
【Python】手把手教你用Python爬取某網(wǎng)小說(shuō)數(shù)據(jù),并進(jìn)行可視化分析

網(wǎng)絡(luò)文學(xué)是以互聯(lián)網(wǎng)為展示平臺(tái)和傳播媒介,借助相關(guān)互聯(lián)網(wǎng)手段來(lái)表現(xiàn)文學(xué)作品及含有一部分文字作品的網(wǎng)絡(luò)技術(shù)產(chǎn)品,在當(dāng)前成為一種新興的文學(xué)現(xiàn)象,并快速興起,各種網(wǎng)絡(luò)小說(shuō)也是層出不窮,今天我們使用selenium爬取紅袖天香網(wǎng)站小說(shuō)數(shù)據(jù),并做簡(jiǎn)單數(shù)據(jù)可視化分析。
紅袖添香建于1999年,是全球領(lǐng)先的女性文學(xué)數(shù)字版權(quán)運(yùn)營(yíng)商之一,日更新小說(shuō)5000部,為超過(guò)240萬(wàn)注冊(cè)用戶提供涵蓋小說(shuō)、散文、雜文、詩(shī)歌、歌詞、劇本、日記等體裁的高品質(zhì)創(chuàng)作和閱讀服務(wù),在言情、職場(chǎng)小說(shuō)等女性文學(xué)寫作及出版領(lǐng)域獨(dú)占高地。(百度百科)
網(wǎng)頁(yè)初步分析
打開(kāi)網(wǎng)頁(yè)如圖所示:
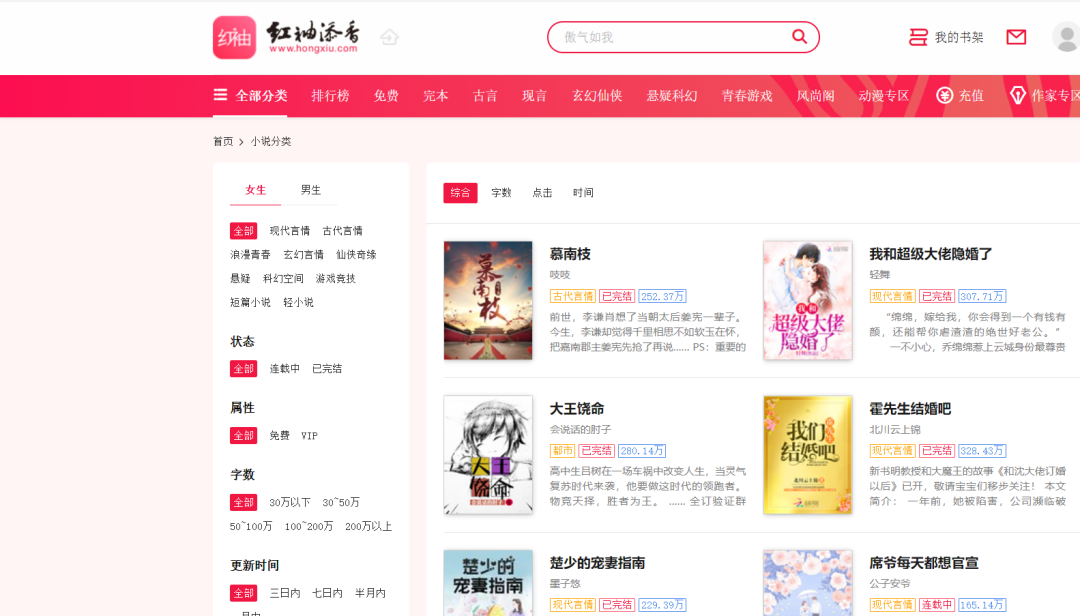
我們要把小說(shuō)分類里面的所有小說(shuō)數(shù)據(jù)全部抓取下來(lái):總共有50個(gè)頁(yè)面,每頁(yè)20條數(shù)據(jù),一共1000條數(shù)據(jù)。
首先使用requests第三方庫(kù)請(qǐng)求數(shù)據(jù),如下所示:
import requests
url = 'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_1' # 第一頁(yè)url
headers = { 'xxx' : 'xxx'}
res = requests.get(url,headers=headers)
print(data.content.decode('utf-8'))
