
Python正則匹配必須掌握的10個(gè)函數(shù)
正則表達(dá)re模塊共有12個(gè)函數(shù),我將分類進(jìn)行講解,這樣方便記憶與理解,先來看看概覽:
search、match、fullmatch:查找一個(gè)匹配項(xiàng)
findall、finditer:查找多個(gè)匹配項(xiàng)
split:分割
sub,subn:替換
compile函數(shù)、template函數(shù): 將正則表達(dá)式的樣式編譯為一個(gè) 正則表達(dá)式對(duì)象
print(dir(re))[...... 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall','finditer', 'fullmatch', 'functools', 'match', 'purge', 'search','split', 'sre_compile', 'sre_parse', 'sub', 'subn', 'template']
一、查找一個(gè)匹配項(xiàng)
查找并返回一個(gè)匹配項(xiàng)的函數(shù)有3個(gè):search、match、fullmatch,他們的作用分別是:
search:查找任意位置的匹配項(xiàng)
match:必須從字符串開頭匹配
fullmatch:整個(gè)字符串與正則完全匹配
1) search()
描述:在給定字符串中尋找第一個(gè)匹配正則表達(dá)式的子字符串,如果找到會(huì)返回一個(gè)Match對(duì)象,這個(gè)對(duì)象中的元素可以group()得到(之后將會(huì)介紹group的概念),如果沒找到就會(huì)返回None。調(diào)用re.match,re.search方法或者對(duì)re.finditer結(jié)果進(jìn)行遍歷,輸出的結(jié)果都是re.Match對(duì)象
語法:re.search(pattern, string, flags=0)
pattern 匹配的正則表達(dá)式
string 要匹配的字符串
flags 標(biāo)志位,用于控制正則表達(dá)式的匹配方式
re.search(r"(\w)(.\d)","as.21").group()
's.2'
假設(shè)返回的Match對(duì)象為m,m.group()來取某組的信息,group(1)返回與第一個(gè)子模式匹配的單個(gè)字符串,group(2)等等以此類推,start()方法得到對(duì)應(yīng)組的開始索引,end()得到對(duì)應(yīng)組的結(jié)束索引,span()以元組形式給出對(duì)應(yīng)組的開始和結(jié)束位置,括號(hào)中填入組號(hào),不填入組號(hào)時(shí)默認(rèn)為0。
匹配對(duì)象m方法有很多,幾個(gè)常用的方法如下:
m.start()?返回匹配到的字符串的起使字符在原始字符串的索引
m.end()?返回匹配到的字符串的結(jié)尾字符在原始字符串的索引
m.group()?返回指定組的匹配結(jié)果
m.groups()?返回所有組的匹配結(jié)果
m.span() 以元組形式給出對(duì)應(yīng)組的開始和結(jié)束位置
其中的組,是指用()括號(hào)括起來的匹配到的對(duì)象,比如下列中的"(\w)(.\d)",就是兩個(gè)組,第一個(gè)組匹配字母,第二個(gè)組匹配.+一個(gè)數(shù)字。
m?=?re.search(r"(\w)(.\d)","as.21")m1 , 4), match='s.2'>m.group()s.2m.group(0)'s.2'm.group(1) #根據(jù)要求返回特定子組's'm.group(2)'.2'm.start()1m.start(2)#第二個(gè)組匹配的索引位置2m.groups()('s',?'.21')m.span()(1, 5)
2) match()
描述:必須從字符串開頭匹配,同樣返回的是Match對(duì)象,對(duì)應(yīng)的方法與search方法一致,此處不再贅述。
語法:re.match(pattern, string, flags=0)
pattern ? 匹配的正則表達(dá)式
string ?要匹配的字符串
flags ? 標(biāo)志位,用于控制正則表達(dá)式的匹配方式,如:是否區(qū)分大小寫,多行匹配等等
#從頭開始匹配,返回一個(gè)數(shù)字,發(fā)現(xiàn)報(bào)錯(cuò),無法返回,因?yàn)椴皇菙?shù)字開頭的text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.match(pattern,text).group()AttributeError: 'NoneType' object has no attribute 'group'#從頭開始匹配,返回一個(gè)單詞,正常返回了開頭的單詞text = 'chi13putao14butu520putaopi666'pattern = r'[a-z]+'re.match(pattern,text).group()'chi'
3) fullmatch()
描述:整個(gè)字符串與正則完全匹配,同樣返回的是Match對(duì)象,對(duì)應(yīng)的方法與search方法一致,此處不再贅述
語法:(pattern, string, flags=0)
pattern ? 匹配的正則表達(dá)式
string ?要匹配的字符串
flags ? 標(biāo)志位,用于控制正則表達(dá)式的匹配方式,如:是否區(qū)分大小寫,多行匹配等等
#必須要全部符合條件才能匹配
re.fullmatch(r'[a-z]+','chiputao14').group()AttributeError:?'NoneType'?object?has?no?attribute?'group're.fullmatch(r'[a-z]+','chiputao').group()'chiputao'
二、查找多個(gè)匹配項(xiàng)
講完查找一項(xiàng),現(xiàn)在來看看查找多項(xiàng)吧,查找多項(xiàng)函數(shù)主要有:findall函數(shù) 與 finditer函數(shù):
1)findall: 從字符串任意位置查找,返回一個(gè)列表
2)finditer:從字符串任意位置查找,返回一個(gè)迭代器
兩個(gè)函數(shù)功能基本類似,只不過一個(gè)是返回列表,一個(gè)是返回迭代器。我們知道列表是一次性生成在內(nèi)存中,而迭代器是需要使用時(shí)一點(diǎn)一點(diǎn)生成出來的,運(yùn)行時(shí)占用內(nèi)存更小。如果存在大量的匹配項(xiàng)的話,建議使用finditer函數(shù),一般情況使兩個(gè)函數(shù)不會(huì)有太大的區(qū)別。
1)findall
描述:返回字符串里所有不重疊的模式串匹配,以字符串列表的形式出現(xiàn)。
語法:re.findall(pattern, string, flags=0)
pattern ? 匹配的正則表達(dá)式
string ?要匹配的字符串
flags ? 標(biāo)志位,用于控制正則表達(dá)式的匹配方式,如:是否區(qū)分大小寫,多行匹配等等
import retext = 'Python太強(qiáng)大,我愛學(xué)Python'pattern = 'Python're.findall(pattern,text)['Python', 'Python']#找出下列字符串中的數(shù)字text = 'chi13putao14butu520putaopi666'#\d+表示匹配任意數(shù)字pattern = r'\d+'re.findall(pattern,text)['13',?'14',?'666',?'520']?text = 'ab-abc-a-cccc-d-aabbcc'pattern = 'ab*'re.findall(pattern,text)['ab', 'ab', 'a', 'a', 'abb']#找到所有副詞'''findall() 匹配樣式 所有 的出現(xiàn),不僅是像 search() 中的第一個(gè)匹配。比如,如果一個(gè)作者希望找到文字中的所有副詞,他可能會(huì)按照以下方法用 findall()'''text = "He was carefully disguised but captured quickly by police."re.findall(r"\w+ly", text)['carefully',?'quickly']
2)finditer()
描述:返回一個(gè)產(chǎn)生匹配對(duì)象實(shí)體的迭代器,能產(chǎn)生字符串中所有RE模式串的非重疊匹配。
語法:re.finditer(pattern, string, flags=0)
pattern ? 匹配的正則表達(dá)式
string ?要匹配的字符串
flags ? 標(biāo)志位,用于控制正則表達(dá)式的匹配方式,如:是否區(qū)分大小寫,多行匹配等等
m = re.finditer("Python","Python非常強(qiáng)大,我愛學(xué)習(xí)Python")mfor i in m:print(i.group(0))PythonPython#找到所有副詞和位置'''如果需要匹配樣式的更多信息, finditer() 可以起到作用,它提供了 匹配對(duì)象 作為返回值,而不是字符串。繼續(xù)上面的例子,如果一個(gè)作者希望找到所有副詞和它的位置,可以按照下面方法使用 finditer()'''text = "He was carefully disguised but captured quickly by police."for m in re.finditer(r"\w+ly", text):print('%02d-%02d: %s' % (m.start(), m.end(), m.group(0)))07-16: carefully40-47: quic
三、匹配項(xiàng)分割
1)split()
描述:split能夠按照所能匹配的字串將字符串進(jìn)行切分,返回切分后的字符串列表
形式.切割功能非常強(qiáng)大
語法:re.split(pattern, string, maxsplit=0, flags=0)
pattern:匹配的字符串
string:需要切分的字符串
maxsplit:分隔次數(shù),默認(rèn)為0(即不限次數(shù))
flags:標(biāo)志位,用于控制正則表達(dá)式的匹配方式,flags表示模式,就是上面我們講解的常量!支持正則及多個(gè)字符切割。
正則表達(dá)的分割函數(shù)與字符串的分割函數(shù)一樣,都是split,只是前面的模塊不一樣,正則表達(dá)的函數(shù)為, ,用pattern分開string,maxsplit表示最多進(jìn)行分割次數(shù),
re.split(r";","var A;B;C:integer;")['var A', 'B', 'C:integer', '']re.split(r"[;:]","var A;B;C:integer;")['var A', 'B', 'C', 'integer', '']text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.split(pattern,text)['chi', 'putao', 'butu', 'putaopi', '']line = 'aac bba ccd;dde eef,fff'#單字符切割re.split(r';',line)['aac bba ccd', 'dde eef,fff']#兩個(gè)字符以上切割需要放在 [ ] 中re.split(r'[;,]',line)['aac bba ccd', 'dde eef', 'fff']#所有空白字符切割re.split(r'[;,\s]',line)['aac', 'bba', 'ccd', 'dde', '', '', 'eef', 'fff']#使用括號(hào)捕獲分組,默認(rèn)保留分割符re.split(r'([;])',line)['aac bba ccd', ';', 'dde eef,fff']#不想保留分隔符,以(?:...)的形式指定re.split(r'(?:[;])',line)['aac bba ccd', 'dde eef,fff']#不想保留分隔符,以(?:...)的形式指定re.split(r'(?:[;,\s])',line)['aac', 'bba', 'ccd', 'dde', '', '', 'eef', 'fff']
?
注意:str模塊也有一個(gè)split函數(shù) ,那這兩個(gè)函數(shù)該怎么選呢?str.split函數(shù)功能簡單,不支持正則分割,而re.split支持正則。關(guān)于二者的速度如何?來實(shí)際測試一下,在相同數(shù)據(jù)量的情況下使用re.split函數(shù)與str.split函數(shù)執(zhí)行次數(shù) 與 執(zhí)行時(shí)間 對(duì)比圖:
#運(yùn)行時(shí)間統(tǒng)計(jì) 只計(jì)算了程序運(yùn)行的CPU時(shí)間,且每次測試時(shí)間有所差異
import time#統(tǒng)計(jì)次數(shù)n = 1000``start_t = time.perf_counter()for i in range(n):re.split(r';',line)##re.splitend_t = time.perf_counter()print?('re.split:?'+str(round(1000000*(end_t-start_t),2)))start_t = time.perf_counter()for i in range(n):line.split(';')##str.splitend_t = time.perf_counter()print ('str.split: '+str(round(1000000*(end_t-start_t),2)))
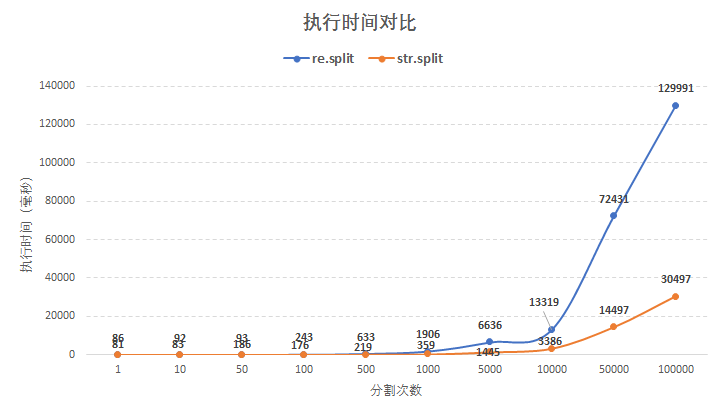
通過上圖對(duì)比發(fā)現(xiàn),5000次循環(huán)以內(nèi)str.split函數(shù)和re.split函數(shù)執(zhí)行時(shí)間差異不大,而循環(huán)次數(shù)1000次以上后str.split函數(shù)明顯更快,而且次數(shù)越多差距越大!
所以結(jié)論是,在不需要正則支持的情況下使用str.split函數(shù)更合適,反之則使用re.split函數(shù)。具體執(zhí)行時(shí)間與測試數(shù)據(jù)有關(guān)!且每次測試時(shí)間有所差異
?
四、匹配項(xiàng)替換
替換主要有sub函數(shù)與subn函數(shù)兩個(gè)函數(shù),他們功能類似,不同點(diǎn)在于sub只返回替換后的字符串,subn返回一個(gè)元組,包含替換后的字符串和替換次數(shù)。
python 里面可以用 replace 實(shí)現(xiàn)簡單的替換字符串操作,如果要實(shí)現(xiàn)復(fù)雜一點(diǎn)的替換字符串操作,需用到正則表達(dá)式。
re.sub用于替換字符串中匹配項(xiàng),返回一個(gè)替換后的字符串,subn方法與sub()相同, 但返回一個(gè)元組, 其中包含新字符串和替換次數(shù)。
sub是substitute表示替換。
1)sub
描述:它的作用是正則替換。
語法:re.sub(pattern, repl, string, count=0, flags=0)
pattern:該參數(shù)表示正則中的模式字符串;
repl:repl可以是字符串,也可以是可調(diào)用的函數(shù)對(duì)象;如果是字符串,則處理其中的反斜杠轉(zhuǎn)義。如果它是可調(diào)用的函數(shù)對(duì)象,則傳遞match對(duì)象,并且必須返回要使用的替換字符串
string:該參數(shù)表示要被處理(查找替換)的原始字符串;
count:可選參數(shù),表示是要替換的最大次數(shù),而且必須是非負(fù)整數(shù),該參數(shù)默認(rèn)為0,即所有的匹配都會(huì)被替換;
flags:可選參數(shù),表示編譯時(shí)用的匹配模式(如忽略大小寫、多行模式等),數(shù)字形式,默認(rèn)為0。
?
把字符串?aaa34bvsa56s中的數(shù)字替換為?*號(hào)
import rere.sub('\d+','*','aaa34bvsa56s')#連續(xù)數(shù)字替換'aaa*bvsa*s're.sub('\d','*','aaa34bvsa56s')#每個(gè)數(shù)字都替換一次'aaa**bvsa**s'#只天換一次count=1,第二次的數(shù)字沒有被替換re.sub('\d+','*','aaa34bvsa56s',count=1)'aaa*bvsa56s'把chi13putao14butu520putaopi666中的數(shù)字換成...text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.sub(pattern,'...',text)'chi...putao...butu...putaopi...'關(guān)于第二個(gè)參數(shù)的用法,我們可以看看下面的內(nèi)容#定義一個(gè)函數(shù)def refun(repl):print(type(repl))return('...')re.sub('\d+',refun,'aaa34bvsa56s')'aaa...bvsa...s'從上面的例子看來,似乎沒啥區(qū)別原字符串中有多少項(xiàng)被匹配到,這個(gè)函數(shù)就會(huì)被調(diào)用幾次。至于傳進(jìn)來的這個(gè)match對(duì)象,我們調(diào)用它的.group()方法,就能獲取到被匹配到的內(nèi)容,如下所示:def refun(repl):print(type(repl),repl.group())return('...')re.sub('\d+',refun,'aaa34bvsa56s')34 56 Out[113]: 'aaa...bvsa...s'這個(gè)功能有什么用呢?我們?cè)O(shè)想有一個(gè)字符串moblie18123456794num123,這個(gè)字符串中有兩段數(shù)字,并且長短是不一樣的。第一個(gè)數(shù)字是11位的手機(jī)號(hào)。我想把字符串替換為:moblie[隱藏手機(jī)號(hào)]num***。不是手機(jī)號(hào)的數(shù)字,每一位數(shù)字逐位替換為星號(hào)。def refun(repl):if len(repl.group()) == 11:return '[隱藏手機(jī)號(hào)]'else:return '*' * len(repl.group())re.sub('\d+', refun, 'moblie18217052373num123')'moblie[隱藏手機(jī)號(hào)]num***'
?
2)subn
描述:函數(shù)與 re.sub函數(shù) 功能一致,只不過返回一個(gè)元組 (字符串, 替換次數(shù))。
語法:re.subn(pattern, repl, string, count=0, flags=0)
參數(shù):同re.sub
re.subn('\d+','*','aaa34bvsa56s')#連續(xù)數(shù)字替換('aaa*bvsa*s', 2)re.subn('\d','*','aaa34bvsa56s')#每個(gè)數(shù)字都替換一次('aaa**bvsa**s', 4)text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.subn(pattern,'...',text)('chi...putao...butu...putaopi...', 4)
五、編譯正則對(duì)象
描述:將正則表達(dá)式的樣式編譯為一個(gè)正則表達(dá)式對(duì)象(正則對(duì)象),可以用于匹配
語法:re.compile(pattern,?flags=0)
參數(shù):
pattern:該參數(shù)表示正則中的模式字符串;
flags:可選參數(shù),表示編譯時(shí)用的匹配模式(如忽略大小寫、多行模式等),數(shù)字形式,默認(rèn)為0。
prog = re.compile(pattern)result = prog.match(string)等價(jià)于result = re.match(pattern, string)
如果需要多次使用這個(gè)正則表達(dá)式的話,使用re.compile()和保存這個(gè)正則對(duì)象以便復(fù)用,可以讓程序更加高效。
六、轉(zhuǎn)義函數(shù)
re.escape(pattern) 可以轉(zhuǎn)義正則表達(dá)式中具有特殊含義的字符,比如:. 或者 * re.escape(pattern) 看似非常好用省去了我們自己加轉(zhuǎn)義,但是使用它很容易出現(xiàn)轉(zhuǎn)義錯(cuò)誤的問題,所以并不建議使用它轉(zhuǎn)義,而建議大家自己手動(dòng)轉(zhuǎn)義!
七、緩存清除函數(shù)
re.purge()函數(shù)作用就是清除正則表達(dá)式緩存,清除后釋放內(nèi)存。
···? END? ···