
【Python】開啟Pandas進階:圖解Pandas透視表、交叉表
一、圖解Pandas透視表、交叉表
終于開始Pandas進階內容的寫作了。相信很多人都應該知道透視表,在Excel會經(jīng)常去制作它,來實現(xiàn)數(shù)據(jù)的分組匯總統(tǒng)計。在Pandas中,我們把它稱之為pivot_table。
透視表的制作靈活性高,可以隨意定制我們想要的的計算統(tǒng)計要求,一般在制作報表神器的時候常用。
下面通過具體的例子來對比Excel和Pandas中透視表的實現(xiàn)方法。

二、Excel透視表
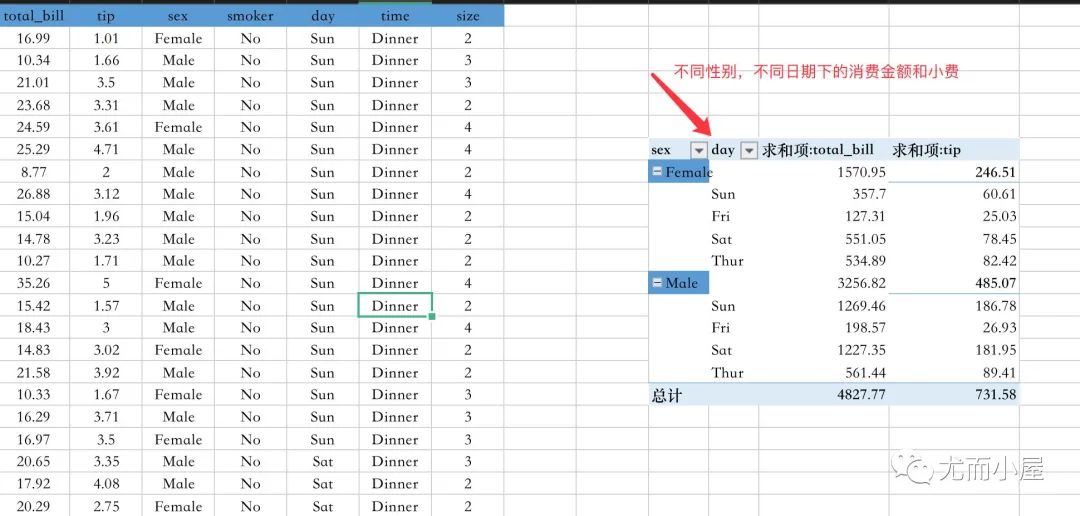
下面是在Excel表格中使用消費數(shù)據(jù)制作的透視表(部分數(shù)據(jù)截圖),我們統(tǒng)計的是不同性別不同日期下的消費金額和小費,同時還顯示了總計的數(shù)據(jù)。
那如果是使用pandas該如何來實現(xiàn)呢???
三、透視表參數(shù)
pandas中實現(xiàn)透視表使用的是:pandas.pivot_table
pd.pivot_table(data, # 制作透視表的數(shù)據(jù)
values=None, # 值
index=None, # 行索引
columns=None, # 列屬性
aggfunc='mean', # 使用的函數(shù),默認是均值
fill_value=None, # 缺失值填充
margins=False, # 是否顯示總計
dropna=True, # 缺失值處理
margins_name='All', # 總計顯示為All
observed=False,
sort=True # 排序功能 版本1.3.0才有
)
最重要的參數(shù)還是:values、index、columns、aggfunce,甚至包含margins、margins_name
附上官網(wǎng)學習地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html
四、透視表參數(shù)詳解
4.1參數(shù)index
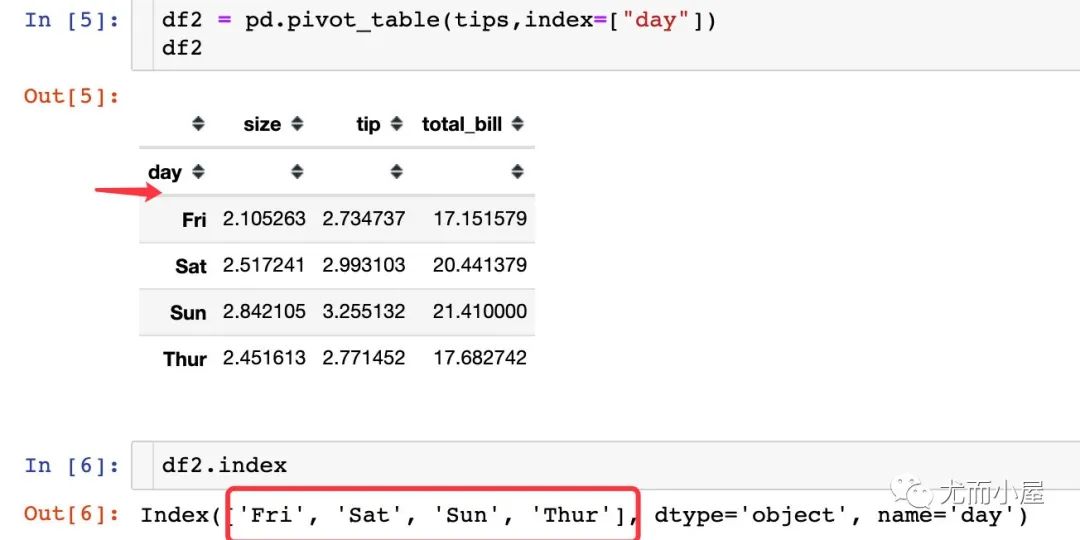
index表示的是我們生成透視表指定的行索引
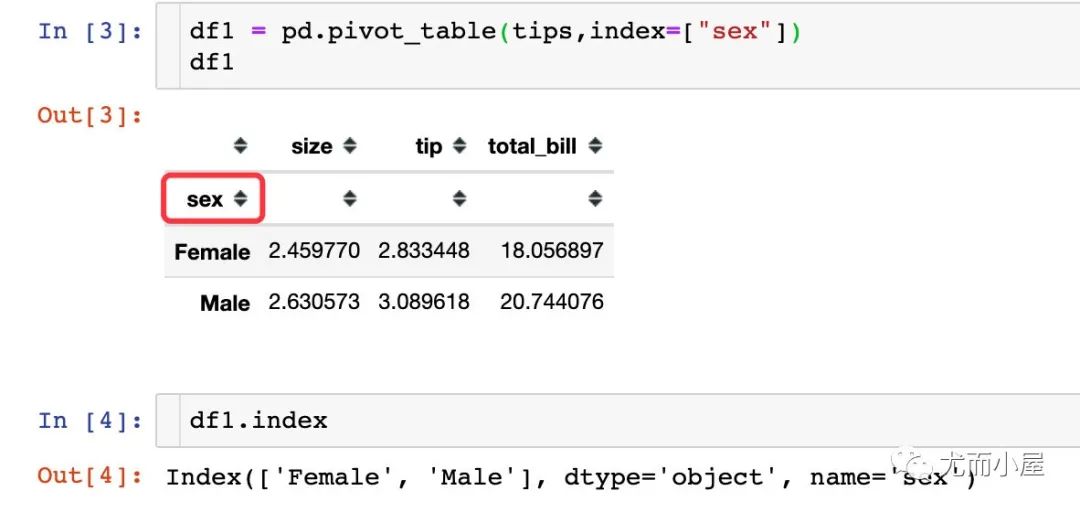
1、單層索引
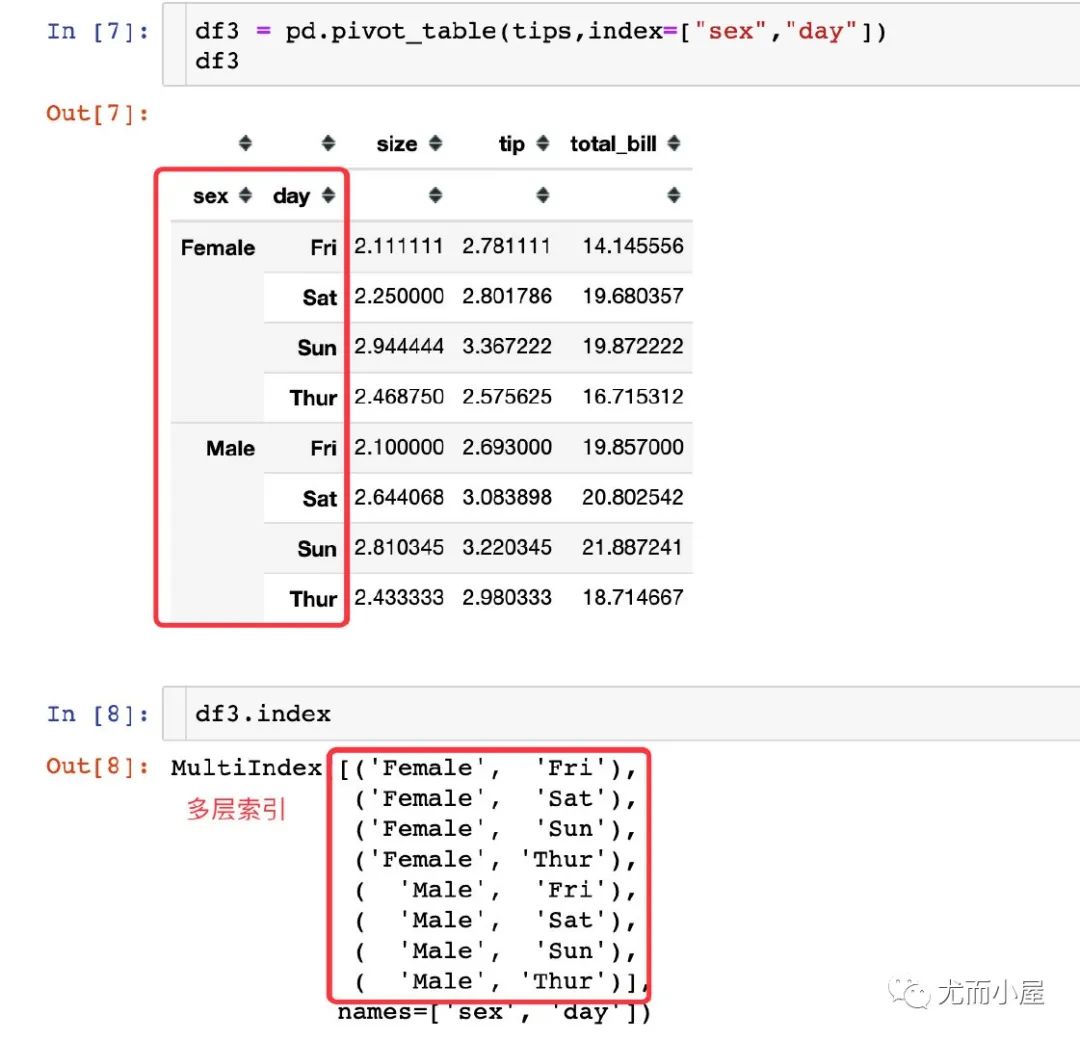
2、多層行索引
4.2參數(shù)values
在上面index參數(shù)的使用中,我們沒有指定values參數(shù),pandas會默認將全部的數(shù)值型數(shù)據(jù)進行透視表的計算,現(xiàn)在指定參數(shù)計算的數(shù)據(jù):
帶上values,只會顯示我們指定的數(shù)據(jù) 不帶上values,數(shù)值型的數(shù)據(jù)匯總結果全部顯示

4.3參數(shù)columns
columns是一個顯示列屬性信息的參數(shù)
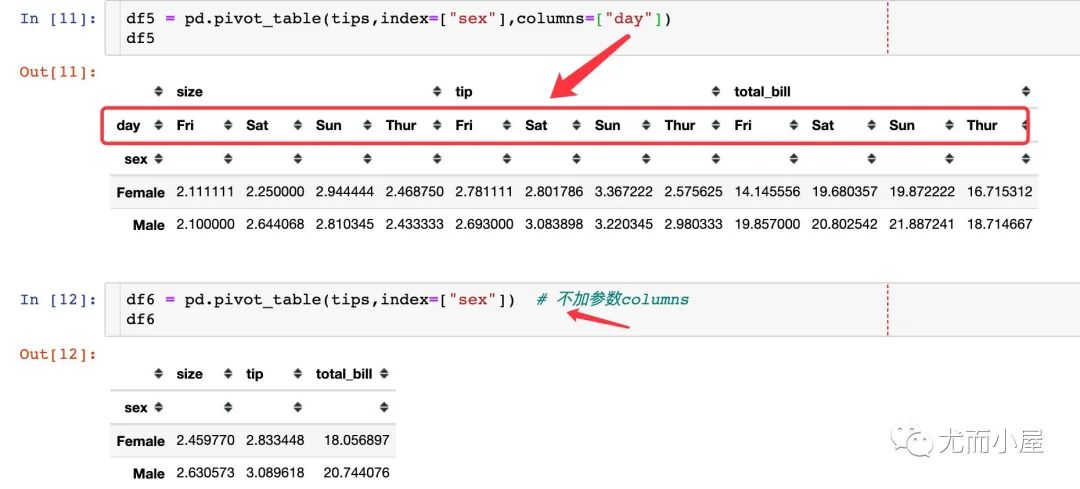
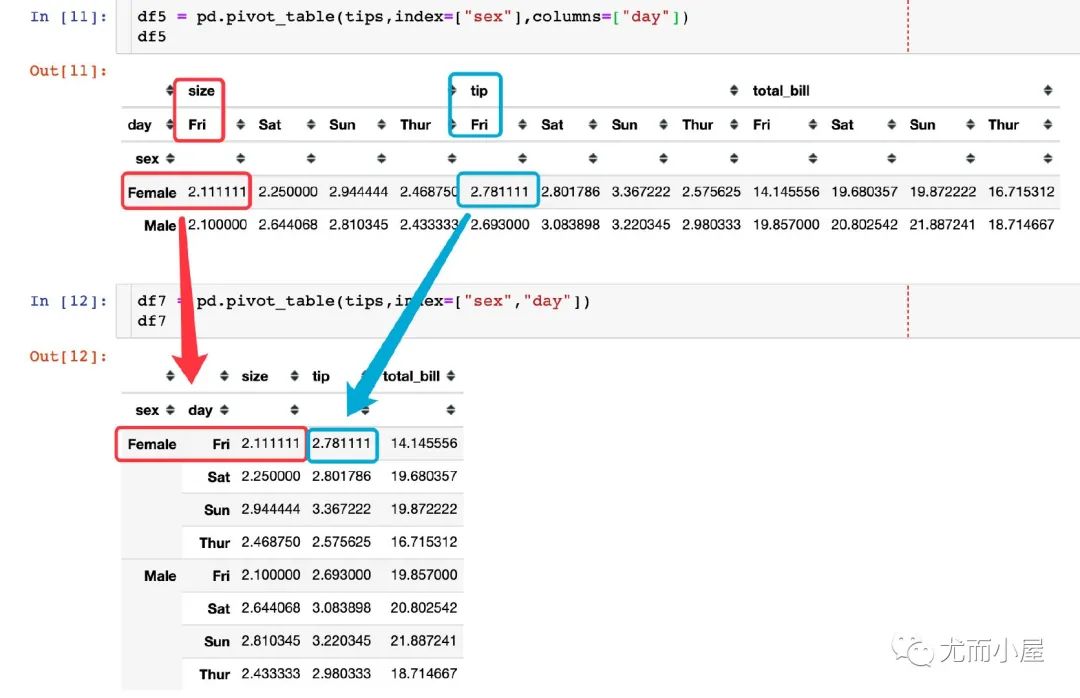
如果我們將day放在index參數(shù)中,會是什么樣子呢?
相當于是:將上面的寬表格式轉成了下面的長表格式
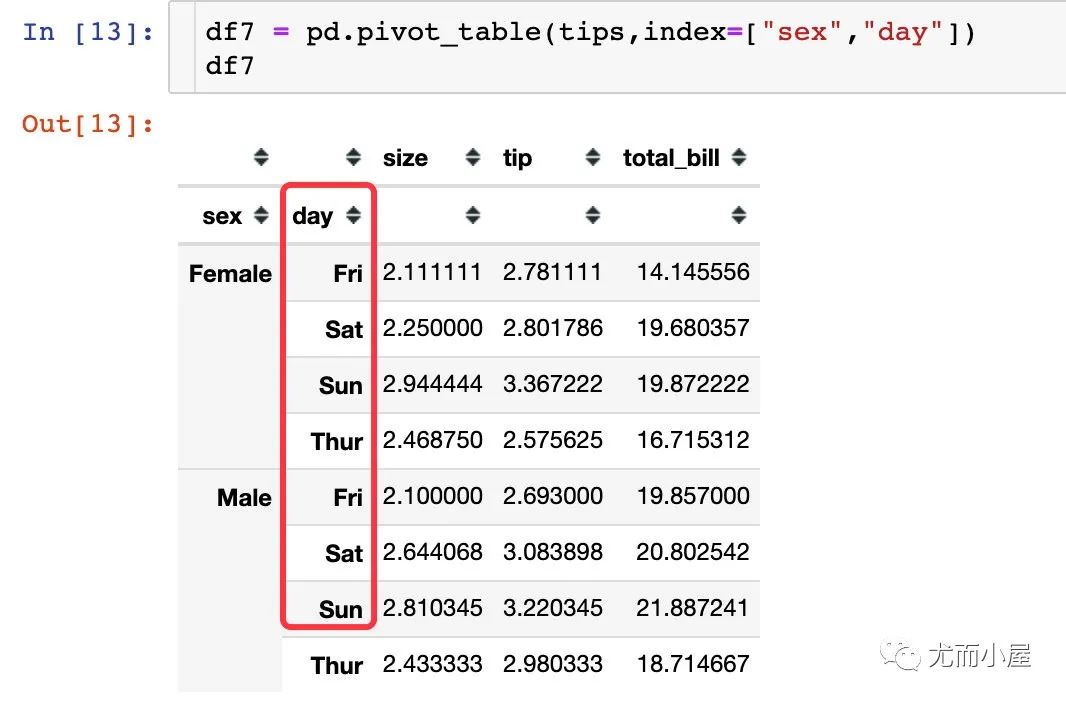
再對比下兩種不同的形式:
4.4參數(shù)aggfunc
aggfunc是一個很靈活的參數(shù),它是用來指定我們匯總想用哪種函數(shù),默認是均值mean,我們也可以使用求和sum、最值max等。多個函數(shù)需要放在一個列表中。
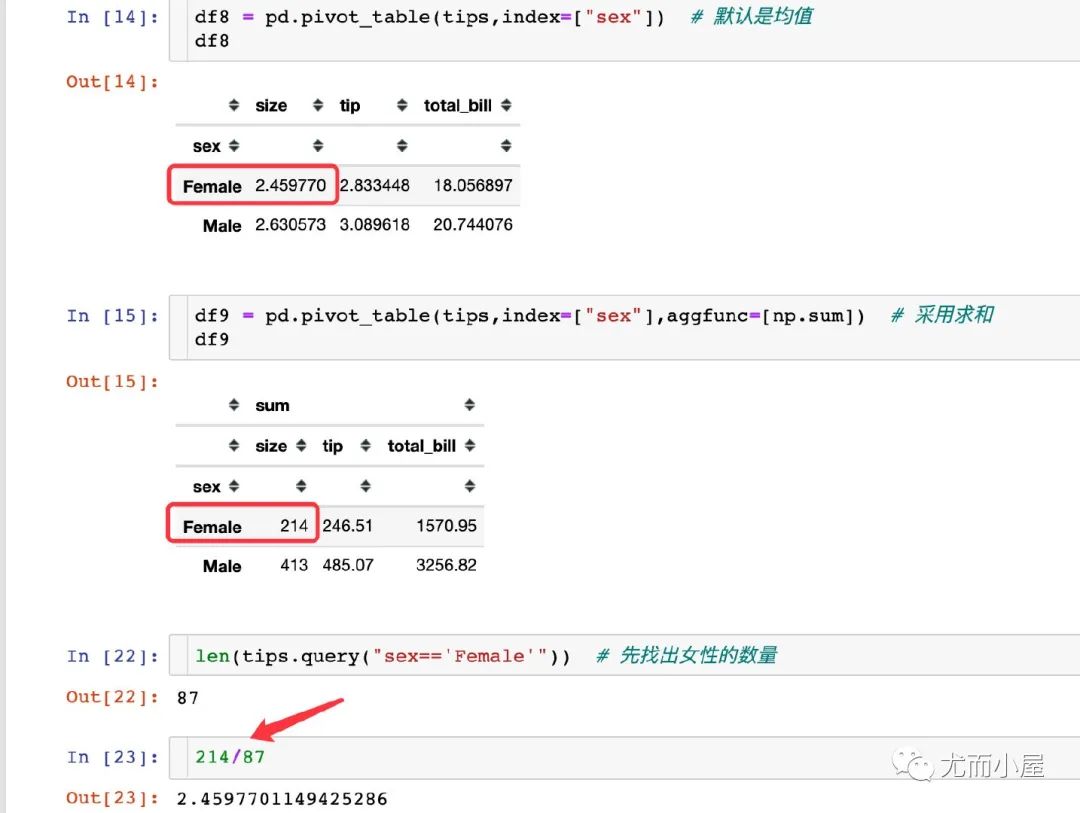
我們將默認求平均mean的情況與求和的情況進行對比:
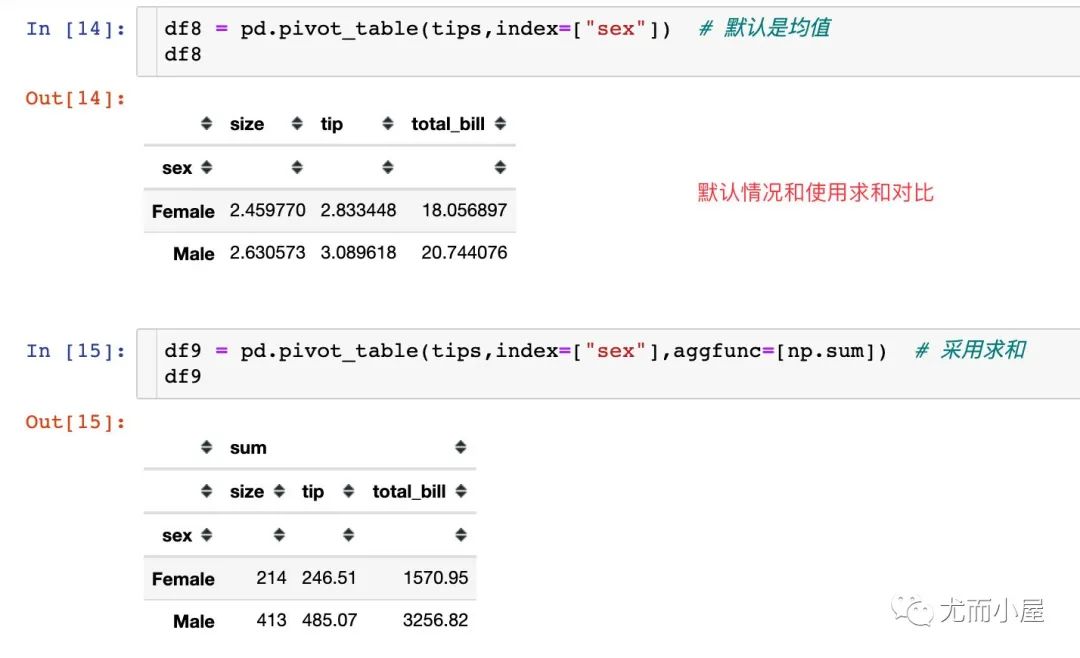
均值和sum求和之間的關系:
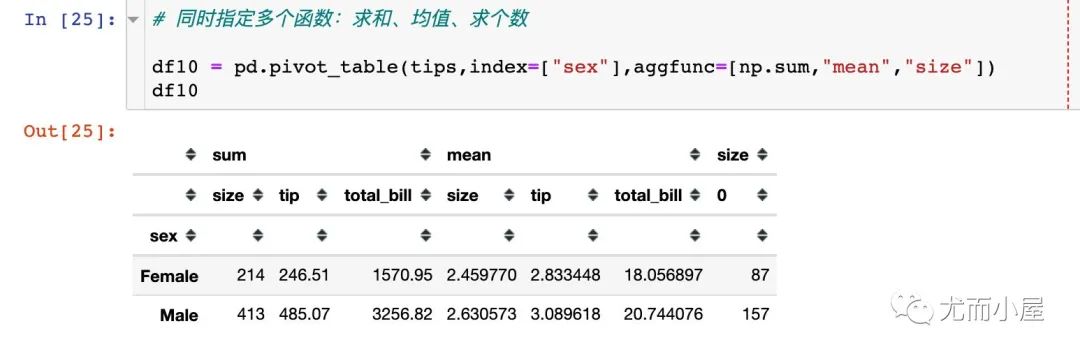
我們可以在aggfunc函數(shù)中指定多個函數(shù),將這些函數(shù)放在同一個列表中:
求和:np.sum 求均值:mean 求個數(shù):size
再看一個例子:
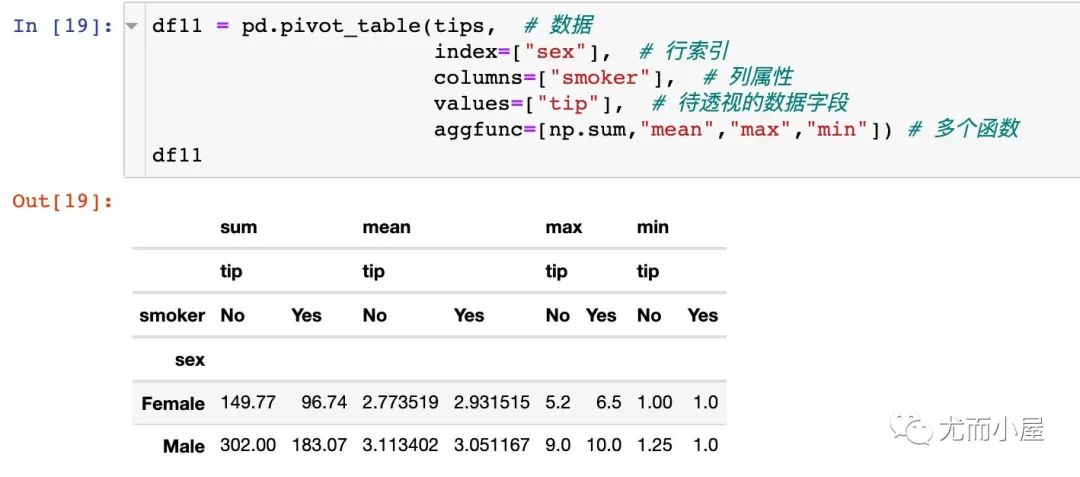
4.5參數(shù)margins、margins_name
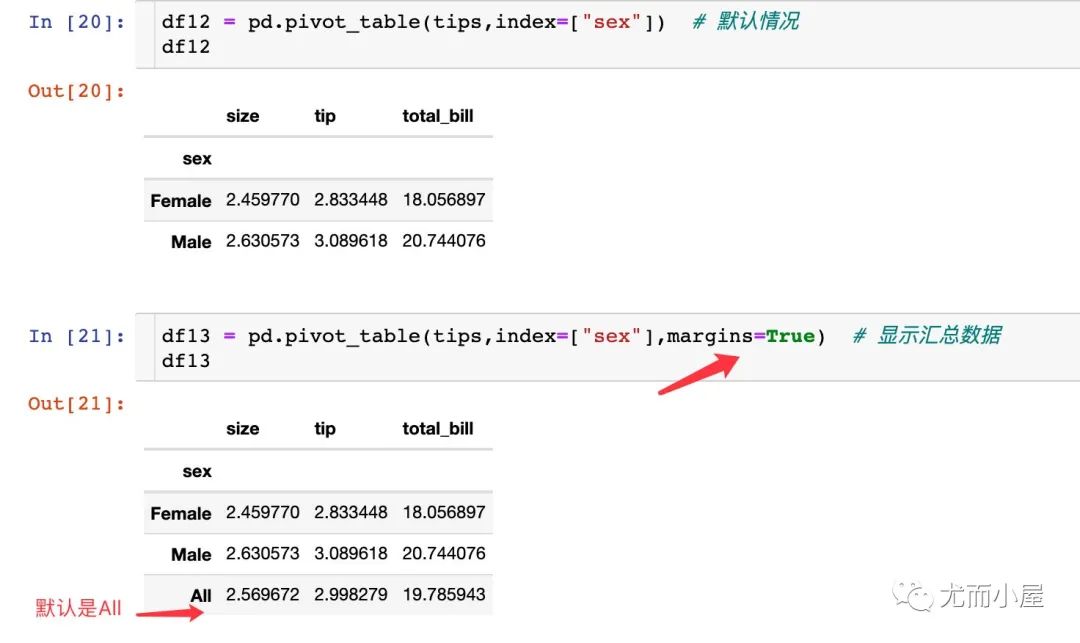
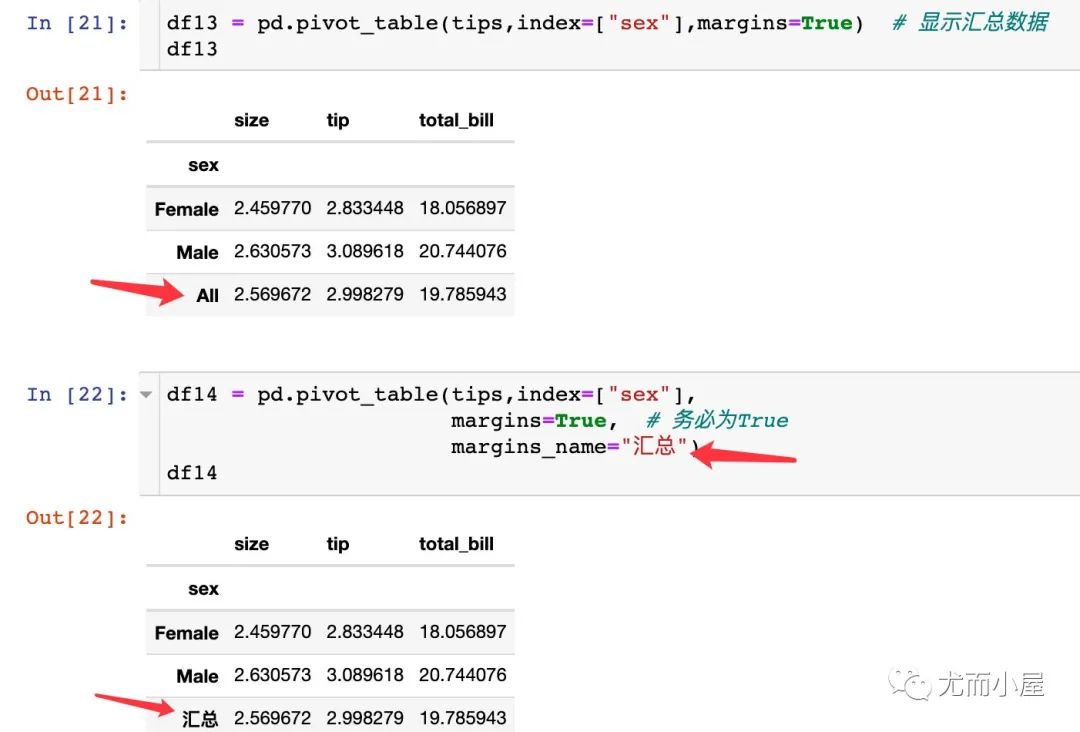
這兩個參數(shù)的作用是對透視表中的分組數(shù)據(jù)進行匯總顯示。需要注意的是:只有margins=True,參數(shù)margins_name的設置才會生效。
修改匯總顯示的名字:
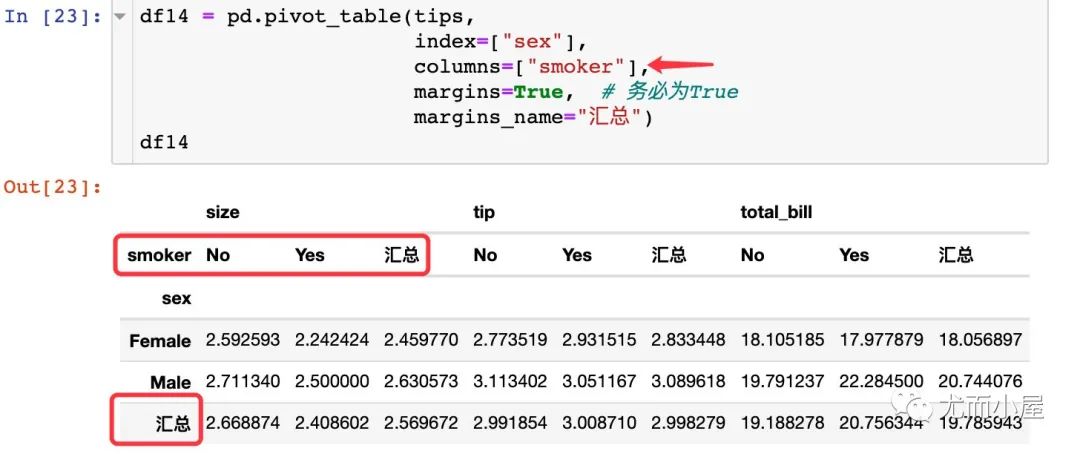
如果有列字段,也會顯示匯總的數(shù)據(jù):
五、交叉表crosstab
交叉表可以理解成一種特殊的透視表,專門用于計算分組的頻率。
5.1參數(shù)
交叉表中每個參數(shù)的解釋,很多還是和透視表相同的:
pandas.crosstab(index, # 行索引,必須是數(shù)組結構數(shù)據(jù),或者Series,或者是二者的列表形式
columns, # 列字段;數(shù)據(jù)要求同上
values=None, # 待透視的數(shù)據(jù)
rownames=None, # 行列名字
colnames=None,
aggfunc=None, # 透視的函數(shù)
margins=False, # 匯總及名稱設置
margins_name='All',
dropna=True, # 舍棄缺失值
normalize=False # 數(shù)據(jù)歸一化;可以是布爾值、all、index、columns、或者{0,1}
)
對最后一個參數(shù)的解釋:如何選擇歸一化的標準
If passed ‘a(chǎn)ll’ or True, will normalize over all values:使用all,對全部的數(shù)值型數(shù)據(jù)歸一化 If passed ‘index’ will normalize over each row:使用index,僅在行上歸一化 If passed ‘columns’ will normalize over each column:使用columns,僅在列上歸一化 If margins is True, will also normalize margin values:如果margins=True,總計值也會參與歸一化
5.2參數(shù)使用
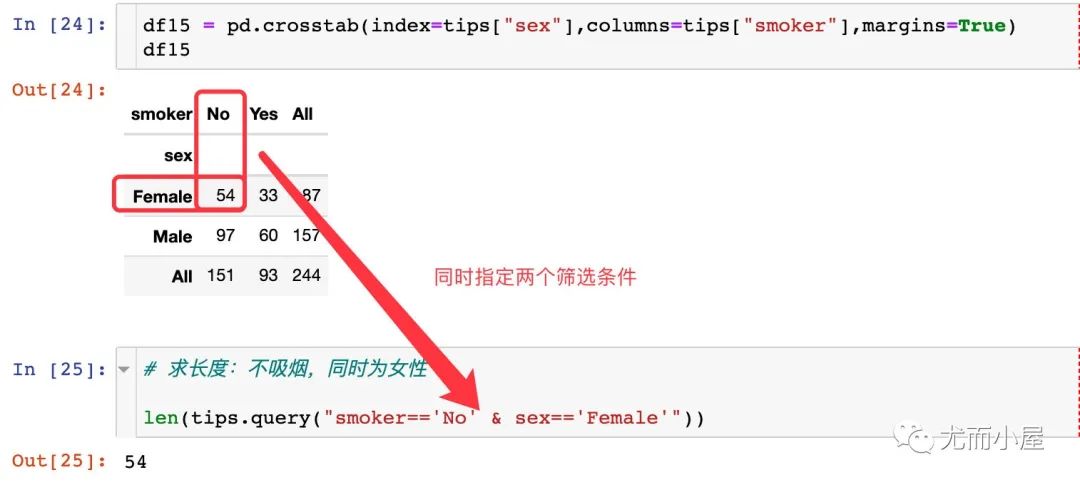
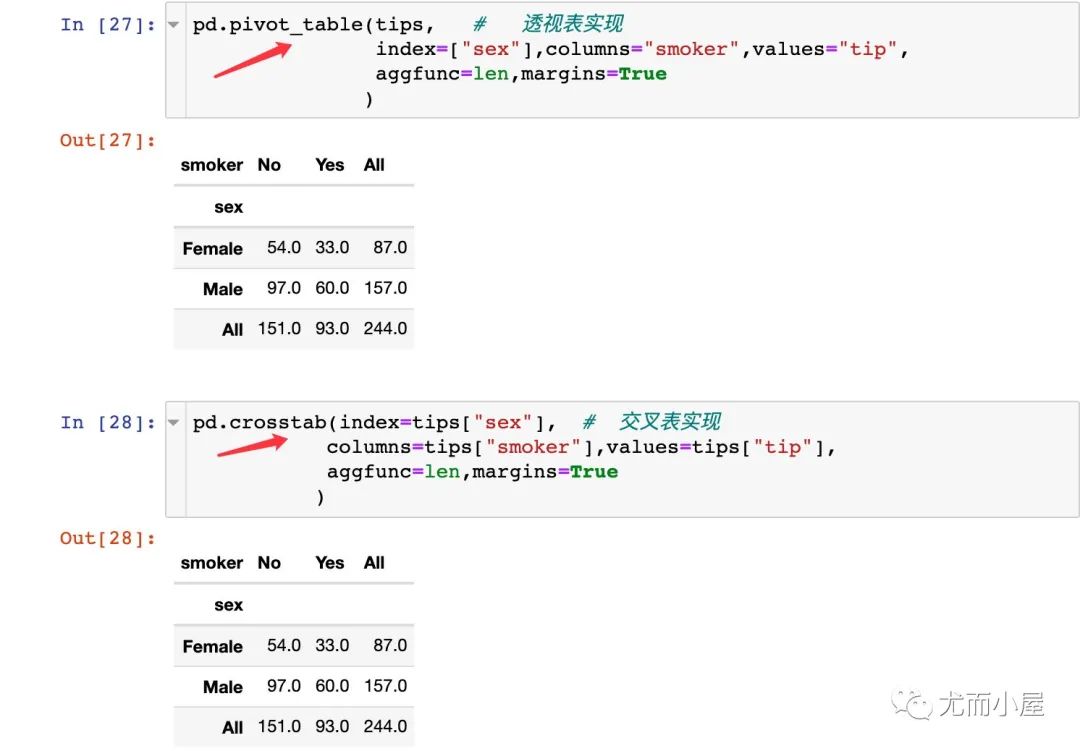
當然,有時候透視表和交叉表是可以實現(xiàn)相同的功能:
六、groupby實現(xiàn)
其實透視表或者交叉表的本質還是分組匯總統(tǒng)計結果,我們也可以利用groupby來實現(xiàn):
1、先分組統(tǒng)計

2、軸旋轉unstack
上面的結果格式上不是很友好,使用的是多層次索引,我們使用軸旋轉函數(shù)unstack將行轉成列:

七、groupby和透視表比較
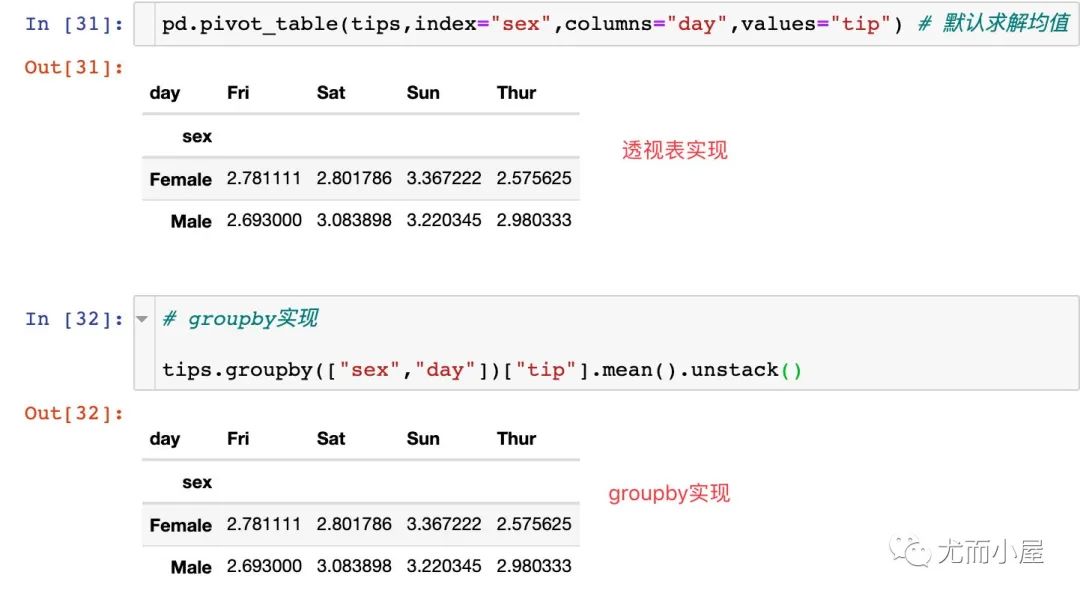
最后再用一個例子來比較下groupby和透視表:
八、備忘錄
這個網(wǎng)上非常流行的一張圖解Pandas透視表函數(shù)的圖形,它利用一份簡單的數(shù)據(jù),清晰明了地講解了pivot_table函數(shù)的每個參數(shù)的含義,保存?zhèn)溆茫?/p>
往期精彩回顧 本站qq群851320808,加入微信群請掃碼: