
【深度學(xué)習(xí)】Vision Transformer in CV
https://github.com/IDEACVR/awesome-detection-transformer
本文主要包含跟Transformer相關(guān)的CV文章,用簡(jiǎn)短的話(huà)來(lái)描述一下涉及到文章的核心idea。可以看作是vision transformer的idea集,查漏補(bǔ)缺使用。需要精讀的文章前面加了*號(hào)。
Image Classification
Uniform-scale
*ViT [paper] [code]
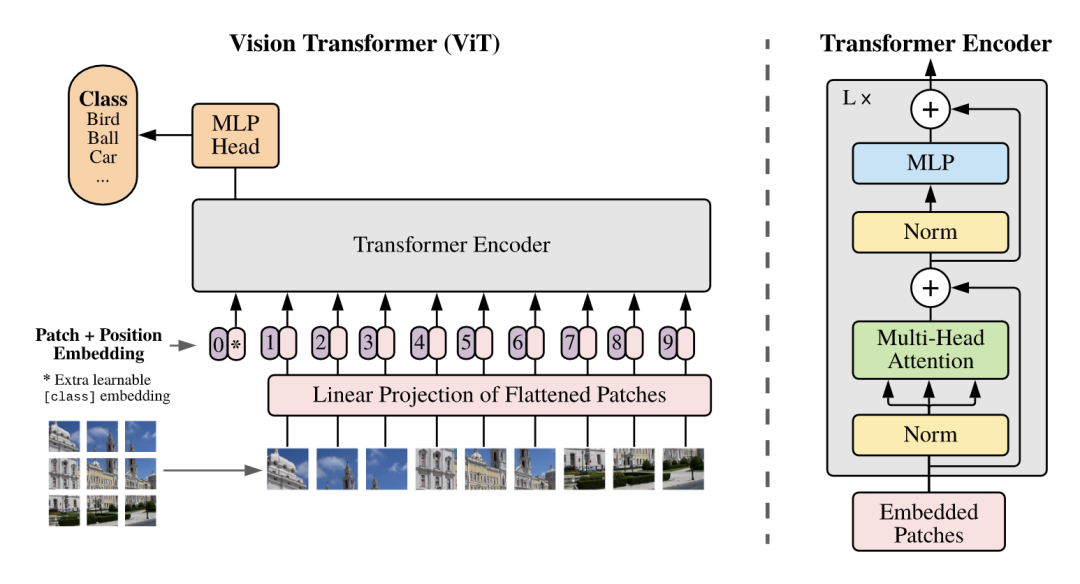
最簡(jiǎn)潔的Vision Transformer模型,先將圖片分成16x16的patch塊,送入transformer encoder,第一個(gè)cls token的輸出送入mlp head得到預(yù)測(cè)結(jié)果。
*DeiT [paper] [code]
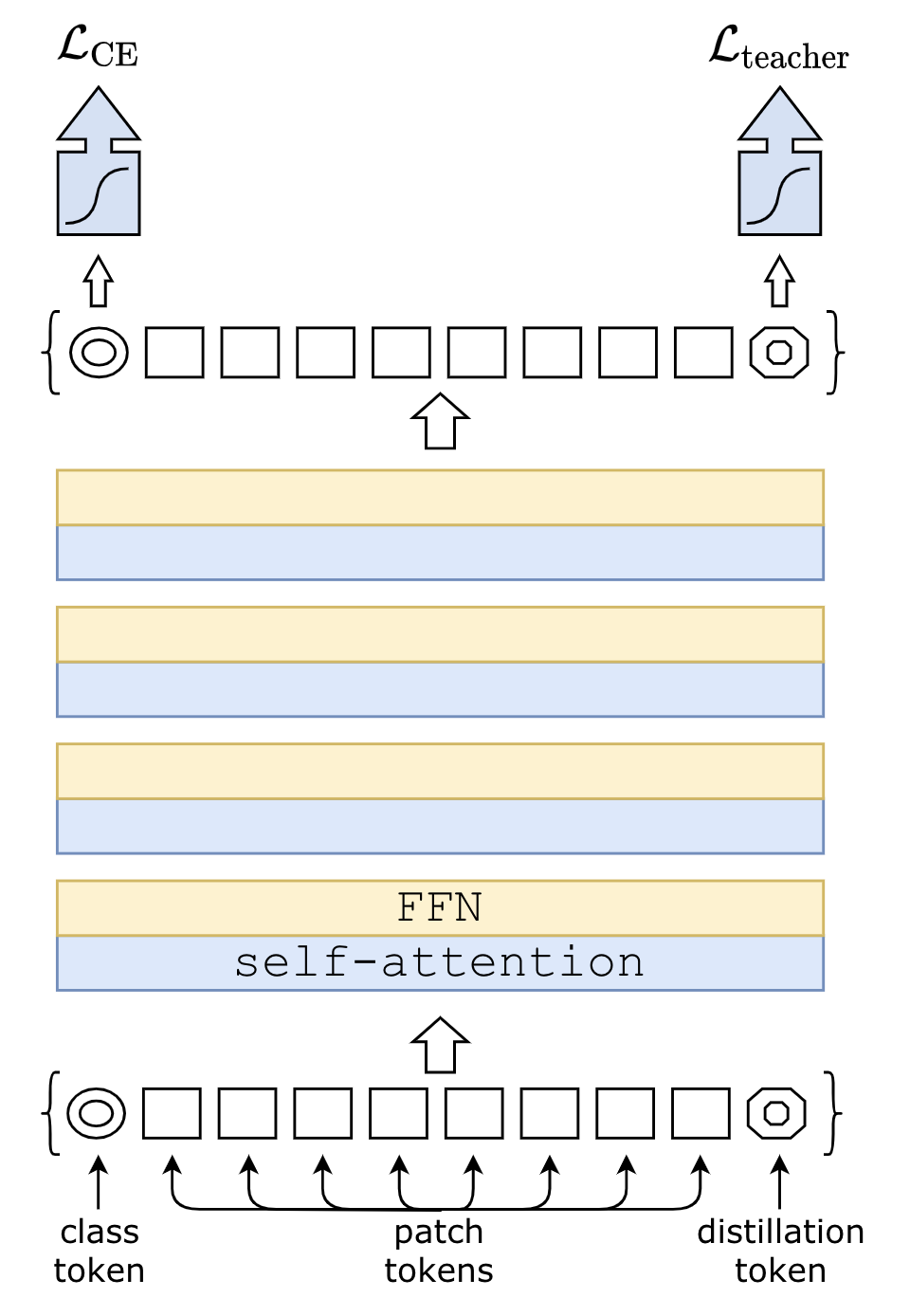
在ViT的基礎(chǔ)上增加了一個(gè)distillation token,巧妙的利用distillation token提升模型精度。
T2T-ViT [paper] [code]
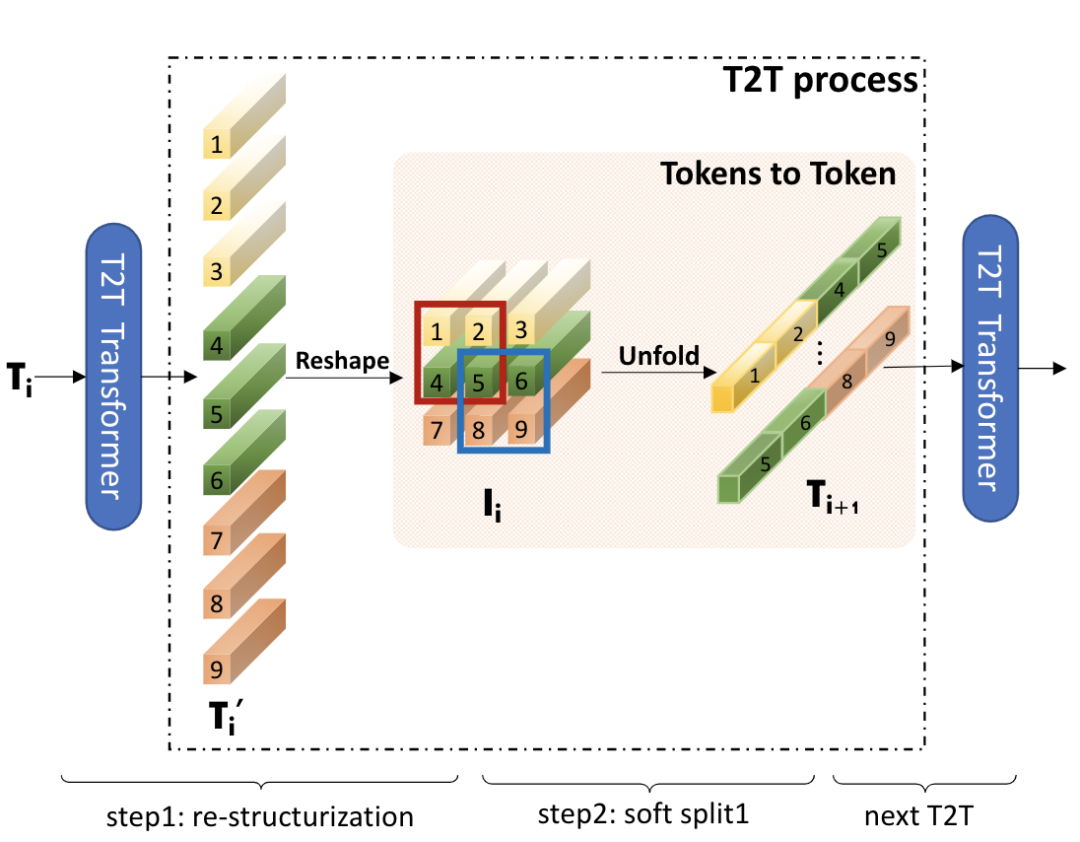
將ViT的patch stem改成重疊的滑窗形式,增強(qiáng)patch之間的信息交流。
Conformer [paper] [code]
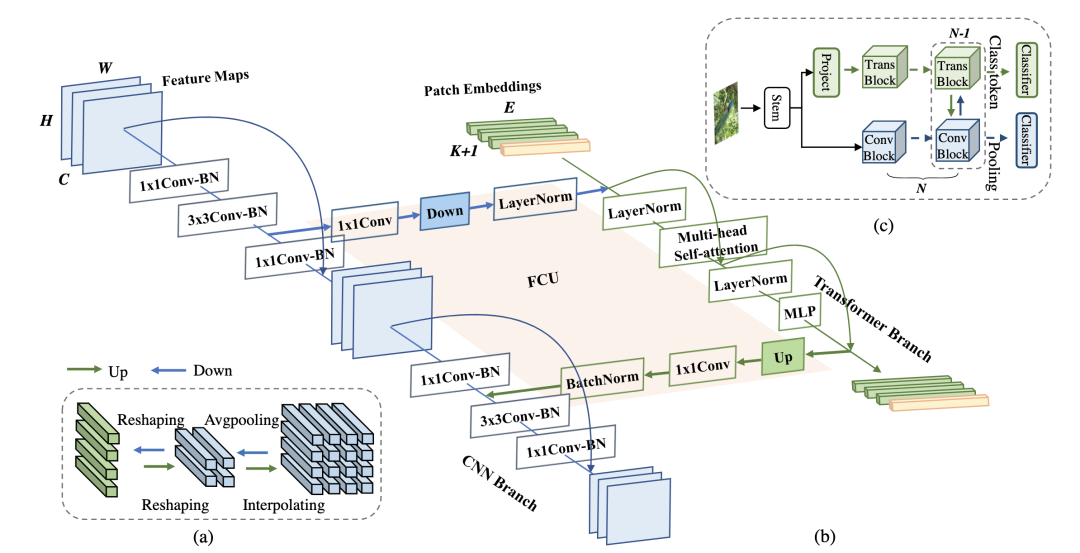
設(shè)計(jì)了一個(gè)CNN和Transformer雙分支結(jié)構(gòu),利用FCU模塊進(jìn)行兩個(gè)分支的信息交流,推理的時(shí)候使用兩個(gè)分支的輸出取平均進(jìn)行預(yù)測(cè)。
TNT [paper] [code]
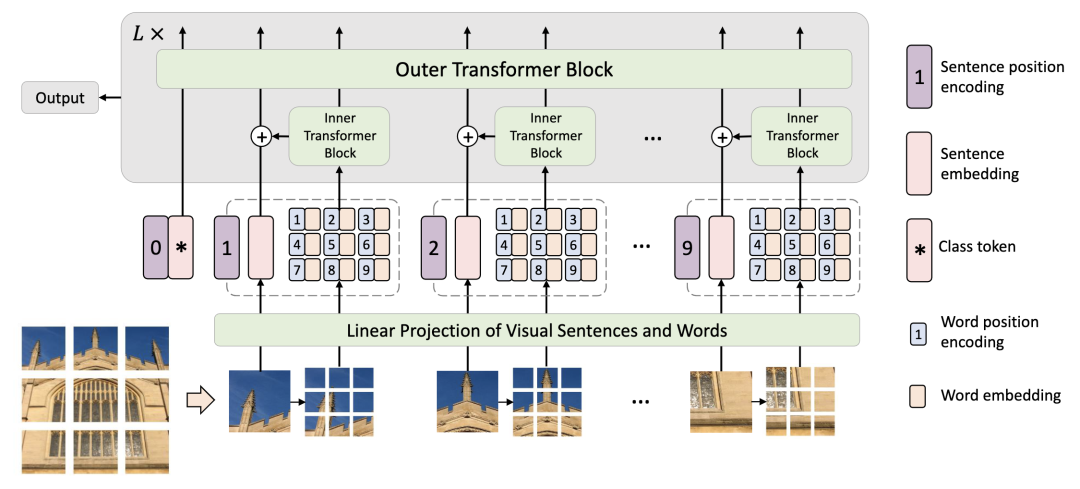
在ViT的基礎(chǔ)上,對(duì)每個(gè)patch進(jìn)一步切分,用嵌套的方式提升每個(gè)patch對(duì)于局部區(qū)域的特征表達(dá)能力,然后將局部提升后的特征和patch特征相加送入下一個(gè)transformer block中。
XCiT [paper] [code]
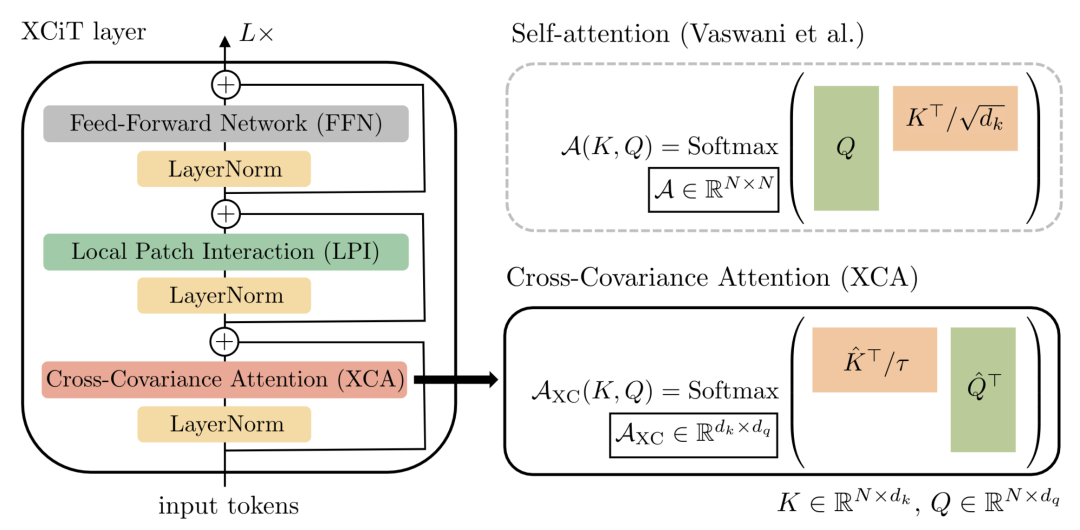
XCiT通過(guò)置換q和k的計(jì)算,從tokens做self-attention轉(zhuǎn)變成channels緯度做self-attention(也就是通道的協(xié)方差計(jì)算),復(fù)雜度從平方降到了線(xiàn)性。
DeepViT [paper]
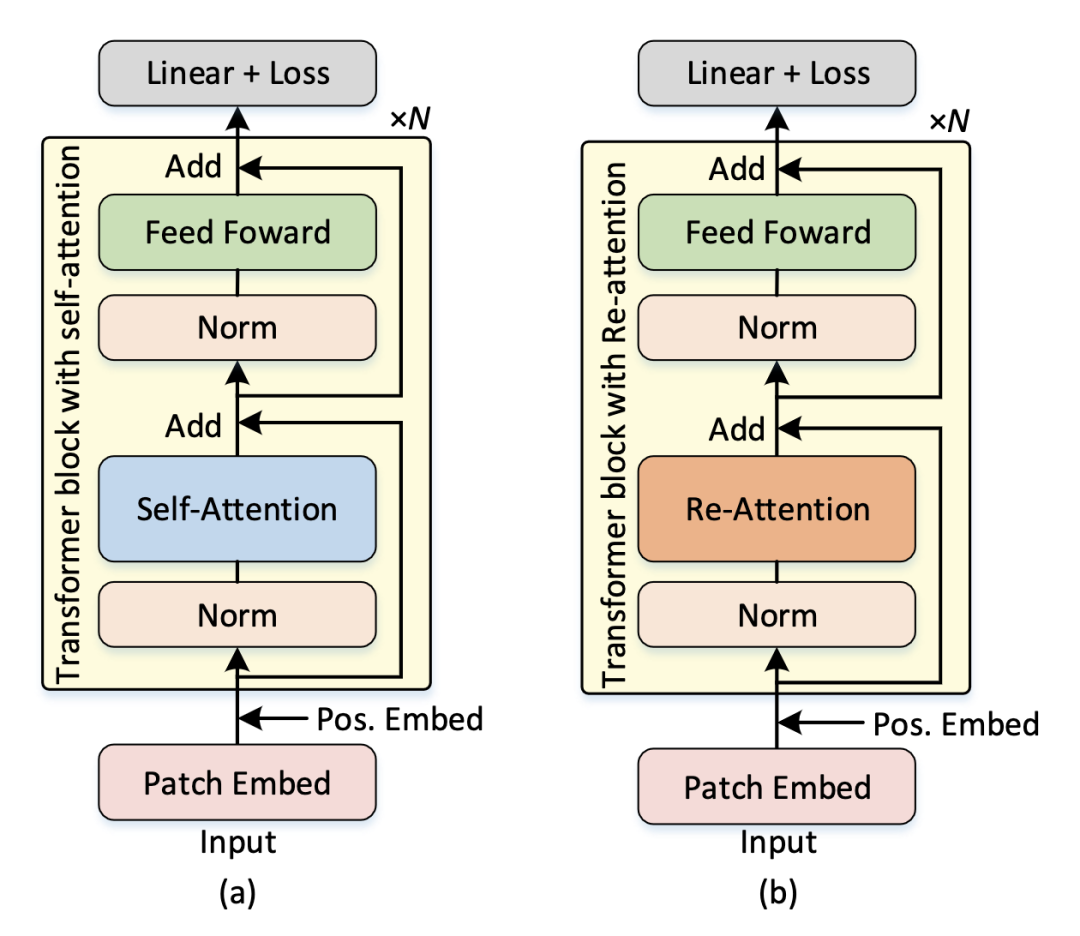
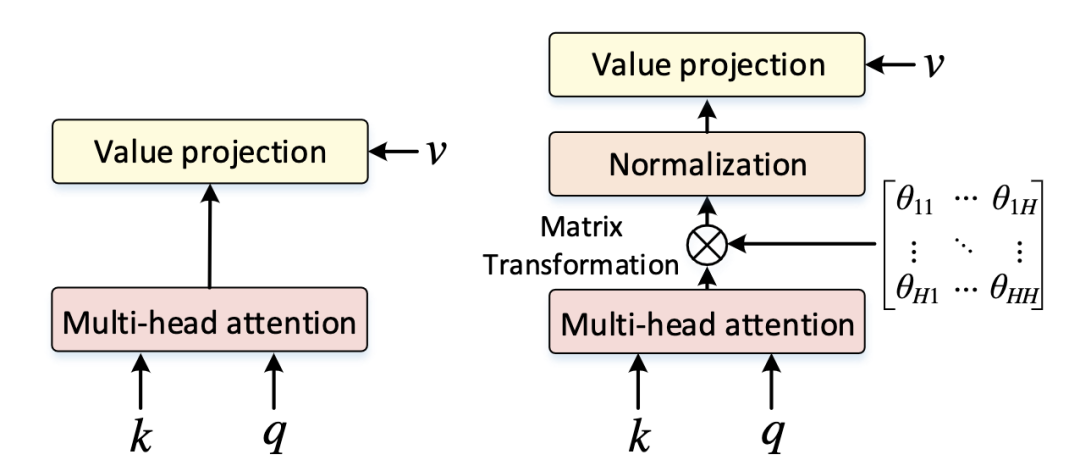
DeepViT發(fā)現(xiàn)隨著深度的增加,ViT的self-attention會(huì)出現(xiàn)坍塌現(xiàn)象,DeepViT提出用Re-Attention來(lái)替代Self-Attention可以避免坍塌,可以訓(xùn)練更深的ViT,Re-Attention在MHSA之后增加了一個(gè)可學(xué)習(xí)的Matrix Transformation。
*Token Labeling ViT [paper] [code]
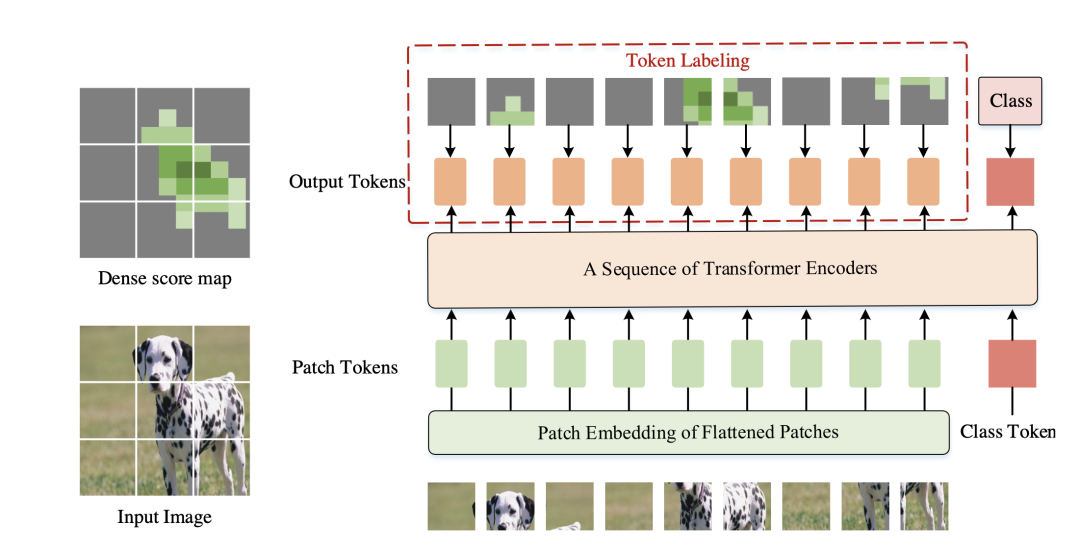
為了增加ViT對(duì)于局部區(qū)域的定位和特征提取能力,token labeling在每個(gè)patch的輸出都增加一個(gè)局部監(jiān)督,token label通過(guò)一個(gè)預(yù)訓(xùn)練過(guò)的特征提取器獲得(本文可以看成是AutoEncoder+CLS的預(yù)訓(xùn)練方法)。由于需要一個(gè)額外的特征提取器,所以需要更多的計(jì)算資源(可以用MaskFeat的方法改進(jìn))。
SoT [paper] [code]
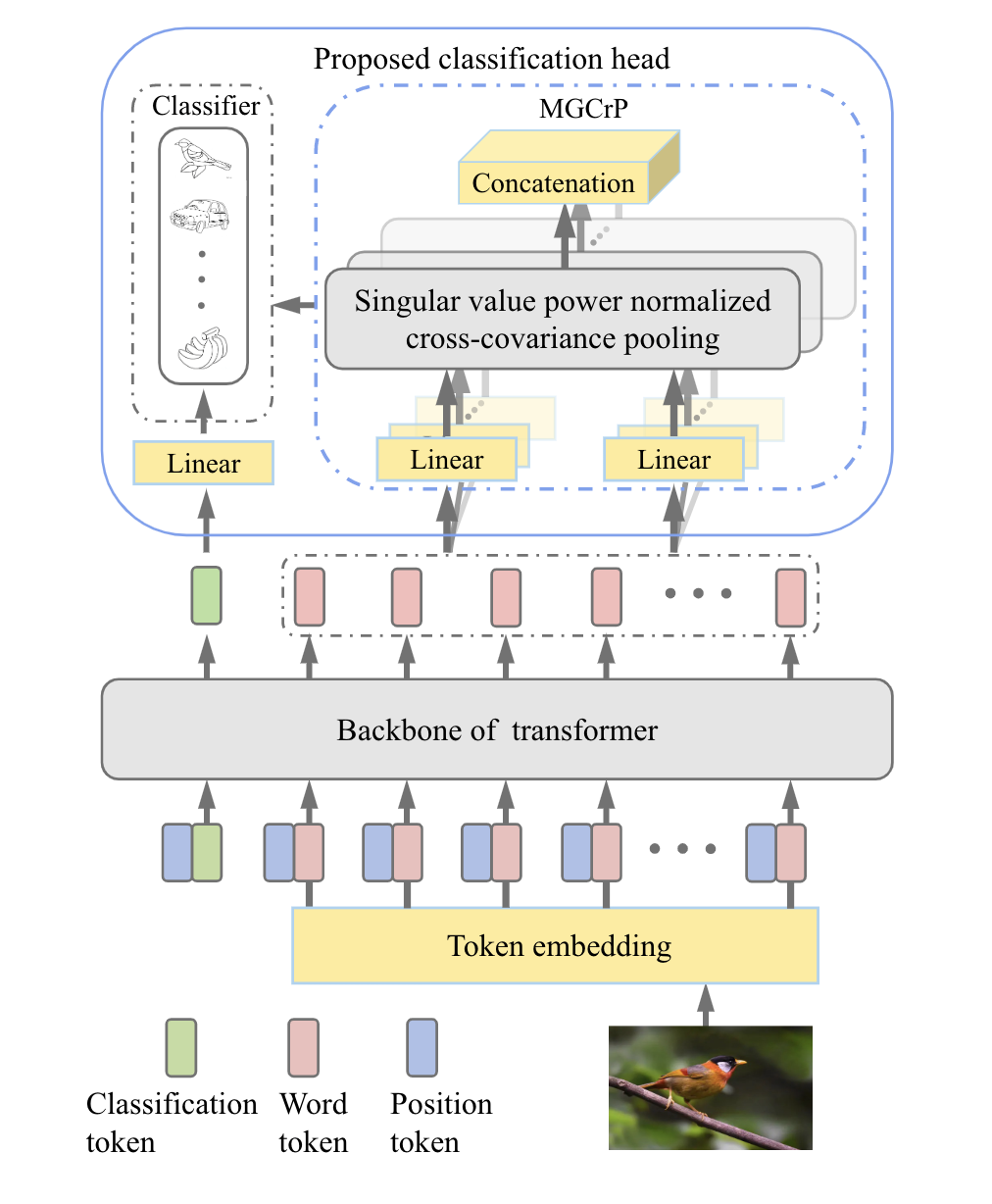
對(duì)patch輸出的word token進(jìn)行協(xié)方差池化,然后和cls token的輸出進(jìn)行融合,提高分類(lèi)對(duì)局部區(qū)域的感知能力。
DVT [paper]
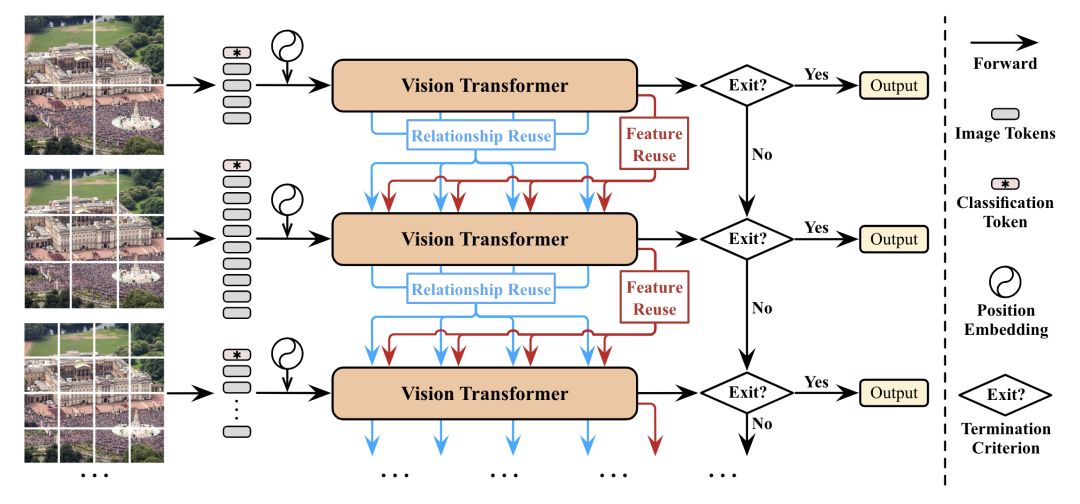
DVT提出每個(gè)圖片應(yīng)該有自己獨(dú)有的token數(shù)量,于是設(shè)計(jì)了一個(gè)級(jí)聯(lián)tokens數(shù)量逐漸增加的多個(gè)transformer,推理的時(shí)候可以從不同級(jí)的transformer判斷輸出。
DynamicViT [paper] [code]
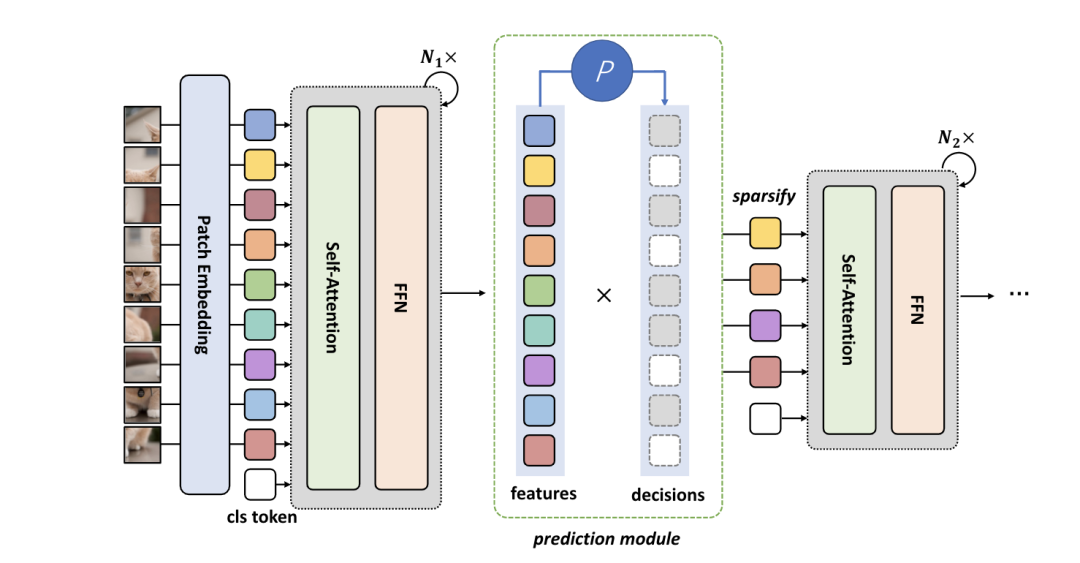
通過(guò)一個(gè)預(yù)測(cè)模塊來(lái)決定token的重要程度,剪枝掉少量不重要的token,將剩余的token送入下一個(gè)block中。
PSViT [paper]
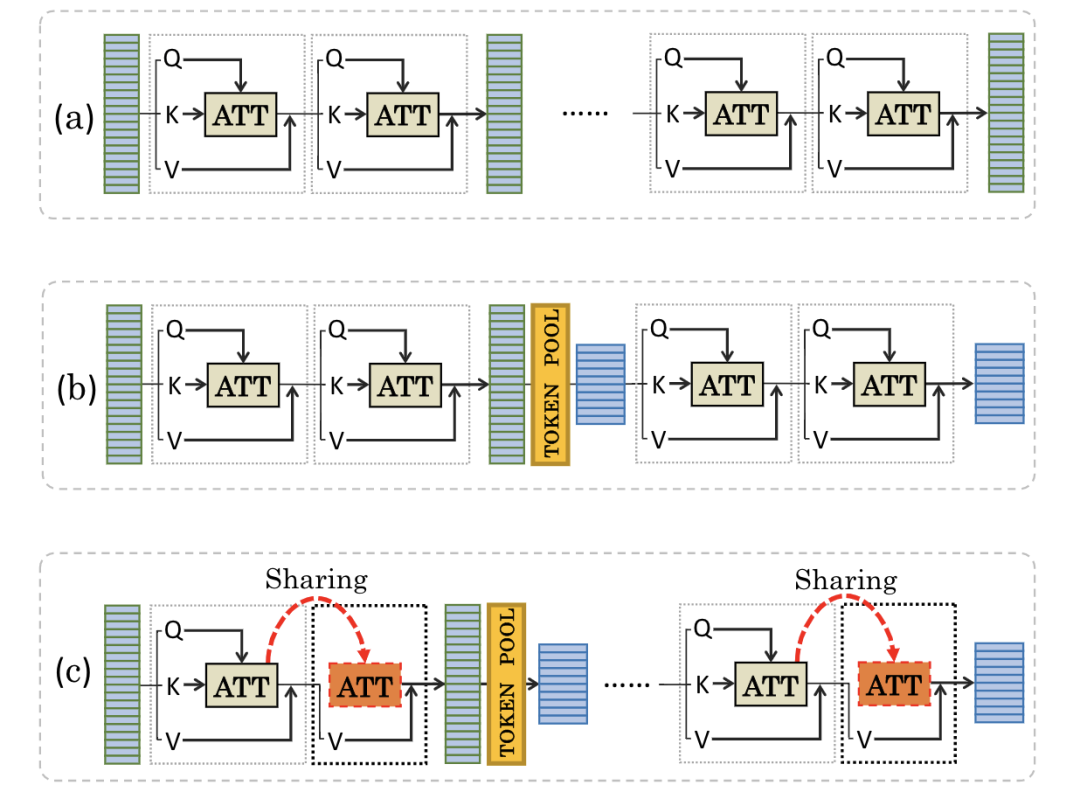
為了減少ViT計(jì)算上的冗余,PSViT提出token pooling和attention sharing兩個(gè)操作,其中token pooling用來(lái)減少token的數(shù)量,attention sharing作用在相關(guān)性較強(qiáng)的相鄰層上。
*TokenLearner [paper] [code]
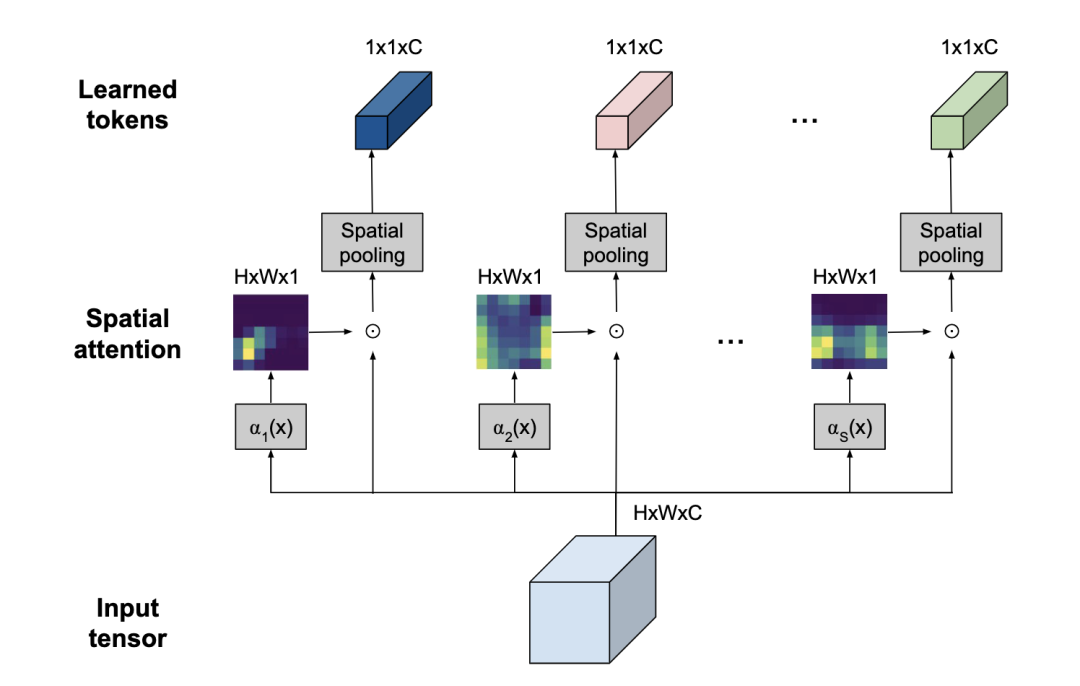
利用spatial attention來(lái)提取出最重要的token信息,減少token數(shù)量。
Evo-ViT [paper]
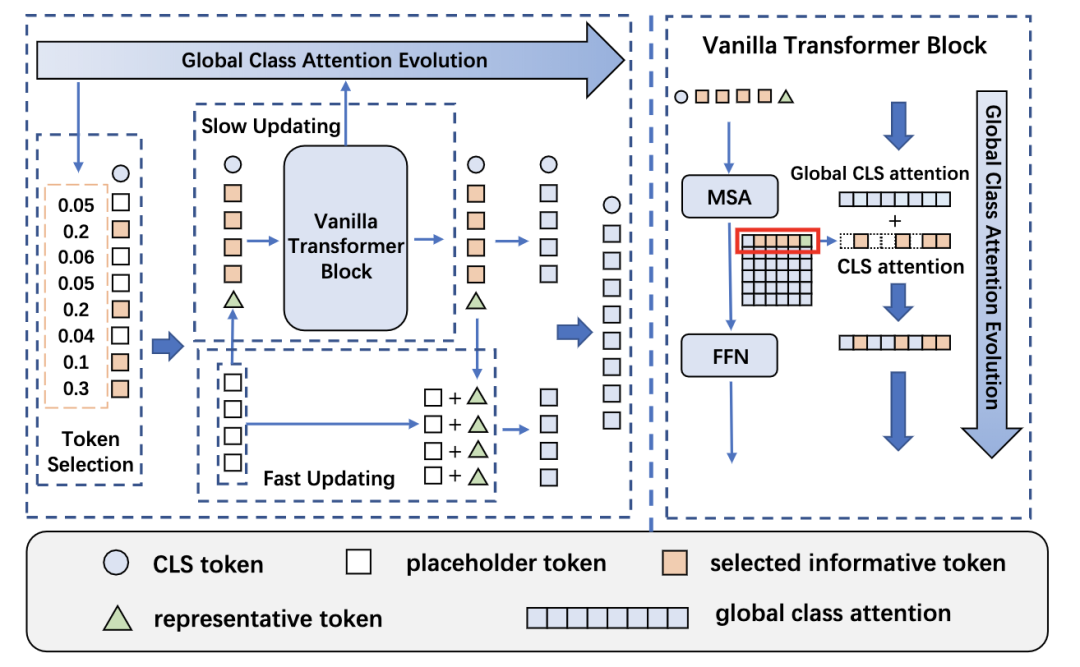
增加一個(gè)representative token,通過(guò)global class attention evolution來(lái)判斷patch token的重要程度,重要程度高的送入block中緩慢更新,重要程度低的和representative token(由placeholder token得到)殘差更新。其中vanilla transformer block的MSA輸出和global cls attention相加得到重要性權(quán)重。
AugViT [paper] [code]
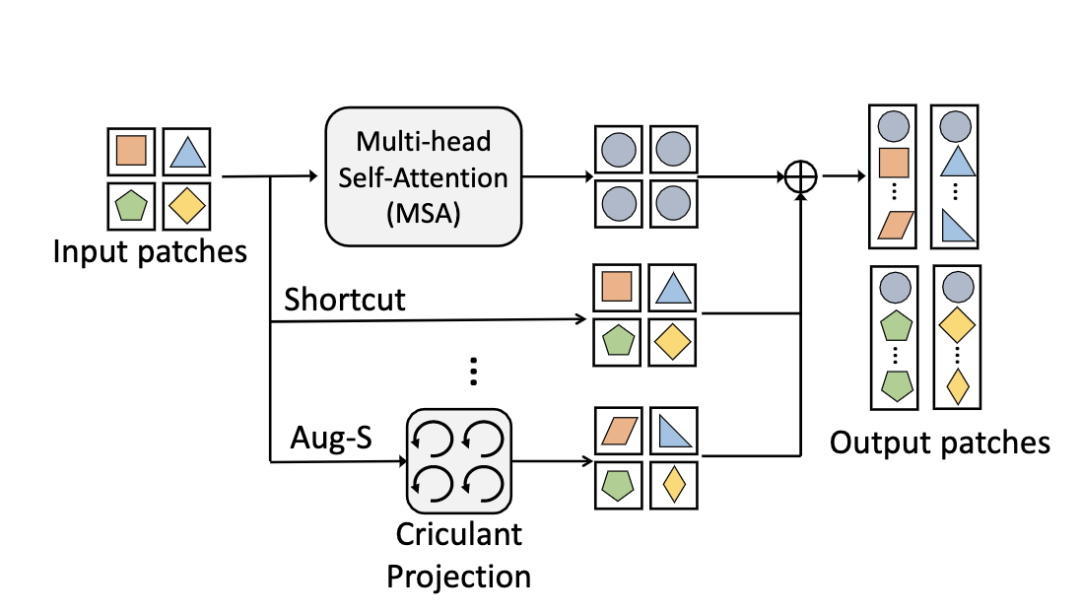
為了避免ViT出現(xiàn)模型坍塌現(xiàn)象,AugViT設(shè)計(jì)了一個(gè)augmented shortcuts結(jié)構(gòu)。具體地,在MSA結(jié)構(gòu)上并行增加兩個(gè)分支,一個(gè)分支做shortcut操作,另一分支對(duì)每個(gè)patch做augmentation來(lái)增加特征表達(dá)的多樣性,最后將三個(gè)分支的輸出相加到一起。
CrossViT [paper] [code]
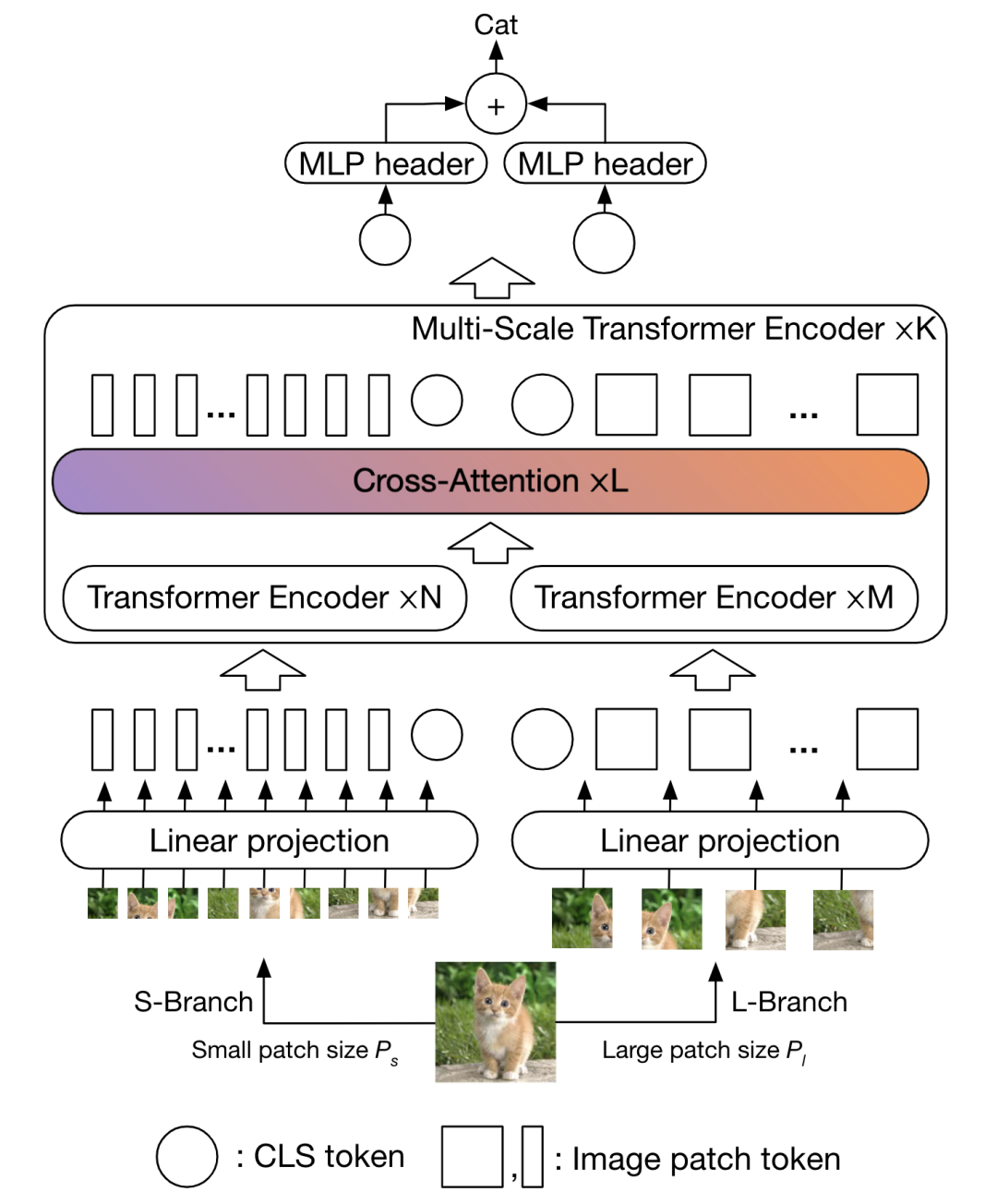
將兩種不同數(shù)量的patch序列分別送入encoder中,然后通過(guò)cross-attention對(duì)兩個(gè)分支的cls token和patch token同時(shí)進(jìn)行融合,最后將兩個(gè)分支的cls token位置的輸出結(jié)果進(jìn)行融合。
AutoFormer [paper] [code]
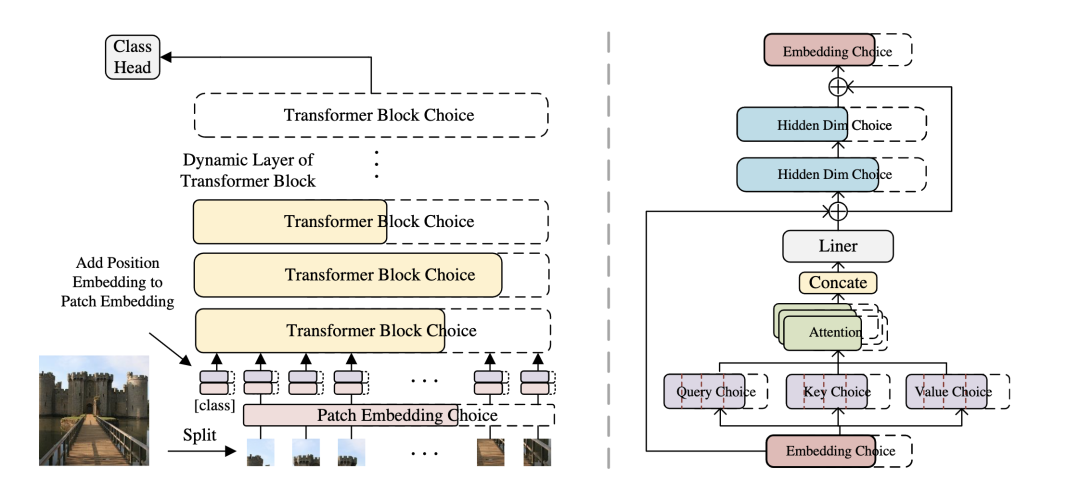
AutoFormer動(dòng)態(tài)的搜索transformer中每一層的embedding緯度、head的數(shù)量、MLP比例和QKV緯度。
*CPVT [paper] [code] ?
