
.NET 內(nèi)存性能分析寶典
前言
Github倉庫:https://github.com/InCerryGit/mem-doc/blob/master/doc/.NETMemoryPerformanceAnalysis.zh-CN.md
本文90%通過機(jī)器翻譯,另外10%譯者按照自己的理解進(jìn)行翻譯,和原文相比有所刪減,與原文并不是一一對應(yīng),但是意思基本一致。另外文章較長,還沒有足夠的時間完全校對好,后續(xù)還會對一些語句不通順、模糊和錯漏的地方進(jìn)行補(bǔ)充,請關(guān)注文檔版本號。

文檔的目的
本文旨在幫助.NET開發(fā)者,如何思考內(nèi)存性能分析,并在需要時找到正確的方法來進(jìn)行這種分析。在本文檔中.NET的包括.NET Framework和.NET Core。為了在垃圾收集器和框架的其他部分獲得最新的內(nèi)存改進(jìn),我強(qiáng)烈建議你使用.NET Core,如果你還沒有的話,因為那是應(yīng)該盡快去升級的地方。
文檔的狀態(tài)
這是一份正在完善的文檔。現(xiàn)在,這份文檔主要凈重在Windows上。添加相應(yīng)的Linux材料肯定會使它更有用。我正計劃在未來這樣做,但也非常歡迎其他朋友(尤其是對Linux部分)對該文件的貢獻(xiàn)。
如何閱讀本文檔
這是一份很長的文檔,但你不需要讀完它;你也不需要按順序閱讀各部分。根據(jù)你在做性能分析方面的經(jīng)驗,有些章節(jié)可以完全跳過。
如果你對性能分析工作完全陌生,我建議從頭開始。
對于那些已經(jīng)能自如地進(jìn)行一般的性能分析工作,但希望增加他們在管理內(nèi)存相關(guān)主題方面的知識的人,他們可以跳過開頭,直接進(jìn)入基礎(chǔ)知識部分。
如果你不是很有經(jīng)驗,并且在做一次性能分析,你可以跳到知道什么時候該擔(dān)心部分開始閱讀,如果需要,再參考基礎(chǔ)知識部分的具體內(nèi)容。
如果你是一名性能工程師,其工作包括將托管內(nèi)存分析作為一項常規(guī)任務(wù),但又是.NET的新手,我強(qiáng)烈建議你真正閱讀并內(nèi)化GC基礎(chǔ)部分,因為它能幫助你更快地關(guān)注正確的事情。然而,如果你手頭有一個緊急問題,你可以去看看我在本文檔中將要使用的工具,熟悉它,然后看看你是否能在GC暫停問題或堆大小問題部分找到相關(guān)癥狀。
如果你已經(jīng)有做托管內(nèi)存性能分析工作的經(jīng)驗,并且有具體的問題,你可以在GC停頓時間長或GC堆太大部分找到它。
注意
當(dāng)我在寫這篇文檔時,我打算根據(jù)分析的需要來介紹一些概念,如并發(fā)的GC或釘住。所以在你閱讀的過程中,你會逐漸接觸到它們。如果你已經(jīng)知道它們是什么,并且正在尋找關(guān)于特定概念的解釋,這里有它們的鏈接
分配預(yù)算
并發(fā)GC/后臺GC
終結(jié)器
分代GC
LOH (LOH-Large-Object-Heap 大對象堆)
釘住
服務(wù)器GC
如何看待性能分析工作?
