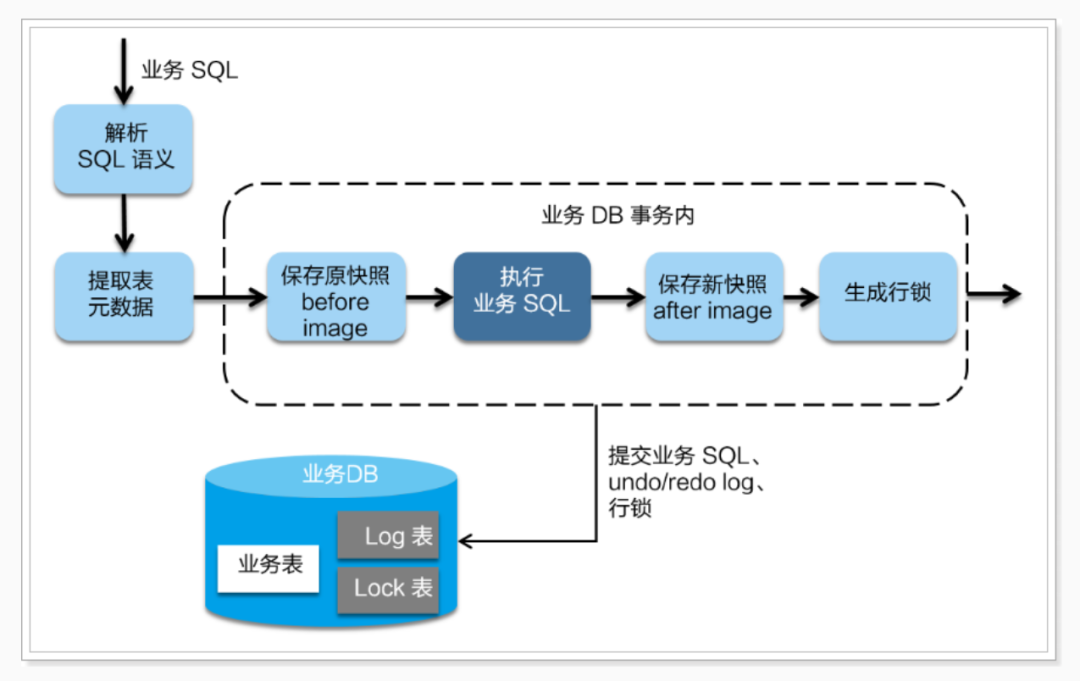
在一階段,Seata 會攔截“業(yè)務(wù) SQL”,首先解析SQL語義,找到“業(yè)務(wù) SQL”要更新的業(yè)務(wù)數(shù)據(jù),在業(yè)務(wù)數(shù)據(jù)被更新前,將其保存成“before image”,然后執(zhí)行“業(yè)務(wù) SQL”更新業(yè)務(wù)數(shù)據(jù),在業(yè)務(wù)數(shù)據(jù)更新之后,再將其保存成“after image”,最后獲取全局行鎖,提交事務(wù)。以上操作全部在一個數(shù)據(jù)庫事務(wù)內(nèi)完成,這樣保證了一階段操作的原子性。
這里的before image和after image類似于數(shù)據(jù)庫的undo和redo日志,但其實(shí)是用數(shù)據(jù)庫模擬的
2)?二階段
二階段如果是提交的話,因?yàn)椤皹I(yè)務(wù) SQL”在一階段已經(jīng)提交至數(shù)據(jù)庫, 所以 Seata 框架只需將一階段保存的快照數(shù)據(jù)和行鎖刪掉,完成數(shù)據(jù)清理即可。
二階段如果是回滾的話,Seata 就需要回滾一階段已經(jīng)執(zhí)行的“業(yè)務(wù) SQL”,還原業(yè)務(wù)數(shù)據(jù)。回滾方式便是用“before image”還原業(yè)務(wù)數(shù)據(jù);但在還原前要首先要校驗(yàn)臟寫,對比“數(shù)據(jù)庫當(dāng)前業(yè)務(wù)數(shù)據(jù)”和 “after image”,如果兩份數(shù)據(jù)完全一致就說明沒有臟寫,可以還原業(yè)務(wù)數(shù)據(jù),如果不一致就說明有臟寫,出現(xiàn)臟寫就需要轉(zhuǎn)人工處理。
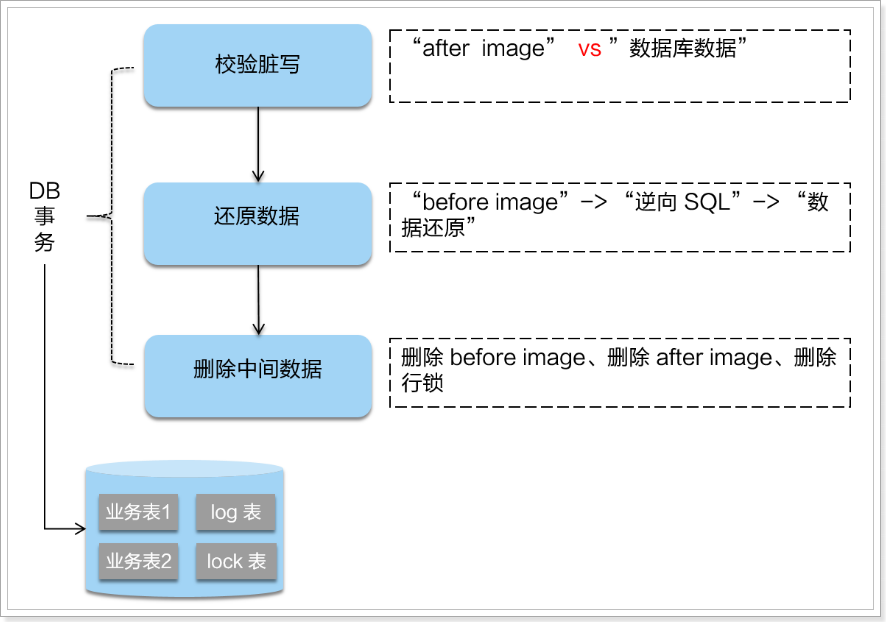
不過因?yàn)橛腥宙i機(jī)制,所以可以降低出現(xiàn)臟寫的概率。
AT 模式的一階段、二階段提交和回滾均由 Seata 框架自動生成,用戶只需編寫“業(yè)務(wù) SQL”,便能輕松接入分布式事務(wù),AT 模式是一種對業(yè)務(wù)無任何侵入的分布式事務(wù)解決方案。
注:Seata的詳細(xì)流程不做贅述。
[參看]:
分布式事務(wù)解決方案
分布式系統(tǒng)一致性解決方案
https://ivanzz1001.github.io/records/post/distribute-systems/2018/05/30/distribute-transaction
喜歡,在看