
如何快速搭建智能人臉識(shí)別系統(tǒng)(附代碼)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

網(wǎng)絡(luò)安全是現(xiàn)代社會(huì)最關(guān)心的問(wèn)題之一,確保只有特定的人才能訪問(wèn)設(shè)備變得極其重要,這是我們的智能手機(jī)設(shè)有兩級(jí)安全系統(tǒng)的主要原因之一。這是為了確保我們的隱私得到維護(hù),只有真正的所有者才能訪問(wèn)他們的設(shè)備。基于人臉識(shí)別的智能人臉識(shí)別技術(shù)就是這樣一種安全措施,本文我們將研究如何利用VGG-16的深度學(xué)習(xí)和遷移學(xué)習(xí),構(gòu)建我們自己的人臉識(shí)別系統(tǒng)。
本項(xiàng)目構(gòu)建的人臉識(shí)別模型將能夠檢測(cè)到授權(quán)所有者的人臉并拒絕任何其他人臉,如果面部被授予訪問(wèn)權(quán)限或訪問(wèn)被拒絕,模型將提供語(yǔ)音響應(yīng)。用戶將有 3 次嘗試驗(yàn)證相同,在第三次嘗試失敗時(shí),整個(gè)系統(tǒng)將關(guān)閉,從而保持安全。如果識(shí)別出正確的面部,則授予訪問(wèn)權(quán)限并且用戶可以繼續(xù)控制設(shè)備。完整代碼將在文章末尾提供Github下載鏈接。
首先,我們將研究如何收集所有者的人臉圖像。然后,如果我們想添加更多可以訪問(wèn)我們系統(tǒng)的人,我們將創(chuàng)建一個(gè)額外的文件夾。我們的下一步是將圖像大小調(diào)整為 (224, 224, 3) 形狀,以便我們可以將其通過(guò) VGG-16 架構(gòu)。請(qǐng)注意,VGG-16 架構(gòu)是在具有上述形狀的圖像凈權(quán)重上進(jìn)行預(yù)訓(xùn)練的。然后我們將通過(guò)對(duì)數(shù)據(jù)集執(zhí)行圖像數(shù)據(jù)增強(qiáng)來(lái)創(chuàng)建圖像的變化。在此之后,我們可以通過(guò)排除頂層來(lái)自由地在 VGG-16 架構(gòu)之上創(chuàng)建我們的自定義模型。接下來(lái)是編譯、訓(xùn)練和相應(yīng)地使用基本回調(diào)擬合模型。

在這一步中,我們將編寫(xiě)一個(gè)簡(jiǎn)單的 Python 代碼,通過(guò)單擊空格鍵按鈕來(lái)收集圖像,我們可以單擊“q”按鈕退出圖形窗口。圖像的收集是一個(gè)重要的步驟,本步驟將授予設(shè)備人臉信息收集的訪問(wèn)權(quán)限。執(zhí)行以下代碼將完成本步驟:
import cv2import oscapture = cv2.VideoCapture(0)directory = "Bharath/"path = os.listdir(directory)count = 0
我們將“打開(kāi)”我們的默認(rèn)網(wǎng)絡(luò)攝像頭,然后繼續(xù)捕獲數(shù)據(jù)集所需的面部圖像。這是由 VideoCapture 命令完成的。然后我們將創(chuàng)建一個(gè)指向我們特定目錄的路徑并將計(jì)數(shù)初始化為 0。這個(gè)計(jì)數(shù)變量將用于標(biāo)記我們的圖像,從 0 到我們單擊的照片總數(shù)。執(zhí)行整個(gè)圖像采集過(guò)程所需的代碼:
while True:ret, frame = capture.read()cv2.imshow('Frame', frame)key = cv2.waitKey(1)if key%256 == 32:img_path = directory + str(count) + ".jpeg"cv2.imwrite(img_path, frame)count += 1elif key%256 == 113:breakcapture.release()cv2.destroyAllWindows()
我們確保代碼僅在網(wǎng)絡(luò)攝像頭被捕獲和激活時(shí)運(yùn)行,然后將捕獲視頻并返回幀。然后我們將分配變量“key”以獲取按下按鈕的命令。這個(gè)按鍵給了我們兩個(gè)選擇:
當(dāng)我們按鍵盤(pán)上的空格鍵時(shí)單擊圖片。
按下“q”時(shí)退出程序。
退出程序后,我們將從網(wǎng)絡(luò)攝像頭中釋放視頻捕獲并銷(xiāo)毀 cv2 圖形窗口。
在下一個(gè)代碼塊中,我們將相應(yīng)地調(diào)整圖像大小。我們希望將我們收集的圖像重塑為適合通過(guò) VGG-16 架構(gòu)的大小,該架構(gòu)是對(duì) imagenet 權(quán)重進(jìn)行預(yù)訓(xùn)練的。
import cv2import osdirectory = "Bharath/"path = os.listdir(directory)for i in path:img_path = directory + iimage = cv2.imread(img_path)image = cv2.resize(image, (224, 224))image)
我們將所有從默認(rèn)幀大小捕獲的圖像重新縮放到 (224, 224) 像素,因?yàn)槲覀兿雵L試像 VGG-16 這樣的遷移學(xué)習(xí)模型,同時(shí)已經(jīng)以 RGB 格式捕獲了圖像。因此我們已經(jīng)有 3 個(gè)通道,我們不需要指定。VGG-16 所需的通道數(shù)為 3,架構(gòu)的理想形狀為 (224, 224, 3)。調(diào)整大小步驟完成后,我們可以將所有者的目錄轉(zhuǎn)移到圖像文件夾中。
我們收集并創(chuàng)建了我們的圖像,下一步是對(duì)數(shù)據(jù)集執(zhí)行圖像數(shù)據(jù)增強(qiáng)以復(fù)制副本并增加數(shù)據(jù)集的大小。可以使用以下代碼塊來(lái)做到這一點(diǎn):
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=30,shear_range=0.3,zoom_range=0.3,width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=True,fill_mode='nearest')train_generator = train_datagen.flow_from_directory(directory,target_size=(Img_Height, Img_width),batch_size=batch_size,class_mode='categorical',shuffle=True)
重新縮放圖像并更新所有參數(shù)以適合我們的模型,參數(shù)如下:
1,重新調(diào)整=重標(biāo)度由1/255歸一化每個(gè)像素值的
2 rotation_range =指定旋轉(zhuǎn)隨機(jī)范圍
3. shear_range =指定在逆時(shí)針?lè)较蚍秶鷥?nèi)的每個(gè)角度的強(qiáng)度
4. zoom_range = 指定縮放范圍
5. width_shift_range = 指定擴(kuò)展的寬度
6. height_shift_range = 指定擴(kuò)展的高度
7. horizontal_flip =水平翻轉(zhuǎn)圖像
8. fill_mode= 根據(jù)最近的邊界填充
train_datagen.flow_from_directory 獲取目錄的路徑并生成批量增強(qiáng)數(shù)據(jù)。可調(diào)用的屬性如下:
1. train dir = 指定我們存儲(chǔ)圖像數(shù)據(jù)的目錄
2. color_mode = 圖像灰度或RGB 格式,默認(rèn)為 RGB
3. target_size = 圖像的尺寸
4.batch_size =操作數(shù)據(jù)批次的數(shù)目
5. class_mode = 確定返回的標(biāo)簽數(shù)組的類(lèi)型
6.shuffle= shuffle:是否對(duì)數(shù)據(jù)進(jìn)行混洗(默認(rèn):True)
在下一個(gè)代碼塊中,我們將在變量 VGG16_MODEL 中導(dǎo)入 VGG-16 模型,并確保我們輸入的模型沒(méi)有頂層。使用沒(méi)有頂層的 VGG-16 架構(gòu),我們現(xiàn)在可以添加我們的自定義層。為了避免訓(xùn)練 VGG-16 層,我們給出以下命令:
layers.trainable = False。我們還將打印出這些層并確保它們的訓(xùn)練設(shè)置為 False。
VGG16_MODEL = VGG16(input_shape=(Img_width, Img_Height, 3), include_top=False, weights='imagenet')for layers in VGG16_MODEL.layers:layers.trainable=Falsefor layers in VGG16_MODEL.layers:print(layers.trainable)
在 VGG-16 架構(gòu)之上構(gòu)建我們的自定義模型:
# Input layerinput_layer = VGG16_MODEL.output# Convolutional LayerConv1 = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='valid',data_format='channels_last', activation='relu',kernel_initializer=keras.initializers.he_normal(seed=0),name='Conv1')(input_layer)# MaxPool LayerPool1 = MaxPool2D(pool_size=(2,2),strides=(2,2),padding='valid',data_format='channels_last',name='Pool1')(Conv1)# Flattenflatten = Flatten(data_format='channels_last',name='Flatten')(Pool1)# Fully Connected layer-1FC1 = Dense(units=30, activation='relu',kernel_initializer=keras.initializers.glorot_normal(seed=32),name='FC1')(flatten)# Fully Connected layer-2FC2 = Dense(units=30, activation='relu',kernel_initializer=keras.initializers.glorot_normal(seed=33),name='FC2')(FC1)# Output layerOut = Dense(units=num_classes, activation='softmax',kernel_initializer=keras.initializers.glorot_normal(seed=3),name='Output')(FC2)model1 = Model(inputs=VGG16_MODEL.input,outputs=Out)
人臉識(shí)別模型將使用遷移學(xué)習(xí)進(jìn)行訓(xùn)練,我們將使用沒(méi)有頂層的 VGG-16 模型。將在 VGG-16 模型的頂層添加自定義層,然后我們將使用此遷移學(xué)習(xí)模型來(lái)預(yù)測(cè)它是否是授權(quán)所有者的臉。自定義層由輸入層組成,它基本上是 VGG-16 模型的輸出。我們添加了一個(gè)帶有 32 個(gè)過(guò)濾器的卷積層,kernel_size 為 (3,3),默認(rèn)步幅為 (1,1),我們使用激活作為 relu,he_normal 作為初始化器。我們將使用池化層對(duì)卷積層中的層進(jìn)行下采樣。2 個(gè)完全連接的層與激活一起用作 relu,即在樣本通過(guò)展平層后的密集架構(gòu)。輸出層有一個(gè) num_classes 為 2 的 softmax 激活,它預(yù)測(cè)num_classes的概率,即授權(quán)所有者或額外的參與者或被拒絕的人臉。最終模型將輸入作為 VGG-16 模型的開(kāi)始,輸出作為最終輸出層。
在下一個(gè)代碼塊中,我們將查看面部識(shí)別任務(wù)所需的回調(diào)。
from tensorflow.keras.callbacks import ModelCheckpointfrom tensorflow.keras.callbacks import ReduceLROnPlateaufrom tensorflow.keras.callbacks import TensorBoardcheckpoint = ModelCheckpoint("face_rec.h5", monitor='accuracy', verbose=1,save_best_only=True, mode='auto', period=1)reduce = ReduceLROnPlateau(monitor='accuracy', factor=0.2, patience=3, min_lr=0.00001, verbose = 1)logdir='logsface'tensorboard_Visualization = TensorBoard(log_dir=logdir, histogram_freq=True)
我們將導(dǎo)入 3 個(gè)必需的回調(diào)來(lái)訓(xùn)練我們的模型:ModelCheckpoint、ReduceLROnPlateau 和 Tensorboard。
ModelCheckpoint — 此回調(diào)用于存儲(chǔ)訓(xùn)練后模型的權(quán)重。我們通過(guò)指定 save_best_only=True 只保存模型的最佳權(quán)重。
ReduceLROnPlateau — 此回調(diào)用于在指定的epoch數(shù)后降低優(yōu)化器的學(xué)習(xí)率。在這里,我們將耐心指定為 10。如果在 10 個(gè) epoch 后準(zhǔn)確率沒(méi)有提高,那么我們的學(xué)習(xí)率就會(huì)相應(yīng)地降低 0.2 倍。
Tensorboard — tensorboard 回調(diào)用于繪制圖形的可視化,即精度和損失的圖形。
='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])epochs = 20model1.fit(train_generator,epochs = epochs,callbacks = [checkpoint, reduce, tensorboard_Visualization])
編譯和擬合我們的模型。將訓(xùn)練模型并將最佳權(quán)重保存到 face_rec.h5,這樣就不必反復(fù)重新訓(xùn)練模型,并且可以在需要時(shí)使用我們保存的模型。本文使用的損失是 categorical_crossentropy,它計(jì)算標(biāo)簽和預(yù)測(cè)之間的交叉熵?fù)p失。我們將使用的優(yōu)化器是 Adam,其學(xué)習(xí)率為 0.001,我們將根據(jù)度量精度編譯我們的模型。我們將在增強(qiáng)的訓(xùn)練圖像上擬合數(shù)據(jù)。在擬合步驟之后,這些是我們能夠在訓(xùn)練損失和準(zhǔn)確性方面取得的結(jié)果:

訓(xùn)練數(shù)據(jù)表:
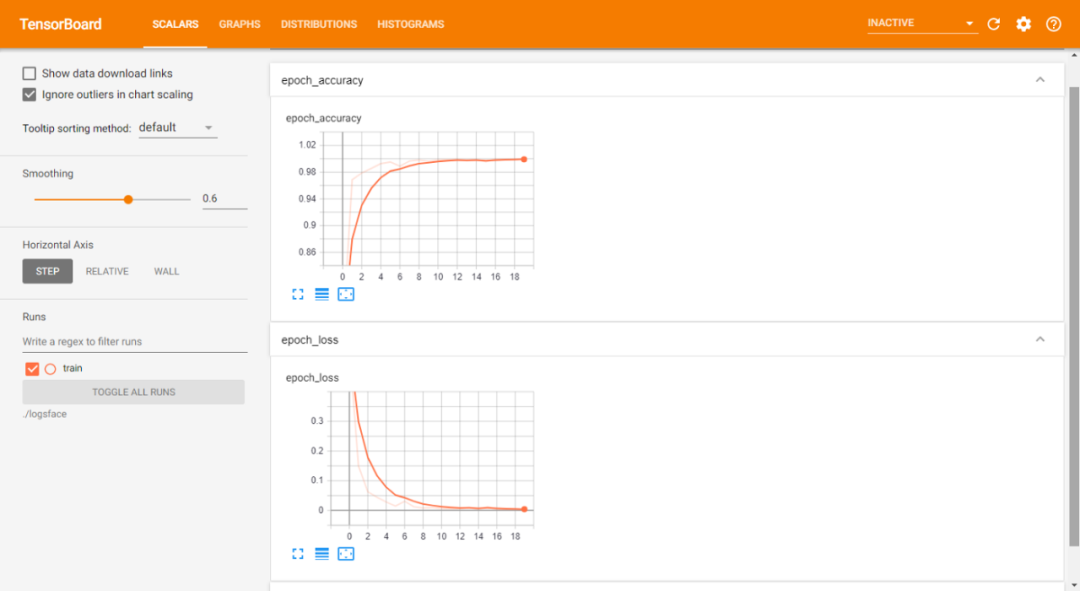
訓(xùn)練和驗(yàn)證數(shù)據(jù)表:
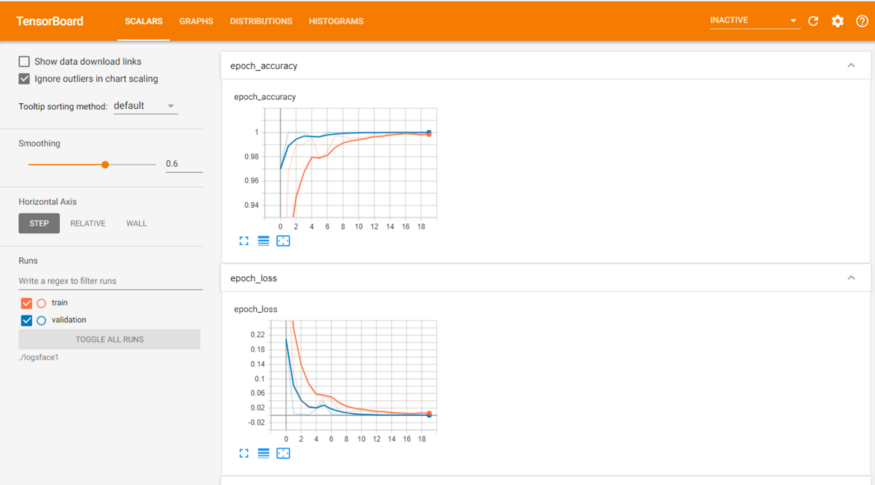
本文GITHUB代碼鏈接:
https://github.com/Bharath-K3/Smart-Face-Lock-System
好消息,小白學(xué)視覺(jué)團(tuán)隊(duì)的知識(shí)星球開(kāi)通啦,為了感謝大家的支持與厚愛(ài),團(tuán)隊(duì)決定將價(jià)值149元的知識(shí)星球現(xiàn)時(shí)免費(fèi)加入。各位小伙伴們要抓住機(jī)會(huì)哦!

交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~