我們發(fā)現(xiàn)請(qǐng)求回來(lái)的數(shù)據(jù)并沒(méi)有第一頁(yè)的小說(shuō)數(shù)據(jù)信息,很明顯數(shù)據(jù)不在網(wǎng)頁(yè)源碼里面,然后通過(guò)查看network,發(fā)現(xiàn)了這樣的請(qǐng)求字段:
_csrfToken: btXPBUerIB1DABWiVC7TspEYvekXtzMghhCMdN43
_: 1630664902028
這個(gè)是做了js加密,所以為了避免分析加密方式,使用selenium爬取數(shù)據(jù)可能更快一些。
selenium 爬取數(shù)據(jù)
01 初步測(cè)試
from selenium import webdriver
import time
url = 'https://y.qq.com/n/ryqq/songDetail/0006wgUu1hHP0N'
driver = webdriver.Chrome()
driver.get(url)
結(jié)果運(yùn)行正常,沒(méi)有問(wèn)題。
02 小說(shuō)數(shù)據(jù)
明確要爬取的小說(shuō)數(shù)據(jù)信息
圖片鏈接、名稱、作者、類型、是否完結(jié)、人氣、簡(jiǎn)介
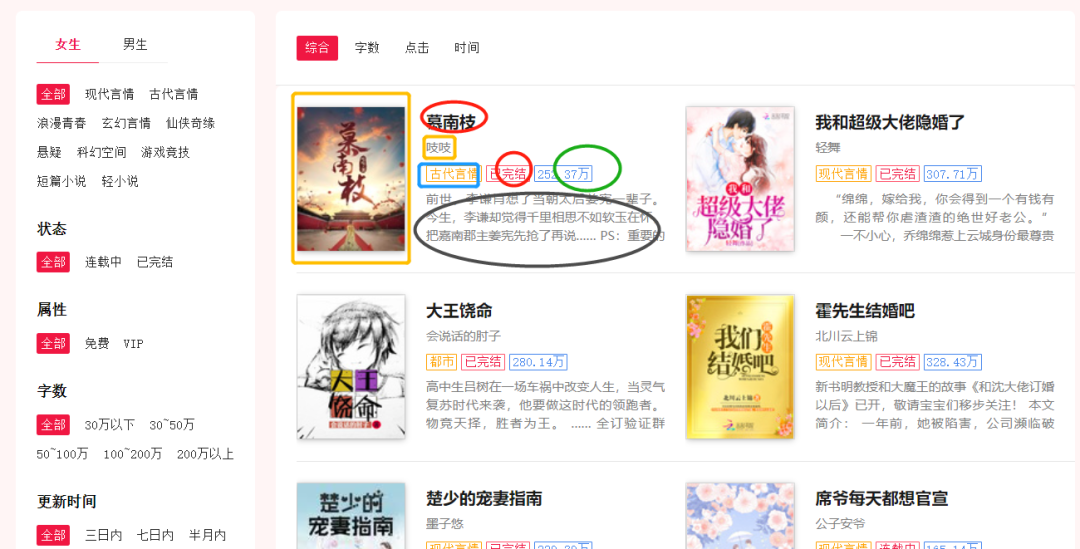
然后通過(guò)點(diǎn)擊下一頁(yè)的按鈕觀察是否是動(dòng)態(tài)數(shù)據(jù):發(fā)現(xiàn)不是;url規(guī)律如下所示:
'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_1' # 第一頁(yè)的url
'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_2' # 第二頁(yè)的url
03 解析數(shù)據(jù)
下面是解析頁(yè)面數(shù)據(jù)的代碼:
def get_data():
ficList = [] # 存儲(chǔ)每一頁(yè)的數(shù)據(jù)
items = driver.find_elements_by_xpath("http://div[@class="right-book-list"]/ul/li")
for item in items:
dic = {}
imgLink = item.find_element_by_xpath("./div[1]/a/img").get_attribute('src')
# 1.圖片鏈接 2.小說(shuō)名稱(name) 3.小說(shuō)類型(types) ....
dic['img'] = imgLink
# ......
ficList.append(dic)
這里有幾個(gè)需要注意的點(diǎn):
注意xpath語(yǔ)句書寫,注意細(xì)節(jié),不要出錯(cuò); 對(duì)于小說(shuō)簡(jiǎn)介,有的簡(jiǎn)介比較長(zhǎng),有換行符,為了便于存儲(chǔ),需要使用字符串的replace方法把'\n'替換為空字符串
04 翻頁(yè)爬取
下面是翻頁(yè)爬取數(shù)據(jù)的代碼:
try:
time.sleep(3)
js = "window.scrollTo(0,100000)"
driver.execute_script(js)
while driver.find_element_by_xpath( "http://div[@class='lbf-pagination']/ul/li[last()]/a"):
driver.find_element_by_xpath("http://div[@class='lbf-pagination']/ul/li[last()]/a").click()
time.sleep(3)
getFiction()
print(count, "*" * 20)
count += 1
if count >= 50:
return None
except Exception as e:
print(e)
代碼說(shuō)明:
使用
try語(yǔ)句,進(jìn)行異常處理,防止有什么特殊頁(yè)面的元素?zé)o法匹配或者其它問(wèn)題。driver執(zhí)行js代碼,操作滾輪,滑動(dòng)到頁(yè)面底部。
js = "window.scrollTo(0,100000)"
driver.execute_script(js)time.sleep(n)因?yàn)檠h(huán)里面添加了解析函數(shù)(driver定位)需要等待數(shù)據(jù)加載完全。while循環(huán)語(yǔ)句,while后面的是‘下一頁(yè)’按鈕定位,保證循環(huán)的爬取下一頁(yè)的數(shù)據(jù)。使用
if語(yǔ)句作為判斷條件,作為while循環(huán)推出的條件,然后要使用return退出函數(shù),break不行。
05 數(shù)據(jù)保存
titles = ['imgLink', 'name', 'author', 'types', 'pink','popu','intro']
with open('hx.csv',mode='w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f, titles)
