
【NLP】圖解Transformer(完整版)
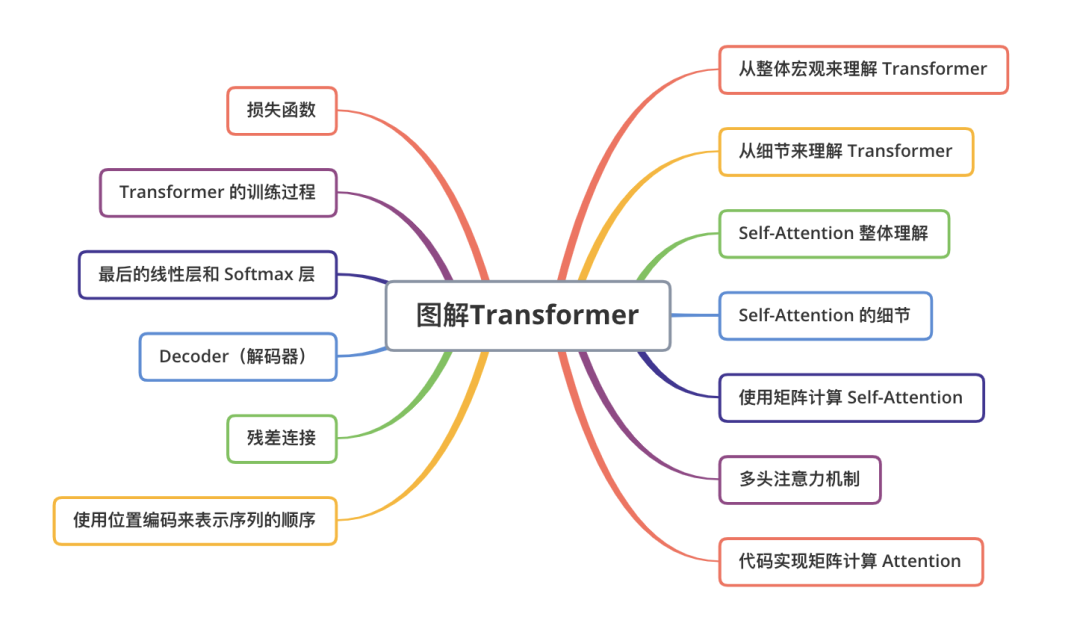
結(jié)構(gòu)總覽
前言
本文翻譯自http://jalammar.github.io/illustrated-transformer,是筆者看過的把 Transformer 講解得最好的文章。這篇文章從輸入開始,一步一步演示了數(shù)據(jù)在 Transformer 中的流動(dòng)過程。由于看過一些中文翻譯的文章,感覺不夠好,所以我自己翻譯了一個(gè)版本,在一些難以直譯的地方,我加入了一些原文沒有的文字說明,來更好地解釋概念。另外,我添加了一些簡單的代碼,實(shí)現(xiàn)了一個(gè)基本的 Self Attention 以及 multi-head attention 的矩陣運(yùn)算。
Transformer 依賴于 Self Attention 的知識。Attention 是一種在深度學(xué)習(xí)中廣泛使用的方法,Attention的思想提升了機(jī)器翻譯的效果。如果你還沒學(xué)習(xí) Attention,請查看這篇 Attention 的精彩講解:https://zhuanlan.zhihu.com/p/265182368。
2017 年,Google 提出了 Transformer 模型,用 Self Attention 的結(jié)構(gòu),取代了以往 NLP 任務(wù)中的 RNN 網(wǎng)絡(luò)結(jié)構(gòu),在 WMT 2014 Englishto-German 和 WMT 2014 English-to-French兩個(gè)機(jī)器翻譯任務(wù)上都取得了當(dāng)時(shí) SOTA 的效果。
這個(gè)模型的其中一個(gè)優(yōu)點(diǎn),就是使得模型訓(xùn)練過程能夠并行計(jì)算。在 RNN 中,每一個(gè) time step 的計(jì)算都依賴于上一個(gè) time step 的輸出,這就使得所有的 time step 必須串行化,無法并行計(jì)算,如下圖所示。
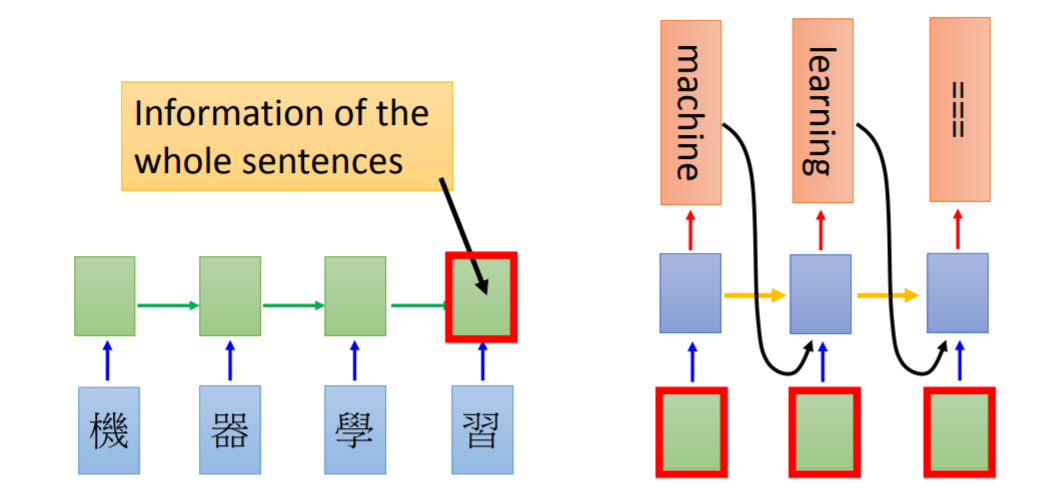
而在 Transformer 中,所有 time step 的數(shù)據(jù),都是經(jīng)過 Self Attention 計(jì)算,使得整個(gè)運(yùn)算過程可以并行化計(jì)算。
這篇文章的目的是從上到下,一步一步拆解 Transformer 的各種概念,希望有助于初學(xué)者更加容易地理解 Transformer 到底是什么。
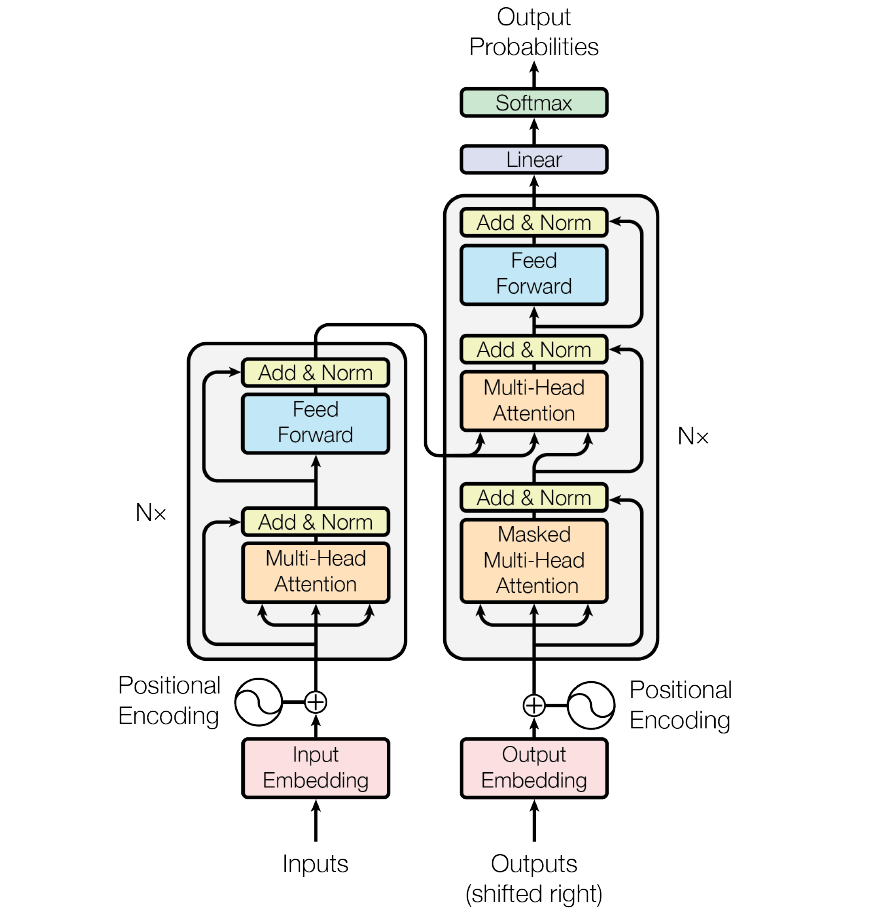
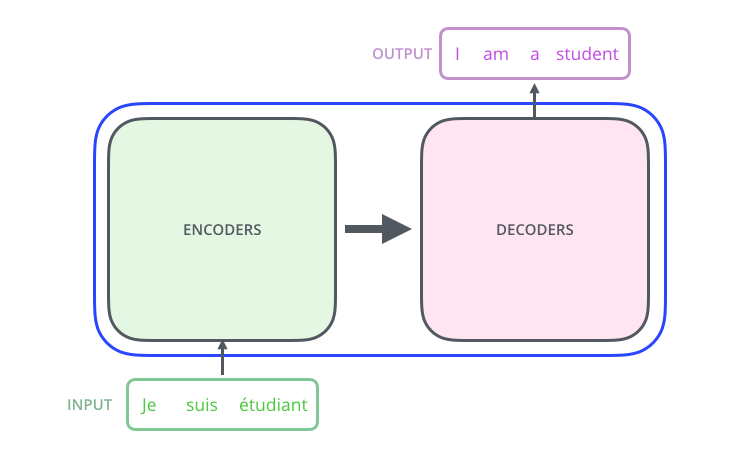
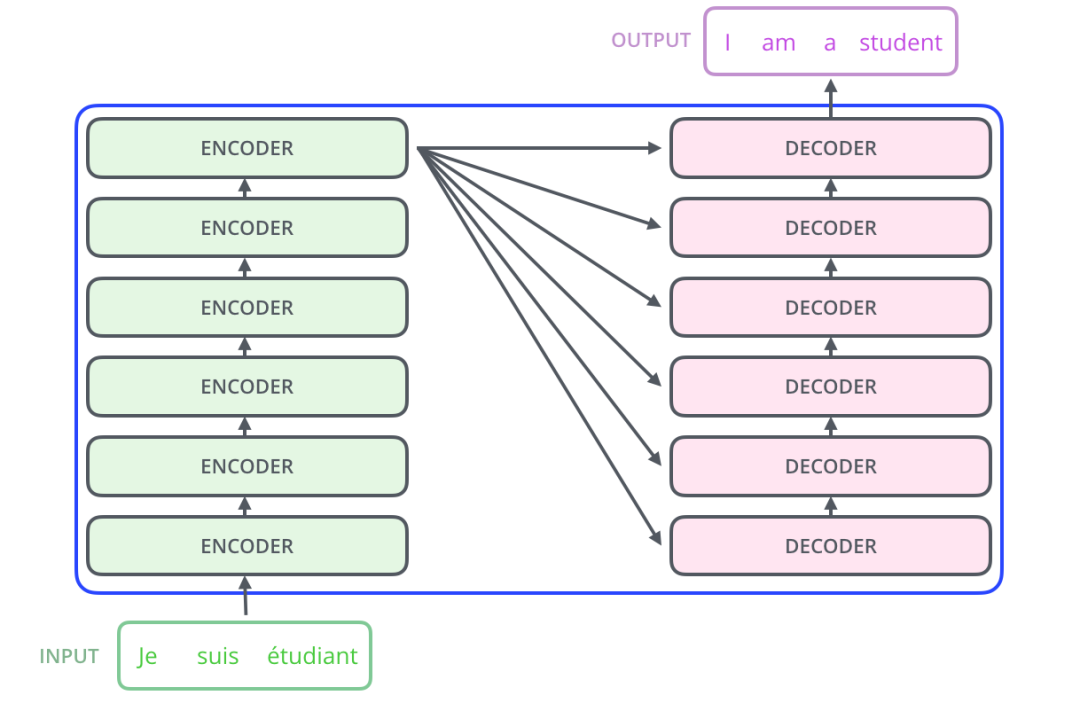
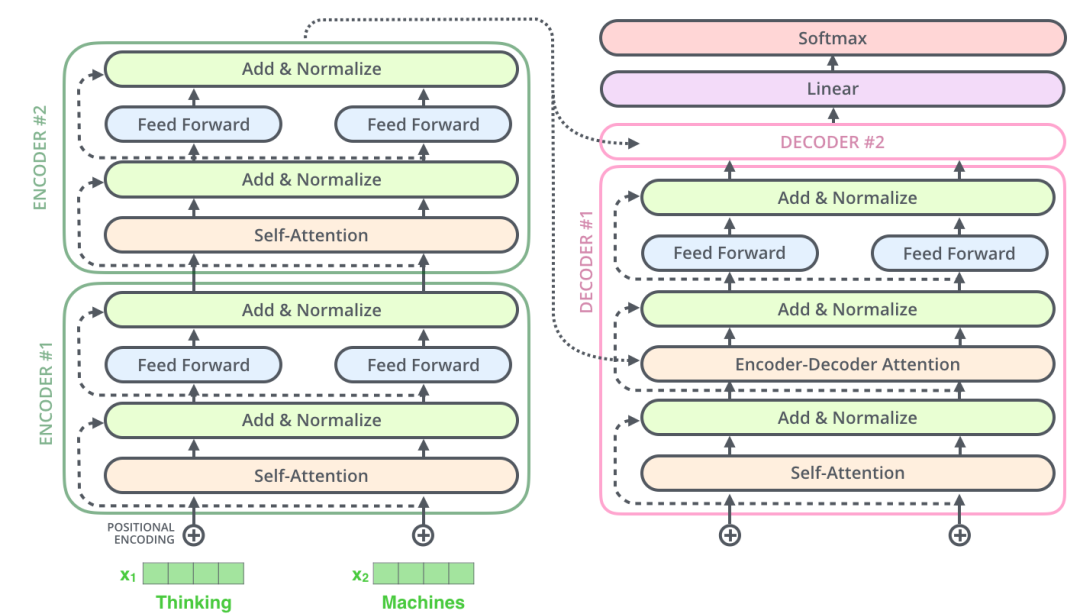
Transformer 使用了 Seq2Seq任務(wù)中常用的結(jié)構(gòu)——包括兩個(gè)部分:Encoder 和 Decoder。一般的結(jié)構(gòu)圖,都是像下面這樣。
一、從整體宏觀來理解 Transformer
首先,我們將整個(gè)模型視為黑盒。在機(jī)器翻譯任務(wù)中,接收一種語言的句子作為輸入,然后將其翻譯成其他語言輸出。

Self-Attention Layer Feed Forward Neural Network(前饋神經(jīng)網(wǎng)絡(luò),縮寫為 FFNN)
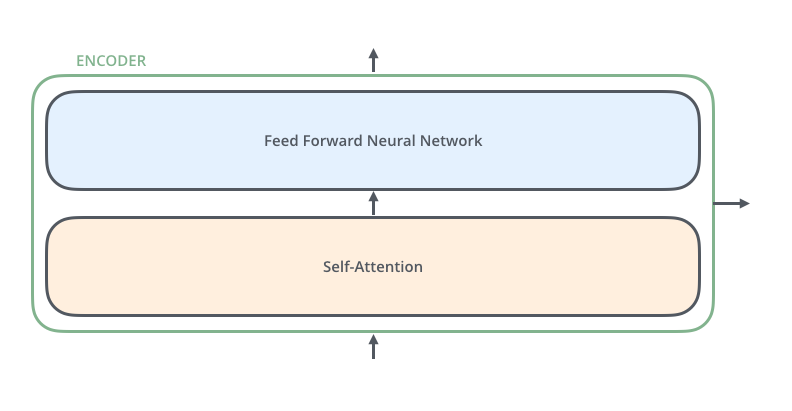
接下來,Self Attention 層的輸出會經(jīng)過前饋神經(jīng)網(wǎng)絡(luò)。
同理,解碼器也具有這兩層,但是這兩層中間還插入了一個(gè) Encoder-Decoder Attention 層,這個(gè)層能幫助解碼器聚焦于輸入句子的相關(guān)部分(類似于 seq2seq 模型 中的 Attention)。
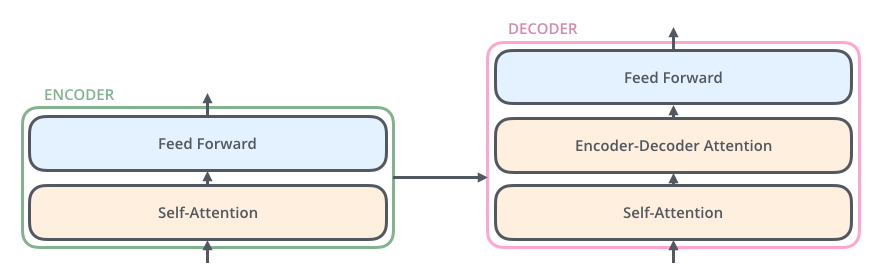
二、從細(xì)節(jié)來理解 Transformer
上面,我們從宏觀理解了 Transformer 的主要部分。下面,我們來看輸入的張量數(shù)據(jù),在 Transformer 中運(yùn)算最終得到輸出的過程。
2.1 Transformer 的輸入
和通常的 NLP 任務(wù)一樣,我們首先會使用詞嵌入算法(embedding algorithm),將每個(gè)詞轉(zhuǎn)換為一個(gè)詞向量。實(shí)際中向量一般是 256 或者 512 維。為了簡化起見,這里將每個(gè)詞的轉(zhuǎn)換為一個(gè) 4 維的詞向量。
那么整個(gè)輸入的句子是一個(gè)向量列表,其中有 3 個(gè)詞向量。在實(shí)際中,每個(gè)句子的長度不一樣,我們會取一個(gè)適當(dāng)?shù)闹担鳛橄蛄苛斜淼拈L度。如果一個(gè)句子達(dá)不到這個(gè)長度,那么就填充全為 0 的詞向量;如果句子超出這個(gè)長度,則做截?cái)唷>渥娱L度是一個(gè)超參數(shù),通常是訓(xùn)練集中的句子的最大長度,你可以嘗試不同長度的效果。

編碼器(Encoder)接收的輸入都是一個(gè)向量列表,輸出也是大小同樣的向量列表,然后接著輸入下一個(gè)編碼器。
第一個(gè)編碼器的輸入是詞向量,而后面的編碼器的輸入是上一個(gè)編碼器的輸出。
下面,我們來看這個(gè)向量列表在編碼器里面是如何流動(dòng)的。
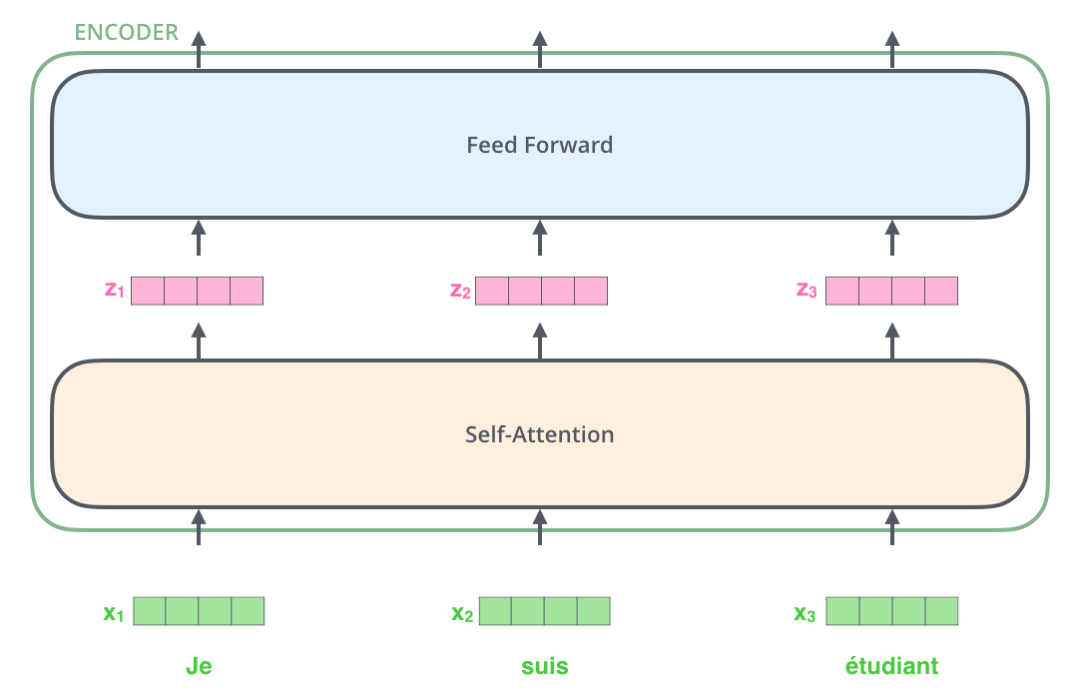
這里我們可以注意到 Transformer 的一個(gè)重要特性:每個(gè)位置的詞向量經(jīng)過編碼器都有自己單獨(dú)的路徑。具體來說,在 Self Attention 層中,這些路徑之間是有依賴關(guān)系的;而在 Feed Forward (前饋神經(jīng)網(wǎng)絡(luò))層中,這些路徑之間是沒有依賴關(guān)系的。因此這些詞向量在經(jīng)過 Feed Forward 層中可以并行計(jì)算(這句話會造成困擾,我認(rèn)為在 Self Attention 層中,也能并行計(jì)算,沒有必要單獨(dú)說 Feed Forward 層也可以并行計(jì)算)。
下面我們用一個(gè)更短的句子,來說明數(shù)據(jù)在編碼器的編碼過程。
2.2 Encoder(編碼器)
上面我們提到,一個(gè)編碼器接收的輸入是一個(gè)向量列表,它會把向量列表輸入到 Self Attention 層,然后經(jīng)過 feed-forward neural network (前饋神經(jīng)網(wǎng)絡(luò))層,最后得到輸出,傳入下一個(gè)編碼器。

每個(gè)位置的詞都經(jīng)過 Self Attention 層,得到的每個(gè)輸出向量都單獨(dú)經(jīng)過前饋神經(jīng)網(wǎng)絡(luò)層,每個(gè)向量經(jīng)過的前饋神經(jīng)網(wǎng)絡(luò)都是一樣的
三、 Self-Attention 整體理解
別被“Self-Attention”這么高大上的詞給唬住了,乍一聽好像每個(gè)人都應(yīng)該對這個(gè)詞熟悉一樣。但我在讀論文《Attention is All You Need》 之前就沒有聽過這個(gè)詞。下面來分析 Self-Attention 的具體機(jī)制。
假設(shè)我們想要翻譯的句子是:
The animal didn't cross the street because it was too tired
這個(gè)句子中的 it 是一個(gè)指代詞,那么 it 指的是什么呢?它是指animal還是street?這個(gè)問題對人來說,是很簡單的,但是對算法來說并不是那么容易。
當(dāng)模型在處理(翻譯)it 的時(shí)候,Self Attention機(jī)制能夠讓模型把it和animal關(guān)聯(lián)起來。
同理,當(dāng)模型處理句子中的每個(gè)詞時(shí),Self Attention機(jī)制使得模型不僅能夠關(guān)注這個(gè)位置的詞,而且能夠關(guān)注句子中其他位置的詞,作為輔助線索,進(jìn)而可以更好地編碼當(dāng)前位置的詞。
如果你熟悉 RNN,回憶一下:RNN 在處理一個(gè)詞時(shí),會考慮前面?zhèn)鬟^來的hidden state,而hidden state就包含了前面的詞的信息。而 Transformer 使用Self Attention機(jī)制,會把其他單詞的理解融入處理當(dāng)前的單詞。

當(dāng)我們在第五層編碼器中(編碼部分中的最后一層編碼器)編碼“it”時(shí),有一部分注意力集中在“The animal”上,并且把這兩個(gè)詞的信息融合到了"it"這個(gè)單詞中。
你可以查看 【Tensor2Tensor notebook】。在這個(gè) notebook 里,你可以加載 Transformer 模型,并通過交互式的可視化,來理解 Self Attention。
四、Self-Attention 的細(xì)節(jié)
4.1 計(jì)算Query 向量,Key 向量,Value 向量
下面我們先看下如何使用向量來計(jì)算 Self Attention,然后再看下如何使用矩陣來實(shí)現(xiàn) Self Attention。(矩陣運(yùn)算的方式,使得 Self Attention 的計(jì)算能夠并行化,這也是 Self Attention 最終的實(shí)現(xiàn)方式)。
計(jì)算 Self Attention 的第 1 步是:對輸入編碼器的每個(gè)詞向量,都創(chuàng)建 3 個(gè)向量,分別是:Query 向量,Key 向量,Value 向量。這 3 個(gè)向量是詞向量分別和 3 個(gè)矩陣相乘得到的,而這個(gè)矩陣是我們要學(xué)習(xí)的參數(shù)。
注意,這 3 個(gè)新得到的向量一般比原來的詞向量的長度更小。假設(shè)這 3 個(gè)向量的長度是?,而原始的詞向量或者最終輸出的向量的長度是 512(這 3 個(gè)向量的長度,和最終輸出的向量長度,是有倍數(shù)關(guān)系的)。關(guān)于 Multi-head Attention,后面會給出實(shí)際代碼。這里為了簡化,假設(shè)只有一個(gè) head 的 Self-Attention。
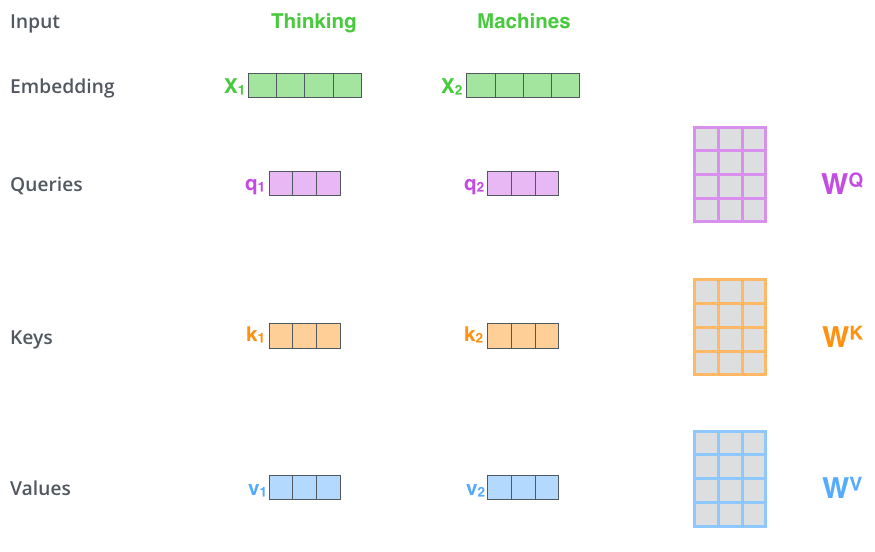
上圖中,有兩個(gè)詞向量:Thinking 的詞向量 x1 和 Machines 的詞向量 x2。以 x1 為例,X1 乘以 WQ 得到 q1,q1 就是 X1 對應(yīng)的 Query 向量。同理,X1 乘以 WK 得到 k1,k1 是 X1 對應(yīng)的 Key 向量;X1 乘以 WV 得到 v1,v1 是 X1 對應(yīng)的 Value 向量。
Query 向量,Key 向量,Value 向量是什么含義呢?
其實(shí)它們就是 3 個(gè)向量,給它們加上一個(gè)名稱,可以讓我們更好地理解 Self-Attention 的計(jì)算過程和邏輯含義。繼續(xù)往下讀,你會知道 attention 是如何計(jì)算出來的,Query 向量,Key 向量,Value 向量又分別扮演了什么角色。
4.2 計(jì)算 Attention Score(注意力分?jǐn)?shù))
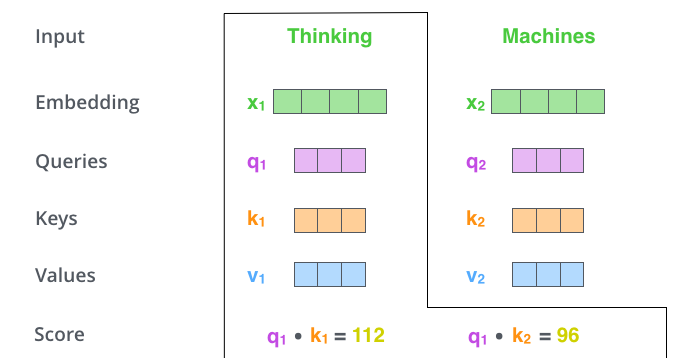
第 2 步,是計(jì)算 Attention Score(注意力分?jǐn)?shù))。假設(shè)我們現(xiàn)在計(jì)算第一個(gè)詞 Thinking 的 Attention Score(注意力分?jǐn)?shù)),需要根據(jù) Thinking 這個(gè)詞,對句子中的其他每個(gè)詞都計(jì)算一個(gè)分?jǐn)?shù)。這些分?jǐn)?shù)決定了我們在編碼Thinking這個(gè)詞時(shí),需要對句子中其他位置的每個(gè)詞放置多少的注意力。
這些分?jǐn)?shù),是通過計(jì)算 "Thinking" 對應(yīng)的 Query 向量和其他位置的每個(gè)詞的 Key 向量的點(diǎn)積,而得到的。如果我們計(jì)算句子中第一個(gè)位置單詞的 Attention Score(注意力分?jǐn)?shù)),那么第一個(gè)分?jǐn)?shù)就是 q1 和 k1 的內(nèi)積,第二個(gè)分?jǐn)?shù)就是 q1 和 k2 的點(diǎn)積。
第 3 步就是把每個(gè)分?jǐn)?shù)除以?( 是 Key 向量的長度)。你也可以除以其他數(shù),除以一個(gè)數(shù)是為了在反向傳播時(shí),求取梯度更加穩(wěn)定。
第 4 步,接著把這些分?jǐn)?shù)經(jīng)過一個(gè) Softmax 層,Softmax可以將分?jǐn)?shù)歸一化,這樣使得分?jǐn)?shù)都是正數(shù)并且加起來等于 1。
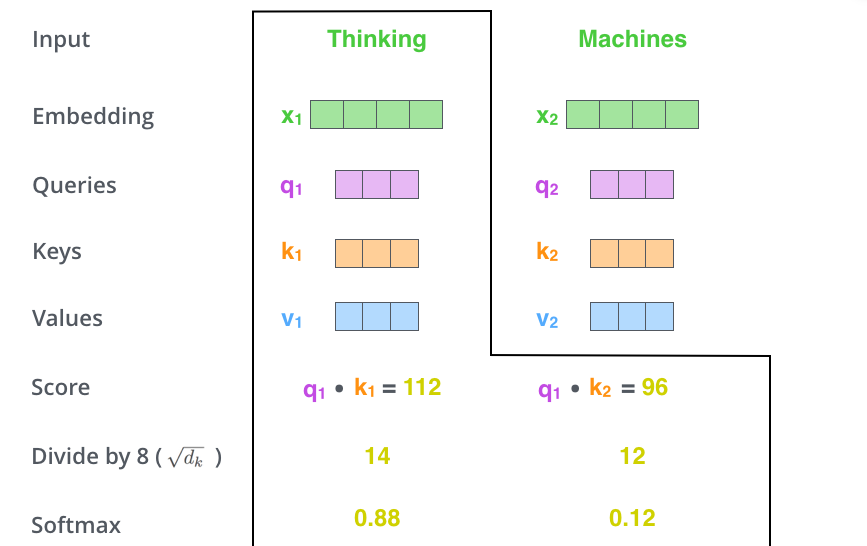
這些分?jǐn)?shù)決定了在編碼當(dāng)前位置(這里的例子是第一個(gè)位置)的詞時(shí),對所有位置的詞分別有多少的注意力。很明顯,在上圖的例子中,當(dāng)前位置(這里的例子是第一個(gè)位置)的詞會有最高的分?jǐn)?shù),但有時(shí),關(guān)注到其他位置上相關(guān)的詞也很有用。
第 5 步,得到每個(gè)位置的分?jǐn)?shù)后,將每個(gè)分?jǐn)?shù)分別與每個(gè) Value 向量相乘。這種做法背后的直覺理解就是:對于分?jǐn)?shù)高的位置,相乘后的值就越大,我們把更多的注意力放到了它們身上;對于分?jǐn)?shù)低的位置,相乘后的值就越小,這些位置的詞可能是相關(guān)性不大的,這樣我們就忽略了這些位置的詞。
第 6 步是把上一步得到的向量相加,就得到了 Self Attention 層在這個(gè)位置(這里的例子是第一個(gè)位置)的輸出。
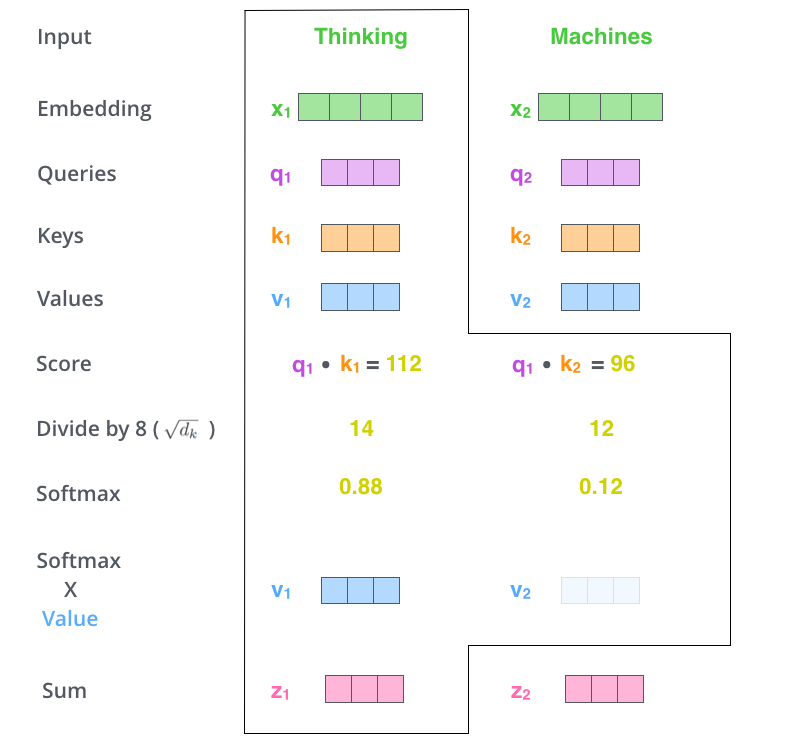
上面這張圖,包含了 Self Attention 的全過程,最終得到的當(dāng)前位置(這里的例子是第一個(gè)位置)的向量會輸入到前饋神經(jīng)網(wǎng)絡(luò)。但這樣每次只能計(jì)算一個(gè)位置的輸出向量,在實(shí)際的代碼實(shí)現(xiàn)中,Self Attention 的計(jì)算過程是使用矩陣來實(shí)現(xiàn)的,這樣可以加速計(jì)算,一次就得到所有位置的輸出向量。下面讓我們來看,如何使用矩陣來計(jì)算所有位置的輸出向量。
五、使用矩陣計(jì)算 Self-Attention
第一步是計(jì)算 Query,Key,Value 的矩陣。首先,我們把所有詞向量放到一個(gè)矩陣 X 中,然后分別和 3 個(gè)權(quán)重矩陣,, 相乘,得到 Q,K,V 矩陣。
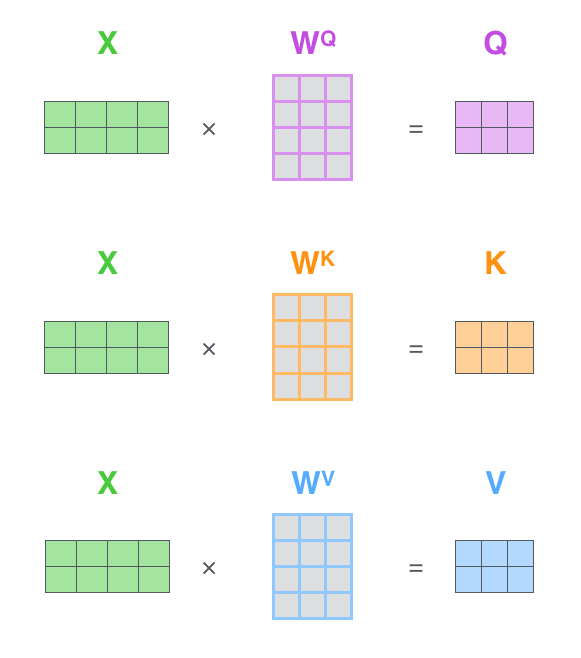
矩陣 X 中的每一行,表示句子中的每一個(gè)詞的詞向量,長度是 512。Q,K,V 矩陣中的每一行表示 Query 向量,Key 向量,Value 向量,向量長度是 64。
接著,由于我們使用了矩陣來計(jì)算,我們可以把上面的第 2 步到第 6 步壓縮為一步,直接得到 Self Attention 的輸出。
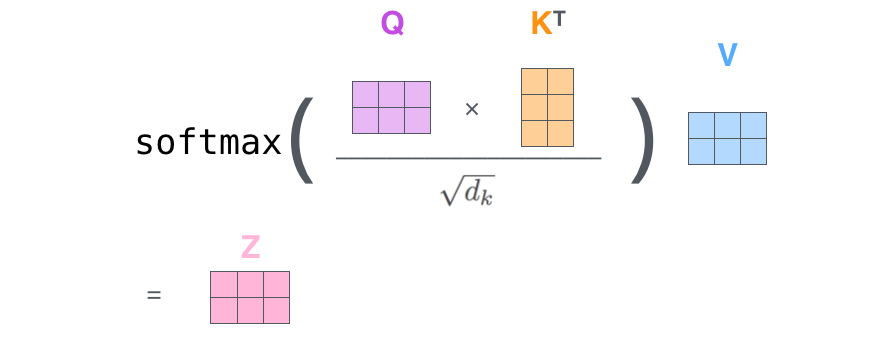
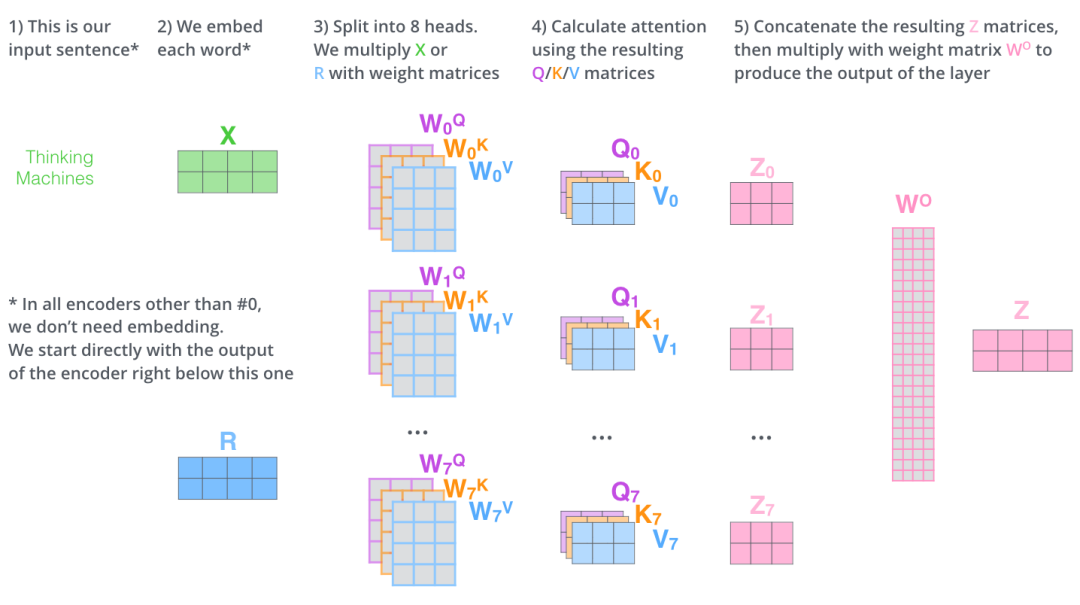
六、多頭注意力機(jī)制(multi-head attention)
Transformer 的論文通過增加多頭注意力機(jī)制(一組注意力稱為一個(gè) attention head),進(jìn)一步完善了 Self Attention 層。這種機(jī)制從如下兩個(gè)方面增強(qiáng)了 attention 層的能力:
它擴(kuò)展了模型關(guān)注不同位置的能力。在上面的例子中,第一個(gè)位置的輸出 z1 包含了句子中其他每個(gè)位置的很小一部分信息,但 z1 可能主要是由第一個(gè)位置的信息決定的。當(dāng)我們翻譯句子:
The animal didn’t cross the street because it was too tired時(shí),我們想讓機(jī)器知道其中的it指代的是什么。這時(shí),多頭注意力機(jī)制會有幫助。多頭注意力機(jī)制賦予 attention 層多個(gè)“子表示空間”。下面我們會看到,多頭注意力機(jī)制會有多組? 的權(quán)重矩陣(在 Transformer 的論文中,使用了 8 組注意力(attention heads)。因此,接下來我也是用 8 組注意力頭 (attention heads))。每一組注意力的?的權(quán)重矩陣都是隨機(jī)初始化的。經(jīng)過訓(xùn)練之后,每一組注意力可以看作是把輸入的向量映射到一個(gè)”子表示空間“。
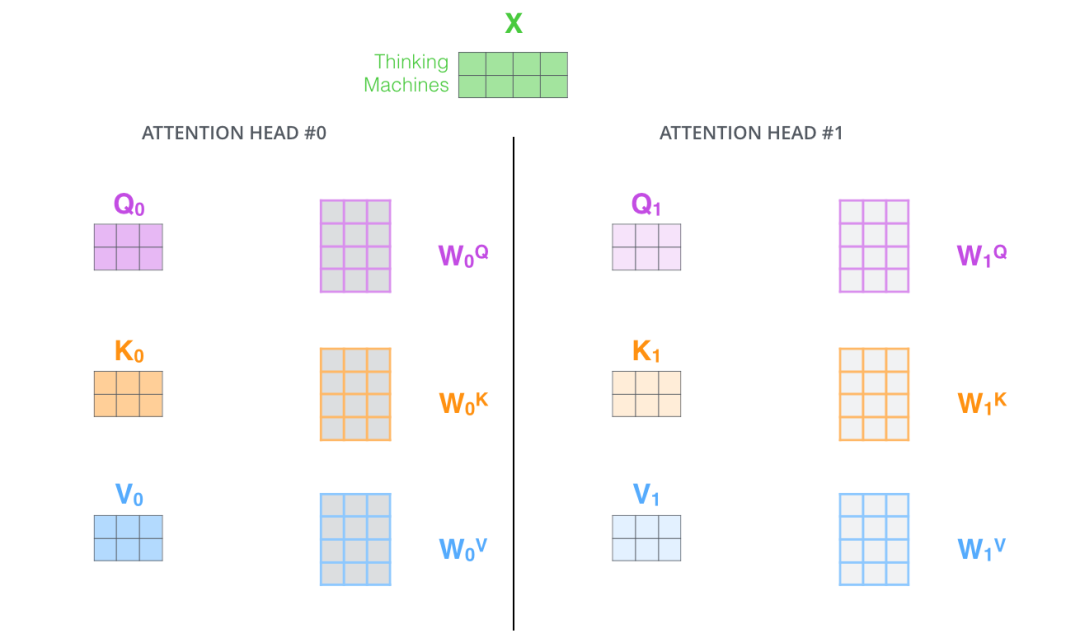
在多頭注意力機(jī)制中,我們?yōu)槊拷M注意力維護(hù)單獨(dú)的 WQ, WK, WV 權(quán)重矩陣。將輸入 X 和每組注意力的WQ, WK, WV 相乘,得到 8 組 Q, K, V 矩陣。
接著,我們把每組 K, Q, V 計(jì)算得到每組的 Z 矩陣,就得到 8 個(gè) Z 矩陣。
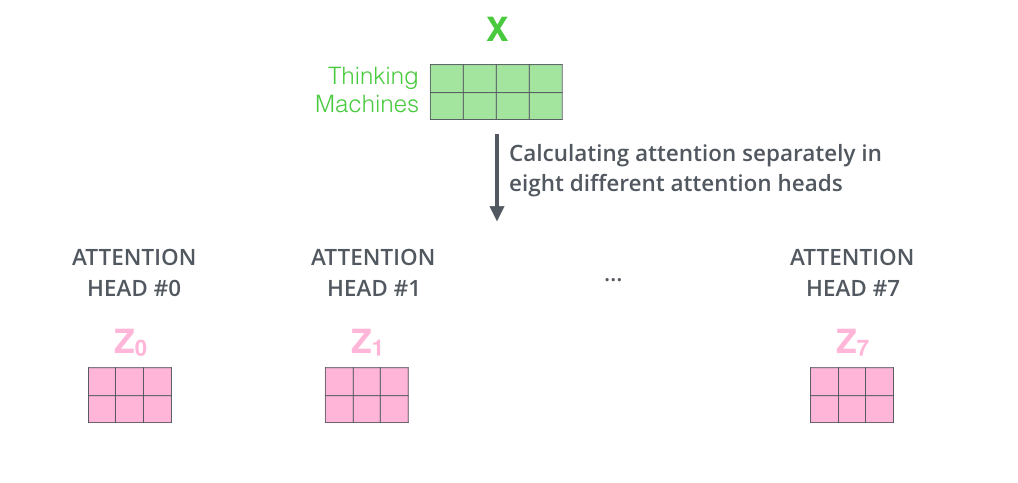
接下來就有點(diǎn)麻煩了,因?yàn)榍梆伾窠?jīng)網(wǎng)絡(luò)層接收的是 1 個(gè)矩陣(其中每行的向量表示一個(gè)詞),而不是 8 個(gè)矩陣。所以我們需要一種方法,把 8 個(gè)矩陣整合為一個(gè)矩陣。
怎么才能做到呢?我們把矩陣拼接起來,然后和另一個(gè)權(quán)重矩陣? 相乘。
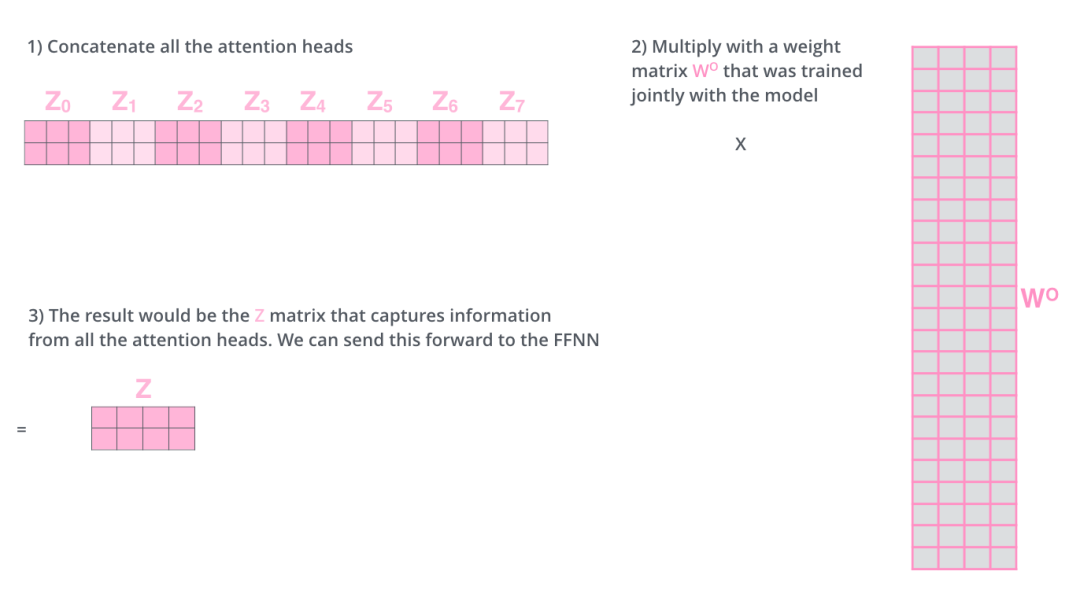
把 8 個(gè)矩陣 {Z0,Z1...,Z7} 拼接起來 把拼接后的矩陣和 WO 權(quán)重矩陣相乘 得到最終的矩陣 Z,這個(gè)矩陣包含了所有 attention heads(注意力頭) 的信息。這個(gè)矩陣會輸入到 FFNN (Feed Forward Neural Network)層。
這就是多頭注意力的全部內(nèi)容。我知道,在上面的講解中,出現(xiàn)了相當(dāng)多的矩陣。下面我把所有的內(nèi)容都放到一張圖中,這樣你可以總攬全局,在這張圖中看到所有的內(nèi)容。
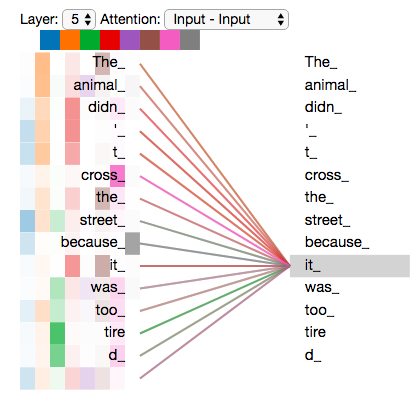
既然我們已經(jīng)談到了多頭注意力,現(xiàn)在讓我們重新回顧之前的翻譯例子,看下當(dāng)我們編碼單詞it時(shí),不同的 attention heads (注意力頭)關(guān)注的是什么部分。

當(dāng)我們編碼單詞"it"時(shí),其中一個(gè) attention head (注意力頭)最關(guān)注的是"the animal",另外一個(gè) attention head 關(guān)注的是"tired"。因此在某種意義上,"it"在模型中的表示,融合了"animal"和"word"的部分表達(dá)。
然而,當(dāng)我們把所有 attention heads(注意力頭) 都在圖上畫出來時(shí),多頭注意力又變得難以解釋了。
七、代碼實(shí)現(xiàn)矩陣計(jì)算 Attention
下面我們是用代碼來演示,如何使用矩陣計(jì)算 attention。首先使用 PyTorch 庫提供的函數(shù)實(shí)現(xiàn),然后自己再實(shí)現(xiàn)。
7.1 使用 PyTorch 庫的實(shí)現(xiàn)
PyTorch 提供了 MultiheadAttention 來實(shí)現(xiàn) attention 的計(jì)算。
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
參數(shù)說明如下:
embed_dim:最終輸出的 K、Q、V 矩陣的維度,這個(gè)維度需要和詞向量的維度一樣
num_heads:設(shè)置多頭注意力的數(shù)量。如果設(shè)置為 1,那么只使用一組注意力。如果設(shè)置為其他數(shù)值,那么 num_heads 的值需要能夠被 embed_dim 整除
dropout:這個(gè) dropout 加在 attention score 后面
現(xiàn)在來解釋一下,為什么 ?num_heads 的值需要能夠被 embed_dim 整除。這是為了把詞的隱向量長度平分到每一組,這樣多組注意力也能夠放到一個(gè)矩陣?yán)铮瑥亩⑿杏?jì)算多頭注意力。
例如,我們前面說到,8 組注意力可以得到 8 組 Z 矩陣,然后把這些矩陣拼接起來,得到最終的輸出。如果最終輸出的每個(gè)詞的向量維度是 512,那么每組注意力的向量維度應(yīng)該是?。
如果不能夠整除,那么這些向量的長度就無法平均分配。
下面的會有代碼示例,如何使用矩陣實(shí)現(xiàn)多組注意力的并行計(jì)算。
定義 MultiheadAttention 的對象后,調(diào)用時(shí)傳入的參數(shù)如下。
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
query:對應(yīng)于 Key 矩陣,形狀是 (L,N,E) 。其中 L 是輸出序列長度,N 是 batch size,E 是詞向量的維度
key:對應(yīng)于 Key 矩陣,形狀是 (S,N,E) 。其中 S 是輸入序列長度,N 是 batch size,E 是詞向量的維度
value:對應(yīng)于 Value 矩陣,形狀是 (S,N,E) 。其中 S 是輸入序列長度,N 是 batch size,E 是詞向量的維度
key_padding_mask:如果提供了這個(gè)參數(shù),那么計(jì)算 attention score 時(shí),忽略 Key 矩陣中某些 padding 元素,不參與計(jì)算 attention。形狀是 (N,S)。其中 N 是 batch size,S 是輸入序列長度。
如果 key_padding_mask 是 ByteTensor,那么非 0 元素對應(yīng)的位置會被忽略 如果 key_padding_mask 是 BoolTensor,那么 ?True 對應(yīng)的位置會被忽略 attn_mask:計(jì)算輸出時(shí),忽略某些位置。形狀可以是 2D ?(L,S),或者 3D (N?numheads,L,S)。其中 L 是輸出序列長度,S 是輸入序列長度,N 是 batch size。
如果 attn_mask 是 ByteTensor,那么非 0 元素對應(yīng)的位置會被忽略 如果 attn_mask 是 BoolTensor,那么 ?True 對應(yīng)的位置會被忽略
需要注意的是:在前面的講解中,我們的 K、Q、V 矩陣的序列長度都是一樣的。但是在實(shí)際中,K、V 矩陣的序列長度是一樣的,而 Q 矩陣的序列長度可以不一樣。
這種情況發(fā)生在:在解碼器部分的Encoder-Decoder Attention層中,Q 矩陣是來自解碼器下層,而 K、V 矩陣則是來自編碼器的輸出。
在完成了編碼(encoding)階段之后,我們開始解碼(decoding)階段。解碼(decoding )階段的每一個(gè)時(shí)間步都輸出一個(gè)翻譯后的單詞(這里的例子是英語翻譯)。
輸出是:
attn_output:形狀是 (L,N,E) attn_output_weights:形狀是 (N,L,S)
代碼示例如下:
## nn.MultiheadAttention 輸入第0維為length
# batch_size 為 64,有 12 個(gè)詞,每個(gè)詞的 Query 向量是 300 維
query = torch.rand(12,64,300)
# batch_size 為 64,有 10 個(gè)詞,每個(gè)詞的 Key 向量是 300 維
key = torch.rand(10,64,300)
# batch_size 為 64,有 10 個(gè)詞,每個(gè)詞的 Value 向量是 300 維
value= torch.rand(10,64,300)
embed_dim = 299
num_heads = 1
# 輸出是 (attn_output, attn_output_weights)
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output = multihead_attn(query, key, value)[0]
# output: torch.Size([12, 64, 300])
# batch_size 為 64,有 12 個(gè)詞,每個(gè)詞的向量是 300 維
print(attn_output.shape)
7.2 手動(dòng)實(shí)現(xiàn)計(jì)算 Attention
在 PyTorch 提供的 MultiheadAttention ?中,第 1 維是句子長度,第 2 維是 batch size。這里我們的代碼實(shí)現(xiàn)中,第 1 維是 batch size,第 2 維是句子長度。代碼里也包括:如何用矩陣實(shí)現(xiàn)多組注意力的并行計(jì)算。代碼中已經(jīng)有詳細(xì)注釋和說明。
class MultiheadAttention(nn.Module):
# n_heads:多頭注意力的數(shù)量
# hid_dim:每個(gè)詞輸出的向量維度
def __init__(self, hid_dim, n_heads, dropout):
super(MultiheadAttention, self).__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
# 強(qiáng)制 hid_dim 必須整除 h
assert hid_dim % n_heads == 0
# 定義 W_q 矩陣
self.w_q = nn.Linear(hid_dim, hid_dim)
# 定義 W_k 矩陣
self.w_k = nn.Linear(hid_dim, hid_dim)
# 定義 W_v 矩陣
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
# 縮放
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))
def forward(self, query, key, value, mask=None):
# K: [64,10,300], batch_size 為 64,有 12 個(gè)詞,每個(gè)詞的 Query 向量是 300 維
# V: [64,10,300], batch_size 為 64,有 10 個(gè)詞,每個(gè)詞的 Query 向量是 300 維
# Q: [64,12,300], batch_size 為 64,有 10 個(gè)詞,每個(gè)詞的 Query 向量是 300 維
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# 這里把 K Q V 矩陣拆分為多組注意力,變成了一個(gè) 4 維的矩陣
# 最后一維就是是用 self.hid_dim // self.n_heads 來得到的,表示每組注意力的向量長度, 每個(gè) head 的向量長度是:300/6=50
# 64 表示 batch size,6 表示有 6組注意力,10 表示有 10 詞,50 表示每組注意力的詞的向量長度
# K: [64,10,300] 拆分多組注意力 -> [64,10,6,50] 轉(zhuǎn)置得到 -> [64,6,10,50]
# V: [64,10,300] 拆分多組注意力 -> [64,10,6,50] 轉(zhuǎn)置得到 -> [64,6,10,50]
# Q: [64,12,300] 拆分多組注意力 -> [64,12,6,50] 轉(zhuǎn)置得到 -> [64,6,12,50]
# 轉(zhuǎn)置是為了把注意力的數(shù)量 6 放到前面,把 10 和 50 放到后面,方便下面計(jì)算
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
# 第 1 步:Q 乘以 K的轉(zhuǎn)置,除以scale
# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]
# attention:[64,6,12,10]
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# 把 mask 不為空,那么就把 mask 為 0 的位置的 attention 分?jǐn)?shù)設(shè)置為 -1e10
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
# 第 2 步:計(jì)算上一步結(jié)果的 softmax,再經(jīng)過 dropout,得到 attention。
# 注意,這里是對最后一維做 softmax,也就是在輸入序列的維度做 softmax
# attention: [64,6,12,10]
attention = self.do(torch.softmax(attention, dim=-1))
# 第三步,attention結(jié)果與V相乘,得到多頭注意力的結(jié)果
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
# x: [64,6,12,50]
x = torch.matmul(attention, V)
# 因?yàn)?query 有 12 個(gè)詞,所以把 12 放到前面,把 5 和 60 放到后面,方便下面拼接多組的結(jié)果
# x: [64,6,12,50] 轉(zhuǎn)置-> [64,12,6,50]
x = x.permute(0, 2, 1, 3).contiguous()
# 這里的矩陣轉(zhuǎn)換就是:把多組注意力的結(jié)果拼接起來
# 最終結(jié)果就是 [64,12,300]
# x: [64,12,6,50] -> [64,12,300]
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
return x
# batch_size 為 64,有 12 個(gè)詞,每個(gè)詞的 Query 向量是 300 維
query = torch.rand(64, 12, 300)
# batch_size 為 64,有 12 個(gè)詞,每個(gè)詞的 Key 向量是 300 維
key = torch.rand(64, 10, 300)
# batch_size 為 64,有 10 個(gè)詞,每個(gè)詞的 Value 向量是 300 維
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
## output: torch.Size([64, 12, 300])
print(output.shape)
7.3 關(guān)鍵代碼
其中用矩陣實(shí)現(xiàn)多頭注意力的關(guān)鍵代碼如下所示, K、Q、V 矩陣拆分為多組注意力,變成了一個(gè) 4 維的矩陣。
# 這里把 K Q V 矩陣拆分為多組注意力,變成了一個(gè) 4 維的矩陣
# 最后一維就是是用 self.hid_dim // self.n_heads 來得到的,表示每組注意力的向量長度, 每個(gè) head 的向量長度是:300/6=50
# 64 表示 batch size,6 表示有 6組注意力,10 表示有 10 個(gè)詞,50 表示每組注意力的詞的向量長度
# K: [64,10,300] 拆分多組注意力 -> [64,10,6,50] 轉(zhuǎn)置得到 -> [64,6,10,50]
# V: [64,10,300] 拆分多組注意力 -> [64,10,6,50] 轉(zhuǎn)置得到 -> [64,6,10,50]
# Q: [64,12,300] 拆分多組注意力 -> [64,12,6,50] 轉(zhuǎn)置得到 -> [64,6,12,50]
# 轉(zhuǎn)置是為了把注意力的數(shù)量 6 放到前面,把 10 和 50 放到后面,方便下面計(jì)算
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
經(jīng)過 attention 計(jì)算得到 x 的形狀是 `[64,12,6,50]`,64 表示 batch size,6 表示有 6組注意力,10 表示有 10 個(gè)詞,50 表示每組注意力的詞的向量長度。把這個(gè)矩陣轉(zhuǎn)換為 `[64,12,300]`的矩陣,就是相當(dāng)于把多組注意力的結(jié)果拼接起來。
e e e e e e e e e e e e e e e e e e e e e e e e e e e e e e e ee
這里的矩陣轉(zhuǎn)換就是:把多組注意力的結(jié)果拼接起來,最終結(jié)果就是 [64,12,300],x: [64,12,6,50] -> [64,12,300]
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
八、使用位置編碼來表示序列的順序
到目前為止,我們闡述的模型中缺失了一個(gè)東西,那就是表示序列中單詞順序的方法。
為了解決這個(gè)問題,Transformer 模型對每個(gè)輸入的向量都添加了一個(gè)向量。這些向量遵循模型學(xué)習(xí)到的特定模式,有助于確定每個(gè)單詞的位置,或者句子中不同單詞之間的距離。這種做法背后的直覺是:將這些表示位置的向量添加到詞向量中,得到了新的向量,這些新向量映射到 Q/K/V,然后計(jì)算點(diǎn)積得到 attention 時(shí),可以提供有意義的信息。
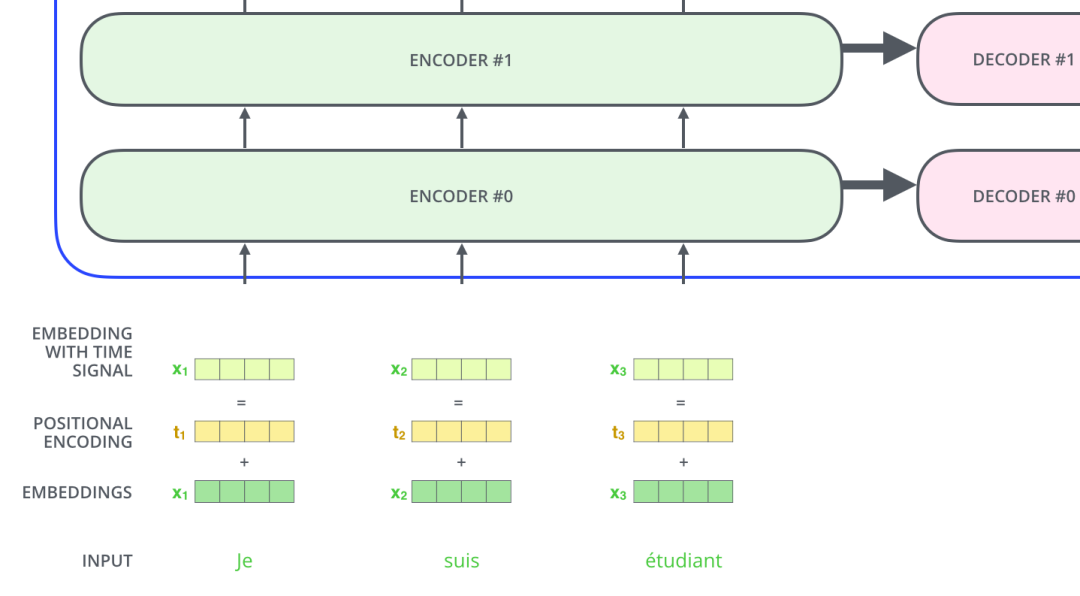
如果我們假設(shè)詞向量的維度是 4,那么帶有位置編碼的向量可能如下所示:
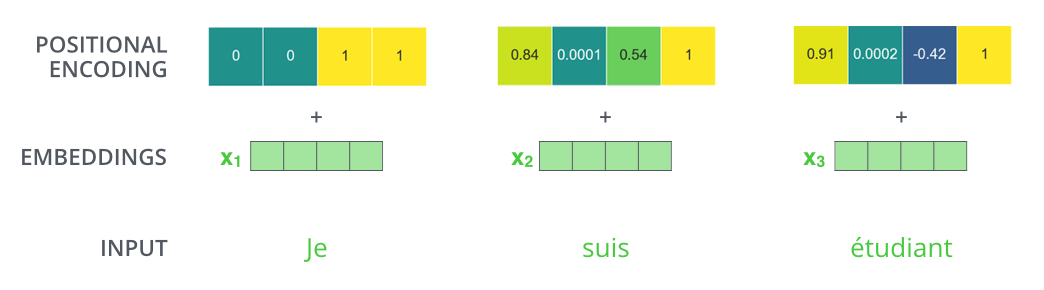
那么帶有位置編碼的向量到底遵循什么模式?
在下圖中,每一行表示一個(gè)帶有位置編碼的向量。所以,第一行對應(yīng)于序列中第一個(gè)單詞的位置編碼向量。每一行都包含 512 個(gè)值,每個(gè)值的范圍在 -1 和 1 之間。我對這些向量進(jìn)行了涂色可視化,你可以從中看到向量遵循的模式。
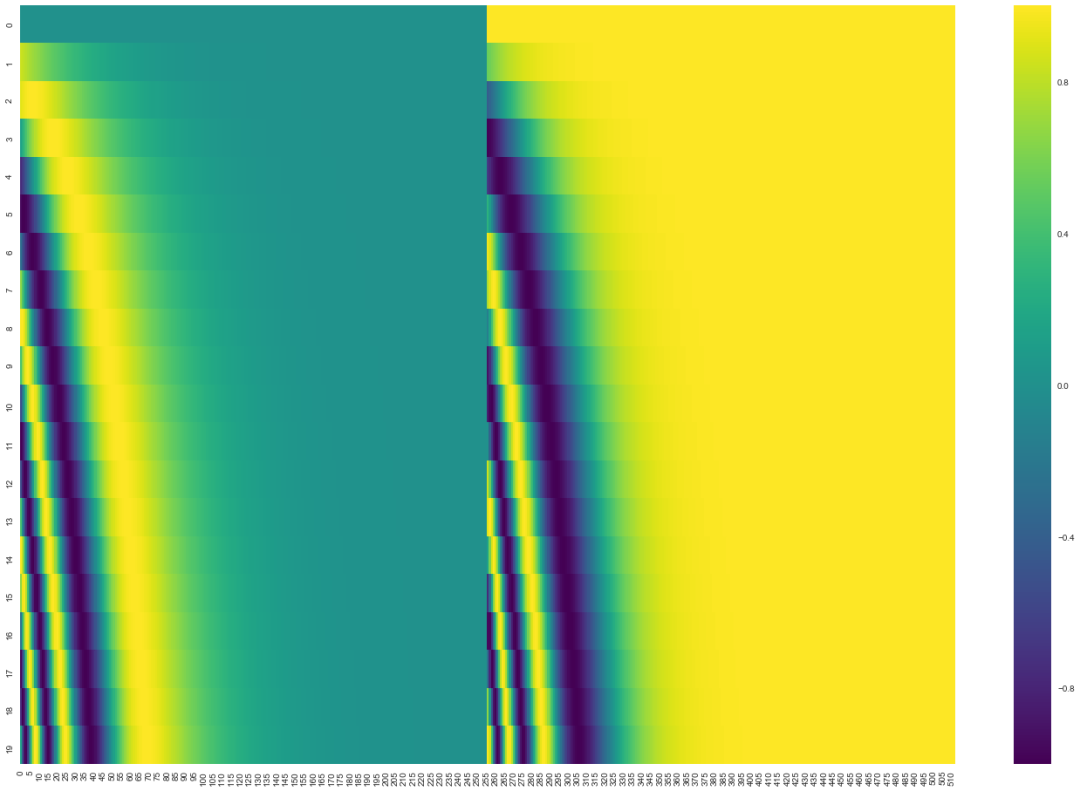
這是一個(gè)真實(shí)的例子,包含了 20 個(gè)詞,每個(gè)詞向量的維度是 512。你可以看到,它看起來像從中間一分為二。這是因?yàn)樽蟀氩糠值闹凳怯?sine 函數(shù)產(chǎn)生的,而右半部分的值是由 cosine 函數(shù)產(chǎn)生的,然后將他們拼接起來,得到每個(gè)位置編碼向量。
你可以在get_timing_signal_1d()上查看生成位置編碼的代碼。這種方法來自于Tranformer2Transformer 的實(shí)現(xiàn)。
而論文中的方法和上面圖中的稍有不同,它不是直接拼接兩個(gè)向量,而是將兩個(gè)向量交織在一起。如下圖所示。
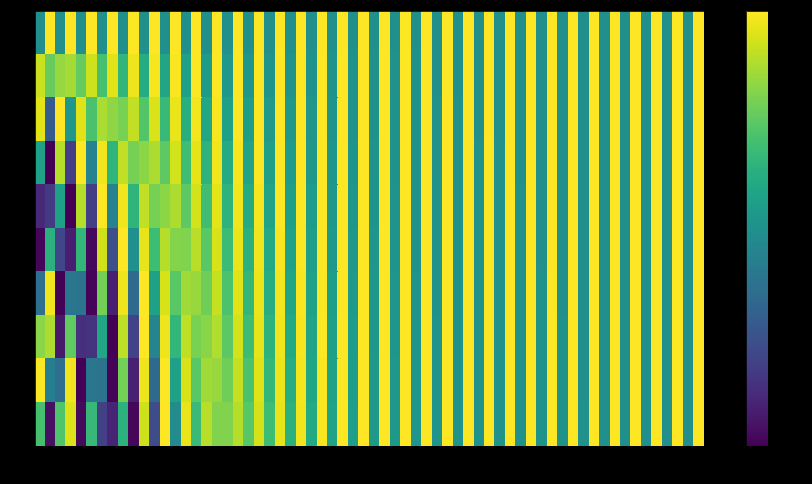
這不是唯一一種生成位置編碼的方法。但這種方法的優(yōu)點(diǎn)是:可以擴(kuò)展到未知的序列長度。例如:當(dāng)我們的模型需要翻譯一個(gè)句子,而這個(gè)句子的長度大于訓(xùn)練集中所有句子的長度,這時(shí),這種位置編碼的方法也可以生成一樣長的位置編碼向量。
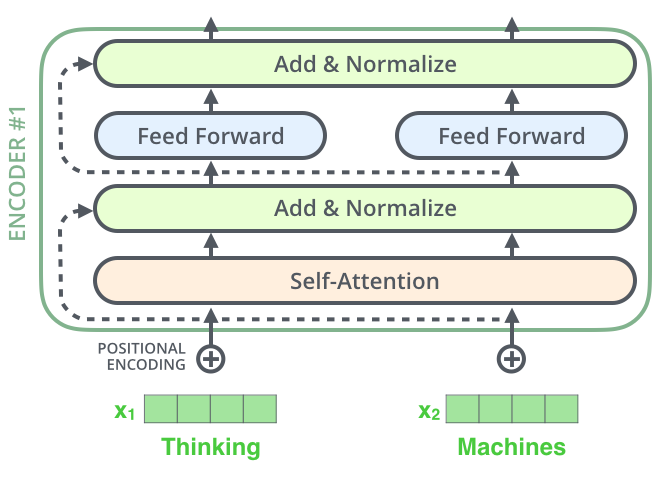
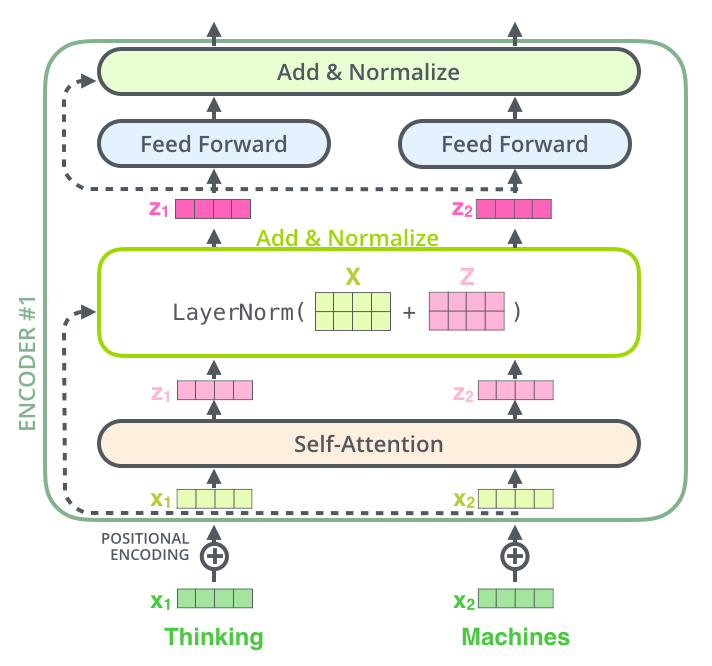
九、殘差連接
在我們繼續(xù)講解之前,編碼器結(jié)構(gòu)中有一個(gè)需要注意的細(xì)節(jié)是:編碼器的每個(gè)子層(Self Attention 層和 FFNN)都有一個(gè)殘差連接和層標(biāo)準(zhǔn)化(layer-normalization)。
十、Decoder(解碼器)
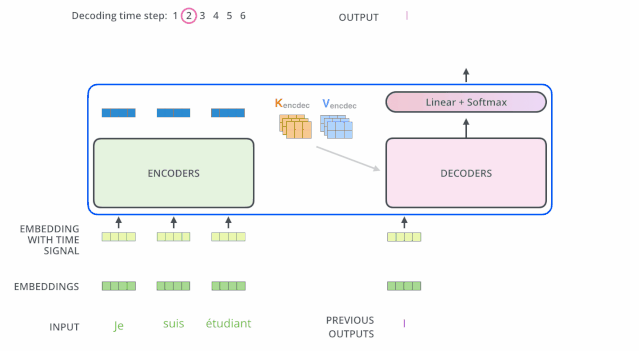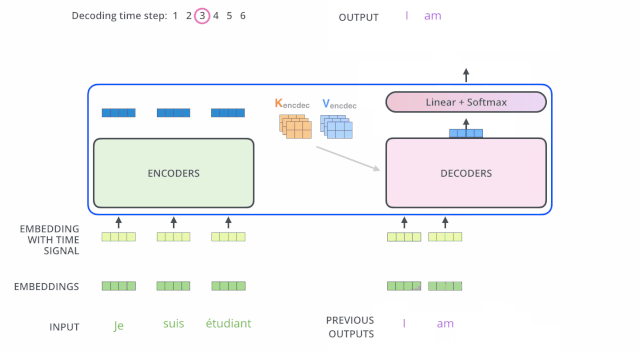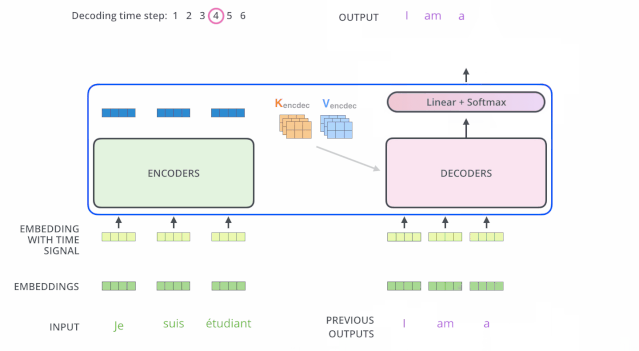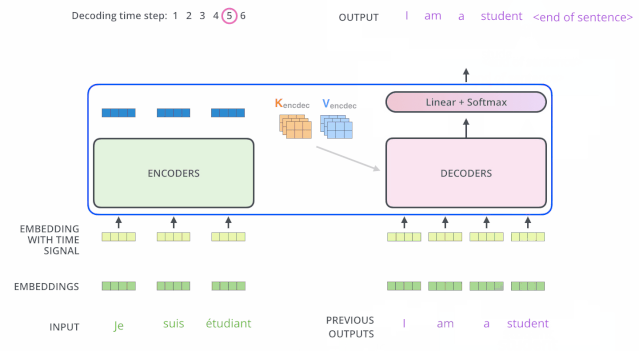
現(xiàn)在我們已經(jīng)介紹了解碼器中的大部分概念,我們也基本知道了解碼器的原理。現(xiàn)在讓我們來看下, 編碼器和解碼器是如何協(xié)同工作的。
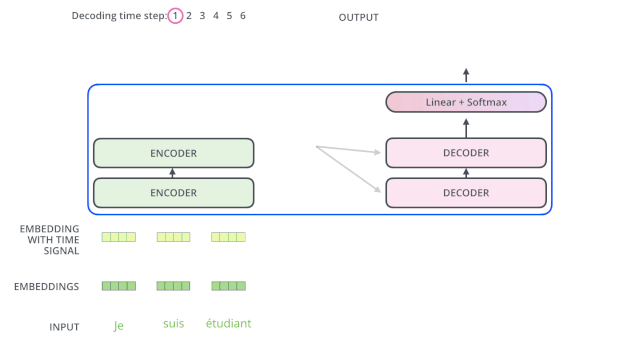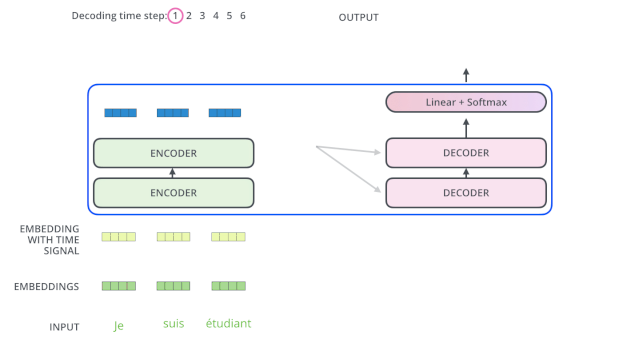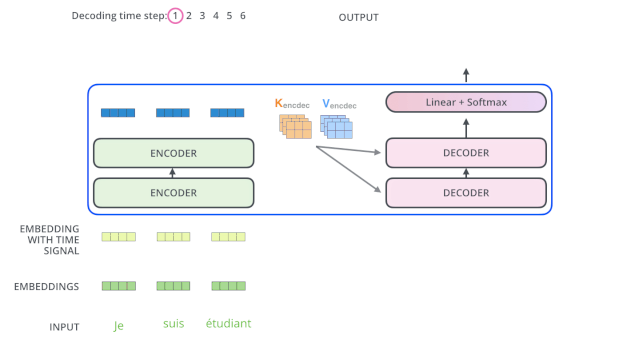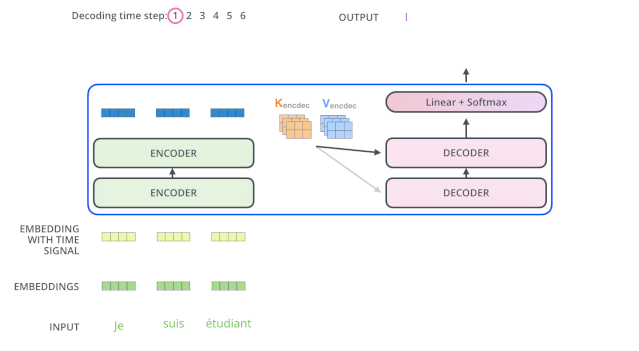
上面說了,編碼器一般有多層,第一個(gè)編碼器的輸入是一個(gè)序列,最后一個(gè)編碼器輸出是一組注意力向量 K 和 V。這些注意力向量將會輸入到每個(gè)解碼器的Encoder-Decoder Attention層,這有助于解碼器把注意力集中中輸入序列的合適位置。
在完成了編碼(encoding)階段之后,我們開始解碼(decoding)階段。解碼(decoding )階段的每一個(gè)時(shí)間步都輸出一個(gè)翻譯后的單詞(這里的例子是英語翻譯)。
接下來會重復(fù)這個(gè)過程,直到輸出一個(gè)結(jié)束符,Transformer 就完成了所有的輸出。每一步的輸出都會在下一個(gè)時(shí)間步輸入到下面的第一個(gè)解碼器。Decoder 就像 Encoder 那樣,從下往上一層一層地輸出結(jié)果。正對如編碼器的輸入所做的處理,我們把解碼器的輸入向量,也加上位置編碼向量,來指示每個(gè)詞的位置。
解碼器中的 Self Attention 層,和編碼器中的 Self Attention 層不太一樣:在解碼器里,Self Attention 層只允許關(guān)注到輸出序列中早于當(dāng)前位置之前的單詞。具體做法是:在 Self Attention 分?jǐn)?shù)經(jīng)過 Softmax 層之前,屏蔽當(dāng)前位置之后的那些位置。
Encoder-Decoder Attention層的原理和多頭注意力(multiheaded Self Attention)機(jī)制類似,不同之處是:Encoder-Decoder Attention層是使用前一層的輸出來構(gòu)造 Query 矩陣,而 Key 矩陣和 Value 矩陣來自于解碼器最終的輸出。
十一、 最后的線性層和 Softmax 層
Decoder 最終的輸出是一個(gè)向量,其中每個(gè)元素是浮點(diǎn)數(shù)。我們怎么把這個(gè)向量轉(zhuǎn)換為單詞呢?這是由 Softmax 層后面的線性層來完成的。
線性層就是一個(gè)普通的全連接神經(jīng)網(wǎng)絡(luò),可以把解碼器輸出的向量,映射到一個(gè)更長的向量,這個(gè)向量稱為 logits 向量。
現(xiàn)在假設(shè)我們的模型有 10000 個(gè)英語單詞(模型的輸出詞匯表),這些單詞是從訓(xùn)練集中學(xué)到的。因此 logits 向量有 10000 個(gè)數(shù)字,每個(gè)數(shù)表示一個(gè)單詞的分?jǐn)?shù)。我們就是這樣去理解線性層的輸出。
然后,Softmax 層會把這些分?jǐn)?shù)轉(zhuǎn)換為概率(把所有的分?jǐn)?shù)轉(zhuǎn)換為正數(shù),并且加起來等于 1)。然后選擇最高概率的那個(gè)數(shù)字對應(yīng)的詞,就是這個(gè)時(shí)間步的輸出單詞。
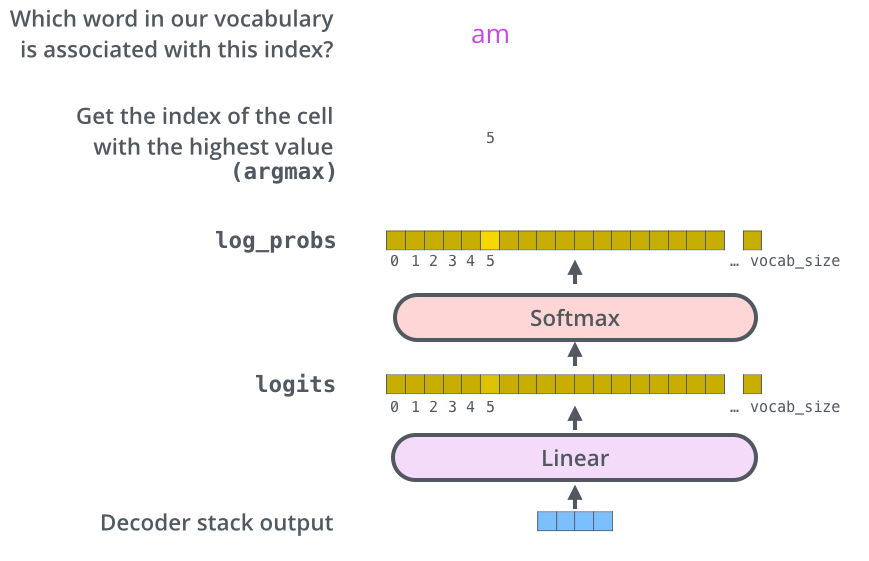
在上圖中,最下面的向量,就是編碼器的輸出,這個(gè)向量輸入到線性層和 Softmax 層,最終得到輸出的詞。
十二、 Transformer 的訓(xùn)練過程
現(xiàn)在我們已經(jīng)了解了 Transformer 的前向傳播過程,下面講講 Transformer 的訓(xùn)練過程,這也是非常有用的知識。
在訓(xùn)練過程中,模型會經(jīng)過上面講的所有前向傳播的步驟。但是,當(dāng)我們在一個(gè)標(biāo)注好的數(shù)據(jù)集上訓(xùn)練這個(gè)模型的時(shí)候,我們可以對比模型的輸出和真實(shí)的標(biāo)簽。
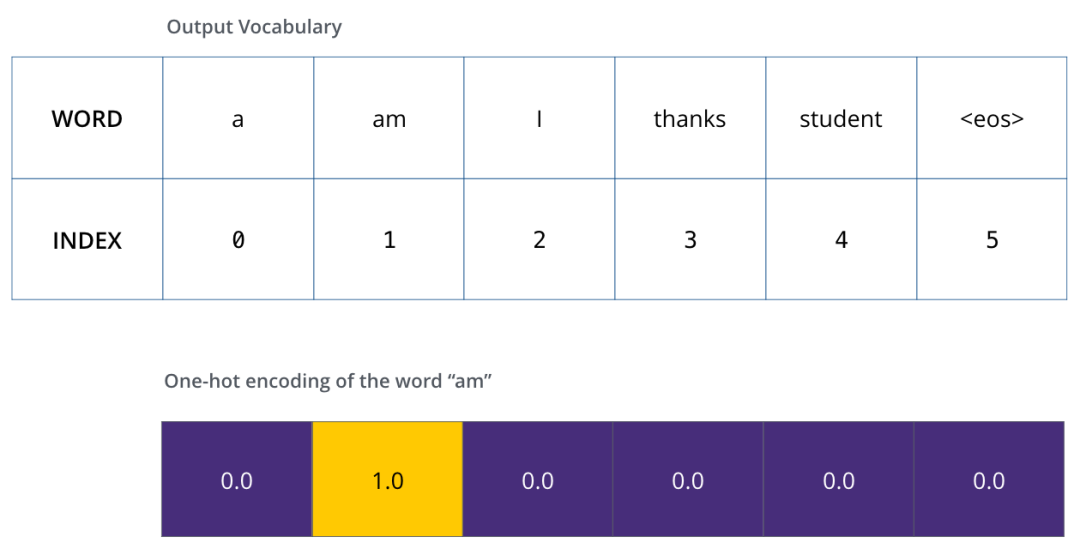
為了可視化這個(gè)對比,讓我們假設(shè)輸出詞匯表只包含 6 個(gè)單詞(“a”, “am”, “i”, “thanks”, “student”, and “
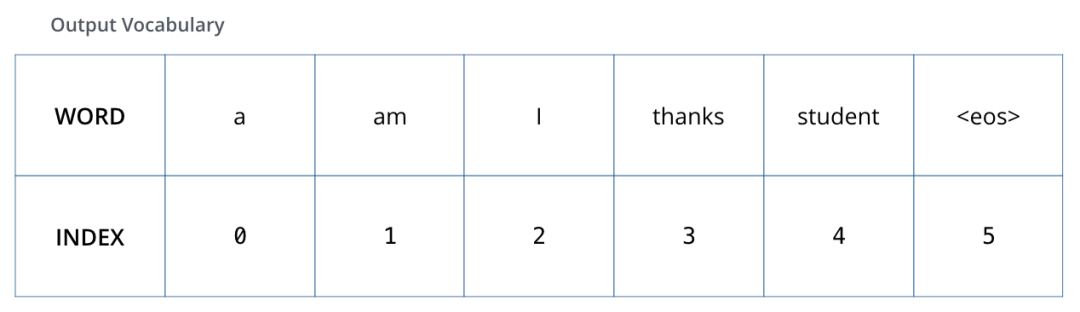
我們模型的輸出詞匯表,是在訓(xùn)練之前的數(shù)據(jù)預(yù)處理階段構(gòu)造的。當(dāng)我們確定了輸出詞匯表,我們可以用向量來表示詞匯表中的每個(gè)單詞。這個(gè)表示方法也稱為 ?one-hot encoding。例如,我們可以把單詞 “am” 用下面的向量來表示:
介紹了訓(xùn)練過程,我們接著討論模型的損失函數(shù),這我們在訓(xùn)練時(shí)需要優(yōu)化的目標(biāo),通過優(yōu)化這個(gè)目標(biāo)來得到一個(gè)訓(xùn)練好的、非常精確的模型。
十三、 損失函數(shù)
用一個(gè)簡單的例子來說明訓(xùn)練過程,比如:把“merci”翻譯為“thanks”。
這意味著我們希望模型最終輸出的概率分布,會指向單詞 ”thanks“(在“thanks”這個(gè)詞的概率最高)。但模型還沒訓(xùn)練好,它輸出的概率分布可能和我們希望的概率分布相差甚遠(yuǎn)。
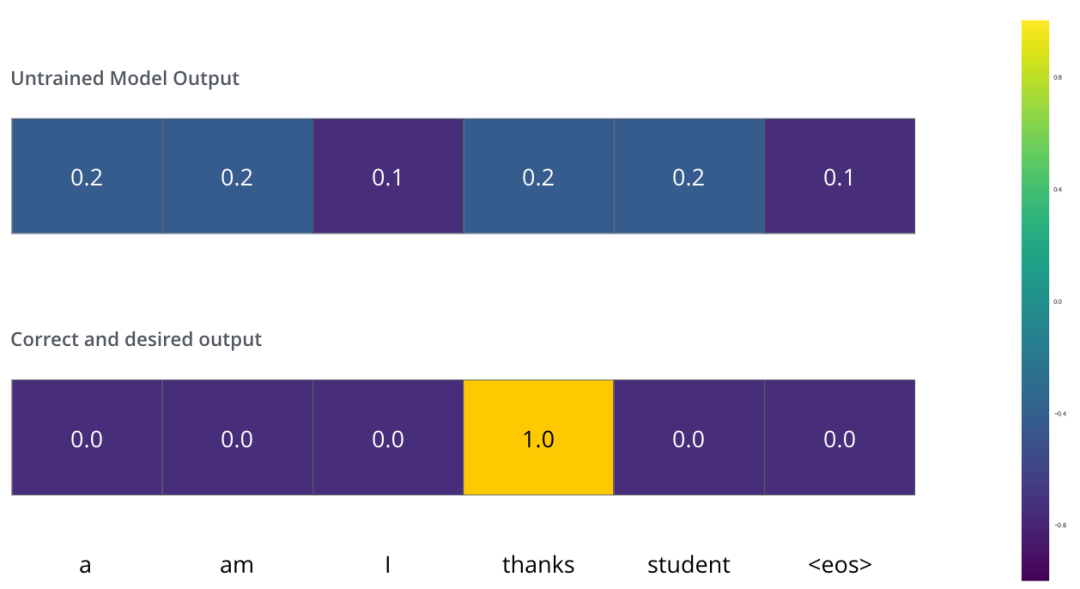
由于模型的參數(shù)都是隨機(jī)初始化的。模型在每個(gè)詞輸出的概率都是隨機(jī)的。我們可以把這個(gè)概率和正確的輸出概率做對比,然后使用反向傳播來調(diào)整模型的權(quán)重,使得輸出的概率分布更加接近震數(shù)輸出。
那我們要怎么比較兩個(gè)概率分布呢?我們可以簡單地用一個(gè)概率分布減去另一個(gè)概率分布。關(guān)于更多細(xì)節(jié),你可以查看交叉熵(cross-entropy)]和KL 散度(Kullback–Leibler divergence)的相關(guān)概念。
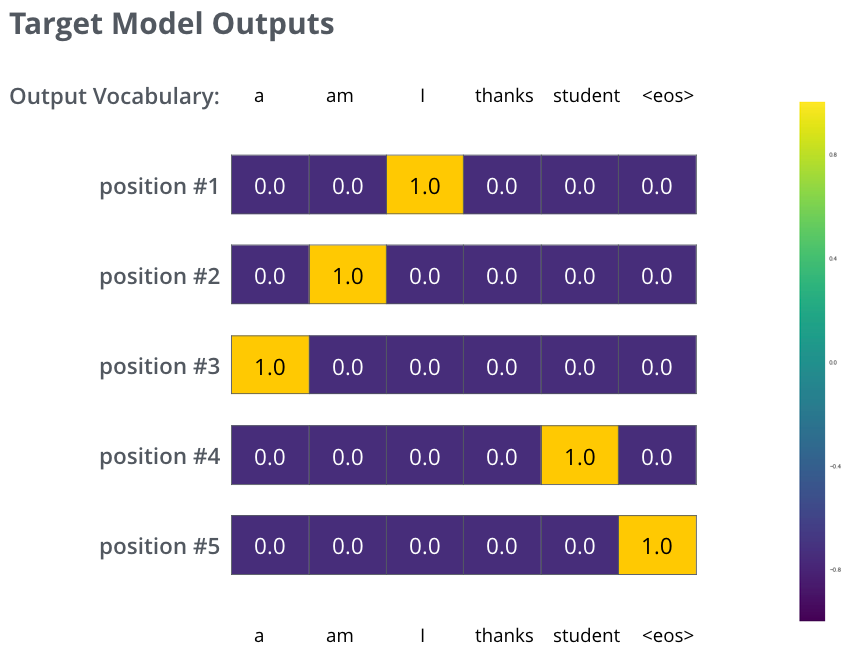
但上面的例子是經(jīng)過簡化的,因?yàn)槲覀兊木渥又挥幸粋€(gè)單詞。在實(shí)際中,我們使用的句子不只有一個(gè)單詞。例如--輸入是:“je suis étudiant” ,輸出是:“i am a student”。這意味著,我們的模型需要輸出多個(gè)概率分布,滿足如下條件:
每個(gè)概率分布都是一個(gè)向量,長度是 vocab_size(我們的例子中,向量長度是 6,但實(shí)際中更可能是 30000 或者 50000) 第一個(gè)概率分布中,最高概率對應(yīng)的單詞是 “i” 第二個(gè)概率分布中,最高概率對應(yīng)的單詞是 “am” 以此類推,直到第 5 個(gè)概率分布中,最高概率對應(yīng)的單詞是 “ ” ,表示沒有下一個(gè)單詞了
我們的模型在一個(gè)足夠大的數(shù)據(jù)集上,經(jīng)過足夠長時(shí)間的訓(xùn)練后,希望輸出的概率分布如下圖所示:
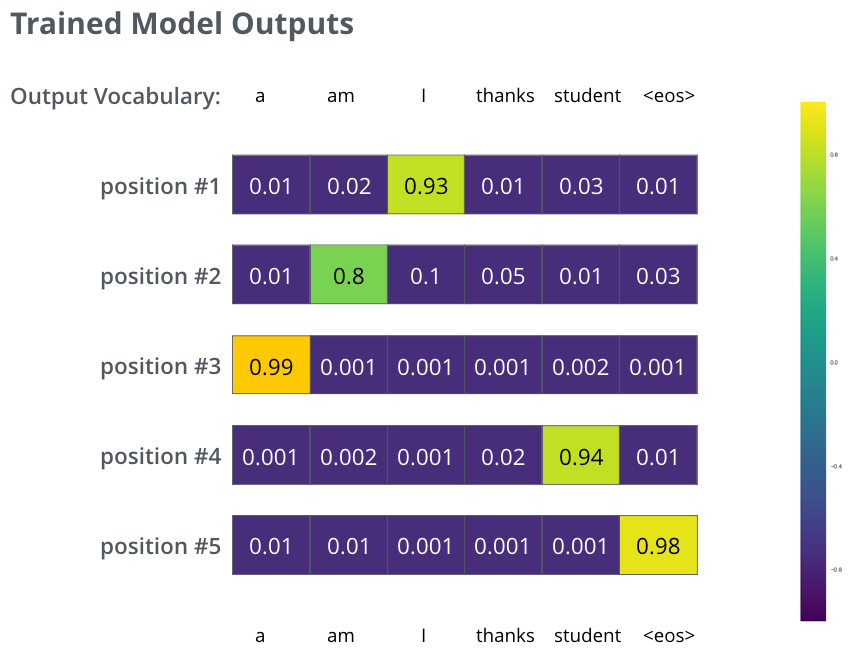
希望經(jīng)過訓(xùn)練,模型會輸出我們希望的正確翻譯。當(dāng)然,如果你要翻譯的句子是訓(xùn)練集中的一部分,那輸出的結(jié)果并不能說明什么。我們希望的是模型在沒見過的句子上也能夠準(zhǔn)確翻譯。需要注意的是:概率分布向量中,每個(gè)位置都會有一點(diǎn)概率,即使這個(gè)位置不是輸出對應(yīng)的單詞--這是 Softmax 中一個(gè)很有用的特性,有助于幫助訓(xùn)練過程。
現(xiàn)在,由于模型每個(gè)時(shí)間步只產(chǎn)生一個(gè)輸出,我們可以認(rèn)為:模型是從概率分布中選擇概率最大的詞,并且丟棄其他詞。這種方法叫做貪婪解碼(greedy decoding)。另一種方法是每個(gè)時(shí)間步保留兩個(gè)最高概率的輸出詞,然后在下一個(gè)時(shí)間步,重復(fù)執(zhí)行這個(gè)過程:假設(shè)第一個(gè)位置概率最高的兩個(gè)輸出的詞是”I“和”a“,這兩個(gè)詞都保留,然后根據(jù)第一個(gè)詞計(jì)算第二個(gè)位置的詞的概率分布,再取出 2 個(gè)概率最高的詞,對于第二個(gè)位置和第三個(gè)位置,我們也重復(fù)這個(gè)過程。這種方法稱為集束搜索(beam search),在我們的例子中,beam_size 的值是 2(含義是:在所有時(shí)間步,我們保留兩個(gè)最高概率),top_beams 的值也是 2(表示我們最終會返回兩個(gè)翻譯的結(jié)果)。beam_size ?和 top_beams 都是你可以在實(shí)驗(yàn)中嘗試的超參數(shù)。
更進(jìn)一步理解
我希望上面講的內(nèi)容,可以幫助你理解 Transformer 中的主要概念。如果你想更深一步地理解,我建議你可以參考下面這些:
閱讀 Transformer 的論文:
《Attention Is All You Need》
鏈接地址:https://arxiv.org/abs/1706.03762閱讀Transformer 的博客文章:
《Transformer: A Novel Neural Network Architecture for Language Understanding》
鏈接地址:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html閱讀《Tensor2Tensor announcement》
鏈接地址:https://ai.googleblog.com/2017/06/accelerating-deep-learning-research.html觀看視頻 【?ukasz Kaiser’s talk】來理解模型和其中的細(xì)節(jié)
鏈接地址:https://www.youtube.com/watch?v=rBCqOTEfxvg運(yùn)行這份代碼:【Jupyter Notebook provided as part of the Tensor2Tensor repo】
鏈接地址:https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb。查看這個(gè)項(xiàng)目:【Tensor2Tensor repo】
鏈接地址:https://github.com/tensorflow/tensor2tensor
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群請掃碼: