
驗(yàn)證碼的爬取和識(shí)別詳解
今天要給大家介紹的是驗(yàn)證碼的爬取和識(shí)別,不過只涉及到最簡單的圖形驗(yàn)證碼,也是現(xiàn)在比較常見的一種類型。
運(yùn)行平臺(tái):Windows
Python版本:Python3.6
IDE: Sublime Text
其他:Chrome瀏覽器

步驟1:簡單介紹驗(yàn)證碼
步驟2:爬取少量驗(yàn)證碼圖片
步驟3:介紹百度文字識(shí)別OCR
步驟4:識(shí)別爬取的驗(yàn)證碼
步驟5:簡單圖像處理
目前,很多網(wǎng)站會(huì)采取各種各樣的措施來反爬蟲,驗(yàn)證碼就是其中一種,比如當(dāng)檢測(cè)到訪問頻率過高時(shí)會(huì)彈出驗(yàn)證碼讓你輸入,確認(rèn)訪問網(wǎng)站的不是機(jī)器人。但隨著爬蟲技術(shù)的發(fā)展,驗(yàn)證碼的花樣也越來越多,從最開始簡單的幾個(gè)數(shù)字或字母構(gòu)成的圖形驗(yàn)證碼(也就是我們今天要涉及的)發(fā)展到需要點(diǎn)擊倒立文字字母的、與文字相符合的圖片的點(diǎn)觸型驗(yàn)證碼,需要滑動(dòng)到合適位置的極驗(yàn)滑動(dòng)驗(yàn)證碼,以及計(jì)算題驗(yàn)證碼等等,總之花樣百出,讓人頭禿。驗(yàn)證碼其他的相關(guān)知識(shí)大家可以看下這個(gè)網(wǎng)站:captcha.org
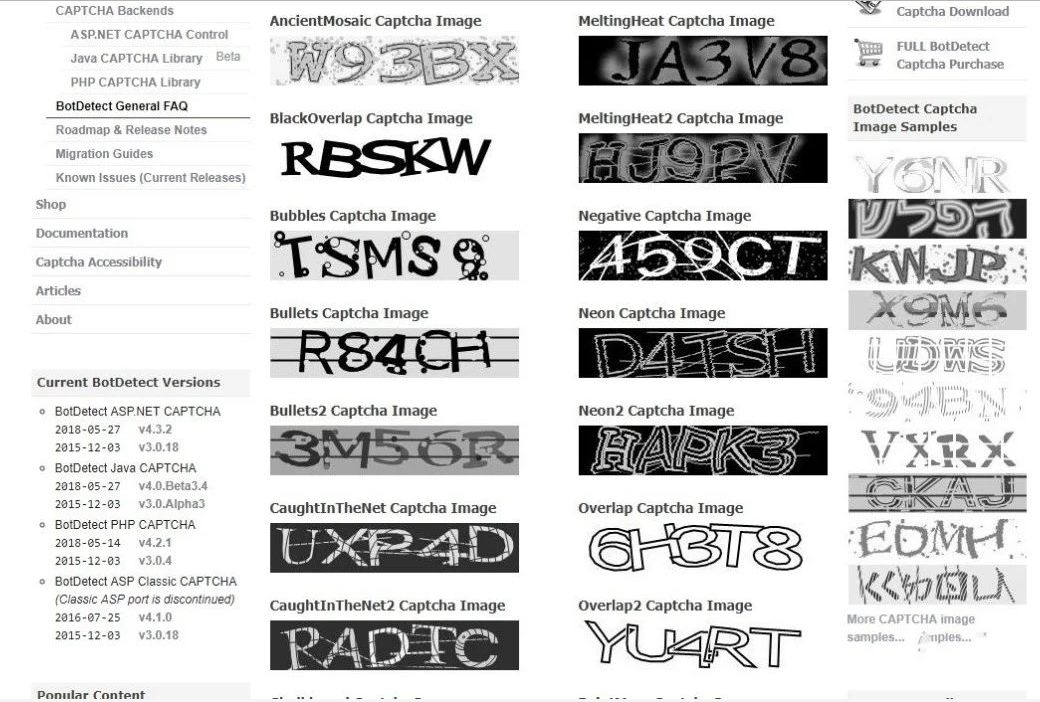
再來簡單說下圖形驗(yàn)證碼吧,就像這張:

由字母和數(shù)字組成,再加上一些噪點(diǎn),但為了防止被識(shí)別,簡單的圖形驗(yàn)證碼現(xiàn)在也變得復(fù)雜,有的加了干擾線,有的加噪點(diǎn),有的加上背景,字體扭曲、粘連、鏤空、混用等等,甚至有時(shí)候人眼都難以識(shí)別,只能默默點(diǎn)擊“看不清,再來一張”。
驗(yàn)證碼難度的提高隨之帶來的就是識(shí)別的成本也需要提高,在接下來的識(shí)別過程中,我會(huì)先直接使用百度文字識(shí)別OCR,來測(cè)試識(shí)別準(zhǔn)確度,再確認(rèn)是否選擇轉(zhuǎn)灰度、二值化以及去干擾等圖像操作優(yōu)化識(shí)別率。
接下來我們就來爬取少量驗(yàn)證碼圖片存入文件。
首先打開Chrome瀏覽器,訪問剛剛介紹的網(wǎng)站,里面有一個(gè)captcha圖像樣本鏈接:https://captcha.com/captcha-examples.html?cst=corg,網(wǎng)頁里有60張不同類型的圖形驗(yàn)證碼,足夠我們用來識(shí)別試驗(yàn)了。
直接來看代碼吧:
import?requests
import?os
import?time
from?lxml?import?etree
def?get_Page(url,headers):
????response?=?requests.get(url,headers=headers)
????if?response.status_code?==?200:
????????#?print(response.text)
????????return?response.text
????return?None
def?parse_Page(html,headers):
????html_lxml?=?etree.HTML(html)
????datas?=?html_lxml.xpath('.//div[@class="captcha_images_left"]|.//div[@class="captcha_images_right"]')
????item=?{}
????#?創(chuàng)建保存驗(yàn)證碼文件夾
????file?=?'D:/******'
????if?os.path.exists(file):
????????os.chdir(file)
????else:????
????????os.mkdir(file)
????????os.chdir(file)????
????for?data?in?datas:
????????#?驗(yàn)證碼名稱
????????name?=?data.xpath('.//h3')
????????#?print(len(name))
????????#?驗(yàn)證碼鏈接
????????src?=?data.xpath('.//div/img/@src')????
????????#?print(len(src))
????????count?=?0
????????for?i?in?range(len(name)):
????????????#?驗(yàn)證碼圖片文件名
????????????filename?=?name[i].text?+?'.jpg'
????????????img_url?=?'https://captcha.com/'?+?src[i]
????????????response?=?requests.get(img_url,headers=headers)
????????????if?response.status_code?==?200:
????????????????image?=?response.content
????????????????with?open(filename,'wb')?as?f:
????????????????????f.write(image)
????????????????????count?+=?1
????????????????????print('保存第{}張驗(yàn)證碼成功'.format(count))
????????????????????time.sleep(1)
def?main():
????url?=?'https://captcha.com/captcha-examples.html?cst=corg'
????headers?=?{'User-Agent':'Mozilla/5.0?(Windows?NT?10.0;?WOW64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/65.0.3325.146?Safari/537.36'}
????html?=?get_Page(url,headers)
????parse_Page(html,headers)
if?__name__?==?'__main__':
????main()
仍然使用Xpath爬取,在右鍵檢查圖片時(shí)可以發(fā)現(xiàn),網(wǎng)頁分為兩欄,如下圖紅框所示,根據(jù)class分為左右兩欄,驗(yàn)證碼分別位于兩欄中。
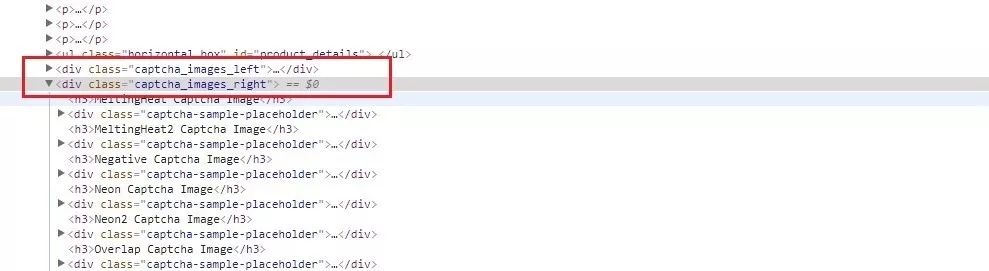
datas?=?html_lxml.xpath('.//div[@class="captcha_images_left"]|.//div[@class="captcha_images_right"]')
這里我使用了Xpath中的路徑選擇,在路徑表達(dá)式中使用“|”表示選取若干路徑,例如這里表示的就是選取class為"captcha_images_left"或者"captcha_images_right"的區(qū)塊。再來看下運(yùn)行結(jié)果:
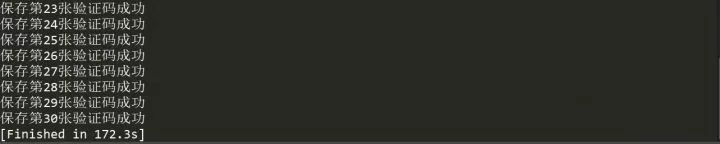
由于每爬取一張驗(yàn)證碼圖片都強(qiáng)制等待了1秒,最后這個(gè)運(yùn)行時(shí)間確實(shí)讓人絕望,看樣子還是需要多線程來加快速度的,關(guān)于多進(jìn)程多線程我們下次再說,這里我們先來看下爬取到的驗(yàn)證碼圖片。

圖片到手了,接下來就是調(diào)用百度文字識(shí)別的OCR來識(shí)別這些圖片了,在識(shí)別之前,先簡單介紹一下百度OCR的使用方法,因?yàn)楹芏嘧R(shí)別驗(yàn)證碼的教程用的都是tesserocr庫,所以一開始我也嘗試過,安裝過程中就遇到了很多坑,后來還是沒有繼續(xù)使用,而是選擇了百度OCR來識(shí)別。百度OCR接口提供了自然場(chǎng)景下圖片文字檢測(cè)、定位、識(shí)別等功能。文字識(shí)別的結(jié)果可以用于翻譯、搜索、驗(yàn)證碼等代替用戶輸入的場(chǎng)景。另外還有其他視覺、語音技術(shù)方面的識(shí)別功能,大家可以直接閱讀文檔了解:百度OCR-API文檔
https://ai.baidu.com/docs#/OCR-API/top
使用百度OCR的話,首先注冊(cè)用戶,然后下載安裝接口模塊,直接終端輸入pip install baidu-aip即可。然后創(chuàng)建文字識(shí)別應(yīng)用,獲取相關(guān)Appid,API Key以及Secret Key,需要了解一下的是百度AI每日提供50000次免費(fèi)調(diào)用通用文字識(shí)別接口的使用次數(shù),足夠我們揮霍了。
然后就可以直接調(diào)用代碼了。
from?aip?import?AipOcr
#??你的?APPID?AK?SK?
APP_ID?=?'你的?APP_ID?'
API_KEY?=?'你的API_KEY'
SECRET_KEY?=?'你的SECRET_KEY'
client?=?AipOcr(APP_ID,?API_KEY,?SECRET_KEY)
#?讀取圖片?
def?get_file_content(filePath):
????with?open(filePath,?'rb')?as?fp:
????????return?fp.read()
image?=?get_file_content('test.jpg')
#??調(diào)用通用文字識(shí)別,?圖片參數(shù)為本地圖片?
result?=?client.basicGeneral(image)
#?定義參數(shù)變量??
options?=?{
????#?定義圖像方向
????????'detect_direction'?:?'true',
????#?識(shí)別語言類型,默認(rèn)為'CHN_ENG'中英文混合
????????'language_type'?:?'CHN_ENG',
}
#?調(diào)用通用文字識(shí)別接口??
result?=?client.basicGeneral(image,options)
print(result)
for?word?in?result['words_result']:
????print(word['words'])
這里我們識(shí)別的是這張圖

可以看一下識(shí)別結(jié)果

上面是識(shí)別后直接輸出的結(jié)果,下面是單獨(dú)提取出來的文字部分。可以看到,除了破折號(hào)沒有輸出外,文字部分都全部正確輸出了。這里我們使用的圖片是jpg格式,文字識(shí)別傳入的圖像支持jpg/png/bmp格式,但在技術(shù)文檔中有提到,使用jpg格式的圖片上傳會(huì)提高一定準(zhǔn)確率,這也是我們爬取驗(yàn)證碼時(shí)使用jpg格式保存的原因。
輸出結(jié)果中,各字段分別代表:
log_id : 唯一的log id,用于定位問題
direction : 圖像方向,傳入?yún)?shù)時(shí)定義為true表示檢測(cè),0表示正向,1表示逆時(shí)針90度,2表示逆時(shí)針180度,3表示逆時(shí)針270度,-1表示未定義。
words_result_num : 識(shí)別的結(jié)果數(shù),即word_result的元素個(gè)數(shù)
word_result : 定義和識(shí)別元素?cái)?shù)組
words : 識(shí)別出的字符串
還有一些非必選字段大家可以去文檔里熟悉一下。
接下來,我們要做的,就是將我們之前爬取到的驗(yàn)證碼用剛介紹的OCR來識(shí)別,看看究竟能不能得到正確結(jié)果。
from?aip?import?AipOcr
import?os
i?=?0
j?=?0
APP_ID?=?'你的?APP_ID?'
API_KEY?=?'你的API_KEY'
SECRET_KEY?=?'你的SECRET_KEY'
client?=?AipOcr(APP_ID,?API_KEY,?SECRET_KEY)
#?讀取圖片?
file_path?=?'D:\******\驗(yàn)證碼圖片'
filenames?=?os.listdir(file_path)
#?print(filenames)
for?filename?in?filenames:
????#?將路徑與文件名結(jié)合起來就是每個(gè)文件的完整路徑
????info?=?os.path.join(file_path,filename)
????with?open(info,?'rb')?as?fp:
????????#?獲取文件夾的路徑????
????????image?=?fp.read()
????????#?調(diào)用通用文字識(shí)別,?圖片參數(shù)為本地圖片
????????result?=?client.basicGeneral(image)
????????#?定義參數(shù)變量??
????????options?=?{
????????????????'detect_direction'?:?'true',
????????????????'language_type'?:?'CHN_ENG',
????????}
????????#?調(diào)用通用文字識(shí)別接口??
????????result?=?client.basicGeneral(image,options)
????????#?print(result)
????????if?result['words_result_num']?==?0:
????????????print(filename?+?':'?+?'----')
????????????i?+=?1
????????else:
????????????for?word?in?result['words_result']:????????????????????
????????????????print(filename?+?'?:?'?+word['words'])
????????????????j?+=?1
print('共識(shí)別驗(yàn)證碼{}張'.format(i+j))
print('未識(shí)別出文本{}張'.format(i))
print('已識(shí)別出文本{}張'.format(j))
和識(shí)別圖片一樣,這里我們將文件夾驗(yàn)證碼圖片里的圖片全部讀取出來,依次讓OCR識(shí)別,并依據(jù)“word_result_num”字段判斷是否成功識(shí)別出文本,識(shí)別出文本則打印結(jié)果,未識(shí)別出來的用“----”代替,并結(jié)合文件名對(duì)應(yīng)識(shí)別結(jié)果 。最后統(tǒng)計(jì)識(shí)別結(jié)果數(shù)量,再來看下識(shí)別結(jié)果。
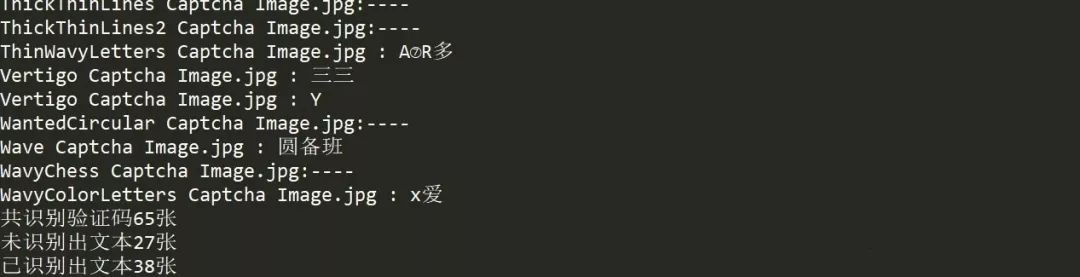
看到結(jié)果,只能說Amazing!60張圖片居然識(shí)別出了65張,并且還有27張為未識(shí)別出文本的,這不是我想要的結(jié)果~先來簡單看下問題出在哪里,看到“Vertigo Captcha Image.jpg"這張圖名出現(xiàn)了兩次,懷疑是在識(shí)別過程中由于被干擾,所以識(shí)別成兩行文字輸出了,這樣就很好解釋為什么多出來5張驗(yàn)證碼圖片了。可是!為什么會(huì)有這么多未識(shí)別出文本呢,而且英文數(shù)字組成的驗(yàn)證碼識(shí)別成中文了,看樣子,不對(duì)驗(yàn)證碼圖片進(jìn)行去干擾處理,僅靠OCR來識(shí)別的想法果然還是行不通啊。那么接下來我們便使用圖像處理的方法來重新識(shí)別驗(yàn)證碼吧。
還是介紹驗(yàn)證碼時(shí)用的這張圖


這張圖也沒能被識(shí)別出來,讓人頭禿。接下來就對(duì)這張圖片進(jìn)行一定處理,看能不能讓OCR正確識(shí)別
from?PIL?import?Image
filepath?=?'D:\******\驗(yàn)證碼圖片\AncientMosaic?Captcha?Image.jpg'
image?=?Image.open(filepath)
#?傳入'L'將圖片轉(zhuǎn)化為灰度圖像
image?=?image.convert('L')
#?傳入'1'將圖片進(jìn)行二值化處理
image?=?image.convert('1')
image.show()
這樣子轉(zhuǎn)化后再來看下圖片變成什么樣了?

確實(shí)有些不同了,趕緊拿去試試能不能識(shí)別,還是失敗了~~繼續(xù)修改
from?PIL?import?Image
filepath?=?'D:\******\驗(yàn)證碼圖片\AncientMosaic?Captcha?Image.bmp'
image?=?Image.open(filepath)
#?傳入'L'將圖片轉(zhuǎn)化為灰度圖像
image?=?image.convert('L')
#?傳入'l'將圖片進(jìn)行二值化處理,默認(rèn)二值化閾值為127
#?指定閾值進(jìn)行轉(zhuǎn)化
count=?170
table?=?[]
for?i?in?range(256):
????if?i?????????table.append(0)
????else:
????????table.append(1?)
image?=?image.point(table,'1')
image.show()
這里我將圖片保存成了bmp模式,然后指定二值化的閾值,不指定的話默認(rèn)為127,我們需要先轉(zhuǎn)化原圖為灰度圖像,不能直接在原圖上轉(zhuǎn)化。然后將構(gòu)成驗(yàn)證碼的所需像素添加到一個(gè)table中,然后再使用point方法構(gòu)建新的驗(yàn)證碼圖片。


