
論文被拒,LeCun喊冤?我雖大肆宣傳,但不影響「雙盲審」公正
點擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達
導(dǎo)讀
?LeCun最近在推特上表示,他的一篇文章已被NeurIPS 2021拒絕,但他依然非常自豪:「問題不在于NeurIPS,而在于新興領(lǐng)域頂會的篩選做法」。盡管LeCun表達了他對雙盲評審的認(rèn)可,關(guān)于雙盲評審是否是一件好事的討論仍在繼續(xù)。

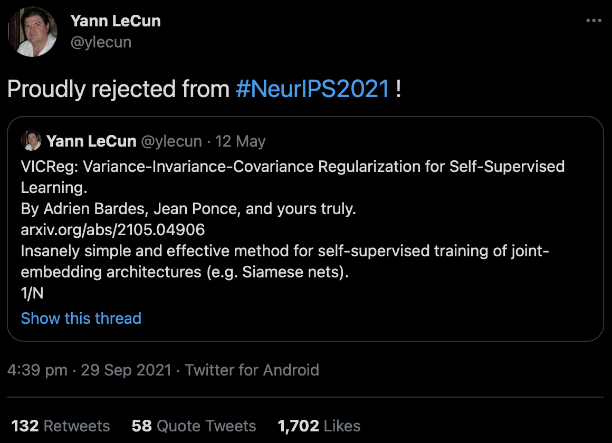







方差項:采用鉸鏈損失,以維持Gx(x)和Gx'(x')的每個組成部分的標(biāo)準(zhǔn)偏差維持在一個邊界以上,這是該論文的創(chuàng)新之處。 不變項:即||Gx(x)-Gx'(x')||^2,這是經(jīng)典的約束項。 協(xié)方差項:即Gx(x)和Gx'(x')的協(xié)方差矩陣的偏離項的平方和,此項借鑒了Barlow Twins中的思想。
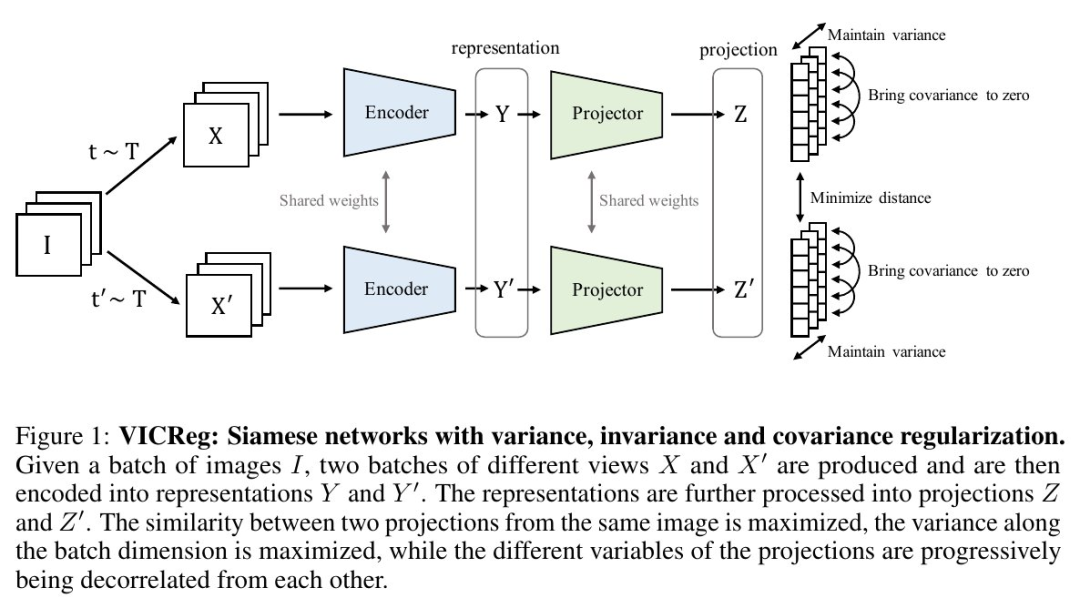
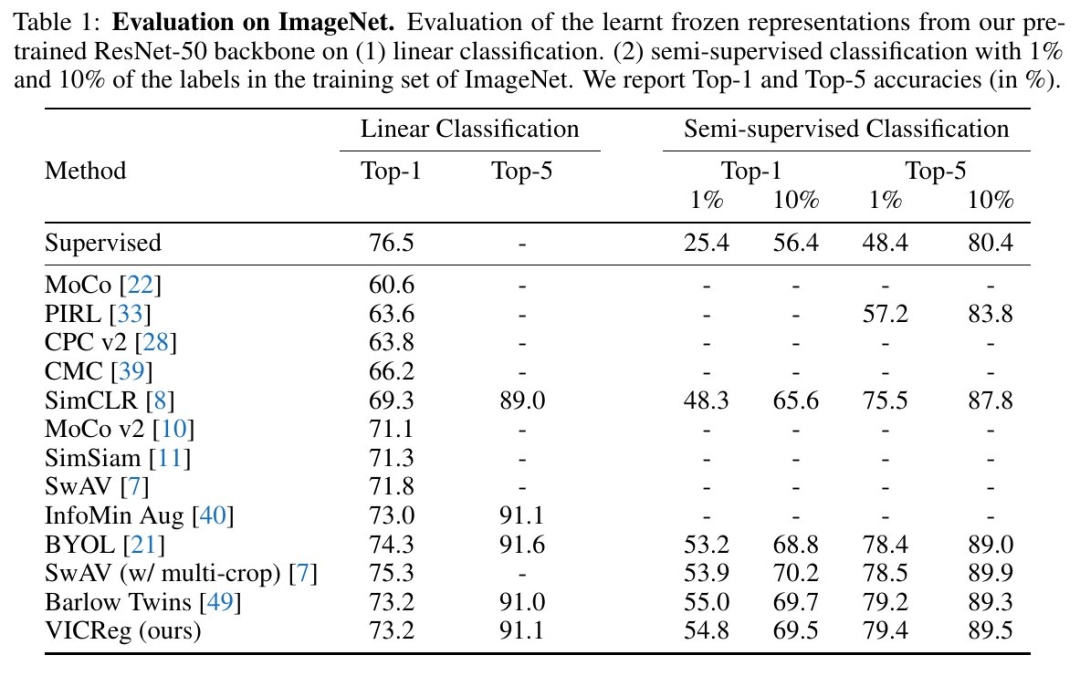
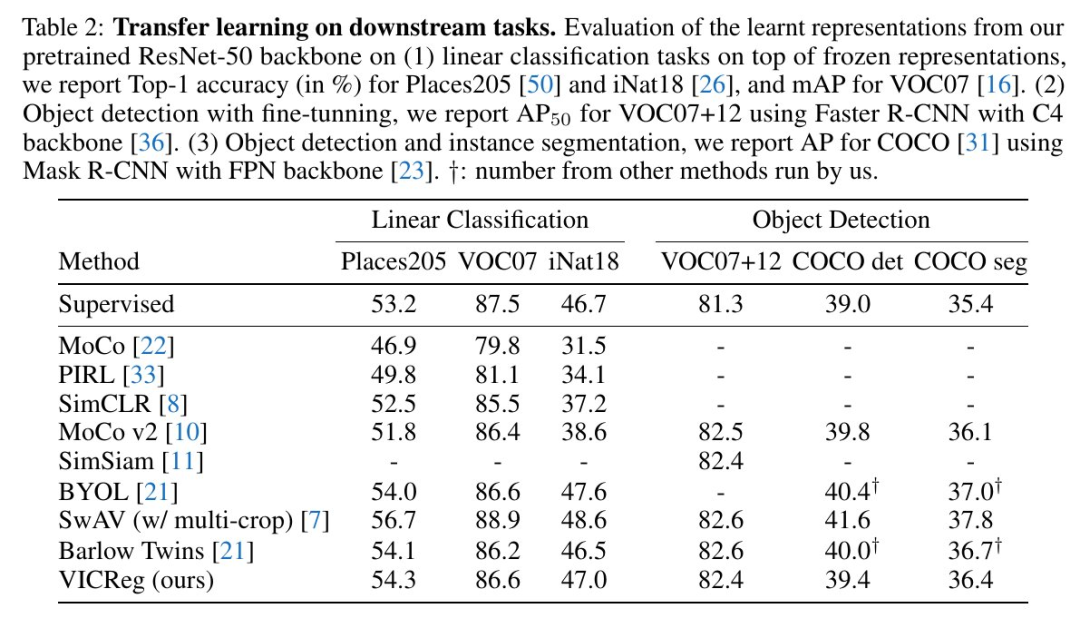
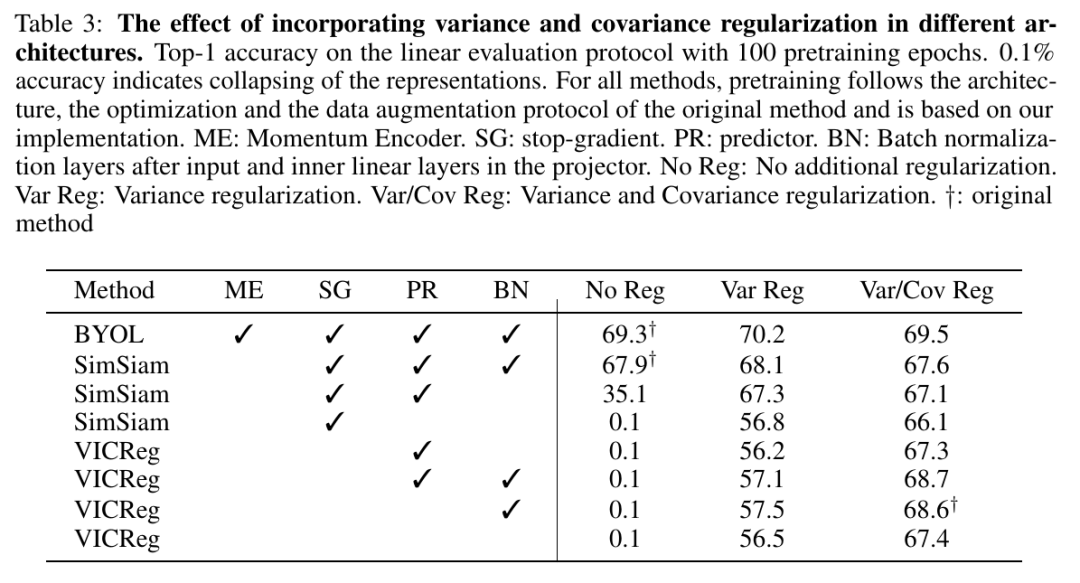
采用簡單的方差鉸鏈損失,很好地控制模型訓(xùn)練時的崩潰(見PyTorch偽代碼) 不需要批標(biāo)準(zhǔn)化或通道標(biāo)準(zhǔn)化 (盡管這有點幫助) 兩個分支之間無需共享權(quán)重(盡管在實驗中權(quán)重是共享的) 不需要平均移動權(quán)重、梯度停止、預(yù)測器、負(fù)樣本挖掘,存儲體,最近鄰和種種量化/蒸餾手段

如果覺得有用,就請分享到朋友圈吧!

點個在看 paper不斷!
評論
圖片
表情