
為什么 Java 不采用 Redis 這種漸進式 rehash?
Redis 中的 hash 擴容是漸進式 rehash,這個擴容過程和我們 Java 中的 HashMap 有很大不同。那么在面試過程中,很多面試官喜歡問,為什么 Java 不采用 Redis 這種漸進式 rehash 呢?
借這個周末的空閑時間,我們先來看看 Redis 是如何進行漸進式 rehash,然后再回答大家,Java 為什么不采用 Redis 這種漸進式 rehash。
Redis 中的 rehash 過程
redis 字典(hash 表)當數(shù)據(jù)越來越多的時候,就會發(fā)生擴容,也就是 rehash。
對比 Java 中的 hashmap,當數(shù)據(jù)數(shù)量達到閾值的時候(0.75),就會發(fā)生rehash,hash 表長度變?yōu)樵瓉淼亩叮瑢⒃?hash 表數(shù)據(jù)全部重新計算 hash 地址,重新分配位置,達到 rehash 目的。
redis 中的 hash 表采用的是漸進式 hash 的方式。
redis 字典(hash 表)底層有兩個數(shù)組,還有一個 rehashidx 用來控制rehash。
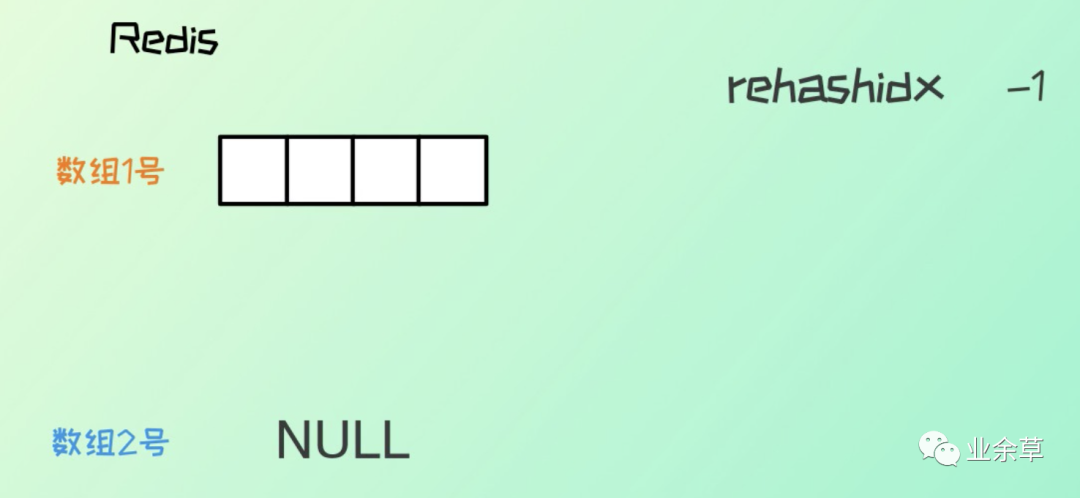

初始默認 hash 長度為 4,當元素個數(shù)與 hash 表長度一致時,就發(fā)生擴容,hash 長度變?yōu)樵瓉淼亩丁?/section>
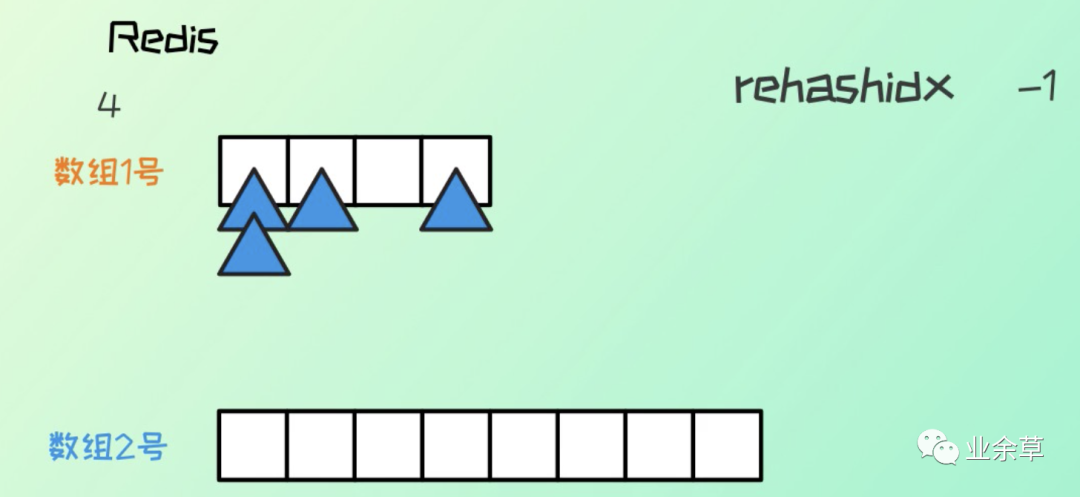
redis 中的 hash 則是執(zhí)行的單步 rehash 的過程。
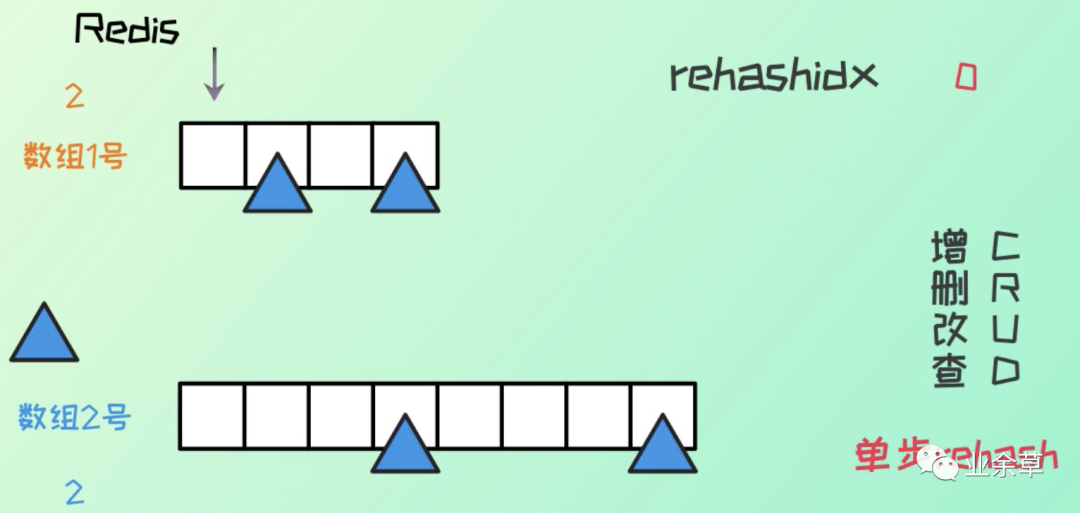
每次的增刪改查,rehashidx + 1,然后執(zhí)行對應原 hash 表 rehashidx 索引位置的 rehash。
總結(jié)
在擴容和收縮的時候,如果哈希字典中有很多元素,一次性將這些鍵全部 rehash 到ht[1]的話,可能會導致服務器在一段時間內(nèi)停止服務。所以,采用漸進式 rehash 的方式,詳細步驟如下:
為
ht[1]分配空間,讓字典同時持有ht[0]和ht[1]兩個哈希表將
rehashindex的值設(shè)置為0,表示rehash工作正式開始在 rehash 期間,每次對字典執(zhí)行增刪改查操作是,程序除了執(zhí)行指定的操作以外,還會順帶將
ht[0]哈希表在rehashindex索引上的所有鍵值對 rehash 到ht[1],當 rehash 工作完成以后,rehashindex的值+1隨著字典操作的不斷執(zhí)行,最終會在某一時間段上
ht[0]的所有鍵值對都會被 rehash 到ht[1],這時將rehashindex的值設(shè)置為-1,表示 rehash 操作結(jié)束。
漸進式 rehash 采用的是一種分而治之的方式,將 rehash 的操作分攤在每一個的訪問中,避免集中式 rehash 而帶來的龐大計算量。
需要注意的是在漸進式 rehash 的過程,如果有增刪改查操作時,如果index大于rehashindex,訪問ht[0],否則訪問ht[1]。
Java 為什么不采用漸進式 rehash?
jdk 中的 HashMap 的重排過程沒有采用漸進的方法。盡管 Jdk HashMap 的重新哈希計算非常優(yōu)雅和有效,但是當原始 HashMap 中的元素數(shù)量包含許多條目時,仍然需要花費大量時間。
像 Redis 這樣的漸進式哈希可以有效地將工作負載均勻分配,這可以顯著減少調(diào)整大小/哈希的時間。
那么 Java 為什么不用呢?
因為,如果考慮類似的增量重新哈希的成本和收益,通過國外網(wǎng)友對 HashMap 的實驗,證明這些成本并不是微不足道的,收益也并不理想。
逐步重新哈希 HashMap:
平均使用 50% 以上的內(nèi)存,因為它需要在增量重新哈希期間保留舊表和新表。 每次操作的計算成本較高。 重新哈希仍然不是完全增量的,因為分配新哈希表數(shù)組必須一次完成。 任何操作的漸進復雜性都沒有改善。 由于無法預測的 GC 暫停,幾乎完全不需要增量哈希的任何事情都可以在 Java 中實現(xiàn),那么為什么要麻煩呢?
以上就是 Java 不采用漸進式 rehash 的原因。如果你也有其他理由或想法,歡迎留言 + 點贊 + 轉(zhuǎn)發(fā)!