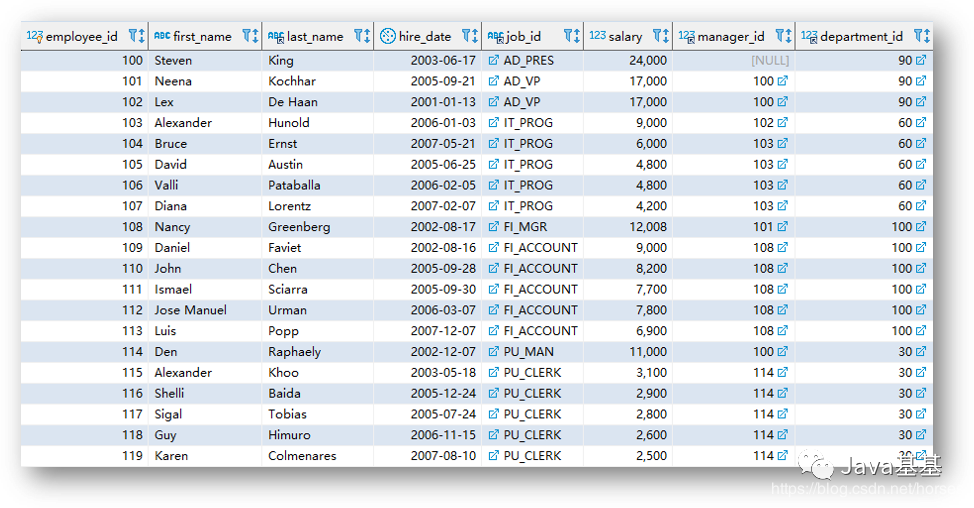
關系模型(Relational model)由 E.F.Codd 博士于 1970 年提出,以集合論中的關系概念為基礎;無論是現(xiàn)實世界中的實體對象還是它們之間的聯(lián)系都使用關系表示。我們在數(shù)據(jù)庫系統(tǒng)中看到的關系就是二維表(Table),由行(Row)和列(Column)組成。因此,也可以說關系表是由數(shù)據(jù)行構成的集合。
關系模型由數(shù)據(jù)結(jié)構、關系操作、完整性約束三部分組成。- 關系模型中的數(shù)據(jù)結(jié)構就是關系表,包括基礎表、派生表(查詢結(jié)果)和虛擬表(視圖)。
- 常用的關系操作包括增加、刪除、修改和查詢(CRUD),使用的就是
SQL
語言。其中查詢操作最為復雜,包括選擇(Selection)、投影(Projection)、并集(Union)、交集(Intersection)、差集(Exception)以及笛卡兒積(Cartesian
product)等。
- 完整性約束用于維護數(shù)據(jù)的完整性或者滿足業(yè)務約束的需求,包括實體完整性(主鍵約束)、參照完整性(外鍵約束)以及用戶定義的完整性(非空約束、唯一約束、檢查約束和默認值)。
我們今天的主題是關系操作語言,也就是 SQL。本文使用的示例數(shù)據(jù)來源于https://blog.csdn.net/horses/article/details/86518676。面向集合
SQL(結(jié)構化查詢語言)是操作關系數(shù)據(jù)庫的標準語言。SQL
非常接近英語,使用起來非常簡單。它在設計之初就考慮了非技術人員的使用需求,我們通常只需說明想要的結(jié)果(What),而將數(shù)據(jù)處理的過程(How)交給數(shù)據(jù)庫管理系統(tǒng)。所以說,SQL
才是真正給人用的編程語言!接下來我們具體分析一下關系的各種操作語句;目的是為了讓大家能夠了解 SQL 是一種面向集合的編程語言,它的操作對象是集合,操作的結(jié)果也是集合。在關系數(shù)據(jù)庫中,關系、表、集合三者通常表示相同的概念。
SELECT
SELECT?employee_id, first_name, last_name, hire_date
??FROM?employees;
它的作用就是從 employees 表中查詢員工信息。顯然,我們都知道 FROM 之后是一個表(關系、集合)。不僅如此,整個查詢語句的結(jié)果也是一個表。所以,我們可以將上面的查詢作為表使用:SELECT?*
??FROM?(SELECT?employee_id, first_name, last_name, hire_date
??????????FROM?employees) t;
括號內(nèi)的查詢語句被稱為派生表,我們給它指定了一個別名叫做 t。同樣,整個查詢結(jié)果也是一個表;這就意味著我們可以繼續(xù)嵌套,雖然這么做很無聊。-- PostgreSQL
SELECT?*
??FROM?upper('sql');
| upper |
|-------|
| SQL |
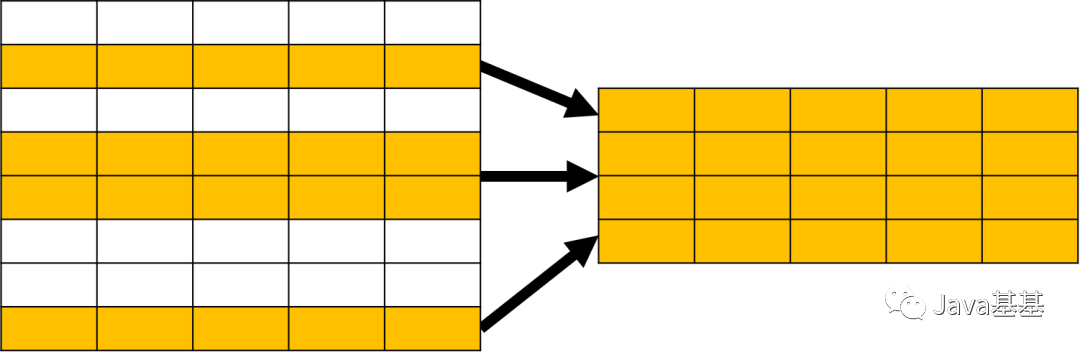
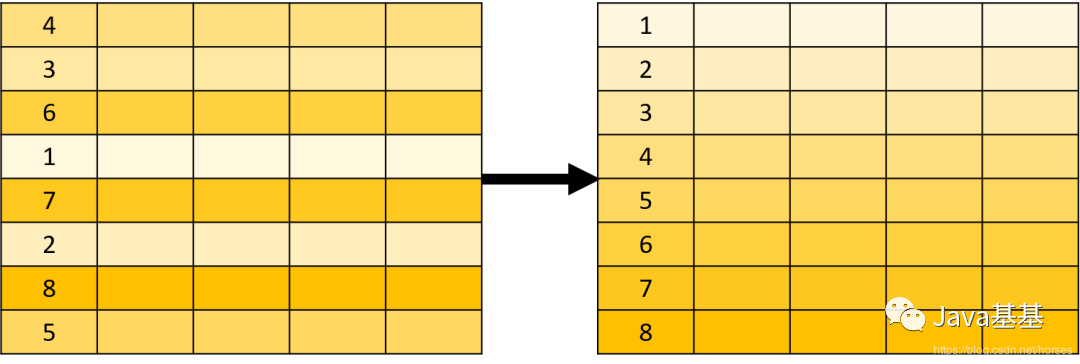
upper() 是一個大寫轉(zhuǎn)換的函數(shù)。它出現(xiàn)再 FROM 子句中,意味著它的結(jié)果也是一個表,只不過是 1 行 1 列的特殊表。SELECT 子句用于指定需要查詢的字段,可以包含表達式、函數(shù)值等。SELECT 在關系操作中被稱為投影(Projection),看下面的示意圖應該就比較好理解了。除了 SELECT 之外,還有一些常用的 SQL 子句。WHERE 用于指定數(shù)據(jù)過濾的條件,在關系運算中被稱為選擇(Selection),示意圖如下:ORDER BY 用于對查詢的結(jié)果進行排序,示意圖如下:總之,SQL 可以完成各種數(shù)據(jù)操作,例如過濾、分組、排序、限定數(shù)量等;所有這些操作的對象都是關系表,結(jié)果也是關系表。GROUP BY
分組( GROUP BY)操作和其他的關系操作不同,因為它改變了關系的結(jié)構。來看下面的示例:SELECT?department_id, count(*), first_name
??FROM?employees
?GROUP?BY?department_id;
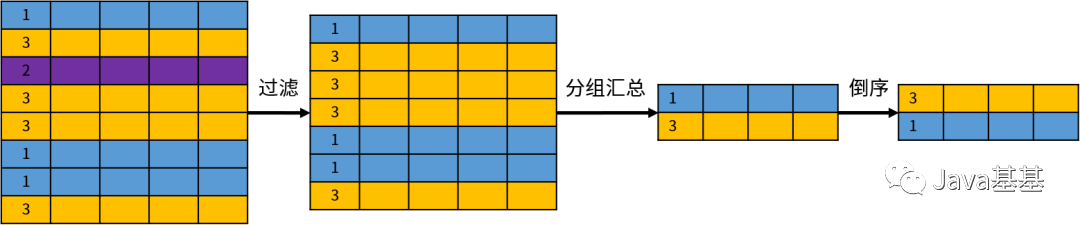
該語句的目的是按照部門統(tǒng)計員工的數(shù)量,但是存在一個語法錯誤,就是 first_name 不能出現(xiàn)在查詢列表中。原因在于按照部門進行分組的話,每個部門包含多個員工;無法確定需要顯示哪個員工的姓名,這是一個邏輯上的錯誤。所以說,GROUP BY 改變了集合元素(數(shù)據(jù)行)的結(jié)構,創(chuàng)建了一個全新的關系。分組操作的示意圖如下:盡管如此,GROUP BY 的結(jié)果仍然是一個集合。UNION
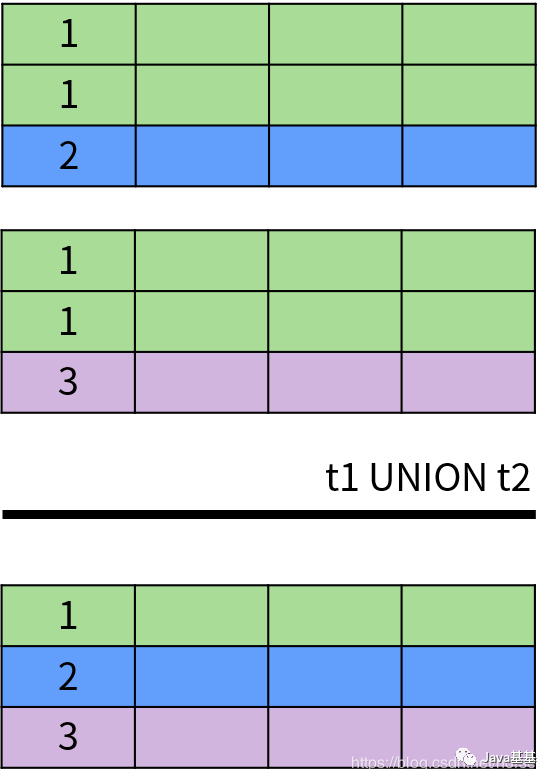
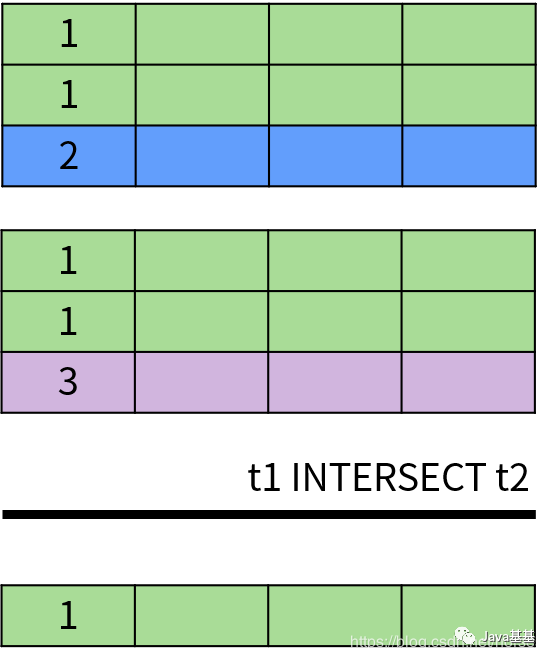
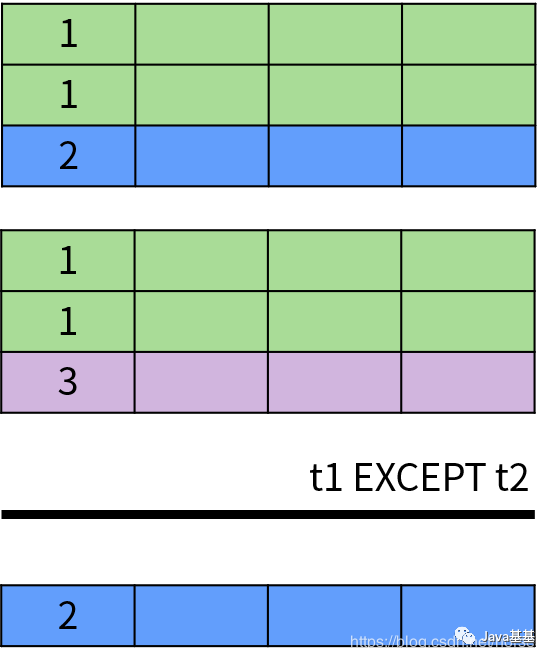
SQL 面向集合特性最明顯的體現(xiàn)就是 UNION(并集運算)、INTERSECT(交集運算)和 EXCEPT/MINUS(差集運算)。這些集合運算符的作用都是將兩個集合并成一個集合,因此需要滿足以下條件:具體來說,UNION 和 UNION ALL 用于計算兩個集合的并集,返回出現(xiàn)在第一個查詢結(jié)果或者第二個查詢結(jié)果中的數(shù)據(jù)。它們的區(qū)別在于 UNION 排除了結(jié)果中的重復數(shù)據(jù),UNION ALL 保留了重復數(shù)據(jù)。下面是 UNION 操作的示意圖:INTERSECT 操作符用于返回兩個集合中的共同部分,即同時出現(xiàn)在第一個查詢結(jié)果和第二個查詢結(jié)果中的數(shù)據(jù),并且排除了結(jié)果中的重復數(shù)據(jù)。INTERSECT 運算的示意圖如下:EXCEPT 或者 MINUS 操作符用于返回兩個集合的差集,即出現(xiàn)在第一個查詢結(jié)果中,但不在第二個查詢結(jié)果中的記錄,并且排除了結(jié)果中的重復數(shù)據(jù)。EXCEPT 運算符的示意圖如下:除此之外,DISTINCT 運算符用于消除重復數(shù)據(jù),也就是排除集合中的重復元素。SQL
中的關系概念來自數(shù)學中的集合理論,因此 UNION、INTERSECT 和 EXCEPT
分別來自集合論中的并集(∪\cup∪)、交集(∩\cap∩)和差集(?\setminus?)運算。需要注意的是,集合理論中的集合不允許存在重復的數(shù)據(jù),但是
SQL 允許。因此,SQL 中的集合也被稱為多重集合(multiset);多重集合與集合理論中的集合都是無序的,但是 SQL 可以通過
ORDER BY 子句對查詢結(jié)果進行排序。
JOIN
在 SQL 中,不僅實體對象存儲在關系表中,對象之間的聯(lián)系也存儲在關系表中。因此,當我們想要獲取這些相關的數(shù)據(jù)時,需要使用到另一個操作:連接查詢(JOIN)。常見的 SQL連接查類型包括內(nèi)連接、外連接、交叉連接等。其中,外連接又可以分為左外連接、右外連接以及全外連接。內(nèi)連接(Inner Join)返回兩個表中滿足連接條件的數(shù)據(jù),內(nèi)連接的原理如下圖所示:左外連接(Left Outer Join)返回左表中所有的數(shù)據(jù);對于右表,返回滿足連接條件的數(shù)據(jù);如果沒有就返回空值。左外連接的原理如下圖所示:右外連接(Right Outer Join)返回右表中所有的數(shù)據(jù);對于左表,返回滿足連接條件的數(shù)據(jù),如果沒有就返回空值。右外連接與左外連接可以互換,以下兩者等價:t1 RIGHT?JOIN t2
t2 LEFT?JOIN t1
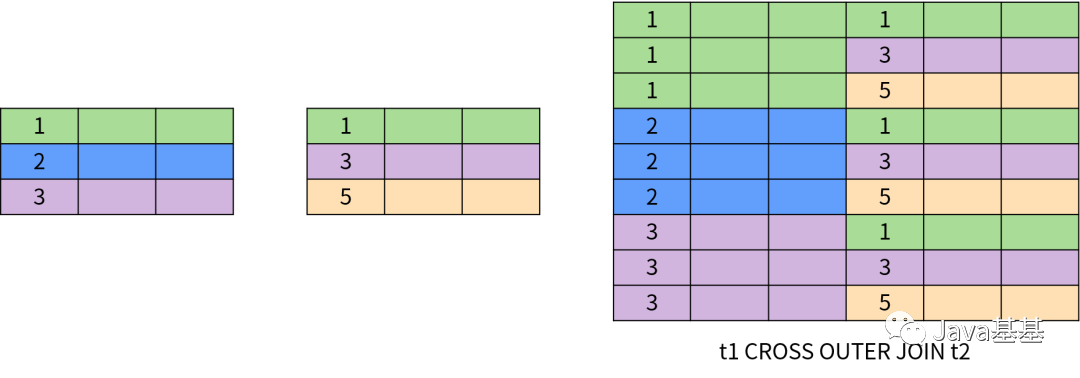
全外連接(Full Outer Join)等價于左外連接加上右外連接,同時返回左表和右表中所有的數(shù)據(jù);對于兩個表中不滿足連接條件的數(shù)據(jù)返回空值。全外連接的原理如下圖所示:交叉連接也稱為笛卡爾積(Cartesian Product)。兩個表的交叉連接相當于一個表的所有行和另一個表的所有行兩兩組合,結(jié)果的數(shù)量為兩個表的行數(shù)相乘。交叉連接的原理如下圖所示:其他類型的連接還有半連接(SEMI JOIN)、反連接(ANTI JOIN)。
集合操作將兩個集合合并成一個更大或更小的集合;連接查詢將兩個集合轉(zhuǎn)換成一個更大或更小的集合,同時獲得了一個更大的元素(更多的列)。很多時候集合操作都可以通過連接查詢來實現(xiàn),例如:SELECT?department_id
??FROM?departments
?UNION
SELECT?department_id
??FROM?employees;
SELECT?COALESCE(d.department_id, e.department_id)
??FROM?departments d
??FULL?JOIN?employees e ON?(e.department_id = d.department_id);
我們已經(jīng)介紹了許多查詢的示例,接下來看看其他的數(shù)據(jù)操作。DML
DML 表示數(shù)據(jù)操作語言,也就是插入、更新和刪除。以下是一個插入語句示例:CREATE?TABLE?test(id?int);
-- MySQL、SQL Server 等
INSERT?INTO?test(id) VALUES?(1),(2),(3);
-- Oracle
INSERT?INTO?test(id)
(SELECT?1?AS?id?FROM?DUAL
UNION?ALL
SELECT?2?FROM?DUAL
UNION?ALL
SELECT?3?FROM?DUAL);
我們通過一個 INSERT 語句插入了 3 條記錄,或者說是插入了一個包含 3 條記錄的關系表。因為,UNION ALL 返回的是一個關系表。VALUES 同樣是指定了一個關系表,在 SQL Server 和 PostgreSQL 中支持以下語句:SELECT?*
FROM?(
??VALUES(1),(2),(3)
) test(id);
前面我們已經(jīng)說過,F(xiàn)ROM 之后是一個關系表,所以這里的 VALUES 也是一樣。由于我們經(jīng)常插入單條記錄,并沒有意識到實際上是以表為單位進行操作。同樣,UPDATE 和 DELETE 語句也都是以關系表為單位的操作;只不過我們習慣了說更新一行數(shù)據(jù)或者刪除幾條記錄。