現(xiàn)在已經(jīng)識(shí)別到文字了,雖然我不知道為啥識(shí)別成了“珍”,分析之后發(fā)現(xiàn)是因?yàn)閦我在設(shè)置參數(shù)設(shè)置了“l(fā)anguage_type”為“CHN_ENG”,中英文混合模式,于是我修改成“ENG”英文類型,發(fā)現(xiàn)可以識(shí)別成字符了,但依然沒有識(shí)別成功,嘗試其他我所知道的方法后,我表示很無語,我決定繼續(xù)嘗試PIL庫的其他方法試試。
#?找到邊緣
image?=?image.filter(ImageFilter.FIND_EDGES)
#?image.show()
#?邊緣增強(qiáng)
image?=?image.filter(ImageFilter.EDGE_ENHANCE)
image.show()

還是不能正確識(shí)別,我決定換個(gè)驗(yàn)證碼試試。。。。。。

我找了這張帶有陰影的
from?PIL?import?Image,ImageFilter
filepath?=?'D:\******\驗(yàn)證碼圖片\CrossShadow2?Captcha?Image.jpg'
image?=?Image.open(filepath)
#?傳入'L'將圖片轉(zhuǎn)化為灰度圖像
image?=?image.convert('L')
#?傳入'l'將圖片進(jìn)行二值化處理,默認(rèn)二值化閾值為127
#?指定閾值進(jìn)行轉(zhuǎn)化
count=?230
table?=?[]
for?i?in?range(256):
????if?i?????????table.append(1)
????else:
????????table.append(0)
image?=?image.point(table,'1')
image.show()
簡單處理后,得到這樣的圖片:

識(shí)別結(jié)果為:

識(shí)別成功了,老淚縱橫!!!看樣子百度OCR還是可以識(shí)別出驗(yàn)證碼的,不過識(shí)別率還是有點(diǎn)低,需要對(duì)圖像進(jìn)行一定處理,才能增加識(shí)別的準(zhǔn)確率。不過百度OCR對(duì)規(guī)范文本的識(shí)別還是很準(zhǔn)確的。
那么與其他驗(yàn)證碼相比,究竟是什么讓這個(gè)驗(yàn)證碼更容易被OCR讀懂呢?
字母沒有相互疊加在一起,在水平方向上也沒有彼此交叉。也就是說,可以在每一個(gè)字 母外面畫一個(gè)方框,而不會(huì)重疊在一起。
圖片沒有背景色、線條或其他對(duì) OCR 程序產(chǎn)生干擾的噪點(diǎn)。
白色背景色與深色字母之間的對(duì)比度很高。
這樣的驗(yàn)證碼相對(duì)識(shí)別起來較容易,另外,像識(shí)別圖片時(shí)的白底黑字就屬于很標(biāo)準(zhǔn)的規(guī)范文本了,所以識(shí)別的準(zhǔn)確度較高。至于更復(fù)雜的圖形驗(yàn)證碼,就需要更深的圖像處理技術(shù)或者訓(xùn)練好的OCR來完成了,如果只是簡單識(shí)別一個(gè)驗(yàn)證碼的話,不如人工查看圖片輸入,更多一點(diǎn)的話,也可以交給打碼平臺(tái)來識(shí)別。
作者丨HDMI
https://www.zhihu.com/people/hdmi-blog/activities
END
若覺得文章對(duì)你有幫助,隨手轉(zhuǎn)發(fā)分享,也是我們繼續(xù)更新的動(dòng)力。
長按二維碼,掃掃關(guān)注哦
?「C語言中文網(wǎng)」官方公眾號(hào),關(guān)注手機(jī)閱讀教程??
推薦關(guān)注

關(guān)注公號(hào)
【Python開發(fā)與大數(shù)據(jù)人工智能】
因?yàn)殛P(guān)注后即可得算法小白資料大全

點(diǎn)擊“閱讀原文”,領(lǐng)取 2020 年最新免費(fèi)技術(shù)資料大全