
知識圖譜數(shù)據(jù)庫讀寫性能基準測試

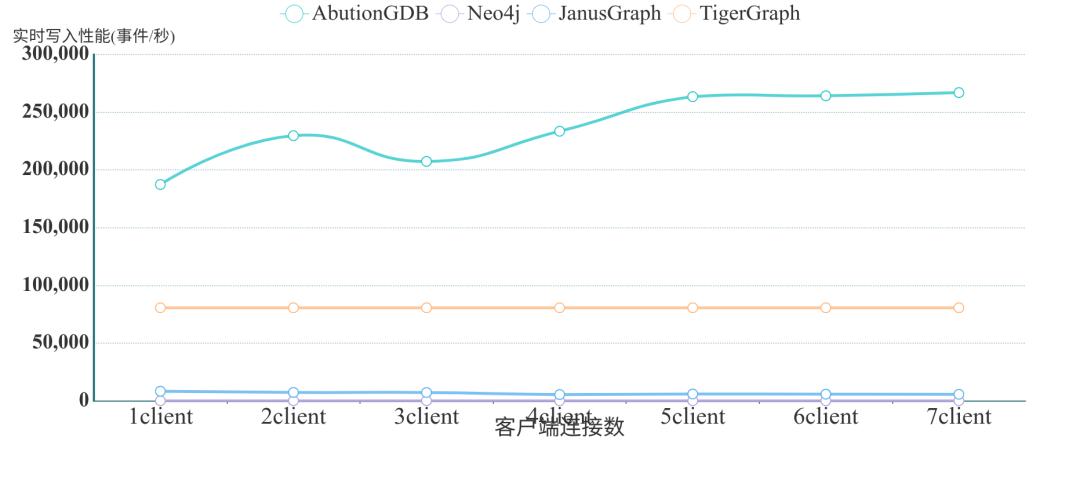
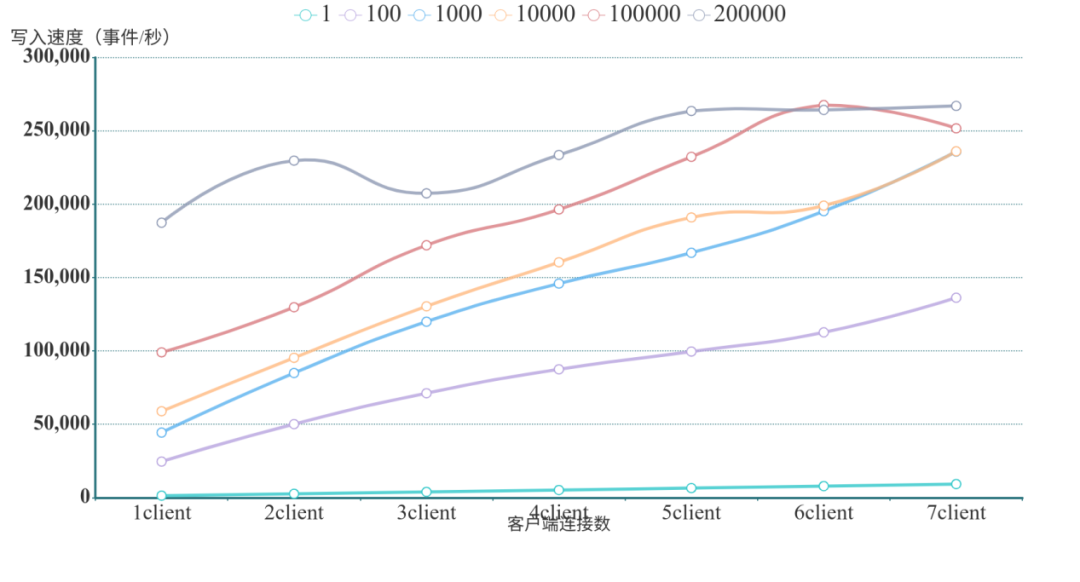
表1:實時批量寫入事件數(shù)性能測試結(jié)果
測試用數(shù)據(jù)說明
圖1數(shù)據(jù)示例

統(tǒng)計結(jié)果說明
AbutionGDB與其他數(shù)據(jù)庫單節(jié)點對比測試
測試環(huán)境及步驟說明
寫入性能對比
AbutionGDB批量實時寫入結(jié)果
 ?
?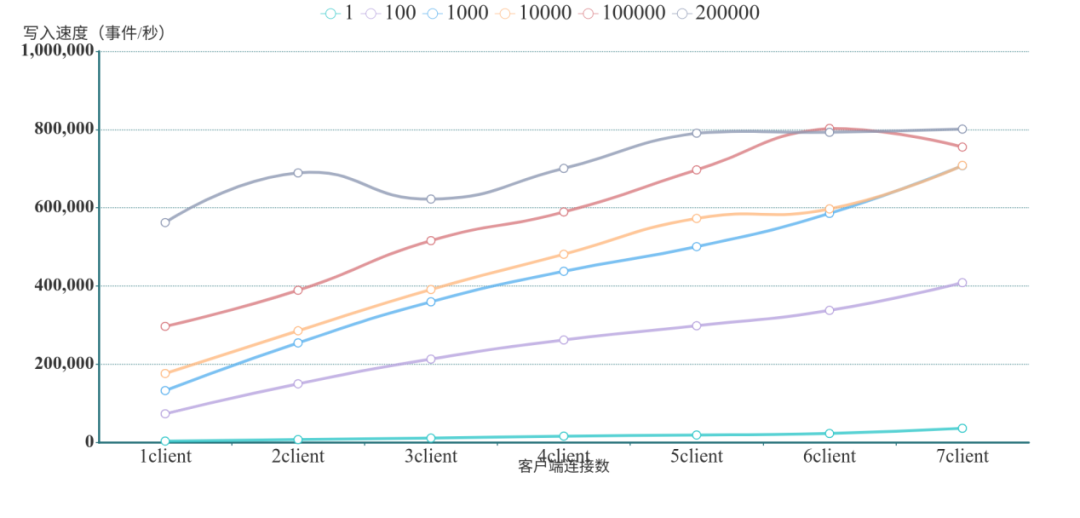 ? ? ?
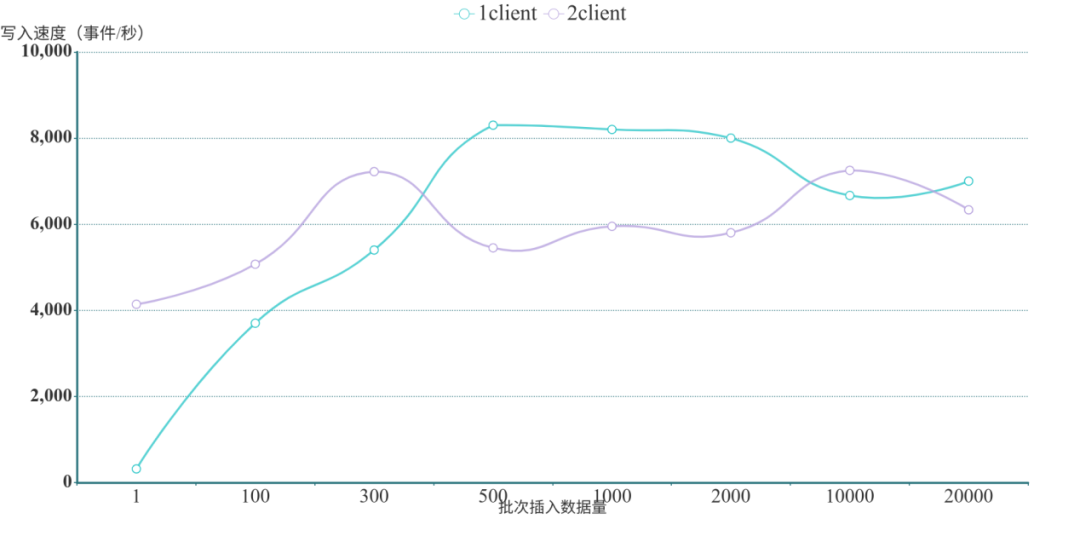
? ? ?Neo4j批量實時寫入結(jié)果
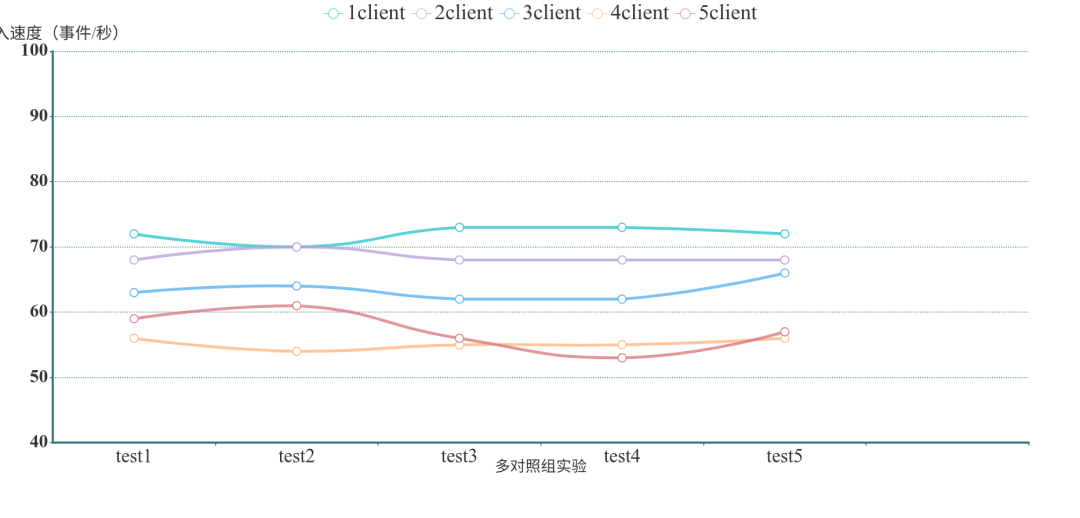 ?
?
TigerGraph批量實時寫入結(jié)果
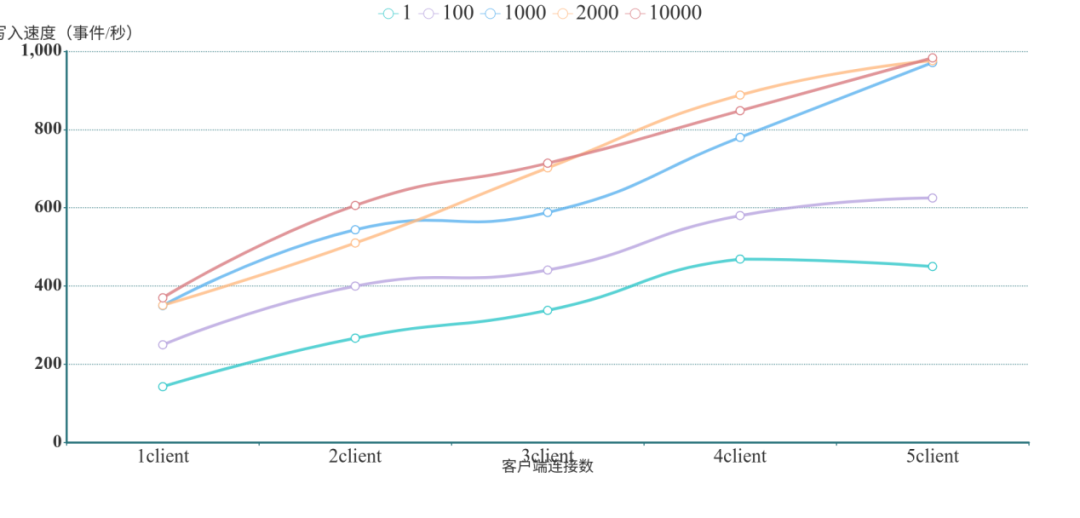 ? ? ?
? ? ?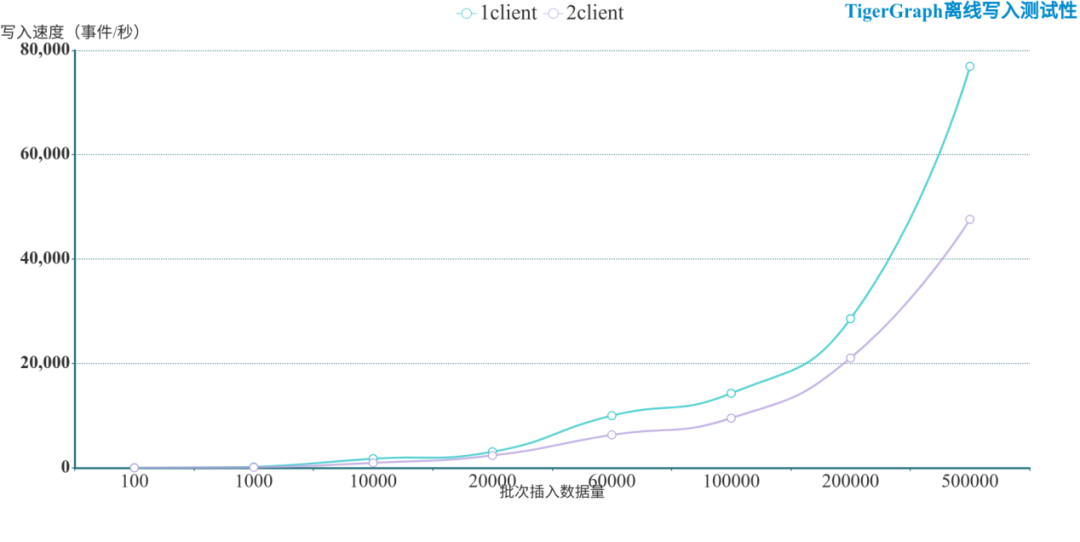 ? ? ?
? ? ?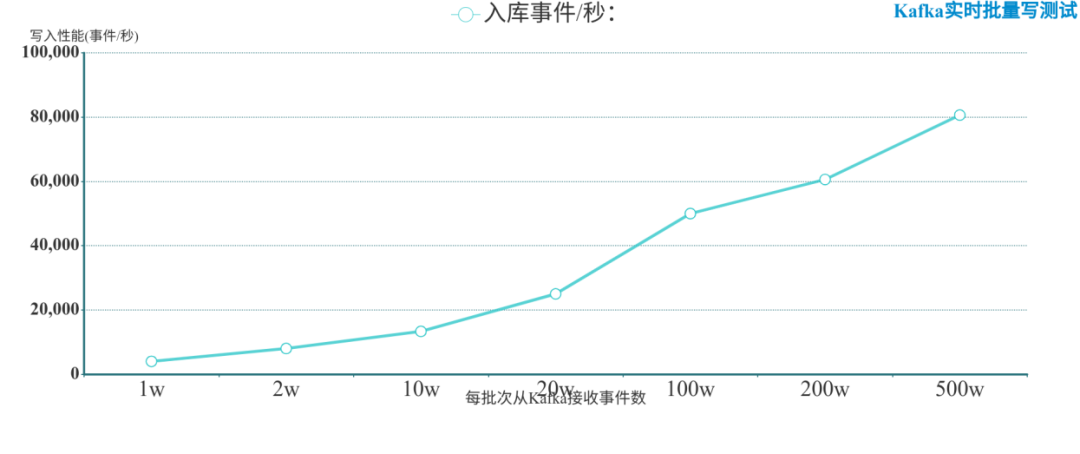 ? ? ?
? ? ?
? ? ?
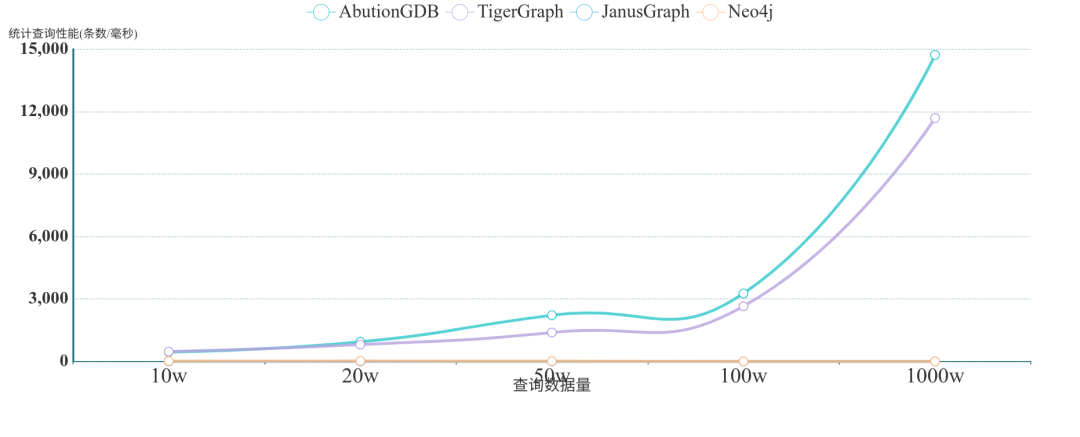
? ? ?讀取性能對比
? ? ?
評論
圖片
表情