
SQL中去重的三種方法,還有誰(shuí)不會(huì)?
來(lái)自:CSDN,作者:米竹 鏈接:https://blog.csdn.net/xienan_ds_zj/article/details/103869048
SQL去重是數(shù)據(jù)分析工作中比較常見(jiàn)的一個(gè)場(chǎng)景,今天給大家具體介紹3種去重的方法。
在使用SQL提數(shù)的時(shí)候,常會(huì)遇到表內(nèi)有重復(fù)值的時(shí)候,比如我們想得到 uv (獨(dú)立訪客),就需要做去重。
在 MySQL 中通常是使用 distinct 或 group by子句,但在支持窗口函數(shù)的 sql(如Hive SQL、Oracle等等) 中還可以使用 row_number 窗口函數(shù)進(jìn)行去重。
舉個(gè)栗子,現(xiàn)有這樣一張表 task:
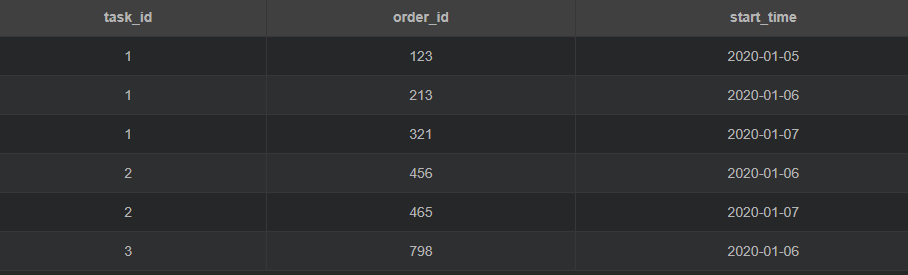
備注:
task_id: 任務(wù)id;order_id: 訂單id;start_time: 開(kāi)始時(shí)間
注意:一個(gè)任務(wù)對(duì)應(yīng)多條訂單
我們需要求出任務(wù)的總數(shù)量,因?yàn)?task_id 并非唯一的,所以需要去重:
distinct
-- 列出 task_id 的所有唯一值(去重后的記錄)
-- select distinct task_id
-- from Task;
-- 任務(wù)總數(shù)
select count(distinct task_id) task_num
from Task;
distinct 通常效率較低。它不適合用來(lái)展示去重后具體的值,一般與 count 配合用來(lái)計(jì)算條數(shù)。
distinct 使用中,放在 select 后邊,對(duì)后面所有的字段的值統(tǒng)一進(jìn)行去重。比如distinct后面有兩個(gè)字段,那么 1,1 和 1,2 這兩條記錄不是重復(fù)值 。
group by
-- 列出 task_id 的所有唯一值(去重后的記錄,null也是值)
-- select task_id
-- from Task
-- group by task_id;
-- 任務(wù)總數(shù)
select count(task_id) task_num
from (select task_id
from Task
group by task_id) tmp;
row_number
row_number() over (partition by <用于分組的字段名> order by <用于組內(nèi)排序的字段名>)-- 在支持窗口函數(shù)的 sql 中使用
select count(case when rn=1 then task_id else null end) task_num
from (select task_id
, row_number() over (partition by task_id order by start_time) rn
from Task) tmp;

-- 下方的分號(hào);用來(lái)分隔行
select distinct user_id
from Test; -- 返回 1; 2
select distinct user_id, user_type
from Test; -- 返回1, 1; 1, 2; 2, 1
select user_id
from Test
group by user_id; -- 返回1; 2
select user_id, user_type
from Test
group by user_id, user_type; -- 返回1, 1; 1, 2; 2, 1
select user_id, user_type
from Test
group by user_id;
-- Hive、Oracle等會(huì)報(bào)錯(cuò),mysql可以這樣寫。
-- 返回1, 1 或 1, 2 ; 2, 1(共兩行)。只會(huì)對(duì)group by后面的字段去重,就是說(shuō)最后返回的記錄數(shù)等于上一段sql的記錄數(shù),即2條
-- 沒(méi)有放在group by 后面但是在select中放了的字段,只會(huì)返回一條記錄(好像通常是第一條,應(yīng)該是沒(méi)有規(guī)律的)