
跨平臺代碼的3種組織方式
一、緣起
二、問題引入
三、三個解決方案
四、One More Thing
一、緣起
在上一篇文章中,分享了一個跨平臺的頭文件是長成什么樣子的,這個頭文件對于 windows 平臺下更有意義一些,因為要處理庫函數(shù)的導入和導出聲明(dllexport、dllimport)。
其實,可以在這個頭文件的基礎上繼續(xù)擴充,以達到更細粒度的控制。例如:對編譯器的判斷、對編譯器版本的判斷等等。
同樣的,我們在源代碼中也會遇到一些跨平臺的問題。不同的功能,在不同的平臺下,實現(xiàn)方式是不一樣的,如何對這些平臺相關的代碼進行組織呢?這篇文章就來聊聊這個問題。
PS: 文末提供了一個簡單的、跨平臺構建代碼示例。
二、問題引入
假設我們寫一個庫,需要實現(xiàn)一個函數(shù):獲取系統(tǒng)時間戳。作為實現(xiàn)庫的作者,你決定提供下面的 API 函數(shù):
t_time.h: 聲明接口函數(shù)(t_get_timestamp);
t_time.c:實現(xiàn)接口函數(shù);
下面的任務就是在函數(shù)實現(xiàn)中,通過不同下的 C 庫或系統(tǒng)調用,來計算系統(tǒng)當前的時間戳。
在 Linux 平臺下,可以通過下面這段代碼實現(xiàn):
struct timeval tv;gettimeofday(&tv, null);return tv.tv_sec * 1000 + tv.tv_usec / 1000;
在 Windows 平臺下,可以通過下面這段代碼實現(xiàn):
struct timeb tp;ftime(&tp);return tp.time *1000 + tp.millitm;
那么問題來了:怎么把這兩段平臺相關的代碼組織在一起?下面就介紹 3 種不同的組織方式,沒有優(yōu)劣之分,每個人都有不同的習慣,選擇適合自己和團隊的方式就行。
此外,這個示例中只有 1 個函數(shù),而且比較短小。如果這種跨平臺的函數(shù)很多、而且都很長,也許你的選擇又不一樣了。
三、三個解決方案
方案1
直接在接口函數(shù)中,通過平臺宏定義來區(qū)分不同平臺。
平臺宏定義(T_LINUX, T_WINDOWS),是在上一篇文章中介紹的,通過操作系統(tǒng)、編譯器來判斷當前的平臺是什么,然后定義出統(tǒng)一的平臺宏定義為我們自己所用:
代碼組織方式如下:
int64 t_get_timestamp(){int64 ts = -1;struct timeval tv;gettimeofday(&tv, null);ts = tv.tv_sec * 1000 + tv.tv_usec / 1000;struct timeb tp;ftime(&tp);ts = tp.time;ts = ts *1000 + tp.millitm;return ts;}
這樣的方式,把所有平臺代碼全部放在 API 函數(shù)中了,通過平臺宏定義進行條件編譯,因為代碼比較短小,看起來還不錯。
方案2
把不同平臺的實現(xiàn)代碼放在獨立的文件中,然后通過 #include 預處理符號,在 API 函數(shù)中,把平臺相關的代碼引入進來。
也就是再增加 2 個文件:
t_time_linux.c:存放 Linux 平臺下的代碼實現(xiàn);
t_time_windows.c:存放 Windows 平臺下的代碼實現(xiàn);
(1) t_time_linux.c
int64 t_get_timestamp(){int64 ts = -1;struct timeval tv;gettimeofday(&tv, null);ts = tv.tv_sec * 1000 + tv.tv_usec / 1000;return ts;}
(2) t_time_windows.c
int64 t_get_timestamp(){int64 ts = -1;struct timeb tp;ftime(&tp);ts = tp.time;ts = ts *1000 + tp.millitm;return ts;}
(3) t_time.c
這個文件不做任何事情,僅僅是 include 其他的代碼。
int64 t_get_timestamp(){return -1;}
有些人比較反感這樣的組織方式,一般都是 include 一個 .h 頭文件,而這里通過平臺宏定義,include 不同的 .c 源文件,感覺怪怪的?!
其實,也有一些開源庫是這么干的,比如下面:
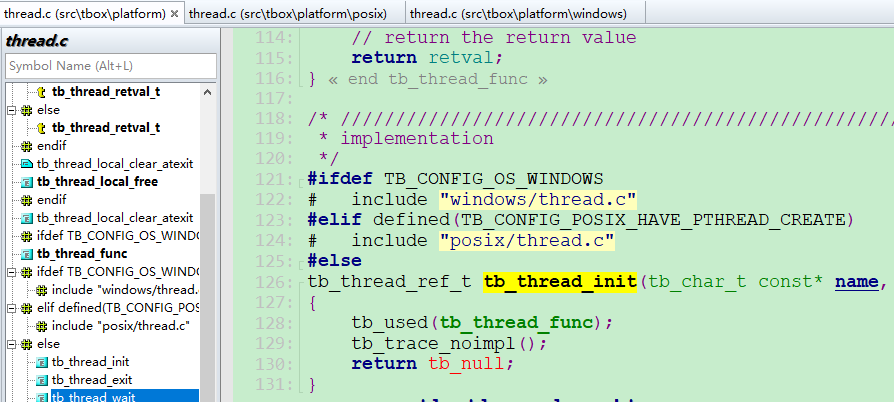
方案3
在上面方案2中,是在源代碼中填入不同平臺的實現(xiàn)代碼。
其實可以換一種思路,既然已經(jīng)根據(jù)平臺的不同、放在不同的文件中了,那么可以讓不同的源文件加入到編譯過程中就可以了。
測試代碼是使用 cmake 工具來構建的,因此可以編輯 CMakelists.txt 文件,來控制參與編譯的源文件。
CMakelists.txt 文件部分內容
# 設置平臺變量if (CMAKE_SYSTEM_NAME MATCHES "Linux")set(PLATFORM linux)elseif (CMAKE_SYSTEM_NAME MATCHES "Windows")set(PLATFORM windows)endif()# 根據(jù)平臺變量,來編譯不同的源文件set(LIBSRC t_time_${PLATFORM}.c)
這樣的組織方式,感覺代碼更“干凈”一些。同樣的,我們也可以看到一些開源庫也是這么做的:
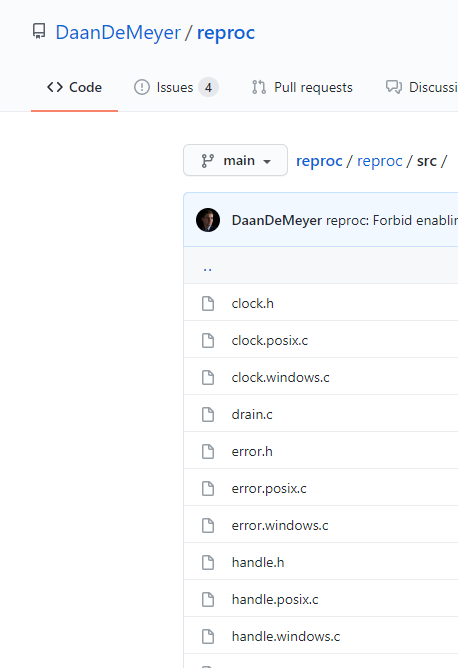

四、One More Thing
為了文章的篇幅,以上只是貼了代碼的片段。
我寫了一個最簡單的 demo,使用 cmake 來構建跨平臺的動態(tài)庫、靜態(tài)庫、可執(zhí)行程序。寫這個 demo 的目的,主要是作為一個外殼,來測試一些寫文章時的代碼。
在 Linux 平臺下,通過 cmake 指令手動編譯;在 Windows 平臺下,可以通過 CLion 集成開發(fā)環(huán)境直接編譯、執(zhí)行,也可以通過 cmake 工具直接生成 VS2017/2019 解決方案。
已經(jīng)把這個 demo 放在 gitee 倉庫中了,感興趣的小伙伴,請在公眾號回復:dg36,即可收到克隆地址。
星標公眾號,能更快找到我!
1. C語言指針-從底層原理到花式技巧,用圖文和代碼幫你講解透徹
2. 原來gdb的底層調試原理這么簡單
3. 一步步分析-如何用C實現(xiàn)面向對象編程
4. 都說軟件架構要分層、分模塊,具體應該怎么做(一)
5. 都說軟件架構要分層、分模塊,具體應該怎么做(二)