HBase 解析 | HBase二級索引方案解析
什么是二級索引
HBase中的一級索引指數(shù)據(jù)在寫入region時(shí),會(huì)根據(jù)rowkey進(jìn)行排序后寫入,之后regionserver在加載region時(shí),會(huì)自動(dòng)為當(dāng)前region的rowkey創(chuàng)建一個(gè)LSM樹的索引,方便對當(dāng)前region,rowkey的查詢。
那么問題來了。HBase本身只提供基于行鍵和全表掃描的查詢,而行鍵索引單一,對于多維度的查詢困難。
二級索引的本質(zhì)就是建立各列值與行鍵之間的映射關(guān)系。
Coprocessor
在講解如何構(gòu)建二級索引前,我們有必要簡單介紹一下Coprocessor這個(gè)核心特性。
在舊版本的(<0.92)Hbase中,統(tǒng)計(jì)數(shù)據(jù)表的總行數(shù),需要使用Counter 方法,執(zhí)行一次MapReduce Job才能得到。雖然HBase在數(shù)據(jù)存儲層中集成了MapReduce,能夠有效用于數(shù)據(jù)表的分布式計(jì)算。然而在很多情況下,做一些簡單的相加或者聚合計(jì)算的時(shí)候,如果直接將計(jì)算過程放置在server 端,能夠減少通訊開銷,從而獲得很好的性能提升。
在這種情況下,協(xié)處理器(Coprocessor)應(yīng)運(yùn)而生。它允許你將業(yè)務(wù)計(jì)算代碼放入在RegionServer的協(xié)處理器中,將處理好的數(shù)據(jù)再返回給客戶端,這可以極大地降低需要傳輸?shù)臄?shù)據(jù)量,從而獲得性能上的提升。同時(shí)協(xié)處理器也允許用戶擴(kuò)展實(shí)現(xiàn)HBase目前所不具備的功能,如權(quán)限校驗(yàn)、二級索引、完整性約束等。
于是,HBase在0.92版本之后引入了協(xié)處理器(coprocessors),實(shí)現(xiàn)了一些激動(dòng)人心的新特性:能夠輕易建立二次索引、復(fù)雜過濾器(謂詞下推)以及訪問控制等。
協(xié)處理器類型
Observer協(xié)處理器
類似于傳統(tǒng)數(shù)據(jù)庫中的觸發(fā)器,當(dāng)發(fā)生某些事件的時(shí)候這類協(xié)處理器會(huì)被 Server 端調(diào)用。
