
實踐指南 | 圖像分類中常用的tricks

極市導(dǎo)讀
?本文匯集了11種圖像分類中的常用技巧。?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
1 Warmup
學(xué)習(xí)率是神經(jīng)網(wǎng)絡(luò)訓(xùn)練中最重要的超參數(shù)之一,針對學(xué)習(xí)率的技巧有很多。Warmup是在ResNet中提到的一種學(xué)習(xí)率預(yù)熱的方法。由于剛開始訓(xùn)練時模型的權(quán)重(weights)是隨機初始化的,此時選擇一個較大的學(xué)習(xí)率,可能會帶來模型的不穩(wěn)定。
學(xué)習(xí)率預(yù)熱就是在剛開始訓(xùn)練的時候先使用一個較小的學(xué)習(xí)率,訓(xùn)練一些epoches或iterations,等模型穩(wěn)定時再修改為預(yù)先設(shè)置的學(xué)習(xí)率進行訓(xùn)練。ResNet論文中使用一個110層的ResNet在cifar10上訓(xùn)練時,先用0.01的學(xué)習(xí)率訓(xùn)練直到訓(xùn)練誤差低于80%(大概訓(xùn)練了400個iterations),然后使用0.1的學(xué)習(xí)率進行訓(xùn)練。
上述的方法是constant warmup,18年Facebook又針對上面的warmup進行了改進,因為從一個很小的學(xué)習(xí)率一下變?yōu)楸容^大的學(xué)習(xí)率可能會導(dǎo)致訓(xùn)練誤差突然增大。論文提出了gradual warmup來解決這個問題,即從最開始的小學(xué)習(xí)率開始,每個iteration增大一點,直到最初設(shè)置的比較大的學(xué)習(xí)率。
2 Linear scaling learning rate
在凸優(yōu)化問題中,隨著批量的增加,收斂速度會降低,神經(jīng)網(wǎng)絡(luò)也有類似的實證結(jié)果。隨著batch size的增大,處理相同數(shù)據(jù)量的速度會越來越快,但是達到相同精度所需要的epoch數(shù)量越來越多。也就是說,使用相同的epoch時,大batch size訓(xùn)練的模型與小batch size訓(xùn)練的模型相比,驗證準確率會減小。
上面提到的gradual warmup是解決此問題的方法之一。另外,linear scaling learning rate也是一種有效的方法。在mini-batch SGD訓(xùn)練時,梯度下降的值是隨機的,因為每一個batch的數(shù)據(jù)是隨機選擇的。增大batch size不會改變梯度的期望,但是會降低它的方差。也就是說,大batch size會降低梯度中的噪聲,所以我們可以增大學(xué)習(xí)率來加快收斂。
具體做法很簡單,比如ResNet原論文]中,batch size為256時選擇的學(xué)習(xí)率是0.1,當我們把batch size變?yōu)橐粋€較大的數(shù)b時,學(xué)習(xí)率應(yīng)該變?yōu)?0.1 × b/256。
3 Cosine learning rate decay
在warmup之后的訓(xùn)練過程中,學(xué)習(xí)率不斷衰減是一個提高精度的好方法。其中有step decay和cosine decay等,前者是隨著epoch增大學(xué)習(xí)率不斷減去一個小的數(shù),后者是讓學(xué)習(xí)率隨著訓(xùn)練過程曲線下降。對于cosine decay,假設(shè)總共有T個batch(不考慮warmup階段),在第t個batch時,學(xué)習(xí)率η_t為:
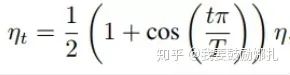
這里,η代表初始設(shè)置的學(xué)習(xí)率。這種學(xué)習(xí)率遞減的方式稱之為cosine decay。
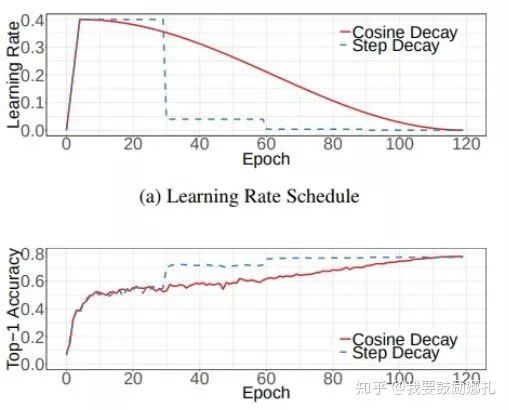
下面是帶有warmup的學(xué)習(xí)率衰減的可視化圖[4]。其中,圖(a)是學(xué)習(xí)率隨epoch增大而下降的圖,可以看出cosine decay比step decay更加平滑一點。圖(b)是準確率隨epoch的變化圖,兩者最終的準確率沒有太大差別,不過cosine decay的學(xué)習(xí)過程更加平滑。
4 Label-smoothing
在分類問題中,我們的最后一層一般是全連接層,然后對應(yīng)標簽的one-hot編碼,即把對應(yīng)類別的值編碼為1,其他為0。這種編碼方式和通過降低交叉熵損失來調(diào)整參數(shù)的方式結(jié)合起來,會有一些問題。這種方式會鼓勵模型對不同類別的輸出分數(shù)差異非常大,或者說,模型過分相信它的判斷。但是,對于一個由多人標注的數(shù)據(jù)集,不同人標注的準則可能不同,每個人的標注也可能會有一些錯誤。模型對標簽的過分相信會導(dǎo)致過擬合。
標簽平滑(Label-smoothing regularization,LSR)是應(yīng)對該問題的有效方法之一,它的具體思想是降低我們對于標簽的信任,例如我們可以將損失的目標值從1稍微降到0.9,或者將從0稍微升到0.1。標簽平滑最早在inception-v2中被提出,它將真實的概率改造為:
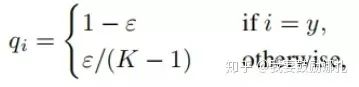
其中,ε是一個小的常數(shù),K是類別的數(shù)目,y是圖片的真正的標簽,i代表第i個類別,q_i是圖片為第i類的概率。
總的來說,LSR是一種通過在標簽y中加入噪聲,實現(xiàn)對模型約束,降低模型過擬合程度的一種正則化方法。
5 Random image cropping and patching
Random image cropping and patching 方法隨機裁剪四個圖片的中部分,然后把它們拼接為一個圖片,同時混合這四個圖片的標簽。RICAP在caifar10上達到了2.19%的錯誤率。
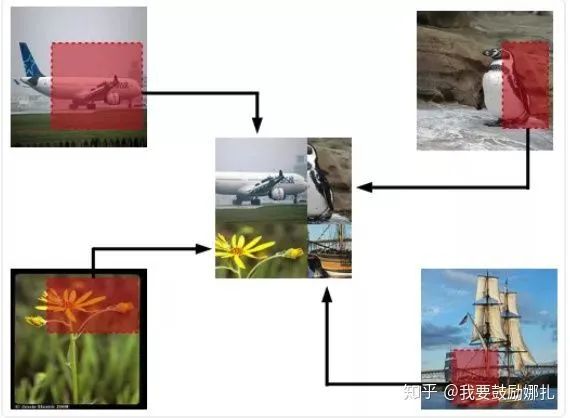
如下圖所示,Ix, Iy是原始圖片的寬和高。w和h稱為boundary position,它決定了四個裁剪得到的小圖片的尺寸。w和h從beta分布Beta(β, β)中隨機生成,β也是RICAP的超參數(shù)。最終拼接的圖片尺寸和原圖片尺寸保持一致。
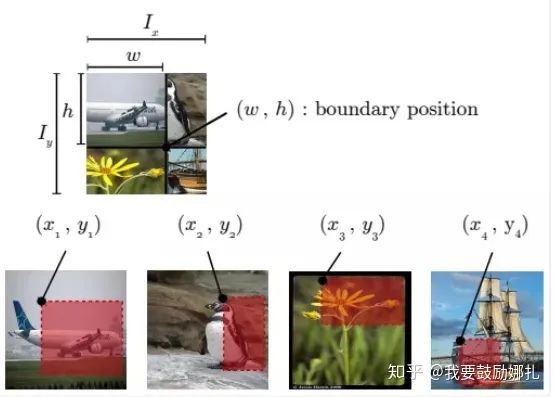
6 Knowledge Distillation
提高幾乎所有機器學(xué)習(xí)算法性能的一種非常簡單的方法是在相同的數(shù)據(jù)上訓(xùn)練許多不同的模型,然后對它們的預(yù)測進行平均。但是使用所有的模型集成進行預(yù)測是比較麻煩的,并且可能計算量太大而無法部署到大量用戶。Knowledge Distillation(知識蒸餾)方法就是應(yīng)對這種問題的有效方法之一。
**在知識蒸餾方法中,我們使用一個教師模型來幫助當前的模型(學(xué)生模型)訓(xùn)練。**教師模型是一個較高準確率的預(yù)訓(xùn)練模型,因此學(xué)生模型可以在保持模型復(fù)雜度不變的情況下提升準確率。比如,可以使用ResNet-152作為教師模型來幫助學(xué)生模型ResNet-50訓(xùn)練。在訓(xùn)練過程中,我們會加一個蒸餾損失來懲罰學(xué)生模型和教師模型的輸出之間的差異。
給定輸入,假定p是真正的概率分布,z和r分別是學(xué)生模型和教師模型最后一個全連接層的輸出。之前我們會用交叉熵損失l(p,softmax(z))來度量p和z之間的差異,這里的蒸餾損失同樣用交叉熵。所以,使用知識蒸餾方法總的損失函數(shù)是
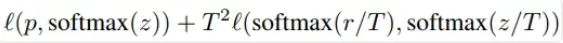
上式中,第一項還是原來的損失函數(shù),第二項是添加的用來懲罰學(xué)生模型和教師模型輸出差異的蒸餾損失。其中,T是一個溫度超參數(shù),用來使softmax的輸出更加平滑的。實驗證明,用ResNet-152作為教師模型來訓(xùn)練ResNet-50,可以提高后者的準確率。
7 Cutout
Cutout是一種新的正則化方法。原理是在訓(xùn)練時隨機把圖片的一部分減掉,這樣能提高模型的魯棒性。它的來源是計算機視覺任務(wù)中經(jīng)常遇到的物體遮擋問題。通過cutout生成一些類似被遮擋的物體,不僅可以讓模型在遇到遮擋問題時表現(xiàn)更好,還能讓模型在做決定時更多地考慮環(huán)境(context)。
效果如下圖,每個圖片的一小部分被cutout了。

8 Random erasing
Random erasing其實和cutout非常類似,也是一種模擬物體遮擋情況的數(shù)據(jù)增強方法。區(qū)別在于,cutout是把圖片中隨機抽中的矩形區(qū)域的像素值置為0,相當于裁剪掉,random erasing是用隨機數(shù)或者數(shù)據(jù)集中像素的平均值替換原來的像素值。而且,cutout每次裁剪掉的區(qū)域大小是固定的,Random erasing替換掉的區(qū)域大小是隨機的。

9 Mixup training
Mixup是一種新的數(shù)據(jù)增強的方法。Mixup training,就是每次取出2張圖片,然后將它們線性組合,得到新的圖片,以此來作為新的訓(xùn)練樣本,進行網(wǎng)絡(luò)的訓(xùn)練,如下公式,其中x代表圖像數(shù)據(jù),y代表標簽,則得到的新的xhat, yhat。
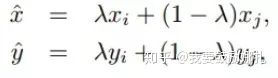
其中,λ是從Beta(α, α)隨機采樣的數(shù),在[0,1]之間。在訓(xùn)練過程中,僅使用(xhat, yhat)。
Mixup方法主要增強了訓(xùn)練樣本之間的線性表達,增強網(wǎng)絡(luò)的泛化能力,不過mixup方法需要較長的時間才能收斂得比較好。
10 AdaBound
AdaBound,按照作者的說法,會讓你的訓(xùn)練過程像adam一樣快,并且像SGD一樣好。
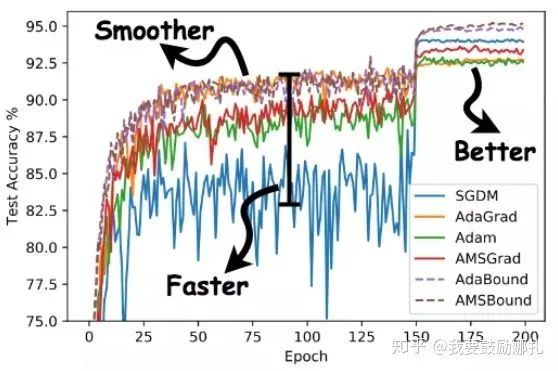
如下圖所示,使用AdaBound會收斂速度更快,過程更平滑,結(jié)果更好。
另外,這種方法相對于SGD對超參數(shù)的變化不是那么敏感,也就是說魯棒性更好。但是,針對不同的問題還是需要調(diào)節(jié)超參數(shù)的,只是所用的時間可能變少了。
當然,AdaBound還沒有經(jīng)過普遍的檢驗,也有可能只是對于某些問題效果好。
11 ?AutoAugment
數(shù)據(jù)增強在圖像分類問題上有很重要的作用,但是增強的方法有很多,并非一股腦地用上所有的方法就是最好的。那么,如何選擇最佳的數(shù)據(jù)增強方法呢?AutoAugment就是一種搜索適合當前問題的數(shù)據(jù)增強方法的方法。該方法創(chuàng)建一個數(shù)據(jù)增強策略的搜索空間,利用搜索算法選取適合特定數(shù)據(jù)集的數(shù)據(jù)增強策略。此外,從一個數(shù)據(jù)集中學(xué)到的策略能夠很好地遷移到其它相似的數(shù)據(jù)集上。
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標檢測論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
