
用了 Elasticsearch 后,查詢起飛了!


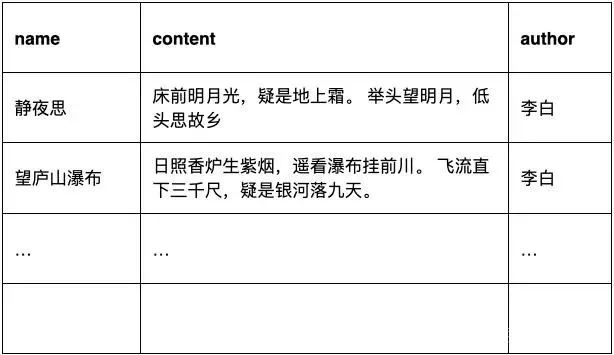
select?name?from?poems?where?content?like?"%前%";
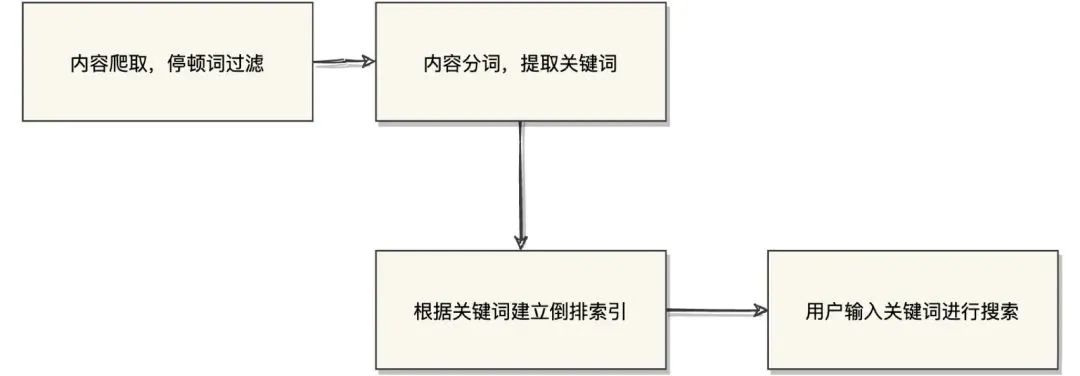
內(nèi)容爬取,停頓詞過濾,比如一些無用的像"的",“了”之類的語氣詞/連接詞
內(nèi)容分詞,提取關(guān)鍵詞
根據(jù)關(guān)鍵詞建立倒排索引
用戶輸入關(guān)鍵詞進(jìn)行搜索
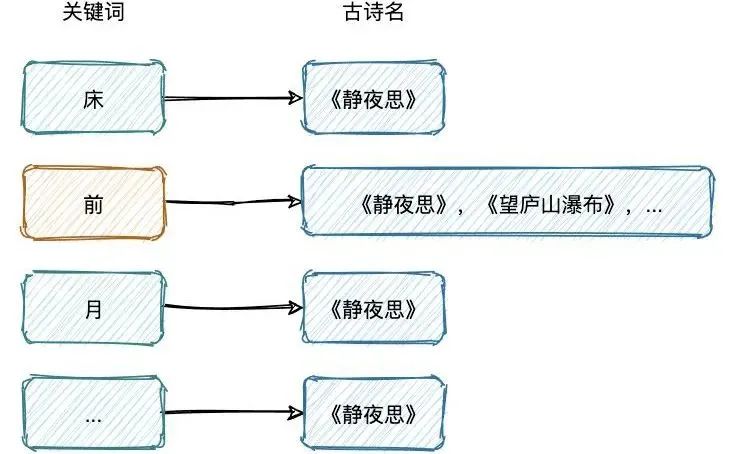
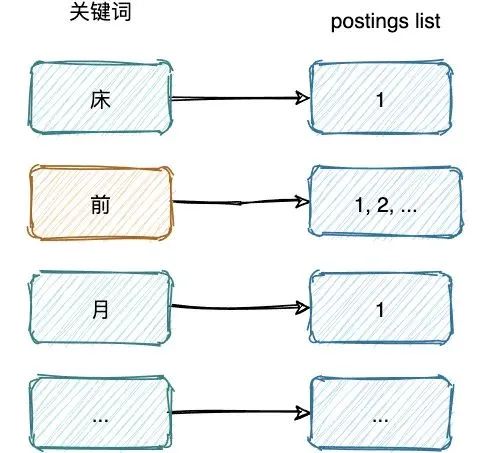
空間占用小,通過對(duì)詞典中單詞前綴和后綴的重復(fù)利用,壓縮了存儲(chǔ)空間
查詢速度快,O(len(str)) 的查詢時(shí)間復(fù)雜度。
postings list 如果不進(jìn)行壓縮,會(huì)非常占用磁盤空間
聯(lián)合查詢下,如何快速求交并集(intersections and unions)

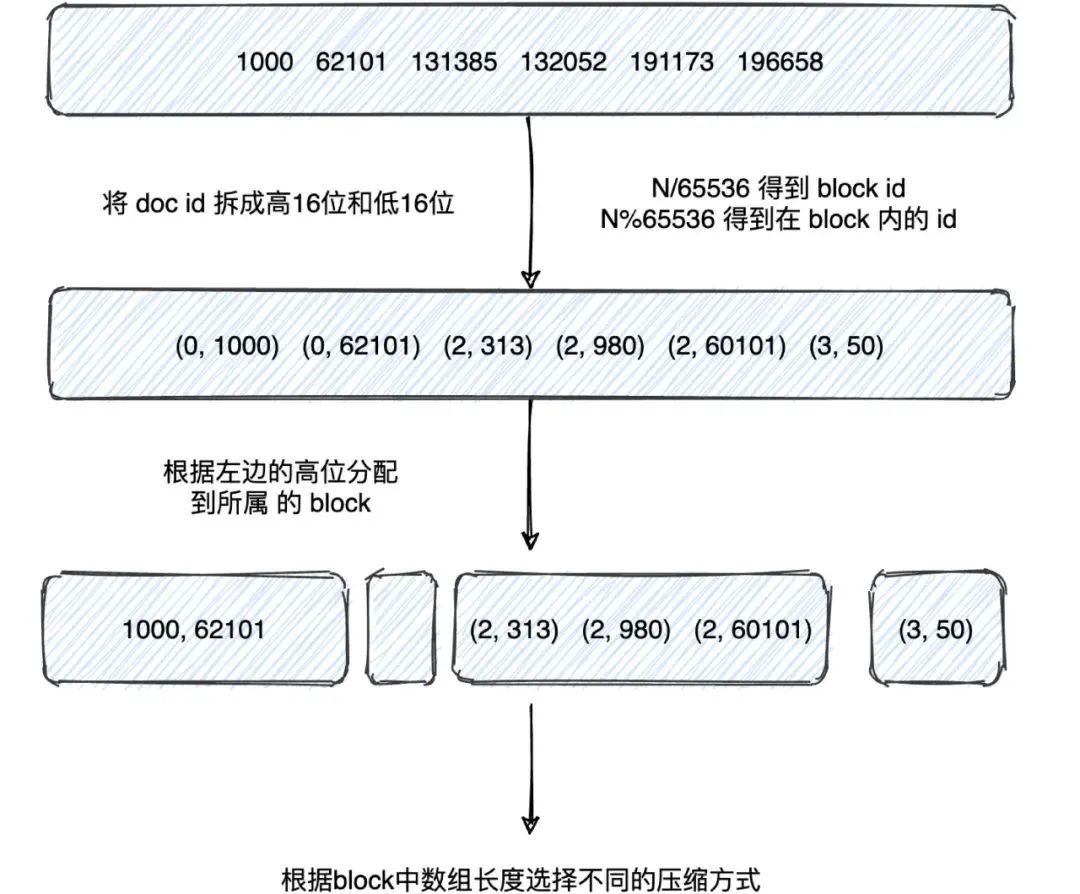
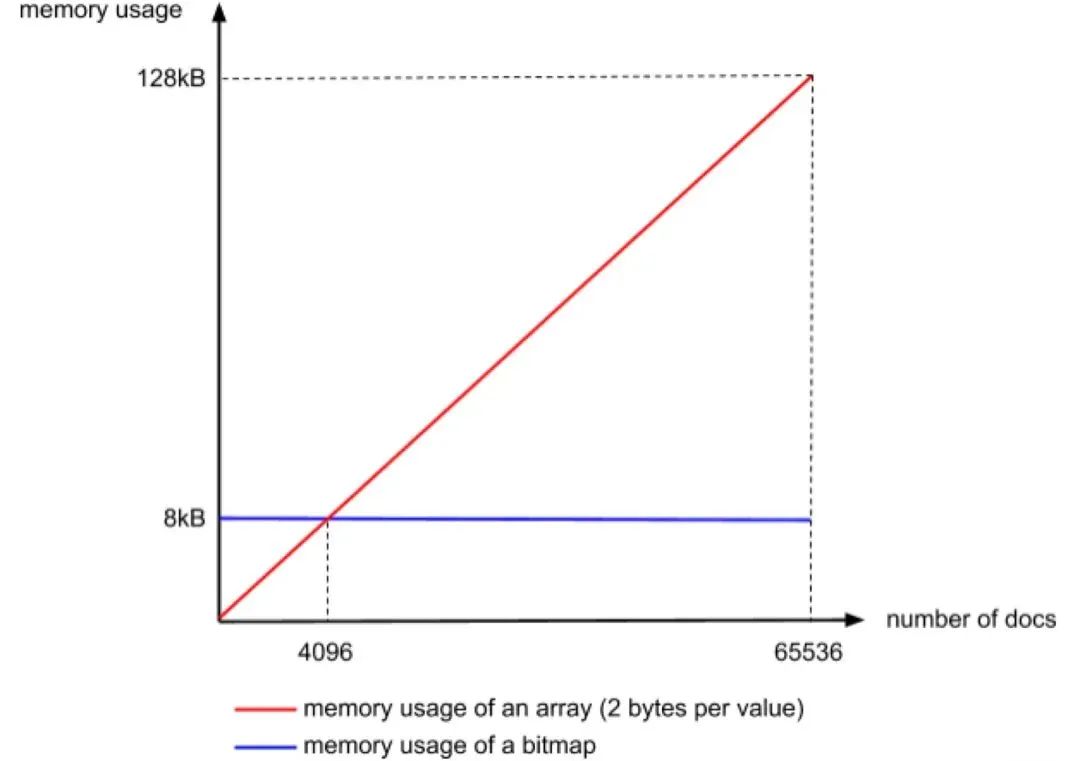
len<4096 ArrayContainer 直接存值
len>=4096 BitmapContainer 使用 bitmap 存儲(chǔ)
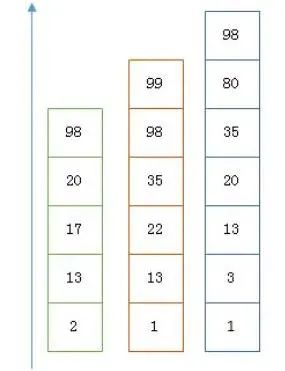
高位聚合(假設(shè)數(shù)據(jù)中有 100w 個(gè)高位相同的值,原先需要 100w_2byte,現(xiàn)在只要 1_2byte)
低位壓縮
為了能夠快速定位到目標(biāo)文檔,ES 使用倒排索引技術(shù)來優(yōu)化搜索速度,雖然空間消耗比較大,但是搜索性能提高十分顯著。
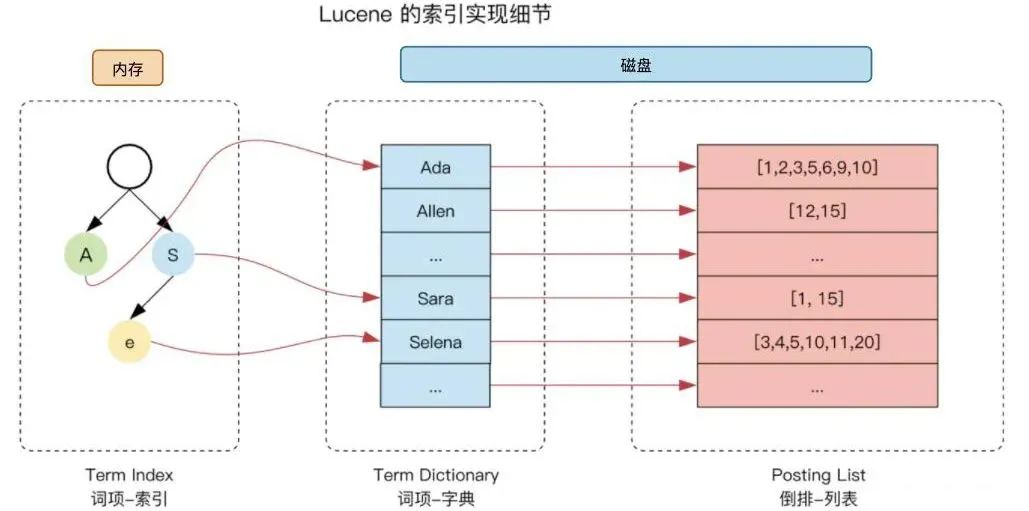
為了能夠在數(shù)量巨大的 terms 中快速定位到某一個(gè) term,同時(shí)節(jié)約對(duì)內(nèi)存的使用和減少磁盤 io 的讀取,lucene 使用“term index -> term dictionary -> postings list”的倒排索引結(jié)構(gòu),通過 FST 壓縮放入內(nèi)存,進(jìn)一步提高搜索效率。
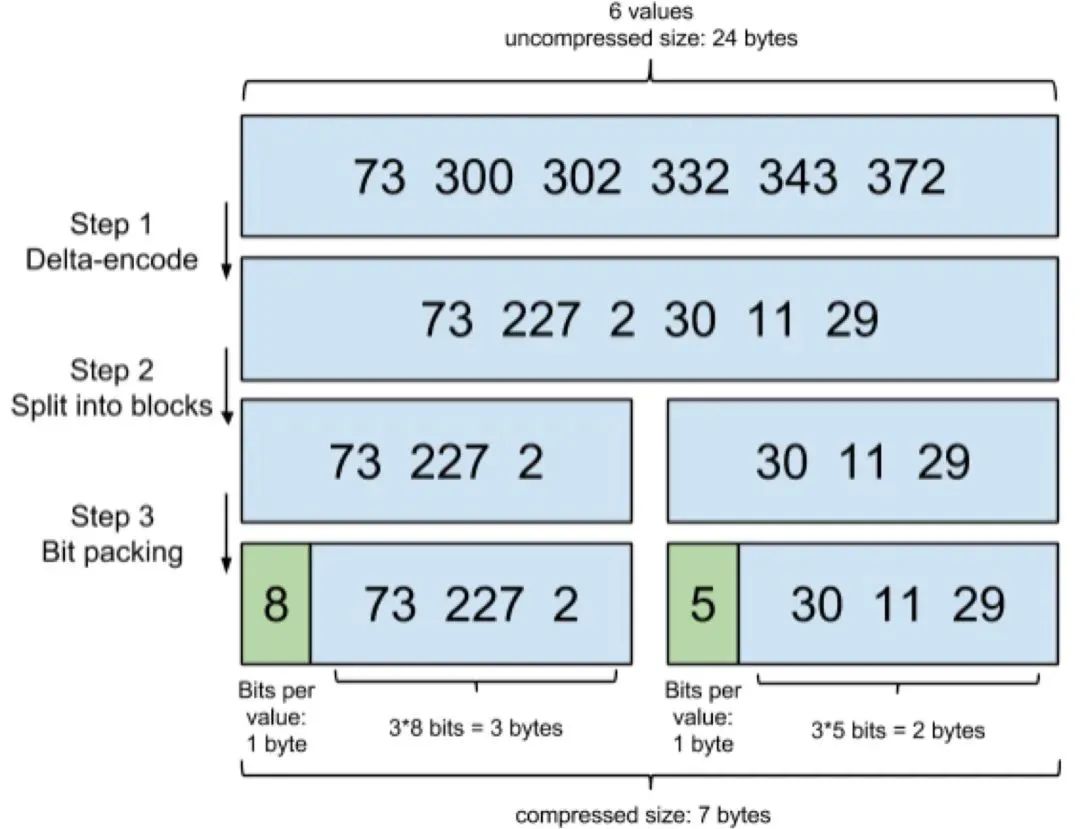
為了減少 postings list 的磁盤消耗,Lucene 使用了 FOR(Frame of Reference)技術(shù)壓縮,帶來的壓縮效果十分明顯。
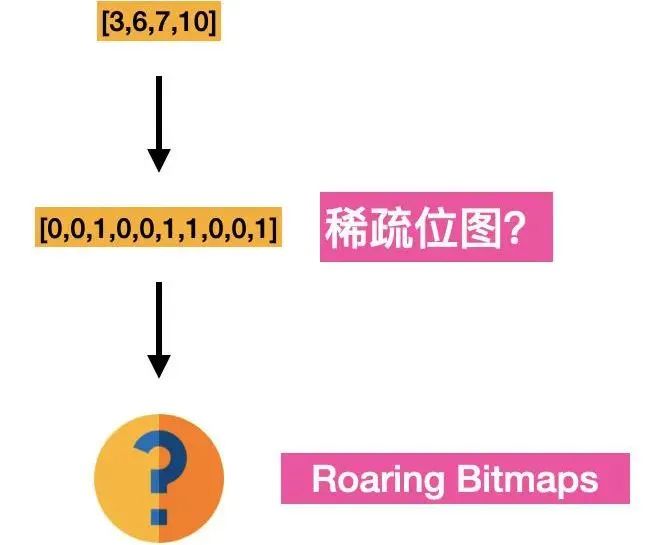
ES 的 filter 語句采用了 Roaring Bitmap 技術(shù)來緩存搜索結(jié)果,保證高頻 filter 查詢速度的同時(shí)降低存儲(chǔ)空間消耗。
在聯(lián)合查詢時(shí),在有 filter cache 的情況下,會(huì)直接利用位圖的原生特性快速求交并集得到聯(lián)合查詢結(jié)果,否則使用 skip list 對(duì)多個(gè) postings list 求交并集,跳過遍歷成本并且節(jié)省部分?jǐn)?shù)據(jù)的解壓縮 CPU 成本。
不需要索引的字段,一定要明確定義出來,因?yàn)槟J(rèn)是自動(dòng)建索引的
同樣的道理,對(duì)于 String 類型的字段,不需要 analysis 的也需要明確定義出來,因?yàn)槟J(rèn)也是會(huì) analysis 的
選擇有規(guī)律的 ID 很重要,隨機(jī)性太大的 ID(比如 Java 的 UUID)不利于查詢
https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps
https://www.elastic.co/cn/blog/found-elasticsearch-from-the-bottom-up
http://blog.mikemccandless.com/2014/05/choosing-fast-unique-identifier-uuid.html
https://www.infoq.cn/article/database-timestamp-02
https://zhuanlan.zhihu.com/p/137574234
最近面試BAT,整理一份面試資料《Java面試BAT通關(guān)手冊》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。 獲取方式:關(guān)注公眾號(hào)并回復(fù)?java?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。 明天見(??ω??)??