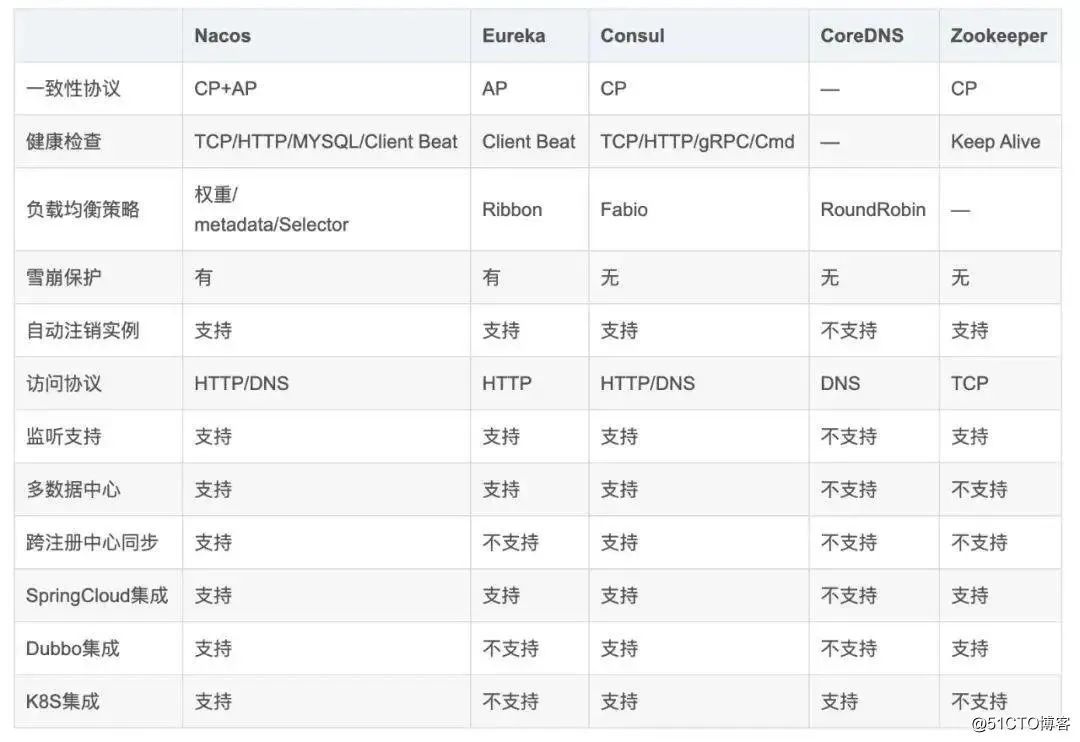
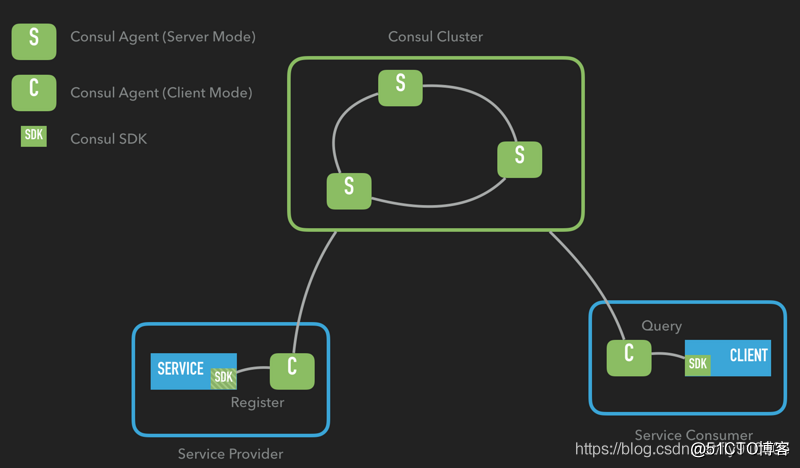
關(guān)于 P 的理解,我覺得是在整個系統(tǒng)中某個部分,掛掉了,或者宕機(jī)了,并不影響整個系統(tǒng)的運作或者說使用,而可用性是,某個系統(tǒng)的某個節(jié)點掛了,但是并不影響系統(tǒng)的接受或者發(fā)出請求,CAP 不可能都取,只能取其中2個原因是 如果C是第一需求的話,那么會影響A的性能,因為要數(shù)據(jù)同步,不然請求結(jié)果會有差異,但是數(shù)據(jù)同步會消耗時間,期間可用性就會降低。如果A是第一需求,那么只要有一個服務(wù)在,就能正常接受請求,但是對與返回結(jié)果變不能保證,原因是,在分布式部署的時候,數(shù)據(jù)一致的過程不可能想切線路那么快。再如果,同事滿足一致性和可用性,那么分區(qū)容錯就很難保證了,也就是單點,也是分布式的基本核心,好了,明白這些理論,就可以在相應(yīng)的場景選取服務(wù)注冊與發(fā)現(xiàn)了
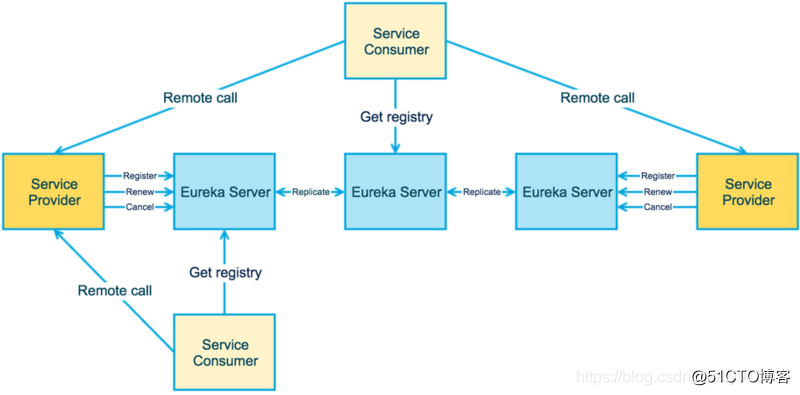
圖片Spring Cloud Netflix 在設(shè)計 Eureka 時就緊遵AP原則(盡管現(xiàn)在2.0發(fā)布了,但是由于其閉源的原因 ,但是目前 Ereka 1.x 任然是比較活躍的)。Eureka Server 也可以運行多個實例來構(gòu)建集群,解決單點問題,但不同于 ZooKeeper 的選舉 leader 的過程,Eureka Server 采用的是Peer to Peer 對等通信。這是一種去中心化的架構(gòu),無 master/slave 之分,每一個 Peer 都是對等的。在這種架構(gòu)風(fēng)格中,節(jié)點通過彼此互相注冊來提高可用性,每個節(jié)點需要添加一個或多個有效的 serviceUrl 指向其他節(jié)點。每個節(jié)點都可被視為其他節(jié)點的副本。在集群環(huán)境中如果某臺 Eureka Server 宕機(jī),Eureka Client 的請求會自動切換到新的 Eureka Server 節(jié)點上,當(dāng)宕機(jī)的服務(wù)器重新恢復(fù)后,Eureka 會再次將其納入到服務(wù)器集群管理之中。當(dāng)節(jié)點開始接受客戶端請求時,所有的操作都會在節(jié)點間進(jìn)行復(fù)制(replicate To Peer)操作,將請求復(fù)制到該 Eureka Server 當(dāng)前所知的其它所有節(jié)點中。當(dāng)一個新的 Eureka Server 節(jié)點啟動后,會首先嘗試從鄰近節(jié)點獲取所有注冊列表信息,并完成初始化。Eureka Server 通過 getEurekaServiceUrls() 方法獲取所有的節(jié)點,并且會通過心跳契約的方式定期更新。默認(rèn)情況下,如果 Eureka Server 在一定時間內(nèi)沒有接收到某個服務(wù)實例的心跳(默認(rèn)周期為30秒),Eureka Server 將會注銷該實例(默認(rèn)為90秒, eureka.instance.lease-expiration-duration-in-seconds 進(jìn)行自定義配置)。當(dāng) Eureka Server 節(jié)點在短時間內(nèi)丟失過多的心跳時,那么這個節(jié)點就會進(jìn)入自我保護(hù)模式。Eureka的集群中,只要有一臺Eureka還在,就能保證注冊服務(wù)可用(保證可用性),只不過查到的信息可能不是最新的(不保證強(qiáng)一致性)。除此之外,Eureka還有一種自我保護(hù)機(jī)制,如果在15分鐘內(nèi)超過85%的節(jié)點都沒有正常的心跳,那么Eureka就認(rèn)為客戶端與注冊中心出現(xiàn)了網(wǎng)絡(luò)故障,此時會出現(xiàn)以下幾種情況: