
三種方法,Python輕松提取PDF中全部圖片

有時(shí)我們需要將一份或者多份PDF文件中的圖片提取出來,如果采取在線的網(wǎng)站實(shí)現(xiàn)的話又擔(dān)心圖片泄漏,手動(dòng)操作又覺得麻煩,其實(shí)用Python也可以輕松搞定!
今天就跟大家系統(tǒng)分享幾種Python提取 PDF 圖片的方法。其實(shí)沒有非常完美的方法,每種方法提取效率都不是百分之百,因此可以考慮用多種方法進(jìn)行互補(bǔ),主要將涉及:
基于 fitz庫(kù)和正則搜索提取圖片基于 pdf2image庫(kù)的兩種方法提取圖片
基于 fitz 庫(kù)和正則搜索
fitz 是 pymupdf 的子模塊,需要先用命令行安裝 pymupdf:
pip?install?pymupdf
但注意導(dǎo)入時(shí)使用 import fitz 導(dǎo)入模塊!
下面的代碼就利用 fitz 庫(kù)提取圖片需要通過正則匹配圖片元素,將模板元素轉(zhuǎn)化為像素后再以圖片形式寫出
import?fitz
import?re
import?os
file_path?=?r'C:\xxx\xxx.pdf'?#?PDF?文件路徑
dir_path?=?r'C:\xxx'?#?存放圖片的文件夾
def?pdf2image1(path,?pic_path):
????checkIM?=?r"/Subtype(?=?*/Image)"
????pdf?=?fitz.open(path)
????lenXREF?=?pdf._getXrefLength()
????count?=?1
????for?i?in?range(1,?lenXREF):
????????text?=?pdf._getXrefString(i)
????????isImage?=?re.search(checkIM,?text)
????????if?not?isImage:
????????????continue
????????pix?=?fitz.Pixmap(pdf,?i)
????????new_name?=?f"img_{count}.png"
????????pix.writePNG(os.path.join(pic_path,?new_name))
????????count?+=?1
????????pix?=?None
pdf2image1(file_path,?dir_path)
運(yùn)行提取示例文件后結(jié)果如下: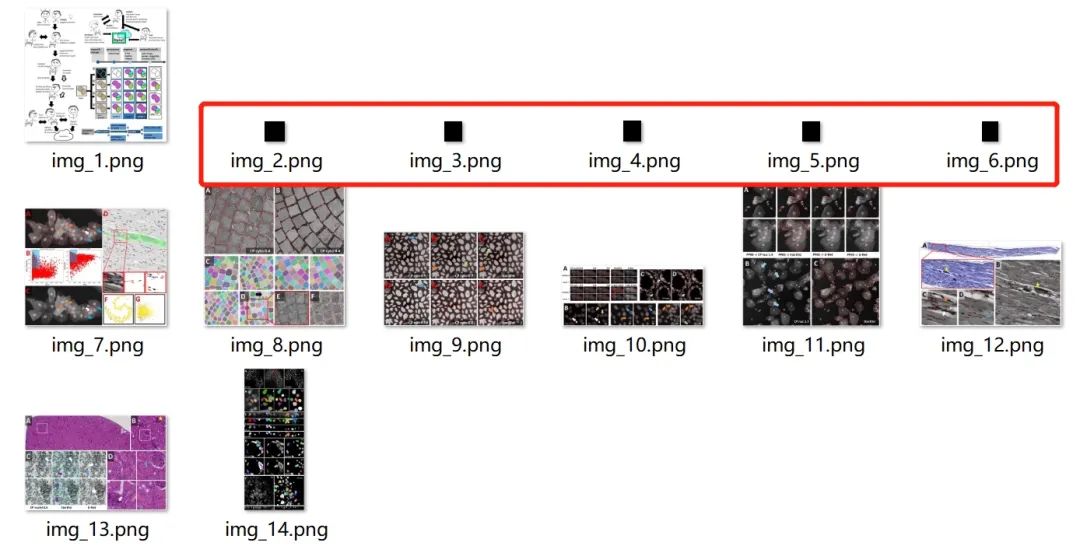
可以看到,有一些很小的色塊也被提取成圖片,那么怎么過濾掉它們呢?
有一個(gè)簡(jiǎn)單的方法是通過大小過濾,pix 像素在 fitz 庫(kù)中存在一個(gè)重要的方法 pix.size 可以反映像素多少,簡(jiǎn)單的色素塊該值較低,可以通過設(shè)置一個(gè)閾值過濾。以閾值 10000 為例過濾:
import?fitz
import?re
import?os
file_path?=?r'C:\xxx\xxx.pdf'?#?PDF?文件路徑
dir_path?=?r'C:\xxx'?#?存放圖片的文件夾
def?pdf2image1(path,?pic_path):
????checkIM?=?r"/Subtype(?=?*/Image)"
????pdf?=?fitz.open(path)
????lenXREF?=?pdf._getXrefLength()
????count?=?1
????for?i?in?range(1,?lenXREF):
????????text?=?pdf._getXrefString(i)
????????isImage?=?re.search(checkIM,?text)
????????if?not?isImage:
????????????continue
????????pix?=?fitz.Pixmap(pdf,?i)
????????if?pix.size?10000:?#?在這里添加一處判斷一個(gè)循環(huán)
????????????continue?#?不符合閾值則跳過至下
????????new_name?=?f"img_{count}.png"
????????pix.writePNG(os.path.join(pic_path,?new_name))
????????count?+=?1
????????pix?=?None
pdf2image1(file_path,?dir_path)

可以看到,全部圖片都被正常提取!
基于 pdf2image 庫(kù)的兩種方法
一看名字就知道這個(gè)庫(kù)的用處了,官方文檔為https://www.cnpython.com/pypi/pdf2image
可以簡(jiǎn)單通過 pip install pdf2image 安裝,但poppler才是真正起做用的轉(zhuǎn)換器,因此需要額外安裝和配置:
“”
windows用戶必須安裝 poppler for Windows,然后將bin/文件夾添加到PATHMac用戶必須安裝 poppler for Mac
具體發(fā)揮作用的代碼官方文檔也給出了詳細(xì)的說明: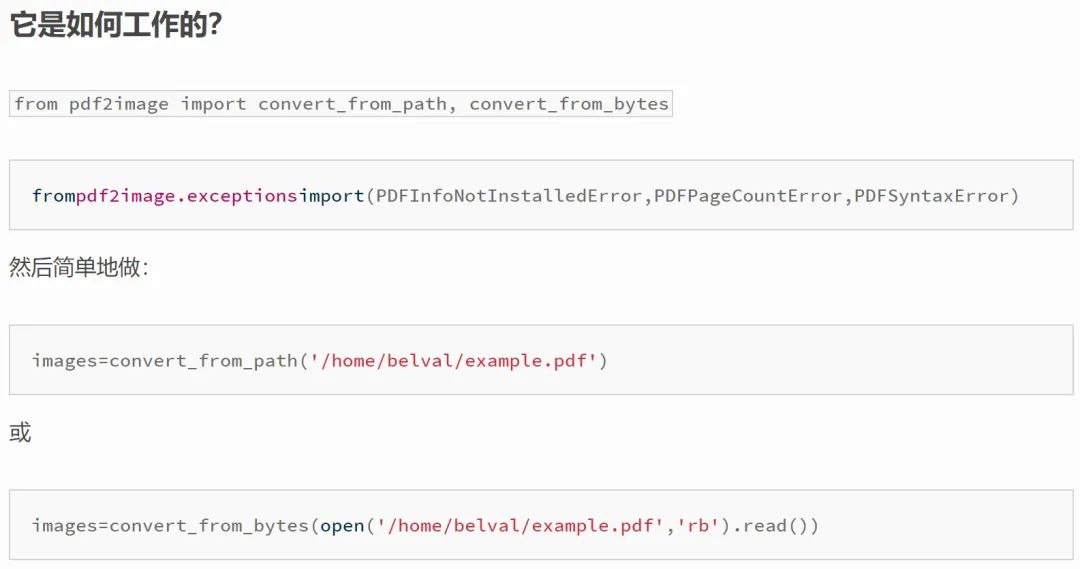
那么我們就分別嘗試這兩種方法:
from?pdf2image?import?convert_from_path,convert_from_bytes
import?tempfile
from?pdf2image.exceptions?import?PDFInfoNotInstalledError,?PDFPageCountError,?PDFSyntaxError
import?os
file_path?=?r'C:\xxx\xxx.pdf'?#?PDF?文件路徑
dir_path?=?r'C:\xxx'?#?存放圖片的文件夾
def?pdf2image2(file_path,?dir_path):
????images?=?convert_from_path(file_path,?dpi=200)
????for?image?in?images:
????????if?not?os.path.exists(dir_path):
????????????os.makedirs(dir_path)
????????image.save(file_path?+?f'\img_{images.index(image)}.png',?'PNG')
pdf2image2(file_path,?dir_path)
可以成功提取圖片。再試試第二種方法:
from?pdf2image?import?convert_from_path,convert_from_bytes
import?tempfile
from?pdf2image.exceptions?import?PDFInfoNotInstalledError,?PDFPageCountError,?PDFSyntaxError
import?os
file_path?=?r'C:\xxx\xxx.pdf'?#?PDF?文件路徑
dir_path?=?r'C:\xxx'?#?存放圖片的文件夾
def?pdf2image3(file_path,?dir_path):
????images?=?convert_from_bytes(open(file_path,?'rb').read())
????for?image?in?images:
????????if?not?os.path.exists(dir_path):
????????????os.makedirs(dir_path)
????????image.save(file_path?+?f'\img_{images.index(image)}.png',?'PNG')
pdf2image3(file_path,?dir_path)
可以看到結(jié)果和之前一致,PDF中全部圖片都被提取出來!
再補(bǔ)充一下。核心方法covert_from_bytes包含大量參數(shù),可以自行修改。幾個(gè)常用參數(shù)總結(jié)如下:
| 參數(shù) | 意義 |
|---|---|
| pdf_path | PDF 文檔路徑 |
| dpi | 圖像質(zhì)量(如果是學(xué)術(shù)期刊雜志常見 300dpi) |
| output_folder | 將生成的圖像寫入文件夾(而不是直接寫入內(nèi)存) |
| first_page | 起始轉(zhuǎn)換頁(yè)數(shù) |
| last_page | 轉(zhuǎn)換至哪一頁(yè) |
| fmt | 圖像格式,可以指定為 png,默認(rèn)為 ppm |
| thread_count | 允許參與轉(zhuǎn)換的線程數(shù) |
| userpw | PDF 的密碼 |
| output_file | 輸出文件名 |
| poppler_path | 指定 poppler 的安裝路徑,一開始配置好就無需指定 |
值得一提的是thread_count 參數(shù),可以啟動(dòng)多線程會(huì)大大加快轉(zhuǎn)換速度,尤其是 PDF 頁(yè)面較多時(shí)。有興趣的讀者可以做嘗試。
-END-
掃碼添加早小起
1.?回復(fù)「進(jìn)群」進(jìn)入Python技術(shù)交流群
2. 回復(fù)「Python」獲得Python技術(shù)圖書
3. 回復(fù)「習(xí)題」領(lǐng)取Python數(shù)據(jù)處理200題