Observer Coprocessor 就是一些散布在 HBase Server 端代碼中的 hook 鉤子,在固定的事件發(fā)生時(shí)被調(diào)用。比如:put 操作之前有鉤子函數(shù)prePut,該函數(shù)在 put 操作執(zhí)行前會(huì)被Region Server調(diào)用;在 put 操作之后則有postPut `鉤子函數(shù)。
當(dāng)前Observer協(xié)處理器有下面4種類型:
RegionObserver:允許您觀察 Region 上的事件,例如 Get 和 Put 操作; RegionServerObserver:允許您觀察與 RegionServer 操作相關(guān)的事件,例如啟動(dòng)、停止或執(zhí)行合并、提交或回滾。 WALObserver:提供 WAL 相關(guān)操作鉤子; MasterObserver:提供 DDL-類型的操作鉤子。如創(chuàng)建、刪除、修改數(shù)據(jù)表等。
以上四種類型的 Observer 協(xié)處理器均繼承自Coprocessor接口;這四個(gè)接口中分別定義了所有可用的鉤子方法以便在對應(yīng)方法前后執(zhí)行特定的操作。通常情況下我們并不會(huì)直接實(shí)現(xiàn)上面接口而是繼承其Base實(shí)現(xiàn)類,Base 實(shí)現(xiàn)類只是簡單空實(shí)現(xiàn)了接口中的方法,這樣我們在實(shí)現(xiàn)自定義的協(xié)處理器時(shí)就不必實(shí)現(xiàn)所有方法只需要重寫必要方法即可。

下面是以RegionObserver為例子講解Observer這種協(xié)處理器的原理:

客戶端發(fā)起get請求 該請求被分派給合適的 RegionServer和RegioncoprocessorHost攔截該請求,然后在該表上登記的每個(gè)RegionObserer上調(diào)用preGet()如果沒有被preGet攔截,該請求繼續(xù)送到Region,然后進(jìn)行處理 Region產(chǎn)生的結(jié)果再次被 coprocessorHost攔截,調(diào)用postGet()處理假如沒有postGet()攔截該響應(yīng),最終結(jié)果被返回給客戶端
Observer協(xié)處理器
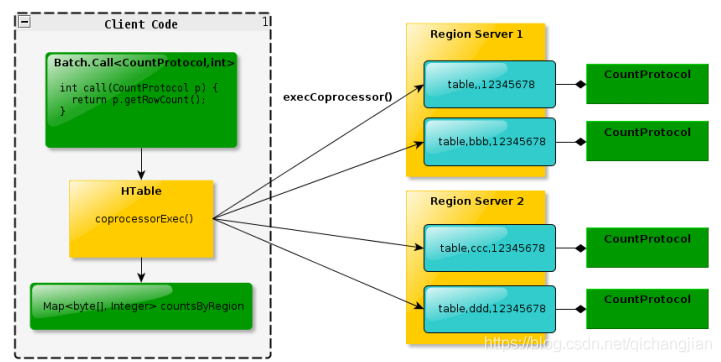
Endpoint協(xié)處理器類似傳統(tǒng)數(shù)據(jù)庫中的存儲過程,客戶端可以調(diào)用這些 Endpoint協(xié)處理器執(zhí)行一段Server端代碼,并將Server端代碼的結(jié)果返回給客戶端進(jìn)一步處理,最常見的用法就是進(jìn)行聚集操作;
