
【深度學習】Transformer溫故知新
這是之前學習paddle時候的筆記,對Transformer框架進行了拆解,附圖解和代碼,希望對大家有幫助?
寫在前面
最近在學習paddle相關內容,質量比較高的參考資料好像就paddle官方文檔[1]。所以如果大家想學習一下的話,可以先簡單過一遍文檔,如果你之前有tensorflow或者torch的基礎,看起來應該會比較快,都差不多的嘛。然后細節(jié)的部分就可以去實戰(zhàn)看(寫)代碼了。下面是一個用paddle實現(xiàn)的目前NLP領域最火的Transformer模型,包括模型詳細的拆解可視化以及對應每一步的代碼實現(xiàn),enjoy!
Encoder Part Residuals & Layer Norm Feed Forward Self-Attention 完整Encoder代碼 Decoder Part Masked Multi-Head Attention Encoder-Decoder Attention 整體Decoder代碼 Full Transformer
一、Encoder Part
下圖是一個encoder block,可以看到主要由以下四部分組成:
Self-Attention Feed Forward Residual Connection Layer Norm
下面我們由簡單至復雜來搭建每一部分并給出對應代碼。
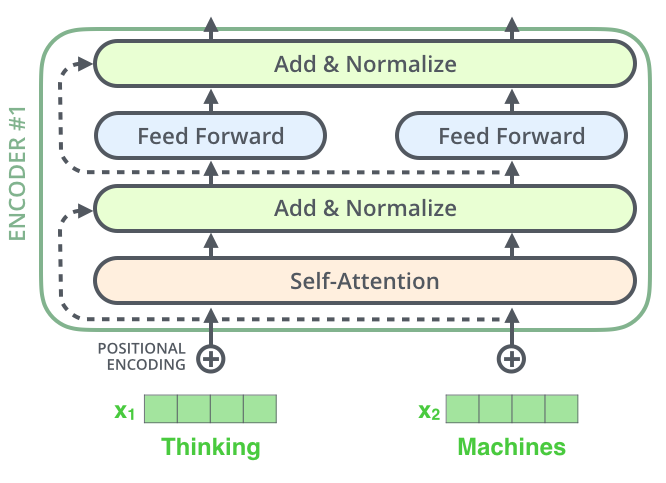
1、Residuals & Layer Norm
也就是上圖中淺綠色框框中的內容。
「殘差層」:大多數(shù)關于transformer的文章對于Residual的介紹都比較簡單,但是實際上殘差層在整個網(wǎng)絡中的作用非常重要,它可以有效解決網(wǎng)絡模型層數(shù)增大而引起的信息損失問題,來自kaiming大神的Deep residual learning for image recognition[2]; 「歸一化」:神經網(wǎng)絡中關于歸一化的做法有很多,這里使用的是層歸一化,更詳細的資料推薦張俊林老師的深度學習中的Normalization模型[3]
def pre_post_process_layer(prev_out, out, process_cmd, dropout_rate=0.):"""根據(jù)process_cmd的值來設置不同的操作"""for cmd in process_cmd:if cmd == "a": # 添加residual connectionout = out + prev_out if prev_out else outelif cmd == "n": # 添加layer normalizationout = layers.layer_norm(out, begin_norm_axis=len(out.shape)-1,param_attr=fluid.initializer.Constant(1.),bias_attr=fluid.initializer.Constant(0.))elif cmd == "d": # 添加dropoutif dropout_rate:out = layers.dropout(out,dropout_prob=dropout_rate,seed=dropout_seed,is_test=False)return out
2、Feed Forward
前饋層,上圖中藍色框框,包括兩個線性變換,使用的激活函數(shù)為「relu」
注意,self-attention是對所有輸入統(tǒng)一處理的,而前饋層是position-wise的。參數(shù)在同一層是共享的,但是在層與層之間是獨立的。輸入和輸出的維度 ,內層的維度
def positionwise_feed_forward(x, d_inner_hid, d_hid, dropout_rate):hidden = layers.fc(input=x,size=d_inner_hid,num_flatten_dims=2,act="relu")if dropout_rate:hidden = layers.dropout(hidden, dropout_prob=dropout_rate, seed=dropout_seed, is_test=False)out = layers.fc(input=hidden, size=d_hid, num_flatten_dims=2)return out
3、Self-Attention
Transformer中最重要的組成部分。在所有的attention中最關鍵就是要理解三個概念:、、。很多同學可能都對這三個詞非常熟悉,但是對其具體對應的實體非常模糊,這里我們以檢索為例介紹一下其原理,看看能不能理解。(已經了解的自行跳過haha)
比如你現(xiàn)在想要了解一下「自然語言處理」的相關信息,你就會去搜索框里輸入
自然語言處理,這時候你輸入的就是 ;接著搜索庫里會有很多文檔,想要返回你的搜索結果,一個簡單的思路就是看看你的搜索內容和文檔title的相似度,這時候每個文檔title就是 ,將 和每個 做點乘計算相似度,我們會得到一系列數(shù)值 ,然后用這一組值對文檔,也就是我們的 進行加權召回,按得分降序返回。
所以本質上我們可以將Attention簡單理解為「加權和」。更為具體的注意力介紹可以參考我之前的博客:理解Attention機制原理及模型[4]
3.1 Scaled Dot Product Attention
下面來看看具體在文本中是怎么運算的。
每一個輸入經過Embedding層后轉化成詞向量 ; 所有token都會經過三個可學習矩陣分別映射為三個向量 、、, 對每一個單詞,將其作為 ,所有單詞作為 ,計算相似度得分; 將相似度得分進行規(guī)一化后與對應的 相乘,得出加權和,即為該單詞的注意力得分。
公式為:
其可視化過程如下圖,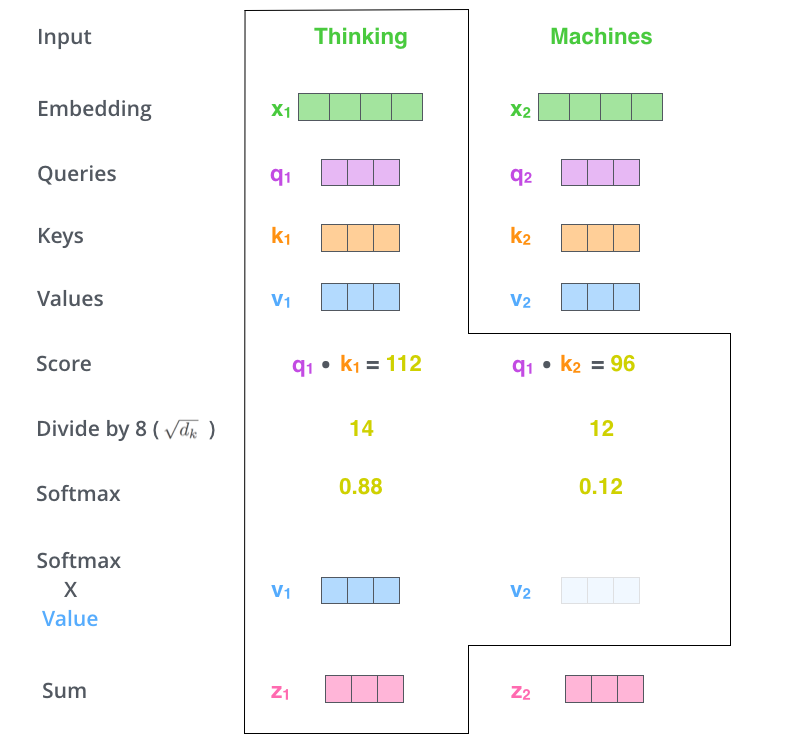
轉換成矩陣形式可以簡化表示為,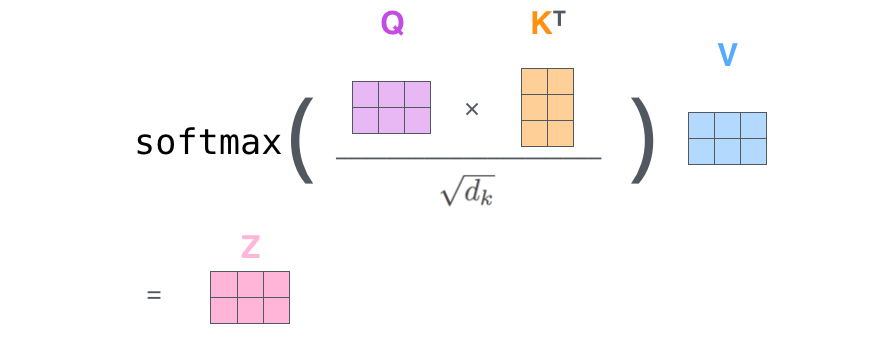
def __compute_qkv(queries, keys, values, n_head, d_key, d_value):"""上述第二步,將輸入通過三個可學習的矩陣映射為query、value和key"""q = layers.fc(input=queries,size=d_key*n_head,bias_attr=False,num_flatten_dims=2)fc_layer = wrap_layer_with_block(layers.fc, fluid.default_main_program().current_block().parent_idx) if cache is not None and static_kv else layers.fck = fc_layer(input=keys,size=d_key*n_head,bias_attr=False,num_flatten_dims=2)v = fc_layer(input=values,size=d_value*n_head,bias_attr=False,num_flatten_dims=2)return q, k, v
def scaled_dot_product_attention(q, k, v, attn_bias, d_key, dropout_rate):"""上述第三、四步,計算attention得分"""product = layers.matmul(x=q, y=k, transpose_y=True, alpha=d_key**-0.5)if attn_bias:product += attn_biasweights = layers.softmax(product)if dropout_rate:weights = layers.dropout(weights,dropout_prob=dropout_rate,seed=dropout_seed,is_test=False)out = layers.matmul(weights, v)return out
注意scaled_dot_product_attention函數(shù)中有一個attn_bias的操作,作用是mask掉指定的位置。在整個transformer的結構中,使用的地方有三處:
Encoder的self-attention,作用是mask掉padding的位置; Decoder的encoder-self-attention,作用是mask掉padding的位置; Decoder的masked-self-attention,作用是解碼過程mask掉當前詞之后的詞信息
3.2 Multi-Head Attention
multi-head的出發(fā)點是為了讓模型在多個不同的子空間中學習到不同方面的信息,幫助模型捕獲更豐富的特征。
操作也非常容易理解,
首先將輸入映射為 、、, 接著拆分成 個注意力頭,并行地運算上一節(jié)中的 Scaled Dot Product Attention,最后將結果進行拼接。
整體計算公式為:
可視化如下圖所示: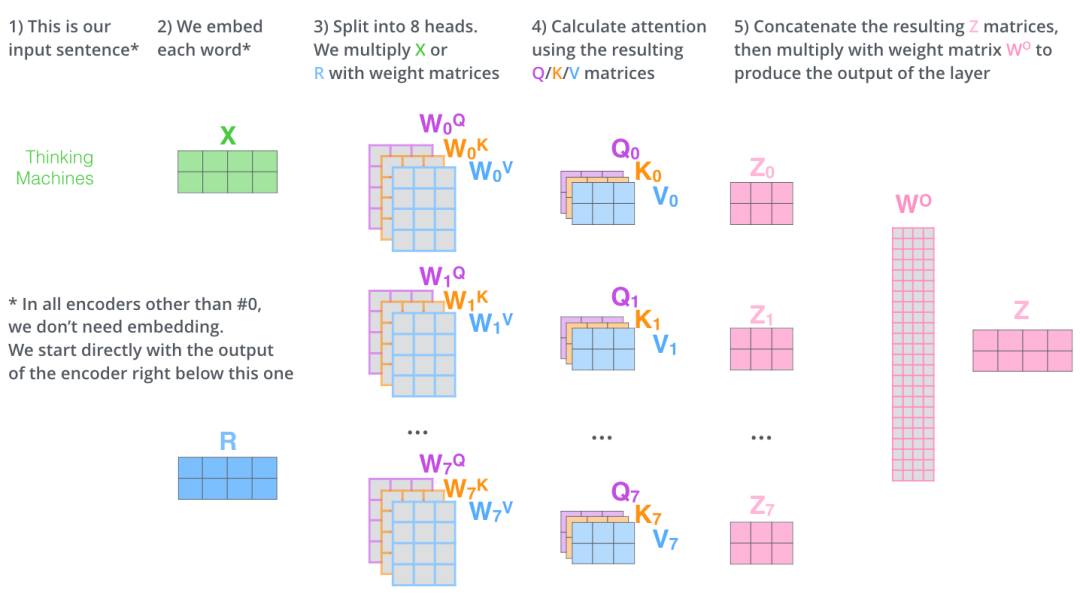
3.2.1 拆分
在輸入張量的最后一個維度上進行reshape以拆分出多頭,然后轉置方便后續(xù)運算。具體而言,將輸入形狀為[bs,max_sequence_length,n_head * hidden_dim]轉換為[bs,n_head,max_sequence_length,hidden_dim]
def __split_heads_qkv(queries, keys, values, n_head, d_key, d_value):# reshape:這里shape參數(shù)里的0表示從輸入張量對應維數(shù)直接復制出來# inplace=True,不進行數(shù)據(jù)的復制,運算更為高效reshaped_q = layers.reshape(x=queries, shape=[0, 0, n_head, d_key], inplace=True)# 轉置:perm參數(shù)表示將第一個和第二個維度交換q = layers.transpose(x=reshaped_q, perm=[0, 2, 1, 3])reshape_layer = wrap_layer_with_block(layers.reshape,fluid.default_main_program().current_block().parent_idx)if cache is not None and static_kv else layers.reshapetranspose_layer = wrap_layer_with_block(layers.transpose,fluid.default_main_program().current_block().parent_idx)if cache is not None and static_kv else layers.transposereshaped_k = reshape_layer(x=keys, shape=[0, 0, n_head, d_key], inplace=True)k = transpose_layer(x=reshaped_k, perm=[0, 2, 1, 3])reshaped_v = reshape_layer(x=values, shape=[0, 0, n_head, d_value], inplace=True)v = transpose_layer(x=reshaped_v, perm=[0, 2, 1, 3])# 設計的優(yōu)化,包括推斷過程的緩存和處理流程if cache is not None:cache_, i = cacheif static_kv:cache_k, cache_v = cache_["static_k"], cache_["static_v"]static_cache_init = wrap_layer_with_block(layers.assign,fluid.default_main_program().current_block().parent_idx)static_cache_init(k,fluid.default_main_program().global_block().var("static_k_%d" % i))static_cache_init(v,fluid.default_main_program().global_block().var("static_v_%d" % i))k, v = cache_k, cache_velse:cache_k, cache_v = cache_["k"], cache_["v"]k = layers.concat([cache_k, k], axis=2)v = layers.concat([cache_v, v], axis=2)cache_["k"], cache_["v"] = (k, v)return q, k, v
3.2.2 ?合并
可以認為是上一節(jié)拆分的逆操作,先是transpose,再是reshape。具體而言,將輸入形狀為[bs,n_head,max_sequence_length,hidden_dim]轉換為[bs,max_sequence_length,n_head * hidden_dim]
def __combine_heads(x):# 首先驗證輸入形狀if len(x.shape) != 4:raise ValueError("Input(x) should be a 4-D Tensor.")trans_x = layers.transpose(x, perm=[0, 2, 1, 3])return layers.reshape(x=trans_x,shape=[0, 0, trans_x.shape[2] * trans_x.shape[3]],inplace=True)
3.2.3 整體
有了前面幾節(jié)的函數(shù)操作之后,就可以構建整體multi-head attention了
def multi_head_attention(queries,keys,values,attn_bias,d_key,d_value,d_model, n_head=1,dropout_rate=0.,cache=None,static_kv=False):keys = queries if keys is None else keysvalues = keys if values is None else values## 檢查輸入形狀if not (len(queries.shape) == len(keys.shape) == len(values.shape) == 3):raise ValueError("Inputs: quries, keys and values should all be 3-D tensors.")q, k, v = __compute_qkv(queries, keys, values, n_head, d_key, d_value)q, k, v = __split_heads_qkv(q, k, v, n_head, d_key, d_value)ctx_multiheads = scaled_dot_product_attention(q, k, v, attn_bias, d_model,dropout_rate)out = __combine_heads(ctx_multiheads)proj_out = layers.fc(input=out,size=d_model,bias_attr=False,num_flatten_dims=2)return proj_out
4、完整Encoder代碼
有了上面的鋪墊之后,我們就可以寫出encoder的代碼框架了。具體代碼篇幅原因就不再粘貼,可以根據(jù)開篇所述方式獲取。
二、Decoder Part
ok,我們先停下來回顧一下前面都解決了哪些內容:
Encoder包含的幾個部分:self-attention、feed-forward、add&norm 詳細介紹了Scaled Dot Product Attention原理及代碼實現(xiàn) 詳細介紹了Multi-Head Attention原理及代碼實現(xiàn)
接下去來看看transformer的右半部分:Decoder。如下圖所示,是一個decoder block,主要由五部分組成:
Encoder-Decoder Attention (Masked)Self-Attention Feed Forward Residual Connection Layer Norm 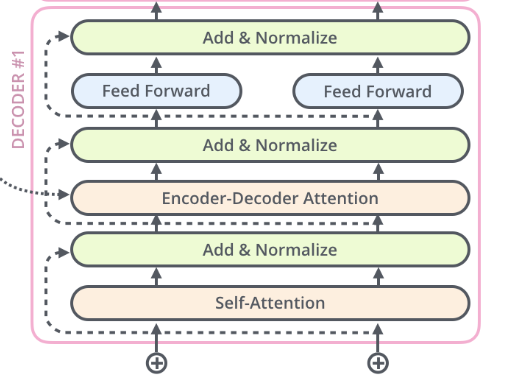
1、Masked Multi-Head Attention
關于這個,我們在前面3.1節(jié)其實有過說明,當解碼第 個特征向量時,我們只能看到其之前的解碼結果,這樣做的目的也很直觀,防止信息泄露,因為我們總不能偷看答案吧哈哈。
那么具體怎么做呢?其實也不難:構造一個mask矩陣,上三角全為0,表示無法attend未來的信息,如下,
2、Encoder-Decoder Attention
其實Deocer的五個組件我們在Encoder Part里面已經完成了四個部分,只剩下一個Encoder-Decoder Attention是沒有涉及的。其實這個跟encoder_layer的差不多,只不過是它的 和 來自encoder的輸出,而 則來自decoder的上一個輸出。
可視化動圖就更清楚了,
3、整體Decoder代碼
不啰嗦了,跟encoder很類似,看代碼也很直觀。
三、Full Transformer
終于快寫完了....
最后我們就像搭積木一樣,把前面的部分組建成一個完整的transformer網(wǎng)絡,如下圖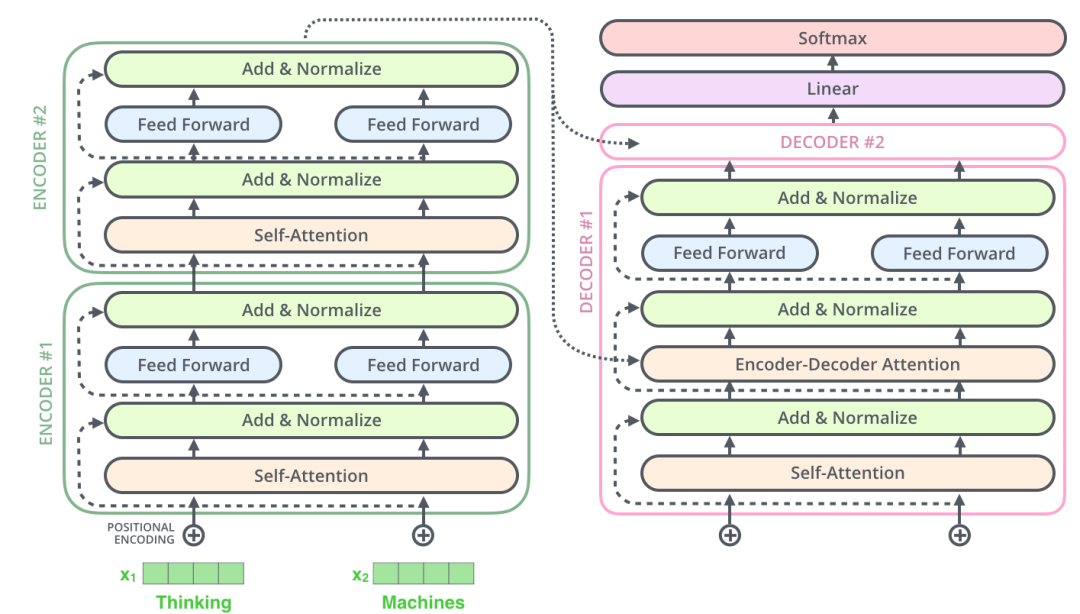
def transformer(model_input,src_vocab_size,trg_vocab_size,max_length,n_layer,n_head,d_key,d_value,d_model,d_inner_hid,prepostprocess_dropout,attention_dropout,relu_dropout,preprocess_cmd,postprocess_cmd,weight_sharing,label_smooth_eps,bos_idx=0,is_test=False):if weight_sharing:assert src_vocab_size == trg_vocab_size, ("Vocabularies in source and target should be same for weight sharing.")enc_inputs = (model_input.src_word, model_input.src_pos,model_input.src_slf_attn_bias)dec_inputs = (model_input.trg_word, model_input.trg_pos,model_input.trg_slf_attn_bias, model_input.trg_src_attn_bias)label = model_input.lbl_wordweights = model_input.lbl_weightenc_output = wrap_encoder(enc_inputs,src_vocab_size,max_length,n_layer,n_head,d_key,d_value,d_model,d_inner_hid,prepostprocess_dropout,attention_dropout,relu_dropout,preprocess_cmd,postprocess_cmd,weight_sharing,bos_idx=bos_idx)predict = wrap_decoder(dec_inputs,trg_vocab_size,max_length,n_layer,n_head,d_key,d_value,d_model,d_inner_hid,prepostprocess_dropout,attention_dropout,relu_dropout,preprocess_cmd,postprocess_cmd,weight_sharing,enc_output=enc_output)# Padding index do not contribute to the total loss. The weights is used to# cancel padding index in calculating the loss.if label_smooth_eps:# TODO: use fluid.input.one_hot after softmax_with_cross_entropy removing# the enforcement that the last dimension of label must be 1.label = layers.label_smooth(label=layers.one_hot(input=label, depth=trg_vocab_size),epsilon=label_smooth_eps)cost = layers.softmax_with_cross_entropy(logits=predict,label=label,soft_label=True if label_smooth_eps else False)weighted_cost = layers.elementwise_mul(x=cost, y=weights, axis=0)sum_cost = layers.reduce_sum(weighted_cost)token_num = layers.reduce_sum(weights)token_num.stop_gradient = Trueavg_cost = sum_cost / token_numreturn sum_cost, avg_cost, predict, token_num
積木搭好了,我們怎么調用呢?下面就可以寫一個create_net函數(shù),接受輸入為is_training(是否訓練階段),model_input(模型輸入),args(一些詞表、維度、長度等模型參數(shù))
def create_net(is_training, model_input, args):if is_training:sum_cost, avg_cost, _, token_num = transformer(model_input, args.src_vocab_size, args.trg_vocab_size,args.max_length + 1, args.n_layer, args.n_head, args.d_key,args.d_value, args.d_model, args.d_inner_hid,args.prepostprocess_dropout, args.attention_dropout,args.relu_dropout, args.preprocess_cmd, args.postprocess_cmd,args.weight_sharing, args.label_smooth_eps, args.bos_idx)return sum_cost, avg_cost, token_numelse:out_ids, out_scores = fast_decode(model_input, args.src_vocab_size, args.trg_vocab_size,args.max_length + 1, args.n_layer, args.n_head, args.d_key,args.d_value, args.d_model, args.d_inner_hid,args.prepostprocess_dropout, args.attention_dropout,args.relu_dropout, args.preprocess_cmd, args.postprocess_cmd,args.weight_sharing, args.beam_size, args.max_out_len, args.bos_idx,args.eos_idx)return out_ids, out_scores
本文參考資料
paddle官方文檔: https://www.paddlepaddle.org.cn/
[2]Deep residual learning for image recognition: https://arxiv.org/abs/1512.03385
[3]深度學習中的Normalization模型: https://zhuanlan.zhihu.com/p/43200897
[4]理解Attention機制原理及模型: https://blog.csdn.net/Kaiyuan_sjtu/article/details/81806123
-?END?-
往期精彩回顧
適合初學者入門人工智能的路線及資料下載 (圖文+視頻)機器學習入門系列下載 中國大學慕課《機器學習》(黃海廣主講) 機器學習及深度學習筆記等資料打印 《統(tǒng)計學習方法》的代碼復現(xiàn)專輯 機器學習交流qq群955171419,加入微信群請掃碼: