
最新OCR開源神器來了!
01
導(dǎo)讀
最近,由PaddleOCR原創(chuàng)團隊,針對PP-OCR進行了一些經(jīng)驗性改進,構(gòu)建了一種新的OCR系統(tǒng),稱為PP-OCRv2。
■ 從算法改進思路上看,主要有五個方面的改進。
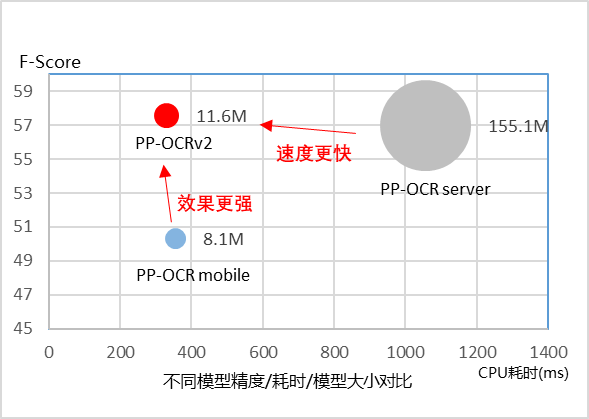
■ 從效果上看,主要有三個方面提升:
GitHub項目: https://github.com/PaddlePaddle/PaddleOCR
注:為了照顧剛了解PaddleOCR的新用戶,在第二、三部分簡單進行一些背景介紹,熟悉PaddleOCR的老用戶可以直接跳到第四部分。
02
PaddleOCR歷史表現(xiàn)回顧
? 2020年6月,8.6M超輕量模型發(fā)布,GitHub Trending 全球趨勢榜日榜第一。
? 2020年8月,開源CVPR2020頂會算法,再上GitHub趨勢榜單!
? 2020年10月,發(fā)布PP-OCR算法,開源3.5M超超輕量模型,再上Paperswithcode 趨勢榜第一!
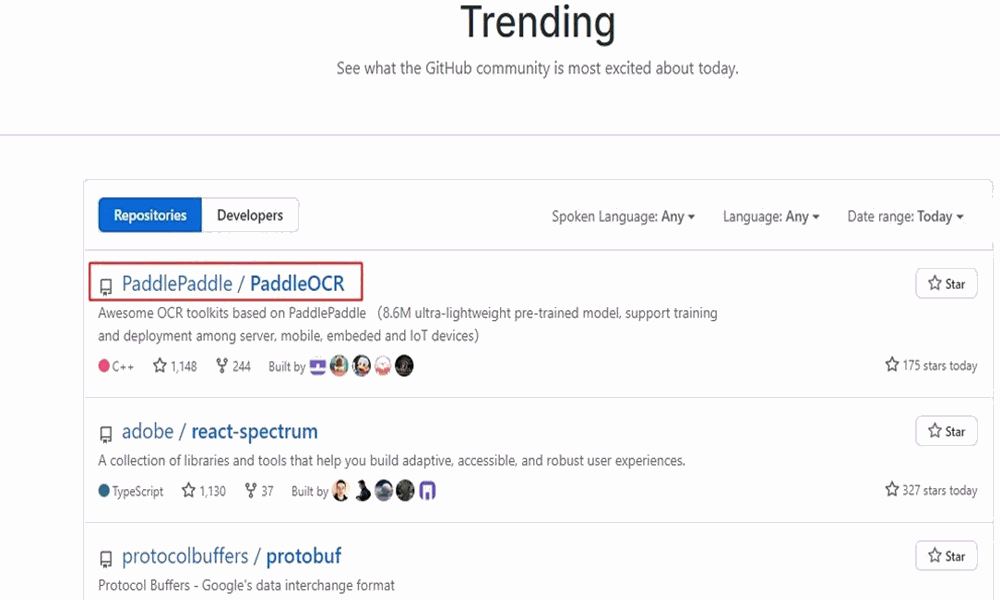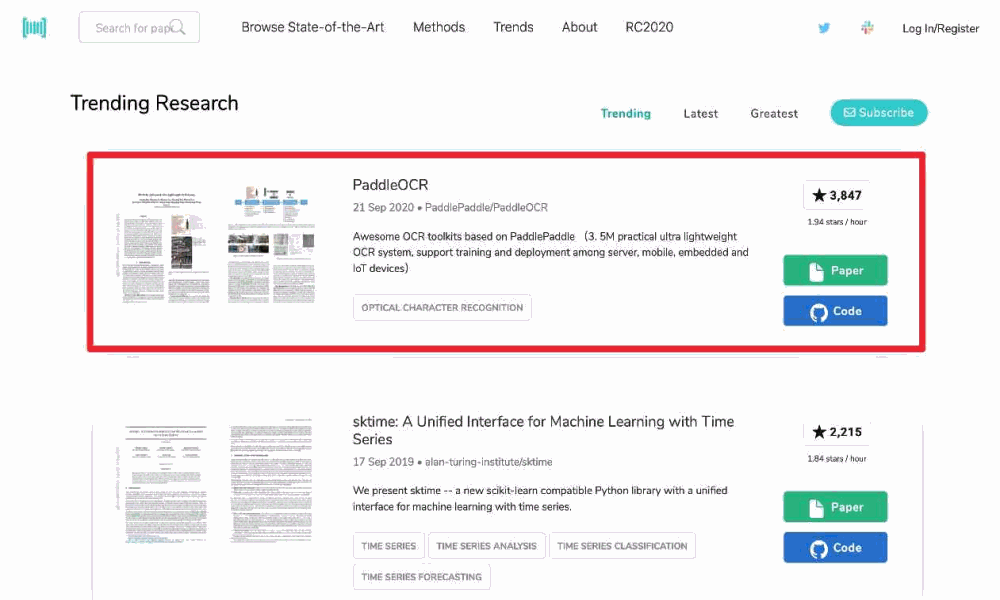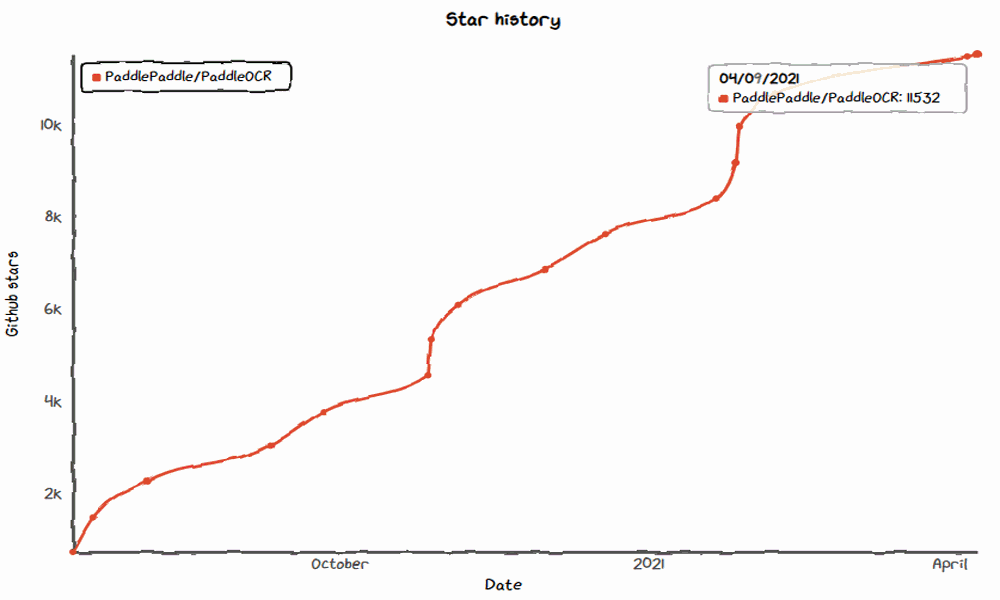
? 2021年1月,發(fā)布Style-Text文本合成算法和PPOCRLabel數(shù)據(jù)標注工具,star數(shù)量突破10000+,在《Github 2020數(shù)字洞察報告》中被評為中國Github Top20活躍項目。
? 2021年4月,開源AAAI頂會論文PGNet端到端識別算法,Star突破13k。
? 2021年8月,開源版面分析與表格識別算法PP-Structure,Star突破15k。
? 2021年9月,發(fā)布PP-OCRv2算法,效果和速度再升級。
03
PaddleOCR開源能力速覽
(1)通用文本檢測識別效果:支持通用場景下的OCR文本快速檢測識別

(2)文本合成工具Style-Text效果:相比于傳統(tǒng)的數(shù)據(jù)合成算法,Style-Text可以實現(xiàn)特殊背景下的圖片風格遷移,只需要少許目標場景圖像,就可以合成大量數(shù)據(jù),效果展示如下:

(3)半自動標注工具PPOCRLabel:通過內(nèi)置高質(zhì)量的PP-OCR中英文超輕量預(yù)訓(xùn)練模型,可以實現(xiàn)OCR數(shù)據(jù)的高效標注。CPU機器運行也是完全沒問題的。用法也是非常的簡單,標注效率提升60%-80%是妥妥的,效果演示如下:

(4)文檔結(jié)構(gòu)分析+表格提取PP-Structure:可以對文檔圖片中的文本、表格、圖片、標題與列表區(qū)域進行分類,還可以利用表格識別技術(shù)完整地提取表格結(jié)構(gòu)信息,使得表格圖片變?yōu)榭删庉嫷腅xcel文件。
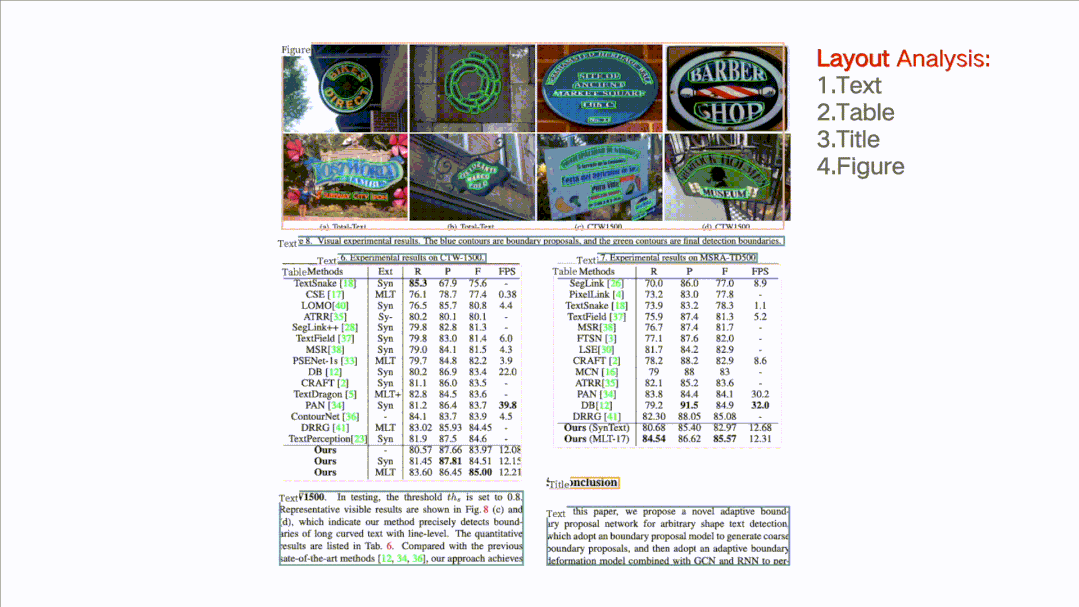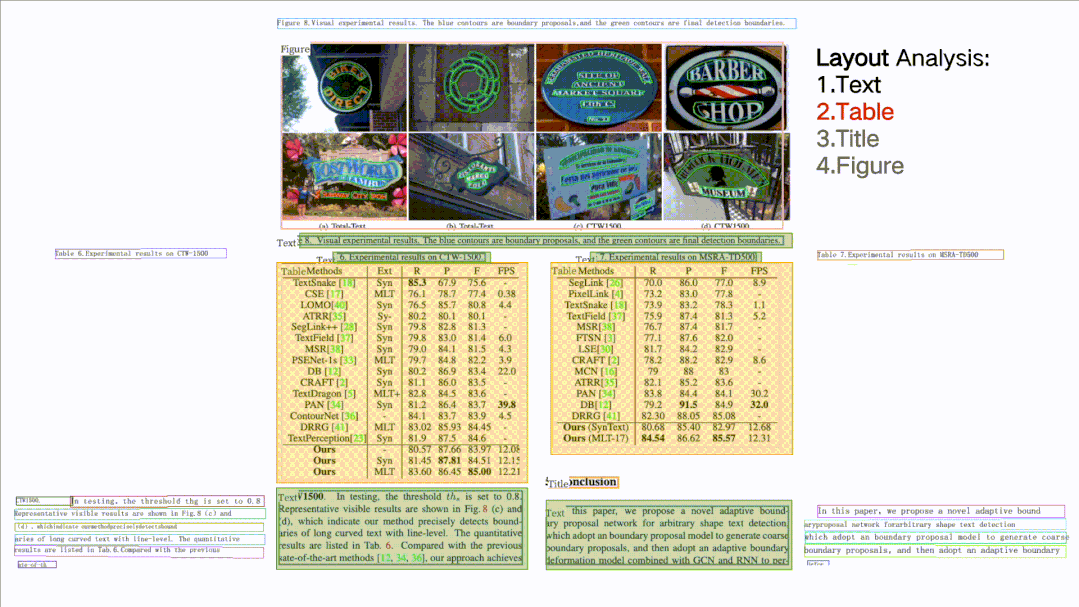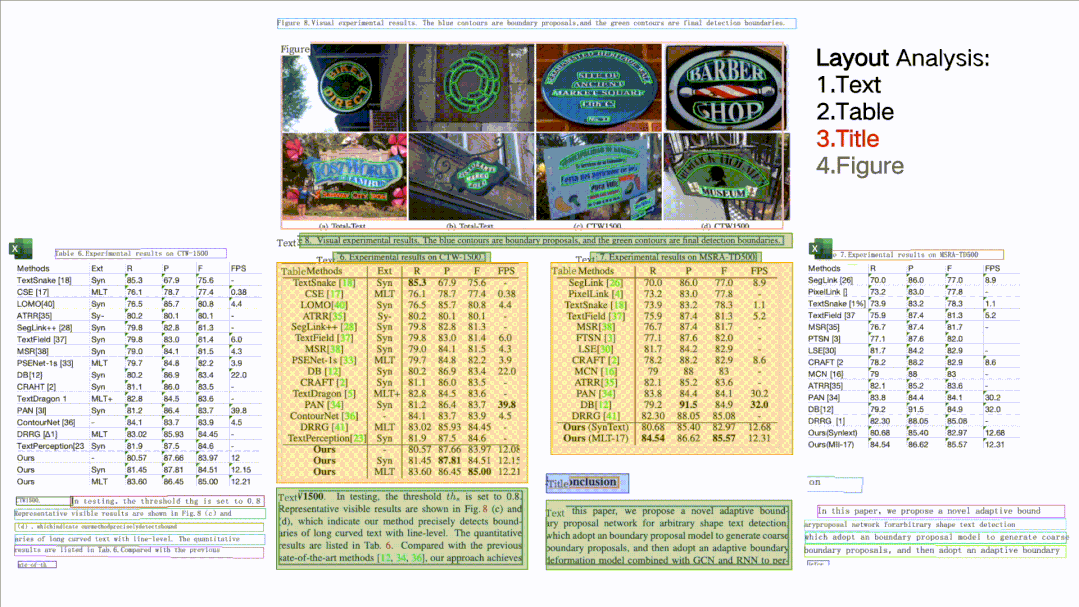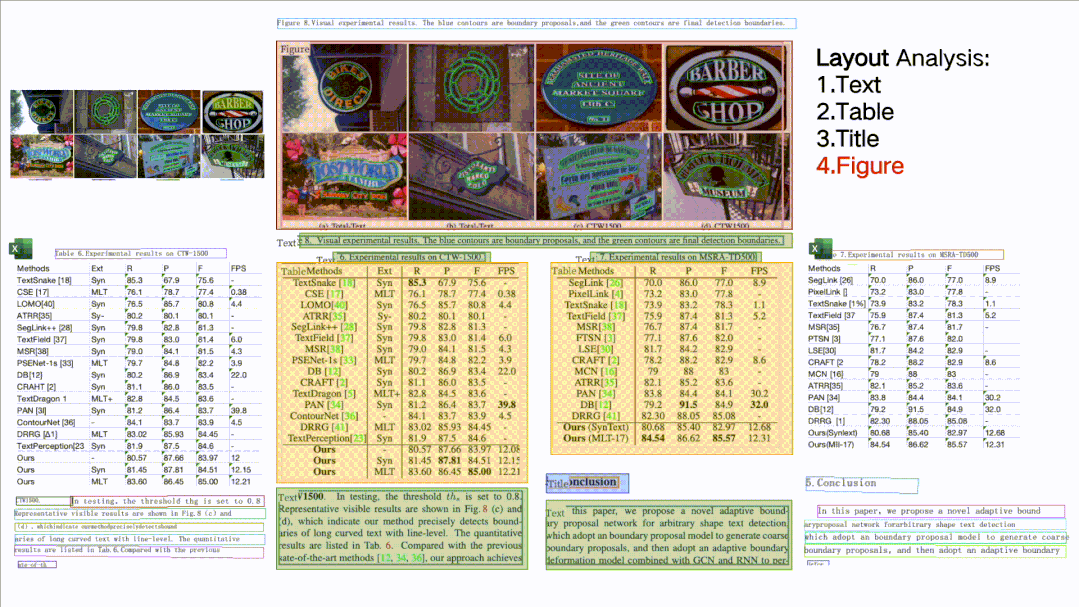

(5)核心能力全部可以自定義訓(xùn)練,動靜統(tǒng)一的開發(fā)體驗
動態(tài)圖和靜態(tài)圖是深度學習框架常用的兩種模式。在動態(tài)圖模式下,代碼編寫運行方式符合Python程序員的習慣,易于調(diào)試,但在性能方面, Python執(zhí)行開銷較大,與C++有一定差距。相比動態(tài)圖,靜態(tài)圖在部署方面更具有性能的優(yōu)勢。靜態(tài)圖程序在編譯執(zhí)行時,預(yù)先搭建好的神經(jīng)網(wǎng)絡(luò)可以脫離Python依賴,在C++端被重新解析執(zhí)行,而且擁有整體網(wǎng)絡(luò)結(jié)構(gòu)也能進行一些網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)化。
傳送門:
Github:https://github.com/PaddlePaddle/PaddleOCR
那么最近的2021年9月份更新,PaddleOCR又給大家?guī)砟男@喜呢?
04
PP-OCRv2五大關(guān)鍵技術(shù)點深入解讀:
全新升級的PP-OCRv2版本,整體的框架圖保持了與PP-OCR相同的Pipeline,如下圖所示。

在優(yōu)化策略方面,主要從五個角度進行了深入優(yōu)化(如上圖紅框所示),主要包括:
■ 檢測模型優(yōu)化:采用CML知識蒸餾策略
■ 檢測模型優(yōu)化:CopyPaste數(shù)據(jù)增廣策略
■ 識別模型優(yōu)化:LCNet輕量級骨干網(wǎng)絡(luò)
■ 識別模型優(yōu)化:UDML 知識蒸餾策略
■ 識別模型優(yōu)化:Enhanced CTC loss 改進
下面展開詳細介紹:
(1) 檢測模型優(yōu)化:采用CML (Collaborative Mutual Learning) 協(xié)同互學習知識蒸餾策略。
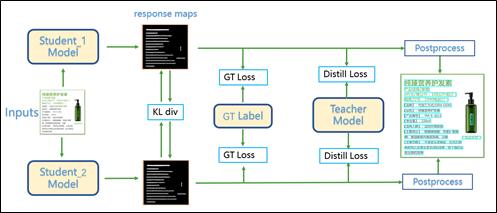
如上圖所示,CML的核心思想結(jié)合了①傳統(tǒng)的Teacher指導(dǎo)Student的標準蒸餾與 ②Students網(wǎng)絡(luò)直接的DML互學習,可以讓Students網(wǎng)絡(luò)互學習的同時,Teacher網(wǎng)絡(luò)予以指導(dǎo)。對應(yīng)的,精心設(shè)計關(guān)鍵的三個Loss損失函數(shù):GT Loss、DML Loss和Distill Loss,在Teacher網(wǎng)絡(luò)Backbone為ResNet18的條件下,對Student的MobileNetV3起到了良好的提升效果。
(2) 檢測模型優(yōu)化:CopyPaste數(shù)據(jù)增廣策略

數(shù)據(jù)增廣是提升模型泛化能力重要的手段之一,CopyPaste 是一種新穎的數(shù)據(jù)增強技巧,已經(jīng)在目標檢測和實例分割任務(wù)中驗證了有效性。利用CopyPaste,可以合成文本實例來平衡訓(xùn)練圖像中的正負樣本之間的比例。相比而言,傳統(tǒng)圖像旋轉(zhuǎn)、隨機翻轉(zhuǎn)和隨機裁剪是無法做到的。CopyPaste主要步驟包括:①隨機選擇兩幅訓(xùn)練圖像,②隨機尺度抖動縮放,③隨機水平翻轉(zhuǎn),④隨機選擇一幅圖像中的目標子集,⑤粘貼在另一幅圖像中隨機的位置。這樣,就比較好的提升了樣本豐富度,同時也增加了模型對環(huán)境魯棒性。
經(jīng)過以上兩個檢測方向的優(yōu)化策略,PP-OCRv2檢測部分的實驗效果如下:

(3) 識別模型優(yōu)化:LCNet輕量級骨干網(wǎng)絡(luò)

這里,PP-OCRv2的研發(fā)團隊提出了一種基于MobileNetV1改進的新的骨干網(wǎng)絡(luò)LCNet,主要的改動包括:
①除SE模塊,網(wǎng)絡(luò)中所有的relu替換為h-swish,精度提升1%-2%
②LCNet第五階段,DW的kernel size變?yōu)?x5,精度提升0.5%-1%
③LCNet第五階段的最后兩個DepthSepConv block添加SE模塊, 精度提升0.5%-1%
④GAP后添加1280維的FC層,增加特征表達能力,精度提升2%-3%
(4) 識別模型優(yōu)化:UDML 知識蒸餾策略
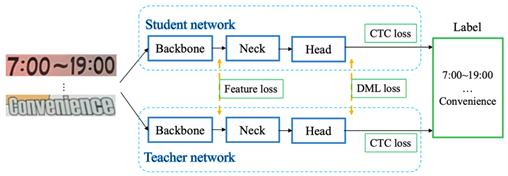
在標準的DML知識蒸餾的基礎(chǔ)上,新增引入了對于Feature Map的監(jiān)督機制,新增Feature Loss,增加迭代次數(shù),在Head部分增加額外的FC網(wǎng)絡(luò),最終加快蒸餾的速度同時提升效果。
(5) 識別模型優(yōu)化:Enhanced CTC loss 改進

考慮到中文OCR任務(wù)經(jīng)常遇到的識別難點是相似字符數(shù)太多,容易誤識,借鑒Metric Learning的想法,引入Center Loss,進一步增大類間距離,核心思路如上圖公式所示。
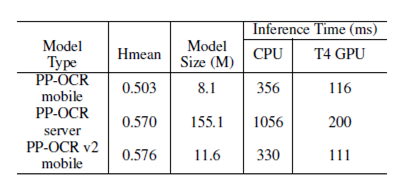
經(jīng)過以上三個識別方向的優(yōu)化策略,PP-OCRv2識別部分的實驗效果如下:

經(jīng)過以上五個方向的優(yōu)化,最終PP-OCRv2僅以少量模型大小增加的代價,全面超越PP-OCR,取得了良好的效果。
05
良心出品的中英文文檔教程
隨著本次PP-OCRv2升級,PaddleOCR的項目文檔也全面升級,結(jié)構(gòu)更清晰,內(nèi)容更豐富。


開源地址:https://github.com/PaddlePaddle/PaddleOCR
06
相關(guān)學習
9月8日晚20:15-21:30,百度高級研發(fā)工程師將為我們詳細解析速度與精度都大幅提升的PaddleOCR,感興趣的同學可以一起學習!
掃描二維碼,加入交流群