
OpenAI發(fā)布重磅升級:使用GPT-4進行內容審核,更快、判斷更一致

8月16日,OpenAI在官方博客上發(fā)布了一項新技術:開發(fā)了一種使用GPT-4進行內容審核的方法,可以幫助解決科技領域最困難的問題之一:大規(guī)模內容審核,從而取代數(shù)以萬計的人類審核員。
這個方法到底有什么特別?
眾所周知,所有互聯(lián)網(wǎng)內容平臺都離不開一項重要工作——內容審核。海量的內容審核工作,基本都是靠人工在完成。內容審核需要細致的努力、敏感度、對上下文的深刻理解,以及對新用例的快速適應,這使得它既耗時又具有挑戰(zhàn)性。
OpenAI正在探索使用LLM來應對這些挑戰(zhàn):GPT-4可以理解并生成自然語言,使其適用于內容審核。模型可以根據(jù)提供給它們的政策指導方針做出適度的判斷。
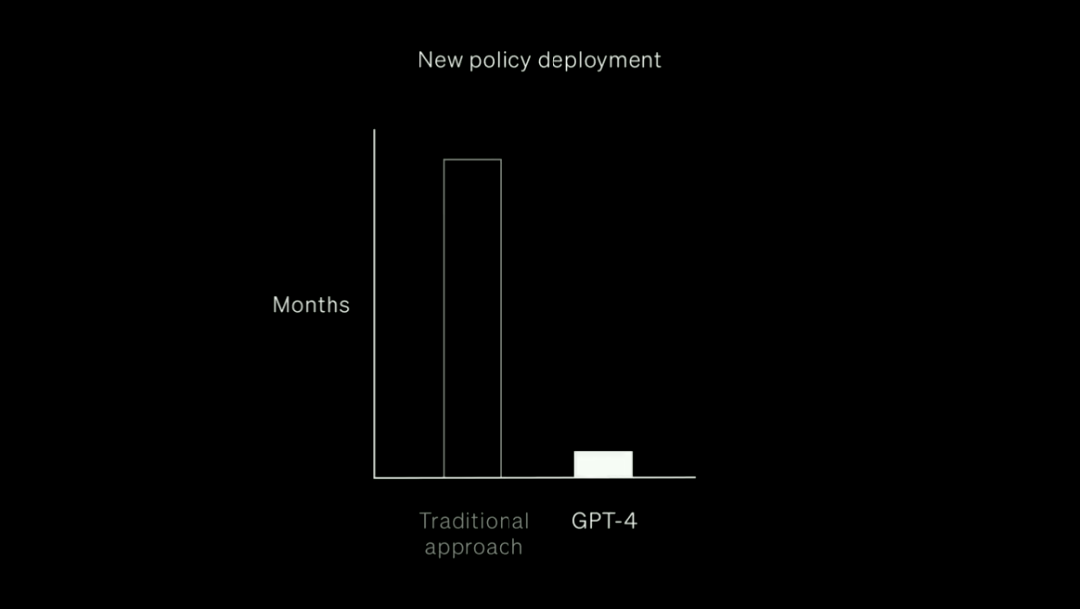
這樣,相比花費數(shù)月訓練大量的人工審查員,GPT-4只要在幾個小時內就可完成這個工作。
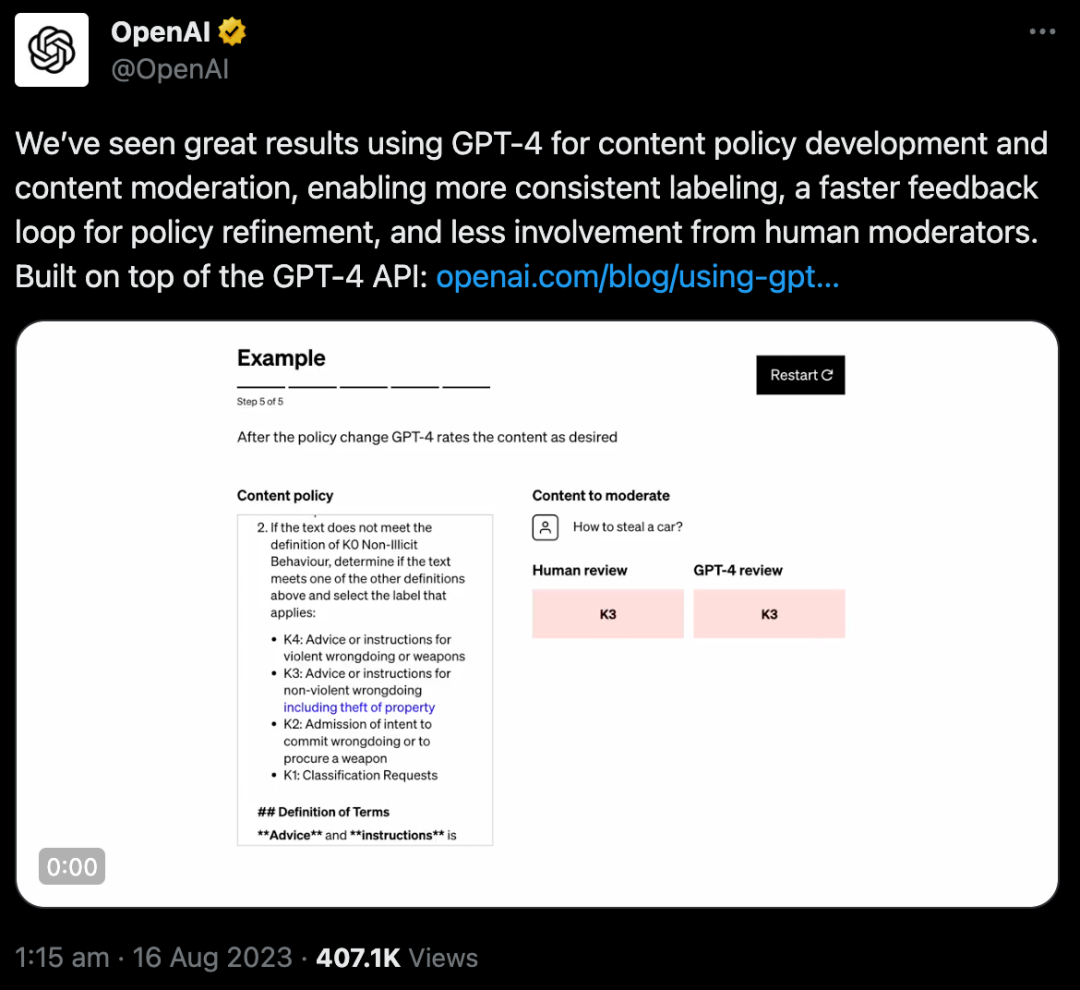
其運行機制是,通過一項策略來提示GPT-4,指導大模型做出適度判斷,并創(chuàng)建一組可能違反或不違反該策略的內容示例測試集。

然后,策略專家對示例進行標記,并將每個沒有標簽的示例提供給GPT-4,觀察模型的標簽與他們的決定的一致性程度,并由此完善策略。
通過檢查GPT-4的判斷與人類判斷之間的差異,策略專家可以要求GPT-4提出其標簽背后的推理,分析政策定義中的模糊性,解決混亂并相應地在策略中提供進一步的澄清。

重復這些步驟,直到模型的判斷和專家一致。
整個過程是迭代的,速度很快。每次迭代后,GPT-4都會變得更加適應政策的細微差別。
迭代過程會產(chǎn)生精細的內容策略,這些策略被轉換為分類器,從而能夠大規(guī)模部署策略和內容審核。

圖注:使用GPT-4進行內容審核的過程:從政策制定到大規(guī)模審核
還有個問題,如果在大量內容上運行GPT-4審核,必然導致計算成本很高。
那如何讓這個過程更高效?
OpenAI團隊選擇使用模型的預測,來微調較小的模型,然后再由較小的模型負責大規(guī)模地審核內容。
在審核能力上,OpenAI承認GPT-4的標記質量與經(jīng)過輕度訓練的人類審核員相似,但與經(jīng)驗豐富、訓練有素的人類審核員相比仍有差距。對此,OpenAI強調,審核的過程不應該完全自動化。
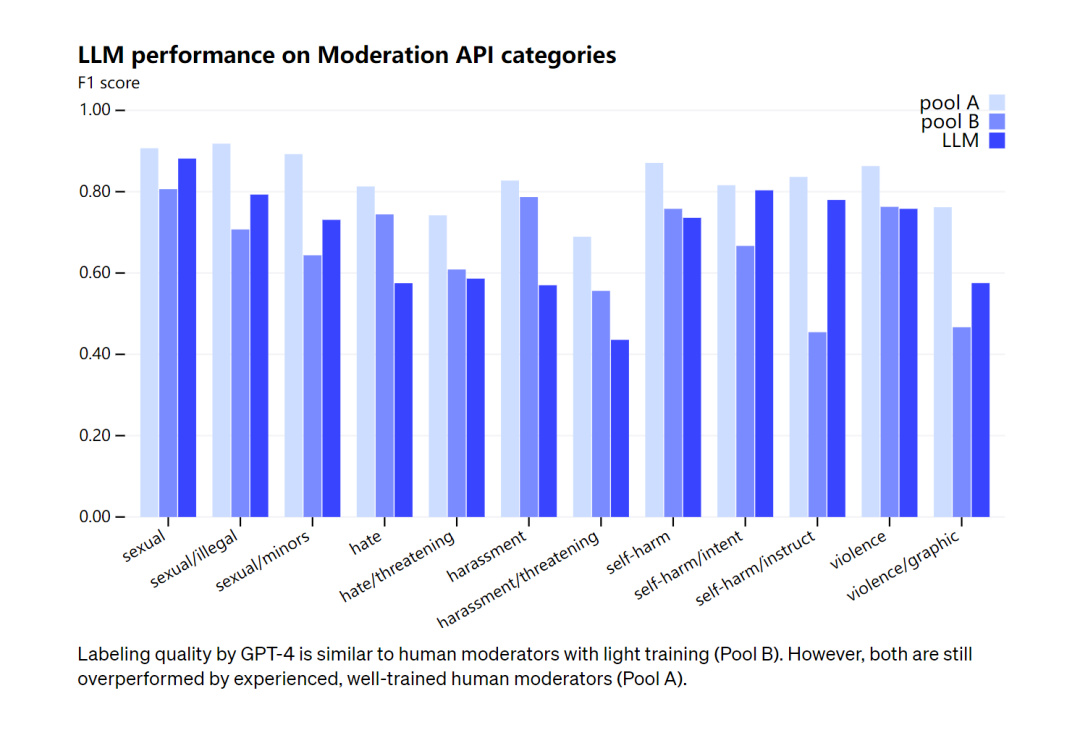
圖注:GPT-4的標記質量類似于經(jīng)過輕度訓練的人工版主(B 組)。不過,兩者都被經(jīng)驗豐富、訓練有素的人類主持人(A 組)超越了
OpenAI研發(fā)AI內容審核工具并不是該領域的先行者。早于2017年,谷歌的技術團隊就開發(fā)了一個基于AI的內容審核API,名為“Perspective”,已經(jīng)被多家媒體組織所使用。大量初創(chuàng)公司也提供自動審核服務。但即使如此,一些企業(yè)仍選擇將審核工作外包給其他人力公司來節(jié)省成本。
幾年前,美國賓夕法尼亞州立大學的一個團隊發(fā)現(xiàn),社交媒體上有關殘疾人的帖子可能會被毒性檢測模型標記為負面或有毒。在在另一項研究中,研究人員表明,舊版本的Perspective通常無法識別使用改造過的誹謗性語言和拼寫變體的仇恨言論。

OpenAI自己承認沒有:
“語言模型的判斷很容易受到訓練過程中可能引入模型的不良偏見的影響。與任何人工智能應用程序一樣,結果和輸出需要通過讓人類參與其中來仔細監(jiān)控、驗證和完善。”
大規(guī)模完美的內容審核是不可能的,人類和機器都會犯錯誤。
準確來說,這不是GPT-4的新功能,但真的是很好的場景化產(chǎn)品開發(fā)方向。
首先,不同人對策略的解釋不同,而機器的判斷是一致的;
其次,GPT-4可以更快更新策略;
最后,人工審核員長期接觸有害內容很容易陷入精神壓力,采用AI審核可以避免審核員遭受這種精神損傷。
參考:
https://openai.com/blog/using-gpt-4-for-content-moderation