
服務(wù)器性能優(yōu)化的正確姿勢(好文推薦)
導(dǎo)言:運維工作中除了要維持平臺的穩(wěn)定運行以外,還得對服務(wù)器的性能進(jìn)行優(yōu)化,讓服務(wù)器發(fā)揮出良好的工作性能是穩(wěn)定運行的基礎(chǔ)。騰訊互娛DBA團(tuán)隊的汪偉(simon)在這一領(lǐng)域里整理出了一套性能優(yōu)化的資料為大家在性能優(yōu)化提供充足的方向。概述
什么是性能?
性能最通俗的衡量指標(biāo)就是“時間”,CPU的使用率指的是CPU用于計算的時間占比,磁盤使用率指的是磁盤操作的時間占比。
當(dāng)CPU使用率100%時,意味著有部分請求來不及計算,響應(yīng)時間增加或者超時;
當(dāng)磁盤使用率100%時,意味著有部分請求需要等待IO操作,響應(yīng)時間也會增加或者超時。
換言之,所有的操作都在理想的時間內(nèi),就不存在“性能優(yōu)化“的問題。我們在分析性能的時候,總是會首先要找到是什么引起響應(yīng)時間變慢了,對應(yīng)單機性能的分析,一般我們會將目光鎖定在CPU和IO上,因為對于應(yīng)用程序一般分為CPU bound型和IO。
bound型,即計算密集型或者讀寫密集型;至于內(nèi)存,其性能因素往往也會反映到CPU或者IO上,因為內(nèi)存的設(shè)計初衷就是提高內(nèi)核指令和應(yīng)用程序的讀寫性能。
當(dāng)內(nèi)存不足,系統(tǒng)可能進(jìn)行大量的交換操作,這時候磁盤可能成為瓶頸;而缺頁、內(nèi)存分配、釋放、復(fù)制、內(nèi)存地址空間映射等等問題又可能引起CPU的瓶頸;更嚴(yán)重的情況是直接影響功能,這個就不僅僅是性能的問題了。
性能優(yōu)化并不是一個孤立的課題,除了響應(yīng)時間的考慮,我們往往還需要綜合功能完整性、安全性等等方面的問題。
性能分析的基礎(chǔ)
性能優(yōu)化需要厚實的基礎(chǔ)知識:
操作系統(tǒng)
操作系統(tǒng)管理著應(yīng)用程序所需要的所有資源,例如CPU和IO,當(dāng)任何一個組件出現(xiàn)問題,我們的分析也是基于操作系統(tǒng)的,例如文件系統(tǒng)類型,磁盤類型,磁盤raid類型都需要操作系統(tǒng)管理和支持。系統(tǒng)編程技術(shù)
系統(tǒng)編程技術(shù)涉及到我們?nèi)绾问褂孟到y(tǒng)資源,例如對IO的操作我們可以使用buffering I/O,也可以使用Direct IO,可以采用同步的方式,也可以采用異步的方式,可以使用多進(jìn)程,也可以使用多線程的方式。懂得不同編程技術(shù)的原理,有利于問題的分析。應(yīng)用程序
例如數(shù)據(jù)庫組件的數(shù)據(jù)類型、引擎、索引、復(fù)制、配置參數(shù)、備份、高可用等等都可能是性能問題的元兇。
性能分析的方法論
問題分析方面,各類方法論如金字塔思維、5W2H、麥肯錫七步法等等。套用5W2H方法,可以提出性能分析的幾個問題
What-現(xiàn)象的表現(xiàn)是什么樣的
When-什么時候發(fā)生
Why-為什么會發(fā)生
Where-哪個地方發(fā)生的問題
How much-耗費了多少資源,問題解決后能減少多少資源耗用
How to do-怎么解決問題
但是這些只能給出方向,性能分析需要找到原因需要更具體的方法,怎么解決一個問題也需要更加具體的方式。
Brendan Gregg在《性能之巔:洞悉系統(tǒng)、企業(yè)與云計算》第二章中講到大量的方法,比較突出的如Use方法、負(fù)載特征歸納、性能監(jiān)控、靜態(tài)性能調(diào)優(yōu)、延時分析、工具法等等。
其中工具法最具體,但是工具法也有自己的限制,如磁盤的飽和度,在磁盤使用率100%的時候,磁盤的負(fù)載可能還可以繼續(xù)增加。在實際分析問題中,負(fù)載特征歸納更有指導(dǎo)意義,靜態(tài)跟蹤和動態(tài)跟蹤讓我們更容易更直觀發(fā)現(xiàn)問題。
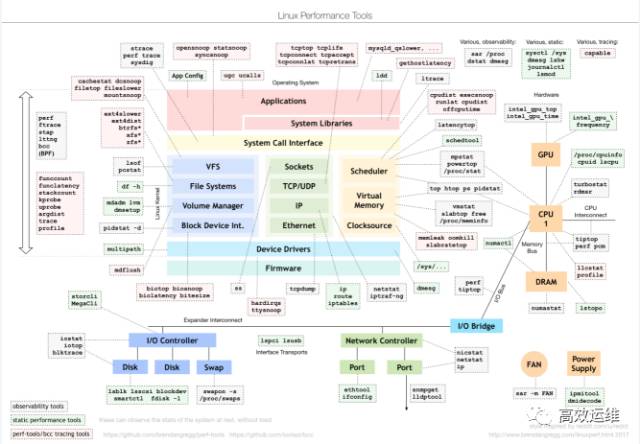
CPU
認(rèn)識CPU
CPU本身的架構(gòu)和內(nèi)核調(diào)度器的架構(gòu)這里不做詳細(xì)講述,具體可以參考操作系統(tǒng)類書籍。但是仍然需要清楚一些概念:
處理器
核
硬件線程
CPU內(nèi)存緩存
時鐘頻率
每指令周期數(shù)CPI和每周期指令數(shù)IPC
CPU指令
使用率
用戶時間/內(nèi)核時間
調(diào)度器
運行隊列
搶占
多進(jìn)程
多線程
字長
針對應(yīng)用程序,我們通常關(guān)注的是內(nèi)核CPU調(diào)度器功能和性能
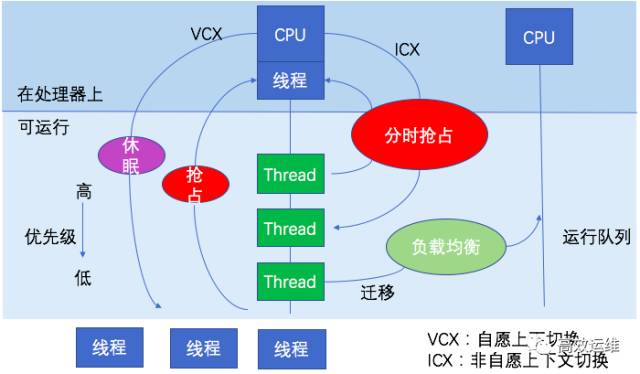
線程的狀態(tài)分析主要是分析線程的時間用在什么地方,而線程狀態(tài)的分類一般分為:
on-CPU:執(zhí)行中,執(zhí)行中的時間通常又分為用戶態(tài)時間user和系統(tǒng)態(tài)時間sys。
off-CPU:等待下一輪上CPU,或者等待I/O、鎖、換頁等等,其狀態(tài)可以細(xì)分為可執(zhí)行、匿名換頁、睡眠、鎖、空閑等狀態(tài)。
如果大量時間花在CPU上,對CPU的剖析能夠迅速解釋原因;如果系統(tǒng)時間大量處于off-cpu狀態(tài),定位問題就會費時很多。
分析方法與工具
在觀察CPU性能的時候,按照負(fù)載特征歸納的方法,可以檢查如下清單:
整個系統(tǒng)范圍內(nèi)的CPU負(fù)載如何,CPU使用率如何,單個CPU的使用率呢?
CPU負(fù)載的并發(fā)程度如何?是單線程嗎?有多少線程?
哪個應(yīng)用程序在使用CPU,使用了多少?
哪個內(nèi)核線程在使用CPU,使用了多少?
中斷的CPU用量有多少?
用戶空間和內(nèi)核空間使用CPU的調(diào)用路徑是什么樣的?
遇到了什么類型的停滯周期?
要回答上面的問題,使用系統(tǒng)性能分析工具最經(jīng)濟(jì)和直接,這里列舉的工具足夠回答上面的問題:
| 工具 | 描述 |
|---|---|
| uptime | 平均負(fù)載 |
| vmstat | 包括系統(tǒng)范圍的CPU平均負(fù)載 |
| top | 監(jiān)控每個進(jìn)程/線程CPU用量 |
| pidstat | 每個進(jìn)程/線程CPU用量分解 |
| ps | 進(jìn)程狀態(tài) |
| perf | CPU剖析和跟蹤,性能計數(shù)器分析 |
上述問題中,調(diào)用路徑和停滯周期的分析可以使用perf工具,也可以使用DTrace等更靈活的工具。
其中perf支持對各類內(nèi)核時間的跟蹤計數(shù)統(tǒng)計,可以使用perf list查看。例如停滯周期分析可能十分復(fù)雜,需要對CPU和調(diào)度器架構(gòu)有較系統(tǒng)的認(rèn)識和了解。
停滯的周期可能發(fā)生在一級、二級或者三級緩存,如緩存未命中,也可能是內(nèi)存IO和資源IO上的停滯周期,perf中有諸如L1-dcahce-loads,L1-icache-loads等事件的計數(shù)統(tǒng)計。
實際案例
火焰圖幫助分析CPU的調(diào)用路徑
我們在壓測mysql在某機型上的非原地更新性能時,分析mysql服務(wù)器延時情況時,分析了CPU上主要的函數(shù)調(diào)用。
使用perf top能夠看到調(diào)用次數(shù)的排名,但是調(diào)用關(guān)系不能展示出來。火焰圖很清晰地提供了調(diào)用關(guān)系的視圖(如下兩圖中的比例不同是因為perf top加了-p參數(shù),火焰圖分析是針對整個系統(tǒng))。

內(nèi)存
認(rèn)識內(nèi)存
如前所述,內(nèi)存是為提高效率而生,實際分析問題的時候,內(nèi)存出現(xiàn)問題可能不只是影響性能,而是影響服務(wù)或者引起其他問題。同樣對于內(nèi)存有些概念需要清楚:
主存
虛擬內(nèi)存
常駐內(nèi)存
地址空間
OOM
頁緩存
缺頁
換頁
交換空間
交換
用戶分配器libc、glibc、libmalloc和mtmalloc
LINUX內(nèi)核級SLUB分配器
分析方法與工具
Brendan在書中給出了一些問題,比如內(nèi)存總線的平衡性,NUMA系統(tǒng)中,內(nèi)存是否被分配到合適的節(jié)點中去等等,這些問題在實際分析問題的時候,并不能作為切入點,需要持續(xù)的分析。因此筆者簡化為如下清單:
系統(tǒng)范圍內(nèi)的物理內(nèi)存和虛擬內(nèi)存使用率
換頁、交換、oom的情況
內(nèi)核和文件系統(tǒng)緩存的使用情況
進(jìn)程的內(nèi)存用于何處
進(jìn)程為何分配內(nèi)存
內(nèi)核為何分配內(nèi)存
哪些進(jìn)程在持續(xù)地交換
進(jìn)程或者內(nèi)存是否存在內(nèi)存泄漏?
內(nèi)存的分析工具如下:
| 工具 | 描述 |
|---|---|
| free | 緩存容量統(tǒng)計信息 |
| vmstat | 虛擬內(nèi)存統(tǒng)計信息 |
| top | 監(jiān)視每個進(jìn)程的內(nèi)存使用情況 |
| ps | 進(jìn)程狀態(tài) |
| Dtrace | 分配跟蹤 |
除了DTrace,所有的工具只能回答信息統(tǒng)計,進(jìn)程的內(nèi)存使用情況等等,至于是否發(fā)生內(nèi)存泄漏等,只能通過分配跟蹤。
但是DTrace需要對內(nèi)核函數(shù)有很深入的了解,通過D語言編寫腳本完成跟蹤。Perf也有一些諸如cache-miss、page-faults的事件用于跟蹤,但是并不直觀。
實際案例
關(guān)于內(nèi)存泄漏,從監(jiān)控和頂層觀察很難發(fā)現(xiàn)問題,一般都是從底層程序代碼來分析,案例中使用各種觀察工具和跟蹤工具都不能很確定原因所在,只能通過分析代碼來排查問題。
最終發(fā)現(xiàn)是lua腳本語言分配內(nèi)存速度快,包驅(qū)動的周期性服務(wù)的用法中,lua自動回收不能迅速釋放內(nèi)存,而是集中回收,如果頻繁回收又可能帶來CPU的壓力。開發(fā)項目組最后采用的解決方式為分步回收,每次回收一部分內(nèi)存,然后周期性全量回收。
IO
邏輯IO vs 物理IO
通常在討論問題時,總是會分析IO的負(fù)載,IO的負(fù)載通常指的是磁盤IO,也就是物理IO,例如我們使用iostat獲取的avgqu-sz、svctm和until等指標(biāo)。
因為我們的讀寫最終都是來自或者去往磁盤的,關(guān)注磁盤的IO情況非常正確。但是我們在進(jìn)行讀寫操作的時候,面向的對象大多數(shù)時候并不會直接面向磁盤,而是面向文件系統(tǒng)的,除非使用raw io的方式。
如下圖為通用的IO結(jié)構(gòu)圖,如果你想了解更詳細(xì),可以查看第二張圖片。我們知道LINUX通過文件系統(tǒng)將所有的硬件設(shè)備甚至網(wǎng)絡(luò)都抽象為文件來管理, 例如read()調(diào)用時,實際就是就是調(diào)用了vfs_read函數(shù),文件系統(tǒng)會確認(rèn)請求的數(shù)據(jù)是否在頁緩存中,如果不在內(nèi)存中,于是將請求發(fā)送到塊設(shè)備;
此時內(nèi)核會先獲取到數(shù)據(jù)在物理設(shè)備上的實際位置,然后將讀請求發(fā)送給塊設(shè)備的請求隊列中,IO調(diào)度器會通過一定的調(diào)度算法,將請求發(fā)送給磁盤設(shè)備驅(qū)動層,執(zhí)行真正的讀操作。
在這一過程中可能發(fā)生哪些情況呢?如果應(yīng)用程序執(zhí)行的是大量的順序讀會怎樣?隨機讀又會怎樣?如果是順序讀,正確的做法就是進(jìn)行預(yù)讀,讓請求的數(shù)據(jù)落到內(nèi)存中,提升讀效率。所以在應(yīng)用程序發(fā)起一次讀,從文件系統(tǒng)到磁盤的過程中,存在讀放大的問題。
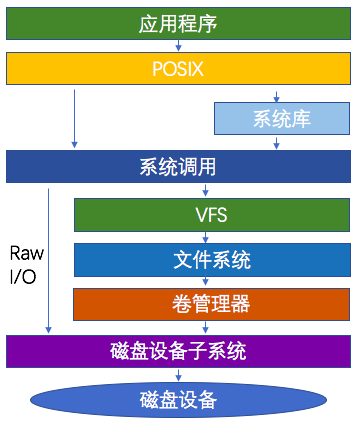
在寫操作時同樣存在類似的情況,應(yīng)用程序發(fā)起對文件系統(tǒng)的IO操作,物理IO與應(yīng)用程序之間,有時候會顯得無關(guān)、間接、放大或者縮小。
無關(guān):
其他的應(yīng)用程序:磁盤IO來自其他的應(yīng)用程序,如監(jiān)控,agent等
其他用戶:如同虛擬機母機下的其他用戶
其他內(nèi)核任務(wù):如重建raid,校驗等
間接:
文件系統(tǒng)預(yù)讀:增加額外的IO,但是可能預(yù)讀的數(shù)據(jù)無用
文件系統(tǒng)緩沖:寫緩存推遲或者合并回寫磁盤,造成磁盤瞬時IO壓力
放大:
文件系統(tǒng)元數(shù)據(jù):增大額外的IO
文件系統(tǒng)記錄尺寸:向上對齊等增加了IO大小
縮小:
文件系統(tǒng)緩存:直接讀取緩存,而不需要操作磁盤
合并:一次性回寫磁盤
文件系統(tǒng)抵消:同一地址更新多次,回寫磁盤時只保留最后一次修改
壓縮:減少數(shù)據(jù)量
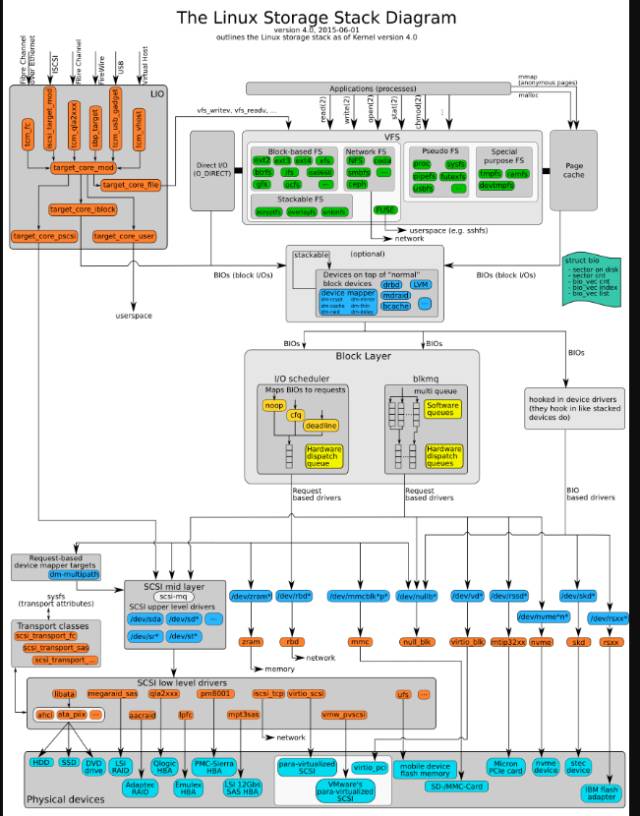
圖片來源:
https://www.thomas-krenn.com/de/wikiDE/images/b/ba/Linux-storage-stack-diagram_v4.0.png
文件系統(tǒng)分析與工具
與文件系統(tǒng)相關(guān)的術(shù)語如下:
文件系統(tǒng)
VFS
文件系統(tǒng)緩存
頁緩存page cache
緩沖區(qū)高速緩存buffer cache
目錄緩存
inode
inode緩存
如下圖為文件系統(tǒng)緩存的結(jié)構(gòu)圖,頁緩存緩存了虛擬內(nèi)存的頁面,包括文件系統(tǒng)的頁面,提升了文件和目錄的性能。Linux將緩沖區(qū)高速緩存放入到了頁緩存中,即page cache包含buffer cache。
文件系統(tǒng)使用的內(nèi)存臟頁由內(nèi)核線程寫回磁盤,如圖中的頁面掃描器kswapd為后臺的頁面換出進(jìn)程,當(dāng)內(nèi)存不足,超過一定時間(30s)或者有過多的臟頁時都會觸發(fā)磁盤回寫。
文件系統(tǒng)延時指的是一個文件系統(tǒng)邏輯請求從開始到結(jié)束的時間,包括在文件系統(tǒng)、內(nèi)核磁盤IO子系統(tǒng)以及等待磁盤設(shè)備響應(yīng)的時間。同步訪問時,應(yīng)用程序會在請求時阻塞,等待文件系統(tǒng)請求結(jié)束,異步方式下,文件系統(tǒng)對其并無直接影響。
但是異步訪問也分select、poll、epoll等方式,也就是所謂的異步阻塞、異步非阻塞。在異步方式下,一般是打印出用戶層發(fā)起文件系統(tǒng)邏輯IO的調(diào)用棧,得到調(diào)用了哪個函數(shù)產(chǎn)生了IO。
Linux未提供查看文件系統(tǒng)延時的工具和接口,但是磁盤的指標(biāo)信息卻比較豐富,但是很多情況下,文件系統(tǒng)IO和磁盤IO之間并沒有直接關(guān)系,例如應(yīng)用程序?qū)懳募到y(tǒng)。
但是根本不關(guān)心數(shù)據(jù)什么時候?qū)懙酱疟P了,而后臺刷數(shù)據(jù)到磁盤時,可能造成磁盤IO負(fù)載增加,從磁盤角度,應(yīng)用程序的寫入可能受到影響了,而實際上應(yīng)用程序并沒有等待。
文件系統(tǒng)的分析可以試著回答下面的問題:
哪個應(yīng)用程序在使用文件系統(tǒng)?
在對哪些文件進(jìn)行操作?
在進(jìn)行什么樣的操作,讀寫比是多少,同步還是異步?
文件系統(tǒng)的緩存有多大,目前的使用情況?
有遇到什么錯誤嗎?是請求不合法,還是文件系統(tǒng)自身的問題?
其實上面的問題,除了能夠看到系統(tǒng)的內(nèi)存情況,頁緩存和buffer cache大小,能夠看到哪些進(jìn)程在進(jìn)行讀寫操作,在讀哪些文件,其他的比如應(yīng)用程序?qū)ξ募到y(tǒng)的讀寫比,同步還是異步,這些問題沒有工具能給出明確的信息。當(dāng)然我們可以通過跟蹤應(yīng)用程序的內(nèi)核調(diào)用棧來發(fā)現(xiàn)問題,也可以在應(yīng)用程序中輸出日志來幫助分析。
磁盤分析與工具
在理解磁盤IO之前,同樣我們需要理解一些概念,例如:
虛擬磁盤
扇區(qū)
I/O請求
磁盤命令
帶寬
吞吐
I/O延時
服務(wù)時間
等待時間
隨機IO/連續(xù)IO
同步/異步
磁盤接口
Raid
對于磁盤IO,我們可以列出如下等問題來幫助我們分析性能問題:
每塊磁盤的使用率是多少?
每塊磁盤上有多長等待隊列?
平均服務(wù)時間和等待時間時多少?
是哪個應(yīng)用程序或者用戶正在使用磁盤?
應(yīng)用程序讀寫的方式是怎樣的?
為什么會發(fā)起磁盤IO,內(nèi)核調(diào)用路徑是什么樣的?
磁盤上的讀寫比是多少?
隨機IO還是順序IO?
Linux對磁盤的性能分析工具主要如下:
| 工具 | 描述 |
|---|---|
| iostat | 各種單個磁盤統(tǒng)計信息 |
| iotop、pidstat | 按進(jìn)程列出磁盤IO的使用情況 |
| perf、Dtrace | 跟蹤工具 |
磁盤上是隨機IO還是順序IO,很多時候我們并沒有很好的方式去判斷,因為塊設(shè)備回寫磁盤的時候,隨機IO可能已經(jīng)被整理為順序IO了。對于磁盤的分析同樣可以使用perf跟蹤事件或者DTrace設(shè)置探針。
在分析mysql在某機型上做非全cache非原地更新時,為什么單實例無法將機器性能壓滿的時候,我們在分析的過程中跟蹤了塊設(shè)備的內(nèi)核事件。我們對比了多實例非原地更新和單實例非原地更新的時候,磁盤的操作情況。如下為非原地更新時跟蹤的結(jié)果。
對結(jié)果分析后看到,單實例非原地更新時,將近30%是blk_finish_plug,有70%是blk_queue_bio,而多實例時正好相反,大量的blk_finish_plug和少量的blk_queue_bio(當(dāng)然,這不是為什么性能壓不滿的原因)。
參考文獻(xiàn)
Brendan Gregg《性能之巔:洞悉系統(tǒng)、企業(yè)與云計算》
http://www.brendangregg.com
Robert Love《Linux Kernel Development》