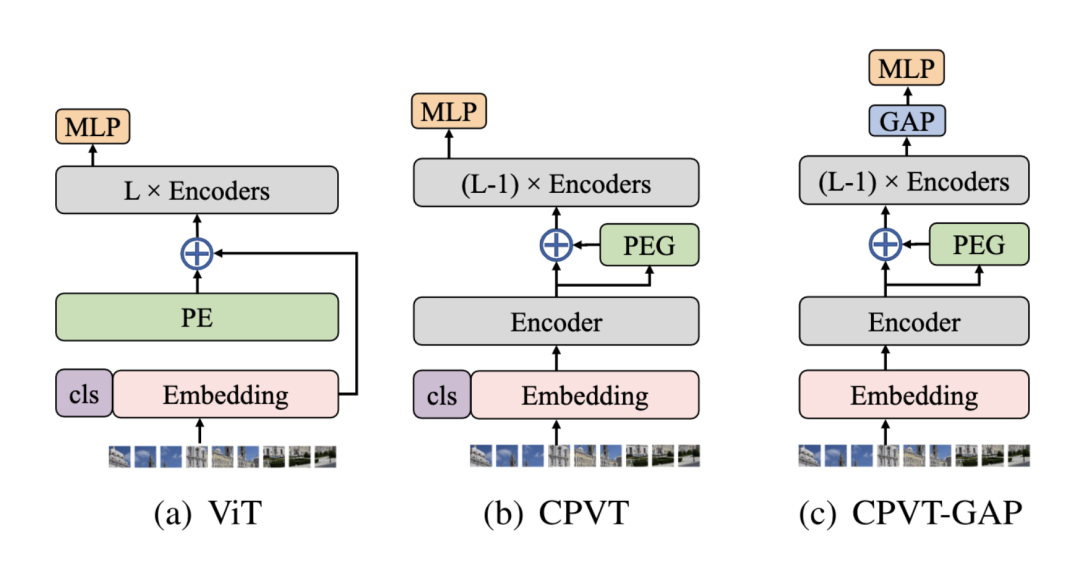
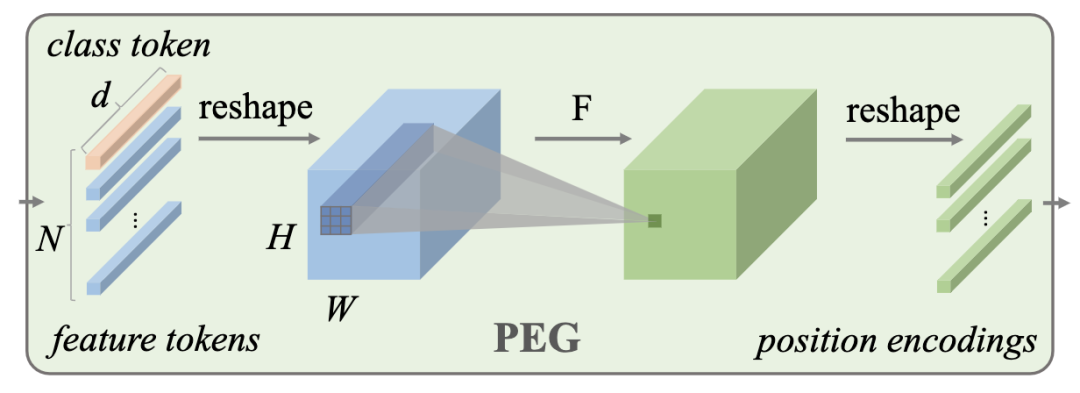
CPVT設(shè)計(jì)了一個(gè)PEG結(jié)構(gòu)來(lái)替代PE(positional encoding),PEG通過(guò)feature token生成得到。
V-MoE [paper]
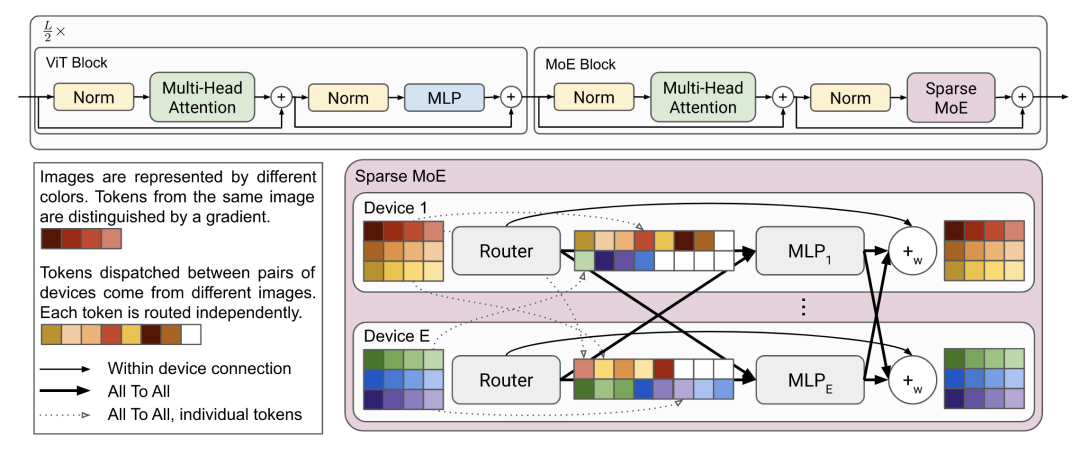
V-MoE用Sparse MoE來(lái)替換ViT中的MLP結(jié)構(gòu)。Sparse MoE中的每個(gè)MLP分別保存在獨(dú)立的device上,并且處理相同固定數(shù)量的tokens。
DPT [paper] [code]
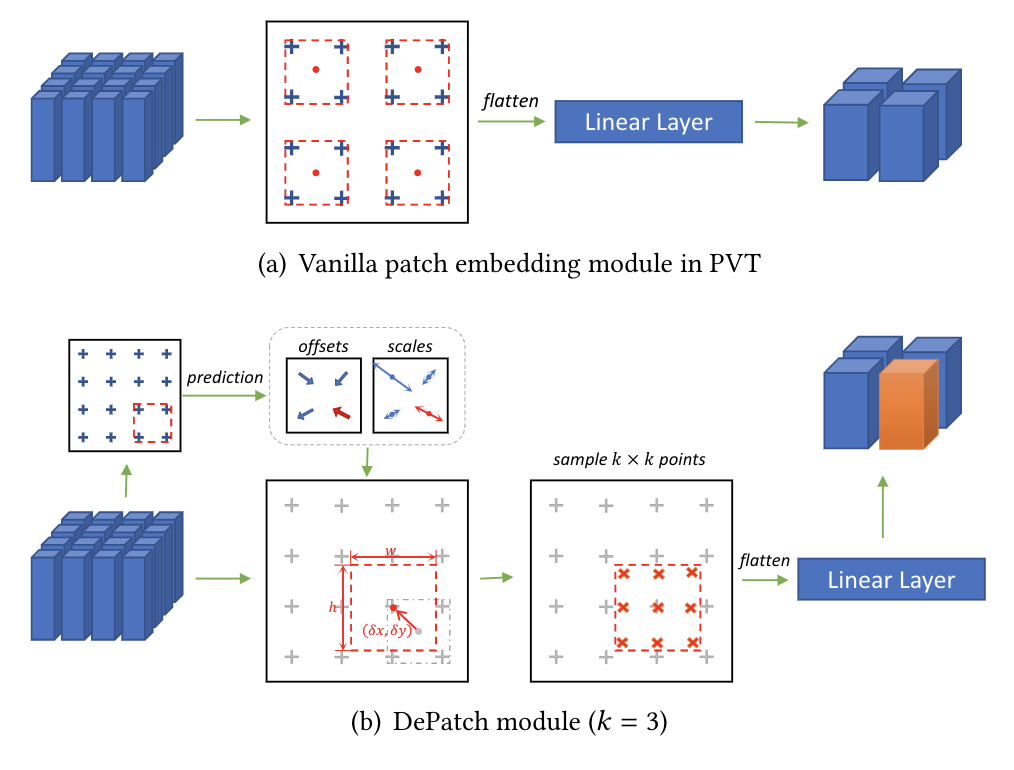
DPT設(shè)計(jì)另一個(gè)可形變的patch選取方式。
*EViT [paper]
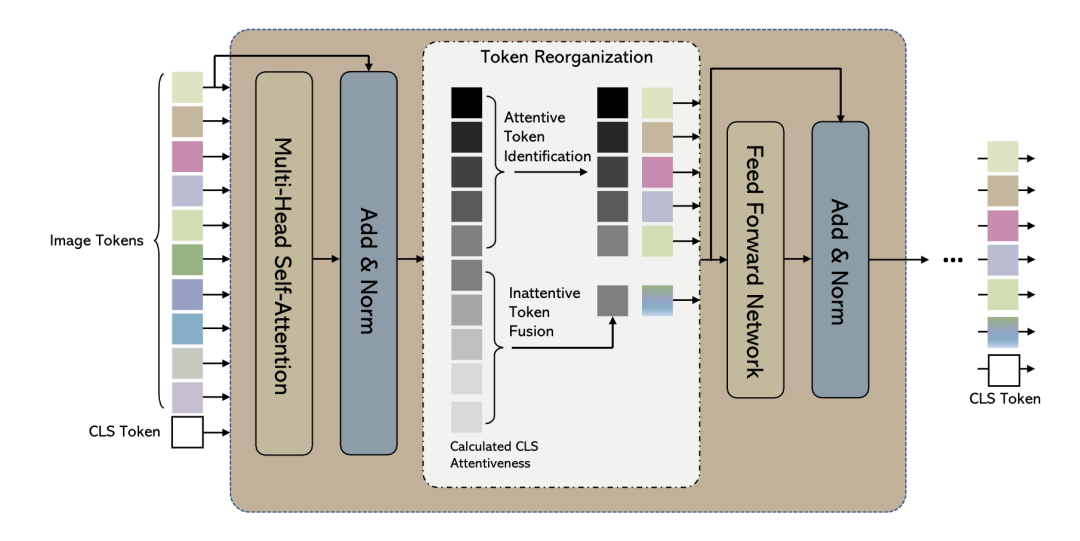
EViT通過(guò)計(jì)算每個(gè)patch token和cls token的相關(guān)性來(lái)決定重要程度,重要程度高的直接送入FFN,重要程度低的融合成一個(gè)token。
Multi-scale
*SwinTv1 [paper] [code] ?
*SwinTv2 [paper]
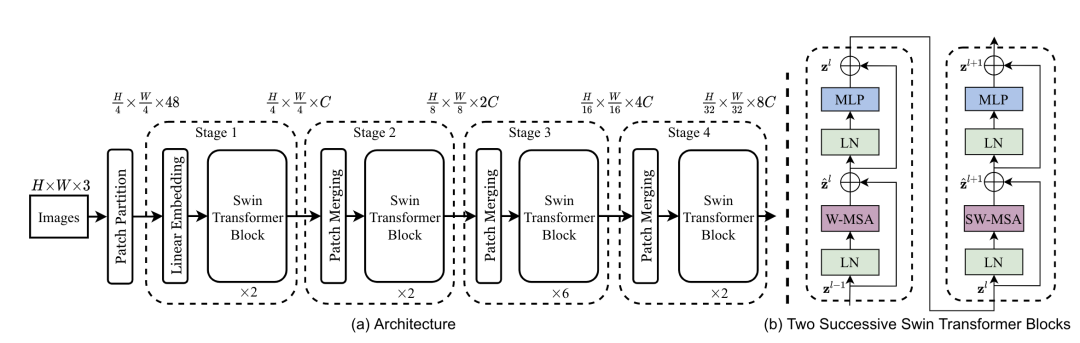
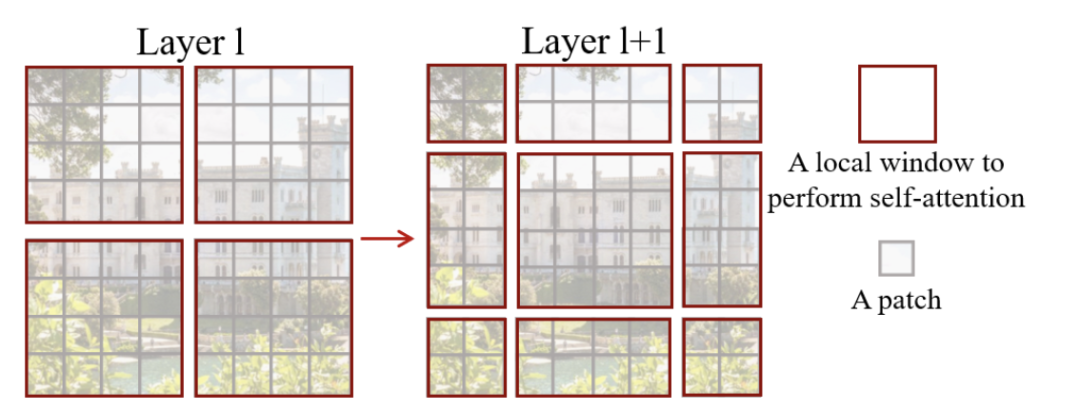
為了更好的應(yīng)用于det、seg等下游任務(wù),需要對(duì)ViT進(jìn)行多尺度設(shè)計(jì)。SwinT通過(guò)patch merging減少token的數(shù)量,另外設(shè)計(jì)了W-MSA結(jié)構(gòu),只對(duì)windows內(nèi)的patch進(jìn)行self-attention計(jì)算來(lái)降低計(jì)算量,為了增加不同windows之間的信息傳遞,設(shè)計(jì)了SW-MSA結(jié)構(gòu)。
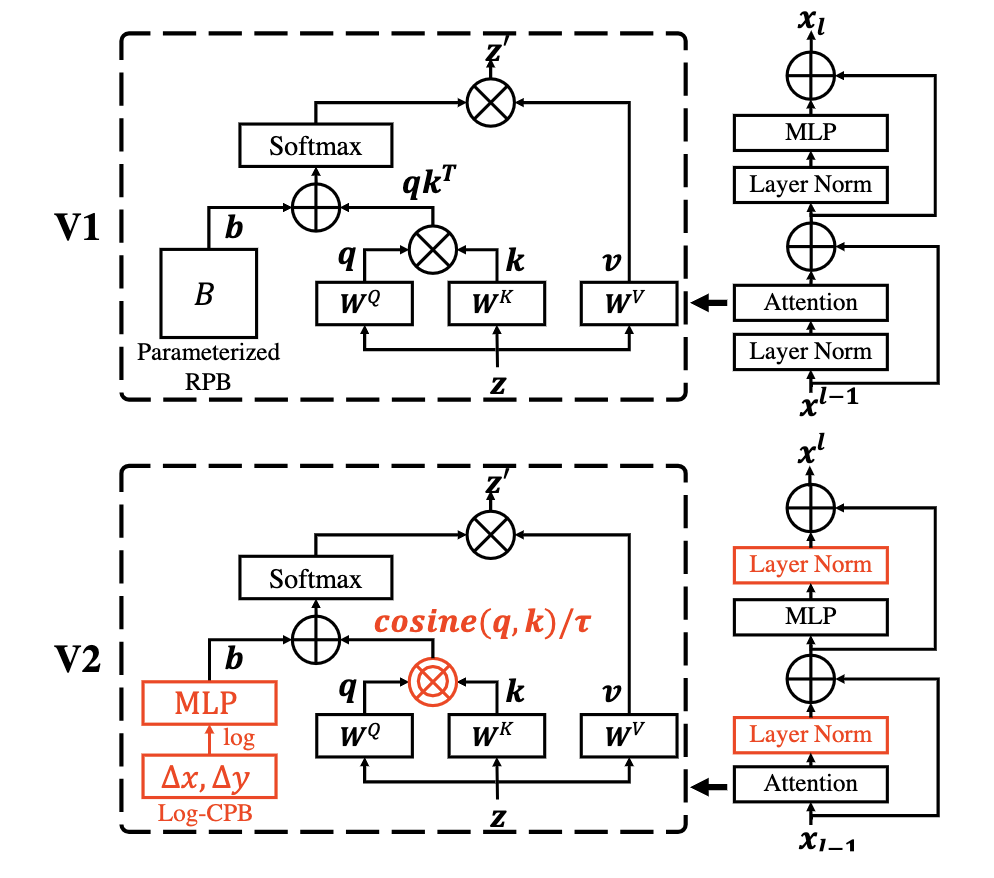
為了更好的擴(kuò)大SwinT的模型容量和window的分辨率,SwinTv2重新設(shè)計(jì)了block結(jié)構(gòu)。
用post-norm替代pre-norm
用cosine attention替代dot product attention
用log-spaced continuous relative position替代parameterized relative position
1和2使得SwinT更容易擴(kuò)大模型容量,3使得SwinT更容易跨window分辨率遷移。
*PVTv1 [paper] [code]
*PVTv2 [paper]
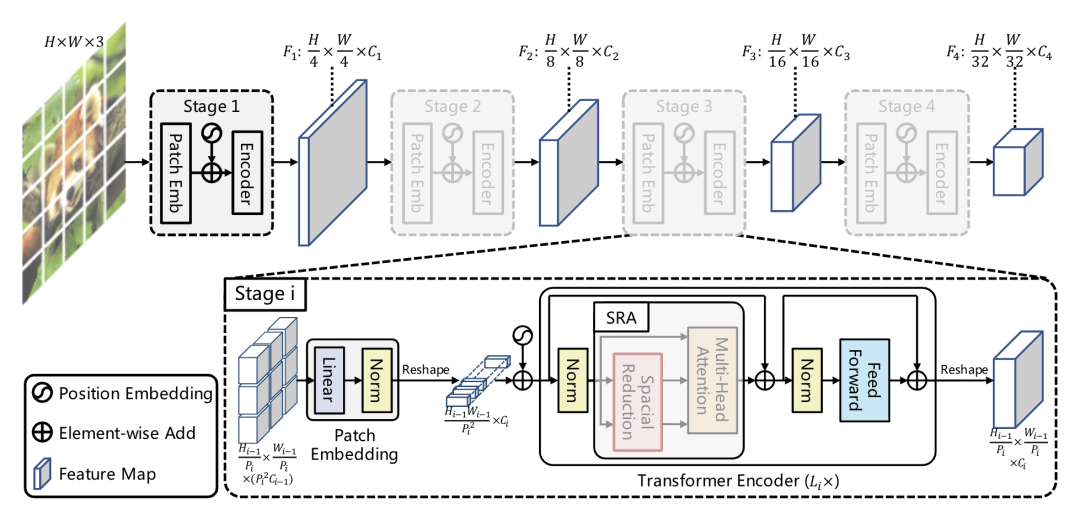
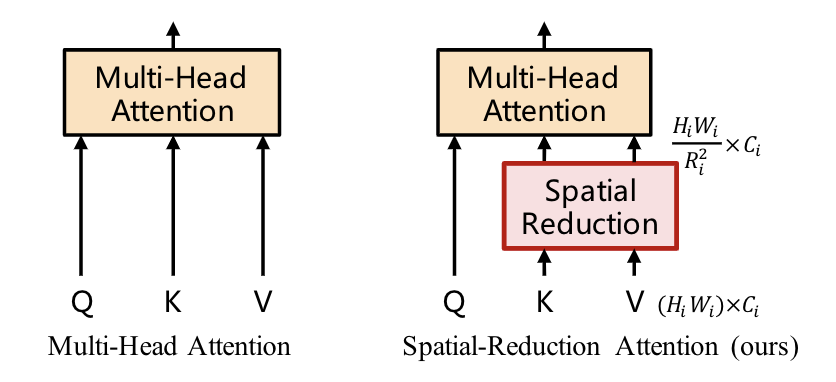
PVT設(shè)計(jì)了一個(gè)多stage的多尺度架構(gòu),為了做stage之間的下采樣,將MHSA改造成SRA,SRA中的K和V都下采樣R^2倍。
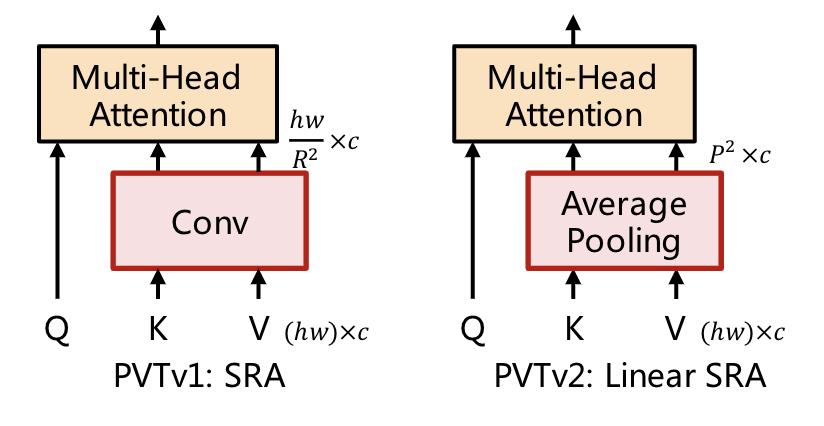
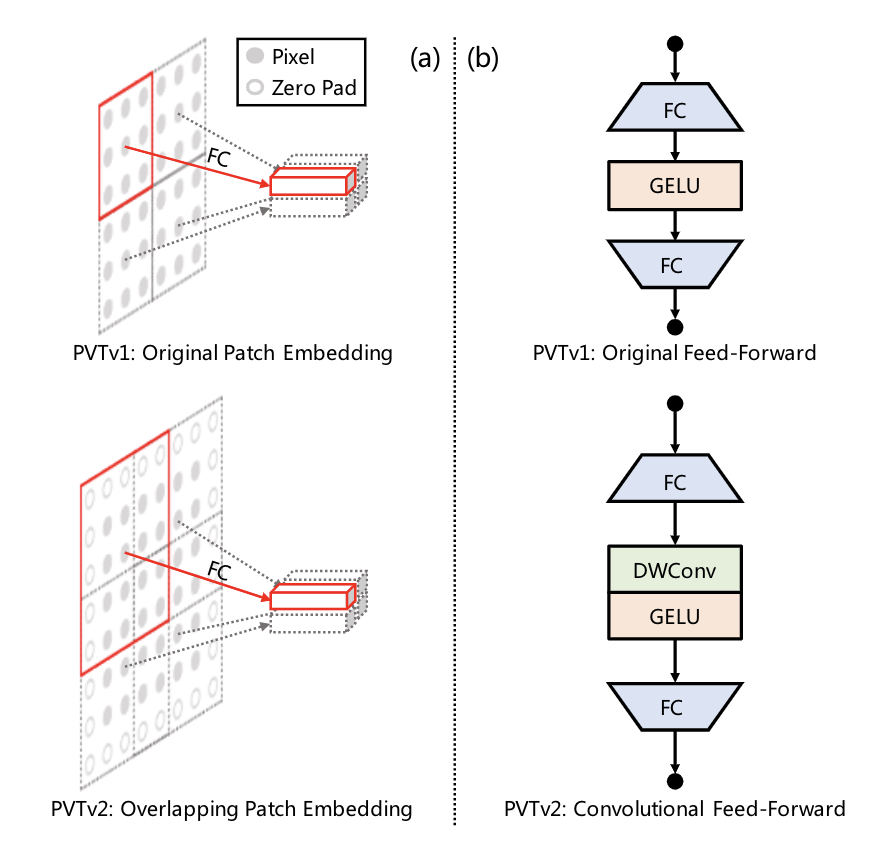
PVTv2在PVTv1的基礎(chǔ)上做了三點(diǎn)改進(jìn):
將SRA的下采樣conv替換成average pooling
將不重疊的patch embedding替換成重疊的patch embedding
移除position encoding,并且在FFN中增加一個(gè)dwconv
1可以將PVT計(jì)算量降到線(xiàn)性,2可以獲得更多局部連續(xù)的特征,3可以處理任意尺寸的圖像。
*Twins [paper] [code]
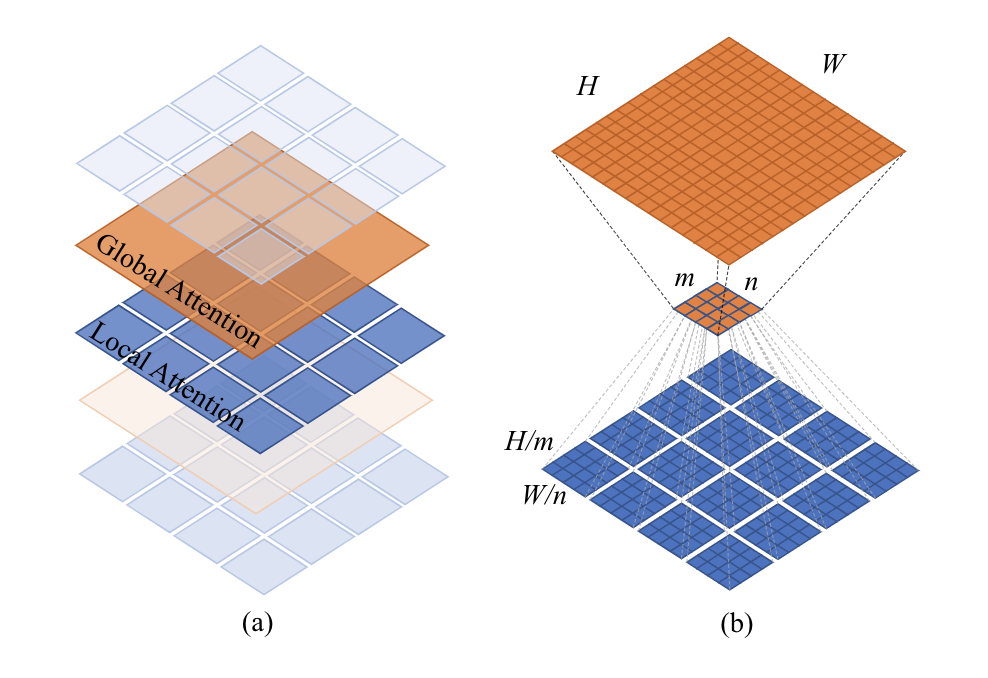
Twins沿用PVT的整體架構(gòu),并且用CPVT中的PEG來(lái)替代PE,同時(shí)將transformer block堆疊設(shè)計(jì)成global attention和local attention交替使用的形式,并且為了減少計(jì)算量,global attention將重要信息總結(jié)成mxn個(gè)表示,同時(shí)每個(gè)表示和其他sub-windows進(jìn)行信息交流。
CoaT [paper] [code]
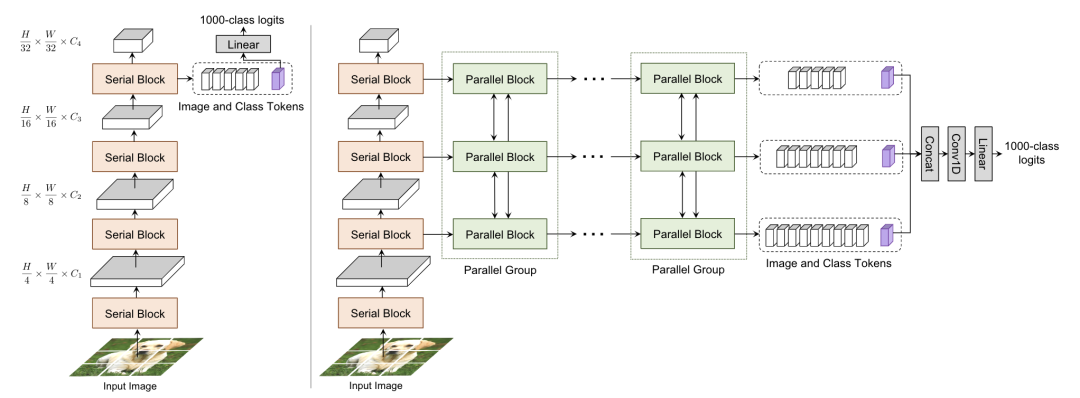
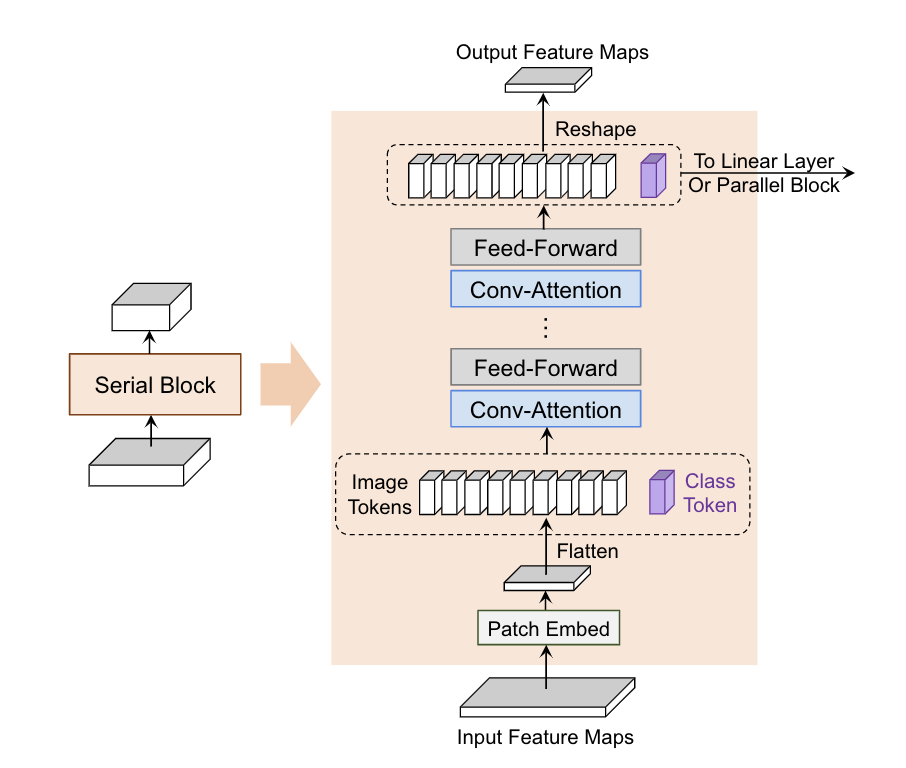
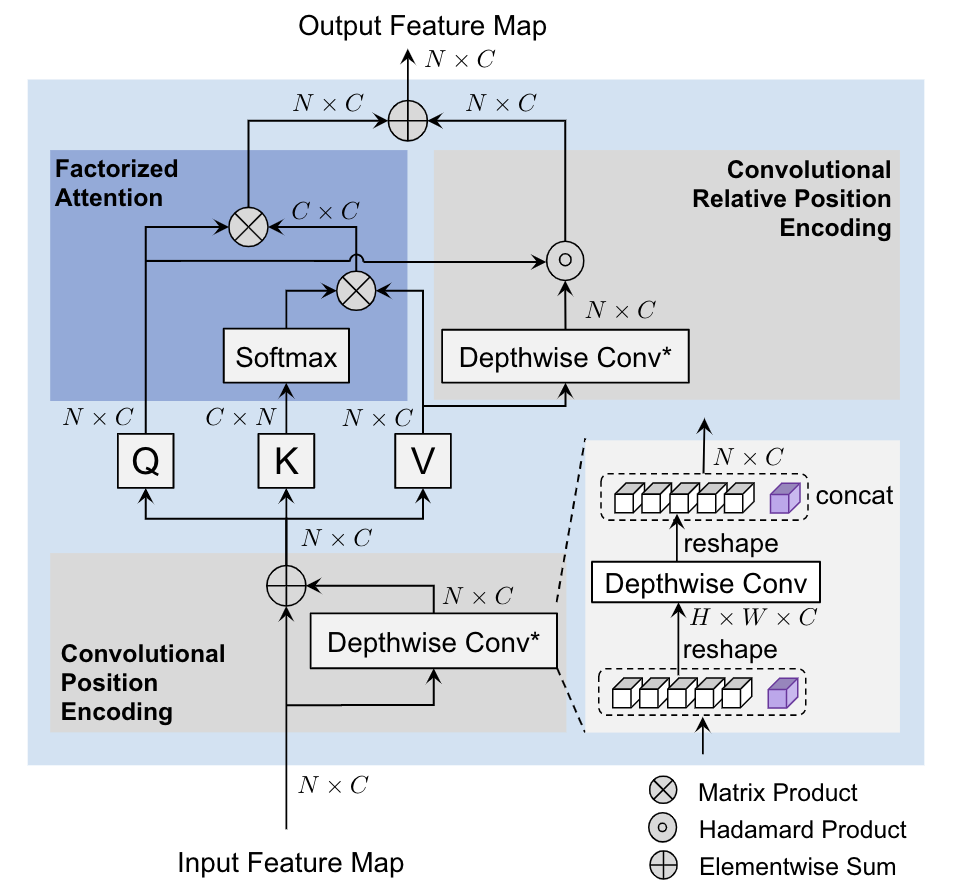
CoaT設(shè)計(jì)了一個(gè)co-scale機(jī)制,通過(guò)一系列串行和并行的block來(lái)預(yù)測(cè)結(jié)果,同時(shí)設(shè)計(jì)了一個(gè)Conv-Attention結(jié)構(gòu)來(lái)替代MHSA,用一個(gè)dwconv來(lái)得到position encoding,另一個(gè)dwconv來(lái)得到relative position encoding。
CvT [paper] [code]
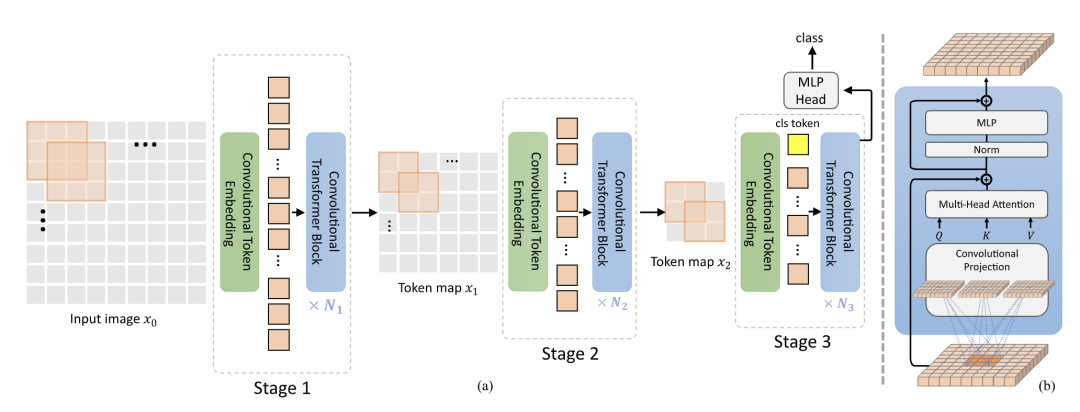
CvT去掉position encoding,用conv同時(shí)替換掉token embedding和MHSA中的QKV projection,通過(guò)conv來(lái)引入位置信息。
Shuffle Transformer [paper] [code]
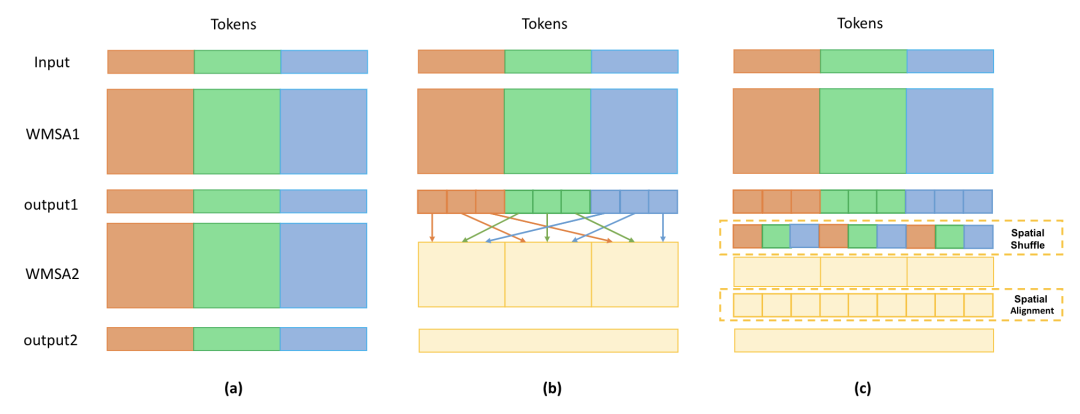
通過(guò)shuffle和unshuffle操作,來(lái)增加token之間的信息交流。
Focal Transformer [paper] [code]
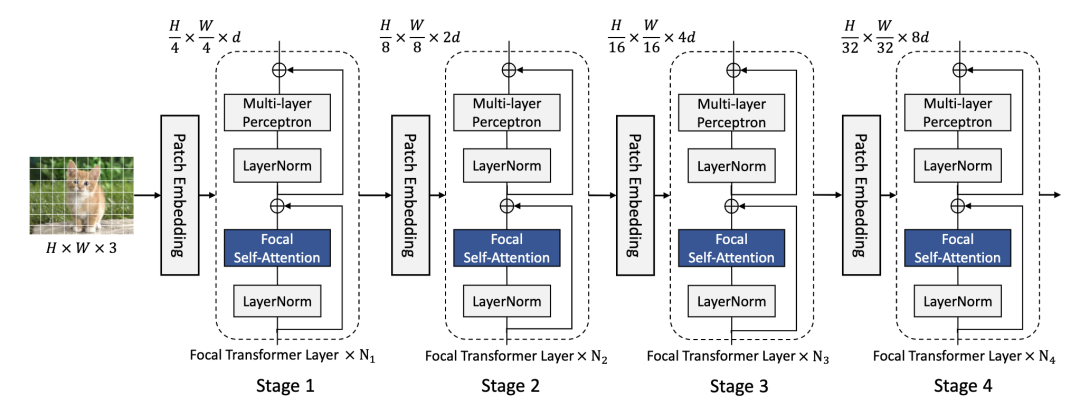

改變SwinT的劃分windows的方式,每個(gè)query patch對(duì)應(yīng)三種粒度的windows尺寸,如圖所示。將W-MSA替換成Focal Self-Attention整體架構(gòu)和SwinT保持一致。
CSWinT [paper] [code]
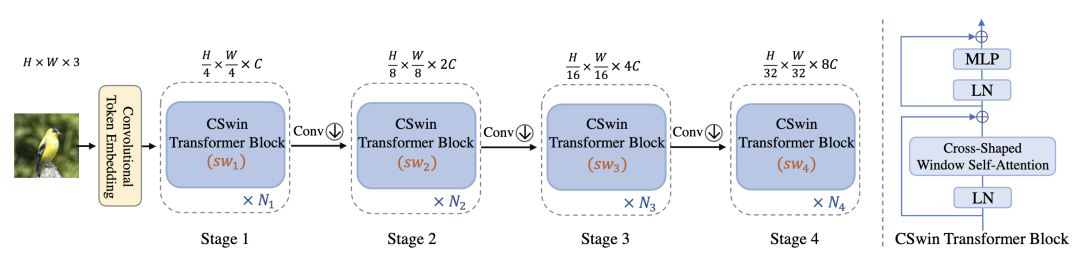
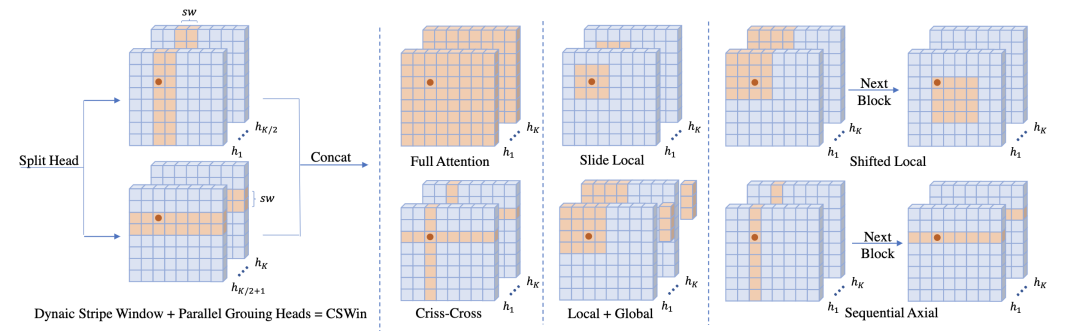
改變SwinT的劃分windows的方式,每個(gè)query patch通過(guò)兩個(gè)并行分支做self-attention,并且kv從dynaic stripe window中取。
*MViT [paper] [code]
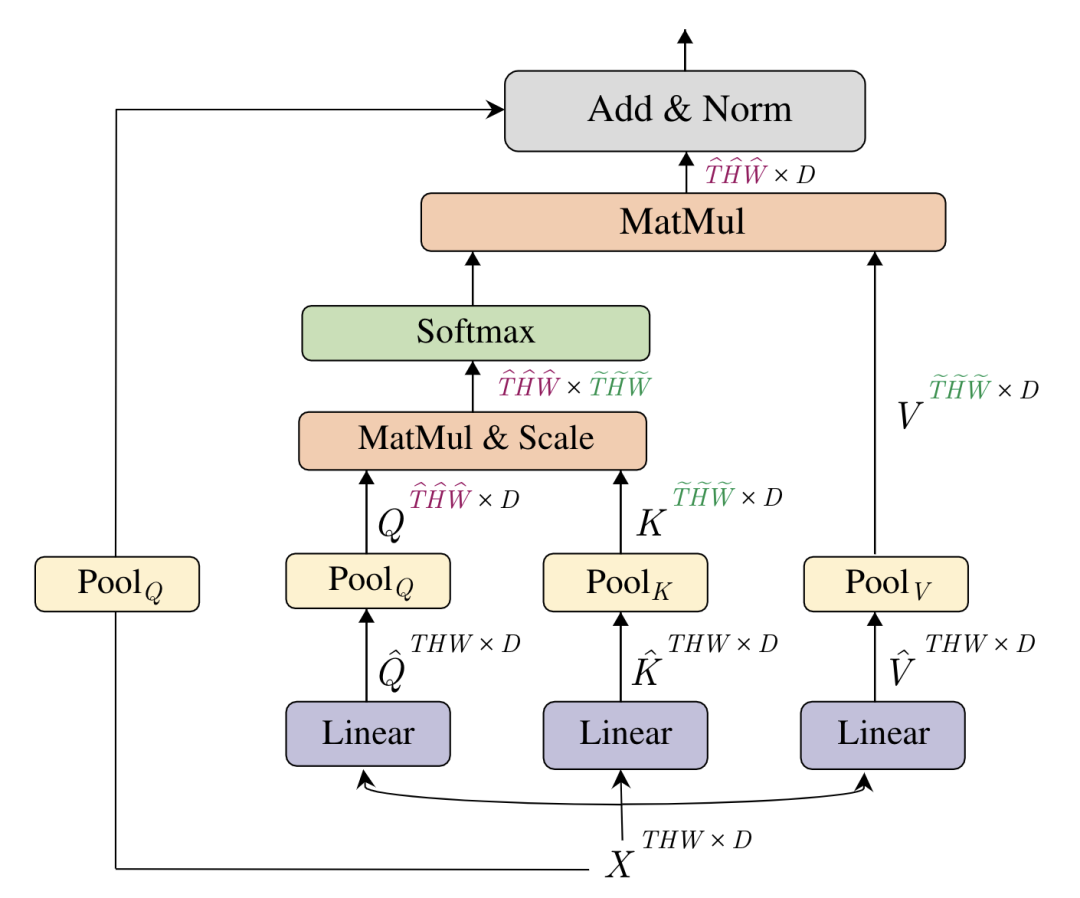
MViT通過(guò)對(duì)XQKV池化進(jìn)行下采樣構(gòu)建金字塔架構(gòu)。
Hybrid ViTs with Convolutions
LeViT [paper] [code]
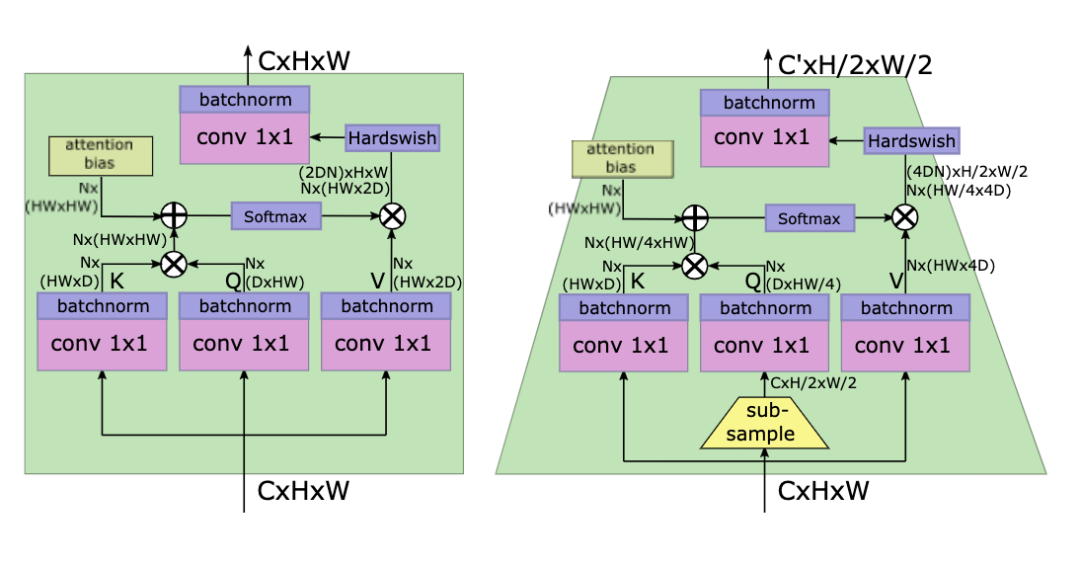
LeViT的patch embedding設(shè)計(jì)成4個(gè)conv3x3堆疊,同時(shí)下采樣的self-attention對(duì)Q進(jìn)行下采樣。
localViT [paper] [code]
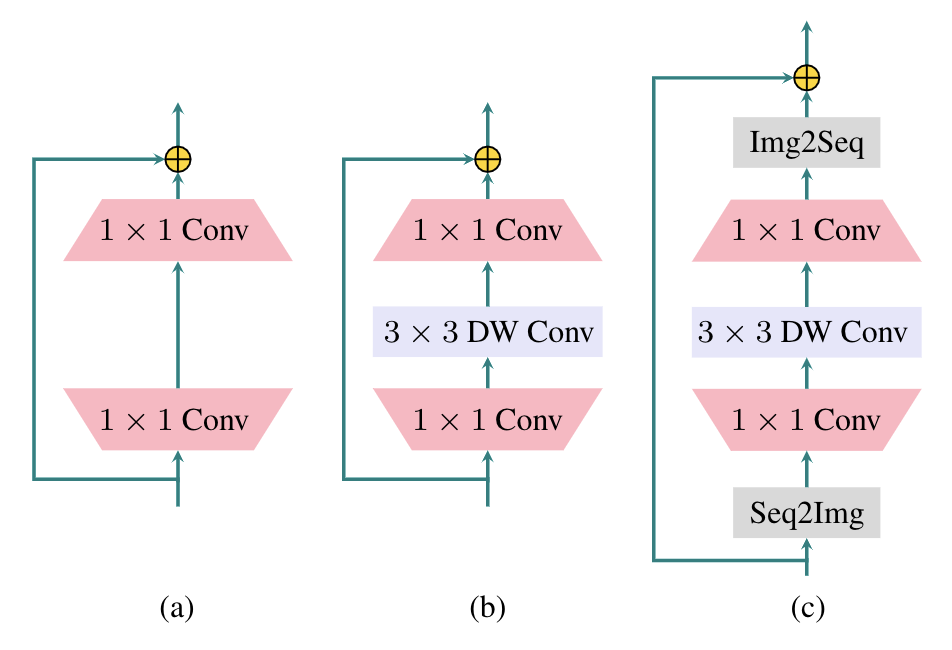
FC和1x1conv等效,在FFN中增加一個(gè)3x3的DWConv就變成了圖c,輸入輸出增加Img2Seq和Seq2Img的操作。
ResT [paper] [code]
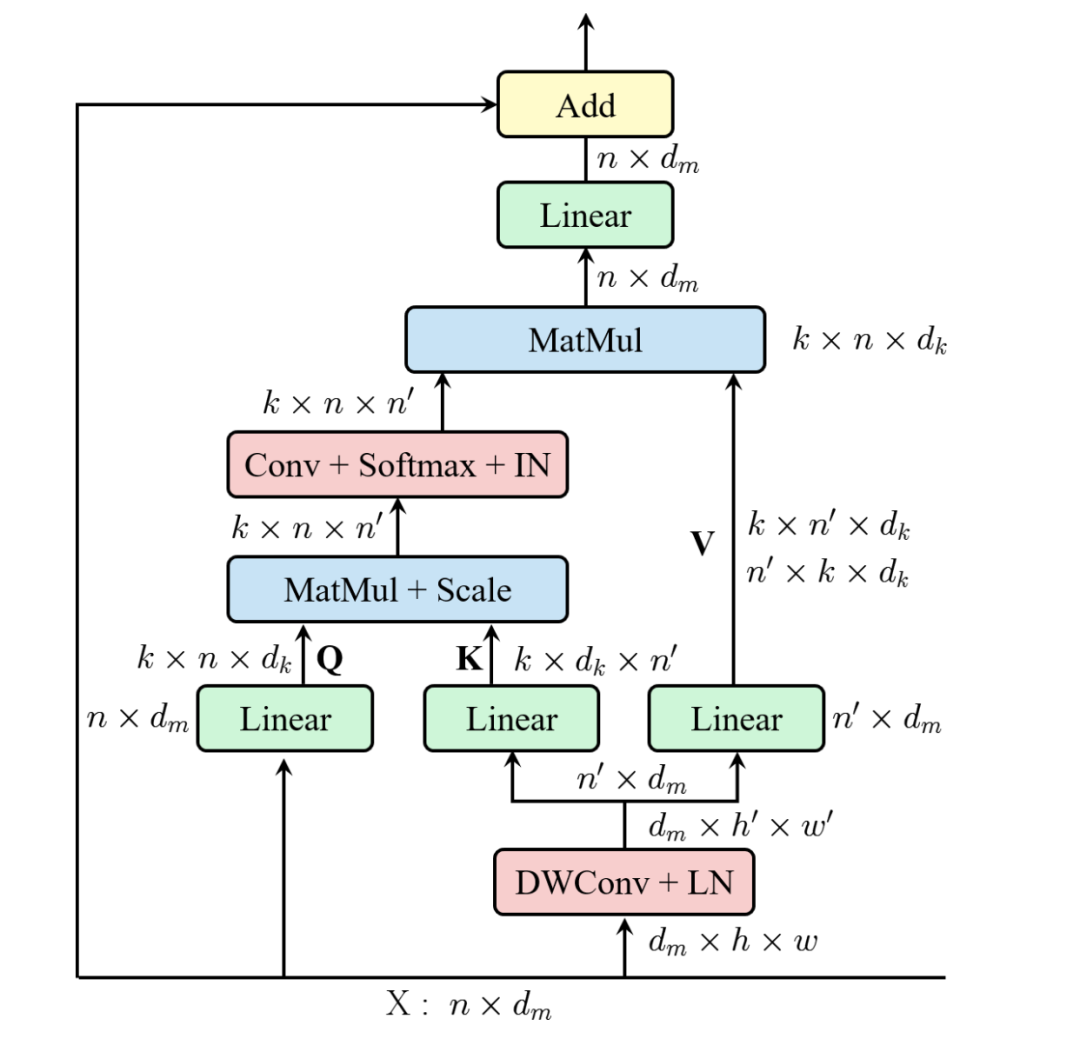
ResT在MHSA中增加DWConv降低KV的緯度,另一個(gè)conv用來(lái)增加不同head的信息交流。
NesT [paper]
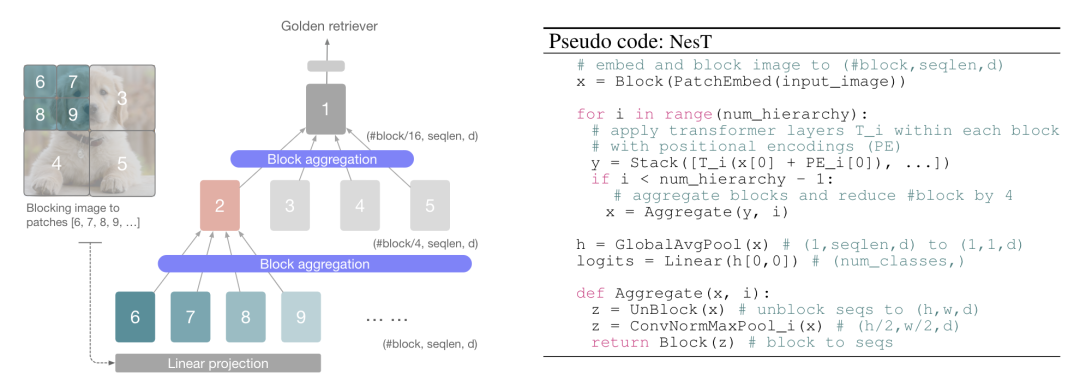
NesT通過(guò)最大池化對(duì)patch進(jìn)行聚合。
CoAtNet [paper]
通過(guò)交替堆疊depthwise conv和self-attention來(lái)設(shè)計(jì)架構(gòu)。
BoTNet [paper]
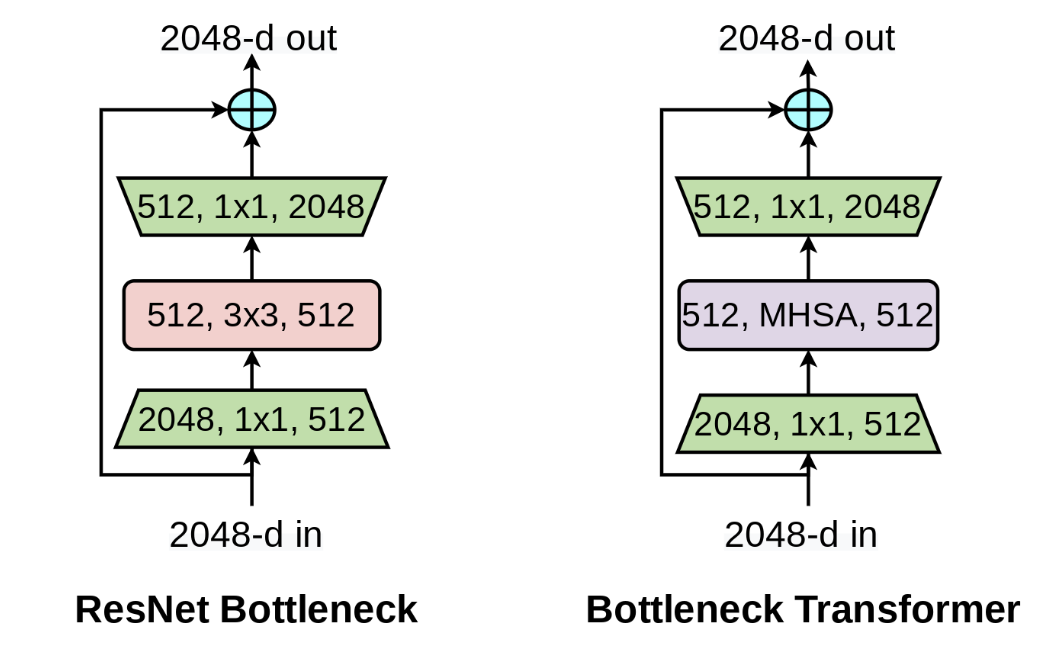
模仿ResNet的bottleneck,將Transformer的block設(shè)計(jì)成bottleneck的形式,一個(gè)bottleneck由1x1conv、MHSA、1x1conv堆疊而成。
ConViT [paper]
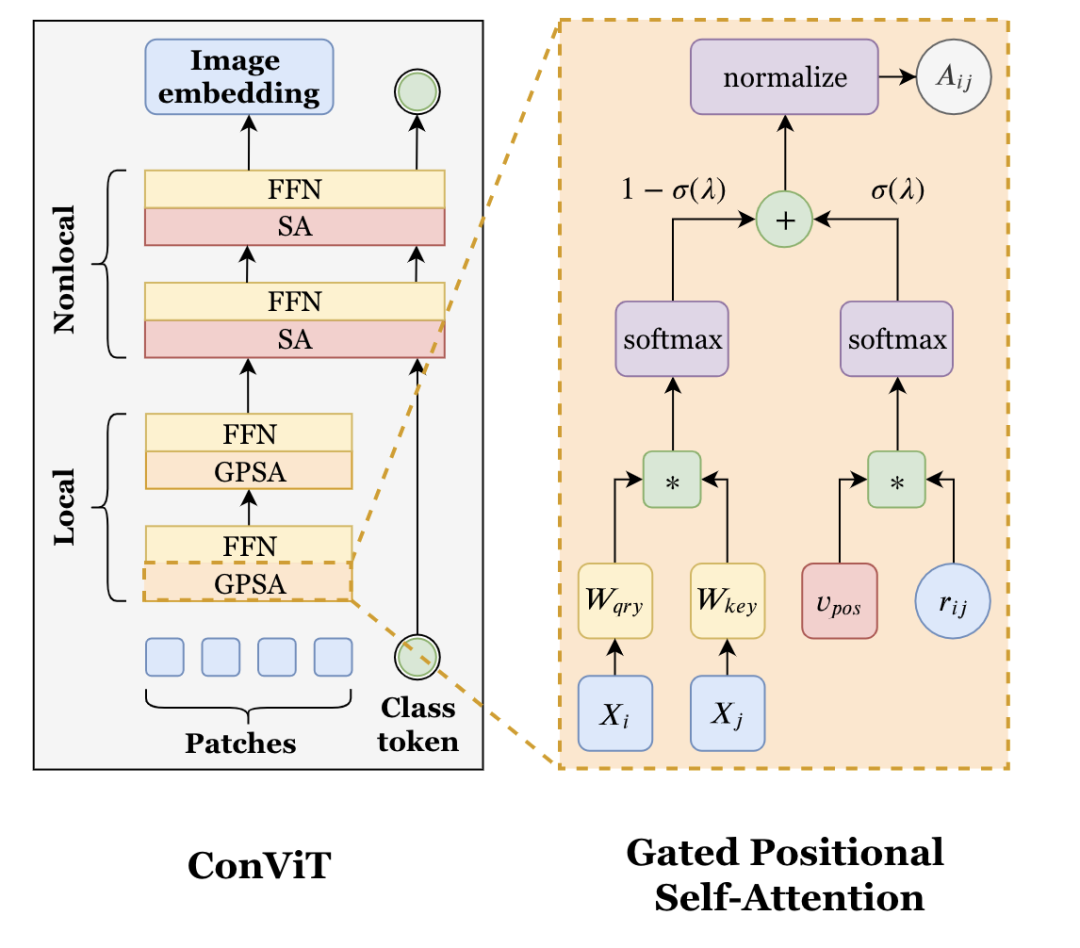
ConViT設(shè)計(jì)了一個(gè)GPSA,只對(duì)patch token進(jìn)行操作,并且引入了位置信息。10個(gè)GPSA堆疊之后接2個(gè)SA。
MobileViT [paper]
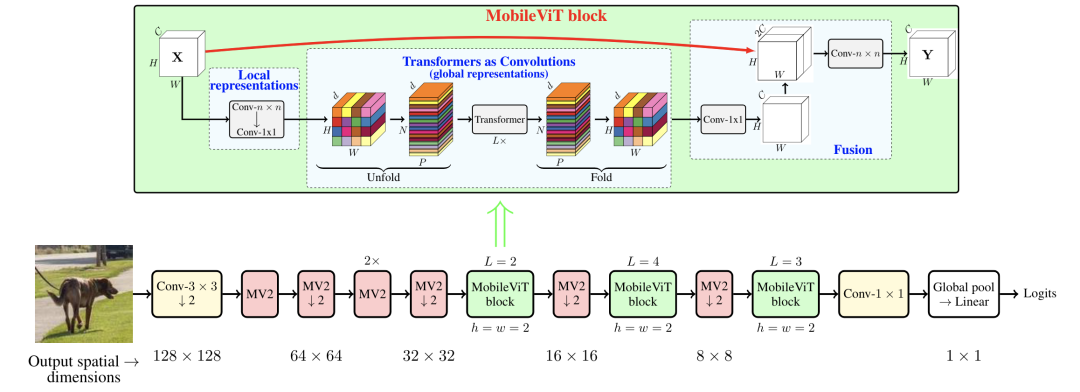
MobileViT通過(guò)堆疊MobileNetv2 block和MobileViT block構(gòu)成。
CeiT [paper]
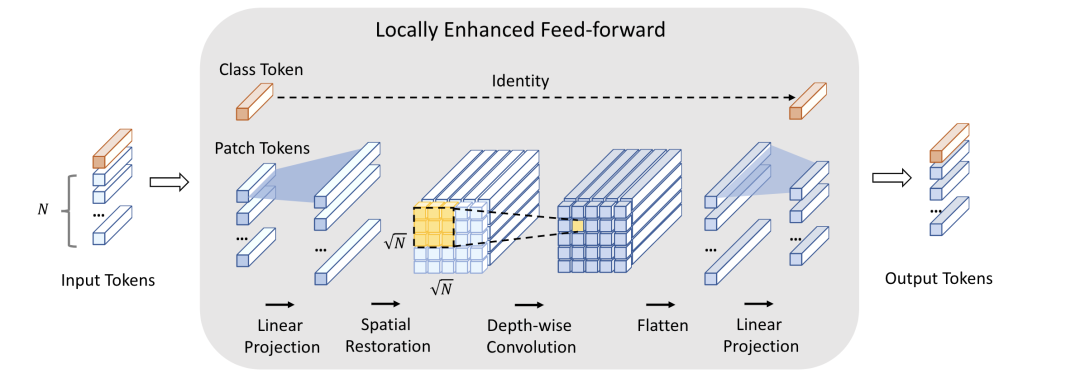
CeiT設(shè)計(jì)了一個(gè)局部增強(qiáng)的LeFF結(jié)構(gòu),只對(duì)patch token部分做linear projection和depth-wise conv。
CMT [paper]
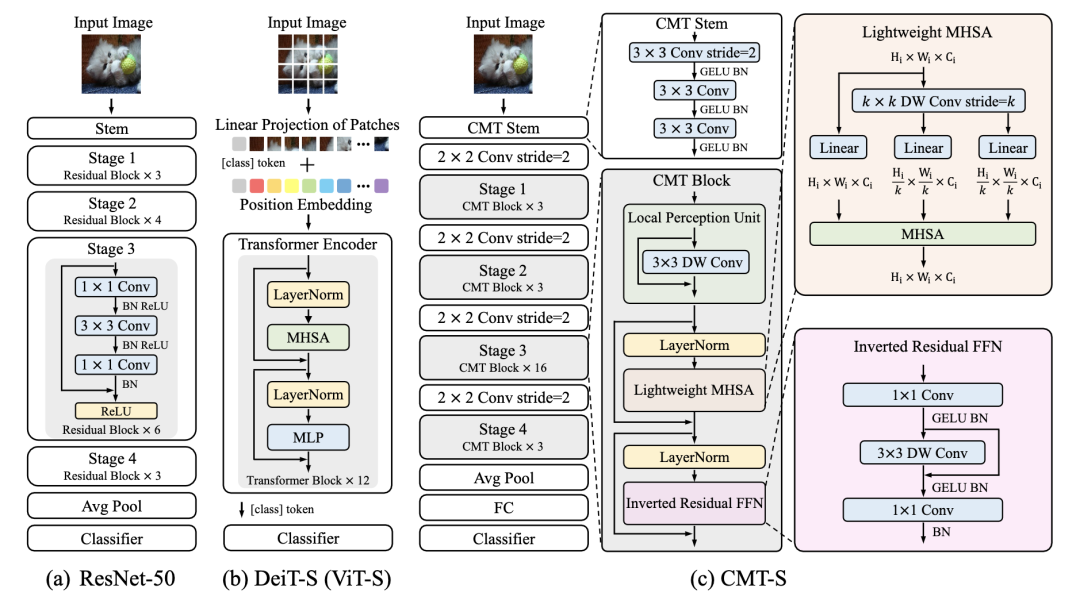
CMT設(shè)計(jì)了一個(gè)CMT block,如圖所示。
Object Detection
CNN backbone
*DETR [paper] [code]
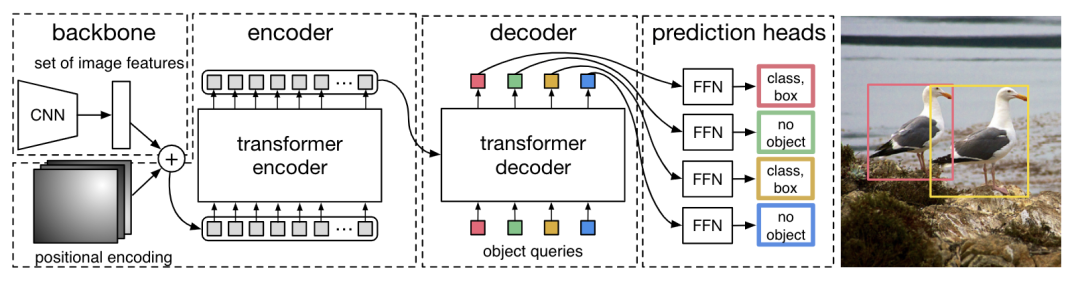
DETR是第一個(gè)使用Transformer做目標(biāo)檢測(cè)的算法。圖片先通過(guò)CNN提取特征,然后和positional encoding相加送入transformer,最后通過(guò)FFN預(yù)測(cè)結(jié)果。其中decoder部分需要設(shè)置object queries,并行輸出預(yù)測(cè)結(jié)果,訓(xùn)練的時(shí)候pred和target通過(guò)雙邊匹配算法進(jìn)行匹配。
*UP-DETR [paper]
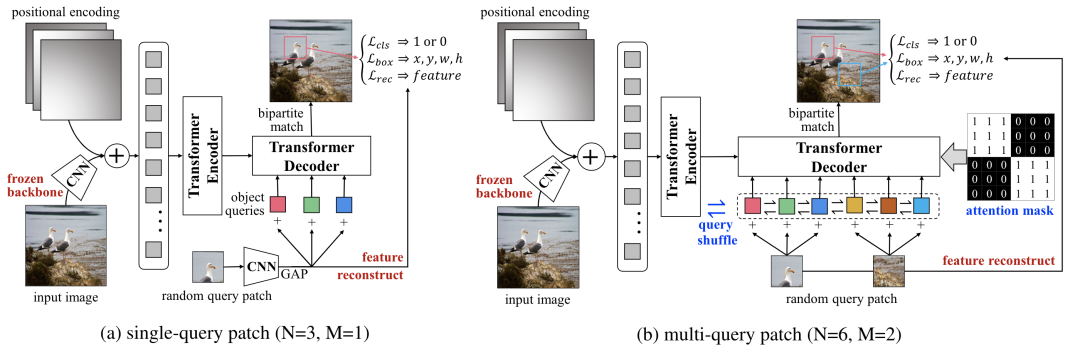
為了對(duì)DETR進(jìn)行預(yù)訓(xùn)練,UP-DETR處理了兩個(gè)關(guān)鍵問(wèn)題:
為了進(jìn)行分類(lèi)和定位對(duì)多任務(wù)訓(xùn)練,UP-DETR固定住預(yù)訓(xùn)練過(guò)的backbone和對(duì)patch特征進(jìn)行重建來(lái)保留transformer的判別力。
為了對(duì)多個(gè)patch進(jìn)行定位,不同queries設(shè)置不同的區(qū)域和大小。UP-DETR設(shè)計(jì)了兩種預(yù)訓(xùn)練方式,一種是single-query,另一種是multi-query。對(duì)于multi-query設(shè)計(jì)了object query shuffle和attention mask操作來(lái)解決query patches和object queries對(duì)齊問(wèn)題。
DETReg [paper] [code]
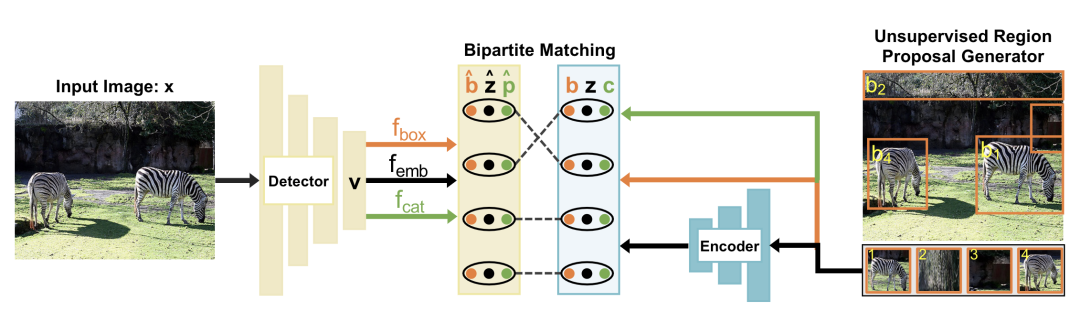
上圖是DETReg的整體框架。給定一張圖片x,使用DETR得到embeddings v,總共設(shè)計(jì)了三個(gè)分支,一個(gè)分支預(yù)測(cè)box,一個(gè)分支預(yù)測(cè)embdding,還有一個(gè)分支預(yù)測(cè)目標(biāo)分?jǐn)?shù)cat。偽gt區(qū)域提議label通過(guò)selective search得到,偽gt目標(biāo)embedding通過(guò)自監(jiān)督算法SwAV得到,proposal的目標(biāo)分?jǐn)?shù)都設(shè)置為1。通過(guò)雙邊匹配將預(yù)測(cè)proposal和偽label進(jìn)行匹配,不匹配的預(yù)測(cè)proposal分?jǐn)?shù)用0填充。
SMCA [paper] [code]
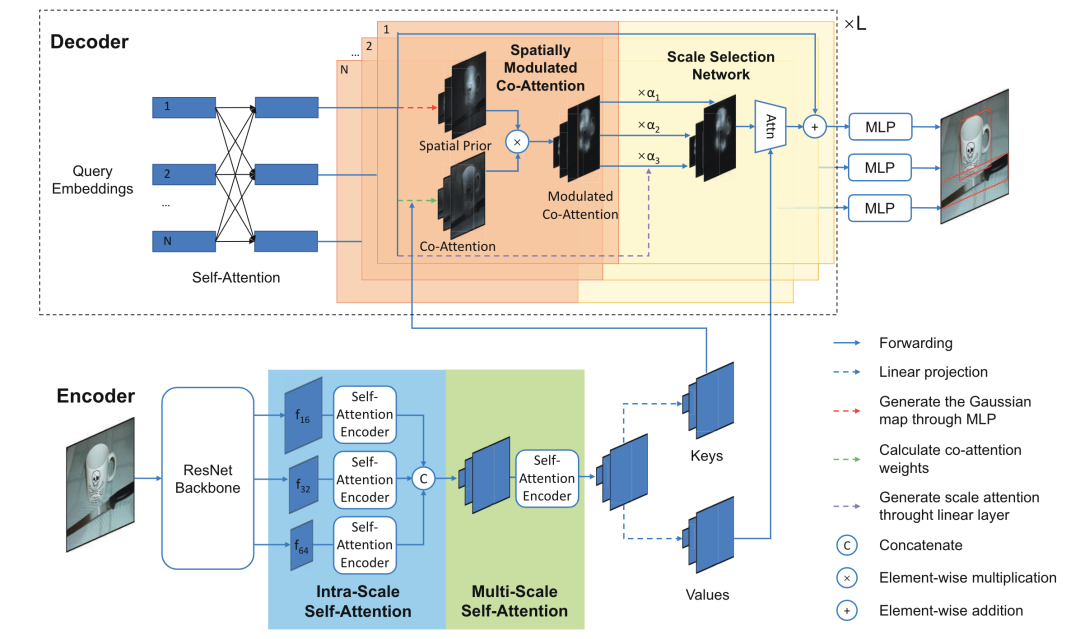
SMCA設(shè)計(jì)了一個(gè)Spatially Modulated Co-Attention組件來(lái)加快DETR的收斂速度,具體地,decoder的每個(gè)query先做一個(gè)spatial prior,然后和key進(jìn)行co-attention。另外SMCA還設(shè)計(jì)來(lái)一個(gè)Multi-Scale Self-Attention來(lái)進(jìn)一步提升精度。
*Deformable DETR [paper] [code]
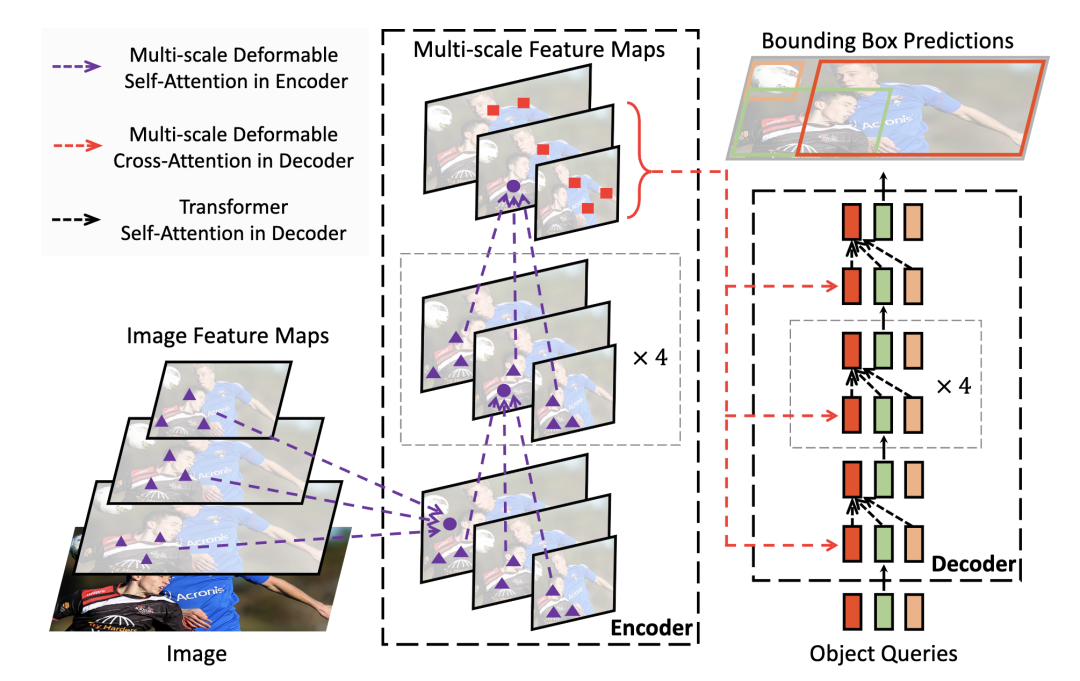
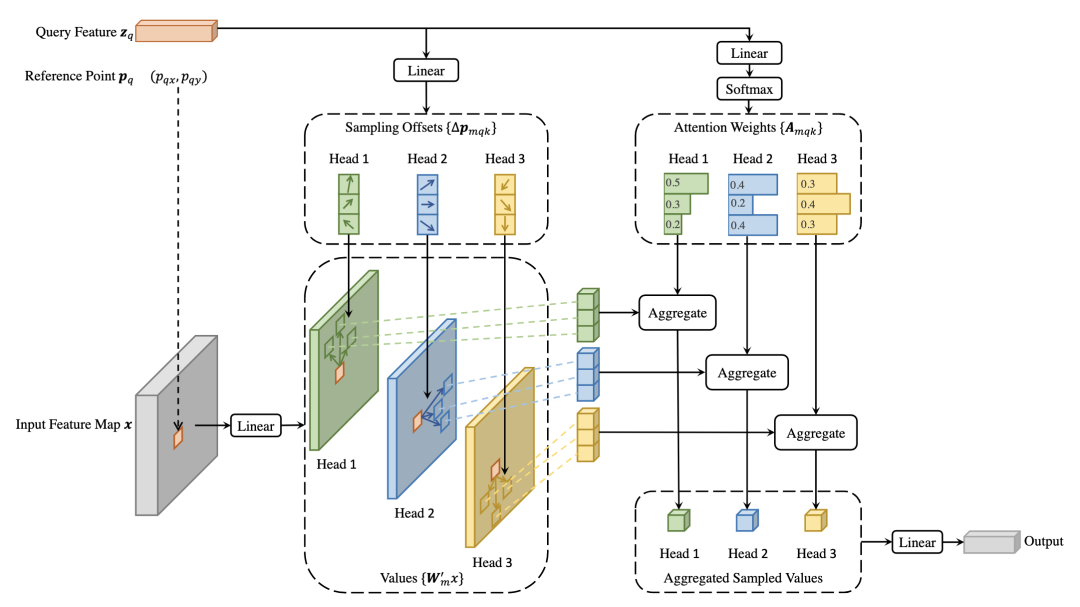
Deformable DETR結(jié)合了deformable conv的稀疏空間采樣和transformer的相關(guān)性建模能力的優(yōu)點(diǎn)。提出的deformable attention module用一些采樣位置作為重要的key元素,并且Deformable DETR將該謀愛(ài)拓展到multi-scale上。
Anchor DETR [paper] [code]
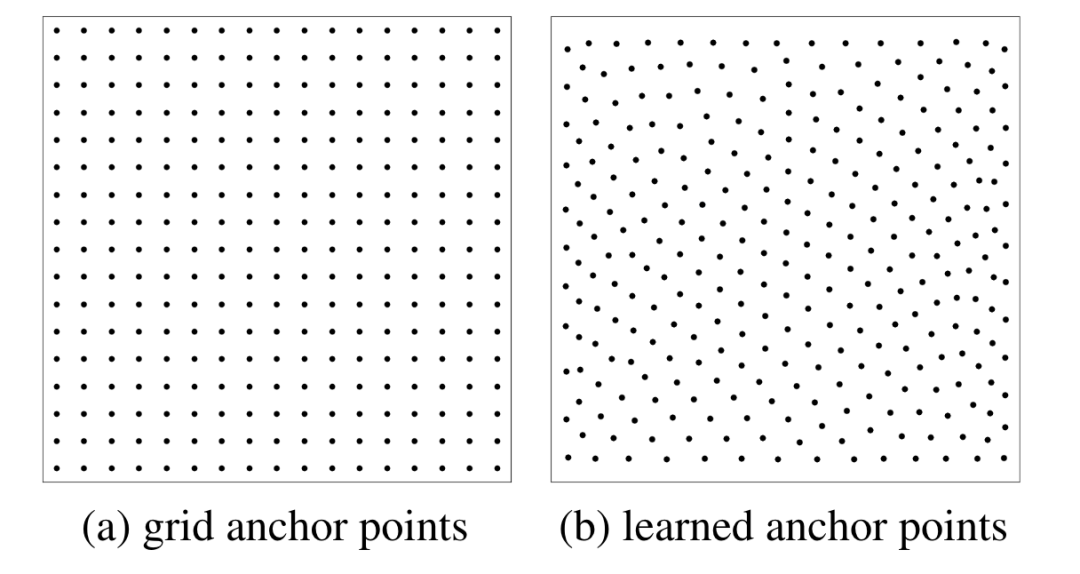
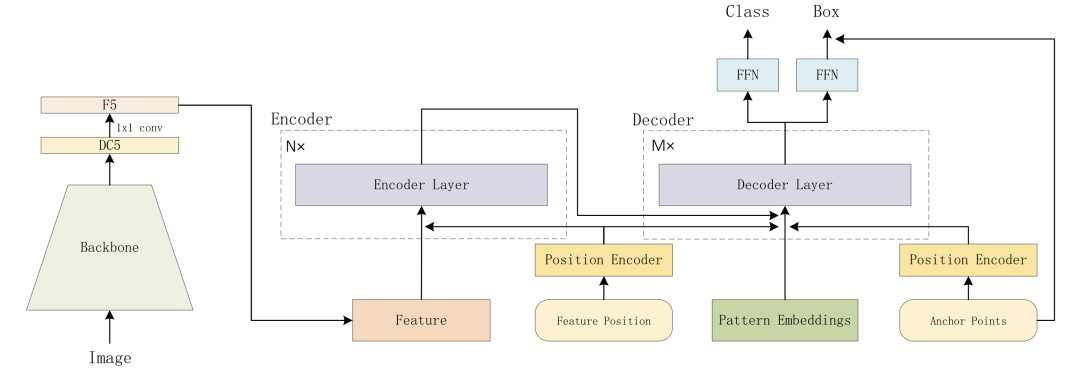
Anchor DETR在decoder部分設(shè)計(jì)了基于anchor points的object queries,并且row-column decoupled attention來(lái)替代MHSA,降低計(jì)算復(fù)雜度。
*Conditional DETR [paper] [code]
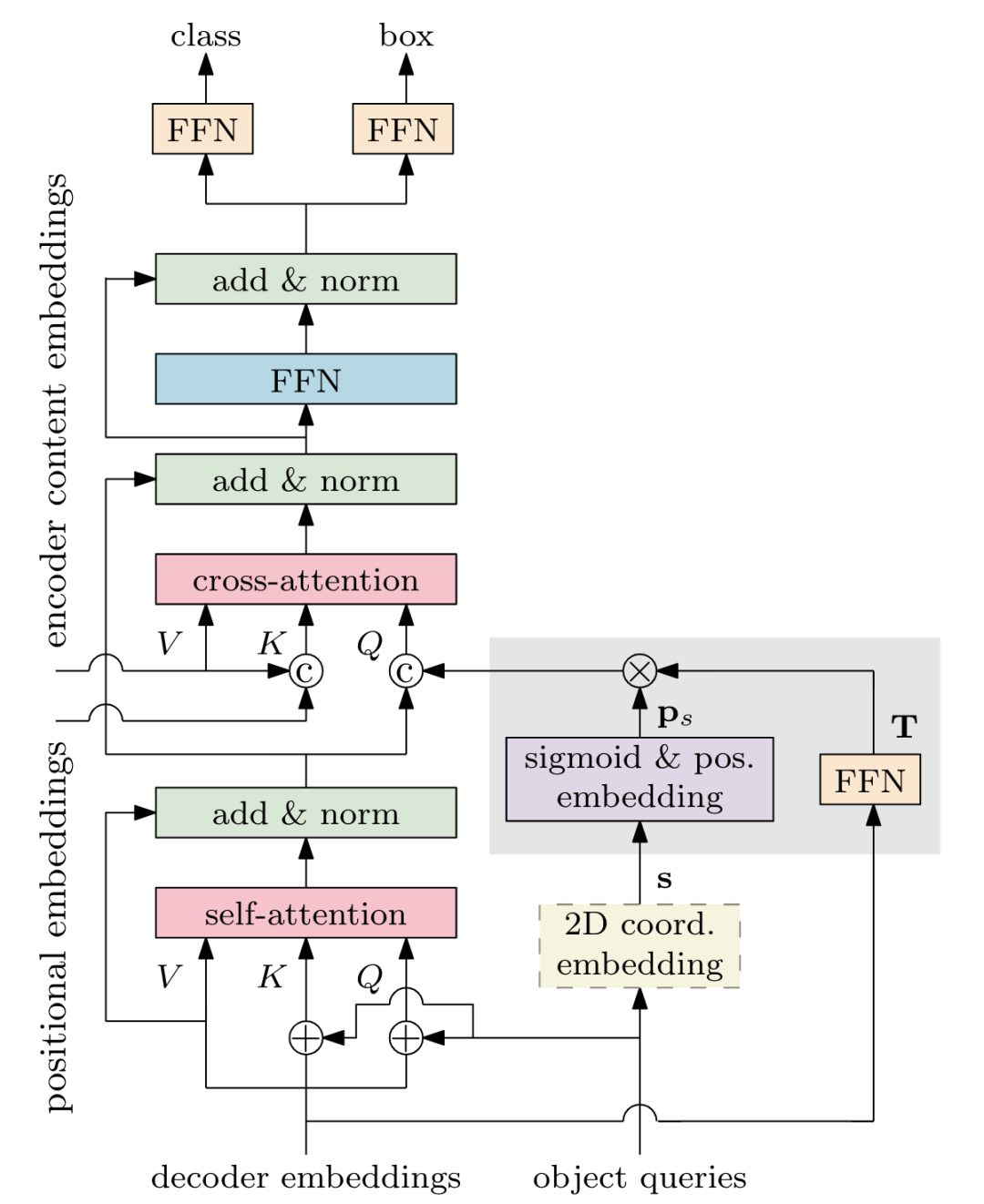
Conditional DETR將content queries和spatial queries獨(dú)立開(kāi),使得各自關(guān)注于content attention weights和spatial attention weights,加快訓(xùn)練的收斂速度。
*TSP-FCOS [paper]
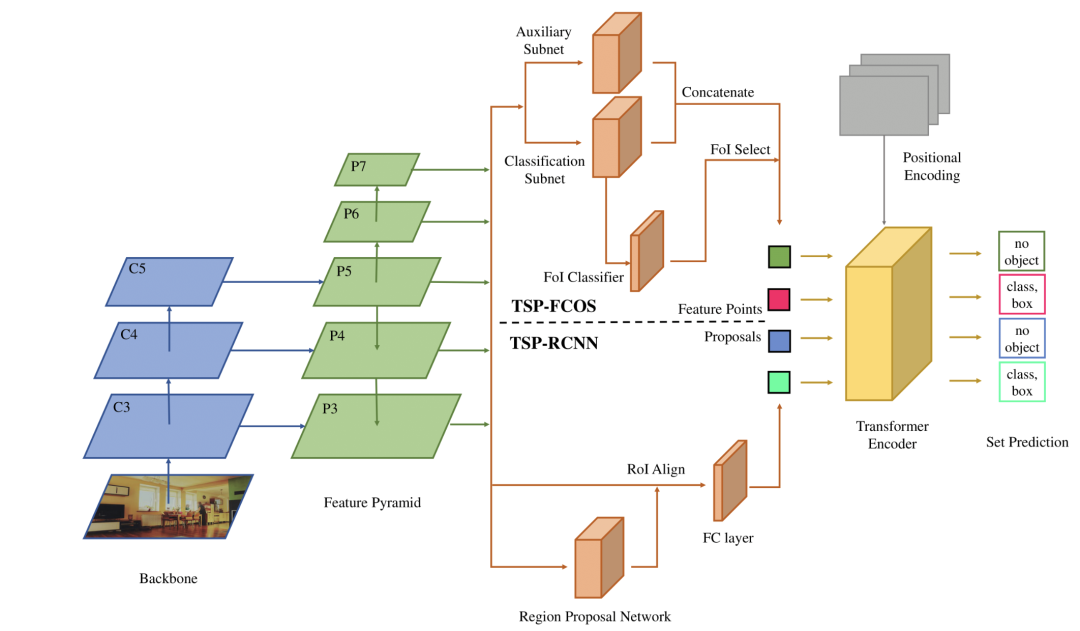
本文實(shí)驗(yàn)觀察發(fā)現(xiàn),影響DETR收斂速度的主要原因是cross-attention和雙邊匹配的不穩(wěn)定。于是本文提出只使用transformer的encoder,其中TSP-FCOS設(shè)計(jì)了一種FoI Select來(lái)選擇特征。并且還設(shè)計(jì)來(lái)一種新的雙邊匹配算法來(lái)加快收斂。
PnP-DETR [paper] [code]
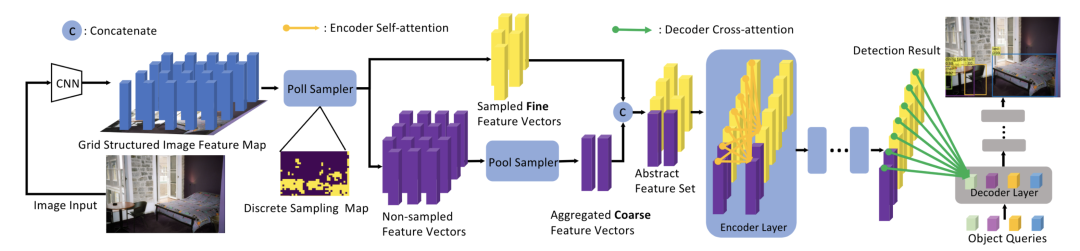 PnP-DETR設(shè)計(jì)了兩種采樣方式來(lái)降低計(jì)算復(fù)雜度,poll sampler和pool sampler,poll sampler對(duì)feature map對(duì)每個(gè)位置預(yù)測(cè)分?jǐn)?shù),然后挑選出fine的特征,通過(guò)pool sampler對(duì)coarse特征進(jìn)行聚合。
PnP-DETR設(shè)計(jì)了兩種采樣方式來(lái)降低計(jì)算復(fù)雜度,poll sampler和pool sampler,poll sampler對(duì)feature map對(duì)每個(gè)位置預(yù)測(cè)分?jǐn)?shù),然后挑選出fine的特征,通過(guò)pool sampler對(duì)coarse特征進(jìn)行聚合。
D^2ETR [paper]
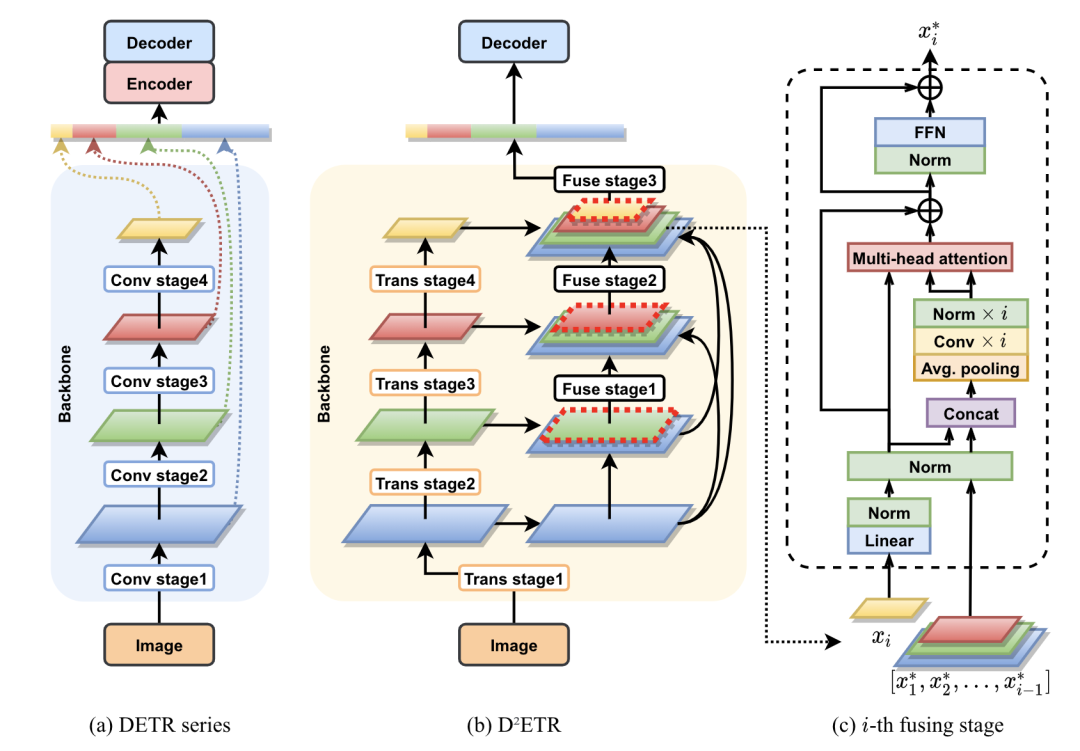
D^2ETR去掉了DETR的encoder部分,同時(shí)在backbone部分對(duì)不同stage的特征進(jìn)行融合操作。
Sparse DETR [paper] [code]
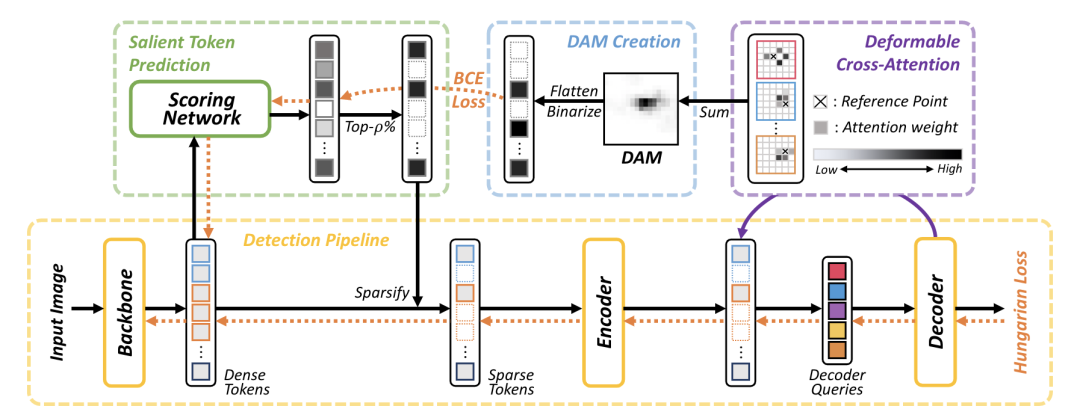
Sparse DETR通過(guò)Deformable cross-attention得到binarized decoder cross-attention map(DAM),用來(lái)作為scoring network的監(jiān)督信號(hào),預(yù)測(cè)出token的重要程度,并且只保留top-p%的token進(jìn)行訓(xùn)練。
*Efficient DETR [paper]
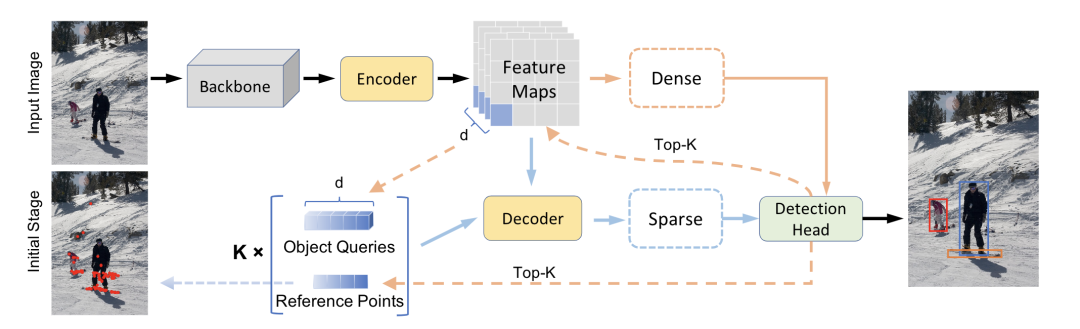
Efficient DETR通過(guò)預(yù)測(cè)結(jié)果來(lái)初始化object queries,具體地,選取top-K個(gè)位置的feature當(dāng)作object queries,位置當(dāng)作reference points,k組embedding送入decoder進(jìn)行稀疏預(yù)測(cè),最終Efficient DETR只需要一個(gè)decoder就能超過(guò)DETR 6個(gè)decoder的精度。
Dynamic DETR [paper]
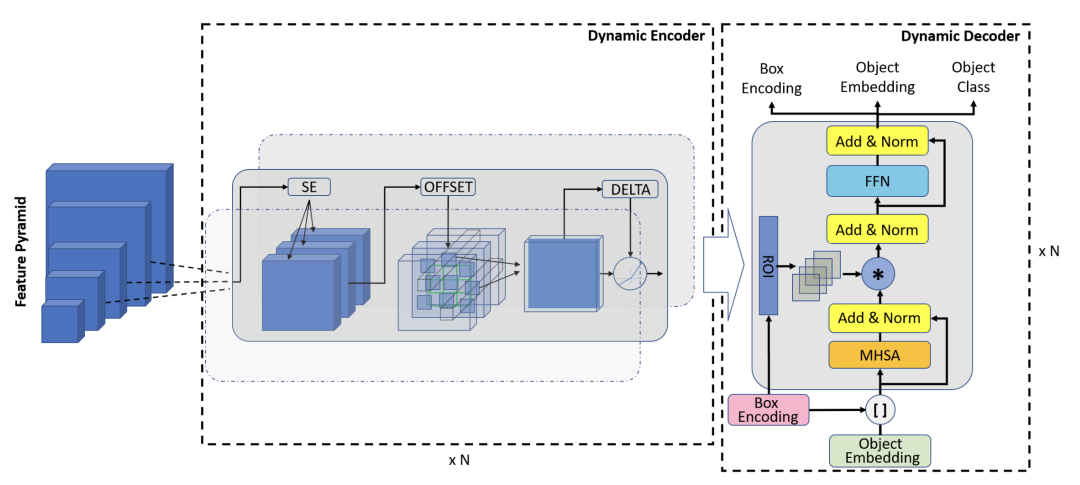
Dynamic DETR的dynamic encoder部分引入SE然后用deformable self-attention來(lái)提取多尺度特征,dynamic decoder部分引入可學(xué)習(xí)的box encoding,然后對(duì)encoder的特征做roi池化,最后和decoder的中間層embedding做相乘。
*DAB-DETR ?[paper] [code]
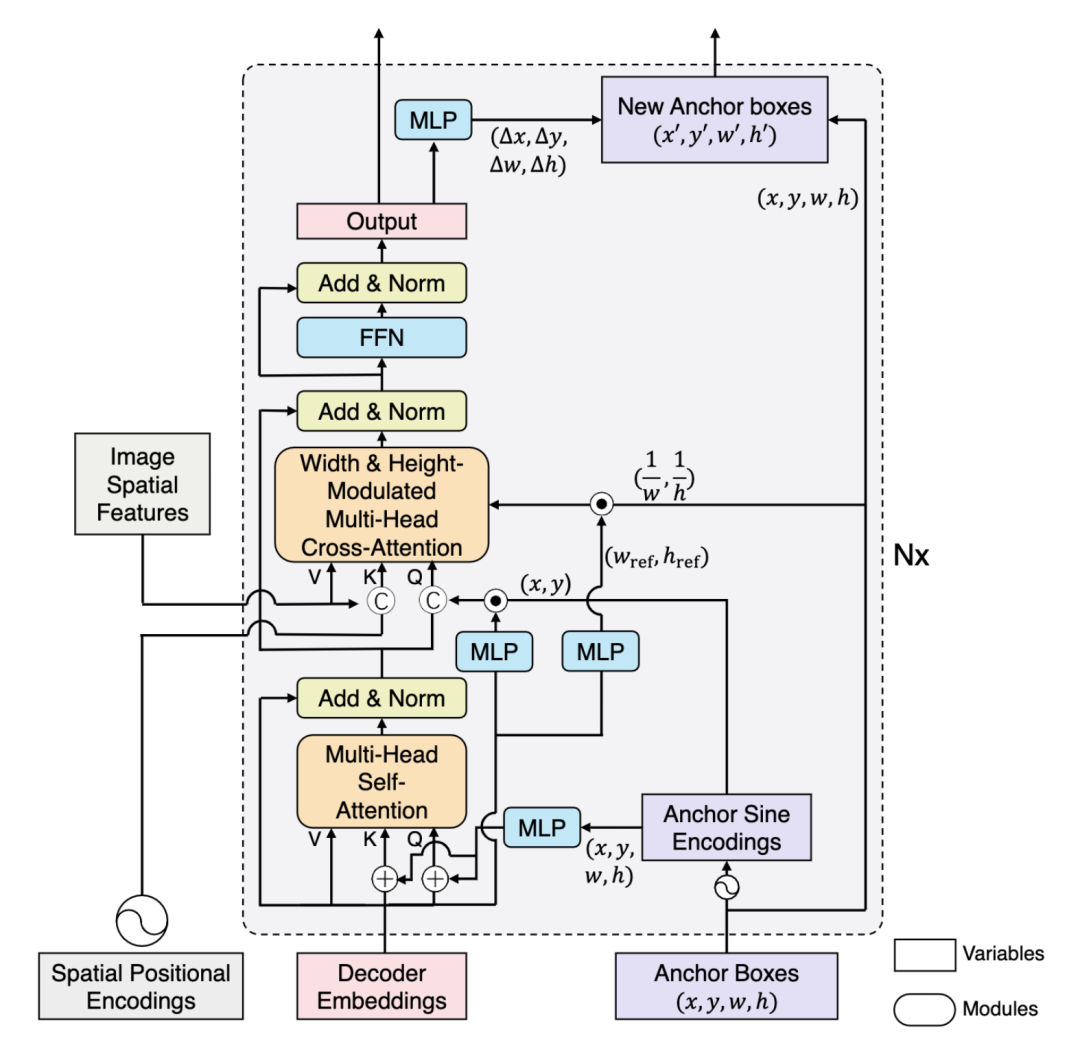
DAB-DETR直接動(dòng)態(tài)更新anchor boxes提供參照點(diǎn)和參照anchor尺寸來(lái)改善cross-attention的計(jì)算。
*DN-DETR [paper] [code]
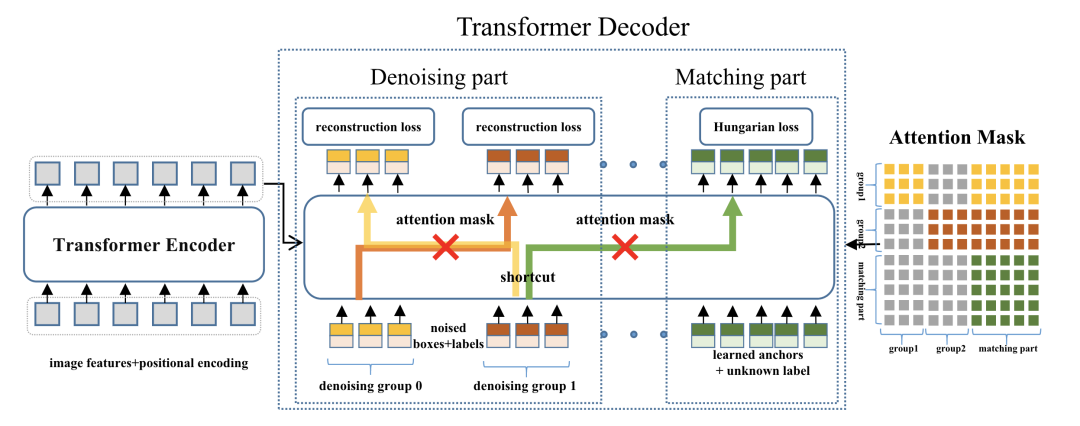
DN-DETR在DAB-DETR的基礎(chǔ)上,增加來(lái)一個(gè)denoising輔助任務(wù),從而避免訓(xùn)練前期雙邊匹配的不穩(wěn)定,加快收斂速度。
*DINO [paper] [code]
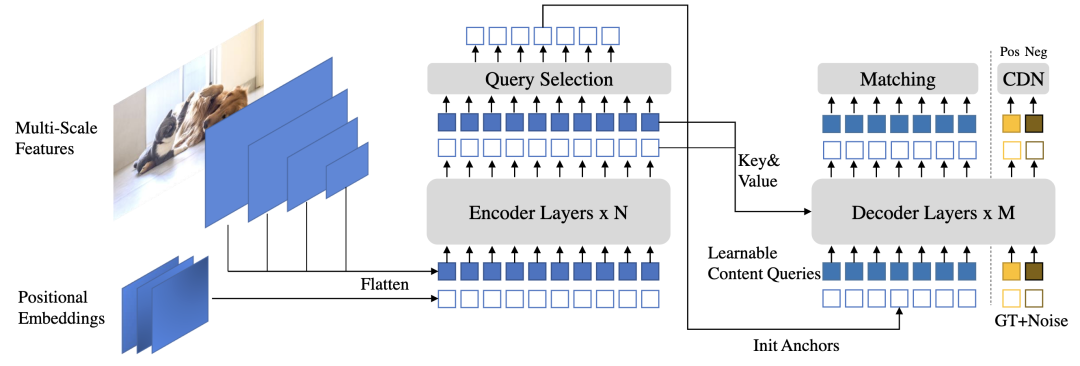
DINO在DN-DETR的基礎(chǔ)上引入了三點(diǎn)改進(jìn):
增加了一個(gè)新的輔助任務(wù)contrastive denoising training,在相同的gt box添加兩種不同的noise,noise小的當(dāng)作正樣本,noise大的當(dāng)作負(fù)樣本。
提出mixed query selection方法,從encoder的輸出中選擇初始anchor boxes作為positional queries。
提出look forward twice方法,利用refined box信息來(lái)幫助優(yōu)化前面層的參數(shù)。
Pure Transformer
Pix2Seq [paper]
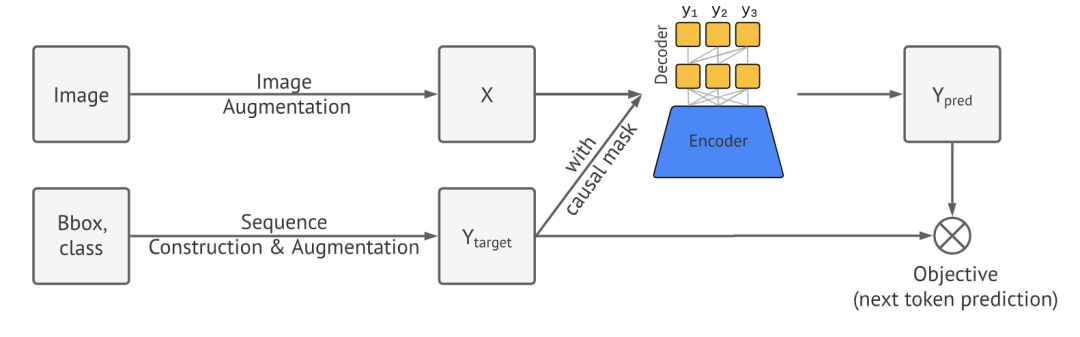
Pix2Seq直接把目標(biāo)檢測(cè)任務(wù)當(dāng)成是序列任務(wù),將cls和bbox構(gòu)建成序列目標(biāo),圖片通過(guò)Transformer直接預(yù)測(cè)序列結(jié)果。
YOLOS [paper] [code]
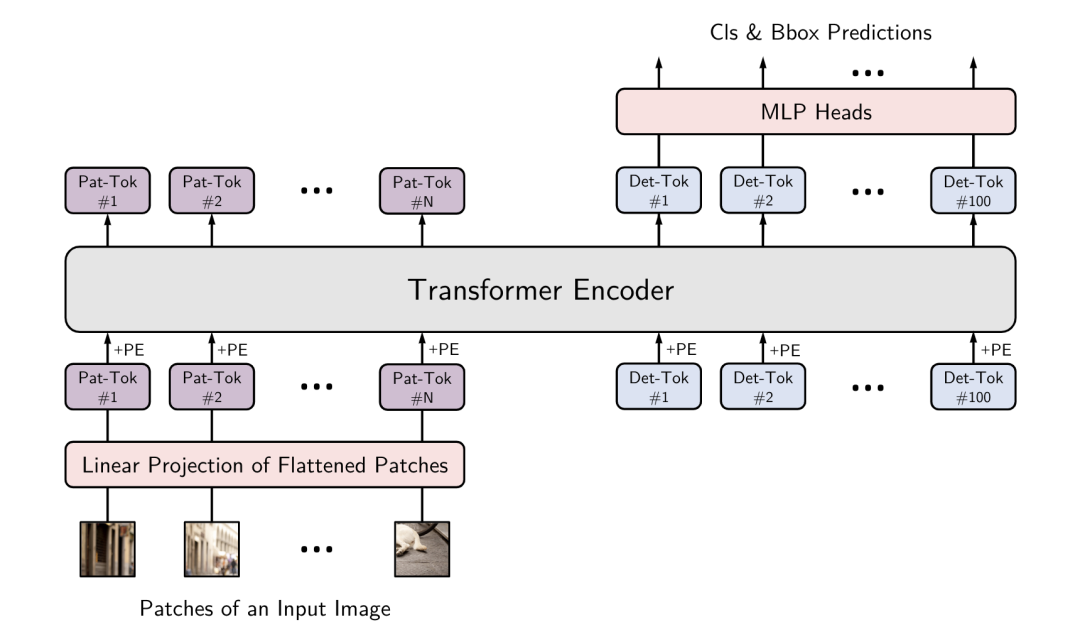
YOLOS只使用transformer encoder做目標(biāo)檢測(cè),模仿vit在encoder部分設(shè)置det token,在輸出部分接MLP預(yù)測(cè)出cls和bbox。
FP-DETR [paper]
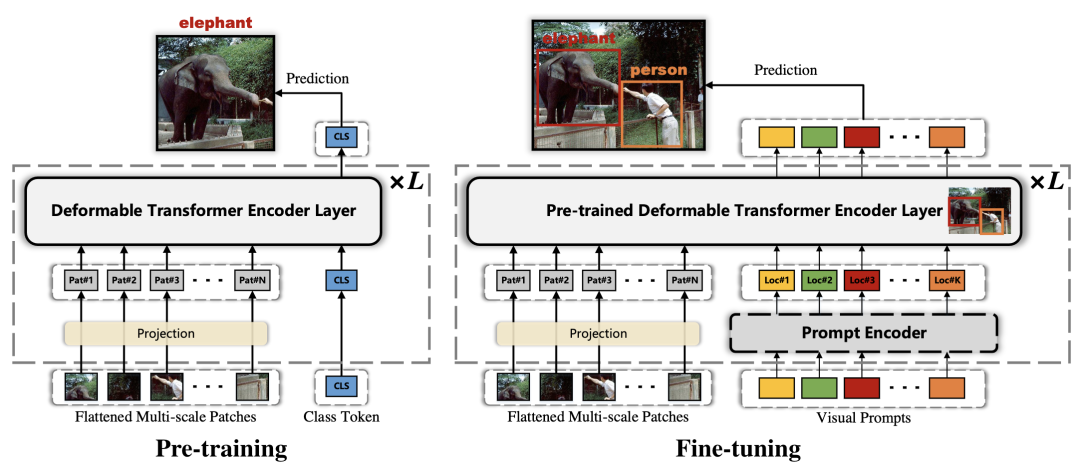
FP-DETR只使用transformer encoder部分,先使用cls token來(lái)做pre-training,然后替換成visual prompts來(lái)做fine-tuning。其中visual prompts由query content embedding和query positional embedding相加得到。
Instance segmentation
SOTR [paper] [code]
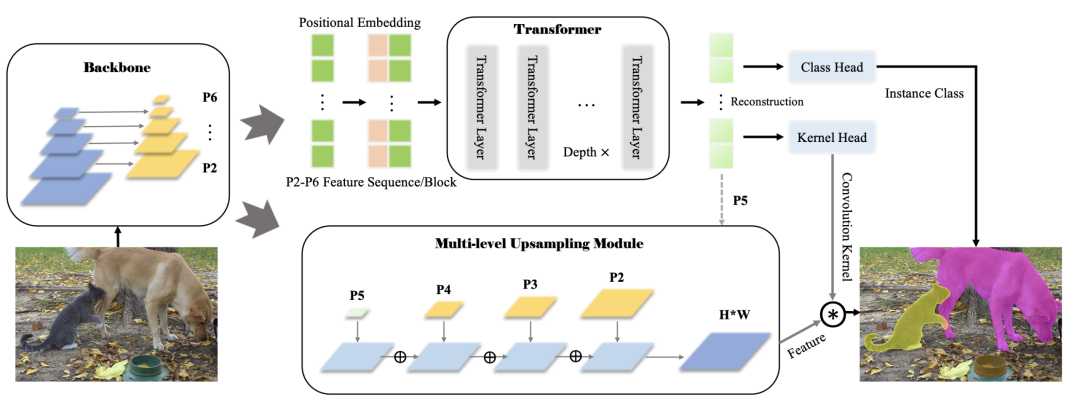
SOTR在FPN backbone的基礎(chǔ)上最小修改構(gòu)建的。將多尺度的feature map加上positional embedding送入transformer模型中,通過(guò)cls head和kernel head預(yù)測(cè)出instance cls和dynamic conv,另一個(gè)分支對(duì)多尺度特征進(jìn)行上采樣融合得到,最后和dynamic conv想乘得到不同instance cls的區(qū)域。
panoptic segmentation
Max-DeepLab [paper] [code]
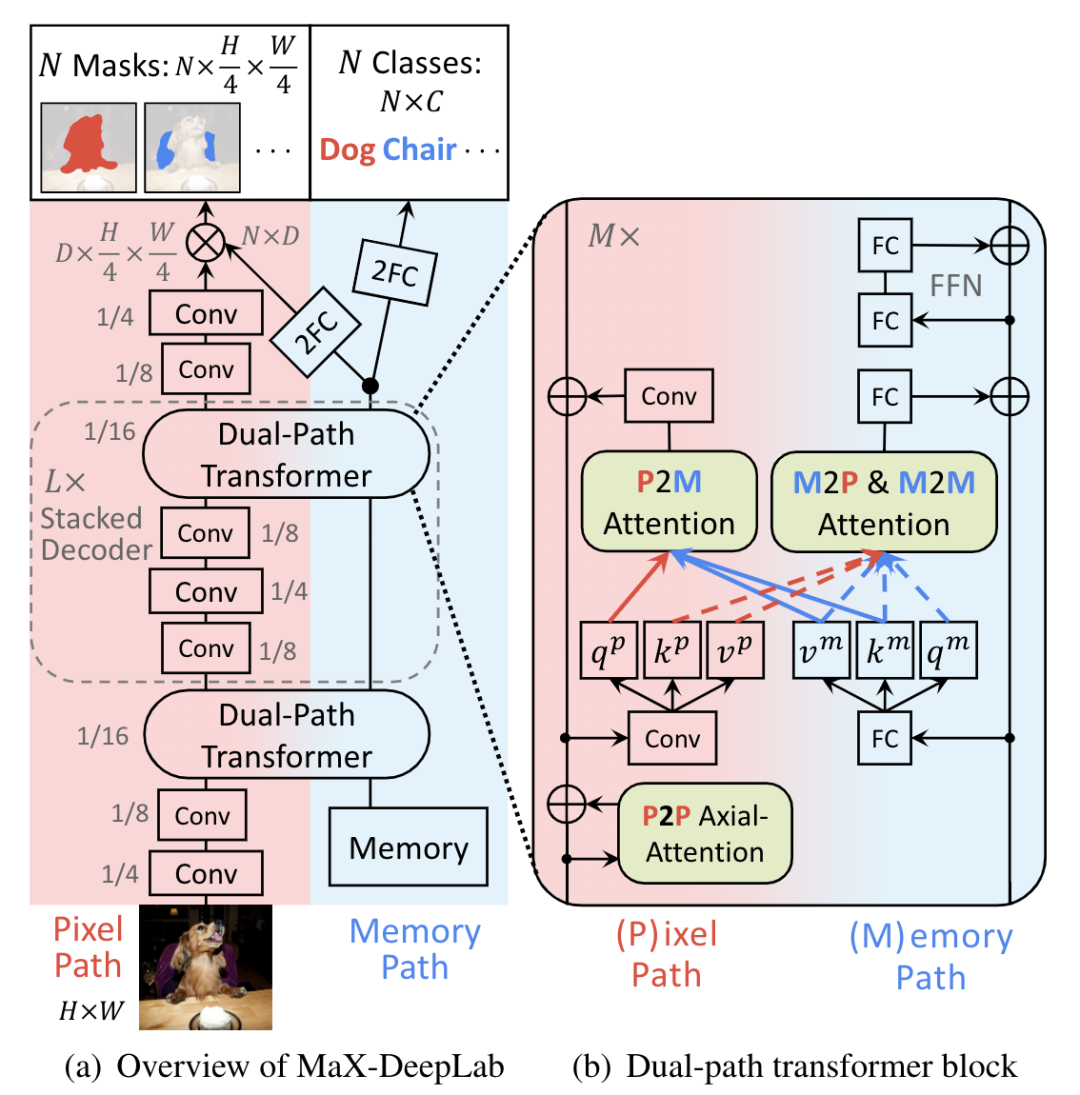
Max-DeepLab設(shè)計(jì)了兩個(gè)分支pixel path和memory path,兩個(gè)分支在dual-path tansformer中進(jìn)行交互,最終pixel path預(yù)測(cè)出mask,memory path預(yù)測(cè)出cls。
*MaskFormer ?[paper] [code]
*Mask2Former [paper] [code]
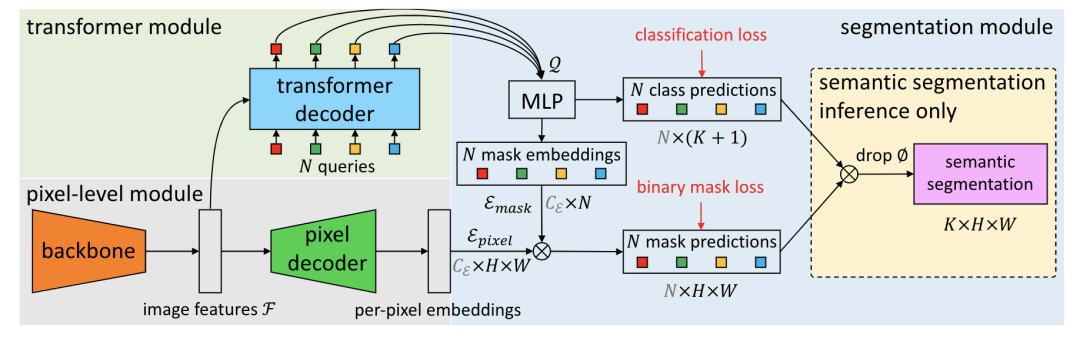
MaskFormer提出將全景分割看成是mask分類(lèi)任務(wù)。通過(guò)transformer decoder和MLP得到N個(gè)mask embedding和N個(gè)cls pred。另一個(gè)分支通過(guò)pixel decoder得到per-pixel embedding,然后將mask embedding和per-pixel embedding相乘得到N個(gè)mask prediction,最后cls pred和mask pred相乘,丟棄沒(méi)有目標(biāo)的mask,得到最終預(yù)測(cè)結(jié)果。
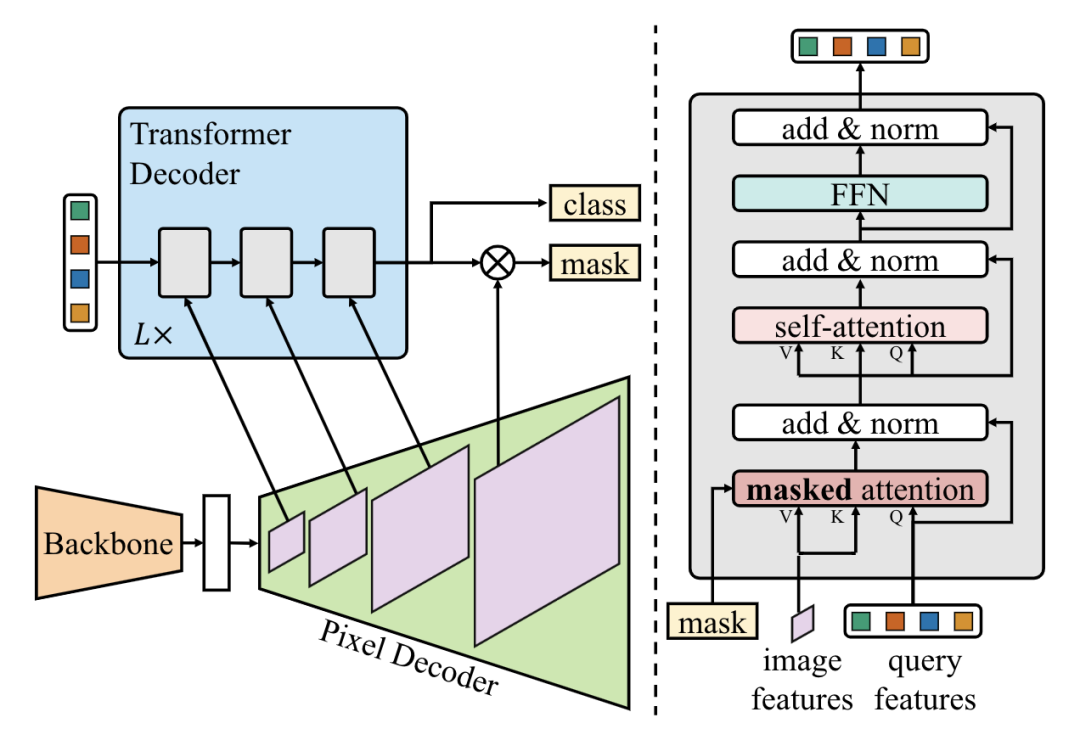
Mask2Former在MaskFormer的基礎(chǔ)上,增加了masked attention機(jī)制,另外還調(diào)整了decoder部分的self-attention和cross-attention的順序,還提出了使用importance sampling來(lái)加快訓(xùn)練速度。
Image Segmentation
semantic segmentation
SETR [paper] [code]
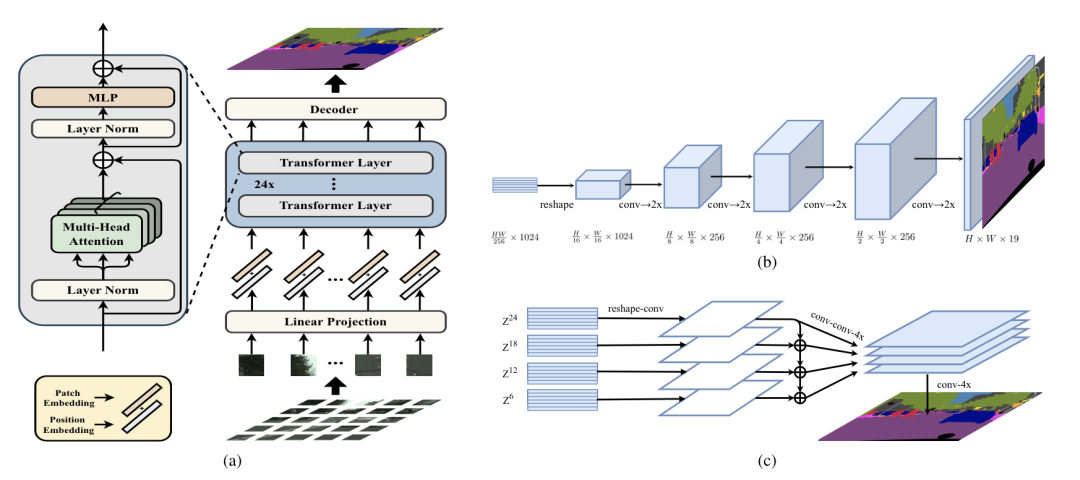
SETR用ViT/DeiT作為backbone,然后設(shè)計(jì)了兩種head形式:SETR-PUP和SETR-MLA。PUP將backbone輸出的feature reshape成二維形式,然后不斷的上采樣得到最終的預(yù)測(cè)結(jié)果;MLA將多個(gè)stage的中間feature進(jìn)行reshape,然后融合上采樣得到最終的預(yù)測(cè)結(jié)果。
SegFormer [paper] [code]
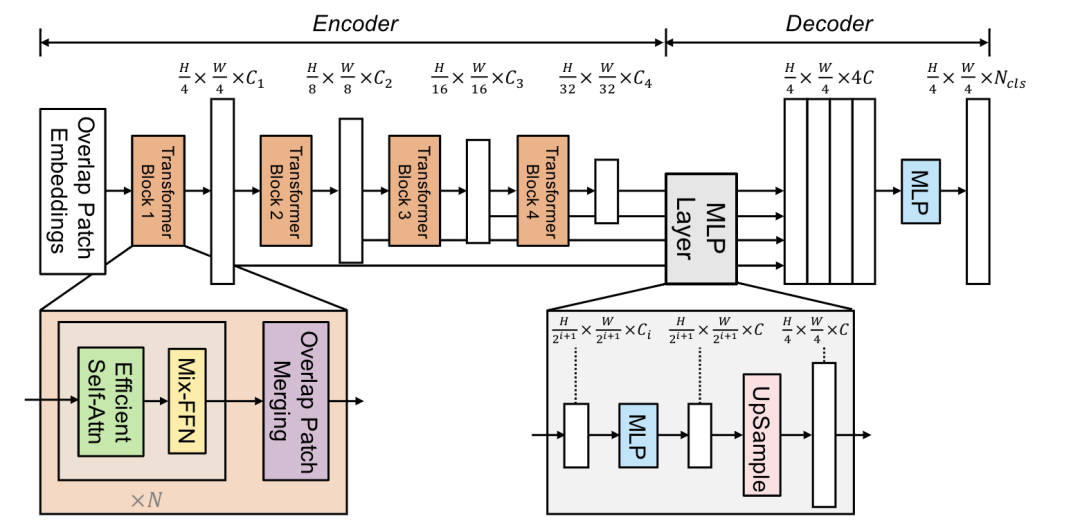
SegFormer設(shè)計(jì)了一個(gè)encoder-decoder的分割框架,其中transformer block由Efficient Self-Attn、Mix-FFN、Overlap Patch Merging構(gòu)成。Efficient Self-Attn對(duì)K進(jìn)行下采樣,Mix-FFN額外使用了conv。
Segmenter [paper] [code]
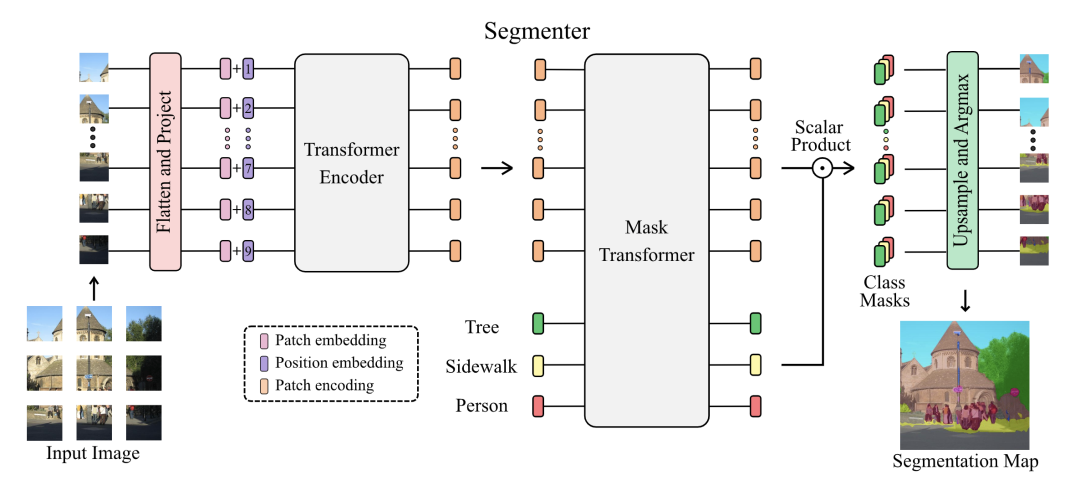
Segmenter設(shè)計(jì)了類(lèi)別無(wú)關(guān)的cls token,最后預(yù)測(cè)的時(shí)候分別和patch token進(jìn)行點(diǎn)乘,最后reshap成二維圖像。
U-Net Transformer [paper]
TransUNet [paper] [code]
Swin-Unet [paper] [code]
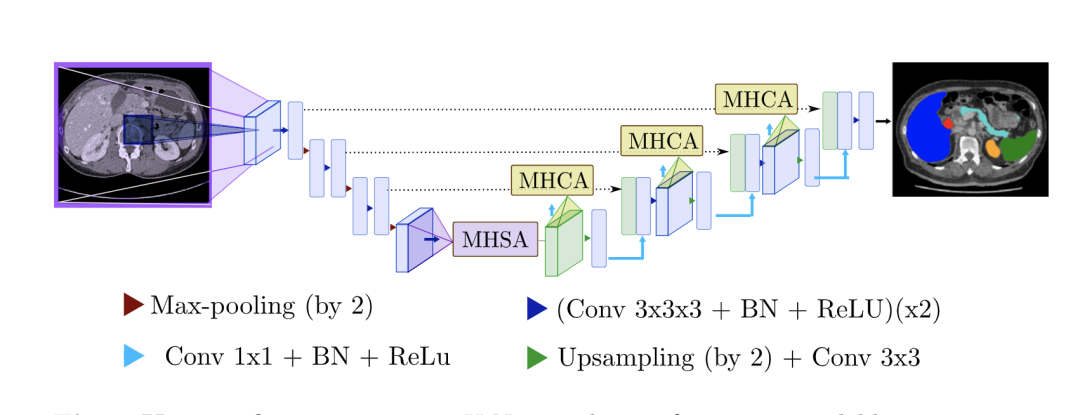
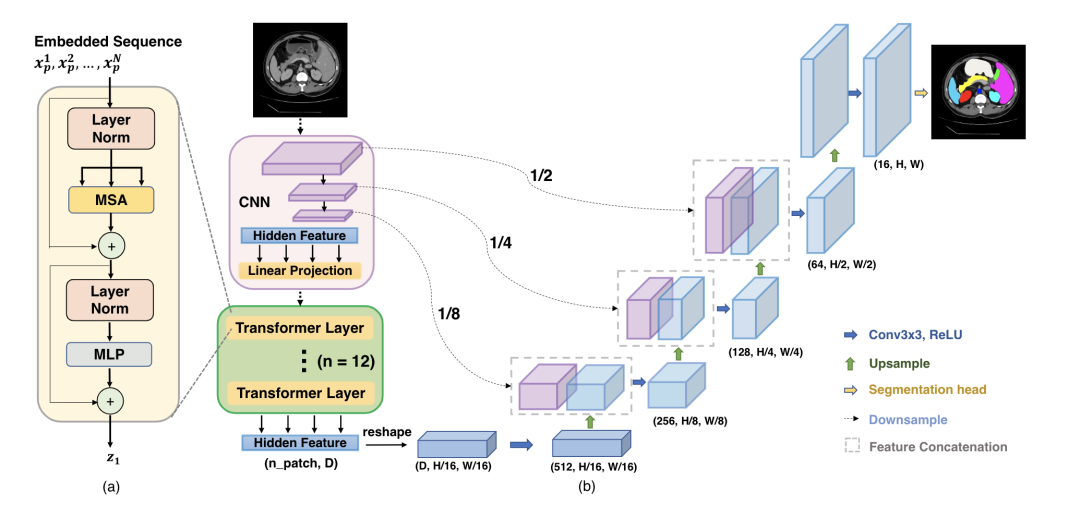
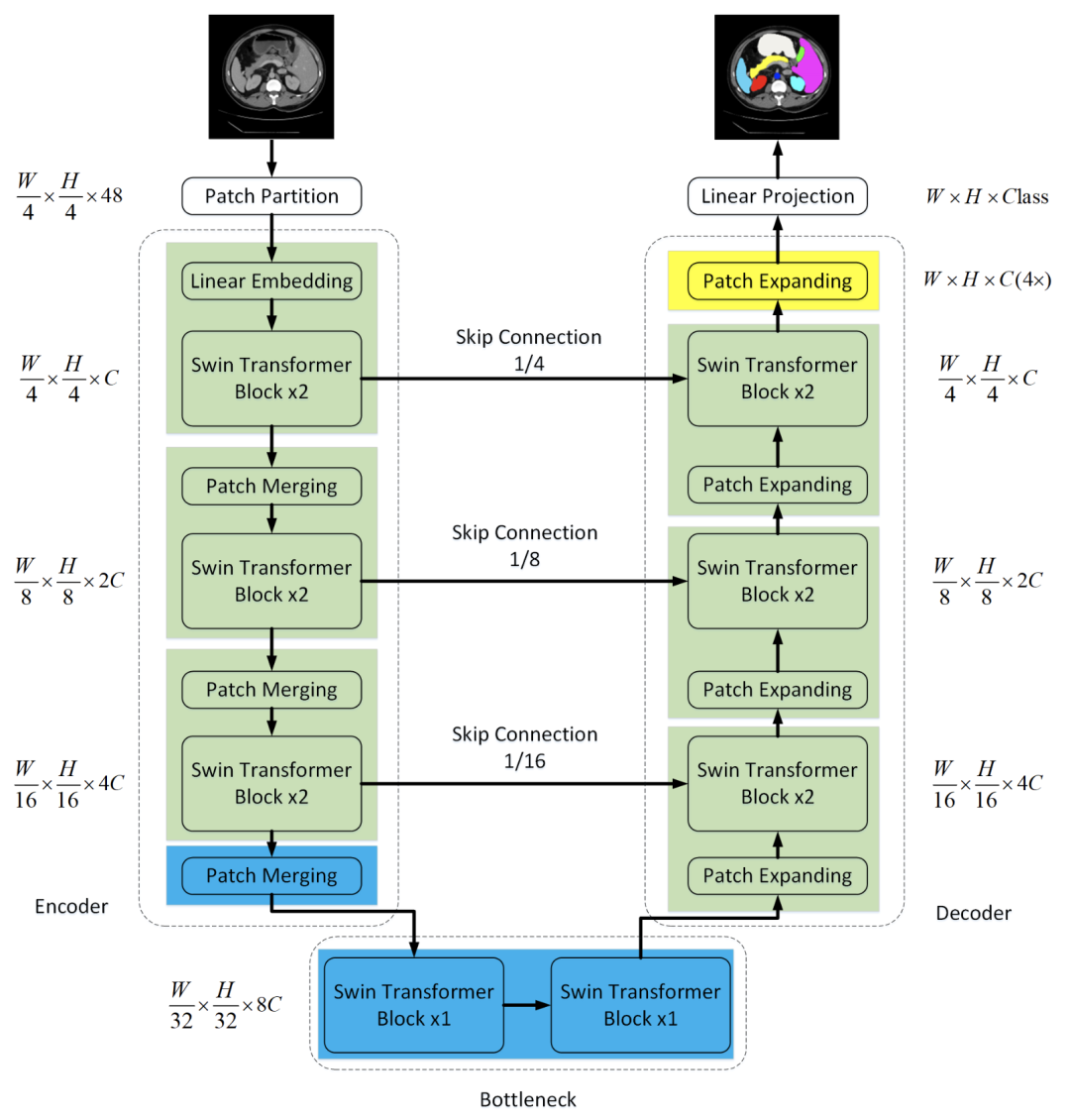
在U-Net結(jié)構(gòu)中引入Transformer
P2T [paper]
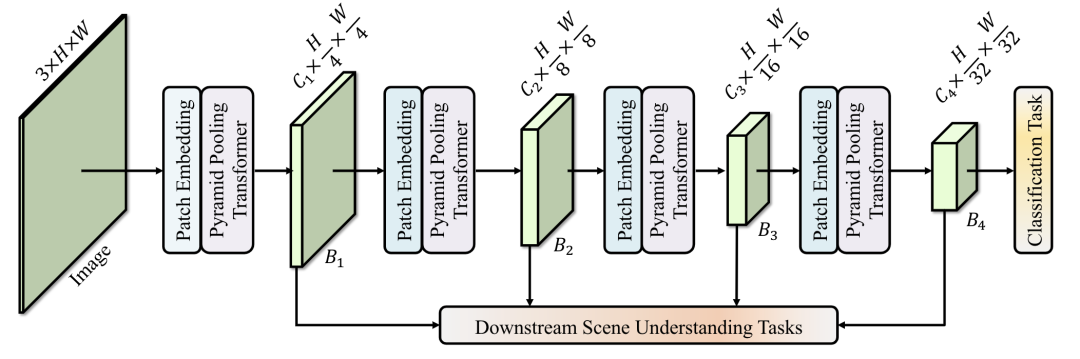
用對(duì)KV做池化的MHSA做下采樣。
HRFormer [paper]
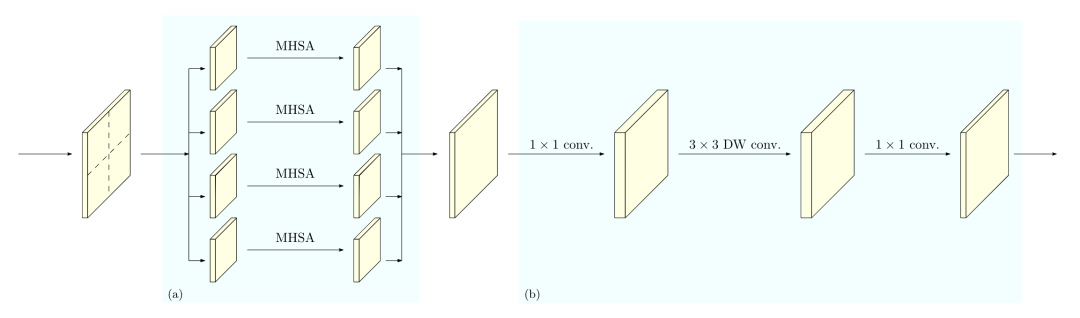
HRFormer的block由local-window self-attention和FFN組成。
往期精彩回顧