
如何用 OpenCV、Python 和深度學(xué)習(xí)實(shí)現(xiàn)面部識(shí)別?
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文轉(zhuǎn)自|新機(jī)器視覺(jué)

Face ID 的興起帶動(dòng)了一波面部識(shí)別技術(shù)熱潮。本文將介紹如何使用 OpenCV、Python 和深度學(xué)習(xí)在圖像和視頻中實(shí)現(xiàn)面部識(shí)別,以基于深度識(shí)別的面部嵌入,實(shí)時(shí)執(zhí)行且達(dá)到高準(zhǔn)確度。

以下為譯文:
想知道怎樣用OpenCV、Python和深度學(xué)習(xí)進(jìn)行面部識(shí)別嗎?
這篇文章首先將簡(jiǎn)單介紹下基于深度學(xué)習(xí)的面部識(shí)別的工作原理,以及“深度度量學(xué)習(xí)”(deep metric learning)的概念。接下來(lái)我會(huì)幫你安裝好面部識(shí)別需要的庫(kù)。最后我們會(huì)發(fā)現(xiàn),這個(gè)面部識(shí)別的實(shí)現(xiàn)能夠?qū)崟r(shí)運(yùn)行。

▌理解深度學(xué)習(xí)面部識(shí)別嵌入
那么,基于深度學(xué)習(xí)的面部識(shí)別是怎樣工作的呢?秘密就是一種叫做“深度度量學(xué)習(xí)”的技術(shù)。
如果你有深度學(xué)習(xí)的經(jīng)驗(yàn),你應(yīng)該知道,通常情況下訓(xùn)練好的網(wǎng)絡(luò)會(huì)接受一個(gè)輸入圖像,并且給輸入的圖像生成一個(gè)分類(lèi)或標(biāo)簽。
而在這里,網(wǎng)絡(luò)輸出的并不是單一的標(biāo)簽(也不是圖像中的坐標(biāo)或邊界盒),而是輸出一個(gè)表示特征向量的實(shí)數(shù)。
對(duì)于dlib面部識(shí)別網(wǎng)絡(luò)來(lái)說(shuō),輸出的特征向量為128維(即一個(gè)由128個(gè)實(shí)數(shù)組成的列表),用來(lái)判斷面部。網(wǎng)絡(luò)的訓(xùn)練是通過(guò)三元組進(jìn)行的:
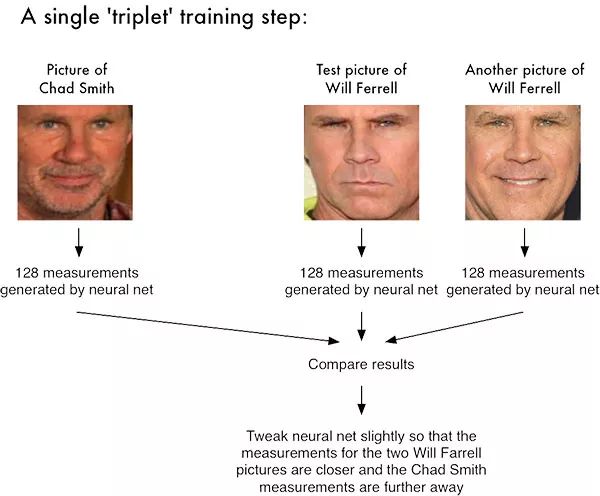
圖1:利用深度度量學(xué)習(xí)進(jìn)行面部識(shí)別需要“三元組訓(xùn)練”。三元組包括三張不同的面部圖像,其中兩張屬于同一個(gè)人。神經(jīng)網(wǎng)絡(luò)為每張面部圖像生成一個(gè)128維向量。對(duì)于同一個(gè)人的兩張面部圖像,我們調(diào)整神經(jīng)網(wǎng)絡(luò)使得輸出向量的距離度量盡可能接近。圖片來(lái)源:Adam Geitgey的“Machine Learning is Fun”博客(https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78)
這里我們需要給網(wǎng)絡(luò)提供三張圖片:
其中兩張圖片是同一個(gè)人的面部;第三張圖片是從數(shù)據(jù)集中取得的隨機(jī)面部圖片,并且保證與另外兩張圖片不是同一個(gè)人。以圖1為例,這里我們用了三張圖片,一張是Chad Smith,兩張是Will Ferrell。
網(wǎng)絡(luò)會(huì)測(cè)試這些面部圖片,并為每張圖片生成128維嵌入(embedding,即qualification)。
接下來(lái),基本思路就是調(diào)整神經(jīng)網(wǎng)絡(luò)的權(quán)重,使得兩張Will Ferrell的測(cè)量結(jié)果盡量接近,而Chad Smith的測(cè)量結(jié)果遠(yuǎn)離。
我們的面部識(shí)別網(wǎng)絡(luò)的架構(gòu)基于He等人在《Deep Residual Learning for Image Recognition》(https://arxiv.org/abs/1512.03385)中提出的ResNet-34,但層數(shù)較少,而且過(guò)濾器的數(shù)量減少了一半。
網(wǎng)絡(luò)本身由Davis King(https://www.pyimagesearch.com/2017/03/13/an-interview-with-davis-king-creator-of-the-dlib-toolkit/)在大約300萬(wàn)張圖片上訓(xùn)練。在Labeled Faces in the Wild(LFW)(http://vis-www.cs.umass.edu/lfw/)數(shù)據(jù)集上與其他方法相比,該網(wǎng)絡(luò)的準(zhǔn)確度達(dá)到了99.38%。
Davis King(dlib的作者)和Adam Geitgey(https://adamgeitgey.com/, 我們即將用到的face_recognition模塊的作者)都有文章介紹了基于深度學(xué)習(xí)的面部識(shí)別的工作原理:
High Quality Face Recognition with Deep Metric Learning(Davis,http://blog.dlib.net/2017/02/high-quality-face-recognition-with-deep.html)
Modern Face Recognition with Deep Learning( Adam,https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78)
強(qiáng)烈建議閱讀以上文章,以深入了解深度學(xué)習(xí)面部嵌入的工作原理。
▌安裝面部識(shí)別庫(kù)
為了用Python和OpenCV吸納面部識(shí)別,我們需要安裝一些庫(kù):
dlib(http://dlib.net/);
face_recognition(https://github.com/ageitgey/face_recognition)。
由Davis King維護(hù)的dlib庫(kù)包含了“深度度量學(xué)習(xí)”的實(shí)現(xiàn),用來(lái)在實(shí)際的識(shí)別過(guò)程中構(gòu)建面部嵌入。
Adam Geitgey創(chuàng)建的face_recognition庫(kù)則封裝了dlib的面部識(shí)別功能,使之更易用。
我假設(shè)你的系統(tǒng)上已經(jīng)裝好了OpenCV。如果沒(méi)有也不用擔(dān)心,可以看看我的OpenCV安裝指南一文(https://www.pyimagesearch.com/opencv-tutorials-resources-guides/),選擇適合你的系統(tǒng)的指南即可。
這里我們來(lái)安裝dlib和face_recognition庫(kù)。
注意:下面的安裝過(guò)程需要在Python虛擬環(huán)境中進(jìn)行。我強(qiáng)烈推薦使用虛擬環(huán)境來(lái)隔離項(xiàng)目,這是使用Python的好習(xí)慣。如果你看了我的OpenCV安裝指南,并且安裝了virtualenv和virtualenvwrapper,那么只要在安裝dlib和face_recognition之前執(zhí)行workon命令即可。
安裝沒(méi)有GPU支持的dlib
如果你沒(méi)有GPU,可以用pip安裝dlib(參考這篇指南:https://www.pyimagesearch.com/2018/01/22/install-dlib-easy-complete-guide/)。
$ workon # optional
$ pip install dlib或者從源代碼進(jìn)行編譯:
$ workon <your env name here> # optional
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS安裝有GPU支持的dlib(可選)
如果你有兼容CUDA的GPU,那么可以安裝有GPU支持的dlib,這樣面部識(shí)別能更快、更精確。
我建議從源代碼安裝dlib,這樣可以更精細(xì)地控制安裝過(guò)程:
$ workon <your env name here> # optional
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDA安裝face_recognition包
face_recognition模塊只需簡(jiǎn)單地使用pip命令即可安裝:
$ workon <your env name here> # optional
$ pip install face_recognition安裝imutlis
我們還需要imutils包提供一些遍歷的函數(shù)。在Python虛擬環(huán)境中使用pip即可:
$ workon <your env name here> # optional
$ pip install imutils▌面部識(shí)別數(shù)據(jù)集

圖2:利用Python和Bing圖像搜索API自動(dòng)創(chuàng)建的面部識(shí)別數(shù)據(jù)集,圖中顯示的是電影侏羅紀(jì)公園的六個(gè)角色。
1993年的《侏羅紀(jì)公園》是我最喜歡的電影,為了紀(jì)念最新上映的《侏羅紀(jì)世界:失落王國(guó)》,我們將使用電影中的一些角色進(jìn)行面部識(shí)別:
Alan Grant,古生物學(xué)家(22張圖像)
Clair Dearing,公園管理人(53張圖像)
Ellie Sattler,古生物學(xué)家(31張圖像)
Ian Malcolm,數(shù)學(xué)家(41張圖像)
John Hammond,商人,侏羅紀(jì)公園所有者(36張圖像)
Owen Grady,恐龍研究學(xué)者(35張圖像)
這個(gè)數(shù)據(jù)集只需要30分鐘就可以建好,參見(jiàn)我的文章《怎樣(快速)建立深度學(xué)習(xí)圖像數(shù)據(jù)集》(https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/)。
有了這個(gè)數(shù)據(jù)集,我們可以:
為數(shù)據(jù)集中的每張圖像建立128維嵌入;
利用這些嵌入,從圖像和視頻中識(shí)別每個(gè)角色的面部。
▌面部識(shí)別項(xiàng)目結(jié)構(gòu)
項(xiàng)目結(jié)構(gòu)可以參考下面的tree命令的輸出結(jié)果:
$ tree --filelimit 10 --dirsfirst
.
├── dataset
│ ├── alan_grant [22 entries]
│ ├── claire_dearing [53 entries]
│ ├── ellie_sattler [31 entries]
│ ├── ian_malcolm [41 entries]
│ ├── john_hammond [36 entries]
│ └── owen_grady [35 entries]
├── examples
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
├── output
│ └── lunch_scene_output.avi
├── videos
│ └── lunch_scene.mp4
├── search_bing_api.py
├── encode_faces.py
├── recognize_faces_image.py
├── recognize_faces_video.py
├── recognize_faces_video_file.py
└── encodings.pickle
10 directories, 11 files該項(xiàng)目有4個(gè)頂層目錄:
dataset/:包含六個(gè)角色的面部圖像,用角色名組織到各個(gè)子目錄中;
examples/:包含三個(gè)不屬于該數(shù)據(jù)集的測(cè)試圖像;
output/:存儲(chǔ)經(jīng)過(guò)面部識(shí)別處理后的視頻,上面有我生成的一個(gè)視頻,來(lái)自于原版《侏羅紀(jì)公園》電影的午飯場(chǎng)景;
videos/:輸入視頻存放于該文件夾中,該文件夾也包含了尚未經(jīng)過(guò)面部識(shí)別的“午飯場(chǎng)景”的視頻。
根目錄下還有6個(gè)文件:
search_bing_api.py:第一步就是建立數(shù)據(jù)集(我已經(jīng)幫你做好了)。關(guān)于利用Bing API建立數(shù)據(jù)集的具體方法請(qǐng)參考我這篇文章:https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/;
encode_faces.py:該腳本用來(lái)進(jìn)行面部編碼(128維向量);
recognize_faces_image.py:基于數(shù)據(jù)集生成的編碼,對(duì)單張圖片進(jìn)行面部識(shí)別;
recognize_faces_video.py:對(duì)來(lái)自攝像頭的實(shí)時(shí)視頻流進(jìn)行面部識(shí)別并輸出視頻文件;
recognize_faces_video_file.py:對(duì)硬盤(pán)上保存的視頻文件進(jìn)行面部識(shí)別,并輸出處理后的視頻文件。本文不再討論該腳本,因?yàn)樗幕窘Y(jié)構(gòu)與上面識(shí)別視頻流的腳本相同;
encodings.pickle:該腳本將encode_faces.py生成的面部識(shí)別編碼序列化并保存到硬盤(pán)上。
用search_bing_api.py創(chuàng)建好圖像數(shù)據(jù)集之后,就可以運(yùn)行encode_faces.py來(lái)創(chuàng)建嵌入了。
接下來(lái)我們將運(yùn)行識(shí)別腳本來(lái)進(jìn)行面部識(shí)別。
▌用OpenCV和深度學(xué)習(xí)對(duì)面部進(jìn)行編碼

圖3:利用深度學(xué)習(xí)和Python進(jìn)行面部識(shí)別。對(duì)每一個(gè)面部圖像,用face_recognition模塊的方法生成一個(gè)128維實(shí)數(shù)特征向量。
在識(shí)別圖像和視頻中的面部之前,我們首先需要在訓(xùn)練集中識(shí)別面部。要注意的是,我們并不是在訓(xùn)練網(wǎng)絡(luò)——該網(wǎng)絡(luò)已經(jīng)在300萬(wàn)圖像的訓(xùn)練集上訓(xùn)練過(guò)了。
當(dāng)然我們可以從頭開(kāi)始訓(xùn)練網(wǎng)絡(luò),或者微調(diào)已有模型的權(quán)重,但那就超出了這個(gè)項(xiàng)目的范圍。再說(shuō),你需要巨量的圖像才能從頭開(kāi)始訓(xùn)練網(wǎng)絡(luò)。
相反,使用預(yù)先訓(xùn)練好的網(wǎng)絡(luò)來(lái)給訓(xùn)練集中的218張面部圖像建立128維嵌入更容易些。
然后,在分類(lèi)過(guò)程中,只需利用簡(jiǎn)單的k-NN模型,加上投票,即可確定最終的面部分類(lèi),也可以使用其他經(jīng)典機(jī)器學(xué)習(xí)模型。
現(xiàn)在打開(kāi)本文“下載”鏈接中的encode_faces.py文件,看看是如何構(gòu)建面部嵌入的:
1# import the necessary packages
2from imutils import paths
3import face_recognition
4import argparse
5import pickle
6import cv2
7import os首先需要導(dǎo)入必需的包。這個(gè)腳本需要事先安裝imutils、face_recognition和OpenCV。請(qǐng)翻到前面“安裝面部識(shí)別庫(kù)”一節(jié)確保你已經(jīng)安裝了必須的庫(kù)。
首先用argparse處理運(yùn)行時(shí)傳遞的命令行參數(shù):
1# construct the argument parser and parse the arguments
2ap = argparse.ArgumentParser()
3ap.add_argument("-i", "--dataset", required=True,
4 help="path to input directory of faces + images")
5ap.add_argument("-e", "--encodings", required=True,
6 help="path to serialized db of facial encodings")
7ap.add_argument("-d", "--detection-method", type=str, default="cnn",
8 help="face detection model to use: either `hog` or `cnn`")
9args = vars(ap.parse_args())如果你之前沒(méi)有用過(guò)PyImageSearch,你可以多讀讀我的博客文章,就明白上面這段代碼了。首先利用argparse分析命令行參數(shù),在命令行上執(zhí)行Python程序時(shí),可以在終端中給腳本提供格外的信息。第2-9行不需要做任何改動(dòng),它們只是為了分析終端上的輸入。如果不熟悉這些代碼,可以讀讀我這篇文章:https://www.pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/ 。
下面逐一列出參數(shù):
--dataset:數(shù)據(jù)集的路徑(利用search_bing_api.py創(chuàng)建的數(shù)據(jù)集);
--encodings:面部編碼將被寫(xiě)到該參數(shù)所指的文件中;
--detection-method:首先需要檢測(cè)到圖像中的面部,才能對(duì)其進(jìn)行編碼。兩種面部檢測(cè)方法為hog或cnn,因此該參數(shù)只接受這兩個(gè)值。
現(xiàn)在參數(shù)已經(jīng)定義好了,我們可以獲得數(shù)據(jù)集文件的路徑了(同時(shí)進(jìn)行兩個(gè)初始化):
1# grab the paths to the input images in our dataset
2print("[INFO] quantifying faces...")
3imagePaths = list(paths.list_images(args["dataset"]))
4
5# initialize the list of known encodings and known names
6knownEncodings = []
7knownNames = []行3用輸入數(shù)據(jù)集的路徑,建立了一個(gè)列表imagePaths。
我們還需要在循環(huán)開(kāi)始之前初始化兩個(gè)列表,分別是knownEncodings和knownNames。這兩個(gè)列表分別包含面部編碼數(shù)據(jù)和數(shù)據(jù)集中相應(yīng)人物的名字(行6和行7)。
現(xiàn)在可以依次循環(huán)侏羅紀(jì)公園中的每個(gè)角色了!
1# loop over the image paths
2for (i, imagePath) in enumerate(imagePaths):
3 # extract the person name from the image path
4 print("[INFO] processing image {}/{}".format(i + 1,
5 len(imagePaths)))
6 name = imagePath.split(os.path.sep)[-2]
7
8 # load the input image and convert it from BGR (OpenCV ordering)
9 # to dlib ordering (RGB)
10 image = cv2.imread(imagePath)
11 rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
這段代碼會(huì)循環(huán)218次,處理數(shù)據(jù)集中的218張面部圖像。行2在所有圖像路徑中進(jìn)行循環(huán)。
接下來(lái),行6要從imagePath中提取人物的名字(因?yàn)樽幽夸浢褪侨宋锩?/span>
然后將imagePath傳遞給cv2.imread(行10),讀取圖像保存到image中。
OpenCV中的顏色通道排列順序?yàn)锽GR,但dlib要求的順序?yàn)镽GB。由于face_recognition模塊使用了dlib,因此在繼續(xù)下一步之前,行11轉(zhuǎn)換了顏色空間,并將轉(zhuǎn)換后的新圖像保存在rgb中。
接下來(lái)定位面部位置并計(jì)算編碼:
1 # detect the (x, y)-coordinates of the bounding boxes
2 # corresponding to each face in the input image
3 boxes = face_recognition.face_locations(rgb,
4 model=args["detection_method"])
5
6 # compute the facial embedding for the face
7 encodings = face_recognition.face_encodings(rgb, boxes)
8
9 # loop over the encodings
10 for encoding in encodings:
11 # add each encoding + name to our set of known names and
12 # encodings
13 knownEncodings.append(encoding)
14 knownNames.append(name)這段代碼是最有意思的部分!
每次循環(huán)都會(huì)檢測(cè)一個(gè)面部圖像(或者一張圖像中有多個(gè)面部,我們假設(shè)這些面部都屬于同一個(gè)人,但如果你使用自己的圖像的話(huà),這個(gè)假設(shè)有可能不成立,所以一定要注意)。
比如,假設(shè)rgb里的圖像是Ellie Sattler的臉。
行3和4查找面部位置,返回一個(gè)包含了許多方框的列表。我們給face_recognition.face_locations方法傳遞了兩個(gè)參數(shù):
rgb:RGB圖像;
model:cnn或hog(該值包含在命令行參數(shù)字典中,賦給了detection_method鍵)。CNN方法比較準(zhǔn)確,但速度較慢;HOG比較快,但不太準(zhǔn)確。
然后,在行7,我們要將Ellie Sattler的面部的邊界盒boxes轉(zhuǎn)換成128個(gè)數(shù)字。這個(gè)步驟就是將面部編碼成向量,可以通過(guò)face_recognition.face_encodings方法實(shí)現(xiàn)。
接下來(lái)秩序?qū)llie Sattler的encoding和name添加到恰當(dāng)?shù)牧斜碇校╧nownEncodings或knownNames)。
然后對(duì)數(shù)據(jù)集中所有218張圖像進(jìn)行這一步驟。
提取這些編碼encodings的目的就是要在另一個(gè)腳本中利用它們進(jìn)行面部識(shí)別。現(xiàn)在來(lái)看看怎么做:
1# dump the facial encodings + names to disk
2print("[INFO] serializing encodings...")
3data = {"encodings": knownEncodings, "names": knownNames}
4f = open(args["encodings"], "wb")
5f.write(pickle.dumps(data))
6f.close()行3構(gòu)建了一個(gè)字典,它包含encodings和names兩個(gè)鍵。
行4-6將名字和編碼保存到硬盤(pán)中,供以后使用。
怎樣才能在終端上運(yùn)行encode_faces.py腳本?
要?jiǎng)?chuàng)建面部嵌入,可以從終端執(zhí)行以下命令:
1$ python encode_faces.py --dataset dataset --encodings encodings.pickle
2[INFO] quantifying faces...
3[INFO] processing image 1/218
4[INFO] processing image 2/218
5[INFO] processing image 3/218
6...
7[INFO] processing image 216/218
8[INFO] processing image 217/218
9[INFO] processing image 218/218
10[INFO] serializing encodings...
11$ ls -lh encodings*
12-rw-r--r--@ 1 adrian staff 234K May 29 13:03 encodings.pickle從輸出中課件,它生成了個(gè)名為encodings.pickle的文件,該文件包含了數(shù)據(jù)集中每個(gè)面部圖像的128維面部嵌入。
在我的Titan X GPU上,處理整個(gè)數(shù)據(jù)集花費(fèi)了一分鐘多一點(diǎn),但如果只使用CPU,就要做好等待很久的心理準(zhǔn)備。
在我的Macbook Pro上(沒(méi)有GPU),編碼218張圖像需要21分20秒。
如果你有GPU并且編譯dlib時(shí)選擇了支持GPU,那么速度應(yīng)該會(huì)快得多。
▌識(shí)別圖像中的面部

圖4:John Hammond的面部識(shí)別,使用了Adam Geitgey的深度學(xué)習(xí)Python模塊face_recognition。
現(xiàn)在已經(jīng)給數(shù)據(jù)集中的每張圖像建好了128維面部嵌入,我們可以用OpenCV、Python和深度學(xué)習(xí)進(jìn)行面部識(shí)別了。
打開(kāi)recognize_faces_image.py,插入以下代碼(或者從本文的”下載“部分下載代碼和相關(guān)的圖像):
1# import the necessary packages
2import face_recognition
3import argparse
4import pickle
5import cv2
6
7# construct the argument parser and parse the arguments
8ap = argparse.ArgumentParser()
9ap.add_argument("-e", "--encodings", required=True,
10 help="path to serialized db of facial encodings")
11ap.add_argument("-i", "--image", required=True,
12 help="path to input image")
13ap.add_argument("-d", "--detection-method", type=str, default="cnn",
14 help="face detection model to use: either `hog` or `cnn`")
15args = vars(ap.parse_args())這段代碼首先導(dǎo)入了必需的包(行2-5)。face_recognition模塊完成主要工作,OpenCV負(fù)責(zé)加載圖像、轉(zhuǎn)換圖像,并顯示處理之后的圖像。
行8-15負(fù)責(zé)分析三個(gè)命令行參數(shù):
--encodings:包含面部編碼的pickle文件的路徑;
--image:需要進(jìn)行面部識(shí)別的圖像;
--detection-method:這個(gè)選項(xiàng)應(yīng)該很熟悉了。可以根據(jù)系統(tǒng)的能力,選擇hog或cnn之一。追求速度的話(huà)就選擇hog,追求準(zhǔn)確度就選擇cnn。
注意:在樹(shù)莓派上必須選擇hog,因?yàn)閮?nèi)存容量不足以運(yùn)行CNN方法。
接下來(lái)要加載計(jì)算好的編碼和面部名稱(chēng),然后為輸入圖像構(gòu)建128維面部編碼:
1# load the known faces and embeddings
2print("[INFO] loading encodings...")
3data = pickle.loads(open(args["encodings"], "rb").read())
4
5# load the input image and convert it from BGR to RGB
6image = cv2.imread(args["image"])
7rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
8
9# detect the (x, y)-coordinates of the bounding boxes corresponding
10# to each face in the input image, then compute the facial embeddings
11# for each face
12print("[INFO] recognizing faces...")
13boxes = face_recognition.face_locations(rgb,
14 model=args["detection_method"])
15encodings = face_recognition.face_encodings(rgb, boxes)
16
17# initialize the list of names for each face detected
18names = []行3從硬盤(pán)加載pickle過(guò)的編碼和名字?jǐn)?shù)據(jù)。稍后在實(shí)際的面部識(shí)別步驟中會(huì)用到這些數(shù)據(jù)。
然后,行6和行7加載輸入圖像image,并轉(zhuǎn)換其顏色通道順序(同encode_faces.py腳本一樣),保存到rgb中。
接下來(lái),行13-15繼續(xù)檢測(cè)輸入圖像中的所有面部,并計(jì)算它們的128維encodings(這些代碼也應(yīng)該很熟悉了)。
現(xiàn)在應(yīng)該初始化一個(gè)列表names,用來(lái)保存每個(gè)檢測(cè)的面部。該列表將在下一步填充。
現(xiàn)在遍歷面部編碼encodings列表:
1# loop over the facial embeddings
2for encoding in encodings:
3 # attempt to match each face in the input image to our known
4 # encodings
5 matches = face_recognition.compare_faces(data["encodings"],
6 encoding)
7 name = "Unknown"行2開(kāi)始遍歷根據(jù)輸入圖像計(jì)算出的面部編碼。
接下來(lái)見(jiàn)證面部識(shí)別的奇跡吧!
在行5和行6,我們嘗試?yán)胒ace_recognition.compare_faces將輸入圖像中的每個(gè)面部(encoding)對(duì)應(yīng)到已知的編碼數(shù)據(jù)集(保存在data["encodings"]中)上。
該函數(shù)會(huì)返回一個(gè)True/False值的列表,每個(gè)值對(duì)應(yīng)于數(shù)據(jù)集中的一張圖像。對(duì)于我們的侏羅紀(jì)公園的例子,數(shù)據(jù)集中有218張圖像,因此返回的列表將包含218個(gè)布爾值。
compare_faces函數(shù)內(nèi)部會(huì)計(jì)算待判別圖像的嵌入和數(shù)據(jù)集中所有面部的嵌入之間的歐幾里得距離。
如果距離位于容許范圍內(nèi)(容許范圍越小,面部識(shí)別系統(tǒng)就越嚴(yán)格),則返回True,表明面部吻合。否則,如果距離大于容許范圍,則返回False表示面部不吻合。
本質(zhì)上我們用了個(gè)更”炫酷“的k-NN模型進(jìn)行分類(lèi)。具體的實(shí)現(xiàn)細(xì)節(jié)可以參考compare_faces的實(shí)現(xiàn)(https://github.com/ageitgey/face_recognition/blob/master/face_recognition/api.py#L213)。
最終,name變量會(huì)的值就是人的名字。如果沒(méi)有任何”投票“,則保持"Unknown"不變(行7)。
根據(jù)matches列表,可以計(jì)算每個(gè)名字的”投票“數(shù)目(與每個(gè)名字關(guān)聯(lián)的True值的數(shù)目),計(jì)票之后選擇最適合的人的名字:
1 # check to see if we have found a match
2 if True in matches:
3 # find the indexes of all matched faces then initialize a
4 # dictionary to count the total number of times each face
5 # was matched
6 matchedIdxs = [i for (i, b) in enumerate(matches) if b]
7 counts = {}
8
9 # loop over the matched indexes and maintain a count for
10 # each recognized face face
11 for i in matchedIdxs:
12 name = data["names"][i]
13 counts[name] = counts.get(name, 0) + 1
14
15 # determine the recognized face with the largest number of
16 # votes (note: in the event of an unlikely tie Python will
17 # select first entry in the dictionary)
18 name = max(counts, key=counts.get)
19
20 # update the list of names
21 names.append(name)如果matches中包含任何True的投票(行2),則需要確定True值在matches中的索引位置。這一步在行6中通過(guò)建立一個(gè)簡(jiǎn)單的matchedIdxs列表實(shí)現(xiàn)。對(duì)于example_01.png來(lái)說(shuō),它大概是這個(gè)樣子:
1(Pdb) matchedIdxs
2[35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 71, 72, 73, 74, 75]然后初始化一個(gè)名為counts的字典,其鍵為角色的名字,值是投票的數(shù)量。
接下來(lái)遍歷matchedIdxs,統(tǒng)計(jì)每個(gè)相關(guān)的名字,并在counts增加相應(yīng)的計(jì)數(shù)值。counts字典可能是這個(gè)樣子(Ian Malcolm高票的情況):
1(Pdb) counts
2{'ian_malcolm': 40}回憶一下我們的數(shù)據(jù)集中只有41張圖片,因此40分并且沒(méi)有任何其他投票可以認(rèn)為非常高了。
取出counts中投票最高的名字,本例中為'ian_malcolm'。
循環(huán)的第二次迭代(由于圖像中有兩個(gè)人臉)會(huì)取出下面的counts:
1(Pdb) counts
2{'alan_grant': 5}盡管這個(gè)投票分值較低,但由于這是字典中唯一的人名,所以很可能我們找到了Alan Grant。
注意:這里使用了Python調(diào)試器PDB來(lái)檢查counts字典的值。PDB的用法超出了本文的范圍,你可以在Python的文檔頁(yè)面(https://docs.python.org/3/library/pdb.html)找到其用法。
如下面的圖5所示,我們正確識(shí)別了Ian Malcolm和Alan Grant,所以這一段代碼工作得還不錯(cuò)。
我們來(lái)繼續(xù)循環(huán)每個(gè)人的邊界盒和名字,然后將名字畫(huà)在輸出圖像上以供展示之用:
1# loop over the recognized faces
2for ((top, right, bottom, left), name) in zip(boxes, names):
3 # draw the predicted face name on the image
4 cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
5 y = top - 15 if top - 15 > 15 else top + 15
6 cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
7 0.75, (0, 255, 0), 2)
8
9# show the output image
10cv2.imshow("Image", image)
11cv2.waitKey(0)行2開(kāi)始循環(huán)檢測(cè)到的面部邊界盒boxes和預(yù)測(cè)的names。我們調(diào)用了zip(boxes, names)以創(chuàng)建一個(gè)容易進(jìn)行循環(huán)的對(duì)象,每次迭代將得到一個(gè)二元組,從中可以提取邊界盒坐標(biāo)和名字。
行4利用邊界盒坐標(biāo)畫(huà)一個(gè)綠色方框。
我們還利用坐標(biāo)計(jì)算了人名文本的顯示位置(行5),并將人名的文本畫(huà)在圖像上(行6和行7)。如果邊界盒位于圖像頂端,則將文本移到邊界盒下方(行5),否則文本就被截掉了。
然后顯示圖像,直到按下任意鍵為止(行10和11)。
怎樣運(yùn)行面部識(shí)別的Python腳本?
在終端中,首先用workon命令保證位于正確的Python虛擬環(huán)境中(如果你用了虛擬環(huán)境的話(huà))。
然后運(yùn)行該腳本,同時(shí)至少提供兩個(gè)命令行參數(shù)。如果選擇HoG方式,別忘了傳遞--detection-method hog(否則默認(rèn)會(huì)使用深度學(xué)習(xí)檢測(cè)方式)。
趕快試試吧!
打開(kāi)終端并執(zhí)行腳本,用OpenCV和Python進(jìn)行面部識(shí)別:
1$ python recognize_faces_image.py --encodings encodings.pickle \
2 --image examples/example_01.png
3[INFO] loading encodings...
4[INFO] recognizing faces...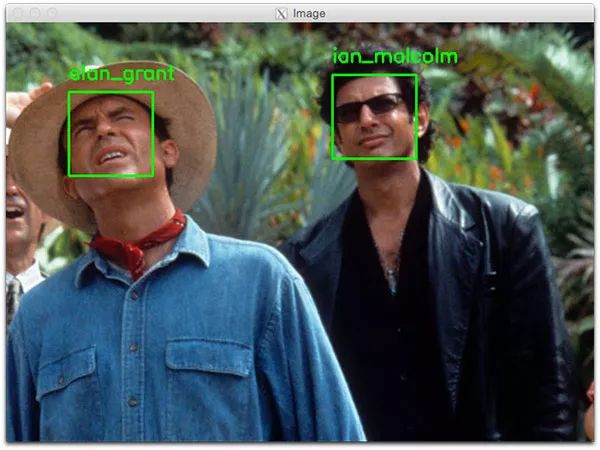
圖5:Python + OpenCV + 深度學(xué)習(xí)方法識(shí)別出了Alan Grant和Ian Malcom的面部。
另一個(gè)面部識(shí)別的例子:
1$ python recognize_faces_image.py --encodings encodings.pickle \
2 --image examples/example_02.png
3[INFO] loading encodings...
4[INFO] recognizing faces...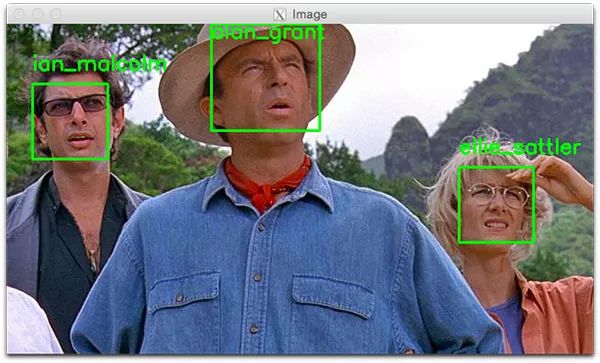
圖6:用OpenCV和Python進(jìn)行面部識(shí)別。
▌在視頻中進(jìn)行面部識(shí)別

圖7:用Python、OpenCV和深度學(xué)習(xí)在視頻中進(jìn)行面部識(shí)別。
我們已經(jīng)完成了圖像中的面部識(shí)別,現(xiàn)在來(lái)試試在視頻中進(jìn)行(實(shí)時(shí))面部識(shí)別。
關(guān)于性能的重要提示:CNN面部識(shí)別器只能在有GPU的情況下實(shí)時(shí)運(yùn)行(CPU也可以運(yùn)行,但視頻會(huì)非常卡,實(shí)際的幀速率不到0.5FPS)。如果你只有CPU,應(yīng)當(dāng)考慮使用HoG方式(或者甚至采用OpenCV的Haar層疊方式,以后會(huì)撰文說(shuō)明),以獲得較好的速度。
下面的腳本從前面的recognize_faces_image.py腳本中借用了許多代碼。因此我將略過(guò)之前介紹過(guò)的部分,只說(shuō)明下視頻部分,以便于理解。
下載好代碼之后,打開(kāi)recognize_faces_video.py:
1# import the necessary packages
2from imutils.video import VideoStream
3import face_recognition
4import argparse
5import imutils
6import pickle
7import time
8import cv2
9
10# construct the argument parser and parse the arguments
11ap = argparse.ArgumentParser()
12ap.add_argument("-e", "--encodings", required=True,
13 help="path to serialized db of facial encodings")
14ap.add_argument("-o", "--output", type=str,
15 help="path to output video")
16ap.add_argument("-y", "--display", type=int, default=1,
17 help="whether or not to display output frame to screen")
18ap.add_argument("-d", "--detection-method", type=str, default="cnn",
19 help="face detection model to use: either `hog` or `cnn`")
20args = vars(ap.parse_args())行2-8導(dǎo)入包,然后行11-20解析命令行參數(shù)。
這里有四個(gè)命令行參數(shù),其中兩個(gè)是介紹過(guò)的(--encodings和--detection-method)。另外兩個(gè)參數(shù)是:
--output:視頻輸出路徑;
--display:指示是否將視頻幀輸出到屏幕的標(biāo)志。1表示顯示到屏幕,0表示不顯示。
然后加載編碼并啟動(dòng)VideoStream:
1# load the known faces and embeddings
2print("[INFO] loading encodings...")
3data = pickle.loads(open(args["encodings"], "rb").read())
4
5# initialize the video stream and pointer to output video file, then
6# allow the camera sensor to warm up
7print("[INFO] starting video stream...")
8vs = VideoStream(src=0).start()
9writer = None
10time.sleep(2.0)
我們利用imutils中的VideoStream類(lèi)來(lái)訪(fǎng)問(wèn)攝像頭。行8啟動(dòng)視頻流。如果系統(tǒng)中有多個(gè)攝像頭(如內(nèi)置攝像頭和外置USB攝像頭),可以將src=0改成src=1等。
稍后會(huì)將處理過(guò)的視頻寫(xiě)到硬盤(pán)中,所以這里將writer初始化成None(行9)。sleep兩秒讓攝像頭預(yù)熱。
接下來(lái)啟動(dòng)一個(gè)while循環(huán),開(kāi)始抓取并處理視頻幀:
1# loop over frames from the video file stream
2while True:
3 # grab the frame from the threaded video stream
4 frame = vs.read()
5
6 # convert the input frame from BGR to RGB then resize it to have
7 # a width of 750px (to speedup processing)
8 rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
9 rgb = imutils.resize(frame, width=750)
10 r = frame.shape[1] / float(rgb.shape[1])
11
12 # detect the (x, y)-coordinates of the bounding boxes
13 # corresponding to each face in the input frame, then compute
14 # the facial embeddings for each face
15 boxes = face_recognition.face_locations(rgb,
16 model=args["detection_method"])
17 encodings = face_recognition.face_encodings(rgb, boxes)
18 names = []循環(huán)從行2開(kāi)始,第一步就是從視頻流中抓取一個(gè)frame(行4)。
上述代碼中剩下的行8-18基本上與前一個(gè)腳本相同,只不過(guò)這里處理的是視頻幀,而不是靜態(tài)圖像。基本上就是讀取frame,預(yù)處理,檢測(cè)到面部邊界盒boxes,然后給每個(gè)邊界盒計(jì)算encodings。
接下來(lái)遍歷每個(gè)找到的面部的encodings:
1 # loop over the facial embeddings
2 for encoding in encodings:
3 # attempt to match each face in the input image to our known
4 # encodings
5 matches = face_recognition.compare_faces(data["encodings"],
6 encoding)
7 name = "Unknown"
8
9 # check to see if we have found a match
10 if True in matches:
11 # find the indexes of all matched faces then initialize a
12 # dictionary to count the total number of times each face
13 # was matched
14 matchedIdxs = [i for (i, b) in enumerate(matches) if b]
15 counts = {}
16
17 # loop over the matched indexes and maintain a count for
18 # each recognized face face
19 for i in matchedIdxs:
20 name = data["names"][i]
21 counts[name] = counts.get(name, 0) + 1
22
23 # determine the recognized face with the largest number
24 # of votes (note: in the event of an unlikely tie Python
25 # will select first entry in the dictionary)
26 name = max(counts, key=counts.get)
27
28 # update the list of names
29 names.append(name)在這段代碼中依次循環(huán)每個(gè)encodings,并嘗試匹配到已知的面部數(shù)據(jù)上。如果找到匹配,則計(jì)算數(shù)據(jù)集中每個(gè)名字獲得的票數(shù)。然后取出得票最高的名字,就是該面部對(duì)應(yīng)的名字。這些代碼與前面的代碼完全相同。
下一段代碼循環(huán)找到的面部并在周?chē)?huà)出邊界盒,并顯示人的名字:
1 # loop over the recognized faces
2 for ((top, right, bottom, left), name) in zip(boxes, names):
3 # rescale the face coordinates
4 top = int(top * r)
5 right = int(right * r)
6 bottom = int(bottom * r)
7 left = int(left * r)
8
9 # draw the predicted face name on the image
10 cv2.rectangle(frame, (left, top), (right, bottom),
11 (0, 255, 0), 2)
12 y = top - 15 if top - 15 > 15 else top + 15
13 cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
14 0.75, (0, 255, 0), 2)這些代碼也完全相同,所以我們只關(guān)注與食品有關(guān)的代碼。
我們還可以將視頻幀寫(xiě)到硬盤(pán)中,因此來(lái)看看是怎樣使用OpenCV將視頻寫(xiě)到硬盤(pán)中的(https://www.pyimagesearch.com/2016/02/22/writing-to-video-with-opencv/):
1 # if the video writer is None *AND* we are supposed to write
2 # the output video to disk initialize the writer
3 if writer is None and args["output"] is not None:
4 fourcc = cv2.VideoWriter_fourcc(*"MJPG")
5 writer = cv2.VideoWriter(args["output"], fourcc, 20,
6 (frame.shape[1], frame.shape[0]), True)
7
8 # if the writer is not None, write the frame with recognized
9 # faces t odisk
10 if writer is not None:
11 writer.write(frame)如果命令行參數(shù)提供了輸出文件路徑(可選),而我們還沒(méi)有初始化視頻的writer(行3),就要先初始化之。
行4初始化了VideoWriter_fourcc。FourCC是一種四字符編碼,在這里就是MJPG 四字符編碼。
接下來(lái)將對(duì)象、輸出路徑、每秒幀數(shù)的目標(biāo)值和幀尺寸傳遞給VideoWriter(行5和6)。
最后,如果writer存在,就繼續(xù)將幀寫(xiě)到磁盤(pán)中。
下面是是否將面部識(shí)別視頻幀輸出到屏幕的處理:
1 # check to see if we are supposed to display the output frame to
2 # the screen
3 if args["display"] > 0:
4 cv2.imshow("Frame", frame)
5 key = cv2.waitKey(1) & 0xFF
6
7 # if the `q` key was pressed, break from the loop
8 if key == ord("q"):
9 break如果設(shè)置了display命令行參數(shù),就顯示視頻幀(行4)并檢查退出鍵("q")是否被按下(行5-8),如果被按下,則break掉循環(huán)(行9)。
最后是一些清理工作:
1# do a bit of cleanup
2cv2.destroyAllWindows()
3vs.stop()
4
5# check to see if the video writer point needs to be released
6if writer is not None:
7 writer.release()行2-7清理并釋放屏幕、視頻流和視頻writer。
準(zhǔn)備好運(yùn)行真正的腳本了嗎?
為了演示OpenCV和Python的實(shí)時(shí)面部識(shí)別,打開(kāi)終端然后執(zhí)行下面的命令:
1$ python recognize_faces_video.py --encodings encodings.pickle \
2 --output output/webcam_face_recognition_output.avi --display 1
3[INFO] loading encodings...
4[INFO] starting video stream...下面是我錄制的演示視頻,用來(lái)演示面部識(shí)別系統(tǒng):
視頻文件中的面部識(shí)別
之前在“面部識(shí)別項(xiàng)目結(jié)構(gòu)”一節(jié)中說(shuō)過(guò),下載的代碼中還有個(gè)名為recognize_faces_video_file.py的腳本。
這個(gè)腳本實(shí)際上和剛才識(shí)別攝像頭的腳本相同,只不過(guò)它接收視頻文件作為輸入,然后生成輸出視頻文件。
我對(duì)原版侏羅紀(jì)公園電影中經(jīng)典的“午飯場(chǎng)景”做了面部識(shí)別,在該場(chǎng)景中,演員們圍在桌子旁邊討論他們對(duì)于公園的想法:
1$ python recognize_faces_video_file.py --encodings encodings.pickle \
2 --input videos/lunch_scene.mp4 --output output/lunch_scene_output.avi \
3 --display 0下面是結(jié)果:
注意:別忘了我們的模型是根據(jù)原版電影中的四個(gè)角色進(jìn)行訓(xùn)練的:Alan Grant、Ellie Sattler、Ian Malcolm和John Hammond。模型并沒(méi)有針對(duì)Donald Gennaro(律師)進(jìn)行訓(xùn)練,所以他的面部被標(biāo)記為“Unknown”。這個(gè)行為是特意的(不是意外),以演示我們的視頻識(shí)別系統(tǒng)在識(shí)別訓(xùn)練過(guò)的面部的同時(shí),會(huì)把不認(rèn)識(shí)的面部標(biāo)記為“Unknown”。
下面的視頻中我從《侏羅紀(jì)公園》和《侏羅紀(jì)世界》的預(yù)告片中截取的剪輯:
可見(jiàn),面部識(shí)別和OpenCV代碼的效果很不錯(cuò)!
▌面部識(shí)別代碼能運(yùn)行在樹(shù)莓派上嗎?
從某種意義上,可以。不過(guò)有一些限制:
樹(shù)莓派內(nèi)存太小,沒(méi)辦法運(yùn)行更準(zhǔn)確的基于CNN的面部檢測(cè)器;
因此只能用HOG方式;
即使如此,HOG方式在樹(shù)莓派上也太慢,沒(méi)辦法用于實(shí)時(shí)面部檢測(cè);
所以只能用OpenCV的Haar層疊方式。
即使這樣能運(yùn)行起來(lái),實(shí)際的速率也只有1~2FPS,而且就算是這種速率也需要許多技巧。
▌總結(jié)
在這篇指南中,我們學(xué)習(xí)了如何利用OpenCV、Python和深度學(xué)習(xí)來(lái)進(jìn)行面部識(shí)別。此外,我們還利用了Davis King的dlib庫(kù)和Adam Geitgey的face_recognition模塊,后者對(duì)dlib的深度度量學(xué)習(xí)進(jìn)行了封裝,使得面部識(shí)別更容易完成。
我們發(fā)現(xiàn),我們的面部識(shí)別實(shí)現(xiàn)同時(shí)具有以下兩個(gè)特點(diǎn):準(zhǔn)確,并且能在GPU上實(shí)時(shí)運(yùn)行。
最后,希望你喜歡今天的面部識(shí)別的文章!
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~