
【Python基礎】如何編寫簡潔美觀的Python代碼
編譯 | VK?
來源 | Analytics Vidhya
概述
Python風格教程將使你能夠編寫整潔漂亮的Python代碼
在這個風格教程中學習不同的Python約定和Python編程的其他細微差別
介紹
你有沒有遇到過一段寫得很糟糕的Python代碼?我知道你們很多人都會點頭的。
編寫代碼是數(shù)據(jù)科學家或分析師角色的一部分。另一方面,編寫漂亮整潔的Python代碼完全是另一回事。作為一個精通分析或數(shù)據(jù)科學領域(甚至軟件開發(fā))的程序員,這很可能會改變你的形象。
那么,我們?nèi)绾尉帉戇@種所謂漂亮的Python代碼呢?
歡迎學習Python風格教程

數(shù)據(jù)科學和分析領域的許多人來自非編程背景。我們先從學習編程的基礎知識開始,接著理解機器學習背后的理論,然后開始征服數(shù)據(jù)集。
在這個過程中,我們經(jīng)常不練習核心編程,也不注意編程慣例。
這就是本Python風格教程將要解決的問題。我們將回顧PEP-8文檔中描述的Python編程約定,你將成為一個更好的程序員!
目錄
為什么這個Python風格的教程對數(shù)據(jù)科學很重要?
什么是PEP8?
了解Python命名約定
Python風格教程的代碼布局
熟悉正確的Python注釋
Python代碼中的空格
Python的一般編程建議
自動格式化Python代碼
為什么這個Python風格的教程對數(shù)據(jù)科學很重要
有幾個原因使格式化成為編程的一個重要方面,尤其是對于數(shù)據(jù)科學項目:
可讀性
好的代碼格式將不可避免地提高代碼的可讀性。這不僅會使你的代碼更有條理,而且會使讀者更容易理解程序中正在發(fā)生的事情。如果你的程序運行了數(shù)千行,這將特別有用。
你會有很多的數(shù)據(jù)幀、列表、函數(shù)、繪圖等,如果不遵循正確的格式準則,你甚至會很容易失去對自己代碼的跟蹤!
協(xié)作
如果你在一個團隊項目上合作,大多數(shù)數(shù)據(jù)科學家都會這樣做,那么好的格式化就成了一項必不可少的任務。
這樣可以確保代碼被正確理解而不產(chǎn)生任何麻煩。此外,遵循一個通用的格式模式可以在整個項目生命周期中保持程序的一致性。
Bug修復
當你需要修復程序中的錯誤時,擁有一個格式良好的代碼也將有助于你。錯誤的縮進、不恰當?shù)拿榷己苋菀资拐{試成為一場噩夢!
因此,最好是以正確的編寫風格來開始編寫你的程序!
考慮到這一點,讓我們快速概述一下本文將介紹的PEP-8樣式教程!
什么是PEP-8
PEP-8或Python增強建議是Python編程的風格教程。它是由吉多·范羅森、巴里·華沙和尼克·科格蘭寫的。它描述了編寫漂亮且可讀的Python代碼的規(guī)則。
遵循PEP-8的編碼風格將確保Python代碼的一致性,從而使其他讀者、貢獻者或你自己更容易理解代碼。
本文介紹了PEP-8指導原則中最重要的方面,如如何命名Python對象、如何構造代碼、何時包含注釋和空格,最后是一些很重要但很容易被大多數(shù)Python程序員忽略的一般編程建議。
讓我們學習編寫更好的代碼!
官方PEP-8文檔可以在這里找到。
https://www.python.org/dev/peps/pep-0008/
了解Python命名約定
莎士比亞有句名言:“名字里有什么?”. 如果他當時遇到了一個程序員,他會很快得到一個答復——“很多!”.
是的,當你編寫一段代碼時,你為變量、函數(shù)等選擇的名稱對代碼的可理解性有很大的影響。看看下面的代碼:
#?函數(shù)?1
def?func(x):
???a?=?x.split()[0]
???b?=?x.split()[1]
???return?a,?b
print(func('Analytics?Vidhya'))
#?函數(shù)?2
def?name_split(full_name):
???first_name?=?full_name.split()[0]
???last_name?=?full_name.split()[1]
???return?first_name,?last_name
print(name_split('Analytics?Vidhya'))
#?輸出
('Analytics',?'Vidhya')
('Analytics',?'Vidhya')
這兩個函數(shù)的作用是一樣的,但是后者提供了一個更好的直覺讓我們知道發(fā)生了什么,即使沒有任何注釋!
這就是為什么選擇正確的名稱和遵循正確的命名約定可以在編寫程序時可以產(chǎn)生巨大的不同。話雖如此,讓我們看看如何在Python中命名對象!
開頭命名
這些技巧可以應用于命名任何實體,并且應該嚴格遵守。
遵循相同的模式
thisVariable,?ThatVariable,?some_other_variable,?BIG_NO
避免使用長名字,同時也不要太節(jié)儉的名字
this_could_be_a_bad_name?=?“Avoid?this!”
t?=?“This?isn\’t?good?either”
使用合理和描述性的名稱。這將有助于以后你記住代碼的用途
X?=?“My?Name”??#?防止這個
full_name?=?“My?Name”??#?這個更好
避免使用以數(shù)字開頭的名字
1_name?=?“This?is?bad!”
避免使用特殊字符,如@、!、#、$等
phone_?#?不好
變量命名
變量名應始終為小寫
blog?=?"Analytics?Vidhya"
對于較長的變量名,請使用下劃線分隔單詞。這提高了可讀性
awesome_blog?=?"Analytics?Vidhya"
盡量不要使用單字符變量名,如“I”(大寫I字母)、“O”(大寫O字母)、“l(fā)”(小寫字母l)。它們與數(shù)字1和0無法區(qū)分。看看:
O?=?0?+?l?+?I?+?1
全局變量的命名遵循相同的約定
函數(shù)命名
遵循小寫和下劃線命名約定
使用富有表現(xiàn)力的名字
#?避免
def?con():
????...
#?這個更好
def?connect():
????...
如果函數(shù)參數(shù)名與關鍵字沖突,請使用尾隨下劃線而不是縮寫。例如,將break轉換為break_u而不是brk
#?避免名稱沖突
def?break_time(break_):
????print(“Your?break?time?is”,?break_,”long”)
類名命名
遵循CapWord(或camelCase或StudlyCaps)命名約定。每個單詞以大寫字母開頭,單詞之間不要加下劃線
#?遵循CapWord
class?MySampleClass:
????pass
如果類包含具有相同屬性名的子類,請考慮向類屬性添加雙下劃線
這將確保類Person中的屬性__age被訪問為 _Person__age。這是Python的名稱混亂,它確保沒有名稱沖突
class?Person:
????def?__init__(self):
????????self.__age?=?18
obj?=?Person()?
obj.__age??#?錯誤
obj._Person__age??#?正確
對異常類使用后綴“Error”
class?CustomError(Exception):
????“””自定義異常類“””
類方法命名
實例方法(不附加字符串的基本類方法)的第一個參數(shù)應始終為self。它指向調用對象
類方法的第一個參數(shù)應始終為cls。這指向類,而不是對象實例
class?SampleClass:
????def?instance_method(self,?del_):
????????print(“Instance?method”)
????@classmethod
????def?class_method(cls):
????????print(“Class?method”)
包和模塊命名
盡量使名字簡短明了
應遵循小寫命名約定
對于長模塊名稱,首選下劃線
避免包名稱使用下劃線
testpackage?#?包名稱
sample_module.py?#?模塊名稱
常量命名
常量通常在模塊中聲明和賦值
常量名稱應全部為大寫字母
對較長的名稱使用下劃線
#?下列常量變量在global.py模塊
PI?=?3.14
GRAVITY?=?9.8
SPEED_OF_Light?=?3*10**8
Python風格教程的代碼布局
現(xiàn)在你已經(jīng)知道了如何在Python中命名實體,下一個問題應該是如何用Python構造代碼!
老實說,這是非常重要的,因為如果沒有適當?shù)慕Y構,你的代碼可能會出問題,對任何評審人員來說都是最大的障礙。
所以,不用再多費吹灰之力,讓我們來了解一下Python中代碼布局的基礎知識吧!
縮進
它是代碼布局中最重要的一個方面,在Python中起著至關重要的作用。縮進告訴代碼塊中要包含哪些代碼行以供執(zhí)行。缺少縮進可能是一個嚴重的錯誤。
縮進確定代碼語句屬于哪個代碼塊。想象一下,嘗試編寫一個嵌套的for循環(huán)代碼。在各自的循環(huán)之外編寫一行代碼可能不會給你帶來語法錯誤,但你最終肯定會遇到一個邏輯錯誤,這可能會在調試方面耗費時間。
遵循下面提到的縮進風格,以獲得一致的Python腳本風格。
始終遵循4空格縮進規(guī)則
#?示例
if?value<0:
????print(“negative?value”)
#?另一個例子
for?i?in?range(5):
????print(“Follow?this?rule?religiously!”)
建議用空格代替制表符
建議用空格代替制表符。但是當代碼已經(jīng)用制表符縮進時,可以使用制表符。
if?True:
????print('4?spaces?of?indentation?used!')
將大型表達式拆分成幾行
處理這種情況有幾種方法。一種方法是將后續(xù)語句與起始分隔符對齊。
#?與起始分隔符對齊。
def?name_split(first_name,
???????????????middle_name,
???????????????last_name)
#?另一個例子。
ans?=?solution(value_one,?value_two,
???????????????value_three,?value_four)
第二種方法是使用4個空格的縮進規(guī)則。這將需要額外的縮進級別來區(qū)分參數(shù)和塊內(nèi)其他代碼。
#?利用額外的縮進。
def?name_split(
????????first_name,
????????middle_name,
????????last_name):
????print(first_name,?middle_name,?last_name)
最后,你甚至可以使用“懸掛縮進”。懸掛縮進在Python上下文中是指包含圓括號的行以開括號結束的文本樣式,后面的行縮進,直到括號結束。
#?懸掛縮進
ans?=?solution(
????value_one,?value_two,
????value_three,?value_four)
縮進if語句可能是一個問題
帶有多個條件的if語句自然包含4個空格。如你所見,這可能是個問題。隨后的行也將縮進,并且無法區(qū)分if語句和它執(zhí)行的代碼塊。現(xiàn)在,我們該怎么辦?
好吧,我們有幾種方法可以繞過它:
#?這是個問題。
if?(condition_one?and
????condition_two):
????print(“Implement?this”)
一種方法是使用額外的縮進!
#?使用額外的縮進
if?(condition_one?and
????????condition_two):
????print(“Implement?this”)
另一種方法是在if語句條件和代碼塊之間添加注釋,以區(qū)分這兩者:
#?添加注釋。
if?(condition_one?and
????condition_two):
????#?此條件有效
????print(“Implement?this”)
括號的閉合
假設你有一個很長的字典。你將所有的鍵值對放在單獨的行中,但是你將右括號放在哪里?是在最后一行嗎?還是跟在最后一個鍵值對?如果放在最后一行,右括號位置的縮進是多少?
也有幾種方法可以解決這個問題。
一種方法是將右括號與前一行的第一個非空格字符對齊。
#?
learning_path?=?{
????‘Step?1’?:?’Learn?programming’,
????‘Step?2’?:?‘Learn?machine?learning’,
????‘Step?3’?:?‘Crack?on?the?hackathons’
????}
第二種方法是把它作為新行的第一個字符。
learning_path?=?{
????‘Step?1’?:?’Learn?programming’,
????‘Step?2’?:?‘Learn?machine?learning’,
????‘Step?3’?:?‘Crack?on?the?hackathons’
}
在二元運算符前換行
如果你試圖在一行中放入太多的運算符和操作數(shù),這肯定會很麻煩。相反,為了更好的可讀性,把它分成幾行。
現(xiàn)在很明顯的問題是——在操作符之前還是之后中斷?慣例是在操作符之前斷行。這有助于識別操作符和它所作用的操作數(shù)。
#?在操作符之前斷行
gdp?=?(consumption
??????+?government_spending
??????+?investment
??????+?net_exports
??????)
