
如何實現(xiàn)一個高效的Softmax CUDA kernel?——OneFlow 性能優(yōu)化分享
Softmax操作是深度學習模型中最常用的操作之一。在深度學習的分類任務中,網(wǎng)絡最后的分類器往往是Softmax + CrossEntropy的組合:
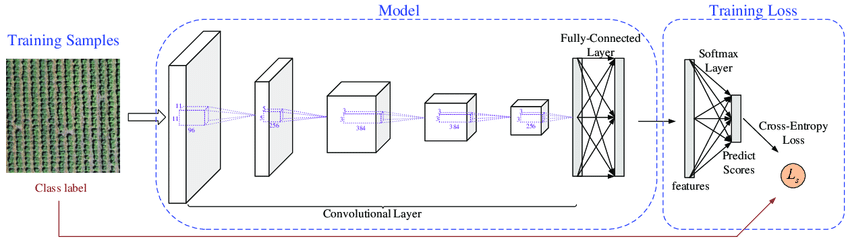
盡管當Softmax和CrossEntropy聯(lián)合使用時,其數(shù)學推導可以約簡,但還是有很多場景會單獨使用Softmax Op。如BERT的Encoder每一層的attention layer中就單獨使用了Softmax求解attention的概率分布;GPT-2的attention的multi-head部分也單獨使用了Softmax 等等。
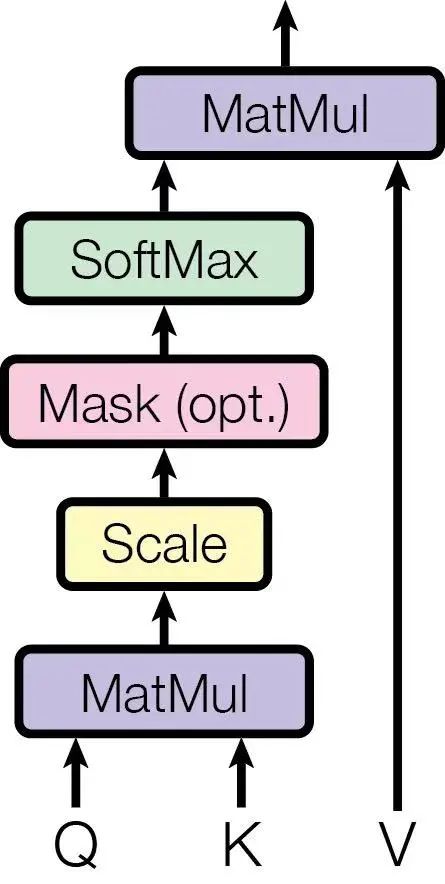
深度學習框架中的所有計算的算子都會轉化為GPU上的CUDA kernel function,Softmax操作也不例外。Softmax作為一個被大多數(shù)網(wǎng)絡廣泛使用的算子,其CUDA Kernel實現(xiàn)高效性會影響很多網(wǎng)絡最終的訓練速度。那么如何實現(xiàn)一個高效的Softmax CUDA Kernel?本文將會介紹OneFlow中優(yōu)化的Softmax CUDA Kernel的技巧,并跟cuDNN中的Softmax操作進行實驗對比,結果表明,OneFlow深度優(yōu)化后的Softmax對顯存帶寬的利用率可以接近理論上限,遠高于cuDNN的實現(xiàn)。
GPU基礎知識與CUDA性能優(yōu)化原則
對GPU基礎知識的介紹以及CUDA性能優(yōu)化的原則與目標可以參考之前的文章:《開源100天,OneFlow送上“百天大禮包”:深度學習框架如何進行性能優(yōu)化?》
其中簡單介紹了GPU的硬件結構與執(zhí)行原理:
Kernel:即CUDA Kernel function,是GPU的基本計算任務描述單元。每個Kernel都會根據(jù)配置參數(shù)在GPU上由非常多個線程并行執(zhí)行,GPU計算高效就是因為同時可以由數(shù)千個core(thread)同時執(zhí)行,計算效率遠超CPU。
GPU的線程在邏輯上分為Thread、Block、Grid三級,硬件上分為core、warp兩級;
GPU內存分為Global memory、Shared memory、Local memory三級。
GPU最主要提供的是兩種資源:計算資源 和 顯存帶寬資源。如果我們能將這兩種資源充分利用,且對資源的需求無法再降低,那么性能就優(yōu)化到了極限,執(zhí)行時間就會最短。在大多數(shù)情況下,深度學習訓練中的GPU計算資源是被充分利用的,而一個GPU CUDA Kernel的優(yōu)化目標就是盡可能充分利用顯存帶寬資源。
如何評估一個CUDA Kernel是否充分利用了顯存帶寬資源?
對于顯存帶寬資源來說,“充分利用“指的是Kernel的有效顯存讀寫帶寬達到了設備顯存帶寬的上限,其中設備顯存帶寬可以通過執(zhí)行 cuda中的的bandwidthTest得到。Kernel的有效顯存帶寬通過Kernel讀寫數(shù)據(jù)量和Kernel執(zhí)行時間進行評估:

Naive的Softmax實現(xiàn)
在介紹優(yōu)化技巧之前,我們先看看一個未經優(yōu)化的Softmax Kernel的最高理論帶寬是多少。如下圖所示,一個最簡單的Softmax計算實現(xiàn)中,分別調用幾個基礎的CUDA Kernel function來完成整體的計算:
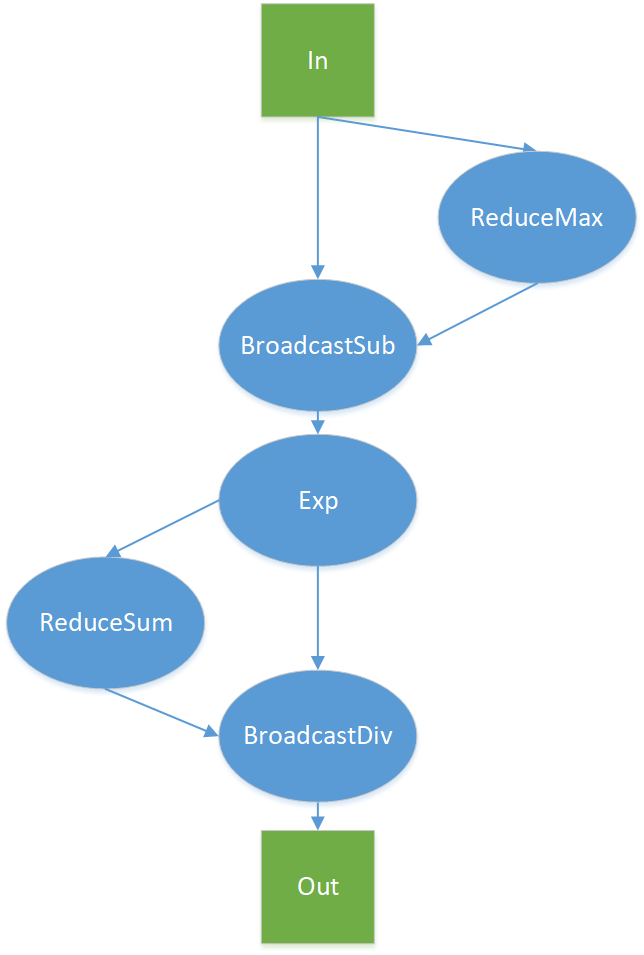
假設輸入的數(shù)據(jù)大小為D,shape = (num_rows, num_cols), 即 D = num_rows * num_cols ,最Navie的操作會多次訪問Global memory,其中:
ReduceMax =
D + num_rows(read 為 D, write 為 num_rows)BroadcaseSub =
2 * D + num_rows(read 為 D + num_rows,write 為 D)Exp =
2 * D(read 、write 均為D)ReduceSum =
D + num_rows(read 為 D, write 為 num_rows)BroadcastDive =
2 * D + num_rows(read 為 D + num_rows, write 為 D)
總共需要8 * D + 4 * num_rows 的訪存開銷。由于num_rows相比于D可以忽略,則Navie版本的Softmax CUDA Kernel需要訪問至少8倍數(shù)據(jù)的顯存,即:
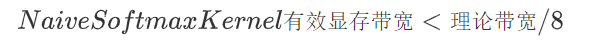
對于GeForce RTX? 3090顯卡,其理論帶寬上限為936GB/s,那么Navie版本的Softmax CUDA Kernel利用顯存帶寬的上界就是936 / 8 = 117 GB/s。
在之前的文章里,我們在方法:借助shared memory合并帶有Reduce計算的Kernel中提到了對Softmax Kernel的訪存優(yōu)化到了 2 * D,但這仍然沒有優(yōu)化到極致。在本文的優(yōu)化后,大多數(shù)場景下OneFlow的Softmax CUDA Kernel的顯存帶寬利用可以逼近理論帶寬。
OneFlow 與 cuDNN 的對比結果
我們對OneFlow深度優(yōu)化后的Softmax CUDA Kernel 與 cuDNN中的Softmax Kernel的訪存帶寬進行了對比測試,測試結果如下:
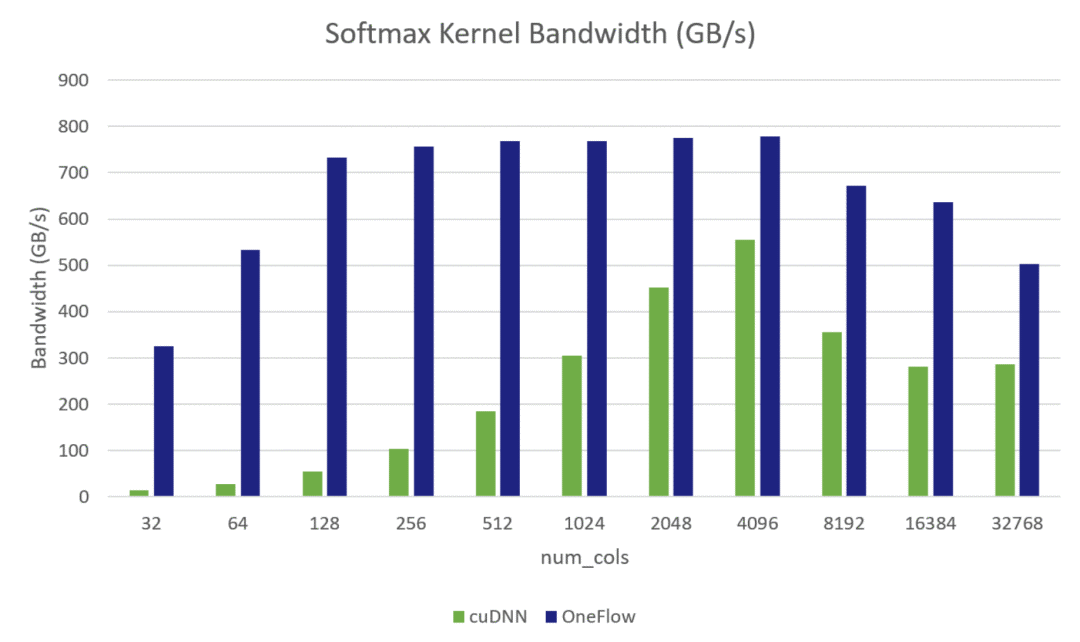
Softmax Kernel Bandwidth:
Softmax Grad Kernel Bandwidth:
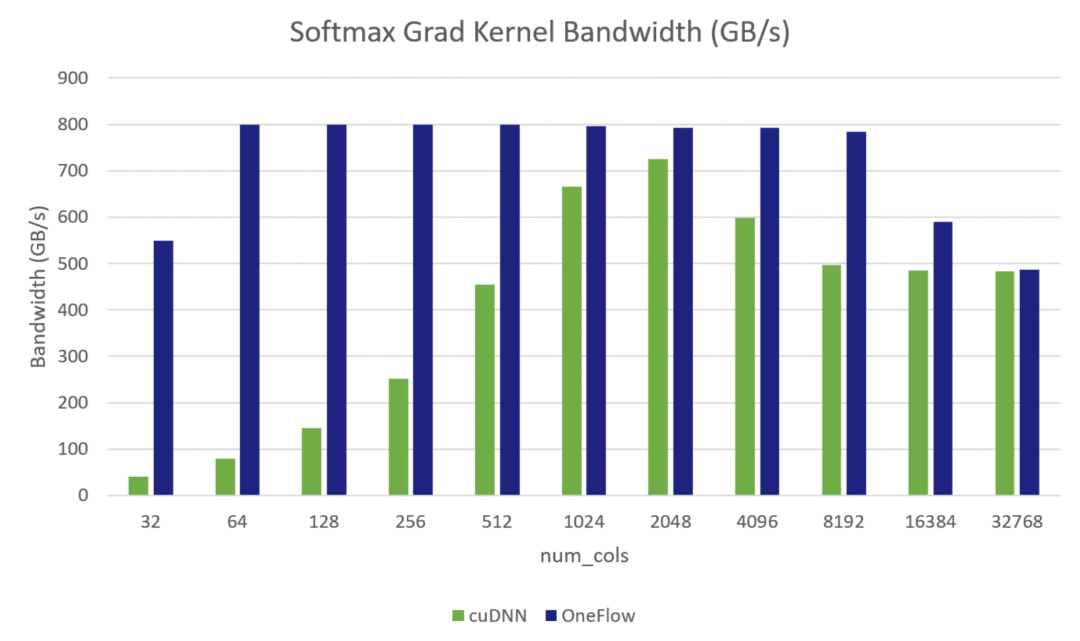
其中測試環(huán)境是 GeForce RTX? 3090 GPU,數(shù)據(jù)類型是half,Softmax的Shape = (49152, num_cols),其中49152 = 32 * 12 * 128,是BERT-base網(wǎng)絡中的attention Tensor的前三維,我們固定了前三維,將最后一維動態(tài)變化,測試了從32到32768不同大小的Softmax前向Kernel和反向Kernel的有效顯存帶寬。從上面兩張圖中可以看出OneFlow在多數(shù)情況下都可以逼近理論帶寬(800GB/s左右,與cudaMemcpy的訪存帶寬相當。官方公布的理論帶寬為936GB/S)。并且在所有情況下,OneFlow的CUDA Kernel的有效訪存帶寬都優(yōu)于cuDNN的實現(xiàn)。
OneFlow深度優(yōu)化Softmax CUDA Kernel的技巧
Softmax 函數(shù)的輸入形狀為:(num_rows, num_cols),num_cols的變化,會對有效帶寬產生影響;因為,沒有一種 通用 的優(yōu)化方法可以實現(xiàn)在所有 num_cols的情況下都是傳輸最優(yōu)的。所以,在 OneFlow 中采用分段函數(shù)優(yōu)化SoftmaxKernel:對于不同 num_cols范圍,選擇不同的實現(xiàn),以在所有情況下都能達到較高的有效帶寬。見 Optimize softmax cuda kernel
(https://github.com/Oneflow-Inc/oneflow/pull/4058)
OneFlow 中分三種實現(xiàn),分段對 softmax 進行優(yōu)化:
(1) 一個 Warp 處理一行的計算,適用于 num_cols <= 1024 情況
硬件上并行執(zhí)行的32個線程稱之為一個warp,同一個warp的32個thread執(zhí)行同一條指令。warp是GPU調度執(zhí)行的基本單元
(2) 一個 Block 處理一行的計算,借助 Shared Memory 保存中間結果數(shù)據(jù),適用于需要的 Shared Memory 資源滿足 Kernel Launch 的可啟動條件的情況,在本測試環(huán)境中是 1024 < num_cols <= 4096
(3) 一個 Block 處理一行的計算,不使用 Shared Memory,重復讀輸入 x,適用于不支持(1)、(2)的情況
下面以前向計算為例分別對三種實現(xiàn)進行介紹:
實現(xiàn)1:每個Warp處理一行元素
每個 Warp 處理一行元素,行 Reduce 需要做 Warp 內的 Reduce 操作,這里實現(xiàn) WarpAllReduce 完成 Warp 內各線程間的求 Global Max 和 Global Sum 操作,WarpAllReduce 是利用Warp級別原語 __shfl_xor_sync 實現(xiàn)的,代碼如下。
主體循環(huán)邏輯如下,首先根據(jù) num_cols信息算出每個線程要處理的cols_per_thread,每個線程分配cols_per_thread大小的寄存器,將輸入x讀到寄存器中,后續(xù)計算均從寄存器中讀取。
理論上來說,每個 Warp 處理一行元素的速度是最快的,但是由于需要使用寄存器將輸入x緩存起來,而寄存器資源是有限的,并且在 num_cols>1024 情況下,使用(2)的 shared memory 方法已經足夠快了,因此僅在 num_cols<=1024 時采用 Warp 的實現(xiàn)。
實現(xiàn)2:一個Block處理一行元素
一個 Block 處理一行元素,行 Reduce 需要做 Block 內的 Reduce 操作,需要做 Block 內線程同步,利用 BlockAllReduce 完成 Warp 內各線程間的求 Global Max 和 Global Sum 操作。BlockAllReduce 是借助 Cub 的 BlockReduce 方法實現(xiàn)的,代碼如下:
主體循環(huán)邏輯如下,根據(jù) num_cols算出需要的 Shared Memory 大小作為 Launch Kernel 參數(shù),借助 Shared Memory 保存輸入,后續(xù)計算直接從 Shared Memory 讀取。
由于 SM 內的 Shared Memory 資源同樣有限,因此當 num_cols超過一定范圍,kernel 啟動時申請 Shared Memory 超過最大限制,就會出現(xiàn)無法啟動的問題,因此,僅在調用 cudaOccupancyMaxActiveBlocksPerMultiprocessor 返回值大于0時采用 Shared Memory 方案。
此外,需要注意的是,由于 Block 內線程要做同步,當 SM 中正在調度執(zhí)行的一個 Block 到達同步點時,SM 內可執(zhí)行 Warp 逐漸減少,若同時執(zhí)行的 Block 只有一個,則 SM 中可同時執(zhí)行的 Warp 會在此時逐漸降成0,會導致計算資源空閑,造成浪費,若此時同時有其他 Block 在執(zhí)行,則在一個 Block 到達同步點時仍然有其他 Block 可以執(zhí)行。當 block_size 越小時,SM 可同時調度的 Block 越多,因此在這種情況下 block_size 越小越好。但是當在調大 block_size,SM 能同時調度的 Block 數(shù)不變的情況下,block_size 應該是越大越好,越大就有越好的并行度。因此代碼中在選擇 block_size 時,對不同 block_size 都計算了 cudaOccupancyMaxActiveBlocksPerMultiprocessor,若結果相同,使用較大的 block_size。
實現(xiàn)3:一個Block處理一行的元素,不使用Shared Memory,重復讀輸入x和實現(xiàn)2一樣,仍然是一個 Block 處理一行元素,不同的是,不再用 Shared Memory 緩存x,而是在每次計算時重新讀輸入 x,這種實現(xiàn)沒有最大 num_cols的限制,可以支持任意大小。
此外,需要注意的是,在這種實現(xiàn)中,block_size 應該設越大越好,block_size 越大,SM 中能同時并行執(zhí)行的 Block 數(shù)就越少,對 cache 的需求就越少,就有更多機會命中 Cache,多次讀x不會多次訪問 Global Memory,因此在實際測試中,在能利用 Cache 情況下,有效帶寬不會因為讀3次x而降低幾倍。
公共優(yōu)化技巧
除了以上介紹的針對 softmax 的分段優(yōu)化技巧外,OneFlow 在 softmax 實現(xiàn)中,還使用了一些通用的公共優(yōu)化技巧,他們不僅應用于 softmax 中,也應用在其它 kernel 實現(xiàn)中。在此介紹兩種:
1、將 Half 類型 pack 成 Half2 進行存取,在不改變延遲情況下提高指令吞吐,類似 CUDA template for element-wise kernels 的優(yōu)化
2、Shared Memory 中的 Bank Conflicts
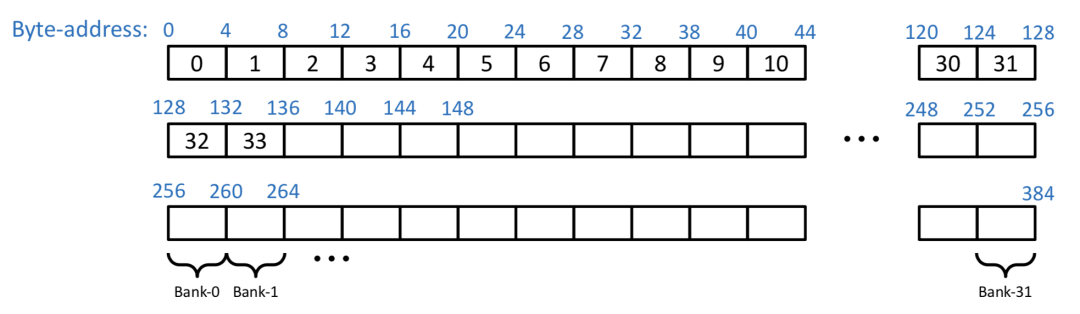
CUDA 將 Shared Memory 按照4字節(jié)或8字節(jié)大小劃分到32個 bank 中,對于 Volta 架構是4字節(jié),這里以4字節(jié)為例,如下圖所示,0-128 bytes地址分別在bank 0-31中,128-256也分別在 bank0-31中。
?
注:此圖及以下
Bank Conflicts圖片來自VOLTA Architecture and performance optimization(https://on-demand.gputechconf.com/gtc/2018/presentation/s81006-volta-architecture-and-performance-optimization.pdf)
當在一個 Warp 內的不同線程訪問同一個 bank 的不同地址,就會出現(xiàn) Bank Conflicts。當發(fā)生 Bank Conflicts 時,線程間只能順序訪問,增加延遲,下圖是一個 Warp 中 n 個線程同時訪問同一個 bank 中的不同地址時的延遲情況。
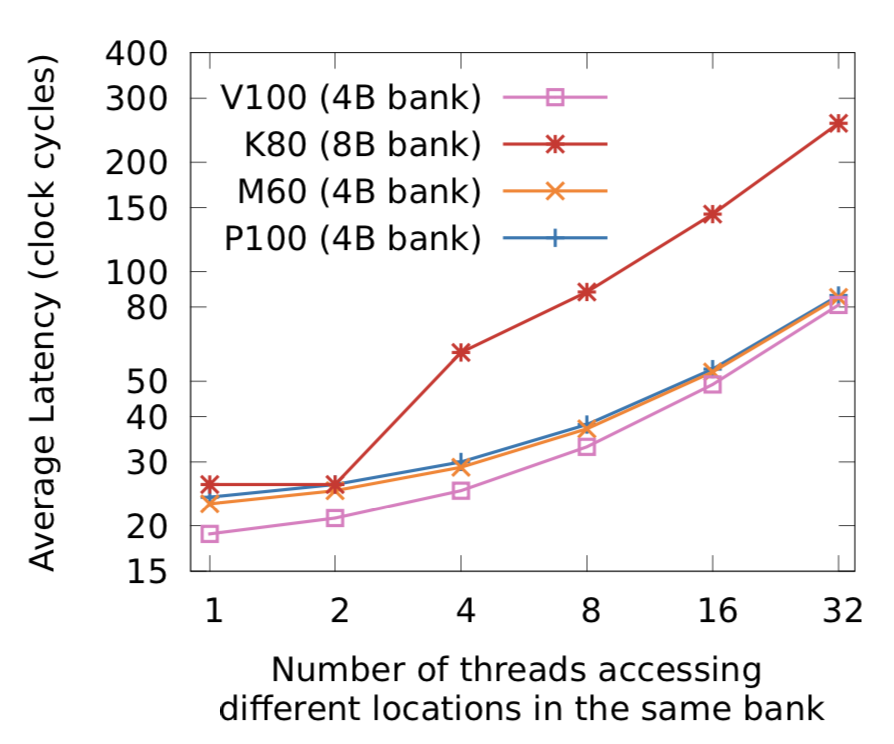
注:圖來自Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking(https://arxiv.org/abs/1804.06826)
Bank Conflicts 的幾種情況:
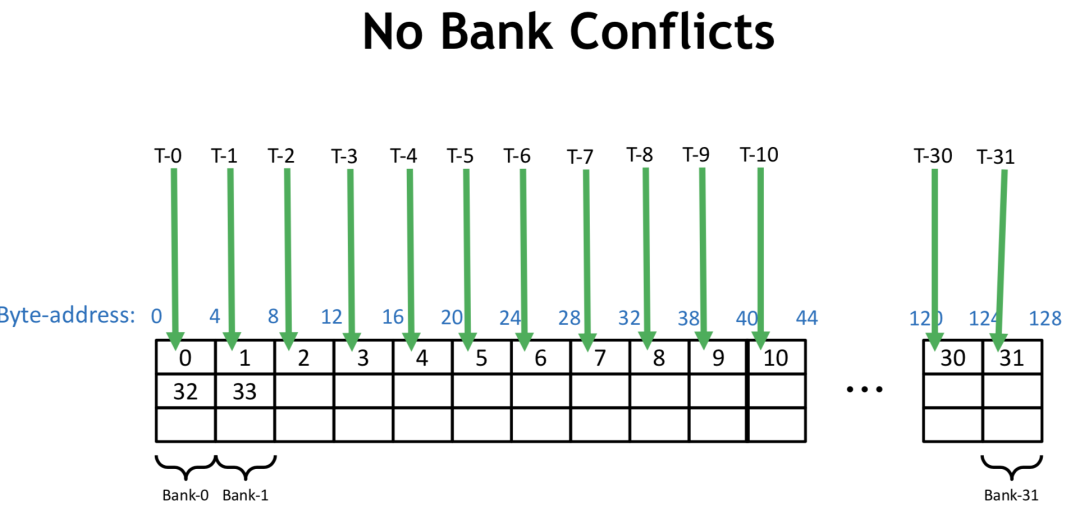
?
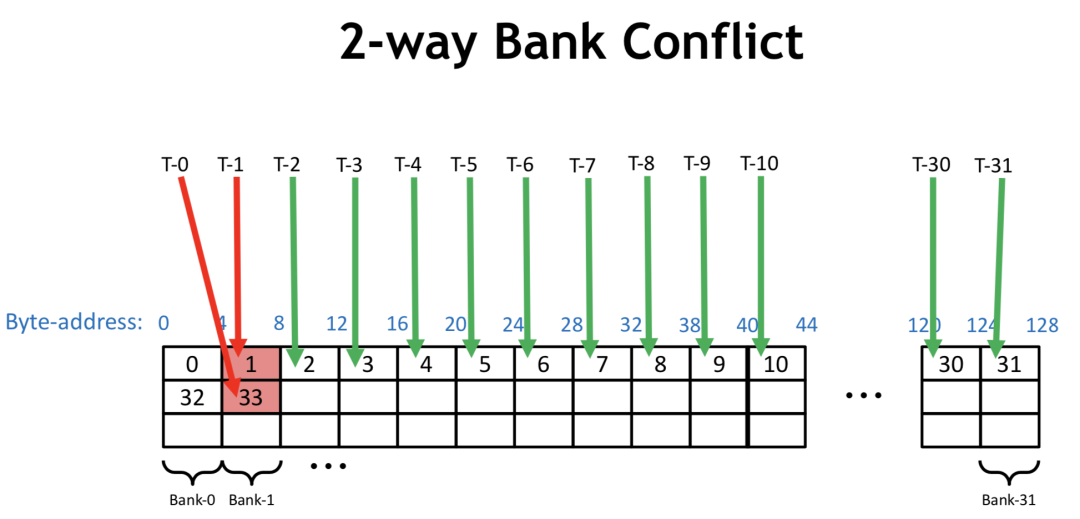
若一個 Warp 內每個線程讀4個字節(jié),順序訪問,則不會有 Bank Conflicts,若一個 Warp 內每個線程讀8個字節(jié),則 Warp 內0號線程訪問的地址在第0和第1個 bank,1號線程訪問的地址在第2和第3個 bank,以此類推,16號線程訪問地址又在第0和第1個 bank內,和0號線程訪問了同一個bank的不同地址,此時即產生了 Bank Conflicts。
在前文的實現(xiàn)(2)中,給 Shared memory 賦值過程中,若采用下面方法,當 pack size=2,每個線程寫連續(xù)兩個4 byte 地址,就會產生 Bank Conflicts。
因此,在實現(xiàn)(2)中,對Shared memory采用了新的內存布局,避免了同一個Warp訪問相同bank的不同地址,避免了Bank Conflicts。
參考資料
Using CUDA Warp-Level Primitives
CUDA Pro Tip: Increase Performance with Vectorized Memory Access
Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
VOLTA Architecture and performance optimization
點擊“閱讀原文”,前往OneFlow代碼倉庫。