如果沒有協(xié)處理器,當(dāng)用戶需要找出一張表中的最大數(shù)據(jù),即max 聚合操作,就必須進(jìn)行全表掃描,在客戶端代碼內(nèi)遍歷掃描結(jié)果,并執(zhí)行求最大值的操作。這樣的方法無法利用底層集群的并發(fā)能力,而將所有計(jì)算都集中到 Client 端統(tǒng)一執(zhí) 行,勢必效率低下。
利用Coprocessor,用戶可以將求最大值的代碼部署到HBase Server端,HBase 將利用底層cluster的多個(gè)節(jié)點(diǎn)并發(fā)執(zhí)行求最大值的操作。即在每個(gè) Region 范圍內(nèi) 執(zhí)行求最大值的代碼,將每個(gè)Region的最大值在Region Server端計(jì)算出,僅僅將該 max 值返回給客戶端。在客戶端進(jìn)一步將多個(gè)Region的最大值進(jìn)一步處理而找到其中的最大值。這樣整體的執(zhí)行效率就會(huì)提高很多。
總體來看
Observer允許集群在正常的客戶端操作過程中可以有不同的行為表現(xiàn)Endpoint允許擴(kuò)展集群的能力,對客戶端應(yīng)用開放新的運(yùn)算命令Observer類似于 RDBMS 中的觸發(fā)器,主要在服務(wù)端工作Endpoint類似于 RDBMS 中的存儲過程,主要在服務(wù)端工作Observer可以實(shí)現(xiàn)權(quán)限管理、優(yōu)先級設(shè)置、監(jiān)控、ddl 控制、二級索引等功能Endpoint可以實(shí)現(xiàn) min、max、avg、sum、distinct、group by 等功能
基于上面的基本知識,Hbase二級索引的實(shí)現(xiàn)主要分為2種:
Coprocessor方案和非Coprocessor方案。
Coprocessor方案(Phoenix等)
其實(shí)從0.94版本開始,HBase官方文檔已經(jīng)提出了hbase上面實(shí)現(xiàn)二級索引的一種路徑:
基于Coprocessor(0.92版本開始引入,達(dá)到支持類似傳統(tǒng)RDBMS的觸發(fā)器的行為)開發(fā)自定義數(shù)據(jù)處理邏輯,采用數(shù)據(jù)"雙寫"(dual-write)策略,在有數(shù)據(jù)寫入同時(shí)同步到二級索引表。
雖然官方一直也沒提供內(nèi)置的支持二級索引的工具, 不過業(yè)界也有些比較知名的基于Coprocessor的開源方案:
華為的hindex: 基于0.94版本,當(dāng)年剛出來的時(shí)候比較火,但是版本較舊,看GitHub項(xiàng)目地址最近這幾年就沒更新過。
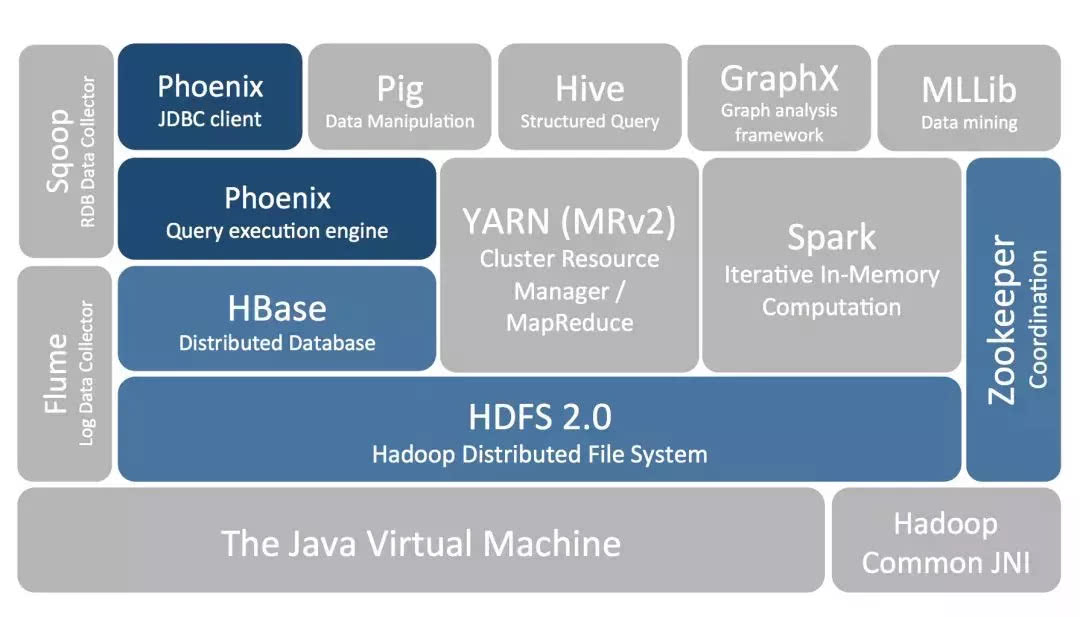
Apache Phoenix: 功能圍繞著SQL on hbase,支持和兼容多個(gè)hbase版本, 二級索引只是其中一塊功能。二級索引的創(chuàng)建和管理直接有SQL語法支持,使用起來很簡便, 該項(xiàng)目目前社區(qū)活躍度和版本更新迭代情況都比較好。
Apache Phoenix在目前開源的方案中,是一個(gè)比較優(yōu)的選擇。主打SQL on HBase, 基于SQL能完成HBase的CRUD操作,支持JDBC協(xié)議。Apache Phoenix在Hadoop生態(tài)里面位置:
Phoenix二級索引特點(diǎn)
Covered Indexes(覆蓋索引) :把關(guān)注的數(shù)據(jù)字段也附在索引表上,只需要通過索引表就能返回所要查詢的數(shù)據(jù)(列),所以索引的列必須包含所需查詢的列(SELECT的列和WHRER的列)。Functional indexes(函數(shù)索引):索引不局限于列,支持任意的表達(dá)式來創(chuàng)建索引。Global indexes(全局索引):適用于讀多寫少場景。通過維護(hù)全局索引表,所有的更新和寫操作都會(huì)引起索引的更新,寫入性能受到影響。在讀數(shù)據(jù)時(shí),Phoenix SQL會(huì)基于索引字段,執(zhí)行快速查詢。Local indexes(本地索引):適用于寫多讀少場景。在數(shù)據(jù)寫入時(shí),索引數(shù)據(jù)和表數(shù)據(jù)都會(huì)存儲在本地。在數(shù)據(jù)讀取時(shí),由于無法預(yù)先確定region的位置,所以在讀取數(shù)據(jù)時(shí)需要檢查每個(gè)region(以找到索引數(shù)據(jù)),會(huì)帶來一定性能(網(wǎng)絡(luò))開銷。
優(yōu)點(diǎn): 基于Coprocessor的方案,從開發(fā)設(shè)計(jì)的角度看,把很多對二級索引管理的細(xì)節(jié)都封裝在的Coprocessor具體實(shí)現(xiàn)類里面,這些細(xì)節(jié)對外面讀寫的人是無感知的, 簡化了數(shù)據(jù)訪問者的使用。
缺點(diǎn): 但是Coprocessor的方案入侵性比較強(qiáng), 增加了在Regionserver內(nèi)部需要運(yùn)行和維護(hù)二級索引關(guān)系表的代碼邏輯等, 對Regionserver的性能會(huì)有一定影響。
非Coprocessor方案
選擇不基于Coprocessor開發(fā),自行在外部構(gòu)建和維護(hù)索引關(guān)系也是另外一種方式。
常見的是采用底層基于Apache Lucene的Elasticsearch(下面簡稱ES)或Apache Solr ,來構(gòu)建強(qiáng)大的索引能力、搜索能力, 例如支持模糊查詢、全文檢索、組合查詢、排序等。
Lily HBase Indexer
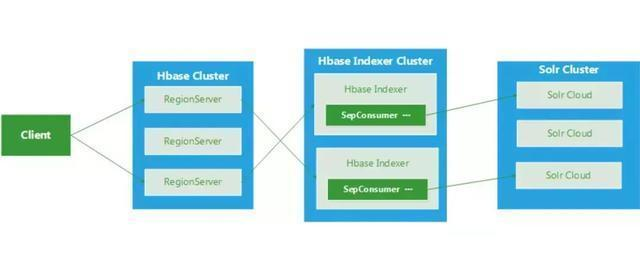
Lily HBase Indexer(也簡稱 HBase Indexer)是國外的NGDATA公司開源的基于solr的索引構(gòu)建工具,特色是其基于HBase的備份機(jī)制,開發(fā)了一個(gè)叫SEP工具,通過監(jiān)控HBase 的WAL日志(Put/Delete操作),來觸發(fā)對solr集群索引的異步更新,基本對HBase無侵入性(但必須開啟WAL)流程圖如下所示:
CDH Search
CDHSearch是Hadoop發(fā)行商Cloudera公司開發(fā)的基于solr的HBase檢索方案,部分集成了Lily HBase Indexer的功能。
下面是CDH search的核心組件交互圖, 體現(xiàn)了在單次client端查詢過程中, 核心的zookeeper和solr等的交互流程:
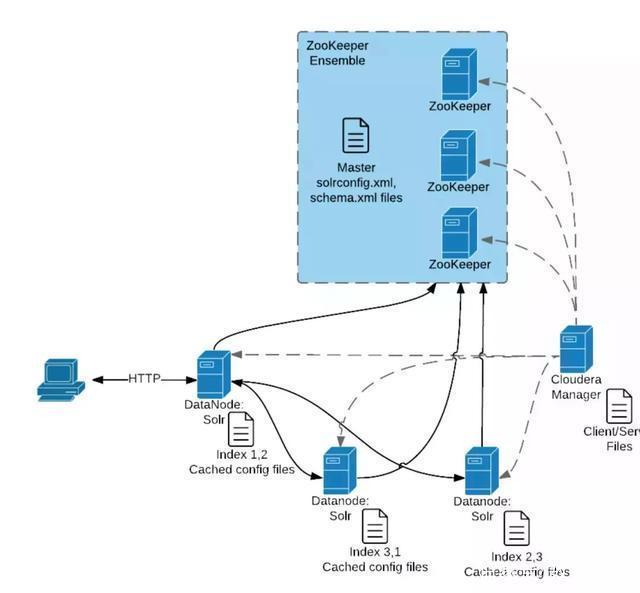
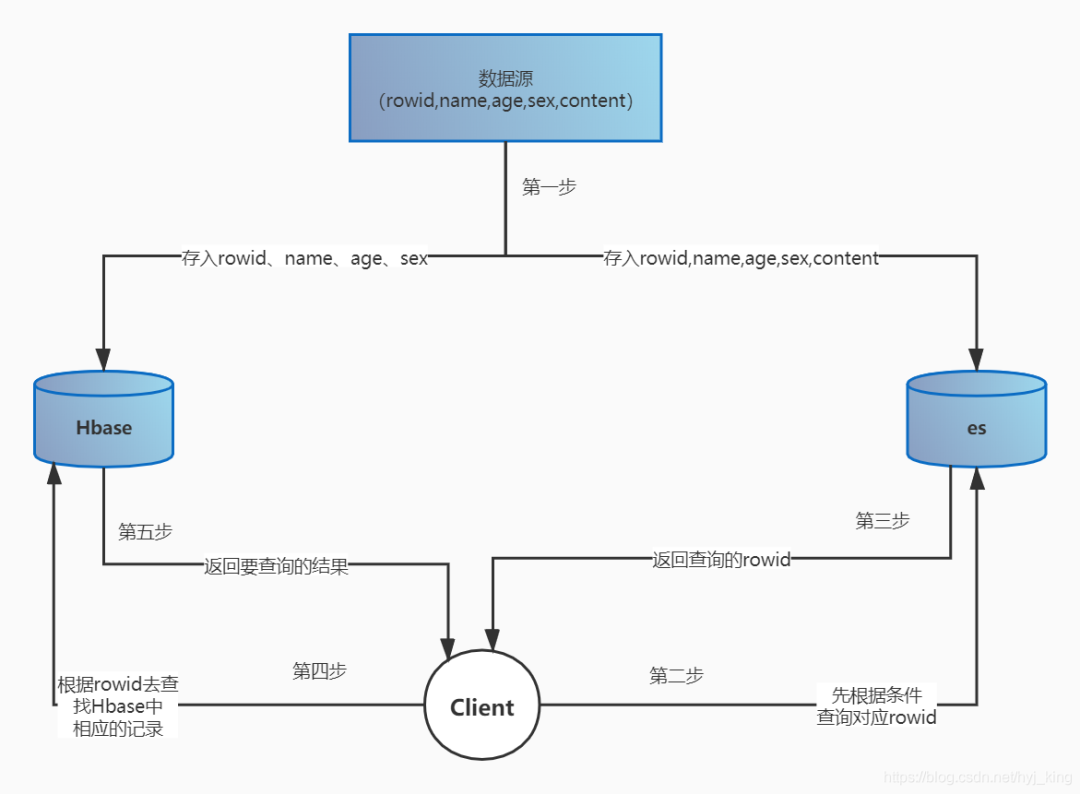
例如, Hbase結(jié)合Solr的場景:
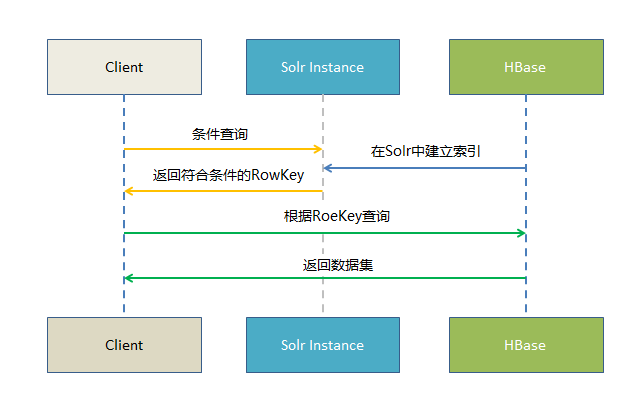
基于Solr的HBase多條件查詢原理很簡單,將HBase表中涉及條件過濾的字段和rowkey在Solr中建立索引,通過Solr的多條件查詢快速獲得符合過濾條件的rowkey值,拿到這些rowkey之后在HBASE中通過指定rowkey進(jìn)行查詢。
其他方案
對于在外部自定義構(gòu)建二級索引的方式,有自己的大數(shù)據(jù)團(tuán)隊(duì)的公司一般都會(huì)針對自己的業(yè)務(wù)場景進(jìn)行優(yōu)化,自行構(gòu)建ES/Solr的搜索集群。例如基于ES構(gòu)建海量索引和檢索能力的案例: