
杭州-螞蟻金服最新面試題匯總

螞蟻金服面試題
1.jdk1.7 到 jdk1.8 Map 發(fā)生了什么變化(底層)?
1.8 之后 hashMap 的數(shù)據(jù)結(jié)構(gòu)發(fā)生了變化,從之前的單純的數(shù)組+鏈表結(jié)構(gòu)變成數(shù)組+鏈 表+紅黑樹。也就是說在 JVM 存儲(chǔ) hashMap 的 K-V 時(shí)僅僅通過 key 來決定每一個(gè) entry 的存 儲(chǔ)槽位(Node[]中的 index)。并且 Value 以鏈表的形式掛在到對(duì)應(yīng)槽位上(1.8 以后如果 value 長度大于 8 則轉(zhuǎn)為紅黑樹)。但是 hashmap1.7 跟 1.8 中都沒有任何同步操作,容易出現(xiàn)并發(fā)問題,甚至出現(xiàn)死循環(huán) 導(dǎo)致系統(tǒng)不可用。解決方案是 jdk 的 ConcurrentHashMap,位于 java.util.concurrent 下,專門 解決并發(fā)問題。
2. ConcurrentHashMap 思路與 hashMap 差不多,但是支持并發(fā)操作,要復(fù)雜很多?
3. 并行跟并發(fā)有什么區(qū)別??
并發(fā):指應(yīng)用交替執(zhí)行不同的任務(wù),多線程原理?
并行:指應(yīng)用同時(shí)執(zhí)行不用的任務(wù)?
區(qū)別:一個(gè)是交替執(zhí)行,一個(gè)是同時(shí)執(zhí)行。
4. jdk1.7 到 jdk1.8 java 虛擬機(jī)發(fā)生了什么變化?
JVM 中內(nèi)存份為堆、棧內(nèi)存,及方法區(qū)。
棧內(nèi)存主要用途:執(zhí)行線程方法,存放本地臨時(shí)變量與線程方法執(zhí)行是需要的引用對(duì)象 的地址。
堆內(nèi)存主要用途:JVM 中所有對(duì)象信息都存放在堆內(nèi)存中,相比棧內(nèi)存,堆內(nèi)存大很多 所以 JVM 一直通過對(duì)堆內(nèi)存劃分不同功能區(qū)塊實(shí)現(xiàn)對(duì)堆內(nèi)存中對(duì)象管理。?
堆內(nèi)存不夠常見錯(cuò)誤:OutOfMemoryError?
棧內(nèi)存溢出常見錯(cuò)誤:StackOverFlowError?
在 JDK7 以及其前期的 JDK 版本中,堆內(nèi)存通常被分為三塊區(qū)域 Nursery 內(nèi)存(young generation)、長時(shí)內(nèi)存(old generation)、永久內(nèi)存(Permanent Generation for VM Matedata), 顯示如下圖:
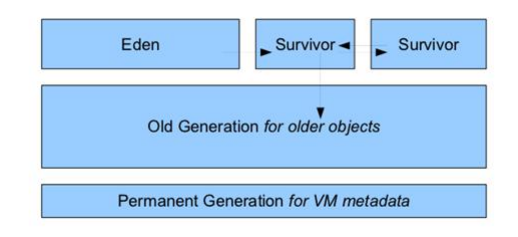
在最上面一層是 Nursery 內(nèi)存,一個(gè)對(duì)象被創(chuàng)建以后首先被房到 Nuersery 中的 Eden 內(nèi) 存中,如果存活周期超過兩個(gè) Survivor(生存周期)之后會(huì)被轉(zhuǎn)移到 Old Generation 中。?
永久內(nèi)存中存放對(duì)象的方法、變量等元數(shù)據(jù)信息。永久內(nèi)存不夠就會(huì)出現(xiàn) 以下錯(cuò)誤:java.lang.OutOfMemoryError:PermGen?
但是在 JDK1.8 中一般都不會(huì)得到這個(gè)錯(cuò)誤,原因在于:1.8 中把存放元數(shù)據(jù)的永久內(nèi)存 從堆內(nèi)存中已到了本地內(nèi)存(native Memory)中,1.8 中 JVM 內(nèi)存結(jié)構(gòu)變成了如下圖:
????
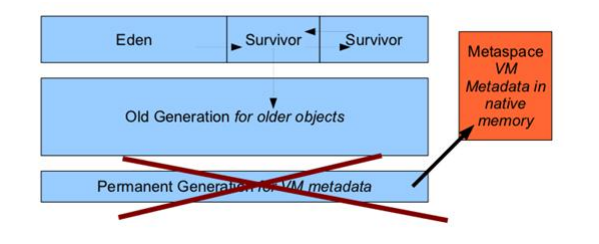
這樣永久內(nèi)存就不占用堆內(nèi)存,可以通過自增長來避免永久內(nèi)存錯(cuò)誤。
-XX:MaxMetaspaceSize=128m 這只最大的遠(yuǎn)內(nèi)存空間 128 兆?
JDK1.8 移除 PermGen,取而代之的是 MetaSpace 源空間?
MetaSpace 垃圾回收:對(duì)僵死的類及類加載器的垃圾回收機(jī)制昂在元數(shù)據(jù)使用達(dá)到 “MaxMetaSpaceSize”參數(shù)的設(shè)定值時(shí)運(yùn)行。?
MetaSpace 監(jiān)控:元空間的使用情況可以在 HotSpot1.8 的詳細(xì) GC 日志輸出中得到。?
更新 JDK1.8 的原因:
字符串存在永久代當(dāng)中,容易出現(xiàn)性能問題和內(nèi)存溢出
類及方法的信息比較難確定其大小,因此對(duì)永久代的大小制定比較困難,太小容易出 現(xiàn)永久代溢出,太大則容易導(dǎo)致老年代溢出。
永久代會(huì)為 GC 帶來不必要的復(fù)雜度,并且回收效率偏低
Oracle 可能會(huì)想 HotSpot 與 JRockit 合并。
5. 如果叫你自己設(shè)計(jì)一個(gè)中間件,你會(huì)如何設(shè)計(jì)??
我會(huì)從以下幾點(diǎn)方面考慮開發(fā):?
1) 遠(yuǎn)程過程調(diào)用?
2) 面向消息:利用搞笑的消息傳遞機(jī)制進(jìn)行平臺(tái)無關(guān)的數(shù)據(jù)交流,并給予數(shù)據(jù)通信來 進(jìn)行分布式系統(tǒng)的集成,有一下三個(gè)特點(diǎn):
i) 通訊程序可以在不同的時(shí)間運(yùn)行
ii) 通訊晨旭之家可以一對(duì)一、一對(duì)多、多對(duì)一甚至是 上述多種方式的混合?
iii) 程序?qū)⑾⒎湃胂㈥?duì)列會(huì)從小吸毒列中取出消 息來進(jìn)行通訊?
3) 對(duì)象請(qǐng)求代理:提供不同形式的通訊服務(wù)包括同步、排隊(duì)、訂閱發(fā)布、廣播等。可構(gòu)筑各種框架如:事物處理監(jiān)控器、分布數(shù)據(jù)訪問、對(duì)象事務(wù)管理器 OTM 等。?
4) 事物處理監(jiān)控有一下功能:
a) 進(jìn)程管理,包括啟動(dòng) server 進(jìn)程、分配任務(wù)、監(jiān)控其執(zhí)行并對(duì)負(fù)載進(jìn)行平衡
b) 事務(wù)管理,保證在其監(jiān)控下的事務(wù)處理的原子性、一致性、獨(dú)立性和持久性?
c) 通訊管理,為 client 和 server 之間提供多種通訊機(jī)制,包括請(qǐng)求響應(yīng)、會(huì)話、 排隊(duì)、訂閱發(fā)布和廣播等
6. 什么是中間件?
中間件是處于操作系統(tǒng)和應(yīng)用程序之間軟件,使用時(shí)旺旺是一組中間件集成在一起,構(gòu) 成一個(gè)平臺(tái)(開發(fā)平臺(tái)+運(yùn)行平臺(tái)),在這組中間件中必須要有一個(gè)通信中間件,即中間件= 平臺(tái)+通信。該定義也限定了只有勇于分布式系統(tǒng)中才能稱為中間件?
主要分類:遠(yuǎn)程過程調(diào)用、面向消息的中間件、對(duì)象請(qǐng)求代理、事物處理監(jiān)控。
7. ThreadLock 用過沒有,說說它的作用??
ThreadLock 為本地線程,為每一個(gè)線程提供一個(gè)局部變量,也就是說只有當(dāng)前線層可以 訪問,是線程安全的。原理:為每一個(gè)線程分配一個(gè)對(duì)象來工作,并不是由 ThreadLock 來 完成的,而是需要在應(yīng)用層面保證的,ThreadLock 只是起到了一個(gè)容器的作用。原理為 ThreadLock 的 set()跟 get()方法。?
實(shí)現(xiàn)原理:
public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);}public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null)return (T)e.value;}return setInitialValue();}
8. Hashcode()和 equals()和==區(qū)別??
(1) hashcode()方法跟 equals()在 java 中都是判斷兩個(gè)對(duì)象是否相等?
(2) 兩個(gè)對(duì)象相同,則 hashcode 至一定要相同,即對(duì)象相同 ---->成員變量相同 ---->hashcode 值一定相同?
(3) 兩個(gè)對(duì)象的 hashcode 值相同,對(duì)象不一定相等。總結(jié):equals 相等則 hashcode 一 定相等,hashcode 相等,equals 不一定相等。?
(4) ==比較的是兩個(gè)引用在內(nèi)存中指向的是不是同一對(duì)象(即同一內(nèi)存空間)
9. mysql 數(shù)據(jù)庫中,什么情況下設(shè)置了索引但無法使用??
(1) 索引的作用:在數(shù)據(jù)庫表中對(duì)字段建立索引可以大大提高查詢速度。
(2) Mysql 索引類型:
a) 普通索引
b) 唯一索引:唯一索引列的值必須唯一允許有空值,如果是組合索 引,則列值的組合必須唯一:CREATE UNIQUE INDEX indexName ON mytable(username(length)) -- 修改表結(jié)構(gòu) ALTER mytable ADD UNIQUE [indexName] ON (username(length)) -- 創(chuàng)建表的時(shí)候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) );?
c) 主鍵索引:一種特殊的唯一索引,不允許有空值,一般在創(chuàng)建表 的時(shí)候創(chuàng)建主鍵索引:CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID) );?
d) 組合索引:CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, city VARCHAR(50) NOT NULL, age INT NOT NULL ); 為了進(jìn)一步榨取 MySQL 的效率,就要考慮建立組合索引。就是 將 name, city, age 建到一個(gè)索引里:代碼如下: ALTER TABLE mytable ADD INDEX name_city_age (name(10),city,age);?
(3) 什么情況下有索引,但用不上??
a) 如果條件中有 OR,即使其中有部分條件帶索引也不會(huì)使用。注 意:要想使用 or,又想讓索引生效,只能將 or 條件中的每個(gè)列 都加上索引。?
b) 對(duì)于多了索引,不是使用的第一部分,則不會(huì)使用索引。?
c) Like 查詢以%開頭,不使用索引
d) 存在索引列的數(shù)據(jù)類型隱形轉(zhuǎn)換,則用不上索引,比如列類型是 字符串,那一定要在條件中將數(shù)據(jù)使用引號(hào)引用起來,否則不使 用索引?
e) Where 子句里對(duì)索引列上有數(shù)學(xué)運(yùn)算,用不上索引?
f) Where 子句中對(duì)索引列使用函數(shù),用不上索引?
g) Mysql 估計(jì)使用全表掃描要比用索引快,不使用索引?
(4) 什么情況下不推薦使用索引??
a) 數(shù)據(jù)唯一性差的字段不要使用索引?
b) 頻繁更新的字段不要使用索引?
c) 字段不在 where 語句中出現(xiàn)時(shí)不要添加索引,如果 where 后含 IS NULL/IS NOT NULL/LIKE ‘%輸入符%’等條件,不要使用索引?
d) Where 子句里對(duì)索引使用不等于(<>),不建議使用索引,效果 一般
10. mysql 優(yōu)化會(huì)不會(huì),mycat 分庫,垂直分庫,水平分庫??
(1) 為查詢緩存優(yōu)化你的查詢?
(2) EXPLAIN select 查詢:explain 的查詢結(jié)果會(huì)告訴你索引主鍵是如何被利用的?
(3) 只需要一行數(shù)據(jù)時(shí)使用 limit1?
(4) 為搜索字段添加索引?
(5) 在關(guān)聯(lián)表的時(shí)候使用相當(dāng)類型的例,并將其索引?
(6) 千萬不要 ORDER BY RAND()?
(7) 避免 select*?
(8) 永遠(yuǎn)為每張表設(shè)置一個(gè) ID?
(9) 使用 ENUM 而不是 VARCHAR?
(10) 從 PROCEDURE ANALYS()提取建議?
(11) 盡可能的使用 NOT NULL?
(12) Java 中使用 Prepared Statements?
(13) 無緩沖的查詢?
(14) 把 IP 地址存成 UNSIGNED INT?
(15) 固定表的長度?
(16) 垂直分庫:“垂直分割”是一種把數(shù)據(jù)庫中的表按列變成幾張表的方法,這樣可以 降低表的復(fù)雜度和字段的數(shù)目,從而達(dá)到優(yōu)化的目的。?
(17) 水平分庫:“水平分割”是一種把數(shù)據(jù)庫中的表按行變成幾張表的方法,這樣可以 降低表的復(fù)雜度和字段的數(shù)目,從而達(dá)到優(yōu)化的目的。?
(18) 越小的列會(huì)越快?
(19) 選擇正確的存儲(chǔ)引擎?
(20) 使用一個(gè)對(duì)象關(guān)系映射器?
(21) 小心永久鏈接?
(22) 拆分大的 DELETE 活 INSERT 語句
11. 分布式事務(wù)解決方案??
(1) 什么是分布式事務(wù)?
a. 什么情況下需要用到分布式事務(wù)?
a) 當(dāng)本地?cái)?shù)據(jù)庫斷電、機(jī)器宕機(jī)、網(wǎng)絡(luò)異常、消息丟失、消息亂序、 數(shù)據(jù)錯(cuò)誤、不可靠 TCP、存儲(chǔ)數(shù)據(jù)丟失、其他異常等需要用到分 布式事務(wù)。?
b) 例如:當(dāng)本地事務(wù)數(shù)據(jù)庫斷電的這種秦光,如何保證數(shù)據(jù)一致 性?數(shù)據(jù)庫由連個(gè)文件組成的,一個(gè)數(shù)據(jù)庫文件和一個(gè)日志文 件,數(shù)據(jù)庫任何寫入操作都要先寫日志,在操作前會(huì)吧日志文件 寫入磁盤,那么斷電的時(shí)候及時(shí)才做沒有完成,在重啟數(shù)據(jù)庫的 時(shí)候,數(shù)據(jù)庫會(huì)根據(jù)當(dāng)前數(shù)據(jù)情況進(jìn)行 undo 回滾活 redo 前滾, 保證了數(shù)據(jù)的強(qiáng)一致性。?
c) 分布式理論:當(dāng)單個(gè)數(shù)據(jù)庫性能產(chǎn)生瓶頸的時(shí)候,可能會(huì)對(duì)數(shù)據(jù) 庫進(jìn)行分區(qū)(物理分區(qū)),分區(qū)之后不同的數(shù)據(jù)庫不同的服務(wù)器 上 ,此時(shí)單個(gè)數(shù)據(jù)庫的 ACID 不適應(yīng)這種清苦啊,在此集群環(huán) 境下很難達(dá)到集群的 ACID,甚至效率性能大幅度下降,重要的 是再很難擴(kuò)展新的分區(qū)了。此時(shí)就需要引用一個(gè)新的理論來使用 這種集群情況:CAP 定理?
d) CAP定理:由加州肚餓伯克利分銷Eric Brewer教授提出,指出WEB 服務(wù)無法同時(shí)滿足 3 個(gè)屬性:?
a. 一致性:客戶端知道一系列的操作都會(huì)同時(shí)發(fā)生 (生效)
b. 可用性:每個(gè)操作都必須以可預(yù)期的響應(yīng)結(jié)束?
c. 分區(qū)容錯(cuò)性:及時(shí)出現(xiàn)單組件無法可用,操作依然 可以完成。具體的將在分布式系統(tǒng)中,在任何數(shù)據(jù)庫設(shè)計(jì)中,一個(gè) WEB 應(yīng) 至多只能同時(shí)支持上面兩個(gè)屬性。設(shè)計(jì)人員必須在一致性和可用 性之間做出選擇。?
e) BASE 理論:分布式系統(tǒng)中追求的是可用性,比一致性更加重要, BASE 理論來實(shí)現(xiàn)高可用性。核心思想是:我們無法做到羥乙酯, 單每個(gè)應(yīng)用都可以根據(jù)自身的業(yè)務(wù)特點(diǎn),采用適當(dāng)?shù)姆绞绞瓜?統(tǒng)達(dá)到最終一致性。?
f) 數(shù)據(jù)庫事務(wù)特性:ACID i. 原子性 ii. 一致性 iii. 獨(dú)立性或隔離性 iv. 持久性?
(2) 分布式系統(tǒng)中,實(shí)現(xiàn)分布式事務(wù)的解決方案:?
a. 兩階段提交 2PC?
b. 補(bǔ)償事務(wù) TCC?
c. 本地消息表(異步確保)?
d. MQ 事務(wù)消息?
e. Sagas 事務(wù)模型
12. sql 語句優(yōu)化會(huì)不會(huì),說出你知道的??
(1) 避免在列上做運(yùn)算,可能會(huì)導(dǎo)致索引失敗?
(2) 使用 join 時(shí)應(yīng)該小結(jié)果集驅(qū)動(dòng)大結(jié)果集,同時(shí)把復(fù)雜的 join 查詢拆分成多個(gè) query, 不然 join 越多表,會(huì)導(dǎo)致越多的鎖定和堵塞。?
(3) 注意 like 模糊查詢的使用,避免使用%%?
(4) 不要使用 select * 節(jié)省內(nèi)存?
(5) 使用批量插入語句,節(jié)省交互?
(6) Limit 基數(shù)比較大時(shí),使用 between and?
(7) 不要使用 rand 函數(shù)隨機(jī)獲取記錄?
(8) 避免使用 null,建表時(shí),盡量設(shè)置 not nul,提高查詢性能?
(9) 不要使用 count(id),應(yīng)該使用 count(*)?
(10) 不要做無謂的排序,盡可能在索引中完成排序?
(11) From 語句中一定不要使用子查詢?
(12) 使用更多的 where 加以限制,縮小查找范圍?
(13) 合理運(yùn)用索引?
(14) 使用 explain 查看 sql 性能
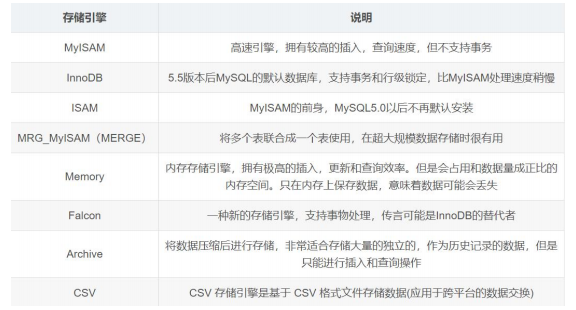
13. mysql 的存儲(chǔ)引擎了解過沒有??
(1) MySQL 存儲(chǔ)引擎種類:?
(2) https://blog.csdn.net/m0_37888031/article/details/80704344?
(3) https://blog.csdn.net/m0_37888031/article/details/80664138?
(4) 事務(wù)處理:在整個(gè)流程中出現(xiàn)任何問題,都能讓數(shù)據(jù)回滾到最開始的狀態(tài),這種處 理方式稱之為事務(wù)處理。也就是說事務(wù)處理要么都成功,要么的失敗
14. 紅黑樹原理??
(1) 紅黑樹的性質(zhì):紅黑樹是一個(gè)二叉搜索樹。在每個(gè)節(jié)點(diǎn)增加了一個(gè)存儲(chǔ)位記錄節(jié)點(diǎn) 的顏色,可以是 RED,也可以是 BLACK,通過任意一條從根到葉子簡單路徑上顏色 的約束,紅黑樹保證最長路徑不超過最短路徑的兩倍,加以平衡。性質(zhì)如下:
i. 每個(gè)節(jié)點(diǎn)顏色不是黑色就是紅色
ii. 根節(jié)點(diǎn)的顏色是黑色的?
iii. 如果一個(gè)節(jié)點(diǎn)是紅色,那么他的兩個(gè)子節(jié)點(diǎn)就是黑色的, 沒有持續(xù)的紅節(jié)點(diǎn)?
iv. 對(duì)于每個(gè)節(jié)點(diǎn),從該節(jié)點(diǎn)到其后代葉節(jié)點(diǎn)的簡單路徑上, 均包含相同數(shù)目的黑色節(jié)點(diǎn)
以上便是螞蟻金服的面試題,如果說想獲取往期最新的面試資料,點(diǎn)贊+在看,關(guān)注我之后領(lǐng)取資料請(qǐng)添加這個(gè)微信號(hào):tulingQY??添加備注【02】 記得一定要備注【02】不然領(lǐng)不到資料!
以下是往期部分面試資料截圖

騰訊、阿里、滴滴后臺(tái)面試題匯總總結(jié) — (含答案)
面試:史上最全多線程面試題 !
最新阿里內(nèi)推Java后端面試題
JVM難學(xué)?那是因?yàn)槟銢]認(rèn)真看完這篇文章

關(guān)注作者微信公眾號(hào) —《JAVA爛豬皮》
了解更多java后端架構(gòu)知識(shí)以及最新面試寶典

看完本文記得給作者點(diǎn)贊+在看哦~~~大家的支持,是作者源源不斷出文的動(dòng)力