
盤點(diǎn)Python基礎(chǔ)之字符串的那些事兒
回復(fù)“書籍”即可獲贈Python從入門到進(jìn)階共10本電子書
為什么需要字符串?
當(dāng)打來瀏覽器登錄某些網(wǎng)站的時(shí)候,需要輸入密碼,瀏覽器把密碼傳送到服務(wù)器后,服務(wù)器會對密碼進(jìn)行驗(yàn)證,其驗(yàn)證過程是把之前保存的密碼與本次傳遞過去的密碼進(jìn)行對比,如果相等,那么就認(rèn)為密碼正確,否則就認(rèn)為不對;服務(wù)器既然想要存儲這些密碼可以用數(shù)據(jù)庫(比如MySQL)去實(shí)現(xiàn)。
當(dāng)然為了簡單起見,咱們可以先找個(gè)變量把密碼存儲起來即可;那么怎樣存儲帶有字母的密碼呢?這時(shí)就要用到字符串。
一、Python中字符串的格式
如下定義的變量a,存儲的是數(shù)字類型的值。
a = 100如下定義的變量b,存儲的是字符串類型的值。
b = "hello itcast.cn"或者b = 'hello itcast.cn'
小總結(jié):
雙引號或者單引號中的數(shù)據(jù),就是字符串
二、字符串輸出
例:
name = 'ming'position = '講師'address = '中山市平區(qū)建材城西路金燕龍辦公樓1層'print('--------------------------------------------------')print("姓名:%s"%name)print("職位:%s"%position)print("公司地址:%s"%address)print('--------------------------------------------------')
結(jié)果:
--------------------------------------------------姓名:ming職位:講師公司地址:中山市昌平區(qū)建材城西路金燕龍辦公樓1層--------------------------------------------------
三、字符串輸入
input通過它能夠完成從鍵盤獲取數(shù)據(jù),然后保存到指定的變量中;
注意:input獲取的數(shù)據(jù),都以字符串的方式進(jìn)行保存,即使輸入的是數(shù)字,那么也是以字符串方式保存。
例:
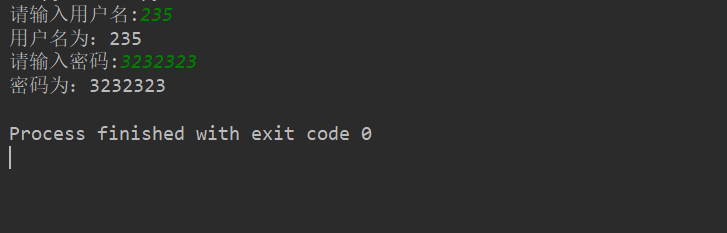
userName = input('請輸入用戶名:')print("用戶名為:%s"%userName)password = input('請輸入密碼:')print("密碼為:%s"%password)
結(jié)果:(根據(jù)輸入的不同結(jié)果也不同)
四、下標(biāo)和切片
1. 下標(biāo)索引
所謂“下標(biāo)”,就是編號,就好比超市中的存儲柜的編號,通過這個(gè)編號就能找到相應(yīng)的存儲空間。
生活中的 "下標(biāo)"
超市儲物柜

字符串中"下標(biāo)"的使用
列表與元組支持下標(biāo)索引好理解,字符串實(shí)際上就是字符的數(shù)組,所以也支持下標(biāo)索引。
如果有字符串:name = 'abcdef',在內(nèi)存中的實(shí)際存儲如下:

如果想取出部分字符,那么可以通過下標(biāo)的方法,(注意Python中下標(biāo)從 0 開始)
name = 'abcdef'print(name[0])print(name[1])print(name[2])
運(yùn)行結(jié)果:

2. 切片的概念:
切片是指對操作的對象截取其中一部分的操作。字符串、列表、元組都支持切片操作。
3. 切片的語法:[起始:結(jié)束:步長]
注意:選取的區(qū)間屬于左閉右開型,即從"起始"位開始,到"結(jié)束"位的前一位結(jié)束(不包含結(jié)束位本身)。
我們以字符串為例講解。
如果取出一部分,則可以在中括號[]中,使用 :
例:
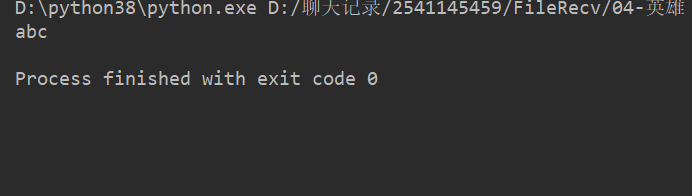
name = 'abcdef'print(name[0:3]) # 取 下標(biāo)0~2 的字符
運(yùn)行結(jié)果 :
例:
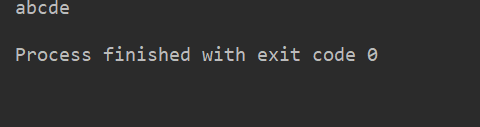
name = 'abcdef'print(name[0:5]) # 取 下標(biāo)為0~4 的字符
運(yùn)行結(jié)果:
例:
name = 'abcdef'print(name[3:5]) # 取 下標(biāo)為3、4 的字符
運(yùn)行結(jié)果:

例:
name = 'abcdef'print(name[2:]) # 取 下標(biāo)為2開始到最后的字符
運(yùn)行結(jié)果:

例:
name = 'abcdef'print(name[1:-1]) # 取 下標(biāo)為1開始 到 最后第2個(gè) 之間的字符
運(yùn)行結(jié)果:

> a = "abcdef"a[:3] #運(yùn)行結(jié)果'abc'a[::2] #運(yùn)行結(jié)果'ace'a[5:1:2]'' #運(yùn)行結(jié)果a[1:5:2]'bd' #運(yùn)行結(jié)果a[::-2]'fdb' #運(yùn)行結(jié)果a[5:1:-2]'fd' #運(yùn)行結(jié)果
五、字符串常見16種操作
以字符串'lstr = 'welcome to Beijing Museumitcpps fdsfs',為例。
介紹字符常見的操作。
<1> find
檢測 str 是否包含在 lstr中,如果是返回開始的索引值,否則返回-1。
語法:
lstr.find(str, start=0, end=len(lstr))例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.find("Museum"))print(lstr.find("dada"))
運(yùn)行結(jié)果:

<2> index
跟find()方法一樣,只不過如果str不在 lstr中會報(bào)一個(gè)異常。
語法:
lstr.index(str, start=0, end=len(lstr))例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.index("dada"))
運(yùn)行結(jié)果:

<3> count
返回 str在start和end之間 在 lstr里面出現(xiàn)的次數(shù)
語法:
lstr.count(str, start=0, end=len(lstr))例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.count("s"))
運(yùn)行結(jié)果:

<4> replace
把 lstr 中的 str1 替換成 str2,如果 count 指定,則替換不超過 count 次.
1str.replace(str1, str2, 1str.count(str1))例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.replace("s", "ttennd"))
運(yùn)行結(jié)果:

<5> split
以 str 為分隔符切片 lstr,如果 maxsplit有指定值,則僅分隔 maxsplit 個(gè)子字符串
1str.split(str=" ", 2) 例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.split("to", 5))
運(yùn)行結(jié)果:

<6> capitalize
把字符串的第一個(gè)字符大寫。
1str.capitalize()例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.capitalize())
運(yùn)行結(jié)果:

<7> title
把字符串的每個(gè)單詞首字母大寫。
> a = "hello itcast"> a.title()'Hello Itcast' #運(yùn)行結(jié)果
<8> startswith
檢查字符串是否是以 obj 開頭, 是則返回 True,否則返回 False
1str.startswith(obj)例:
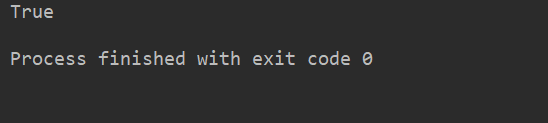
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.startswith('we'))
運(yùn)行結(jié)果:
<9> endswith
檢查字符串是否以obj結(jié)束,如果是返回True,否則返回 False.
1str.endswith(obj)例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.endswith('hfs'))
運(yùn)行結(jié)果:

<10> lower
轉(zhuǎn)換 lstr 中所有大寫字符為小寫
1str.lower() 例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.lower())
運(yùn)行結(jié)果:
<11> upper
轉(zhuǎn)換 lstr 中的小寫字母為大寫
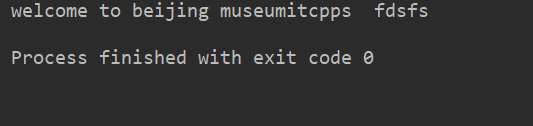
1str.upper() 例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.upper())
運(yùn)行結(jié)果:

<12> strip
刪除lstr字符串兩端的空白字符。
> a = "\n\t itcast \t\n"> a.strip()'itcast' #運(yùn)行結(jié)果
<13> rfind
類似于 find()函數(shù),不過是從右邊開始查找。
1str.rfind(str, start=0,end=len(1str) )例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.rfind('eijing'))
運(yùn)行結(jié)果:

<14> rindex
類似于 index(),不過是從右邊開始。
1str.rindex( str, start=0,end=len(1str))例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.rindex('eijing'))
運(yùn)行結(jié)果:
<15> partition
把lstr以str分割成三部分,str前,str和str后。
1str.partition(str)例:
lstr = 'welcome to Beijing Museumitcpps fdsfs'print(lstr.partition('eijing'))
運(yùn)行結(jié)果:

<16> join
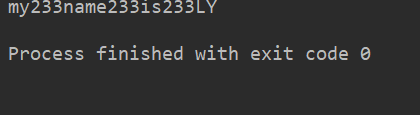
mystr 中每個(gè)字符后面插入str,構(gòu)造出一個(gè)新的字符串。
lstr = 'welcome to Beijing Museumitcpps fdsfs'str='233'lstr.join(str)li=["my","name","is","LY"]print(str.join(li))
運(yùn)行結(jié)果:
六、總結(jié)
本文詳細(xì)的講解了Python基礎(chǔ) ( 字符串 )。介紹了有關(guān)字符串,切片的操作。下標(biāo)索引。以及在實(shí)際操作中會遇到的問題,提供了解決方案。希望可以幫助你更好的學(xué)習(xí)Python。
------------------- End -------------------
往期精彩文章推薦:
手把手教你利用Python輕松拆分Excel為多個(gè)CSV文件
手把手教你4種方法用Python批量實(shí)現(xiàn)多Excel多Sheet合并
手把手教你用Python爬取百度搜索結(jié)果并保存

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請?jiān)诤笈_回復(fù)【入群】
萬水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說一兩句吧~