
自動(dòng)駕駛中多模態(tài)三維目標(biāo)檢測(cè)研究綜述
1. 引言
自動(dòng)駕駛感知模塊
首先,它需要是準(zhǔn)確的,并給出了駕駛環(huán)境的準(zhǔn)確描述。 其次,具有魯棒性。能在惡劣天氣下、甚至當(dāng)一些傳感器退化甚至失效時(shí)保證AV的穩(wěn)定與安全。 第三,實(shí)時(shí)性,能提供快速的反饋。


3D目標(biāo)檢測(cè)

多模態(tài)目標(biāo)檢測(cè)

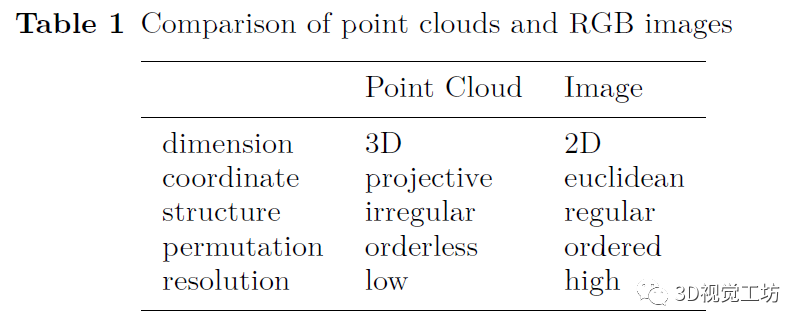
多傳感器校準(zhǔn)和數(shù)據(jù)對(duì)齊:由于多模態(tài)數(shù)據(jù)的異質(zhì)性(如表1所示),無(wú)論是在原始輸入空間還是在特征空間,都很難對(duì)它們進(jìn)行精確對(duì)齊。 信息丟失:我們以計(jì)算為代價(jià),將傳感器數(shù)據(jù)轉(zhuǎn)換為一種可以對(duì)齊的處理格式,信息丟失是不可避免的。 跨模態(tài)數(shù)據(jù)增強(qiáng):數(shù)據(jù)增強(qiáng)在3D目標(biāo)檢測(cè)中起著至關(guān)重要的作用,可以防止模型過(guò)擬合。全局旋轉(zhuǎn)和隨機(jī)翻轉(zhuǎn)等增強(qiáng)策略在單模態(tài)融合方法中得到了廣泛的應(yīng)用,但由于多傳感器一致性的問(wèn)題,許多多傳感器融合方法都缺少這種增強(qiáng)策略。 數(shù)據(jù)集與評(píng)價(jià)指標(biāo):高質(zhì)量、可公開(kāi)使用的多模態(tài)數(shù)據(jù)集數(shù)量有限。即使是現(xiàn)有的數(shù)據(jù)集也存在規(guī)模小、類(lèi)別不平衡、標(biāo)記錯(cuò)誤等問(wèn)題。此外,目前還沒(méi)有針對(duì)多傳感器融合模型的評(píng)價(jià)指標(biāo),這給多傳感器融合方法之間的比較帶來(lái)了困難。
本文貢獻(xiàn)
根據(jù)輸入傳感器數(shù)據(jù)的不同組合,對(duì)基于多模態(tài)的3D目標(biāo)檢測(cè)方法進(jìn)行分類(lèi)。特別是range image(點(diǎn)云的一種信息完整形式)、pseudo-LiDARs (由相機(jī)圖像生成),在過(guò)去的綜述文章中沒(méi)有進(jìn)行討論。 從多個(gè)角度仔細(xì)研究了基于多模態(tài)的3D目標(biāo)檢測(cè)方法的發(fā)展。重點(diǎn)關(guān)注這些方法如何實(shí)現(xiàn)跨模態(tài)數(shù)據(jù)對(duì)齊,如何減少信息損失等關(guān)鍵問(wèn)題。 對(duì)基于深度學(xué)習(xí)的相機(jī)-LiDAR融合的方法進(jìn)行詳細(xì)對(duì)比總結(jié)。同時(shí),我們還介紹了近年來(lái)可用于3D目標(biāo)檢測(cè)的多模態(tài)數(shù)據(jù)集。 仔細(xì)探討具有挑戰(zhàn)性的問(wèn)題,以及可能的解決方案,希望能夠啟發(fā)一些未來(lái)的研究。
2. 背景
基于相機(jī)的3D目標(biāo)檢測(cè)

基于LiDAR的3D目標(biāo)檢測(cè)

基于其他傳感器的3D目標(biāo)檢測(cè)

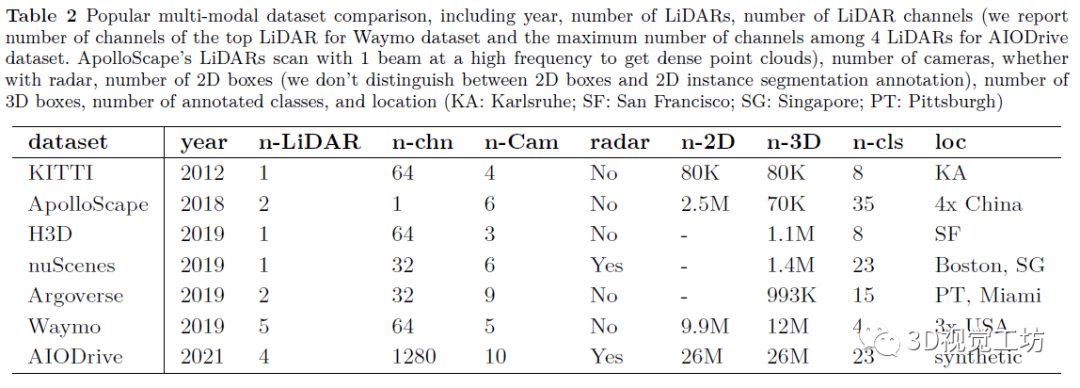
3. 數(shù)據(jù)集與評(píng)價(jià)指標(biāo)

4. 基于深度學(xué)習(xí)的多模態(tài)3D檢測(cè)網(wǎng)絡(luò)
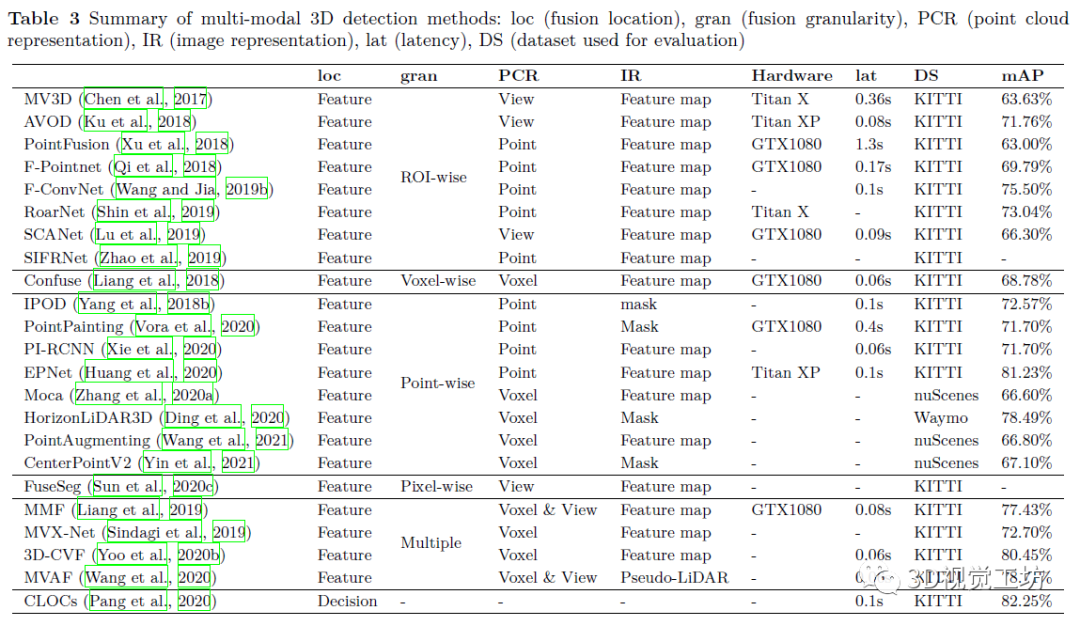
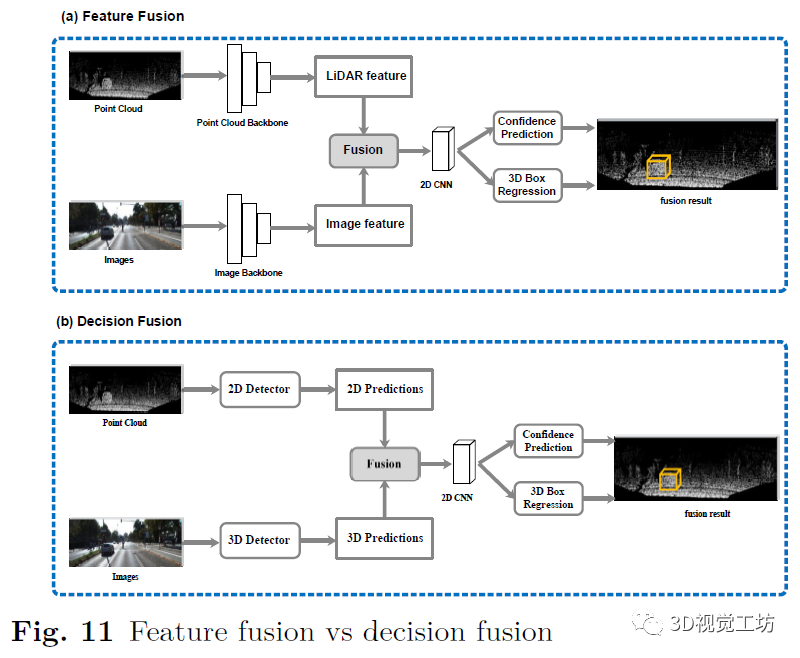
特征融合
Point cloud view & image feature map point cloud voxels & image feature map LiDAR points & image feature map LiDAR points & image mask: point cloud voxels & image mask point cloud voxels & point cloud view & image feature map point cloud voxels & image feature map & image pseudo-LiDAR

決策融合

相機(jī)-LiDAR融合方法總結(jié)
其他傳感器融合方式
5. 開(kāi)放式挑戰(zhàn)與可能的解決方案
多傳感器聯(lián)合標(biāo)定 數(shù)據(jù)對(duì)齊 跨模態(tài)數(shù)據(jù)增強(qiáng) 數(shù)據(jù)集與評(píng)價(jià)指標(biāo)

6. 總結(jié)
原創(chuàng)征稿
3D視覺(jué)工坊是基于優(yōu)質(zhì)原創(chuàng)文章的自媒體平臺(tái),創(chuàng)始人和合伙人致力于發(fā)布3D視覺(jué)領(lǐng)域最干貨的文章,然而少數(shù)人的力量畢竟有限,知識(shí)盲區(qū)和領(lǐng)域漏洞依然存在。為了能夠更好地展示領(lǐng)域知識(shí),現(xiàn)向全體粉絲以及閱讀者征稿,如果您的文章是3D視覺(jué)、CV&深度學(xué)習(xí)、SLAM、三維重建、點(diǎn)云后處理、自動(dòng)駕駛、三維測(cè)量、VR/AR、3D人臉識(shí)別、醫(yī)療影像、缺陷檢測(cè)、行人重識(shí)別、目標(biāo)跟蹤、視覺(jué)產(chǎn)品落地、硬件選型、求職分享等方向,歡迎砸稿過(guò)來(lái)~文章內(nèi)容可以為paper reading、資源總結(jié)、項(xiàng)目實(shí)戰(zhàn)總結(jié)等形式,公眾號(hào)將會(huì)對(duì)每一個(gè)投稿者提供相應(yīng)的稿費(fèi),我們支持知識(shí)有價(jià)!
▲長(zhǎng)按關(guān)注公眾號(hào)
評(píng)論
圖片
表情