
MySQL之InnoDB存儲引擎:淺談Redo Log重做日志
前面我們提到InnoDB存儲引擎是支持事務的。這里我們就來了解如何實現(xiàn)事務的持久性,即所謂的Redo Log重做日志

楔子
我們對MySQL中記錄的修改是在內存中的,具體地是在Buffer Pool緩沖池中。那么一旦出現(xiàn)意外(服務器故障、斷電等)即會導致內存數(shù)據丟失,這顯然無法滿足事務的持久性要求。那么容易想到的持久性的實現(xiàn)方案是實時同步——即每次事務提交完成后就將內存中相關被修改的頁同步回硬盤。但是該方案缺點也很明顯,首先,我們知道內存與硬盤交互的基本單位是頁,也就是說即使我們只是修改了頁中幾個字節(jié)的數(shù)據,也需要將整個頁同步到硬盤中;其次,一條SQL語句有時卻可能還需要修改其它的若干個頁。比如在插入一條記錄時,我們還需要適時調整其它頁來維護整個聚簇索引的B+樹。這個時候如果這些需要調整的頁還不是相鄰的,那么就需要通過多次的隨機IO將其加載到內存中,待修改完再同步到硬盤中。總而言之,即該方案效率十分低下。基于此InnoDB引擎提出了redo log重做日志,對于redo log中的一條記錄而言,其負責記錄了用戶修改的位置、數(shù)據內容。故占用空間較小;其次,對于若干條redo log的記錄而言,其是按生成順序寫到磁盤的,即所謂的順序IO
redo log的記錄格式
前面提到,redo log重做日志用于記錄我們對數(shù)據庫數(shù)據所做的修改。雖然redo log中有很多類型的記錄。但總的來說,不論是簡單類型還是復雜類型,其記錄格式均是統(tǒng)一的,如下所示。可以看到記錄中包括記錄的類型、表空間ID、頁號和日志內容。眾所周知,通過表空間ID+頁號即可唯一定位需要進行修改的頁。其中type類型字段使用1個字節(jié)

簡單類型
有時候我們僅僅只是修改某個頁中的若干個字節(jié),且該修改并不會影響到其它頁中的數(shù)據。這個時候即可通過簡單類型記錄來記錄所做的修改。即在日志內容中記錄頁面偏移量來確定修改頁內位置和修改的數(shù)據內容即可,如下圖所示
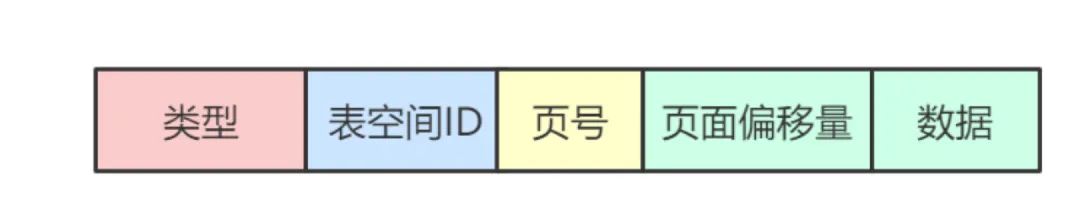
具體地,根據修改的數(shù)據內容的字節(jié)數(shù)可細分為以下類型的日志記錄
MLOG_1BYTE:該類型記錄的type字段值為0x01,意為在某頁面指定偏移量的位置處寫入1個字節(jié)的數(shù)據 MLOG_2BYTE:該類型記錄的type字段值為0x02,意為在某頁面指定偏移量的位置處寫入2個字節(jié)的數(shù)據 MLOG_4BYTE:該類型記錄的type字段值為0x04,意為在某頁面指定偏移量的位置處寫入4個字節(jié)的數(shù)據 MLOG_8BYTE:該類型記錄的type字段值為0x08,意為在某頁面指定偏移量的位置處寫入8個字節(jié)的數(shù)據
另外,還有支持不定長數(shù)據的日志記錄類型——MLOG_WRITE_STRING。其會在頁面偏移量后記錄數(shù)據的長度(即字節(jié)數(shù))
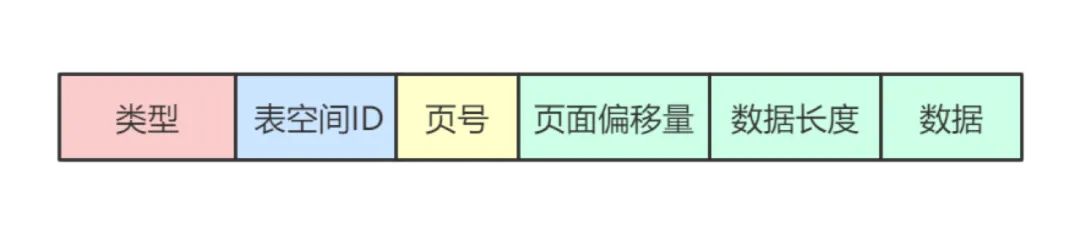
復雜類型
對于有些數(shù)據庫操作而言,例如向數(shù)據表插入一條新的用戶記錄。一方面,其可能導致頁分裂并通過調整來維護該B+樹;另一方面,對于新記錄所在的數(shù)據頁而言,其修改操作也遠不止僅僅添加一條新的用戶記錄那么簡單(還需維護Page Header的統(tǒng)計信息、Page Directory的槽信息、頁內記錄間的單向鏈表)。總而言之,一個數(shù)據庫操作所涉及到的修改有時候可能會非常非常多。在此種情況下,如果是將該操作對應的多處修改均使用上面提到的簡單類型的redo log日志進行記錄,那么很可能多條redo log記錄占用的空間比一個頁都大;而如果將對該頁中 需修改的第一個字節(jié) 到 需修改的最后一個字節(jié) 視為一個整體的話,使用一條redo log記錄進行記錄的話。也是比較浪費空間的,因為這中間還有大部分數(shù)據其實是無需修改的。故針對不同的數(shù)據庫操作,InnoDB提供了各自類型的redo log記錄,即所謂的復雜類型。常見地有
MLOG_REC_INSERT:該類型記錄的type字段值為0x09,用于表示 插入一條非緊湊行格式的記錄 MLOG_COMP_REC_INSERT:該類型記錄的type字段值為0x26,用于表示 插入一條緊湊行格式的記錄 MLOG_COMP_REC_DELETE:該類型記錄的type字段值為0x2A,用于表示 刪除一條緊湊行格式的記錄 MLOG_COMP_LIST_START_DELETE、MLOG_COMP_LIST_END_DELETE:該兩種類型記錄的type字段值分別為0x2C、0x2B,分別用于表示批量刪除緊湊行格式的記錄時的起始記錄、結束記錄 MLOG_ZIP_PAGE_COMPRESS:該類型記錄的type字段值為0x33,用于表示 壓縮一個數(shù)據頁
對于這些復雜類型的redo log記錄而言,其只會在記錄的日志內容處記錄進行相關的數(shù)據庫操作時必要的數(shù)據。當MySQL在崩潰恢復時會將該redo log記錄的日志內容作為參數(shù),通過調用相關函數(shù)實現(xiàn)插入、刪除等數(shù)據庫操作。至于頁內數(shù)據(例如Page Header的統(tǒng)計信息、Page Directory的槽信息等等)將會在相關函數(shù)執(zhí)行過程中進行調整、修改。即可以將復雜類型的redo log視為邏輯日志
Note
所謂非緊湊類型的行格式,有Redundant行格式;而對于緊湊類型的行格式而言,典型地有Compact、Dynamic、Compressed等行格式
Mini-Transaction
前面我們提到,對于一條SQL語句操作可能會產生多條redo log記錄。典型地,在頁分裂操作時會生成多條redo log記錄,如果恢復過程只恢復了部分,即會導致B+樹被破壞掉。這里我們將對底層頁中的一次原子訪問、操作的過程稱為Mini-Transaction(MTR) 。InnoDB適當?shù)膶⑦@些redo log記錄劃分為若干個組,每個組中含有若干條redo log記錄,如下圖所示。對于這一個組中所有的redo log記錄而言,為了保證操作的原子性,即其是不可再進行分割的。在MySQL崩潰后重啟恢復時,對于一個組中的redo日志,要么全部進行恢復,要么一條也不恢復。總而言之,一個MTR包含一組redo log記錄,其是恢復時的最小執(zhí)行單元
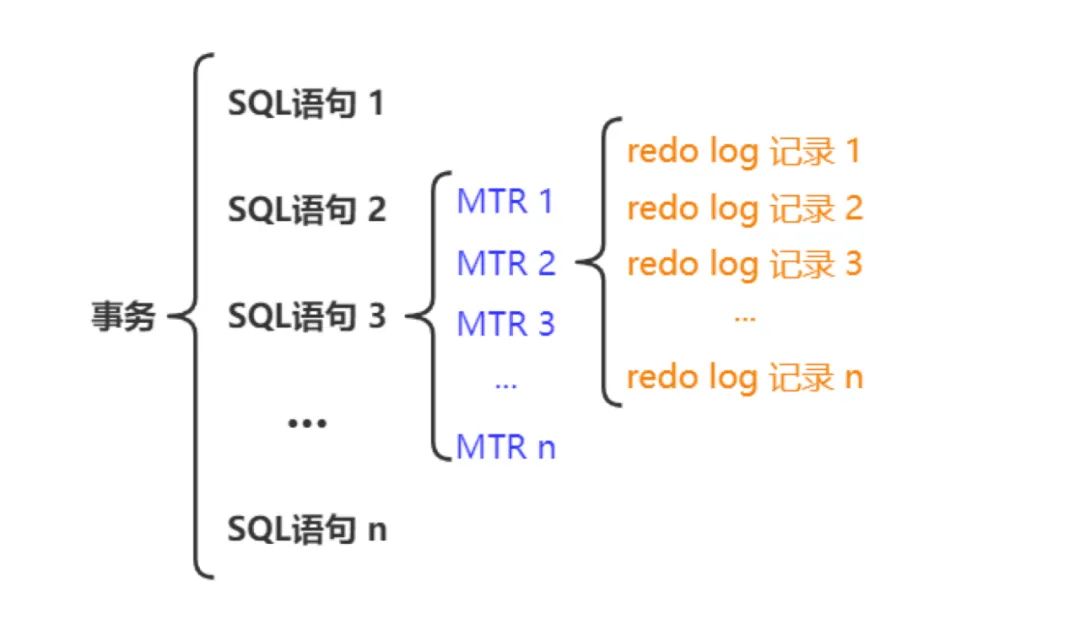
為了實現(xiàn)將MTR組內的多條redo log記錄作為一個整體進行恢復。其會在組內的最后一條redo log記錄后追加一條類型為MLOG_MULTI_REC_END的redo log記錄,該類型記錄的type字段值為0x1F。與我們前面所介紹的各種類型的redo log記錄不同的是,該記錄只含有type字段,無其他組成部分。在恢復過程中,直到解析了該類型的redo log記錄時,才認為解析了完整的一組redo log記錄;否則將直接丟棄之前解析的redo log記錄。特別地,如果某個需要保證原子性操作只生成了一條redo log記錄,即該組內只含一條redo log記錄時,其不是通過在后面追加類型為MLOG_MULTI_REC_END的redo log記錄作為組標識的。因為type字段雖然占用1個字節(jié)的空間,但其只使用了7個比特位用于表示redo log記錄的類型。故其可以通過type字段中未使用的1個比特位作為組標識,即當該比特位為1時,表示該記錄是組內唯一的一條redo log記錄
存儲方式
Redo Log Block
我們知道,MySQL下使用各種類型的頁來存放不同類型的數(shù)據。對于redo log也不例外,通常我們將用于存儲redo log的頁稱之為Block,其中一個block占用512B的空間。其內部結構如下所示
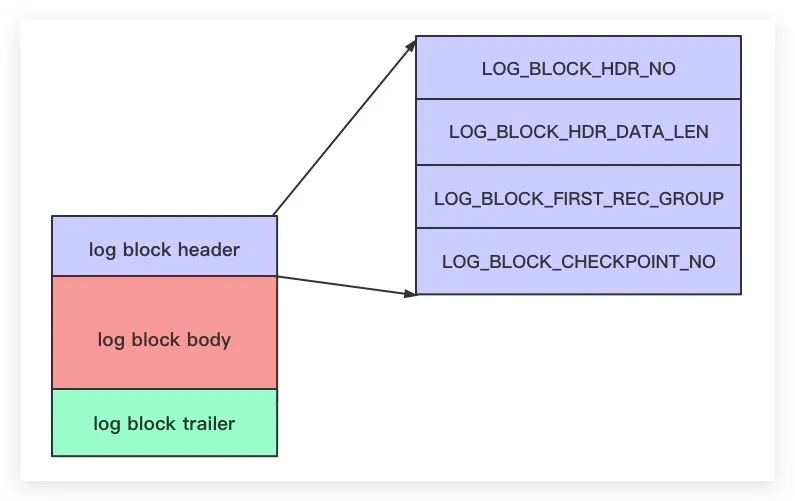
log block header
該部分使用12B的空間大小。其含有的屬性及意義如下
LOG_BLOCK_HDR_NO:用于標示Block的唯一編號 LOG_BLOCK_HDR_DATA_LEN:意為該Block已使用的字節(jié)數(shù)。若該Block的log block body中無redo log,則該值為12。因為log block header部分使用了12個字節(jié);若該Block的log block body中已被寫滿,則該值為512 LOG_BLOCK_FIRST_REC_GROUP:該Block中第一個MTR起始處的偏移量 LOG_BLOCK_CHECKPOINT_NO:checkpoint的序號
log block body
該部分使用496B的空間大小。用于存儲redo log記錄
log block trailer
該部分使用4B的空間大小。其只有一個LOG_BLOCK_CHECKSUM屬性,意為該Block的校驗和
Redo Log Buffer
前面我們說為了提高頁在內存、硬盤之間交互時的效率,InnoDB引入了Buffer Pool緩沖池。類似地針對redo log來說,InnoDB同樣為其引入了所謂的Redo Log Buffer,即redo log緩沖區(qū)。MySQL服務在啟動后會向OS申請一塊連續(xù)的內存空間將其作為Redo Log Buffer,并將其分為若干個連續(xù)的Redo Log Block。如下圖所示
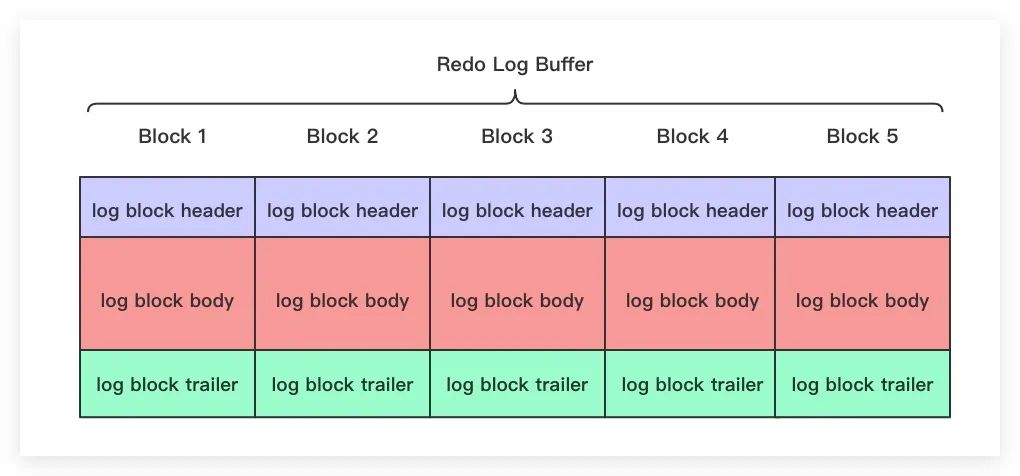
具體地,可通過配置文件中配置參數(shù)innodb_log_buffer_size來設置Redo Log Buffer的大小,單位為字節(jié)
[server]
# 設置Redo Log Buffer為16MB
innodb_log_buffer_size = 16777216;
此外,還可以通過(全局)系統(tǒng)變量innodb_log_buffer_size來進行查看、修改
-- 查看(全局)系統(tǒng)變量 innodb_log_buffer_size
show global variables like 'innodb_log_buffer_size';
-- 修改(全局)系統(tǒng)變量 innodb_log_buffer_size, 設置Redo Log Buffer為16MB
set global innodb_log_buffer_size = 16777216;
在MySQL運行過程中,其會將MTR所生成的redo log記錄先存放在其他地方。直到該MTR結束生成了該組全部的redo log記錄后,再將該組全部的redo log記錄復制到Redo Log Buffer中。具體地,在向Redo Log Buffer中寫入redo log記錄時,是順序使用Redo Log Buffer中各Block的,即先使用前面的Block再使用后面的Block。與此同時,其內部通過全局變量buf_free指向Redo Log Buffer中空閑區(qū)域的起始位置
眾所周知在MySQL實際運行過程中,可能會有多個事務并發(fā)執(zhí)行。當一個事務的一個MTR結束之時,其所生成該組的redo log記錄就需要全部寫入Redo Log Buffer中。換言之,多個事務的redo log記錄會是以MTR為單位被交替寫入到Redo Log Buffer中。假設這里有事務1、事務2,這兩個事務均有兩個MTR。當事務1、事務2之間一旦有某個MTR結束,即會將所其生成的若干條redo log記錄順序寫入到Redo Log Buffer,則有可能會出現(xiàn)如下圖所示的交替寫入的情況
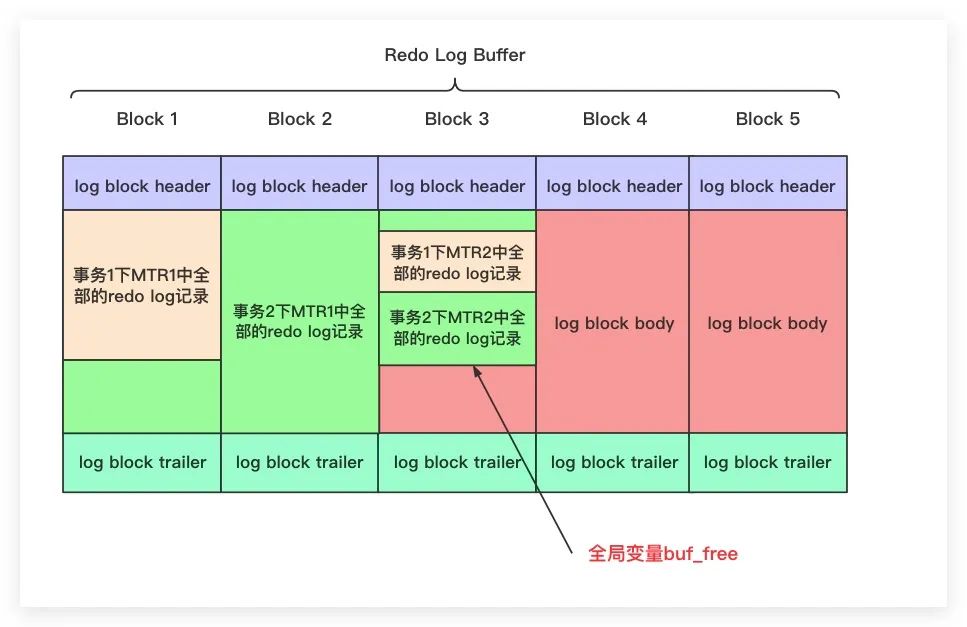
Redo Log File
配置
存放在Redo Log Buffer中的redo log記錄畢竟依然還是在內存當中,一旦發(fā)生意外(服務器宕機、斷電等)就會導致記錄數(shù)據丟失。服務重啟后的數(shù)據恢復工作由于沒有redo log記錄更是無從談起。故MySQL需要將Redo Log Buffer中的數(shù)據同步到硬盤中。一般地,在MySQL的數(shù)據目錄下會有兩個分別名為ib_logfile0、ib_logfile1的日志文件,用于存儲redo log。其中可通過 show variables like 'datadir' 語句查看數(shù)據目錄
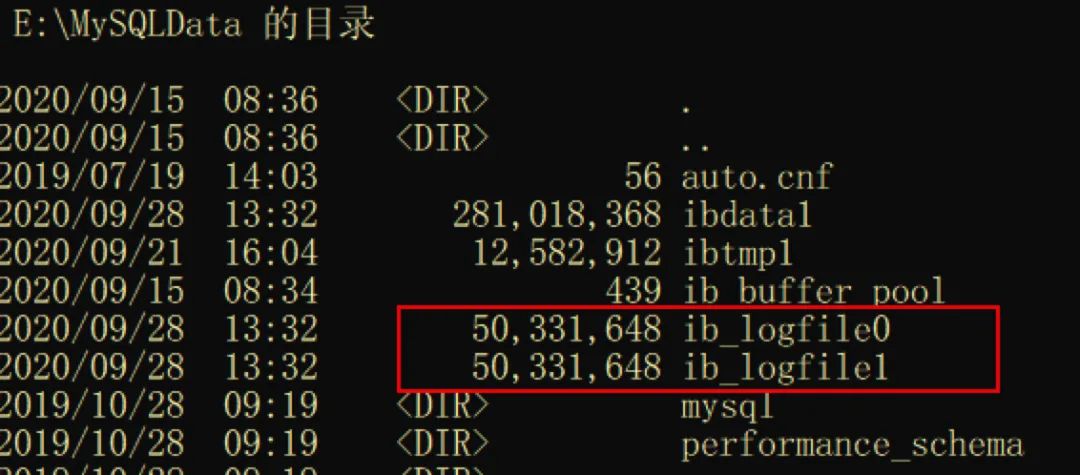
具體地,可通過配置文件中配置參數(shù)來進行相關配置。其中下面各配置項亦是同名的只讀的全局系統(tǒng)變量,即可通過 show variables 語句進行查看
[server]
# 設置Redo Log 日志文件的存放路徑
innodb_log_group_home_dir=E:/MySQLData/redoLog
# 設置每個redo log日志文件的大小為4MB,該配置項單位為字節(jié)
innodb_log_file_size=4194304
# 設置redo log日志文件的數(shù)量
innodb_log_files_in_group=5
易知,對于redo log file使用的空間大小為 innodb_log_file_size × innodb_log_files_in_group。日志文件的文件名則是通過數(shù)字進行編號的。例如當我們設置了innodb_log_files_in_group為5,則就會有5個日志文件,且命名分別為ib_logfile0、ib_logfile1、...、ib_logfile4。通常我們將這些日志文件稱之為日志文件組。在將Redo Log Buffer中的內容寫入磁盤時,也是順序寫入這些日志文件的。即先寫第一個日志文件ib_logfile0,如果滿了就寫到ib_logfile1文件中,依次類推。如果最后一個日志文件ib_logfile4也滿了,則又會從第一個日志文件ib_logfile0開始寫,即所謂的循環(huán)寫入
內部結構
前面我們提到Redo Log Buffer中是由若干個Block組成的。事實上對于Redo Log File而言,其內部同樣是由若干個512B大小的Block組成的,其內部結構示意圖如下所示
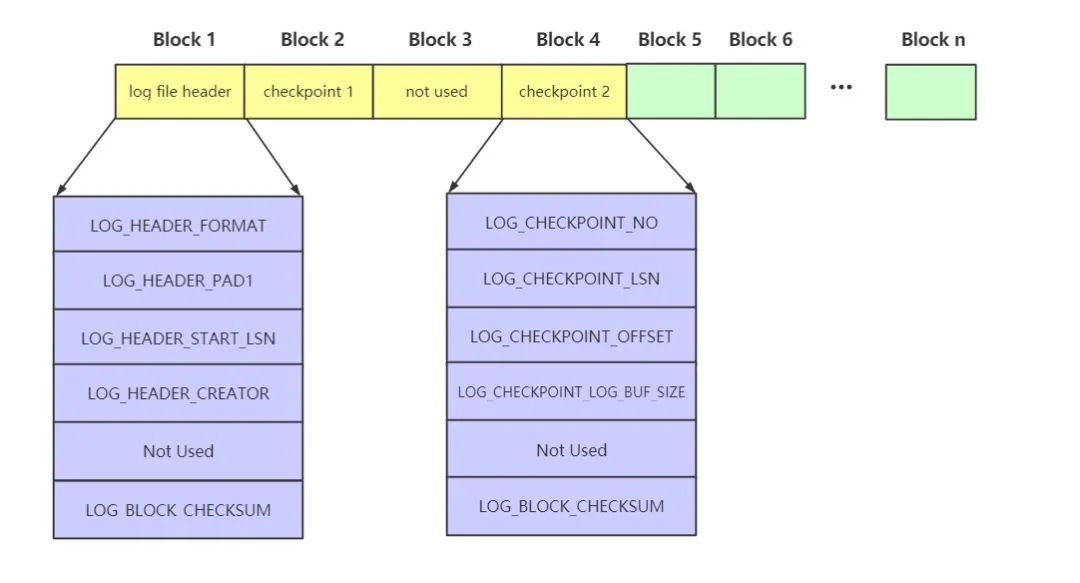
可以看到對于一個Redo Log File日志文件來說。其大致可分為兩部分:前4個Block用于存儲一些屬性、描述信息;剩余Block則用來存放Redo Log Buffer中的Redo Log Block。這里我們重點介紹下日志文件的前4個Block的結構
log file header
LOG_HEADER_FORMAT:該屬性使用4個字節(jié),標識redo log的版本 LOG_HEADER_PAD1:該屬性使用4個字節(jié),用于填充字節(jié)、無實際用途 LOG_HEADER_START_LSN:該屬性使用8個字節(jié),標識該日志文件開始的LSN值。即文件內偏移量為2048字節(jié)處對應的LSN值 LOG_HEADER_CREATOR:該屬性使用32個字節(jié),標識該日志文件的創(chuàng)建者信息。通常情況下,其內容為MySQL的版本信息;如果該日志文件是通過mysqlbackup命令進行創(chuàng)建的,則該屬性內容為"ibbackup"和創(chuàng)建時間 Not Used:未使用,占用460個字節(jié) LOG_BLOCK_CHECKSUM:該屬性使用4個字節(jié),標識該Block的校驗和
checkpoint 1、checkpoint 2
對于checkpoint 1、checkpoint 2的這兩個Block而言,其內部結構完全一樣
LOG_CHECKPOINT_NO:該屬性使用8個字節(jié),標識checkpoint操作的序號 LOG_CHECKPOINT_LSN:該屬性使用8個字節(jié),標識checkpoint操作時對應的LSN值。恢復數(shù)據時從該值開始 LOG_CHECKPOINT_OFFSET:該屬性使用8個字節(jié),標識LOG_CHECKPOINT_LSN屬性的LSN值在日志文件組中的偏移量 LOG_CHECKPOINT_LOG_BUF_SIZE:該屬性使用8個字節(jié),用于標識在checkpoint操作中對應的Redo Log Buffer的大小 Not Used:未使用,占用476個字節(jié) LOG_BLOCK_CHECKSUM:該屬性使用4個字節(jié),標識該Block的校驗和
redo log同步
所謂redo log同步指的就是將內存中的redo log寫入到硬盤中。具體地,是將Redo Log Buffer中的Block鏡像寫入到日志文件剩余的Block中。通常在以下幾種場景中redo log會被寫入到磁盤的日志文件中
Redo Log Buffer 中的剩余空間不多時 在提交事務時,可以不立刻將Buffer Pool中被修改的頁同步到硬盤上。但為了保證持久性,需要將相應的redo log刷新到硬盤上 后臺線程會定時地將Redo Log Buffer中的Block同步到硬盤上 執(zhí)行checkpoint操作時 MySQL服務正常關閉時
這里我們就在提交事務時是否需要相應的redo log從Redo Log Buffer同步到硬盤上來展開說明。事實上,InnoDB引擎提供了一個全局系統(tǒng)變量innodb_flush_log_at_trx_commit來讓用戶自行選擇提交事務時是否立即同步其產生的redo log。具體地,其有以下值可選
0:提交事務時不立即同步redo log到硬盤中,而是通過后臺線程進行同步。顯然此舉可以明顯加快處理請求的速度 1:提交事務時立即同步redo log到硬盤中。該全局系統(tǒng)變量默認為1 2:提交事務時只是將redo log先寫到OS的緩沖區(qū),而不是真正地寫到硬盤中。這樣即使MySQL服務意外停止了,只要OS還在正常運行,事務的持久性依然是可以保證的
可通過下面的SQL語句進行查看、修改
-- 查看全局系統(tǒng)變量 innodb_flush_log_at_trx_commit
show variables like 'innodb_flush_log_at_trx_commit';
-- 修改全局系統(tǒng)變量 innodb_flush_log_at_trx_commit
set global innodb_flush_log_at_trx_commit = 1;
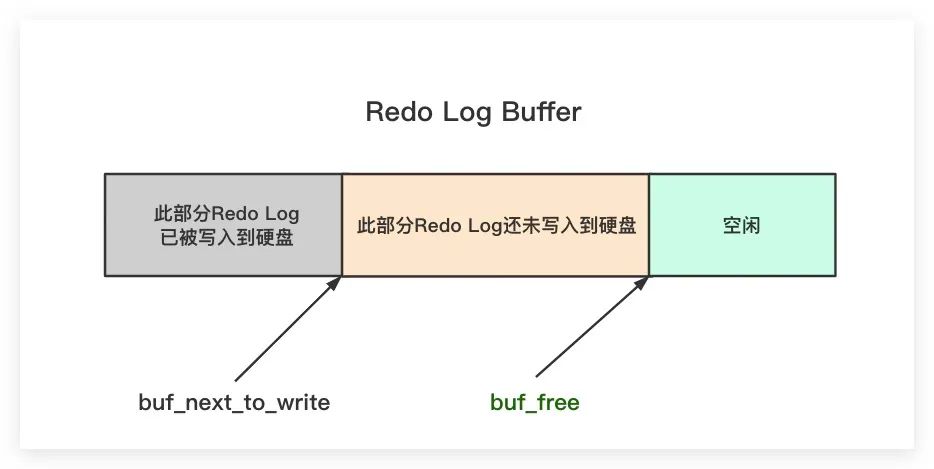
前面我們提到,在InnoDB內部有一個全局變量buf_free指向Redo Log Buffer中空閑區(qū)域的起始位置。與此同時,在InnoDB內部還有一個全局變量buf_next_to_write指向Redo Log Buffer中下一次需要寫入硬盤的起始位置。則Redo Log Buffer中這兩個全局變量之間的關系如下圖所示
Log Sequence Number
在MySQL運行過程中,不斷會有redo log被寫入到Redo Log Buffer中。為此,InnoDB提出了一個Log Sequence Number(LSN)日志序列號的概念,用于表示寫入Redo Log Buffer中的redo log量,其中LSN值的變化趨勢是單調遞增的。對于任一一個redo log都有唯一的LSN值與之對應。這里關于LSN值的計算有兩點值得注意
當MySQL服務第一次啟動時LSN值的初值不是0,而是8704。當MySQL服務被停止后再次啟動時(即非第一次啟動),將繼續(xù)使用上一次服務停止前最新的LSN值 雖然MTR中的一組redo log只是寫到Redo Log Buffer的log block body當中。但是在計算LSN的增長量時,不僅需要依據寫入的redo log量(即redo log的字節(jié)數(shù)),還需要考慮在寫入該組的redo log時其實際使用的log block header、log block trailer部分的字節(jié)數(shù)
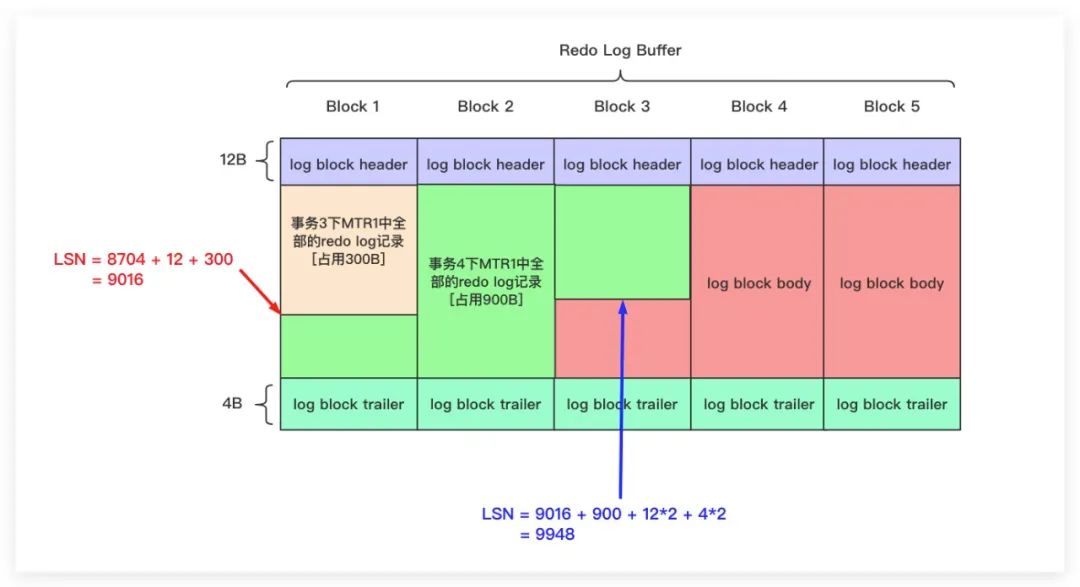
這里結合一個例子來說明LSN是如何計算的,這里假設MySQL服務是第一次啟動。某個時刻下事務3中的一個MTR結束并生成了若干條redo log,其大小為300B。此時將這大小為300B的redo log寫入到Redo Log Buffer的第一個Block中,則此時的LSN值為8704 + 12 + 300 = 9016。至于為什么要加12原因在上面的第2點也說了,因為存儲該redo log的同時,實際上還使用了該Block的log block header(該部分占12個字節(jié));隨后,當事務4中的一個MTR也結束并生成了若干條redo log,大小為900B。則將其寫入Redo Log Buffer后,LSN值更新為 9016 + 900 + 12*2 + 4*2= 9948。示意圖如下所示
在Redo Log Buffer中,全局變量buf_free與LSN值是相對應的;類似地對于全局變量buf_next_to_write而言,其同樣也有一個與之對應的全局變量——flushed_to_disk_lsn,用于表示Redo Log Buffer中哪些redo log被寫入到磁盤中。示意圖如下所示
前面我們提到當我們修改頁數(shù)據時,需要將臟頁的控制塊加入Buffer Pool的flush鏈表進行管理。其中控制塊中還有兩個屬性:oldest_modification、newest_modification。其分別表示該頁被緩存到Buffer Pool后第一次修改時其MTR開始時的LSN值、被緩存到Buffer Pool中每次修改該頁面的MTR結束時的LSN值。具體地,如果該臟頁的控制塊不在flush鏈表中則從頭部插入到flush鏈表中,并向該控制塊的oldest_modification、newest_modification屬性寫入該修改操作開始、結束時對應的LSN值;如果該臟頁的控制塊已經在flush鏈表中只需在每次修改的MTR結束時利用LSN值來更新該控制塊的newest_modification屬性。換言之,對于flush鏈表來說,其是按照控制塊的oldest_modification屬性進行降序排序的。即根據該頁緩存到Buffer Pool后發(fā)生第一次修改的時間由近到遠進行排序
Checkpoint機制
前面我們在介紹Redo Log File的寫入順序時提到,其是循環(huán)寫入的。即當最后一個日志文件寫滿了,其會從繼續(xù)從第一個日志文件開始寫。之所以進行循環(huán)寫入,是因為日志文件所占用的空間不可能無限增大。聰明的朋友可能發(fā)現(xiàn)了,這樣會有問題啊,它會導致之前寫到日志文件的內容被覆蓋了。為此Checkpoint機制應運而生
我們知道一旦Buffer Pool的flush鏈表中的臟頁被同步到硬盤后,則其所對應的redo log也就沒有存在的意義了。而前面提到flush鏈表是按控制塊的oldest_modification屬性進行降序排序的,故鏈表尾部控制塊的oldest_modification屬性是最小的,這里我們假設其值是12345。結合該屬性的意義和LSN值單調遞增的特性,我們可知如果redo log對應的LSN值小于12345的話,則該redo log就沒有繼續(xù)保留的意義了。因為該redo log所對應的臟頁已經被寫入到硬盤中了。這就是Redo Log File可以被重用以進行覆蓋寫入的原因了。具體地,在進行Checkpoint操作時大致有以下兩個步驟
通過flush鏈表最后一個控制塊的oldest_modification屬性,獲取無用redo log對應的最大的LSN值。特別地,InnoDB中使用了一個全局變量checkpoint_lsn來存儲該值。在上文的例子中,該值即為12345 將本次checkpoint的信息保存到第一個redo log file(即ib_logfile0文件)中。根據redo log file的結構可知,其內部有兩個Block可用——checkpoint 1、checkpoint 2。這兩個Block內部結構完全一致,具體使用哪個Block進行存儲。實際上取決于InnoDb中用于統(tǒng)計進行checkpoint次數(shù)的checkpoint_no變量,每進行一次checkpoint操作,該變量自增一次。當checkpoint_no變量的值為偶數(shù)時,使用checkpoint 1 進行存儲;反之,則使用checkpoint 2進行存儲
可以看到通過Checkpoint機制,其解決了下面幾個關鍵問題
MySQL服務發(fā)生崩潰、重啟后,在恢復數(shù)據的過程中,減少了數(shù)據恢復的工作量,縮短了數(shù)據恢復的時間 Buffer Pool容量是有限的,一旦不夠用時即需要根據LRU算法進行淘汰。若該頁為臟頁,則需要將其同步到硬盤上,并進行Checkpoint操作 Redo Log File同樣容量有限,一旦不夠用需要覆蓋之前的日志內容時,為保證被覆蓋的日志內容是不再需要的、無用的,則需要將Buffer Pool中的臟頁同步到硬盤中,并進行Checkpoint操作
至此我們將InnoDB中幾個重要的LSN值進行了介紹,我們可通過下面的語句進行查看
show engine innodb status;
這里就其中涉及關于LSN的輸出結果進行解釋
...
---
LOG
---
# LSN值,即MySQL服務已經生成、寫入到Redo Log Buffer的日志量
Log sequence number 215412149596
# flushed_to_disk_lsn值,即MySQL服務寫入到磁盤的日志量
Log flushed up to 215412149596
# Buffer Pool的flush鏈表中最后一個頁面(即最早被修改)的頁所對應的oldest_modification屬性值
Pages flushed up to 215412149596
# checkpoint_lsn值, 即MySQL服務最近一次checkpoint操作時的LSN值
Last checkpoint at 215412149587
...
恢復數(shù)據
前面說了很多redo log相關的內容,現(xiàn)在到了真正發(fā)揮redo log價值的時刻了。一旦MySQL服務突然掛了,Buffer Pool中的臟頁還沒來得及寫入到硬盤中。此時重啟MySQL服務后,就需要利用redo log來恢復數(shù)據了
恢復數(shù)據的起點
前面我們說了每次checkpoint操作后,會將此次checkpoint的信息保存到第一個redo log file(即ib_logfile0文件)中。而其內部有兩個存儲checkpoint的Block——checkpoint 1、checkpoint 2。顯然我們要從最近一次的checkpoint操作開始恢復數(shù)據。因為對于任何redo log對應的LSN小于checkpoint_lsn的情況,其修改操作的臟頁均已被同步到硬盤中,也就是前面所說的checkpoint機制可以減少恢復數(shù)據時的工作量、縮短恢復數(shù)據的時間。具體地,對于上文的兩個Block——checkpoint 1、checkpoint 2而言,通過比較各自的checkpoint_no屬性即可,較大的者即為最近一次的checkpoint信息。然后利用該Block中的checkpoint_lsn、checkpoint_offset信息,即可進一步確定日志文件組中恢復數(shù)據所需redo log的起點
恢復數(shù)據的終點
前面我們提到Block中有一個LOG_BLOCK_HDR_DATA_LEN屬性,用于表示該Block已使用的字節(jié)數(shù)。當該Block的空間全部使用完畢,則該值為512。則若某個Block該屬性值不為512,則其即為恢復數(shù)據時所需redo log的終點
優(yōu)化恢復
哈希表:減少頁面加載次數(shù)
確定了恢復數(shù)據所需的redo log后,即可順序使用這些redo log將相關頁面加載到內存進行相應的修改操作。但是為了減少頁面加載的次數(shù),減少數(shù)據恢復過程中的時間。InnoDB利用哈希表進行了優(yōu)化。具體地,將redo log中的表空間ID、頁號作為哈希表的鍵,而哈希表的值則為一個鏈表,用于存放對同一個頁進行修改的所有redo log。其中鏈表中的redo log則是按生成時間的順序由遠到近進行排序的。這里鏈表中各redo log順序不能錯亂,否則在利用這些redo log進行數(shù)據恢復時即可能會出現(xiàn)錯誤。例如當我們先向表中插入一條數(shù)據,然后又刪除了該數(shù)據。而如果我們在恢復數(shù)據時,按 先刪除該數(shù)據再插入該數(shù)據 的順序進行恢復,顯然是不符的
當哈希表建立完成后,我們就可以不用順序遍歷所有的redo log進行數(shù)據恢復了。而是通過遍歷哈希表進行恢復,因為此時對某個頁進行所有修改的redo log均在該鍵所對應的鏈表中。這樣即可一次性完成對該頁的恢復、修改,減少了隨機IO的次數(shù)
跳過已經同步到硬盤的頁
對于任何redo log對應的LSN小于checkpoint_lsn的情況,其修改操作的臟頁均已被同步到硬盤中。但是對于redo log對應的LSN大于checkpoint_lsn的情況來說,其修改操作的臟頁是否同步到硬盤中是不確定的。即可能在一次checkpoint后,存在少部分的臟頁已經被同步到硬盤中了。這時我們在恢復數(shù)據時,對于這些頁是無需使用全部的redo log進行修改、恢復的
我們知道在頁的File Header部分有一個FIL_PAGE_LSN屬性,其記錄的是最近一次修改該頁結束時的LSN值(即flush鏈表中控制塊的newest_modification值)。故如果在checkpoint操作后該臟頁被同步到硬盤了,則該頁的FIL_PAGE_LSN屬性必然是大于checkpoint_lsn的。故此時在數(shù)據恢復的過程中,如果發(fā)現(xiàn)redo log對應的LSN值小于FIL_PAGE_LSN屬性,則可直接跳過該redo log。即無需進行重復的修改。顯然此舉可以進一步提高數(shù)據恢復的效率
參考文獻
MySQL是怎樣運行的