
史上最火 ECCV 已開幕,這些論文都太有意思了
By 超神經(jīng)
內(nèi)容提要:計算機視覺領域三大國際頂級會議之一的 ECCV 2020,于 8 月 23 日至 27 日在線召開。今年 ECCV 共接受論文 1361 篇,我們從中篩選出了 15 篇最受關注的論文,與讀者分享。
關鍵詞:ECCV 2020? 精選論文
受疫情影響,今年 ECCV 2020 和其它頂會一樣,由線下轉至線上舉辦,已于 8 月 23 日拉開了帷幕。

23 日主要為工作坊與教程,主議程于?24 日開始
ECCV,全稱 European Conference on Computer Vision(歐洲計算機視覺國際會議)?,是計算機視覺三大國際頂級會議之一(另外兩大頂會為 CVPR 和 ICCV),每兩年舉辦一次。
雖然今年的疫情打亂了人們的很多計劃,但是大家對科研以及論文投稿的熱情卻依然有增無減。據(jù)統(tǒng)計,ECCV 2020 共收到有效投稿 5025 篇,是上一屆(2018 年)投稿量的兩倍還多,因此被認為是「史上最火 ECCV」。
最終被接收發(fā)表論文 1361 篇,接收率為 27%。在接收論文中,oral 的論文數(shù)為 104 篇,占有效投稿總數(shù)的 2%,spotlight 的數(shù)目為 161 篇,比例約為 3%。其余論文為 poster。
?姿態(tài)估計、3D 點云,優(yōu)秀論文一覽
這場計算機視覺領域的盛會,今年為我們帶來了哪些精彩研究成果?
我們從入選論文中,精選出 15 篇,分別涉及 3D 目標檢測、姿態(tài)估計、圖像分類、人臉識別等多個方向。
?行人重識別 《請別打擾我:
在其他行人干擾下的行人重識別》

單位:華中科技大學,中山大學,騰訊優(yōu)圖實驗室
摘要:
傳統(tǒng)的行人重識別假設裁剪的圖像只包含單人。然而,在擁擠的場景中,現(xiàn)成的檢測器可能會生成多人的邊界框,并且其中背景行人占很大比例,或者存在人體遮擋。
從這些帶有行人干擾的圖像中提取的特征可能包含干擾信息,這將導致錯誤的檢索結果。
為了解決這一問題,本文提出了一種新的深層網(wǎng)絡(PISNet)。PISNet 首先利用 Query 圖片引導的注意力模塊來增強圖片中目標的特征。
此外,我們提出了反向注意模塊和多人分離損失函數(shù)促進了注意力模塊來抑制其他行人的干擾。我們的方法在兩個新的行人干擾數(shù)據(jù)集上進行了評估,結果表明,該方法優(yōu)于現(xiàn)有的 Re-ID 方法。

論文地址:https://arxiv.org/pdf/2008.06963
?姿態(tài)估計?《在擁擠場景中基于
多視點幾何的對多人三維姿態(tài)估計》

單位:約翰斯·霍普金斯大學,新加坡國立大學
摘要:
外極約束是目前多機三維人體姿態(tài)估計方法中特征匹配和深度估計的核心問題。盡管該公式在稀疏人群場景中的表現(xiàn)令人滿意,但在密集人群場景中,其有效性經(jīng)常受到挑戰(zhàn),主要是由于兩個來源的模糊性。
首先是由于關節(jié)和對極線之間的歐幾里得距離所提供的簡單線索而導致的人類關節(jié)不匹配。第二個問題是,由于天真地將問題最小化為最小平方,因此缺乏魯棒性。
在本文中,我們脫離了多人三維姿態(tài)估計公式,將其重新定義為人群姿態(tài)估計。我們的方法包括兩個關鍵部分:一個用于快速跨視圖匹配的圖模型和一個用于三維人體姿態(tài)重建的最大后驗(MAP)估計器。我們在四個基準數(shù)據(jù)集上證明了該方法的有效性和優(yōu)越性。
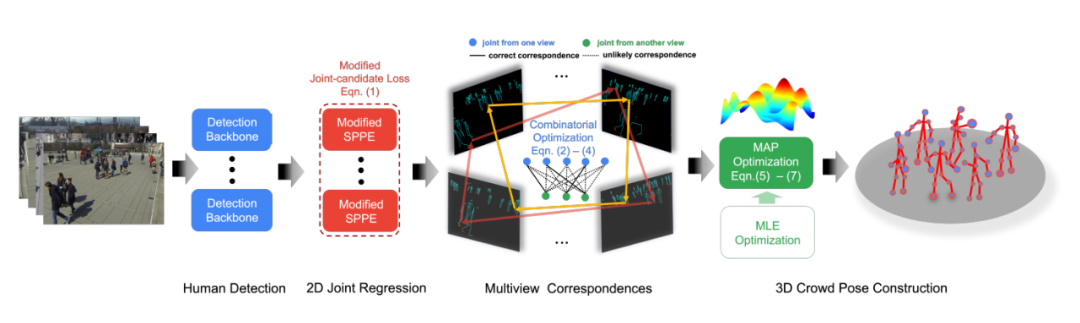
論文地址:https://arxiv.org/pdf/2007.10986
?描述圖像?《基于場景圖分解的自然語言描述生成》

單位:騰訊 AI Lab,威斯康星大學麥迪遜分校
摘要:
本文提出了一種基于場景圖分解的自然語言描述生成方法。
使用自然語言來描述圖像是一項頗具挑戰(zhàn)性的任務,本文通過重新回顧圖像場景圖表達,提出了一種基于場景圖分解的圖像自然語言描述生成方法。該方法的核心是把一張圖片對應的場景圖分解成多個子圖,其中每個子圖對應描述圖像的一部分內(nèi)容或一部分區(qū)域。通過神經(jīng)網(wǎng)絡選擇重要的子圖來生成一個描述圖像的完整句子,該方法可以生成準確、多樣化、可控的自然語言描述。研究者也進行了廣泛的實驗,實驗結果展現(xiàn)了這一新模型的優(yōu)勢。
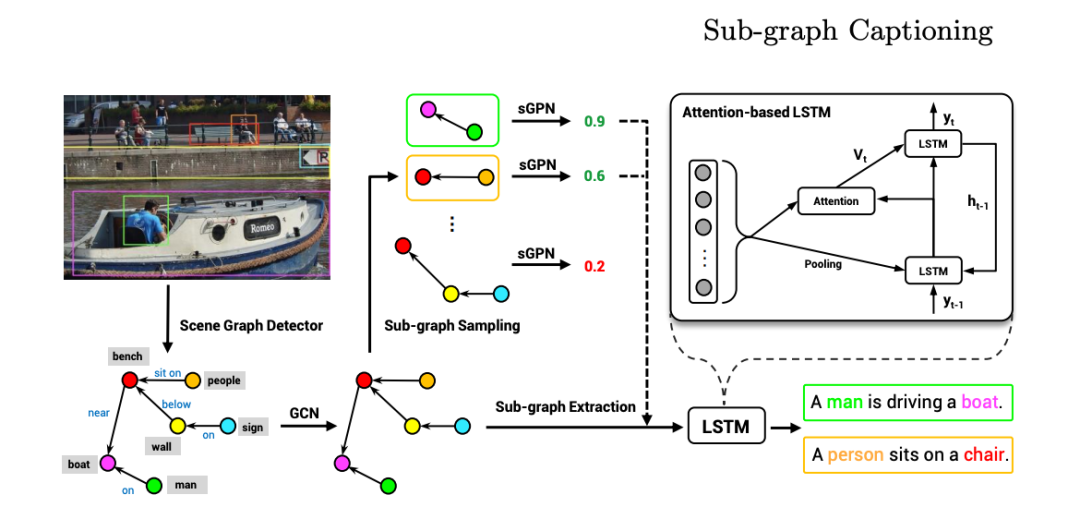
論文地址:https://arxiv.org/abs/2007.11731
?3D 點云?《用于 3D 點云的四元數(shù)等變膠囊網(wǎng)絡》

單位:斯坦福大學,多特蒙德工業(yè)大學,帕多瓦大學
摘要:
我們提出了一種處理點云的三維膠囊架構,它與無序輸入集的 SO(3)旋轉組、平移和排列等價。
該網(wǎng)絡在局部參考幀的稀疏集上運行,該局部參考幀是從輸入點云計算而來的。該網(wǎng)絡通過一種新的三維四元數(shù)群膠囊層建立端到端方差,其中包括一種等方差動態(tài)路由過程。
膠囊層使我們能夠從姿勢中解開幾何圖形,為獲得更多信息描述和結構化的潛在空間鋪平了道路。在此過程中,我們從理論上將膠囊之間的動態(tài)路由過程與著名的 Weiszfeld 算法聯(lián)系起來,該解決方案用于解決具有可證明的收斂特性的迭代重加權最小二乘(IRLS)問題,從而實現(xiàn)了膠囊層間魯棒姿態(tài)估計。
由于稀疏的等變四元數(shù)膠囊,我們的體系結構允許進行聯(lián)合對象分類和方向估計,我們可以在常見基準數(shù)據(jù)集上進行實證驗證。

論文地址:https://arxiv.org/pdf/1912.12098.pdf
?人臉識別?《可解釋的人臉識別》

單位:Systems & Technology Research, Visym Labs
摘要:
可解釋的人臉識別(簡稱 XFR)是一個解釋人臉匹配器返回的匹配結果的問題,以便深入了解為什么一個探測器會匹配一個身份而不是另一個身份。了解該原理,能夠幫助人們?nèi)バ湃魏徒忉屓四樧R別。
在本文中,我們提供了第一個全面的基準和基線評估 XFR。我們定義了一種新的評估方案,叫做「修復游戲」(inpainting game),它是一套由 95 個受試者組成的 3648 個 triplets(probe, mate, nonmate)的精選集合,通過對選定的面部特征(如鼻子、眉毛或嘴)進行合成修復,從而創(chuàng)造出一個被修補的 nonmate。
XFR 算法的任務是生成一個網(wǎng)絡注意力圖,該圖可以最好地指出 probe 圖像中哪些區(qū)域與配對的圖像相匹配,而不是與每個 triplet 被修復的未匹配的區(qū)域。這為量化哪些圖像區(qū)域有助于人臉匹配提供了依據(jù)。
最后,我們在此數(shù)據(jù)集上提供了一個全面的基準,在三個面部匹配器上,比較了五種最先進的算法。這一基準測試包括兩種新的算法,分別稱為子樹 EBP和基于密度的輸入采樣解釋(DISE),它們的性能遠遠優(yōu)于現(xiàn)有的最先進的技術。
我們還在新穎的圖像上顯示了這些網(wǎng)絡注意力技術的定性可視化,并探討了這些可解釋的人臉識別模型如何提高人臉匹配者的透明度和信任度。

論文地址:https://arxiv.org/pdf/2008.00916
?年齡估計?《壽命年齡轉化合成》

單位:華盛頓大學,斯坦福大學,Adobe?Research
摘要:
我們解決了單張照片年齡的遞進和回歸問題——預測一個人在未來或過去的樣子。
現(xiàn)有的老化方法大多局限于改變紋理,忽略了人類老化和生長過程中頭部形狀的變化。這就限制了以前的方法對年齡稍大的成年人的適用性,而這些方法對兒童照片的應用并不能產(chǎn)生高質(zhì)量的結果。
我們提出了一種新的多領域圖像對圖像生成對抗網(wǎng)絡結構,其學習的潛在空間模擬了一個持續(xù)的雙向老化過程。網(wǎng)絡在 FFHQ 數(shù)據(jù)集上進行訓練,我們根據(jù)年齡、性別和語義分割對其進行標記。使用固定年齡類作為錨點來近似連續(xù)年齡變換。我們的框架可以僅根據(jù)一張照片,預測出完整的?0-70 歲的頭像,并修改紋理和頭部的形狀。我們在各種各樣的照片和數(shù)據(jù)集上展示了結果,并顯示了在技術水平上的顯著改進。

論文地址:https://arxiv.org/abs/2003.09764
?傳送門:論文、代碼,通通一鍵即達
以上只是 ECCV 2020 上千篇入選論文中的冰山一角,但是面對 1361 篇海量論文,想要找到自己感興趣的論文以及原文鏈接、代碼等,著實不是件輕松的事情。
不過,一個叫做 Paper Digest Team 的團隊,已經(jīng)為廣大讀者鋪好了路,找論文、找代碼都不再是問題。
該團隊最近發(fā)布了一份《一句話點評 ECCV 2020 論文亮點》的總結,對每篇論文都只用一句話進行了總結,言簡意賅,并且都附上了論文地址,讓讀者快速找到自己最想讀的論文。

內(nèi)容中包括了論文標題、地址、作者和亮點總結
地址拿走不謝:
https://www.paperdigest.org/wp-content/uploads/2020/08/ECCV-2020-Paper-Digests.pdf
此外,他們還貼心地將 170 篇公布了代碼的論文做了整理,讀者可直接點擊相應鏈接查看代碼:
https://www.paperdigest.org/2020/08/eccv-2020-papers-with-code-data/
另外,crossminds.ai 還將 oral 論文的演示文稿整理出來,讀者能夠通過其 demo 演示,更加清晰、直觀地了解論文中的技術,非常有趣:
https://crossminds.ai/category/eccv%202020/
—— 完 ——
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請掃碼進群(如果是博士或者準備讀博士請說明):