
非阻塞同步算法與CAS(Compare and Swap)無鎖算法
你知道的越多,不知道的就越多,業(yè)余的像一棵小草!
你來,我們一起精進(jìn)!你不來,我和你的競爭對(duì)手一起精進(jìn)!
編輯:業(yè)余草
推薦:https://www.xttblog.com/?p=5351
非阻塞同步算法與CAS(Compare and Swap)無鎖算法
鎖(lock)的代價(jià)
鎖是用來做并發(fā)最簡單的方式,當(dāng)然其代價(jià)也是最高的。內(nèi)核態(tài)的鎖的時(shí)候需要操作系統(tǒng)進(jìn)行一次上下文切換,加鎖、釋放鎖會(huì)導(dǎo)致比較多的上下文切換和調(diào)度延時(shí),等待鎖的線程會(huì)被掛起直至鎖釋放。在上下文切換的時(shí)候,cpu之前緩存的指令和數(shù)據(jù)都將失效,對(duì)性能有很大的損失。操作系統(tǒng)對(duì)多線程的鎖進(jìn)行判斷就像兩姐妹在為一個(gè)玩具在爭吵,然后操作系統(tǒng)就是能決定他們誰能拿到玩具的父母,這是很慢的。用戶態(tài)的鎖雖然避免了這些問題,但是其實(shí)它們只是在沒有真實(shí)的競爭時(shí)才有效。
Java在JDK1.5之前都是靠synchronized關(guān)鍵字保證同步的,這種通過使用一致的鎖定協(xié)議來協(xié)調(diào)對(duì)共享狀態(tài)的訪問,可以確保無論哪個(gè)線程持有守護(hù)變量的鎖,都采用獨(dú)占的方式來訪問這些變量,如果出現(xiàn)多個(gè)線程同時(shí)訪問鎖,那第一些線線程將被掛起,當(dāng)線程恢復(fù)執(zhí)行時(shí),必須等待其它線程執(zhí)行完他們的時(shí)間片以后才能被調(diào)度執(zhí)行,在掛起和恢復(fù)執(zhí)行過程中存在著很大的開銷。鎖還存在著其它一些缺點(diǎn),當(dāng)一個(gè)線程正在等待鎖時(shí),它不能做任何事。如果一個(gè)線程在持有鎖的情況下被延遲執(zhí)行,那么所有需要這個(gè)鎖的線程都無法執(zhí)行下去。如果被阻塞的線程優(yōu)先級(jí)高,而持有鎖的線程優(yōu)先級(jí)低,將會(huì)導(dǎo)致優(yōu)先級(jí)反轉(zhuǎn)(Priority Inversion)。
樂觀鎖與悲觀鎖
獨(dú)占鎖是一種悲觀鎖,synchronized就是一種獨(dú)占鎖,它假設(shè)最壞的情況,并且只有在確保其它線程不會(huì)造成干擾的情況下執(zhí)行,會(huì)導(dǎo)致其它所有需要鎖的線程掛起,等待持有鎖的線程釋放鎖。而另一個(gè)更加有效的鎖就是樂觀鎖。所謂樂觀鎖就是,每次不加鎖而是假設(shè)沒有沖突而去完成某項(xiàng)操作,如果因?yàn)闆_突失敗就重試,直到成功為止。
volatile的問題
與鎖相比,volatile變量是一和更輕量級(jí)的同步機(jī)制,因?yàn)樵谑褂眠@些變量時(shí)不會(huì)發(fā)生上下文切換和線程調(diào)度等操作,但是volatile變量也存在一些局限:不能用于構(gòu)建原子的復(fù)合操作,因此當(dāng)一個(gè)變量依賴舊值時(shí)就不能使用volatile變量。
volatile只能保證變量對(duì)各個(gè)線程的可見性,但不能保證原子性。
Java中的原子操作( atomic operations)
原子操作指的是在一步之內(nèi)就完成而且不能被中斷。原子操作在多線程環(huán)境中是線程安全的,無需考慮同步的問題。在java中,下列操作是原子操作:
all assignments of primitive types except for long and double all assignments of references all operations of java.concurrent.Atomic* classes all assignments to volatile longs and doubles
問題來了,為什么long型賦值不是原子操作呢?例如:
long foo = 65465498L;
實(shí)際上java會(huì)分兩步寫入這個(gè)long變量,先寫32位,再寫后32位。這樣就線程不安全了。如果改成下面的就線程安全了:
private volatile long foo;
因?yàn)?volatile 內(nèi)部已經(jīng)做了 synchronized。
CAS無鎖算法
要實(shí)現(xiàn)無鎖(lock-free)的非阻塞算法有多種實(shí)現(xiàn)方法,其中CAS(比較與交換,Compare and swap)是一種有名的無鎖算法。CAS, CPU指令,在大多數(shù)處理器架構(gòu),包括IA32、Space中采用的都是CAS指令,CAS的語義是“我認(rèn)為V的值應(yīng)該為A,如果是,那么將V的值更新為B,否則不修改并告訴V的值實(shí)際為多少”,CAS是項(xiàng)樂觀鎖技術(shù),當(dāng)多個(gè)線程嘗試使用CAS同時(shí)更新同一個(gè)變量時(shí),只有其中一個(gè)線程能更新變量的值,而其它線程都失敗,失敗的線程并不會(huì)被掛起,而是被告知這次競爭中失敗,并可以再次嘗試。CAS有3個(gè)操作數(shù),內(nèi)存值V,舊的預(yù)期值A(chǔ),要修改的新值B。當(dāng)且僅當(dāng)預(yù)期值A(chǔ)和內(nèi)存值V相同時(shí),將內(nèi)存值V修改為B,否則什么都不做。CAS無鎖算法的C實(shí)現(xiàn)如下:
int compare_and_swap (int* reg, int oldval, int newval)
{
ATOMIC();
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
END_ATOMIC();
return old_reg_val;
}
CAS(樂觀鎖算法)的基本假設(shè)前提
CAS比較與交換的偽代碼可以表示為:
do{
備份舊數(shù)據(jù);
基于舊數(shù)據(jù)構(gòu)造新數(shù)據(jù);
}while(!CAS( 內(nèi)存地址,備份的舊數(shù)據(jù),新數(shù)據(jù) ))
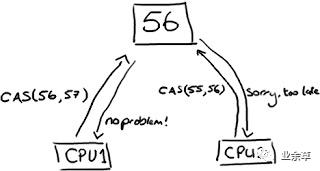
(上圖的解釋:CPU去更新一個(gè)值,但如果想改的值不再是原來的值,操作就失敗,因?yàn)楹苊黠@,有其它操作先改變了這個(gè)值。)
就是指當(dāng)兩者進(jìn)行比較時(shí),如果相等,則證明共享數(shù)據(jù)沒有被修改,替換成新值,然后繼續(xù)往下運(yùn)行;如果不相等,說明共享數(shù)據(jù)已經(jīng)被修改,放棄已經(jīng)所做的操作,然后重新執(zhí)行剛才的操作。容易看出 CAS 操作是基于共享數(shù)據(jù)不會(huì)被修改的假設(shè),采用了類似于數(shù)據(jù)庫的 commit-retry 的模式。當(dāng)同步?jīng)_突出現(xiàn)的機(jī)會(huì)很少時(shí),這種假設(shè)能帶來較大的性能提升。
CAS的開銷(CPU Cache Miss problem)
前面說過了,CAS(比較并交換)是CPU指令級(jí)的操作,只有一步原子操作,所以非常快。而且CAS避免了請(qǐng)求操作系統(tǒng)來裁定鎖的問題,不用麻煩操作系統(tǒng),直接在CPU內(nèi)部就搞定了。但CAS就沒有開銷了嗎?不!有cache miss的情況。這個(gè)問題比較復(fù)雜,首先需要了解CPU的硬件體系結(jié)構(gòu):
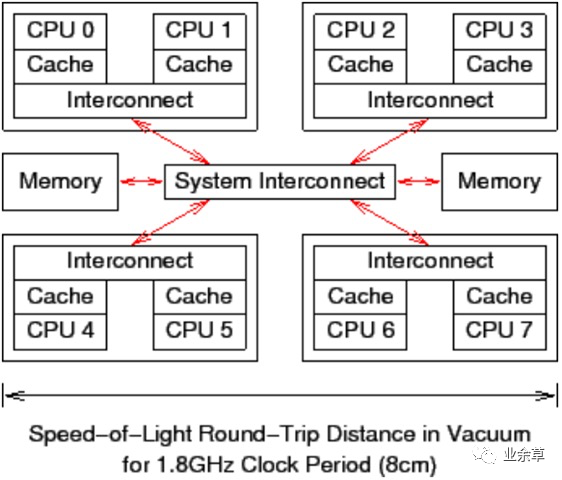
上圖可以看到一個(gè)8核CPU計(jì)算機(jī)系統(tǒng),每個(gè)CPU有cache(CPU內(nèi)部的高速緩存,寄存器),管芯內(nèi)還帶有一個(gè)互聯(lián)模塊,使管芯內(nèi)的兩個(gè)核可以互相通信。在圖中央的系統(tǒng)互聯(lián)模塊可以讓四個(gè)管芯相互通信,并且將管芯與主存連接起來。數(shù)據(jù)以“緩存線”為單位在系統(tǒng)中傳輸,“緩存線”對(duì)應(yīng)于內(nèi)存中一個(gè) 2 的冪大小的字節(jié)塊,大小通常為 32 到 256 字節(jié)之間。當(dāng) CPU 從內(nèi)存中讀取一個(gè)變量到它的寄存器中時(shí),必須首先將包含了該變量的緩存線讀取到 CPU 高速緩存。同樣地,CPU 將寄存器中的一個(gè)值存儲(chǔ)到內(nèi)存時(shí),不僅必須將包含了該值的緩存線讀到 CPU 高速緩存,還必須確保沒有其他 CPU 擁有該緩存線的拷貝。
比如,如果 CPU0 在對(duì)一個(gè)變量執(zhí)行“比較并交換”(CAS)操作,而該變量所在的緩存線在 CPU7 的高速緩存中,就會(huì)發(fā)生以下經(jīng)過簡化的事件序列:
CPU0 檢查本地高速緩存,沒有找到緩存線。 請(qǐng)求被轉(zhuǎn)發(fā)到 CPU0 和 CPU1 的互聯(lián)模塊,檢查 CPU1 的本地高速緩存,沒有找到緩存線。 請(qǐng)求被轉(zhuǎn)發(fā)到系統(tǒng)互聯(lián)模塊,檢查其他三個(gè)管芯,得知緩存線被 CPU6和 CPU7 所在的管芯持有。 請(qǐng)求被轉(zhuǎn)發(fā)到 CPU6 和 CPU7 的互聯(lián)模塊,檢查這兩個(gè) CPU 的高速緩存,在 CPU7 的高速緩存中找到緩存線。 CPU7 將緩存線發(fā)送給所屬的互聯(lián)模塊,并且刷新自己高速緩存中的緩存線。 CPU6 和 CPU7 的互聯(lián)模塊將緩存線發(fā)送給系統(tǒng)互聯(lián)模塊。 系統(tǒng)互聯(lián)模塊將緩存線發(fā)送給 CPU0 和 CPU1 的互聯(lián)模塊。 CPU0 和 CPU1 的互聯(lián)模塊將緩存線發(fā)送給 CPU0 的高速緩存。 CPU0 現(xiàn)在可以對(duì)高速緩存中的變量執(zhí)行 CAS 操作了
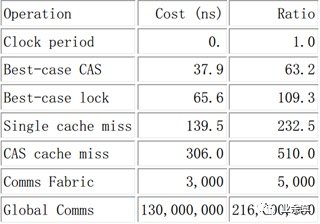
以上是刷新不同CPU緩存的開銷。最好情況下的 CAS 操作消耗大概 40 納秒,超過 60 個(gè)時(shí)鐘周期。這里的“最好情況”是指對(duì)某一個(gè)變量執(zhí)行 CAS 操作的 CPU 正好是最后一個(gè)操作該變量的CPU,所以對(duì)應(yīng)的緩存線已經(jīng)在 CPU 的高速緩存中了,類似地,最好情況下的鎖操作(一個(gè)“round trip 對(duì)”包括獲取鎖和隨后的釋放鎖)消耗超過 60 納秒,超過 100 個(gè)時(shí)鐘周期。這里的“最好情況”意味著用于表示鎖的數(shù)據(jù)結(jié)構(gòu)已經(jīng)在獲取和釋放鎖的 CPU 所屬的高速緩存中了。鎖操作比 CAS 操作更加耗時(shí),是因?yàn)殒i操作的數(shù)據(jù)結(jié)構(gòu)中需要兩個(gè)原子操作。緩存未命中消耗大概 140 納秒,超過 200 個(gè)時(shí)鐘周期。需要在存儲(chǔ)新值時(shí)查詢變量的舊值的 CAS 操作,消耗大概 300 納秒,超過 500 個(gè)時(shí)鐘周期。想想這個(gè),在執(zhí)行一次 CAS 操作的時(shí)間里,CPU 可以執(zhí)行 500 條普通指令。這表明了細(xì)粒度鎖的局限性。
以下是cache miss cas 和lock的性能對(duì)比:
JVM對(duì)CAS的支持
JVM對(duì)CAS的支持:AtomicInt,AtomicLong.incrementAndGet()等。
在JDK1.5之前,如果不編寫明確的代碼就無法執(zhí)行CAS操作,在JDK1.5中引入了底層的支持,在int、long和對(duì)象的引用等類型上都公開了CAS的操作,并且JVM把它們編譯為底層硬件提供的最有效的方法,在運(yùn)行CAS的平臺(tái)上,運(yùn)行時(shí)把它們編譯為相應(yīng)的機(jī)器指令,如果處理器/CPU不支持CAS指令,那么JVM將使用自旋鎖。因此,值得注意的是,CAS解決方案與平臺(tái)/編譯器緊密相關(guān)(比如x86架構(gòu)下其對(duì)應(yīng)的匯編指令是lock cmpxchg,如果想要64Bit的交換,則應(yīng)使用lock cmpxchg8b。在.NET中我們可以使用Interlocked.CompareExchange函數(shù))。
在原子類變量中,如java.util.concurrent.atomic中的AtomicXXX,都使用了這些底層的JVM支持為數(shù)字類型的引用類型提供一種高效的CAS操作,而在java.util.concurrent中的大多數(shù)類在實(shí)現(xiàn)時(shí)都直接或間接的使用了這些原子變量類。
Java 中AtomicLong.incrementAndGet()的實(shí)現(xiàn)源碼為:
public final long incrementAndGet() {
for (;;) {
long current = get();
long next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
由此可見,AtomicLong.incrementAndGet的實(shí)現(xiàn)用了樂觀鎖技術(shù),調(diào)用了sun.misc.Unsafe類庫里面的 CAS算法,用CPU指令來實(shí)現(xiàn)無鎖自增。所以,AtomicLong.incrementAndGet的自增比用synchronized的鎖效率倍增。
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
下面是測試代碼:
package console;
import java.util.concurrent.atomic.AtomicLong;
public class main {
/**
* @param args
*/
public static void main(String[] args) {
System.out.println("START -- ");
calc();
calcSynchro();
calcAtomic();
testThreadsSync();
testThreadsAtomic();
testThreadsSync2();
testThreadsAtomic2();
System.out.println("-- FINISHED ");
}
private static void calc() {
stopwatch sw = new stopwatch();
sw.start();
long val = 0;
while (val < 10000000L) {
val++;
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" calc() elapsed (ms): " + milSecds);
}
private static void calcSynchro() {
stopwatch sw = new stopwatch();
sw.start();
long val = 0;
while (val < 10000000L) {
synchronized (main.class) {
val++;
}
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" calcSynchro() elapsed (ms): " + milSecds);
}
private static void calcAtomic() {
stopwatch sw = new stopwatch();
sw.start();
AtomicLong val = new AtomicLong(0);
while (val.incrementAndGet() < 10000000L) {
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" calcAtomic() elapsed (ms): " + milSecds);
}
private static void testThreadsSync(){
stopwatch sw = new stopwatch();
sw.start();
Thread t1 = new Thread(new LoopSync());
t1.start();
Thread t2 = new Thread(new LoopSync());
t2.start();
while (t1.isAlive() || t2.isAlive()) {
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" testThreadsSync() 1 thread elapsed (ms): " + milSecds);
}
private static void testThreadsAtomic(){
stopwatch sw = new stopwatch();
sw.start();
Thread t1 = new Thread(new LoopAtomic());
t1.start();
Thread t2 = new Thread(new LoopAtomic());
t2.start();
while (t1.isAlive() || t2.isAlive()) {
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" testThreadsAtomic() 1 thread elapsed (ms): " + milSecds);
}
private static void testThreadsSync2(){
stopwatch sw = new stopwatch();
sw.start();
Thread t1 = new Thread(new LoopSync());
t1.start();
Thread t2 = new Thread(new LoopSync());
t2.start();
while (t1.isAlive() || t2.isAlive()) {
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" testThreadsSync() 2 threads elapsed (ms): " + milSecds);
}
private static void testThreadsAtomic2(){
stopwatch sw = new stopwatch();
sw.start();
Thread t1 = new Thread(new LoopAtomic());
t1.start();
Thread t2 = new Thread(new LoopAtomic());
t2.start();
while (t1.isAlive() || t2.isAlive()) {
}
sw.stop();
long milSecds = sw.getElapsedTime();
System.out.println(" testThreadsAtomic() 2 threads elapsed (ms): " + milSecds);
}
private static class LoopAtomic implements Runnable {
public void run() {
AtomicLong val = new AtomicLong(0);
while (val.incrementAndGet() < 10000000L) {
}
}
}
private static class LoopSync implements Runnable {
public void run() {
long val = 0;
while (val < 10000000L) {
synchronized (main.class) {
val++;
}
}
}
}
}
public class stopwatch {
private long startTime = 0;
private long stopTime = 0;
private boolean running = false;
public void start() {
this.startTime = System.currentTimeMillis();
this.running = true;
}
public void stop() {
this.stopTime = System.currentTimeMillis();
this.running = false;
}
public long getElapsedTime() {
long elapsed;
if (running) {
elapsed = (System.currentTimeMillis() - startTime);
} else {
elapsed = (stopTime - startTime);
}
return elapsed;
}
public long getElapsedTimeSecs() {
long elapsed;
if (running) {
elapsed = ((System.currentTimeMillis() - startTime) / 1000);
} else {
elapsed = ((stopTime - startTime) / 1000);
}
return elapsed;
}
// sample usage
// public static void main(String[] args) {
// StopWatch s = new StopWatch();
// s.start();
// //code you want to time goes here
// s.stop();
// System.out.println("elapsed time in milliseconds: " +
// s.getElapsedTime());
// }
}
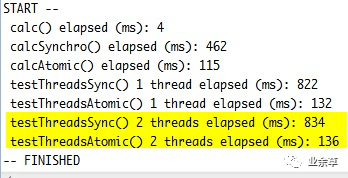
可以看到用AtomicLong.incrementAndGet的性能比用synchronized高出幾倍。
CAS的例子:非阻塞堆棧
下面是比非阻塞自增稍微復(fù)雜一點(diǎn)的CAS的例子:非阻塞堆棧/ConcurrentStack。ConcurrentStack 中的 push() 和 pop() 操作在結(jié)構(gòu)上與NonblockingCounter 上相似,只是做的工作有些冒險(xiǎn),希望在 “提交” 工作的時(shí)候,底層假設(shè)沒有失效。push() 方法觀察當(dāng)前最頂?shù)墓?jié)點(diǎn),構(gòu)建一個(gè)新節(jié)點(diǎn)放在堆棧上,然后,如果最頂端的節(jié)點(diǎn)在初始觀察之后沒有變化,那么就安裝新節(jié)點(diǎn)。如果 CAS 失敗,意味著另一個(gè)線程已經(jīng)修改了堆棧,那么過程就會(huì)重新開始。
public class ConcurrentStack<E> {
AtomicReference<Node<E>> head = new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = head.get();
newHead.next = oldHead;
} while (!head.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = head.get();
if (oldHead == null)
return null;
newHead = oldHead.next;
} while (!head.compareAndSet(oldHead,newHead));
return oldHead.item;
}
static class Node<E> {
final E item;
Node<E> next;
public Node(E item) { this.item = item; }
}
}
在輕度到中度的爭用情況下,非阻塞算法的性能會(huì)超越阻塞算法,因?yàn)?CAS 的多數(shù)時(shí)間都在第一次嘗試時(shí)就成功,而發(fā)生爭用時(shí)的開銷也不涉及線程掛起和上下文切換,只多了幾個(gè)循環(huán)迭代。沒有爭用的 CAS 要比沒有爭用的鎖便宜得多(這句話肯定是真的,因?yàn)闆]有爭用的鎖涉及 CAS 加上額外的處理),而爭用的 CAS 比爭用的鎖獲取涉及更短的延遲。
在高度爭用的情況下(即有多個(gè)線程不斷爭用一個(gè)內(nèi)存位置的時(shí)候),基于鎖的算法開始提供比非阻塞算法更好的吞吐率,因?yàn)楫?dāng)線程阻塞時(shí),它就會(huì)停止?fàn)幱茫托牡氐群蜉喌阶约海瑥亩苊饬诉M(jìn)一步爭用。但是,這么高的爭用程度并不常見,因?yàn)槎鄶?shù)時(shí)候,線程會(huì)把線程本地的計(jì)算與爭用共享數(shù)據(jù)的操作分開,從而給其他線程使用共享數(shù)據(jù)的機(jī)會(huì)。
CAS的例子:非阻塞鏈表
(自增計(jì)數(shù)器和堆棧)都是非常簡單的非阻塞算法,一旦掌握了在循環(huán)中使用 CAS,就可以容易地模仿它們。對(duì)于更復(fù)雜的數(shù)據(jù)結(jié)構(gòu),非阻塞算法要比這些簡單示例復(fù)雜得多,因?yàn)樾薷逆湵怼浠蚬1砜赡苌婕皩?duì)多個(gè)指針的更新。CAS 支持對(duì)單一指針的原子性條件更新,但是不支持兩個(gè)以上的指針。所以,要構(gòu)建一個(gè)非阻塞的鏈表、樹或哈希表,需要找到一種方式,可以用 CAS 更新多個(gè)指針,同時(shí)不會(huì)讓數(shù)據(jù)結(jié)構(gòu)處于不一致的狀態(tài)。
在鏈表的尾部插入元素,通常涉及對(duì)兩個(gè)指針的更新:“尾” 指針總是指向列表中的最后一個(gè)元素,“下一個(gè)” 指針從過去的最后一個(gè)元素指向新插入的元素。因?yàn)樾枰聝蓚€(gè)指針,所以需要兩個(gè) CAS。在獨(dú)立的 CAS 中更新兩個(gè)指針帶來了兩個(gè)需要考慮的潛在問題:如果第一個(gè) CAS 成功,而第二個(gè) CAS 失敗,會(huì)發(fā)生什么?如果其他線程在第一個(gè)和第二個(gè) CAS 之間企圖訪問鏈表,會(huì)發(fā)生什么?
對(duì)于非復(fù)雜數(shù)據(jù)結(jié)構(gòu),構(gòu)建非阻塞算法的 “技巧” 是確保數(shù)據(jù)結(jié)構(gòu)總處于一致的狀態(tài)(甚至包括在線程開始修改數(shù)據(jù)結(jié)構(gòu)和它完成修改之間),還要確保其他線程不僅能夠判斷出第一個(gè)線程已經(jīng)完成了更新還是處在更新的中途,還能夠判斷出如果第一個(gè)線程走向 AWOL,完成更新還需要什么操作。如果線程發(fā)現(xiàn)了處在更新中途的數(shù)據(jù)結(jié)構(gòu),它就可以 “幫助” 正在執(zhí)行更新的線程完成更新,然后再進(jìn)行自己的操作。當(dāng)?shù)谝粋€(gè)線程回來試圖完成自己的更新時(shí),會(huì)發(fā)現(xiàn)不再需要了,返回即可,因?yàn)?CAS 會(huì)檢測到幫助線程的干預(yù)(在這種情況下,是建設(shè)性的干預(yù))。
這種 “幫助鄰居” 的要求,對(duì)于讓數(shù)據(jù)結(jié)構(gòu)免受單個(gè)線程失敗的影響,是必需的。如果線程發(fā)現(xiàn)數(shù)據(jù)結(jié)構(gòu)正處在被其他線程更新的中途,然后就等候其他線程完成更新,那么如果其他線程在操作中途失敗,這個(gè)線程就可能永遠(yuǎn)等候下去。即使不出現(xiàn)故障,這種方式也會(huì)提供糟糕的性能,因?yàn)樾碌竭_(dá)的線程必須放棄處理器,導(dǎo)致上下文切換,或者等到自己的時(shí)間片過期(而這更糟)。
public class LinkedQueue <E> {
private static class Node <E> {
final E item;
final AtomicReference<Node<E>> next;
Node(E item, Node<E> next) {
this.item = item;
this.next = new AtomicReference<Node<E>>(next);
}
}
private AtomicReference<Node<E>> head
= new AtomicReference<Node<E>>(new Node<E>(null, null));
private AtomicReference<Node<E>> tail = head;
public boolean put(E item) {
Node<E> newNode = new Node<E>(item, null);
while (true) {
Node<E> curTail = tail.get();
Node<E> residue = curTail.next.get();
if (curTail == tail.get()) {
if (residue == null) /* A */ {
if (curTail.next.compareAndSet(null, newNode)) /* C */ {
tail.compareAndSet(curTail, newNode) /* D */ ;
return true;
}
} else {
tail.compareAndSet(curTail, residue) /* B */;
}
}
}
}
}
Java的ConcurrentHashMap的實(shí)現(xiàn)原理
從 Java5 中的 ConcurrentHashMap 開始,線程安全,設(shè)計(jì)巧妙,用桶粒度的鎖,避免了put和get中對(duì)整個(gè)map的鎖定,尤其在get中,只對(duì)一個(gè)HashEntry做鎖定操作,性能提升是顯而易見的。
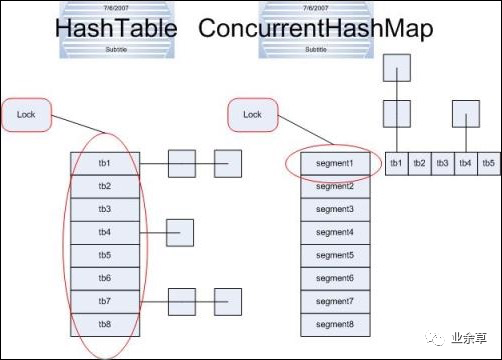
Java的ConcurrentLinkedQueue實(shí)現(xiàn)方法
ConcurrentLinkedQueue也是同樣使用了CAS指令,但其性能并不高因?yàn)橛刑郈AS操作。
高并發(fā)環(huán)境下優(yōu)化鎖或無鎖(lock-free)的設(shè)計(jì)思路
服務(wù)端編程的3大性能殺手:
大量線程導(dǎo)致的線程切換開銷。 鎖。 非必要的內(nèi)存拷貝。
在高并發(fā)下,對(duì)于純內(nèi)存操作來說,單線程是要比多線程快的(比如 redis 單線程)。可以比較一下多線程程序在壓力測試下cpu、內(nèi)存等百分比。
高并發(fā)環(huán)境下要實(shí)現(xiàn)高吞吐量和線程安全,兩個(gè)思路:一個(gè)是用優(yōu)化的鎖實(shí)現(xiàn),一個(gè)是lock-free的無鎖結(jié)構(gòu)。
但非阻塞算法要比基于鎖的算法復(fù)雜得多。開發(fā)非阻塞算法是相當(dāng)專業(yè)的訓(xùn)練,而且要證明算法的正確也極為困難,不僅和具體的目標(biāo)機(jī)器平臺(tái)和編譯器相關(guān),而且需要復(fù)雜的技巧和嚴(yán)格的測試。雖然Lock-Free編程非常困難,但是它通常可以帶來比基于鎖編程更高的吞吐量。所以Lock-Free編程是大有前途的技術(shù)。它在線程中止、優(yōu)先級(jí)倒置以及信號(hào)安全等方面都有著良好的表現(xiàn)。
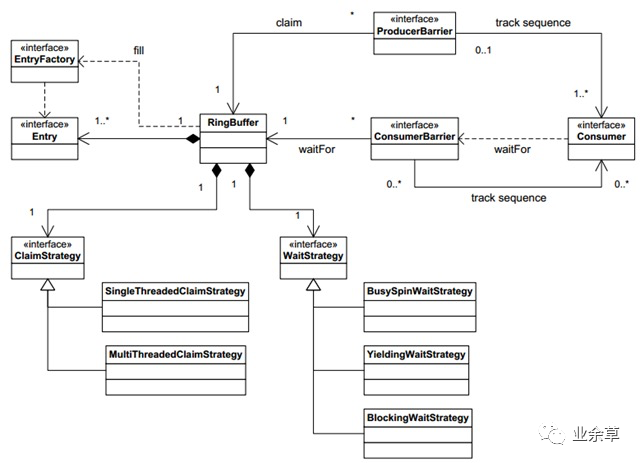
優(yōu)化鎖實(shí)現(xiàn)的例子:Java中的 ConcurrentHashMap,設(shè)計(jì)巧妙,用桶粒度的鎖和鎖分段(也有叫鎖分離)機(jī)制,避免了put和get中對(duì)整個(gè)map的鎖定,尤其在get中,只對(duì)一個(gè)HashEntry做鎖定操作,性能提升是顯而易見的。Lock-free無鎖的例子:CAS(CPU的Compare-And-Swap指令)的利用和LMAX的disruptor無鎖消息隊(duì)列數(shù)據(jù)結(jié)構(gòu)等。有興趣了解LMAX的disruptor無鎖消息隊(duì)列數(shù)據(jù)結(jié)構(gòu)。
disruptor無鎖消息隊(duì)列數(shù)據(jù)結(jié)構(gòu)的類圖。
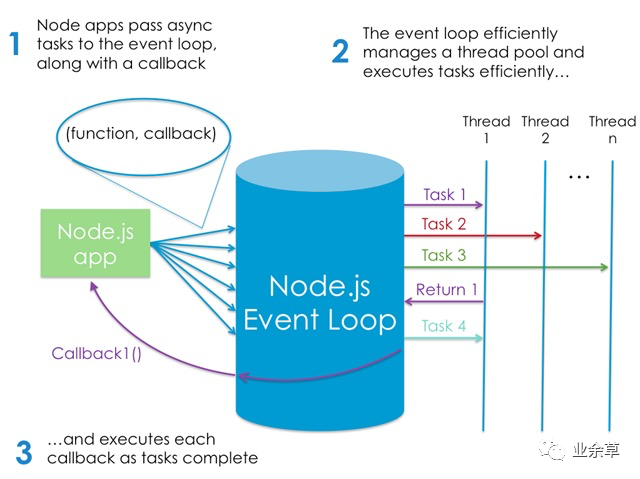
另外,在設(shè)計(jì)思路上除了盡量減少資源爭用以外,還可以借鑒 nginx、node.js 等單線程大循環(huán)的機(jī)制,用單線程或CPU數(shù)相同的線程開辟大的隊(duì)列,并發(fā)的時(shí)候任務(wù)壓入隊(duì)列,線程輪詢?nèi)缓笠粋€(gè)個(gè)順序執(zhí)行。由于每個(gè)都采用異步I/O,沒有阻塞線程。這個(gè)大隊(duì)列可以使用RabbitMQ Queue,或是JDK的同步隊(duì)列(性能稍差),或是使用Disruptor無鎖隊(duì)列(Java)。任務(wù)處理可以全部放在內(nèi)存(多級(jí)緩存、讀寫分離、ConcurrentHashMap、甚至分布式緩存Redis)中進(jìn)行增刪改查。最后用Quarz維護(hù)定時(shí)把緩存數(shù)據(jù)同步到DB中。當(dāng)然,這只是中小型系統(tǒng)的思路,如果是大型分布式系統(tǒng)會(huì)非常復(fù)雜,需要分而治理,用SOA的思路。(注:Redis是單線程的純內(nèi)存數(shù)據(jù)庫,單線程無需鎖,而Memcache是多線程的帶CAS算法,兩者都使用epoll,no-blocking io)
深入JVM的OS的無鎖非阻塞算法
如果深入 JVM 和操作系統(tǒng),會(huì)發(fā)現(xiàn)非阻塞算法無處不在。
垃圾收集器使用非阻塞算法加快并發(fā)和平行的垃圾搜集;調(diào)度器使用非阻塞算法有效地調(diào)度線程和進(jìn)程,實(shí)現(xiàn)內(nèi)在鎖。
基于鎖的 SynchronousQueue 算法被新的非阻塞版本代替。很少有開發(fā)人員會(huì)直接使用 SynchronousQueue,但是通過Executors.newCachedThreadPool()工廠構(gòu)建的線程池用它作為工作隊(duì)列。比較緩存線程池性能的對(duì)比測試顯示,新的非阻塞同步隊(duì)列實(shí)現(xiàn)提供了幾乎是之前實(shí)現(xiàn) 3 倍的速度。