
七夕節(jié)也要學(xué)起來,哈希哈希哈希!
關(guān)注公眾號(hào)“彤哥讀源碼”,解鎖更多源碼、基礎(chǔ)、架構(gòu)知識(shí)!

前言
本文收錄于專輯:http://dwz.win/HjK,點(diǎn)擊解鎖更多數(shù)據(jù)結(jié)構(gòu)與算法的知識(shí)。
你好,我是彤哥。
上一節(jié),我們一起學(xué)習(xí)了,在Java中如何構(gòu)建高性能隊(duì)列,里面牽涉到很多底層的知識(shí),不知道你有Get到多少呢?!
本節(jié),我想跟著大家一起重新學(xué)習(xí)下關(guān)于哈希的一切——哈希、哈希函數(shù)、哈希表。
這三者有什么樣的愛恨情仇?
為什么Object類中需要有一個(gè)hashCode()方法?它跟equals()方法有什么關(guān)系?
如何編寫一個(gè)高性能的哈希表?
Java中的HashMap中的紅黑樹可以使用其它數(shù)據(jù)結(jié)構(gòu)替換嗎?
何為哈希?
Hash,是指把任意長度的輸入通過一定的算法變成固定長度的輸出的過程,這個(gè)輸出稱作Hash值,或者Hash碼,這個(gè)算法叫做Hash算法,或者Hash函數(shù),這個(gè)過程我們一般就稱作Hash,或者計(jì)算Hash,Hash翻譯為中文有哈希、散列、雜湊等。
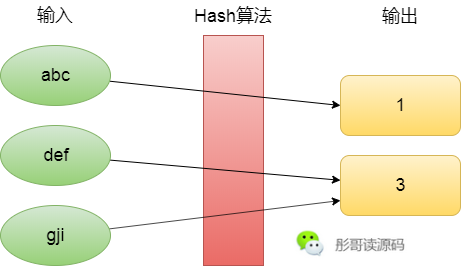
既然是固定長度的輸出,那就意味著輸入是無限多的,輸出是有限的,必然會(huì)出現(xiàn)不同的輸入可能會(huì)得到相同的輸出的情況,所以,Hash算法一般來說也是不可逆的。
那么,Hash算法有哪些用途呢?
哈希算法的用途
哈希算法,是一種廣義的算法,或者說是一種思想,它沒有一個(gè)固定的公式,只要滿足上面定義的算法,都可以稱作Hash算法。
通常來說,它具有以下用途:
加密密碼,比如,使用MD5+鹽的方式來加密密碼;
快速查詢,比如,哈希表的使用,通過哈希表能夠快速查詢元素;
數(shù)字簽名,比如,系統(tǒng)間調(diào)用加上簽名,可以防止篡改數(shù)據(jù);
文件檢驗(yàn),比如,下載騰訊游戲的時(shí)候通常都有有一個(gè)MD5值,安裝包下載下來之后計(jì)算出來一個(gè)MD5值與官方的MD5值進(jìn)行對比,就可知道下載過程中有沒有文件損壞,有沒有被篡改等;
好了,說起Hash算法,或者Hash函數(shù),在Java中,所有對象的父類Object都有一個(gè)Hash函數(shù),即hashCode()方法,為什么Object類中需要定義這么一個(gè)方法呢?
嚴(yán)格來說,Hash算法和Hash函數(shù)還是有點(diǎn)區(qū)別的,相信你能根據(jù)語境進(jìn)行區(qū)分。
讓我們來看看JDK源碼的注釋怎么說:

請看紅框的部分,翻譯一下大致為:為這個(gè)對象返回一個(gè)Hash值,它是為了更好地支持哈希表而存在的,比如HashMap。簡單點(diǎn)說,這個(gè)方法就是給HashMap等哈希表使用的。
// 默認(rèn)返回的是對象的內(nèi)部地址
public native int hashCode();
此時(shí),我們不得不提起Object類中的另一個(gè)方法——equals()。
// 默認(rèn)是直接比較兩個(gè)對象的地址是否相等
public boolean equals(Object obj) {
return (this == obj);
}
hashCode()和equals又有怎樣的糾纏呢?
通常來說,hashCode()可以看作是一種弱比較,回歸Hash的本質(zhì),將不同的輸入映射到固定長度的輸出,那么,就會(huì)出現(xiàn)以下幾種情況:
輸入相同,輸出必然相同;
輸入不同,輸出可能相同,也可能不同;
輸出相同,輸入可能相同,也可能不同;
輸出不同,輸入必然不同;
而equals()是嚴(yán)格比較兩個(gè)對象是否相等的方法,所以,如果兩個(gè)對象equals()為true,那么,它們的hashCode()一定要相等,如果不相等會(huì)怎樣呢?
如果equals()返回true,而hashCode()不相等,那么,試想將這兩個(gè)對象作為HashMap的key,它們很大可能會(huì)定位到HashMap不同的槽中,此時(shí)就會(huì)出現(xiàn)一個(gè)HashMap中插入了兩個(gè)相等的對象,這是不允許的,這也是為什么重寫了equals()方法一定要重寫hashCode()方法的原因。
比如,String這個(gè)類,我們都知道它的equals()方法是比較兩個(gè)字符串的內(nèi)容是否相等,而不是兩個(gè)字符串的地址,下面是它的equals()方法:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
所以,對于下面這兩個(gè)字符串對象,使用equals()比較它們是相等的,而它們的內(nèi)存地址并不相同:
String a = new String("123");
String b = new String("123");
System.out.println(a.equals(b)); // true
System.out.println(a == b); // false
此時(shí),如果不重寫hashCode()方法,那么,a和b將返回不同的hash碼,對于我們常常使用String作為HashMap的key將造成巨大的干擾,所以,String重寫的hashCode()方法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
這個(gè)算法也很簡單,用公式來表示為:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]。
好了,既然這里屢次提到哈希表,那我們就來看看哈希表是如何一步步進(jìn)化的。
哈希表進(jìn)化史
數(shù)組
講哈希表之前,我們先來看看數(shù)據(jù)結(jié)構(gòu)的鼻祖——數(shù)組。
數(shù)組比較簡單,我就不多說了,大家都會(huì)都懂,見下圖。

數(shù)組的下標(biāo)一般從0開始,依次往后存儲(chǔ)元素,查找指定元素也是一樣,只能從頭(或從尾)依次查找元素。
比如,要查找4這個(gè)元素,從頭開始查找的話需要查找3次。
早期的哈希表
上面講了數(shù)組的缺點(diǎn),查找某個(gè)元素只能從頭或者從尾依次查找元素,直到匹配為止,它的均衡時(shí)間復(fù)雜是O(n)。
那么,利用數(shù)組有沒有什么方法可以快速的查找元素呢?
聰明的程序員哥哥們想到一種方法,通過哈希函數(shù)計(jì)算元素的值,用這個(gè)值確定元素在數(shù)組中的位置,這樣時(shí)間復(fù)雜度就能縮短到O(1)了。
比如,有5個(gè)元素分別為3、5、4、1,把它們放入到數(shù)組之前先通過哈希函數(shù)計(jì)算位置,精確放置,而不是像簡單數(shù)組那樣依次放置元素(基于索引而不是元素值來查找位置)。
假如,這里申請的數(shù)組長度為8,我們可以造這么一個(gè)哈希函數(shù)為hash(x) = x % 8,那么最后的元素就變成了下圖這樣:

這時(shí)候我們再查找4這個(gè)元素,先算一下它的hash值為hash(4) = 4 % 8 = 4,所以直接返回4號(hào)位置的元素就可以了。
進(jìn)化的哈希表
事情看著挺完美,但是,來了一個(gè)元素13,要插入的哈希表中,算了一下它的hash值為hash(13) = 13 % 8 = 5,納尼,它計(jì)算的位置也是5,可是5號(hào)已經(jīng)被人先一步占領(lǐng)了,怎么辦呢?
這就是哈希沖突。
為什么會(huì)出現(xiàn)哈希沖突呢?
因?yàn)槲覀兩暾埖臄?shù)組是有限長度的,把無限的數(shù)字映射到有限的數(shù)組上早晚會(huì)出現(xiàn)沖突,即多個(gè)元素映射到同一個(gè)位置上。
好吧,既然出現(xiàn)了哈希沖突,那么我們就要解決它,必須干!
How to?
線性探測法
既然5號(hào)位置已經(jīng)有主了,那我元素13認(rèn)慫,我往后挪一位,我到6號(hào)位置去,這就是線性探測法,當(dāng)出現(xiàn)沖突的時(shí)候依次往后挪直到找到空位置為止。

然鵝,又來了個(gè)新元素12,算得其hash值為hash(12) = 12 % 8 = 4,What?按照這種方式,要往后移3次到7號(hào)位置才有空位置,這就導(dǎo)致了插入元素的效率很低,查找也是一樣的道理,先定位的4號(hào)位置,發(fā)現(xiàn)不是我要找的人,再接著往后移,直到找到7號(hào)位置為止。
二次探測法
使用線性探測法有個(gè)很大的弊端,沖突的元素往往會(huì)堆積在一起,比如,12號(hào)放到7號(hào)位置,再來個(gè)14號(hào)一樣沖突,接著往后再數(shù)組結(jié)尾了,再從頭開始放到0號(hào)位置,你會(huì)發(fā)現(xiàn)沖突的元素有聚集現(xiàn)象,這就很不利于查找了,同樣不利于插入新的元素。
這時(shí)候又有聰明的程序員哥哥提出了新的想法——二次探測法,當(dāng)出現(xiàn)沖突時(shí),我不是往后一位一位這樣來找空位置,而是使用原來的hash值加上i的二次方來尋找,i依次從1,2,3...這樣,直到找到空位置為止。
還是以上面的為例,插入12號(hào)元素,過程是這樣的,本文來源于公主號(hào)彤哥讀源碼:
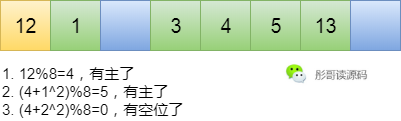
這樣就能很快地找到空位置放置新元素,而且不會(huì)出現(xiàn)沖突元素堆積的現(xiàn)象。
然鵝,又來了新元素20,你瞅瞅放哪?
發(fā)現(xiàn)放哪都放不進(jìn)去了。
研究表明,使用二次探測法的哈希表,當(dāng)放置的元素超過一半時(shí),就會(huì)出現(xiàn)新元素找不到位置的情況。
所以又引出一個(gè)新的概念——擴(kuò)容。
什么是擴(kuò)容?
已放置元素達(dá)到總?cè)萘康膞%時(shí),就需要擴(kuò)容了,這個(gè)x%時(shí)又叫作擴(kuò)容因子。
很顯然,擴(kuò)容因子越大越好,表明哈希表的空間利用率越高。
所以,很遺憾,二次探測法無法滿足我們的目標(biāo),擴(kuò)容因子太小了,只有0.5,一半的空間都是浪費(fèi)的。
這時(shí)候又到了程序員哥哥們發(fā)揮他們聰明特性的時(shí)候了,經(jīng)過996頭腦風(fēng)暴后,又想出了一種新的哈希表實(shí)現(xiàn)方式——鏈表法。
鏈表法
不就是解決沖突嘛!出現(xiàn)沖突我就不往數(shù)組中去放了,我用一個(gè)鏈表把同一個(gè)數(shù)組下標(biāo)位置的元素連接起來,這樣不就可以充分利用空間了嘛,啊哈哈哈哈~~
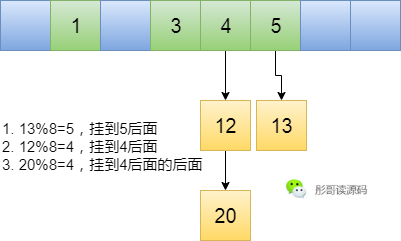
嘿嘿嘿嘿,完美△△。
真的完美嘛,我是一名黑客,我一直往里面放*%8=4的元素,然后你就會(huì)發(fā)現(xiàn)幾乎所有的元素都跑到同一個(gè)鏈表中去了,呵呵,最后的結(jié)果就是你的哈希表退化成了鏈表,查詢插入元素的效率都變成了O(n)。
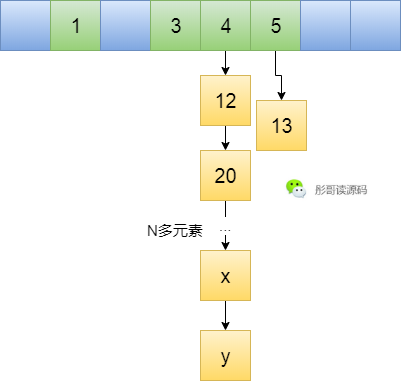
此時(shí),當(dāng)然有辦法,擴(kuò)容因子干啥滴?
比如擴(kuò)容因子設(shè)置為1,當(dāng)元素個(gè)數(shù)達(dá)到8個(gè)時(shí),擴(kuò)容成兩倍,一半的元素還在4號(hào)位置,一半的元素去到了12號(hào)位置,能緩解哈希表的壓力。
然鵝,依舊不是很完美,也只是從一個(gè)鏈表變成兩個(gè)鏈表,本文來源于公主號(hào)彤哥讀源碼。
聰明的程序員哥哥們這次開啟了一次長大9127的頭腦風(fēng)暴,終于搞出了一種新的結(jié)構(gòu)——鏈表樹法。
鏈表樹法
雖然上面的擴(kuò)容在元素個(gè)數(shù)比較少的時(shí)候能解決一部分問題,整體的查找插入效率也不會(huì)太低,因?yàn)樵貍€(gè)數(shù)少嘛。
但是,黑客還在攻擊,元素個(gè)數(shù)還在持續(xù)增加,當(dāng)增加到一定程度的時(shí)候,總會(huì)導(dǎo)致查找插入效率特別低。
所以,換個(gè)思路,既然鏈表的效率低,我把它升級(jí)一下,當(dāng)鏈表長的時(shí)候升級(jí)成紅黑樹怎么樣?
嗯,我看行,說干就干。
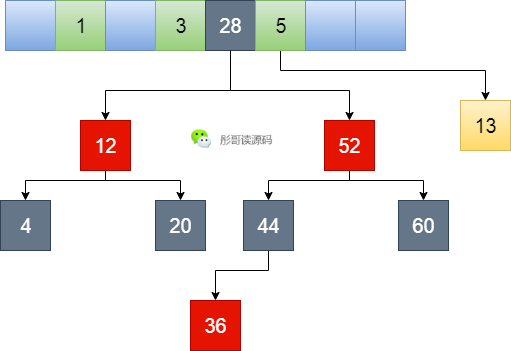
嗯,不錯(cuò)不錯(cuò),媽媽再也不怕我遭到黑客攻擊了,紅黑樹的查詢效率為O(log n),比鏈表的O(n)要高不少。
所以,到這就結(jié)束了嗎?
你想多了,每次擴(kuò)容還是要移動(dòng)一半的元素好么,一顆樹分化成兩顆樹,這樣真的好么好么好么?
程序員哥哥們太難了,這次經(jīng)過了12127的頭腦風(fēng)暴,終于想出個(gè)新玩意——一致性Hash。
一致性Hash
一致性Hash更多地是運(yùn)用在分布式系統(tǒng)中,比如說Redis集群部署了四個(gè)節(jié)點(diǎn),我們把所有的hash值定義為0~2^32個(gè),每個(gè)節(jié)點(diǎn)上放置四分之一的元素。
此處只為舉例,實(shí)際Redis集群的原理是這樣的,具體數(shù)值不是這樣的。
此時(shí),假設(shè)需要給Redis增加一個(gè)節(jié)點(diǎn),比如node5,放在node3和node4中間,這樣只需要把node3到node4中間的元素從node4移動(dòng)到node5上面就行了,其它的元素保持不變。
這樣,就增加了擴(kuò)容的速度,而且影響的元素比較少,大部分請求幾乎無感知。

好了,到這里關(guān)于哈希表的進(jìn)化歷史就講到這里了,你有沒有Get到呢?
后記
本節(jié),我們一起重新學(xué)習(xí)了關(guān)于哈希、哈希函數(shù)、哈希表相關(guān)的知識(shí),在Java中,HashMap的終極形態(tài)是以數(shù)組+鏈表+紅黑樹的形式呈現(xiàn)的。
據(jù)說,這個(gè)紅黑樹還可以換成其它的數(shù)據(jù)結(jié)構(gòu),比如跳表,你造嗎?
下一節(jié),我們就來聊聊跳表這個(gè)數(shù)據(jù)結(jié)構(gòu),并使用它來改寫HashMap,欲獲取最新推文,快點(diǎn)來關(guān)注我吧!
關(guān)注公號(hào)主“彤哥讀源碼”,解鎖更多源碼、基礎(chǔ)、架構(gòu)知識(shí)。