使用空行
將代碼行聚在一起只會使讀者更難理解你的代碼。使代碼看起來更整潔、更美觀的一個好方法是在代碼中引入相應數(shù)量的空行。
頂層函數(shù)和類應該用兩個空行隔開
#分離類和頂層函數(shù)
class?SampleClass():
????pass
def?sample_function():
????print("Top?level?function")
類中的方法應該用一個空格行分隔
#?在類中分離方法
class?MyClass():
????def?method_one(self):
????????print("First?method")
????def?method_two(self):
????????print("Second?method")
盡量不要在具有相關邏輯和函數(shù)的代碼段之間包含空行
def?remove_stopwords(text):?
????stop_words?=?stopwords.words("english")
????tokens?=?word_tokenize(text)?
????clean_text?=?[word?for?word?in?tokens?if?word?not?in?stop_words]?
??????
????return?clean_text
可以在函數(shù)中少用空行來分隔邏輯部分。這使得代碼更容易理解
def?remove_stopwords(text):?
????stop_words?=?stopwords.words("english")
????tokens?=?word_tokenize(text)?
????clean_text?=?[word?for?word?in?tokens?if?word?not?in?stop_words]?
????clean_text?=?'?'.join(clean_text)
????clean_text?=?clean_text.lower()
????return?clean_text
行最大長度
一行不超過79個字符
當你用Python編寫代碼時,不能在一行中壓縮超過79個字符。這是限制,應該是保持聲明簡短的指導原則。
你可以將語句拆分為多行,并將它們轉換為較短的代碼行
#?分成多行
num_list?=?[y?for?y?in?range(100)?
????????????if?y?%?2?==?0?
????????????if?y?%?5?==?0]
print(num_list)
導入包
許多數(shù)據(jù)科學家之所以喜歡使用Python,部分原因是因為有太多的庫使得處理數(shù)據(jù)更加容易。因此,我們假設你最終將導入一堆庫和模塊來完成數(shù)據(jù)科學中的任何任務。
應該始終位于Python腳本的頂部
應在單獨的行上導入單獨的庫
import?numpy?as?np
import?pandas?as?pd
df?=?pd.read_csv(r'/sample.csv')
導入應按以下順序分組:
標準庫導入 相關第三方進口 本地應用程序/庫特定導入 在每組導入后包括一個空行
import?numpy?as?np
import?pandas?as?pd
import?matplotlib
from?glob?import?glob
import?spaCy?
import?mypackage
可以在一行中從同一模塊導入多個類
from?math?import?ceil,?floor
熟悉正確的Python注釋
理解一段未注釋的代碼可能是一項費力的工作。即使是代碼的原始編寫者,也很難記住一段時間后代碼行中到底發(fā)生了什么。
因此,最好及時對代碼進行注釋,這樣讀者就可以正確地理解你試圖用這段代碼實現(xiàn)什么。
一般提示
注釋總是以大寫字母開頭
注釋應該是完整的句子
更新代碼時更新注釋
避免寫顯而易見之事的注釋
注釋的風格
描述它們后面的代碼段
與代碼段有相同的縮進
從一個空格開始
#?從用戶輸入字符串中刪除非字母數(shù)字字符。
import?re
raw_text?=?input(‘Enter?string:‘)
text?=?re.sub(r'\W+',?'??',?raw_text)
內(nèi)聯(lián)注釋
這些注釋與代碼語句位于同一行
應與代碼語句至少分隔兩個空格
以通常的#開頭,然后是空格
不要用它們來陳述顯而易見的事情
盡量少用它們,因為它們會分散注意力
info_dict?=?{}??#?字典,用于存儲提取的信息
文檔字符串
用于描述公共模塊、類、函數(shù)和方法
也稱為“docstrings”
它們之所以能在其他注釋中脫穎而出,是因為它們是用三重引號括起來的
如果docstring以單行結尾,則在同一行中包含結束符“””
如果docstring分為多行,請在新行中加上結束符“””
def?square_num(x):
????"""返回一個數(shù)的平方."""
????return?x**2
def?power(x,?y):
????"""多行注釋。
????返回x**y.
????"""
????return?x**y
Python代碼中的空格
在編寫漂亮的代碼時,空格常常被忽略為一個微不足道的方面。但是正確使用空格可以大大提高代碼的可讀性。它們有助于防止代碼語句和表達式過于擁擠。這不可避免地幫助讀者輕松地瀏覽代碼。
關鍵
避免將空格立即放在括號內(nèi)
#?正確的方法
df[‘clean_text’]?=?df[‘text’].apply(preprocess)
不要在逗號、分號或冒號前加空格
#?正確
name_split?=?lambda?x:?x.split()
字符和左括號之間不要包含空格
#?正確
print(‘This?is?the?right?way’)
#?正確
for?i?in?range(5):
????name_dict[i]?=?input_list[i]
使用多個運算符時,只在優(yōu)先級最低的運算符周圍包含空格
#?正確
ans?=?x**2?+?b*x?+?c
在分片中,冒號充當二進制運算符
它們應該被視為優(yōu)先級最低的運算符。每個冒號周圍必須包含相等的空格
#?正確
df_valid?=?df_train[lower_bound+5?:?upper_bound-5]
應避免尾隨空格
函數(shù)參數(shù)默認值不要在=號周圍有空格
def?exp(base,?power=2):
????return?base**power
請始終在以下二進制運算符的兩邊用單個空格括起來: 賦值運算符(=,+=,-=,等) 比較(=,<,>!=,<>,<=,>=,輸入,不在,是,不是) 布爾值(and,or,not)
#?正確
brooklyn?=?[‘Amy’,?‘Terry’,?‘Gina’,?'Jake']
count?=?0
for?name?in?brooklyn:
????if?name?==?‘Jake’:
????????print(‘Cool’)
????????count?+=?1
Python的一般編程建議
通常,有很多方法來編寫一段代碼。當它們完成相同的任務時,最好使用推薦的編寫方法并保持一致性。我在這一節(jié)已經(jīng)介紹了其中的一些。
與“None”之類的進行比較時,請始終使用“is”或“is not”。不要使用相等運算符
#?錯誤
if?name?!=?None:
????print("Not?null")
#?正確
if?name?is?not?None:
????print("Not?null")
不要使用比較運算符將布爾值與TRUE或FALSE進行比較。雖然使用比較運算符可能很直觀,但沒有必要使用它。只需編寫布爾表達式
#?正確
if?valid:
????print("Correct")
#?錯誤
if?valid?==?True:
????print("Wrong")
與其將lambda函數(shù)綁定到標識符,不如使用泛型函數(shù)。因為將lambda函數(shù)分配給標識符違背了它的目的。回溯也會更容易
#?選擇這個
def?func(x):
????return?None
#?而不是這個
func?=?lambda?x:?x**2
捕獲異常時,請命名要捕獲的異常。不要只使用一個光禿禿的例外。這將確保當你試圖中斷執(zhí)行時,異常塊不會通過鍵盤中斷異常來掩蓋其他異常
try:
????x?=?1/0
except?ZeroDivisionError:
????print('Cannot?divide?by?zero')
與你的返回語句保持一致。也就是說,一個函數(shù)中的所有返回語句都應該返回一個表達式,或者它們都不應該返回表達式。另外,如果return語句不返回任何值,則返回None而不是什么都不返回
#?錯誤
def?sample(x):
????if?x?>?0:
????????return?x+1
????elif?x?==?0:
????????return
????else:
????????return?x-1
#?正確
def?sample(x):
????if?x?>?0:
????????return?x+1
????elif?x?==?0:
????????return?None
????else:
????????return?x-1
如果要檢查字符串中的前綴或后綴,請使用“.startswith()”和“.endswith()",而不是字符串切片。它們更干凈,更不容易出錯
#?正確
if?name.endswith('and'):
????print('Great!')
自動格式化Python代碼
當你編寫小的程序時,格式化不會成為一個問題。但是想象一下,對于一個運行成千行的復雜程序,必須遵循正確的格式規(guī)則!這絕對是一項艱巨的任務。而且,大多數(shù)時候,你甚至不記得所有的格式規(guī)則。
我們?nèi)绾谓鉀Q這個問題呢?好吧,我們可以用一些自動格式化程序來完成這項工作!
自動格式化程序是一個程序,它可以識別格式錯誤并將其修復到位。Black就是這樣一種自動格式化程序,它可以自動將Python代碼格式化為符合PEP8編碼風格的代碼,從而減輕你的負擔。
BLACK:https://pypi.org/project/black/
通過在終端中鍵入以下命令,可以使用pip輕松安裝它:
pip?install?black
但是讓我們看看black在現(xiàn)實世界中有多大的幫助。讓我們用它來格式化以下類型錯誤的程序:
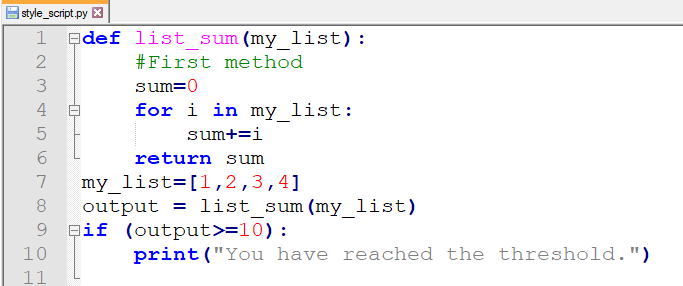
現(xiàn)在,我們要做的就是,前往終端并鍵入以下命令:
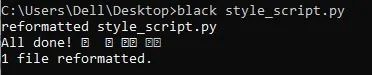
black?style_script.py
完成后,black可能已經(jīng)完成了更改,你將收到以下消息:
一旦再次嘗試打開程序,這些更改將反映在程序中:
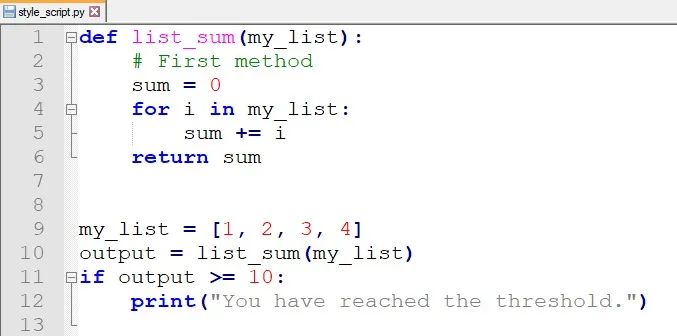
正如你所看到的,它已經(jīng)正確地格式化了代碼,在你不小心違反格式化規(guī)則的情況下它會有幫助。
Black還可以與Atom、Sublime Text、visualstudio代碼,甚至Jupyter Notebook集成在一起!這無疑是一個你永遠不會錯過的插件。
除了black,還有其他的自動格式化程序,如autoep8和yapf,你也可以嘗試一下!
結尾
我們已經(jīng)在Python風格教程中討論了很多關鍵點。如果你在代碼中始終遵循這些原則,那么你將最終得到一個更干凈和可讀的代碼。
另外,當你作為一個團隊在一個項目中工作時,遵循一個共同的標準是有益的。它使其他合作者更容易理解。開始在Python代碼中加入這些風格技巧吧!
原文鏈接:https://www.analyticsvidhya.com/blog/2020/07/python-style-guide/
看到這里,說明你喜歡這篇文章,請點擊「在看」或順手「轉發(fā)」「點贊」。
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請掃碼進群: