
實時 OLAP, 從 0 到 1
業(yè)務背景
機遇挑戰(zhàn)
架構(gòu)演進
架構(gòu)優(yōu)化
未來展望
一、業(yè)務背景

二、機遇挑戰(zhàn)
不能做到實時處理數(shù)據(jù)
存在單點問題,比方某一條鏈路突然掛掉,此時整個環(huán)節(jié)都會出現(xiàn)問題

效率,效率問題是非常常見的。我們的表大概在幾十億量級,跑這種 SQL ,可能需要很長時間, SQL 查詢比較慢,嚴重影響統(tǒng)計效率。
實時,數(shù)據(jù)不是實時的,需要等到一定的時間才會更新,如昨天的數(shù)據(jù)今天才能看到。
監(jiān)控,實時需求,如實時風控,每當區(qū)塊鏈出現(xiàn)一個區(qū)塊,我們就要對它進行分析,但是區(qū)塊出現(xiàn)的時間是隨機的。缺乏完整的監(jiān)控,有時候作業(yè)突然壞了,或者是沒達到指標,我們不能及時知道。
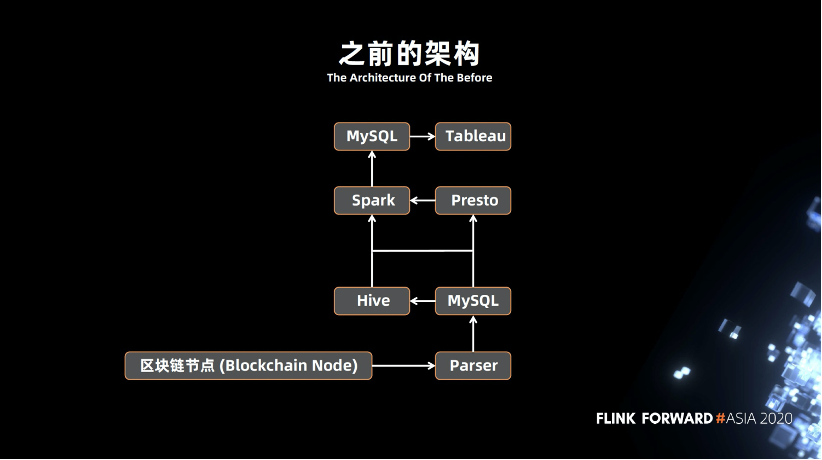
三、架構(gòu)演進

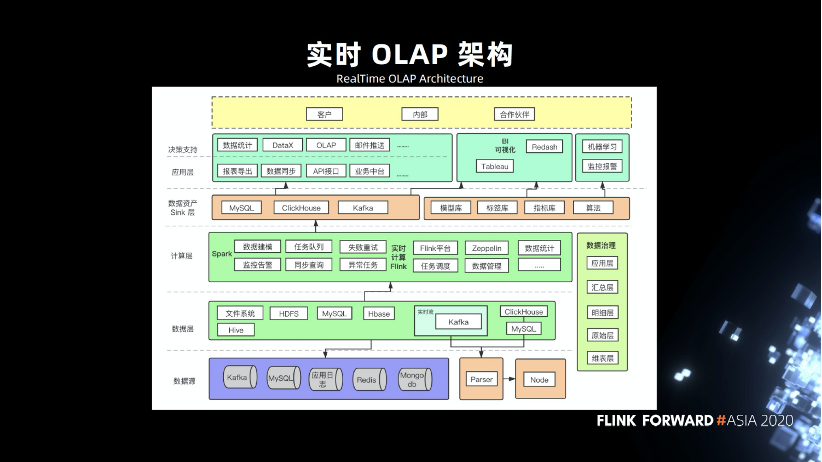


為什么演進這么慢,因為區(qū)塊鏈的發(fā)展還沒有達到一定量級,無法像某些大公司有上億級別或者 PB 級別的數(shù)據(jù)量。我們的數(shù)據(jù)量沒有那么大,區(qū)塊鏈是一個新鮮的事物,沒有一定的歷史。另外的問題就是資源問題,由于人員不足,人員成本上也有所控制。
剛才講的架構(gòu),我們總結(jié)了它適合怎樣的企業(yè)。首先是有一定的數(shù)據(jù)規(guī)模,比說某個企業(yè) MySQL 只有幾千萬的數(shù)據(jù),用 MySQL , Redis , MongoDB 都可以,就不適合這套架構(gòu)。其次是需要一定的成本控制,這一整套成本算下來比 Spark 那一套會低很多。要有技術(shù)儲備,要開發(fā)了解相關(guān)的東西。
區(qū)塊鏈數(shù)據(jù)的特點。數(shù)據(jù)量比較多,歷史數(shù)據(jù)基本上是不變的,實時數(shù)據(jù)相對來說是更有價值的,數(shù)據(jù)和時間存在一定的關(guān)聯(lián)。
適合的是最好的,不要盲目追求新技術(shù),比如數(shù)據(jù)湖,雖然好,但是我們的數(shù)據(jù)量級實際上用不到。 我們不考慮建設(shè)技術(shù)中臺,我們的公司規(guī)模是中小型,部門溝通起來比較容易,沒有太多的隔閡,沒有發(fā)展到一定的組織規(guī)模,所以我們沒有打算發(fā)展技術(shù)中臺,數(shù)據(jù)中臺,不盲目跟風上中臺。 我們達到的效果是縮短了開發(fā)的時長,減少作業(yè)的運行時間。
四、架構(gòu)優(yōu)化

自定義 sink 。
ClickHouse 要一次性插入很多數(shù)據(jù),需要控制好寫入的頻次,優(yōu)先寫入本地表,耗時比較多。
我們主要用在智能合約的交易分析,新增的數(shù)據(jù)比較多,比較頻繁,每幾秒就有很多數(shù)據(jù)。數(shù)據(jù)上關(guān)聯(lián)比較多。

批量導入時失敗和容錯。
Upsert 的優(yōu)化。
開發(fā)了常用 UDF ,大家知道 ClickHouse 官方是不支持 UDF 的嗎?只能通過打補丁,保證 ClickHouse 不會掛。
我們也在做一些開源方面的跟進,做一些補丁方面的嘗試,把我們業(yè)務上,技術(shù)上常用的 UDF ,集合在一起。
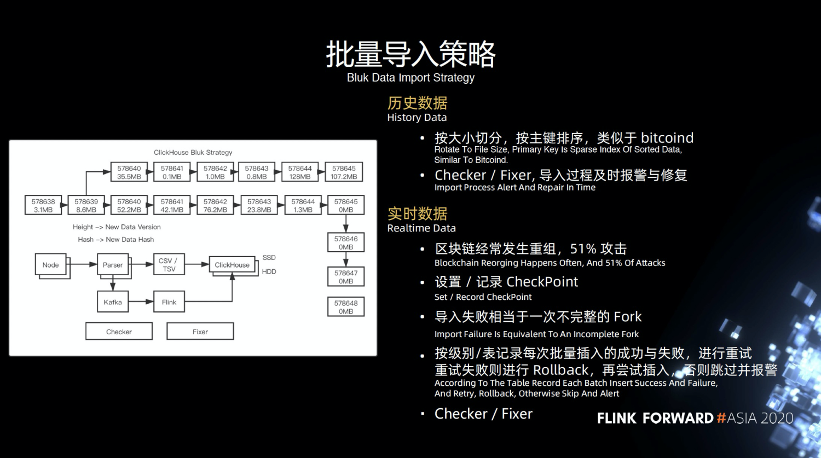
歷史數(shù)據(jù),可以認為是一種冷數(shù)據(jù),相對來說不會經(jīng)常改變。導入的時候按照大小切分,按照主鍵排序,類似于 bitcoind ,底層的 Checker 和 Fixer 工作,導入過程中及時進行報警和修復。比如導入某一數(shù)據(jù)失敗了,如何更好的及時發(fā)現(xiàn),之前就只能人肉監(jiān)控。
實時數(shù)據(jù),我們需要不斷解析實時數(shù)據(jù),大家可能對重組,51%的概念不太熟悉,這里簡單講一下,上圖最長的鏈也是最重要的鏈,它上面的一條鏈是一個重組并且分叉的一條鏈,當有一個攻擊者或者礦工去挖了上面的鏈,最終的結(jié)果會導致這條鏈被廢棄掉,拿不到任何獎勵。

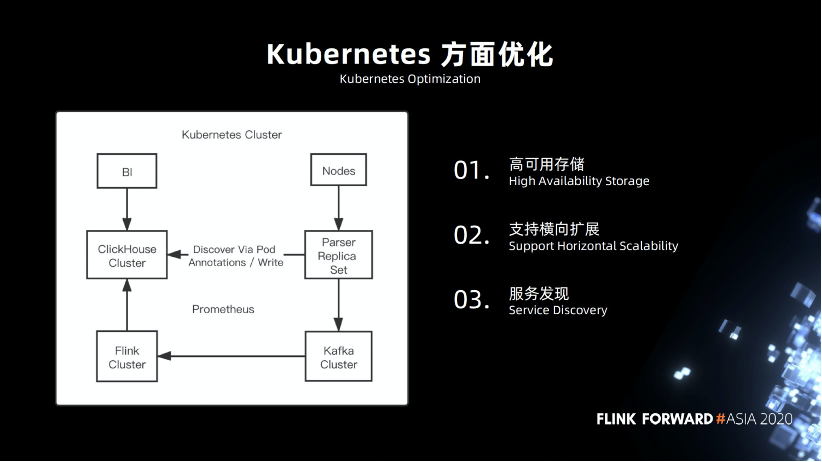
高可用的存儲,在早期的時候,我們就盡可能的將服務部署在 Kubernetes,包括 Flink 集群,基礎(chǔ)業(yè)務組件,幣種節(jié)點,ClickHouse 節(jié)點,在這方面 ClickHouse 做的比較好,方便兼容,支持高可用操作。
支持橫向擴展。
服務發(fā)現(xiàn)方面,我們做了一些定制。

采用 Final 進行查詢,等待數(shù)據(jù)合并完成。
在數(shù)據(jù)方面的話,實現(xiàn)冪等性,保證唯一性,通過主鍵排序,整理出來一組數(shù)據(jù),再寫入。
寫入異常時就及時修復和回填,保證最終一致性。
五、未來展望

擴展更多的業(yè)務和數(shù)據(jù)。之前我們的業(yè)務模式比較單一,只有數(shù)據(jù)方面的統(tǒng)計,之后會挖掘更多信息,包括鏈上追蹤,金融方面的審計。
賺更多的錢,盡可能的活下去,我們才能去做更多的事情,去探索更多的盈利模式。
跟進 Flink 和 PyFlink 的生態(tài),積極參與開源的工作,優(yōu)化相關(guān)作業(yè)。探索多 sink 方面的工作,原生 Kubernetes 的實踐。

數(shù)據(jù)建模的規(guī)范,規(guī)定手段,操作。
Flink 和機器學習相結(jié)合。
爭取拿到實時在線訓練的業(yè)務,F(xiàn)link 做實時監(jiān)控,是非常不錯的選擇。大公司都已經(jīng)有相關(guān)的實踐。包括報警等操作。
總的來說的話,路漫漫其修遠兮,使用 Flink 真不錯。更多 Flink 相關(guān)技術(shù)交流,可掃碼加入社區(qū)釘釘大群~
 戳我,回顧作者分享視頻!
戳我,回顧作者分享視頻!