writer.writeheader()
writer.writerows(data)
print('寫入成功')
06 程序運(yùn)行
結(jié)果如下,顯示的1000條數(shù)據(jù):

使用selenium爬取數(shù)據(jù)的一些注意點(diǎn):
① 點(diǎn)擊下一頁(yè)之后,數(shù)據(jù)不可能瞬間加載完全,一旦數(shù)據(jù)沒(méi)有加載完全,那么使用webdriver的find_Element_by_xpath語(yǔ)句就會(huì)定位不到dom文檔上的元素,進(jìn)而拋出一個(gè)錯(cuò)誤:
selenium.StaleElementReferenceException:
stale element reference: element is not
attached to the page document
大概意思:所引用的元素已過(guò)時(shí),不再依附于當(dāng)前頁(yè)面。產(chǎn)生原因:通常情況下,這是因?yàn)轫?yè)面進(jìn)行了刷新或跳轉(zhuǎn)。
解決方法:
1.重新使用 findElement 或 findElements 方法進(jìn)行元素定位即可。
2.或者只需要使用webdriver.Chrome().refresh刷新一下網(wǎng)頁(yè)就可以,還要在前面等待幾秒鐘再刷新,time.sleep(5)。關(guān)于這個(gè)報(bào)錯(cuò)的解決方法,參考下面博客:
https://www.cnblogs.com/qiu-hua/p/12603675.html
② 在動(dòng)態(tài)點(diǎn)擊下一頁(yè)按鈕時(shí),需要精準(zhǔn)定位到下一頁(yè)的按鈕,其次很重要的一共問(wèn)題,selenium打開(kāi)瀏覽器頁(yè)面時(shí),需要窗口最大化。
由于窗口右側(cè)有一個(gè)絕對(duì)定位的二維碼小窗口,如果不窗口最大化,那個(gè)該窗口就會(huì)擋住下一頁(yè)按鈕導(dǎo)致無(wú)法點(diǎn)擊,這個(gè)需要注意。
數(shù)據(jù)分析與可視化
打開(kāi)文件
import pandas as pd
data = pd.read_csv('./hx.csv')
data.head()
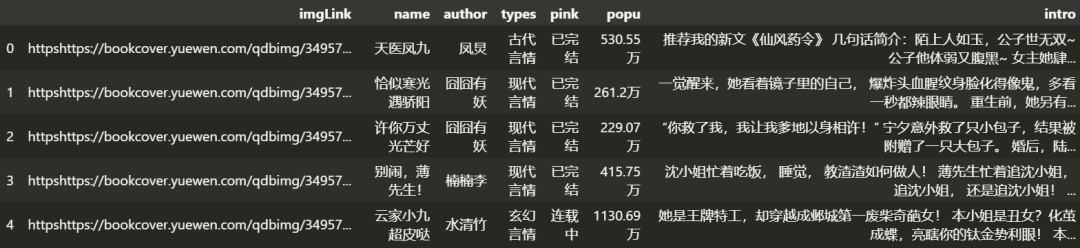
根據(jù)我們的數(shù)據(jù)信息可以做如下的可視化展示:
01 不同類型小說(shuō)占比
types = ['現(xiàn)代言情', '古代言情', '玄幻', '玄幻言情', '科幻空間', '仙俠', '都市', '歷史', '科幻', '仙俠奇緣', '浪漫青春', '其它']
number = [343, 285, 83, 56, 45, 41, 41, 25, 14, 14, 13,40]
pyecharts餅圖
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
pie=(
Pie()
.add(
"",
[list(z) for z in zip(types, number)],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同類型小說(shuō)占比"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_top="15%", pos_left="2%"
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie.html')
結(jié)果如圖
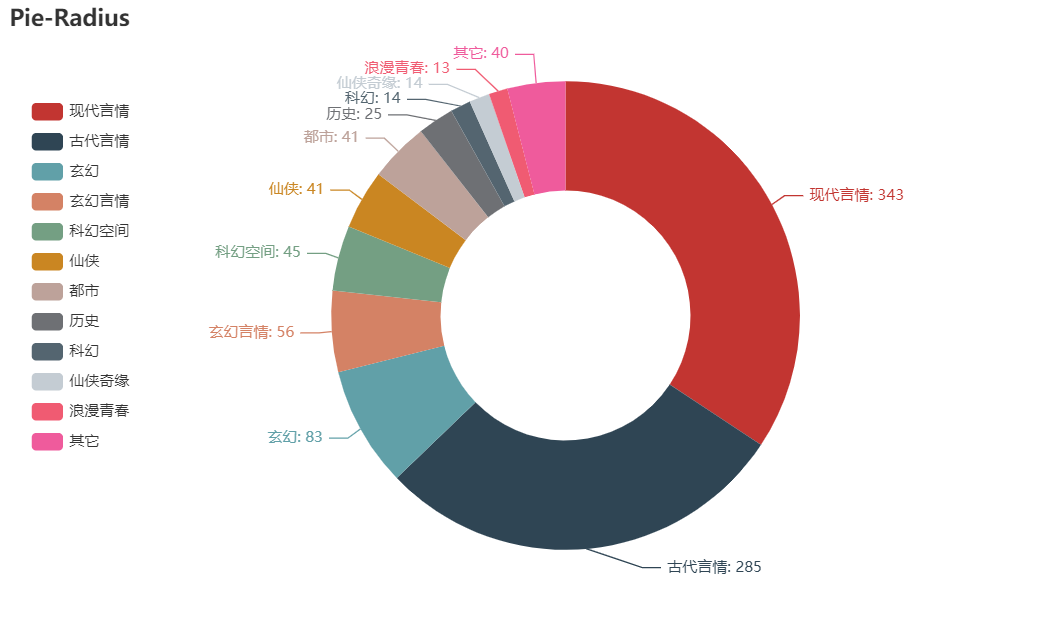
由圖可知,言情小說(shuō)占據(jù)所有小說(shuō)半壁江山。
02 完結(jié)小說(shuō)占比
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
ty = ['已完結(jié)','連載中']
num = [723,269]
pie=(
Pie()
.add("", [list(z) for z in zip(ty,num)])
.set_global_opts(title_opts=opts.TitleOpts(title="完結(jié)小說(shuō)占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie1.html')
結(jié)果如圖:
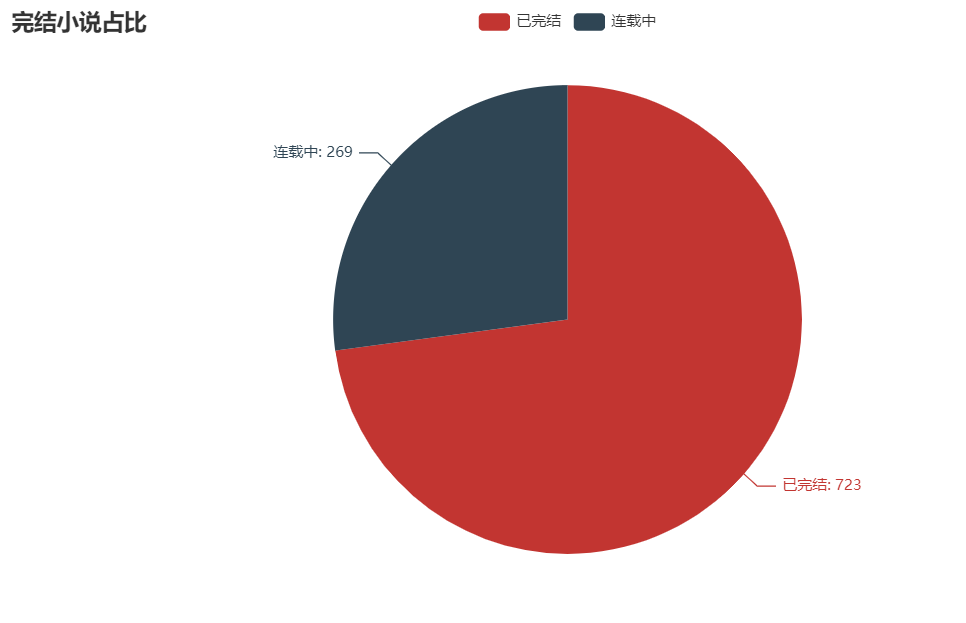
由圖可知,仍有超1/4的小說(shuō)正在連載中。
03 小說(shuō)簡(jiǎn)介詞云圖展示
生成.txt文件
with open('hx.txt','a',encoding='utf-8') as f:
for s in data['intro']:
f.write(s + '\n')
初始化設(shè)置
# 導(dǎo)入相應(yīng)的庫(kù)
import jieba
from PIL import Image
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 導(dǎo)入文本數(shù)據(jù)并進(jìn)行簡(jiǎn)單的文本處理
# 去掉換行符和空格
text = open("./hx.txt",encoding='utf-8').read()
text = text.replace('\n',"").replace("\u3000","")
# 分詞,返回結(jié)果為詞的列表
text_cut = jieba.lcut(text)
# 將分好的詞用某個(gè)符號(hào)分割開(kāi)連成字符串
text_cut = ' '.join(text_cut)
詞云展示
word_list = jieba.cut(text)
space_word_list = ' '.join(word_list)
# print(space_word_list) 打印文字 可以省略
# 調(diào)用包PIL中的open方法,讀取圖片文件,通過(guò)numpy中的array方法生成數(shù)組
mask_pic = np.array(Image.open("./xin.png"))
word = WordCloud(
font_path='C:/Windows/Fonts/simfang.ttf', # 設(shè)置字體,本機(jī)的字體
mask=mask_pic, # 設(shè)置背景圖片
background_color='white', # 設(shè)置背景顏色
max_font_size=150, # 設(shè)置字體最大值
max_words=2000, # 設(shè)置最大顯示字?jǐn)?shù)
stopwords={'的'} # 設(shè)置停用詞,停用詞則不在詞云途中表示
).generate(space_word_list)
image = word.to_image()
word.to_file('h.png') # 保存圖片
image.show()
結(jié)果如圖

這里不能從圖中看出特別的內(nèi)容,我們可以考慮其他的一些更加有效的自然語(yǔ)言分析與處理方法,此處留給讀者朋友們一起思考。
04 根據(jù)類型分析小說(shuō)熱度排行
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(list(c['types'].values))
bar.add_yaxis('小說(shuō)熱度排行',numList)
bar.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
bar.render()
結(jié)果如圖
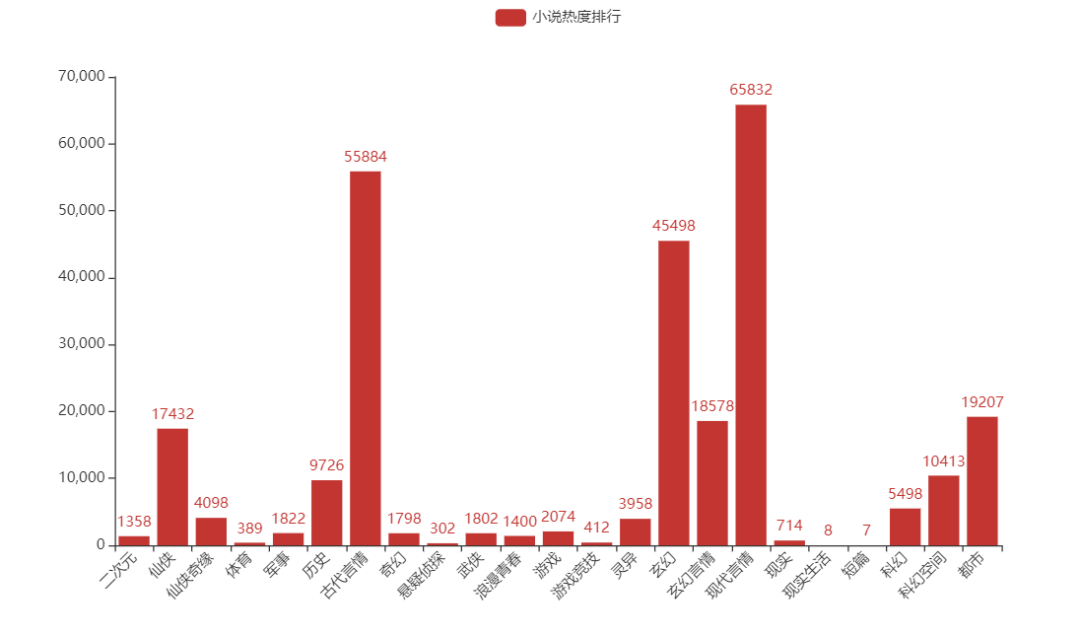
可以看出來(lái),言情小說(shuō)從古至今都是永恒的話題...
言情小說(shuō)是中國(guó)舊體小說(shuō)的一種,又稱才子佳人小說(shuō)。以講述異性相愛(ài)為中心,通過(guò)完整的故事情節(jié)和具體的環(huán)境描寫來(lái)反映愛(ài)情的心理、狀態(tài)、事物等社會(huì)生活的一種文學(xué)體裁。
言情小說(shuō)類型很多主要分為古代,現(xiàn)代等題材。其中又有重生文、穿越文、反穿越文、科幻文、宅斗文、宮斗文、玄幻文、公路文等不同題材。(百度百科)
05 不同作者熱點(diǎn)小說(shuō)占比
我們通過(guò)查看作家寫的小說(shuō)數(shù)量,得到以下結(jié)果:
data['author'].value_counts()
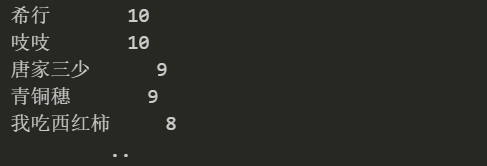
根據(jù)寫作數(shù)量最多的前三位作家,他們只寫了言情小說(shuō),后兩位寫了多種小說(shuō)。接下來(lái)分別分析這些小說(shuō)家中言情小說(shuō)家及其他小說(shuō)家的熱度。
言情小說(shuō)家熱度
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
attr = ["希行", "吱吱", "青銅穗"]
v1 = [1383,1315,1074]
pie=(
Pie()
.add("", [list(z) for z in zip(attr,v1)])
.set_global_opts(title_opts=opts.TitleOpts(title="言情小說(shuō)作家熱度"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie.html')
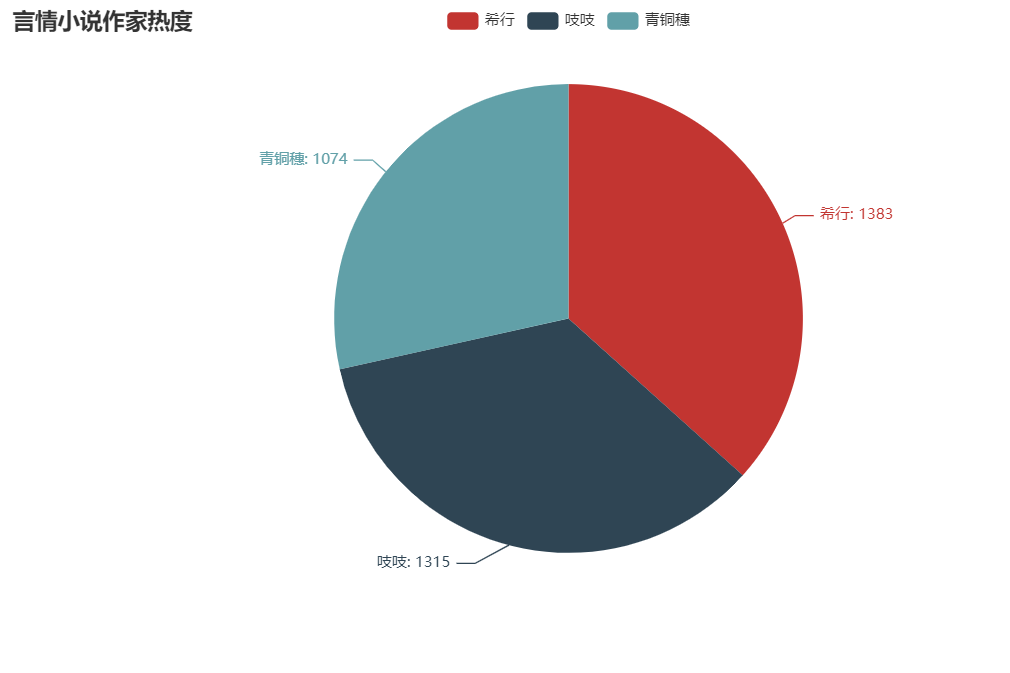
這三個(gè)小說(shuō)家熱度伯仲之間,當(dāng)然,熱度最高的當(dāng)屬希行。
希行,為筆名,原名裴云, 女, 起點(diǎn)中文網(wǎng)古言代表作家之一,女性網(wǎng)絡(luò)文學(xué)超人氣作者。中國(guó)作家協(xié)會(huì)會(huì)員。橙瓜見(jiàn)證·網(wǎng)絡(luò)文學(xué)20年百?gòu)?qiáng)大神作家。2009年創(chuàng)作至今,希行已完結(jié)作品已有11部,創(chuàng)作1000多萬(wàn)字,作品大多簡(jiǎn)繁出版,其中《嬌娘醫(yī)經(jīng)》、《君九齡》已出售影視權(quán)。(百度百科)
兩大小說(shuō)家熱度排行
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
#指定柱狀圖的橫坐標(biāo)
bar.add_xaxis(['玄幻','奇幻','仙俠'])
#指定柱狀圖的縱坐標(biāo),而且可以指定多個(gè)縱坐標(biāo)
bar.add_yaxis("唐家三少", [2315,279,192])
bar.add_yaxis("我吃西紅柿", [552,814,900])
#指定柱狀圖的標(biāo)題
bar.set_global_opts(title_opts=opts.TitleOpts(title="熱度小說(shuō)排行"))
#參數(shù)指定生成的html名稱
bar.render('tw.html')
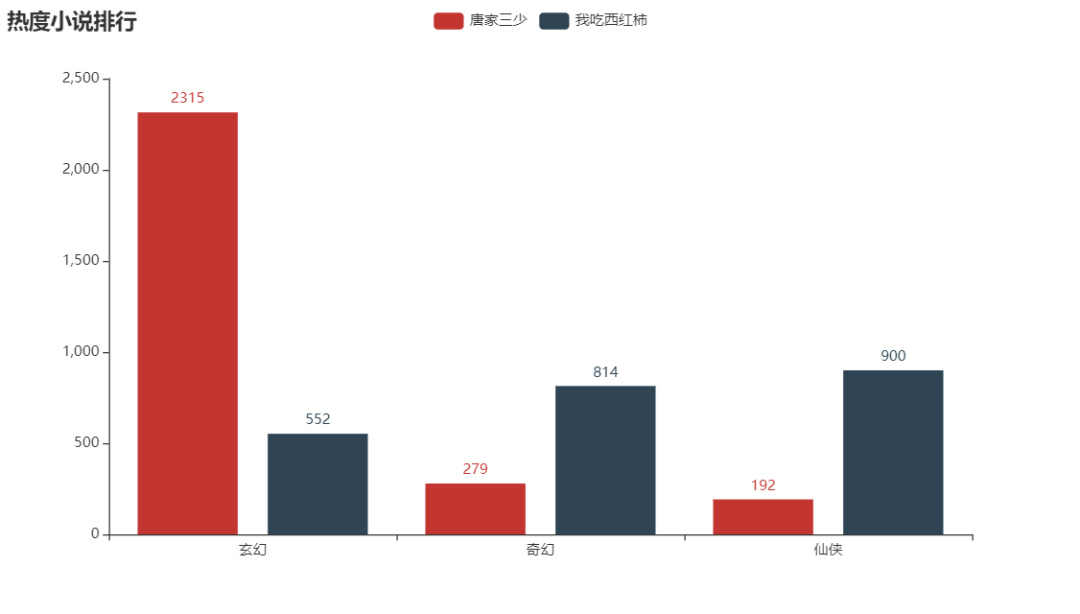
如圖所示,唐家三少的玄幻小說(shuō)更加突出,而 我吃西紅柿 三種小說(shuō)熱度更加平均。
寫在最后
這個(gè)爬取紅袖添香網(wǎng)站小說(shuō)頁(yè)面數(shù)據(jù),我們使用到selenium進(jìn)行數(shù)據(jù)抓取,由于頁(yè)面的js加密,所以使用到selenium,然后對(duì)于注意點(diǎn)進(jìn)行總結(jié):
① selenium爬取數(shù)據(jù)需要注意幾點(diǎn):
各種元素的定位需要精確; 由于使用selenium需要加載js代碼,元素需要全部加載完全,才能進(jìn)行定位,所以打開(kāi)網(wǎng)頁(yè)需要設(shè)置time.sleep(n); 然后對(duì)于很多網(wǎng)站都有個(gè)絕對(duì)定位的元素,可能是二維碼...,固定在電腦屏幕的位置,不會(huì)隨著頁(yè)面滾輪的滾動(dòng)而移動(dòng),所以需要頁(yè)面最大化,防止該窗口擋住頁(yè)面元素,導(dǎo)致無(wú)法點(diǎn)擊或者其它操作。
② 在數(shù)據(jù)可視化展示的時(shí)候要進(jìn)行數(shù)據(jù)清洗,因?yàn)橛械臄?shù)據(jù)是不規(guī)范的,比如會(huì)出現(xiàn)這樣的錯(cuò)誤:
'utf-8' codec can't decode byte 0xcb in
position 2: invalid continuation byte
這是由于編碼方式的不同導(dǎo)致,一般通過(guò)查看頁(yè)面meta標(biāo)簽的charset屬性得到編碼方式,設(shè)置pandas打開(kāi)文件時(shí)的encoding的屬性值;如果還是報(bào)錯(cuò),可以把屬性值修改成 'gb18030'
<meta charset="UTF-8">備注,本文僅以學(xué)習(xí)交流,對(duì)于爬蟲淺嘗輒止,以免對(duì)服務(wù)器增加負(fù)擔(dān)。
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: