
我堅(jiān)持一年了!
大家好,我是小林。
昨天有位關(guān)注我一年的讀者找我,他去年關(guān)注我公眾后,開始自學(xué) CS,主要是計(jì)算機(jī)基礎(chǔ)這一塊。

他從那時(shí)起,就日復(fù)一日的學(xué)習(xí),并在 Github 有做筆記的習(xí)慣,你看他的提交記錄,每天都有,一天都沒拉下,就這樣堅(jiān)持了一年。
這個(gè)一年沒有間斷過的堅(jiān)持,我是真的被震撼到,雖然我也經(jīng)常肝文章,但是我也做不到每天都是學(xué)習(xí)的狀態(tài),總會(huì)想偷懶幾天,畢竟學(xué)習(xí)真的是反人性的哈哈。
這位讀者去年的時(shí)候,也只是會(huì)用 python 輸出 hello world 初學(xué)者,而如今能開始啃 Redis 源碼了,并且還記錄了學(xué)習(xí) Redis 數(shù)據(jù)結(jié)構(gòu)的源碼筆記。

我也跟他討論了我學(xué)計(jì)算基礎(chǔ)的感受,他也有相同的感受,看來是同道中人。
之前有很多讀者問我學(xué)計(jì)算機(jī)基礎(chǔ)有啥用?不懂算法、計(jì)算機(jī)網(wǎng)絡(luò)、操作系統(tǒng)這些東西,也可以完成工作上的 CRUD 業(yè)務(wù)開發(fā),那為什么要花時(shí)間去學(xué)?
是的,不懂這些,確實(shí)不會(huì)影響 CRUD 業(yè)務(wù)開發(fā),對(duì)于這類業(yè)務(wù)開發(fā)的工作,難點(diǎn)是在于對(duì)業(yè)務(wù)的理解,但是門檻并不高,找個(gè)剛畢業(yè)人,讓他花幾個(gè)月時(shí)間熟悉業(yè)務(wù)和代碼,他一樣可以上手開發(fā)了,也就是說,單純的 CRUD 業(yè)開發(fā)工作很快就會(huì)被體力更好的新人取代的。
另外,在面對(duì)一些性能問題,如果沒有計(jì)算機(jī)基礎(chǔ),我們是無從下手的,這時(shí)候程序員之間的分水嶺就出來了。
看到這,大家可能以為小林接下來要賣課,大家放心,這篇文章是干貨,不會(huì)賣課
今天,我不講虛的東西。
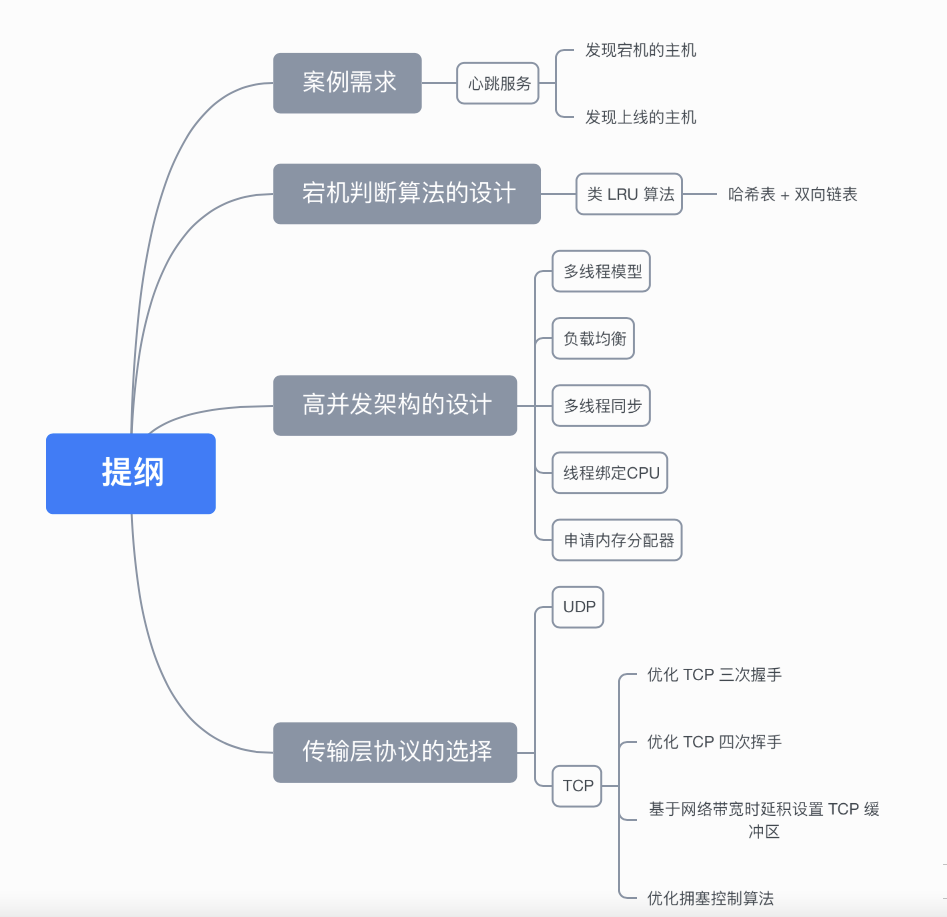
我以如何設(shè)計(jì)一個(gè)「高性能的單機(jī)管理主機(jī)的心跳服務(wù)」的方式,讓大家感受計(jì)算基礎(chǔ)之美,這里會(huì)涉及到數(shù)據(jù)結(jié)構(gòu)與算法 + 操作系統(tǒng) + 計(jì)算機(jī)組成 + 計(jì)算機(jī)網(wǎng)絡(luò)這些知識(shí)。
大家耐心看下去,你會(huì)發(fā)現(xiàn)原來計(jì)算機(jī)基礎(chǔ)知識(shí)的用處,相信我,你會(huì)感觸很深刻。
案例需求
后臺(tái)通常是由多臺(tái)服務(wù)器對(duì)外提供服務(wù)的,也就是所謂的集群。

如果集群中的某一臺(tái)主機(jī)宕機(jī)了,我們必須要感知到這臺(tái)主機(jī)宕機(jī)了,這樣才做容災(zāi)處理,比如該宕機(jī)的主機(jī)的業(yè)務(wù)遷移到另外一臺(tái)主機(jī)等等。
那如何感知呢?那就需要心跳服務(wù)了。
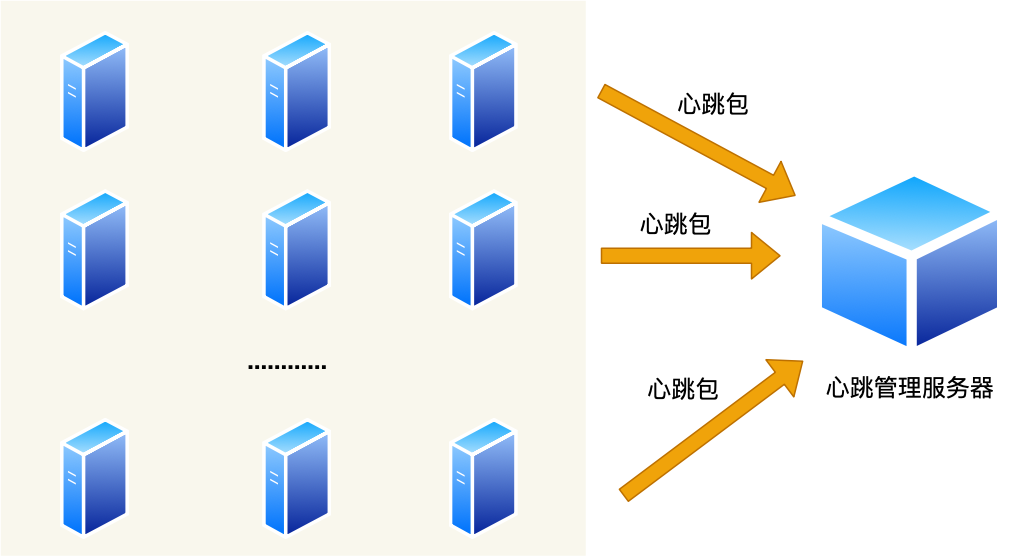
要求每臺(tái)主機(jī)都要向一臺(tái)主機(jī)上報(bào)心跳包,這樣我們就能在這臺(tái)主機(jī)上看到每臺(tái)主機(jī)的在線情況了。
心跳服務(wù)主要做兩件事情:
發(fā)現(xiàn)宕機(jī)的主機(jī);
發(fā)現(xiàn)上線的主機(jī)。
看上去感覺很簡(jiǎn)單,但是當(dāng)集群達(dá)到十萬(wàn),甚至百萬(wàn)臺(tái)的時(shí)候,要實(shí)現(xiàn)一個(gè)可以能管理這樣規(guī)模的集群的心跳服務(wù)進(jìn)程,沒點(diǎn)底層知識(shí)是無法做到的。
接下來,將從三個(gè)維度來設(shè)計(jì)這個(gè)心跳服務(wù):
宕機(jī)判斷算法的設(shè)計(jì)
高并發(fā)架構(gòu)的設(shè)計(jì)
傳輸層協(xié)議的選擇
宕機(jī)判斷算法的設(shè)計(jì)
這個(gè)心跳服務(wù)最關(guān)鍵是判斷宕機(jī)的算法。
如果采用暴力遍歷所有主機(jī)的方式來找到超時(shí)的主機(jī),在面對(duì)只有幾百臺(tái)主機(jī)的場(chǎng)景是沒問題,但是這個(gè)算法會(huì)隨著主機(jī)越多,算法復(fù)雜度也會(huì)上升,程序的性能也就會(huì)急劇下降。
所以,我們應(yīng)該設(shè)計(jì)一個(gè)可以應(yīng)對(duì)超大集群規(guī)模的宕機(jī)判斷算法。
我們先來思考下,心跳包應(yīng)該有什么數(shù)據(jù)結(jié)構(gòu)來管理?
心跳包里的內(nèi)容是有主機(jī)上報(bào)的時(shí)間信息的,也就是有時(shí)間關(guān)系的,那么可以用「雙向鏈表」構(gòu)成先入先出的隊(duì)列,這樣就保存了心跳包的時(shí)序關(guān)系。
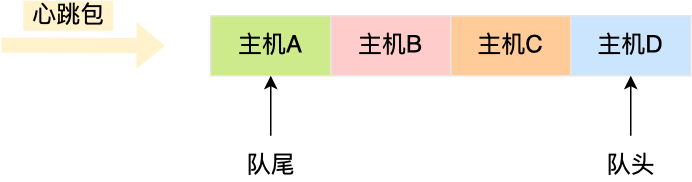
由于采用的數(shù)據(jù)結(jié)構(gòu)是雙向鏈表,所以隊(duì)尾插入和隊(duì)頭刪除操作的時(shí)間復(fù)雜度是 O(1)。
如果有新的心跳包,則將其插入到雙向鏈表的尾部,那么最老的心跳包就是在雙向鏈表的頭部,這樣在尋找宕機(jī)的主機(jī)時(shí),只要看雙向鏈表頭部最老的心跳包,距現(xiàn)在是否超過 5 秒,如果超過 5秒 則認(rèn)為該主機(jī)宕機(jī),然后將其從雙向鏈表中刪除。
細(xì)心的同學(xué)肯定發(fā)現(xiàn)了個(gè)問題,就是如果一個(gè)主機(jī)的心跳包已經(jīng)在隊(duì)列中,那么下次該主機(jī)的心跳包要怎么處理呢?
為了維持隊(duì)列里的心跳包是主機(jī)最新上報(bào)的,所以要先找到該主機(jī)舊的心跳包,然后將其刪除,再把新的心跳包插入到雙向鏈表的隊(duì)尾。
問題來了,在隊(duì)列找到該主機(jī)舊的心跳包,由于數(shù)據(jù)結(jié)構(gòu)是雙向鏈表,所以這個(gè)查詢過程的時(shí)間復(fù)雜度時(shí) O(N),也就是說隨著隊(duì)列里的元素越多,會(huì)越影響程序的性能,這一點(diǎn)我們必須優(yōu)化。
查詢效率最好的數(shù)據(jù)結(jié)構(gòu)就是「哈希表」了,時(shí)間復(fù)雜度只有 O(1),因此我們可以加入這個(gè)數(shù)據(jù)結(jié)構(gòu)來優(yōu)化。
哈希表的 Key 是主機(jī)的 IP 地址,Value 包含主機(jī)在雙向鏈表里的節(jié)點(diǎn),這樣我們就可以通過哈希表輕松找到該主機(jī)在雙向鏈表中的位置。
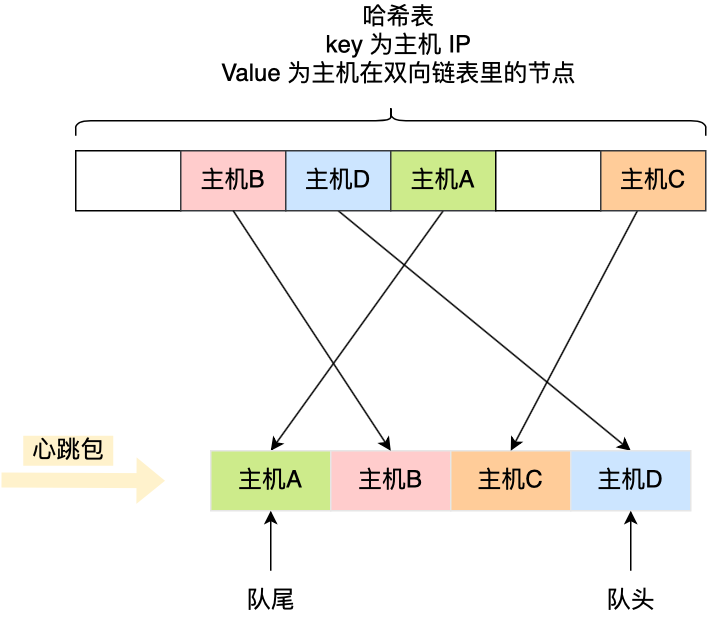
這樣,每當(dāng)收到心跳包時(shí),先判斷其在不在哈希表里。
如果不存在哈希表里,說明是新主機(jī)上線,先將其插入到雙向鏈表的尾部,然后將該主機(jī)的 IP 作為 Key,主機(jī)在雙向鏈表的節(jié)點(diǎn)作為 Value 插入到哈希表。
如果存在哈希表里,說明主機(jī)已經(jīng)上線過,先通過查詢哈希表,找到該主機(jī)在雙向鏈表里舊的心跳包的節(jié)點(diǎn),然后就可以通過該節(jié)點(diǎn)將其從雙向鏈表中刪除,最后將新的心跳包插入到雙向鏈表的隊(duì)尾,同時(shí)更新哈希表。
可以看到,上面這些操作全都是 O(1),不管集群規(guī)模多大,時(shí)間復(fù)雜度都不會(huì)增加,但是代價(jià)就是內(nèi)存占用會(huì)越多,這個(gè)就是以空間換時(shí)間的方式。
有個(gè)細(xì)節(jié)的問題,不知道大家發(fā)現(xiàn)了沒有,就是為什么隊(duì)列的數(shù)據(jù)結(jié)構(gòu)采用雙向鏈表,而不是單向鏈表?
因?yàn)殡p向鏈表比單向鏈表多了個(gè) pre 的指針,可以通過其找到上一個(gè)節(jié)點(diǎn),那么在刪除中間節(jié)點(diǎn)的時(shí)候,就可以直接刪除,而如果是單向鏈表在刪除中間的時(shí)候,我們得先通過遍歷找到需被刪除節(jié)點(diǎn)的上一個(gè)節(jié)點(diǎn),才能完成刪除操作,這里中間多了個(gè)遍歷操作。
既然引入哈希表,那我們?cè)谂袛喑鲇兄鳈C(jī)宕機(jī)了(檢查雙向鏈表隊(duì)頭的主機(jī)是否超時(shí)),除了要將其從雙向鏈表中刪除,也要從哈希表中刪除。要將主機(jī)從哈希表刪除,首先我們要知道主機(jī)的 IP,因?yàn)檫@是哈希表的 Key。
雙向鏈表存儲(chǔ)的內(nèi)容必須包含主機(jī)的 IP 信息,那為了更快查詢到主機(jī)的 IP,雙向鏈表存儲(chǔ)的內(nèi)容可以是一個(gè)鍵值對(duì)(Key-Value),其 Key 就是主機(jī)的 IP,Value 就是主機(jī)的信息。
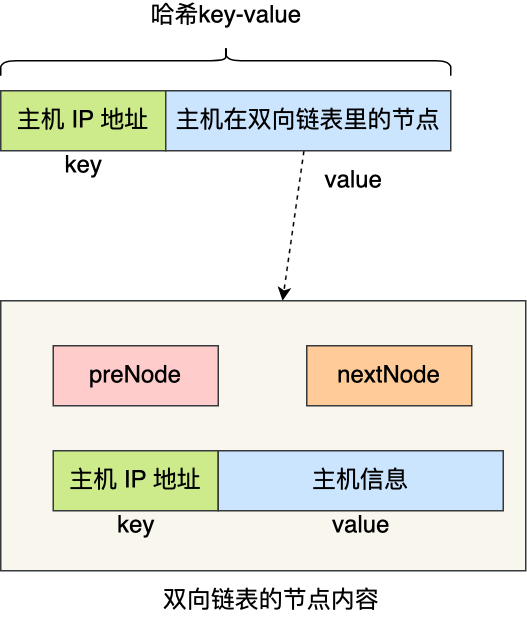
這樣,在發(fā)現(xiàn)雙向鏈表中頭部的節(jié)點(diǎn)超時(shí)了,由于節(jié)點(diǎn)的內(nèi)容是鍵值對(duì),于是就能快速地從該節(jié)點(diǎn)獲取主機(jī)的 IP ,知道了主機(jī)的 IP 信息,就能把哈希表中該主機(jī)信息刪除。
至此,就設(shè)計(jì)出了一個(gè)高性能的宕機(jī)判斷算法,主要用了數(shù)據(jù)結(jié)構(gòu):哈希表 + 雙向鏈表,通過這個(gè)組合,查詢 + 刪除 + 插入操作的時(shí)間復(fù)雜度都是 O(1),以空間換時(shí)間的思想,這就是數(shù)據(jù)結(jié)構(gòu)與算法之美!
熟悉算法的同學(xué)應(yīng)該感受出來了,上面這個(gè)算法就是類 LRU 算法,用于淘汰最近最久使用的元素的場(chǎng)景,該算法應(yīng)用范圍很廣的,操作系統(tǒng)、Redis、MySQL 都有使用該算法。
在很多大廠面試的時(shí)候,經(jīng)常會(huì)考察 LRU 算法,甚至?xí)笫謱懗鰜恚竺嫖以趯懸黄?LRU 算法實(shí)現(xiàn)的文章。
高并發(fā)架構(gòu)的設(shè)計(jì)
設(shè)計(jì)完高效的宕機(jī)判斷算法后,我們來設(shè)計(jì)個(gè)能充分利用服務(wù)器資源的架構(gòu),以應(yīng)對(duì)高并發(fā)的場(chǎng)景。
首先第一個(gè)問題,選用單線程還是多線程模式?
選用單線程的話,意味著程序只能利用一個(gè) CPU 的算力,如果 CPU 是一顆 1GHZ 主頻的 CPU,意味著一秒鐘只有 10 億個(gè)時(shí)鐘周期可以工作,如果要讓心跳服務(wù)程序每秒接收到 100 萬(wàn)心跳包,那么就要求它必須在 1000 個(gè)時(shí)時(shí)鐘周期內(nèi)處理完一個(gè)心跳包。
這是無法做到的,因?yàn)橐粋€(gè)匯編指令的執(zhí)行需要多個(gè)時(shí)鐘周期,更何況高級(jí)語(yǔ)言的一條語(yǔ)句是由多個(gè)匯編指令構(gòu)成的,而且這個(gè) 1000 個(gè)時(shí)鐘周期還要包含內(nèi)核從網(wǎng)卡上讀取報(bào)文,以及協(xié)議棧的報(bào)文分析。
因此,采用單線程模式會(huì)出現(xiàn)算力不足的情況,意味著在百萬(wàn)級(jí)的心跳場(chǎng)景下,容易出現(xiàn)內(nèi)核緩沖區(qū)的數(shù)據(jù)無法被即使取出而導(dǎo)致溢出的現(xiàn)象,然后就會(huì)出現(xiàn)大量的丟包。
所以,我們要選擇多進(jìn)程或者多線程的模式,來充分利用多核的 CPU 資源。多進(jìn)程的優(yōu)勢(shì)是進(jìn)程間互不干擾,但是內(nèi)存不共享,進(jìn)程間通信比較麻煩,因此采用多線程模式開發(fā)會(huì)更好一些,多線程間可以共享數(shù)據(jù)。
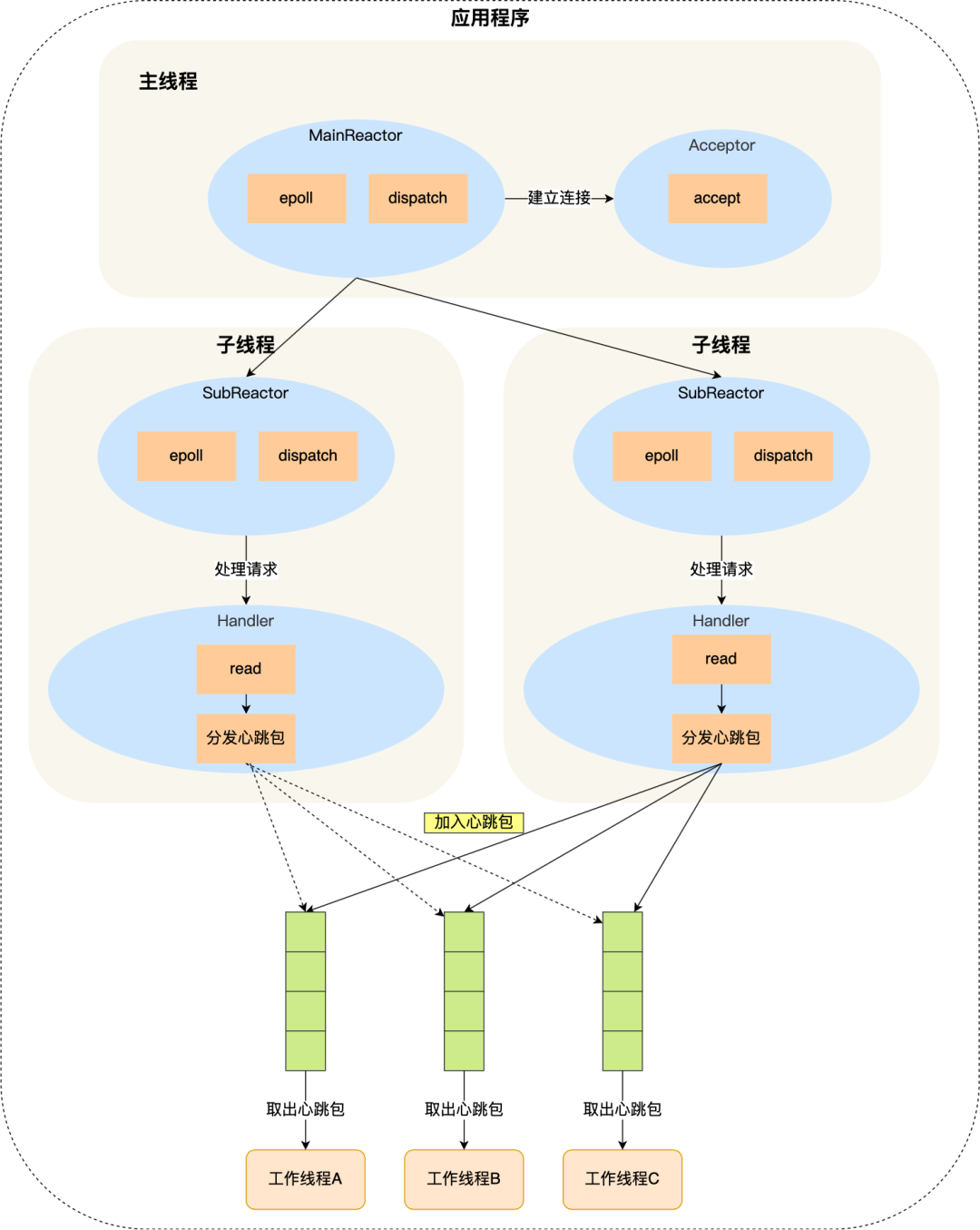
多線程體現(xiàn)在「分發(fā)線程是多線程和工作線程是多線程」,決定了多線程開發(fā)模式后,我們還需要解決五個(gè)問題。
第一個(gè)多路復(fù)用
我們應(yīng)該使用多路復(fù)用技術(shù)來服務(wù)多個(gè)客戶端,而且是要使用 epoll。
因?yàn)?select 和 poll 的缺陷在于,當(dāng)客戶端越多,也就是 Socket 集合越大,Socket 集合的遍歷和拷貝會(huì)帶來很大的開銷;
而 epoll 的方式即使監(jiān)聽的 Socket 數(shù)量越多的時(shí)候,效率不會(huì)大幅度降低,能夠同時(shí)監(jiān)聽的 Socket 的數(shù)目也非常的多了。
多路復(fù)用更詳細(xì)的介紹,可以看之前這篇文章:這次答應(yīng)我,一舉拿下 I/O 多路復(fù)用!
第二個(gè)負(fù)載均衡
在收到心跳包后,我們應(yīng)該要將心跳包均勻分發(fā)到不同的工作線程上處理。
分發(fā)的規(guī)則可以用哈希函數(shù),這樣在接收到心跳包后,解析出主機(jī)的 IP 地址,然后通過哈希函數(shù)分發(fā)給工作線程處理。
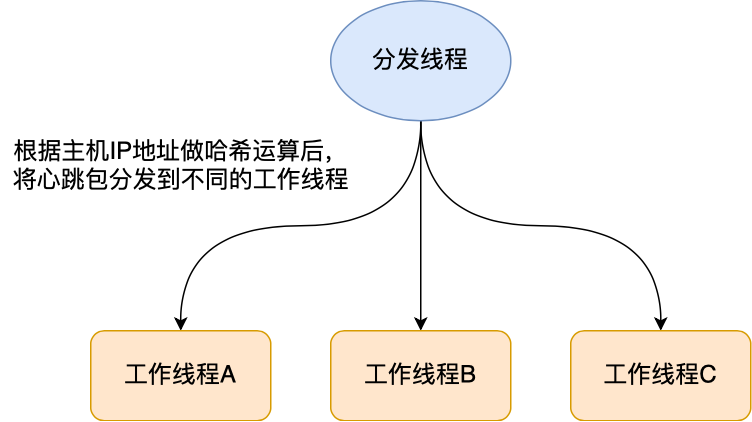
于是每個(gè)工作線程只會(huì)處理特定主機(jī)的心跳包,多個(gè)工作線程間互不干擾,不用在多個(gè)工作線程間加鎖,從而實(shí)現(xiàn)了無鎖編程。
第三個(gè)多線程同步
分發(fā)線程和工作線程之間可以加個(gè)消息隊(duì)列,形成「生產(chǎn)者 - 消費(fèi)者」模型。
分發(fā)線程負(fù)責(zé)將接收到的心跳包加入到隊(duì)列里,工作線程負(fù)責(zé)從隊(duì)列取出心跳包做進(jìn)一步的處理。
除此之外,還需要做如下兩點(diǎn)。
第一點(diǎn),工作線程一般是多于分發(fā)線程,給每一個(gè)工作線程都創(chuàng)建獨(dú)立的緩沖隊(duì)列。
第二點(diǎn),緩沖隊(duì)列是會(huì)被分發(fā)線程和工作線程同時(shí)操作,所以在操作該隊(duì)列要加鎖,為了避免線程獲取鎖失而主動(dòng)放棄 CPU,可以選擇自旋鎖,因?yàn)樽孕i在獲取鎖失敗后,CPU 還在執(zhí)行該線程,只不過 CPU 在空轉(zhuǎn),效率比互斥鎖高。
更多關(guān)于鎖的講解可以看這篇:「互斥鎖、自旋鎖、讀寫鎖、悲觀鎖、樂觀鎖的應(yīng)用場(chǎng)景」
第四個(gè)線程綁定 CPU
現(xiàn)代 CPU 都是多核心的,線程可能在不同 CPU 核心來回切換執(zhí)行,這對(duì) CPU Cache 不是有利的,雖然 L3 Cache 是多核心之間共享的,但是 L1 和 L2 Cache 都是每個(gè)核心獨(dú)有的。
如果一個(gè)線程在不同核心來回切換,各個(gè)核心的緩存命中率就會(huì)受到影響,相反如果線程都在同一個(gè)核心上執(zhí)行,那么其數(shù)據(jù)的 L1 和 L2 Cache 的緩存命中率可以得到有效提高,緩存命中率高就意味著 CPU 可以減少訪問 內(nèi)存的頻率。
當(dāng)有多個(gè)同時(shí)執(zhí)行「計(jì)算密集型」的線程,為了防止因?yàn)榍袚Q到不同的核心,而導(dǎo)致緩存命中率下降的問題,我們可以把線程綁定在某一個(gè) CPU 核心上,這樣性能可以得到非常可觀的提升。
在 Linux 上提供了 sched_setaffinity 方法,來實(shí)現(xiàn)將線程綁定到某個(gè) CPU 核心這一功能。
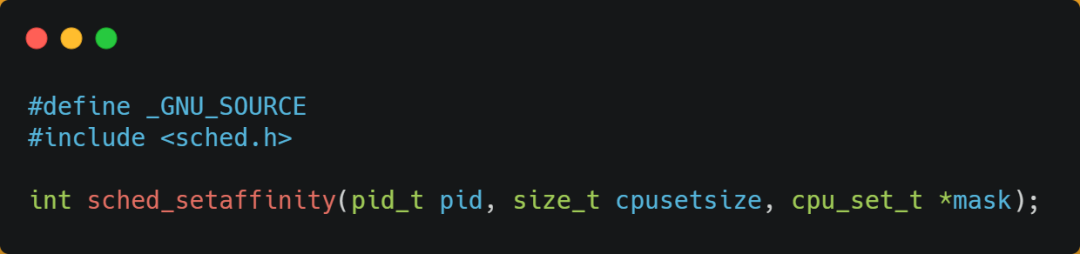
更多關(guān)于 CPU Cache 的介紹,可以看這篇:「如何寫出讓 CPU 跑得更快的代碼?」
第五個(gè)內(nèi)存分配器
Linux 默認(rèn)的內(nèi)存分配器是 PtMalloc2,它有一個(gè)缺點(diǎn)在申請(qǐng)小內(nèi)存和多線程的情況下,申請(qǐng)內(nèi)存的效率并不高。
后來,Google 開發(fā)的 TCMalloc 內(nèi)存分配器就解決這個(gè)問題,它在多線程下分配小內(nèi)存的速度要快很多,所以對(duì)于心跳服務(wù)應(yīng)當(dāng)改用 TCMalloc 申請(qǐng)內(nèi)存。
下圖是 TCMalloc 作者給出的性能測(cè)試數(shù)據(jù),可以看到線程數(shù)越多,二者的速度差距越大,顯然 TCMalloc 更具有優(yōu)勢(shì)。
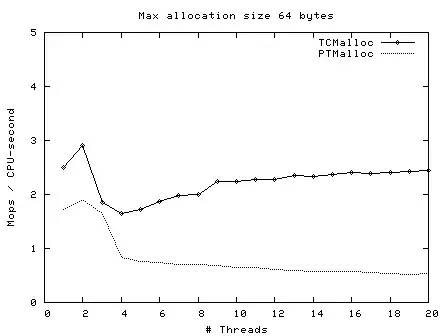
我暫時(shí)就想到這么多了,這里每一個(gè)點(diǎn)都跟「計(jì)算機(jī)組成和操作系統(tǒng)」知識(shí)密切相關(guān)。
傳輸層協(xié)議的選擇
心跳包的傳輸層協(xié)議應(yīng)該是選 TCP 和 UDP 呢?
對(duì)于傳輸層協(xié)議的選擇,我們要看心跳包的長(zhǎng)度大小。
如果長(zhǎng)度小于 MTU,那么可以選擇 UDP 協(xié)議,因?yàn)?UDP 協(xié)議沒那么復(fù)雜,而且心跳包也不是一定要完全可靠傳輸,如果中途發(fā)生丟包,下一次心跳包能收到就行。
如果長(zhǎng)度大于 MTU,就要選擇 TCP 了,因?yàn)?UDP 在傳送大于 1500 字節(jié)的報(bào)文,IP 協(xié)議就會(huì)把報(bào)文拆包后再發(fā)到網(wǎng)絡(luò)中,并在接收方組裝回原來的報(bào)文,然而,IP 協(xié)議并不擅長(zhǎng)做這件事,拆包組包的效率很低。
所以,TCP 協(xié)議就選擇自己做拆包組包的事情,當(dāng)心跳包的長(zhǎng)度大于 MSS 時(shí)就會(huì)在 TCP 層拆包,且保證 TCP 層拆包的報(bào)文長(zhǎng)度不會(huì) MTU。

選擇了 TCP 協(xié)議后,我們還要解決一些事情,因?yàn)?TCP 協(xié)議是復(fù)雜的。
首先,要讓服務(wù)器能支持更多的 TCP 連接,TCP 連接是通過四元組唯一確認(rèn)的,也就是「 源 IP、目的 IP、源端口、目的端口 」。
那么當(dāng)服務(wù)器 IP 地址(目的 IP)和監(jiān)聽端口(目標(biāo)端口)固定時(shí),變化的只有源 IP(2^32) 和源端口(2^16),因此理論上服務(wù)器最大能連接 2^(32+16) 個(gè)客戶端。
這只是理論值,實(shí)際上服務(wù)器的資源肯定達(dá)不到那么多連接。Linux 系統(tǒng)一切皆文件,所以 TCP 連接也是文件,那么服務(wù)器要增大下面這兩個(gè)地方的最大文件句柄數(shù):
通過
ulimit命令增大單進(jìn)程允許最大文件句柄數(shù);通過
/proc/sys/fs/file-nr增大系統(tǒng)允許最大文件句柄數(shù)。
另外, TCP 協(xié)議的默認(rèn)內(nèi)核參數(shù)并不適應(yīng)高并發(fā)的場(chǎng)景,所以我們還得在下面這四個(gè)方向通過調(diào)整內(nèi)核參數(shù)來優(yōu)化 TCP 協(xié)議:
三次握手過程需要優(yōu)化;
四次揮手過程需要優(yōu)化:
TCP 緩沖區(qū)要根據(jù)網(wǎng)絡(luò)帶寬時(shí)延積設(shè)置;
需要優(yōu)化;
前三個(gè)的優(yōu)化的思路,我在之前的文章寫過,詳見:「面試官:換人!他連 TCP 這幾個(gè)參數(shù)都不懂」
這里簡(jiǎn)單說一下優(yōu)化擁塞控制算法的思路。
傳統(tǒng)的擁塞控制分為四個(gè)部分:慢啟動(dòng)、擁塞避免、快速重傳、快速恢復(fù),如下圖:

當(dāng) TCP 連接建立成功后,擁塞控制算法就會(huì)發(fā)生作用,首先進(jìn)入慢啟動(dòng)階段。決定連接此時(shí)網(wǎng)速的是初始擁塞窗口,默認(rèn)值是 10 MSS。
在帶寬時(shí)延積較大的網(wǎng)絡(luò)中,應(yīng)當(dāng)調(diào)高初始擁塞窗口,比如 20 MSS 或 30 MSS,Linux 上可以通過 route ip change 命令修改它。
傳統(tǒng)的擁塞控制算法是基于丟包作為判斷擁塞的依據(jù)。不過實(shí)際上,網(wǎng)絡(luò)剛出現(xiàn)擁塞時(shí)并不會(huì)丟包,而真的出現(xiàn)丟包時(shí),擁塞已經(jīng)非常嚴(yán)重了,比如像理由器里都有緩沖隊(duì)列應(yīng)對(duì)突發(fā)流量:
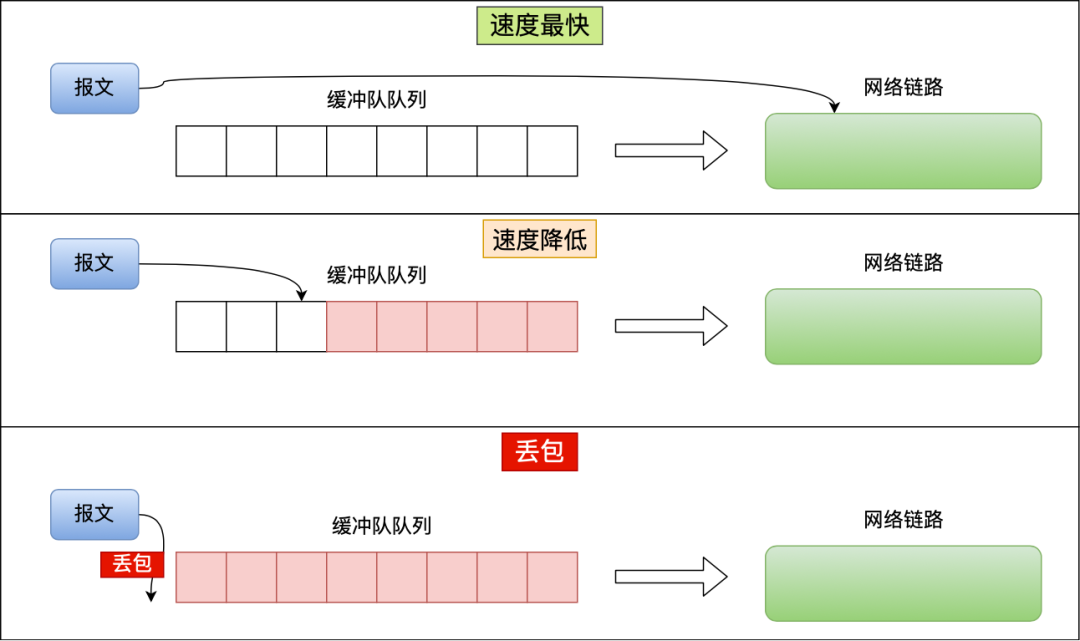
上圖中三種情況:
當(dāng)緩沖隊(duì)列為空時(shí),傳輸速度最快;
當(dāng)緩沖隊(duì)列開始有報(bào)文擠壓,那么網(wǎng)速就開始變慢了,也就是網(wǎng)絡(luò)延時(shí)變高了;
當(dāng)緩沖隊(duì)列溢出時(shí),就出現(xiàn)了丟包現(xiàn)象。
傳統(tǒng)的擁塞控制算法就是在第三步這個(gè)時(shí)間點(diǎn)進(jìn)入擁塞避免階段,顯然已經(jīng)很晚了。
其實(shí)進(jìn)行擁塞控制的最佳時(shí)間點(diǎn),是緩沖隊(duì)列剛出現(xiàn)積壓的時(shí)刻,也就是第二步。
Google 推出的 BBR 算法是以測(cè)量帶寬、時(shí)延來確定擁塞的擁塞控制算法,能提高網(wǎng)絡(luò)環(huán)境的質(zhì)量,減少網(wǎng)絡(luò)延遲和降低丟包率。
Linux 4.9 版本之后都支持 BBR 算法,開啟 BBR 算法的方式:
net.ipv4.tcp_congestion_control=bbr
這里的每一個(gè)知識(shí)都涉及到了計(jì)算機(jī)網(wǎng)絡(luò),這就是計(jì)算機(jī)網(wǎng)絡(luò)之美!
總結(jié)
掌握好數(shù)據(jù)結(jié)構(gòu)與算法,才能設(shè)計(jì)出高效的宕機(jī)判斷算法,本文我們采用哈希表 + 雙向鏈表實(shí)現(xiàn)了類 LRU 算法。
掌握好計(jì)算組成 + 操作系統(tǒng),才能設(shè)計(jì)出高性能的架構(gòu),本文我們采用多線程模式來充分利用 CPU 資源,還需要考慮 IO 多路服用的選擇,鎖的選擇,消息隊(duì)列的引入,內(nèi)存分配器的選擇等等。
掌握好計(jì)算機(jī)網(wǎng)絡(luò),才能選擇契合場(chǎng)景的傳輸協(xié)議,如果心跳包長(zhǎng)度大于 MTU,那么選擇 TCP 更有利,但是 TCP 是個(gè)復(fù)雜的協(xié)議,在高并發(fā)的場(chǎng)景下,需要對(duì) TCP的每一個(gè)階段需要優(yōu)化。如果如果心跳包長(zhǎng)度小于 MTU,且不要求可靠傳輸時(shí),UDP 協(xié)議是更好的選擇。
怎么樣?
是不是感動(dòng)到了計(jì)算機(jī)基礎(chǔ)之美。