
五分鐘帶你學(xué)會(huì)Python網(wǎng)絡(luò)爬蟲

但不管怎樣,爬蟲技術(shù)是無罪的,還是值得我們開發(fā)人員去學(xué)習(xí)了解一下的。在學(xué)習(xí)之前,我們還是要先了解一下相關(guān)概念。

什么是爬蟲
網(wǎng)絡(luò)爬蟲:又被稱為網(wǎng)頁蜘蛛,網(wǎng)絡(luò)機(jī)器人,是一種按照一定的規(guī)則,自動(dòng)的抓取萬維網(wǎng)信息的程序或者腳本。
大數(shù)據(jù)時(shí)代,要進(jìn)行數(shù)據(jù)分析,首先要有數(shù)據(jù)源,可數(shù)據(jù)源從哪里來,花錢買,沒預(yù)算,只能從其它網(wǎng)站就行抓取。
細(xì)分下來,業(yè)內(nèi)分為兩類:爬蟲和反爬蟲。
反爬蟲:顧名思義,就是防止你來我網(wǎng)站或APP上做爬蟲的。
爬蟲工程師和反爬蟲工程師是一對(duì)相愛相殺的小伙伴,經(jīng)常因?yàn)閷?duì)方要加班寫代碼,甚至丟掉工作。比如下面這張圖,大家用心感受一下:
爬蟲的基本原理
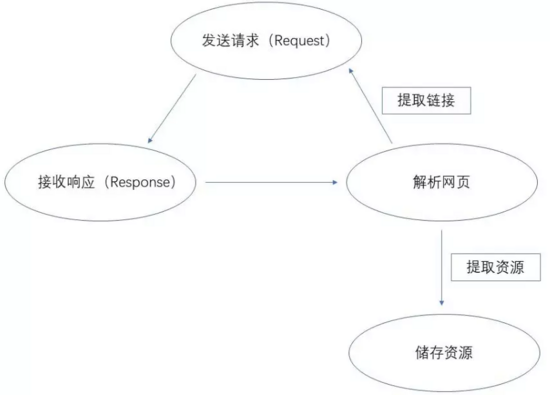
如上圖所示,爬蟲的第一個(gè)步驟就是對(duì)所要爬取的網(wǎng)頁進(jìn)行請(qǐng)求,以獲取其相應(yīng)返回的結(jié)果,然后在使用一些方法,對(duì)響應(yīng)內(nèi)容解析,提取想要的內(nèi)容資源,最后,將提取出來的資源保存起來。
爬蟲工具和語言選擇
一、爬蟲工具
工欲善其事必先利其器的道理相信大家都懂的,想要提升效率,一些常用的工具是必不可少的,以下就是個(gè)人推薦的幾款工具:Chrome、Charles、Postman、Xpath-Helper
二、爬蟲語言
目前主流的Java、Node.js、C#、python等開發(fā)語言,都可以實(shí)現(xiàn)爬蟲。
所以,在語言的選擇上,你可以選擇最擅長的語言來進(jìn)行爬蟲腳本的編寫。
目前爬蟲這塊用的最多的是python,因?yàn)閜ython語法簡潔,方便修改,而且python里有多爬蟲相關(guān)的庫,拿過來就可以使用,網(wǎng)上的資料也比較多。
Python 爬蟲Selenium庫的使用
一、基礎(chǔ)知識(shí)
首先要使用python語言做爬蟲,需要學(xué)習(xí)一下python的基礎(chǔ)知識(shí),還有HTML、CSS、JS、Ajax等相關(guān)的知識(shí)。這里,列出python中一些與爬蟲相關(guān)的庫和框架:
1.1、urllib和urllib2
1.2、Requests
1.3、Beautiful Soup
1.4、Xpath語法與lxml庫
1.5、PhantomJS
1.6、Selenium
1.7、PyQuery
1.8、Scrapy
......
復(fù)制代碼因?yàn)闀r(shí)間有限,本文只介紹Selenium庫的爬蟲技術(shù),像自動(dòng)化測(cè)試,還有其它庫和框架的資料,感興趣的小伙伴可以自行學(xué)習(xí)。
二、Selenium基礎(chǔ)
2.1、Selenium是一個(gè)用于測(cè)試網(wǎng)站的自動(dòng)化測(cè)試工具,支持各種瀏覽器包括Chrome、Firefox、Safari等主流界面瀏覽器,同時(shí)也支持phantomJS無界面瀏覽器。
2.2、安裝方式
pip install Selenium
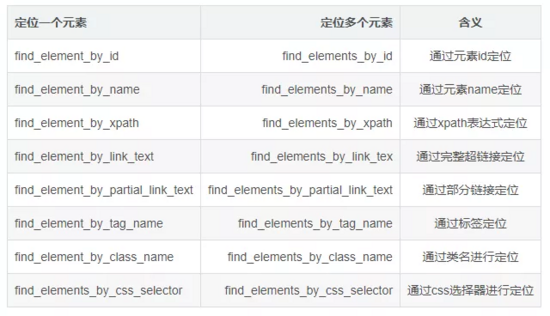
復(fù)制代碼2.3、Selenium定位元素的8種方式
爬蟲實(shí)例演示
本案例的需求是:抓取豆瓣電影Top250電影信息。
url:https://movie.douban.com/top250
復(fù)制代碼
開發(fā)工具采用PyCharm,數(shù)據(jù)庫采用sqlServer2012。
數(shù)據(jù)庫表腳本:
CREATE TABLE Movies
(
Id INT PRIMARY KEY IDENTITY(1,1),
Name NVARCHAR(20) NOT NULL DEFAULT '',
EName NVARCHAR(50) NOT NULL DEFAULT '',
OtherName NVARCHAR(50) NOT NULL DEFAULT '',
Info NVARCHAR(600) NOT NULL DEFAULT '',
Score NVARCHAR(5) NOT NULL DEFAULT '0',
Number NVARCHAR(20) NOT NULL DEFAULT '0',
Remark NVARCHAR(200) NOT NULL DEFAULT '',
createUser INT NOT NULL DEFAULT 0,
createTime DATETIME DEFAULT GETDATE(),
updateUser INT NOT NULL DEFAULT 0,
updateTime DATETIME DEFAULT GETDATE()
);
復(fù)制代碼爬蟲的第一步,分析url,經(jīng)過分析,豆瓣電影Top250頁面的url有一定的規(guī)則:
每頁顯示25條電影信息,url規(guī)則如下,以此類推。

接著,再對(duì)網(wǎng)頁源碼進(jìn)行分析:

最后,編寫爬蟲腳本:
import importlib
import random
import sys
import time
import pymssql
from selenium import webdriver
from selenium.webdriver.common.by import By
# 反爬蟲設(shè)置--偽造IP和請(qǐng)求
ip = ['111.155.116.210', '115.223.217.216', '121.232.146.39', '221.229.18.230', '115.223.220.59', '115.223.244.146',
'180.118.135.26', '121.232.199.197', '121.232.145.101', '121.31.139.221', '115.223.224.114']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
'X-Requested-With': 'XMLHttpRequest',
'X-Forwarded-For': ip[random.randint(0, 10)],
'Host': ip[random.randint(0, 10)]
}
importlib.reload(sys)
try:
conn = pymssql.connect(host="127.0.0.1", user="sa", password="123", database="MySchool",charset="utf8")
except pymssql.OperationalError as msg:
print("error: Could not Connection SQL Server!please check your dblink configure!")
sys.exit()
else:
cur = conn.cursor()
def main():
for n in range(0, 10):
count = n*25
url = 'https://movie.douban.com/top250?start='+str(count)
j = 1
# if(n == 7):
# j = 5
for i in range(j, 26):
driver = webdriver.PhantomJS(desired_capabilities=headers) # 封裝瀏覽器信息
driver.set_page_load_timeout(15)
driver.get(url) # 加載網(wǎng)頁
# data = driver.page_source # 獲取網(wǎng)頁文本
# driver.save_screenshot('1.png') # 截圖保存
name = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/a/span")[0].text.replace('\'', '')
ename = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/a/span")[1].text.replace("/", "").replace(" ", "").replace('\'', '')
try:
otherName = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/a/span")[2].text.lstrip(' / ').replace("/", "|").replace(" ", "").replace('\'', '')
except:
otherName = ''
info = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/p")[0].text.replace("/", "|").replace(" ", "").replace('\'', '')
score = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/div/span[2]")[0].text.replace('\'', '')
number = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/div/span[4]")[0].text.replace("人評(píng)價(jià)", "").replace('\'', '')
remark = driver.find_elements(By.XPATH, "http://ol/li["+str(i)+"]/div/div/div/p/span")[0].text.replace('\'', '')
sql = "insert into Movies(Name,EName,OtherName,Info,Score,Number,Remark) values('"+name + \
"','"+ename+"','"+otherName+"','"+info + \
"','"+score+"','"+number+"','"+remark+"') "
try:
cur.execute(sql)
conn.commit()
print("第"+str(n)+"頁,第"+str(i)+"條電影信息新增成功")
time.sleep(30)
except:
conn.rollback()
print("新增失敗:"+sql)
driver.quit()
if __name__ == '__main__':
main()
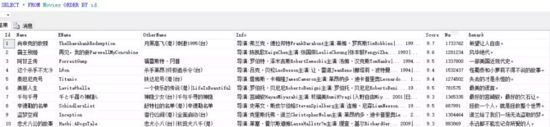
復(fù)制代碼成果展示:
搜索下方加老師微信
老師微信號(hào):XTUOL1988【切記備注:學(xué)習(xí)Python】
領(lǐng)取Python web開發(fā),Python爬蟲,Python數(shù)據(jù)分析,人工智能等精品學(xué)習(xí)課程。帶你從零基礎(chǔ)系統(tǒng)性的學(xué)好Python!
*聲明:本文于網(wǎng)絡(luò)整理,版權(quán)歸原作者所有,如來源信息有誤或侵犯權(quán)益,請(qǐng)聯(lián)系我們刪除或授權(quán)

