
MySQL是如何保證不丟失數(shù)據(jù)的呢?
微信公眾號:歡少的成長之路
介紹
大家好,我是Leo,從事Java后端開發(fā)。之前的文章大概介紹了WAL機制,如果不太清楚的小伙伴下面第一部分我們可以再回顧一下。今天這里主要介紹一下WAL的安全性這一塊。

寫作思路
根據(jù)讀者與朋友的反饋,所以從這篇文章開始我會加一個寫作的思路。可以先讓讀者了解到學完這一篇下來之后能收獲到哪些知識,以防看了半個小時最后啥也沒學到,這樣的確挺氣人的。
步入正題
binlog 寫入機制
binlog寫入日志這個是比較簡單的。提到binlog,必然提到binlog cache。那么binlog cache是什么?
我們有必要了解一些前提知識,再學習binlog。會的人可以跳過這段,照顧一下不懂的朋友。
binlog cache是一個二進制日志文件的緩沖區(qū),他是由一個參數(shù) binlog_cache_size 控制大小的緩沖區(qū)。
一個事務(wù)在執(zhí)行是時候是不允許被拆開的,因此無論事務(wù)多大,都是要一次性保存執(zhí)行的。那么這個就涉及到了binlog cache 的保存問題。如果所占的內(nèi)存大小超過了這個binlog_cache_size 參數(shù)的設(shè)定。就會采用暫存到磁盤。事務(wù)在提交的時候,會先把binlog cache里的數(shù)據(jù)寫入到binlog中,并清空binlog cache數(shù)據(jù)。
如下圖,我們可以從圖中了解一下。
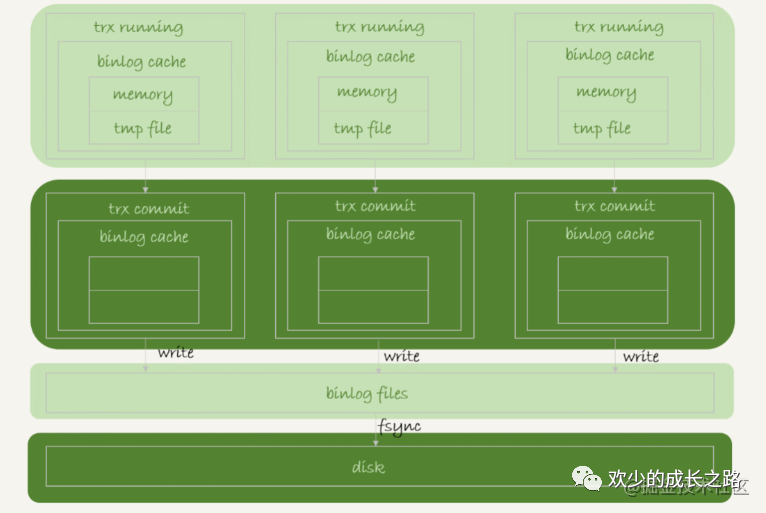
每個binlog_cache是由單獨的一個線程享有的。也就是說多個線程帶著多個binlog_cache去進入write操作的時候是寫入到一個binlog 文件的。效率是非常快的,因為并沒有涉及到磁盤IO的開銷。
當進行到了fsync的時候,才是將數(shù)據(jù)持久化到磁盤操作。這個時候才會占用磁盤IO,也就是我們常說的IOPS。
我們我們可以深入討論一個問題,什么時候進行write,什么時候需要fsync操作呢?

下面我們介紹一下write與fsync的時機。
int sync_binlog=0;
if(sync_binlog==0){
每次提交事務(wù)都只 write,不 fsync
}
if(sync_binlog==1){
每次提交事務(wù)都會執(zhí)行 fsync
}
if(sync_binlog>1){
每次提交事務(wù)都 write,但累積 N 個事務(wù)后才 fsync。
}

因此,在出現(xiàn) IO 瓶頸的場景里,將 sync_binlog 設(shè)置成一個比較大的值,可以提升性能。在實際的業(yè)務(wù)場景中,考慮到丟失日志量的可控性,一般不建議將這個參數(shù)設(shè)成 0,比較常見的是將其設(shè)置為 100~1000 中的某個數(shù)值。
但是,將 sync_binlog 設(shè)置為 N,對應(yīng)的風險是:如果主機發(fā)生異常重啟,會丟失最近 N 個事務(wù)的 binlog 日志。
擴展:上面我們介紹了通過binlog_cahe_size 控制一個參數(shù)的大小。進行磁盤與內(nèi)存緩存區(qū)的抉擇。那么還有哪些參數(shù)是控制這一類問題的。你能想到幾個?
下面我們延伸介紹一下sort_buffer_size ,從前幾篇文章中引用的一段。詳細的可以去order by那篇文章回顧一下。

binlog 寫入機制大概就是這樣了,以后技術(shù)的進步優(yōu)化會再完善的。有不對的地方也可以加以指出!互相探討學習!
redo log 寫入機制
還是老樣子吧。我感覺MySQL的設(shè)計很多地方都很相像。比如change buffer,binlog cache都是一些緩存區(qū),內(nèi)存臨時存放的地方。那么redolog的緩沖區(qū)是什么呢? redo log buffer
我們可以先介紹一下 redo log buffer
redo log buffer 要做的是一個事務(wù)在插入一條數(shù)據(jù)的時候,需要先寫入日志。但是又不能在還沒有提交事務(wù)的時候直接寫到redo log文件中。這個日志的臨時存放處就是redo log buffer。真正在寫入redo log文件的過程是在commit這一步完成的。
這里是開啟一個事務(wù)下執(zhí)行的。如果我們只執(zhí)行一條insert 語句它又是如何實現(xiàn)的呢?
單獨執(zhí)行一個更新語句的時候,InnoDB 會自己啟動一個事務(wù),在語句執(zhí)行完成的時候提交。過程跟上面是一樣的,只不過是“壓縮”到了一個語句里面完成。

上面我們說了 buffer是他的一個臨時緩存區(qū),那么 是不是所有buffe都要持久化到磁盤呢?
不需要 如果事務(wù)執(zhí)行期間 MySQL 發(fā)生異常重啟,那這部分日志就丟了。由于事務(wù)并沒有提交,所以這時日志丟了也不會有損失。
那么事務(wù)還沒提交的時候,redo log buffer 中的部分日志有沒有可能被持久化到磁盤呢?
確實會有。這個問題,要從 redo log 可能存在的三種狀態(tài)說起 如下圖
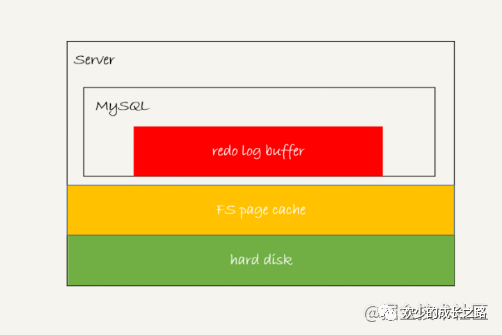
redo log buffer:物理上這是MySQL的進程內(nèi)存
FS page cache:寫入到磁盤,但是還沒有進行持久化。物理上是page cache文件系統(tǒng)。
hard disk,這個就是持久化到磁盤了。
圖中的紅色區(qū)域是內(nèi)存操作,不涉及到磁盤IO。所以性能的非常快的。write也是非常快的,也就是圖中的黃色部分。fsync的速度就慢了很多。因為持久化到磁盤。

MySQL沒那么簡單,這里的redo log是有一個寫入策略的。我們下面介紹一下策略與案例。
寫入策略這個就涉及到了一個參數(shù)innodb_flush_log_at_trx_commit 這個參數(shù)控制寫入redo log,寫入到磁盤的走向。為了提供更好的性能保障!
設(shè)置為 0 的時候,表示每次事務(wù)提交時都只是把 redo log 留在 redo log buffer 中 ;
設(shè)置為 1 的時候,表示每次事務(wù)提交時都將 redo log 直接持久化到磁盤;
設(shè)置為 2 的時候,表示每次事務(wù)提交時都只是把 redo log 寫到 page cache。
InnoDB 有一個后臺線程,每隔 1 秒,就會把 redo log buffer 中的日志,調(diào)用 write 寫到文件系統(tǒng)的 page cache,然后調(diào)用 fsync 持久化到磁盤。

下面我們可以細想一下,redo log buffer幫redo log解決了那么大 的一個難題。那么redo log buffer又是絕對的安全或者說絕對的性能嗎?
如果我事務(wù)正在執(zhí)行,還沒有提交。那么MySQL肯定會把數(shù)據(jù)從redo log寫入到redo log buffer!上面我們介紹了每隔一秒會把redo log buffer里的數(shù)據(jù)做一邊寫入。那么有沒有可能事務(wù)沒執(zhí)行完,可能已經(jīng)寫盤了呢?
答案是肯定的。下面我們介紹一下redo log buffer的刷新策略
控制這個策略的參數(shù)是innodb_log_buffer_size
redo log buffer 占用的空間即將達到 innodb_log_buffer_size 一半的時候,后臺線程會主動寫盤。
(注意,由于這個事務(wù)并沒有提交,所以這個寫盤動作只是 write,而沒有調(diào)用 fsync,也就是只留在了文件系統(tǒng)的 page cache。)
另一種是,并行的事務(wù)提交的時候,順帶將這個事務(wù)的 redo log buffer 持久化到磁盤
(假設(shè)一個事務(wù) A 執(zhí)行到一半,已經(jīng)寫了一些 redo log 到 buffer 中,這時候有另外一個線程的事務(wù) B 提交,如果 innodb_flush_log_at_trx_commit 設(shè)置的是 1,那么按照這個參數(shù)的邏輯,事務(wù) B 要把 redo log buffer 里的日志全部持久化到磁盤。這時候,就會帶上事務(wù) A 在 redo log buffer 里的日志一起持久化到磁盤。)
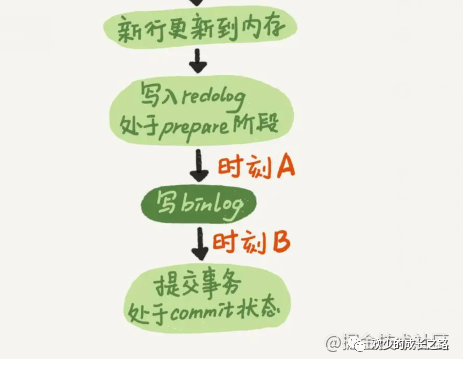
說明: 如上圖所示, 在做兩階段提交的時候會有一個prepare。先寫入redolog處于prepare階段。再寫binlog。最后再commit。
假設(shè): 如果innodb_log_buffer_size 設(shè)置成1,那么redo log在prepare就要持久化一次,因為有一個崩潰恢復的邏輯還要依賴prepare的redo log,再加上binlog來恢復。
每秒一次后臺輪詢刷盤,再加上崩潰恢復這個邏輯,InnoDB 就認為 redo log 在 commit 的時候就不需要 fsync 了,只會 write 到文件系統(tǒng)的 page cache 中就夠了。
通常我們說 MySQL 的“雙 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都設(shè)置成 1。也就是說,一個事務(wù)完整提交前,需要等待兩次刷盤,一次是 redo log(prepare 階段),一次是 binlog。

還遠遠不止這些,有些時候我們聽說大廠的TPS每秒兩萬。也就是說每秒就會寫四萬次磁盤。但是,我用工具測試出來,磁盤能力也就兩萬左右,怎么能實現(xiàn)兩萬的 TPS? 組提交機制

雖然是最后一個模塊,不過還是少不了概念!
這里,先介紹日志邏輯序列號(log sequence number,LSN)的概念。LSN 是單調(diào)遞增的,用來對應(yīng) redo log 的一個個寫入點。每次寫入長度為 length 的 redo log, LSN 的值就會加上 length。LSN 也會寫到 InnoDB 的數(shù)據(jù)頁中,來確保數(shù)據(jù)頁不會被多次執(zhí)行重復的 redo log。
后續(xù)會介紹一下lsn,redo log,checkpoint他們?nèi)叩膮^(qū)別。checkpoint這個還沒忘記吧。就是前面介紹的刷內(nèi)存的時候利用的就是這個checkpoint。redo log和LSN就是正在介紹的。
如下圖所示,trx1,trx2,trx3三個并發(fā)事務(wù)在prepare階段,都寫完了redo log buffer持久化到磁盤的過程。
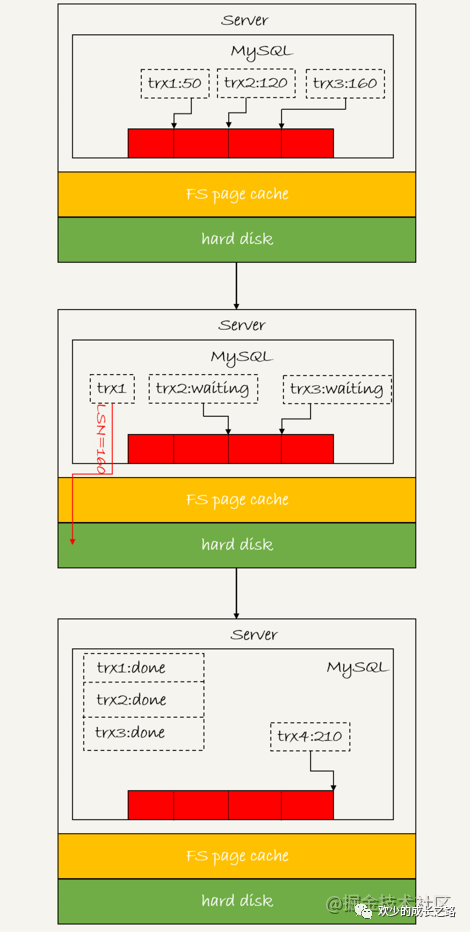
由圖中可以得知
trx1是最先到達的,會被選為這組的leader。
等 trx1 要開始寫盤的時候,這個組里面已經(jīng)有了三個事務(wù),這時候 LSN 也變成了 160;
trx1 去寫盤的時候,帶的就是 LSN=160,因此等 trx1 返回時,所有 LSN 小于等于 160 的 redo log,都已經(jīng)被持久化到磁盤;
這時候 trx2 和 trx3 就可以直接返回了。
所以,一次組提交里面,組員越多,節(jié)約磁盤 IOPS 的效果越好。但如果只有單線程壓測,那就只能老老實實地一個事務(wù)對應(yīng)一次持久化操作了。
在并發(fā)更新場景下,第一個事務(wù)寫完 redo log buffer 以后,接下來這個 fsync 越晚調(diào)用,組員可能越多,節(jié)約 IOPS 的效果就越好。
優(yōu)化:
為了提升MySQL的性能,一般會選擇在這個地方進行延遲,因為這樣可以用節(jié)省更多的IOPS。
我們借助上文的兩階段提交的圖!這里把寫binlog日志這一過程分成了兩步。
先把 binlog 從 binlog cache 中寫到磁盤上的 binlog 文件;
調(diào)用 fsync 持久化。
根據(jù)這里的優(yōu)化改一下。MySQL為了讓組提交效果更好如下圖。
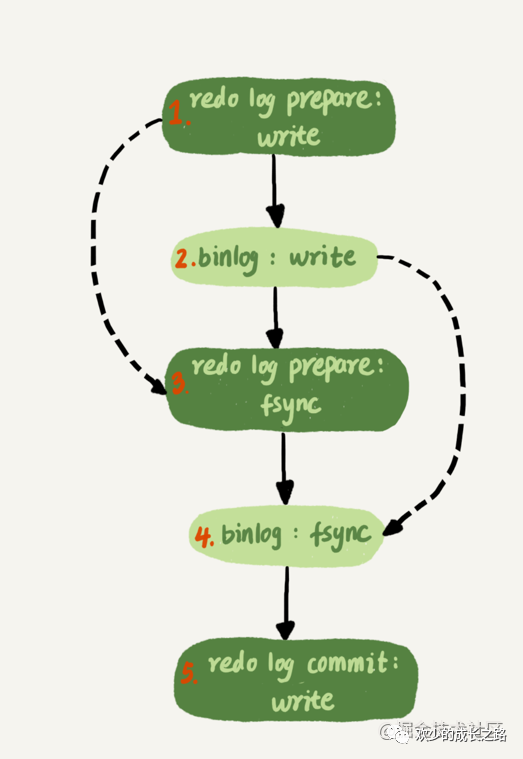
這么一來,binlog也可以組提交了。為什么這么說呢。可以看上圖的第二步。如果多個事務(wù)都已經(jīng)write了(也就是說寫入到redo log buffer了),再到第四步的時候就可以一起持久化到磁盤了。不是提升IOPS嘛的這個優(yōu)化過程嘛!
不過通常情況下第 3 步執(zhí)行得會很快,所以 binlog 的 write 和 fsync 間的間隔時間短,導致能集合到一起持久化的 binlog 比較少,因此 binlog 的組提交的效果通常不如 redo log 的效果那么好。
如果你想提升 binlog 組提交的效果,可以通過設(shè)置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 來實現(xiàn)。這兩個只要有一個滿足條件就會調(diào)用 fsync。
binlog_group_commit_sync_delay 參數(shù),表示延遲多少微秒后才調(diào)用 fsync;
binlog_group_commit_sync_no_delay_count 參數(shù),表示累積多少次以后才調(diào)用 fsync。
所以,當 binlog_group_commit_sync_delay 設(shè)置為 0 的時候,binlog_group_commit_sync_no_delay_count 也無效了。

回到上文的WAL機制那里我們繼續(xù)討論一下。WAL機制主要得以于兩方面
redo log 和 binlog 都是順序?qū)懀疟P的順序?qū)懕入S機寫速度要快;
組提交機制,可以大幅度降低磁盤的 IOPS 消耗。
實戰(zhàn)案例
如果你的 MySQL 現(xiàn)在出現(xiàn)了IO性能瓶頸,可以通過哪些方法來提升性能呢?

設(shè)置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 參數(shù),減少 binlog 的寫盤次數(shù)。這個方法是基于“額外的故意等待”來實現(xiàn)的,因此可能會增加語句的響應(yīng)時間,但沒有丟失數(shù)據(jù)的風險。
將 sync_binlog 設(shè)置為大于 1 的值(比較常見是 100~1000)。這樣做的風險是,主機掉電時會丟 binlog 日志。
將 innodb_flush_log_at_trx_commit 設(shè)置為 2。這樣做的風險是,主機掉電的時候會丟數(shù)據(jù)。
我不建議你把 innodb_flush_log_at_trx_commit 設(shè)置成 0。因為把這個參數(shù)設(shè)置成 0,表示 redo log 只保存在內(nèi)存中,這樣的話 MySQL 本身異常重啟也會丟數(shù)據(jù),風險太大。而 redo log 寫到文件系統(tǒng)的 page cache 的速度也是很快的,所以將這個參數(shù)設(shè)置成 2 跟設(shè)置成 0 其實性能差不多,但這樣做 MySQL 異常重啟時就不會丟數(shù)據(jù)了,相比之下風險會更小。
總結(jié)
今天我們已經(jīng)介紹完了兩大日志的寫入機制。以及日志的兩階段提交的優(yōu)缺點。組提交機制的流程與性能