那些在做性能分析方面有經(jīng)驗的人知道,這可能就像偵探工作一樣--沒有 "如果你按照這10個步驟去做,你就會改善性能或從根本上解決性能問題"的方法。這是為什么呢?因為你的代碼不是唯一在運(yùn)行的東西--你使用操作系統(tǒng)、運(yùn)行時、庫(至少是BCL,但通常是許多其他的),甚至你自己的代碼。而運(yùn)行你的代碼的線程需要與同一進(jìn)程中的其他線程和/或其他進(jìn)程共享機(jī)器/VM/容器。
然而,這并不意味著你需要對我剛才提到的一切有一個徹底的了解。否則我們都不會有任何成就--你根本沒有時間。但你不需要這樣做。你只需要了解足夠的基礎(chǔ)知識,掌握足夠的性能分析技能,這樣你就可以專注于自己代碼的性能分析。在本文中,我們將討論這兩點。我還會解釋事情為什么會這樣,這樣才有意義,而不是讓你背誦那些很容易被翻出來的東西。
這篇文檔談到了你自己可以做什么,以及什么時候是把分析工作交給GC團(tuán)隊的好時機(jī),因為這將是需要在運(yùn)行時進(jìn)行的改進(jìn)。很明顯,我們在GC中仍然在做改進(jìn)的工作(否則我就不會還在這個團(tuán)隊中)。正如我們將看到的,GC的行為是由你的應(yīng)用行為驅(qū)動的,所以你肯定可以改變你的應(yīng)用行為來影響GC。在你作為性能工程師需要做多少工作和GC自動處理多少工作之間存在著一個平衡。.NET GC的理念是,我們盡量自動處理;當(dāng)我們需要你的輸入時(通過配置),我們會以一種從應(yīng)用角度看有意義的方式來要求你,而不是要求你了解GC的親密細(xì)節(jié)。當(dāng)然,GC團(tuán)隊一直在努力讓.NET GC處理越來越多的性能場景,這樣用戶就不需要擔(dān)心了。但如果你遇到了GC目前不能很好處理的情況,我將指出你可以做什么來解決它。
我對性能分析的目標(biāo)是使客戶需要做的大部分分析自動化。我們在這方面已經(jīng)走了很長的路,但我們還沒有達(dá)到所有分析都自動化的程度。在這份文件中,我將告訴你目前做分析的方法,在文件的最后,我將給你一個展望,說明我們正在為實現(xiàn)這個目標(biāo)做什么樣的改進(jìn)。
挑選正確的方法來做性能分析
我們都有有限的資源,如何將這些資源花在能夠產(chǎn)生最大回報的事情上是關(guān)鍵。這意味著你應(yīng)該找到哪個部分是最值得優(yōu)化的,以及如何以最有效的方式優(yōu)化它們。當(dāng)你斷定你需要優(yōu)化某些東西,或者你要如何優(yōu)化某些東西時,應(yīng)該有一個合理的理由來說明你為什么這樣做
知道你的目標(biāo)是什么
當(dāng)人們第一次來找我時,我總是問他們這樣一個問題 - 你的性能目標(biāo)是什么?不同的產(chǎn)品有非常不同的性能要求。在你想出一個數(shù)字之前(例如,將某些東西提高X%),你需要知道你要優(yōu)化的是什么。在頂層,這些是需要優(yōu)化的方面?
優(yōu)化內(nèi)存占用,例如,需要在同一臺機(jī)器上盡可能多地運(yùn)行實例。
優(yōu)化吞吐量,例如,需要在一定的時間內(nèi)處理盡可能多的請求。
針對尾部延遲進(jìn)行優(yōu)化,例如,需要滿足一定的延遲SLA。
當(dāng)然,你可以有多個這樣的要求,例如,你可能需要滿足一個SLA,但仍然需要在一個時間段內(nèi)至少處理一定數(shù)量的請求。在這種情況下,你需要弄清楚什么是優(yōu)先考慮的,這將決定你應(yīng)該把大部分精力放在什么地方。
理解GC只是框架的一個部分
GC行為的變化可能是由于GC本身的變化或框架其他部分的變化,當(dāng)你得到一個新版本時,框架中通常會有很多變化。當(dāng)你在升級后看到內(nèi)存行為的變化時,可能是由于GC的變化或框架中的其他東西開始分配更多的內(nèi)存,并以不同的方式保留內(nèi)存。此外,如果你升級你的操作系統(tǒng)版本或在不同的虛擬化環(huán)境中運(yùn)行你的產(chǎn)品,你也可以得到不同的行為,只是因為它們可能導(dǎo)致你的應(yīng)用程序行為不同。
不要猜測,去測量
測量是你在開始一個產(chǎn)品時絕對應(yīng)該計劃做的事情,而不是在事情發(fā)生后才想到的,特別是當(dāng)你知道你的產(chǎn)品需要在相當(dāng)緊張的情況下運(yùn)行時。如果你正在閱讀這份文件,那么你很有可能正在從事一些對性能有要求的工作。
對于我所接觸的大多數(shù)工程師來說,測量并不是一個陌生的概念。然而,如何測量和測量什么是我見過的許多人需要幫助的事情。
這意味著你需要有一些方法來真實地測量你的性能。在復(fù)雜的服務(wù)器應(yīng)用程序上的一個常見問題是,你很難在你的測試環(huán)境中模擬你在生產(chǎn)中實際看到的情況。
測量并不僅僅意味著 "我可以測量我的應(yīng)用程序每秒可以處理多少個請求,因為這是我所關(guān)心的",它意味著你也應(yīng)該有一些東西,當(dāng)你的測量結(jié)果告訴你某些東西沒有達(dá)到理想的水平時,你可以做有意義的性能分析。能夠發(fā)現(xiàn)問題是一件事。如果你沒有任何東西可以幫助你找出這些問題的原因,那就沒有什么幫助了。當(dāng)然,這需要你知道如何收集數(shù)據(jù),我們將在下面談及。
能夠衡量來自修復(fù)/解決方法的效果。
足夠的測量,讓你知道應(yīng)該把精力集中在哪個領(lǐng)域
我一次又一次地聽到人們會測量一件事,并選擇只優(yōu)化這件事,因為他們從朋友或同事那里聽說了這件事。這就是了解基本原理真正有幫助的地方,這樣你就不會一直關(guān)注你聽說過的一件事,而這件事可能是也可能不是正確的。
測量那些可能影響你的性能指標(biāo)的因素
在您知道哪些因素可能對您關(guān)心的事情(即您的性能指標(biāo))影響最大之后,你應(yīng)該測量它們的效果,這樣你就可以觀察它們在你開發(fā)產(chǎn)品的過程中貢獻(xiàn)是大還是小。一個完美的例子是,服務(wù)器應(yīng)用程序如何改善其P95請求延遲(即第95百分位的請求延遲)。這是一個幾乎每個網(wǎng)絡(luò)服務(wù)器都會看的性能指標(biāo)。當(dāng)然,任何數(shù)量的因素都可以影響這個延遲,但你知道那些可能影響最大的因素。
你每天(或你記錄P95的任何時間單位)的P95延遲可能會波動,但你知道大致的數(shù)字。比方說,你的平均請求延遲是<3ms,而你的P95大約是70ms。你必須有一些方法來測量每個請求總共需要多長時間(否則你就不會知道你的延遲百分?jǐn)?shù))。你可以記錄你看到GC暫停或網(wǎng)絡(luò)IO的時間(兩者都可以通過事件來測量)。對于那些在P95延遲附近的請求,你可以計算出 "P95的GC影響",即
這些請求觀察到的GC暫停總時間/請求總延時
如果這是10%,你應(yīng)該有其他因素沒有計算在內(nèi)。
通常人們會猜測GC停頓是影響他們P95延遲的原因。當(dāng)然這是有可能的,但這絕不是唯一可能的因素,也不是對你的P95影響最大的因素。這就是為什么了解影響很重要,它告訴你應(yīng)該把大部分精力花在什么地方。
而影響你的P95的因素可能與影響你的P99或P99.99的因素非常不同;同樣的原則也適用于其他百分位數(shù)。
優(yōu)化框架代碼與用戶代碼
雖然這個文檔是為每一個關(guān)心內(nèi)存分析的人準(zhǔn)備的,但根據(jù)你所工作的層次,應(yīng)該有不同的考慮。
作為一個從事終端產(chǎn)品的人,你有很大的自由空間去優(yōu)化,因為你可以預(yù)測你的產(chǎn)品在什么樣的環(huán)境下運(yùn)行,例如,一般來說,你知道你傾向于哪種資源的飽和,CPU,內(nèi)存或其他東西。你可以控制你的產(chǎn)品在什么樣的機(jī)器/虛擬機(jī)上運(yùn)行,你使用什么樣的庫,你如何使用它們。你可以做一些估計,比如 "我們的機(jī)器上有128GB的內(nèi)存,計劃在我們最大的進(jìn)程中拿出20GB的內(nèi)存緩存"。
從事平臺技術(shù)或庫工作的人無法預(yù)測他們的代碼將在什么樣的環(huán)境中運(yùn)行。這意味著:1)如果希望用戶能夠在性能關(guān)鍵路徑上使用代碼,則需要節(jié)約內(nèi)存使用;2)你可能要提供不同的API,在性能和可用性之間做出權(quán)衡,并對你的用戶進(jìn)行教育。
內(nèi)存基礎(chǔ)
正如我在上面提到的,讓一個人對整個技術(shù)棧有透徹的了解是完全不現(xiàn)實的。本節(jié)列出了任何需要從事內(nèi)存性能分析工作的人都必須知道的基本知識。
虛擬內(nèi)存基礎(chǔ)
我們通過VMM(虛擬內(nèi)存管理器)使用內(nèi)存,它為每個進(jìn)程提供了自己的虛擬地址空間,盡管同一臺機(jī)器上的所有進(jìn)程都共享物理內(nèi)存(如果你有頁面文件的話)。如果你在一個虛擬機(jī)中運(yùn)行,虛擬機(jī)就有一種在真實機(jī)器上運(yùn)行的錯覺。對于應(yīng)用程序來說,實際上,你很少會直接使用虛擬內(nèi)存工作。如果你寫的是本地代碼,通常你會通過一些本地分配器來使用虛擬地址空間,比如CRT堆,或者C++的new/delete助手-這些分配器會代表你分配和釋放虛擬內(nèi)存;如果你寫的是托管代碼,GC是代表你分配/釋放虛擬內(nèi)存的人。
每個VA(虛擬地址)范圍(指虛擬地址的連續(xù)范圍)可以處于不同的狀態(tài)--自由(free)、保留(reserved)和已提交(committed)。"自由"很容易理解,就是空閑的內(nèi)存。"保留"和"已提交"之間的區(qū)別有時讓人困惑。"保留"是說 "我想讓這個區(qū)域的內(nèi)存供我自己使用"。當(dāng)你"保留"了一個虛擬地址的范圍后,這個范圍就不能用來滿足其他的"保留"請求。在這一點上,你還不能在這個地址范圍內(nèi)存儲你的任何數(shù)據(jù)--要做到這一點,你必須"提交"它,這意味著系統(tǒng)將不得不用一些物理存儲來支持它,以便你可以在其中存儲東西。當(dāng)你通過性能工具查看內(nèi)存時,要確保你看的是正確的東西。如果你的預(yù)留空間用完了,或者"提交"空間用完了,你就會出現(xiàn)內(nèi)存不足的情況(在本文檔中,我主要關(guān)注Windows VMM--在Linux中,當(dāng)你實際接觸到內(nèi)存時,你會出現(xiàn)OOM(Out Of Memory))。
虛擬內(nèi)存可以是私有或共享的。私有意味著它只被當(dāng)前進(jìn)程使用,而共享意味著它可以被其他進(jìn)程共享。所有與GC相關(guān)的內(nèi)存使用都是私有的。
虛擬地址空間可能被分割--換句話說,地址空間中可能有 "缺口"(空閑塊)。當(dāng)你請求保留一大塊虛擬內(nèi)存時,虛擬機(jī)管理器需要在虛擬地址范圍內(nèi)找到一個足夠大的空閑塊來滿足該請求--如果你只有幾個空閑塊,其總和足夠大,那就無法工作。這意味著即使你有2GB,你也不一定能看到所有的2GB被使用。當(dāng)大多數(shù)應(yīng)用程序作為32位進(jìn)程運(yùn)行時,這是一個嚴(yán)重的問題。今天,我們在64位有一個充足的虛擬地址范圍,所以物理內(nèi)存是主要的關(guān)注點。當(dāng)你提交內(nèi)存時,VMM確保你有足夠的物理存儲空間,如果你真的想使用該內(nèi)存。當(dāng)你實際寫入數(shù)據(jù)時,VMM將在物理內(nèi)存中找到一個頁面(4KB)來存儲這些數(shù)據(jù)。這個頁面現(xiàn)在是你進(jìn)程工作集的一部分。當(dāng)你啟動你的進(jìn)程時,這是一個非常正常的操作。
當(dāng)機(jī)器上的進(jìn)程使用的內(nèi)存總量超過機(jī)器所擁有的內(nèi)存時,一些頁面將需要被寫入頁面文件(如果有的話,大多數(shù)情況下是這樣的)。這是一個非常緩慢的操作,所以通常的做法是盡量避免進(jìn)入分頁。我在簡化這個問題--實際的細(xì)節(jié)與這個討論沒有關(guān)系。當(dāng)進(jìn)程處于穩(wěn)定狀態(tài)時,通常你希望看到你積極使用的頁面被保留在你的工作集中,這樣我們就不需要支付任何成本來把它們帶回來。在下一節(jié)中,我們將討論GC是如何避免分頁的。
我故意把這一節(jié)寫得很短,因為GC才是需要代表你與虛擬內(nèi)存互動的人,但了解一點基本情況有助于解釋性能工具的結(jié)果。
GC基礎(chǔ)
垃圾收集器提供了內(nèi)存安全的巨大好處,使開發(fā)人員不必手動釋放內(nèi)存,并節(jié)省了可能是幾個月或幾年的調(diào)試堆損壞的時間。如果你不得不調(diào)試堆損壞,你就會知道這有多難。但是它也給內(nèi)存性能分析帶來了挑戰(zhàn),因為GC不會在每個對象死亡后運(yùn)行(這將是令人難以置信的低效),而且GC越復(fù)雜,如果你需要做內(nèi)存分析,你就必須考慮得越多(你可能會,也可能不會,我們將在下一節(jié)討論這個問題)。本節(jié)是為了建立一些基本概念,幫助你對.NET GC有足夠的了解,以便在面對內(nèi)存調(diào)查時知道什么是正確的方法。
了解GC堆內(nèi)存的使用與進(jìn)程/機(jī)器內(nèi)存的使用情況
GC堆只是你進(jìn)程中的一種內(nèi)存使用情況
在每個進(jìn)程中,每個使用內(nèi)存的組件都是相互共存的。在任何一個.NET進(jìn)程中,總有一些非GC堆的內(nèi)存使用,例如,在你的進(jìn)程中總是有一些模塊被加載,需要消耗內(nèi)存。但可以說,對于大多數(shù)的.NET應(yīng)用程序來說,這意味著GC堆占用大部分的內(nèi)存。
如果一個進(jìn)程的私有提交字節(jié)總數(shù)(如上所述,GC堆總是在私有內(nèi)存中)與你的GC堆的提交字節(jié)數(shù)相當(dāng)接近,你就知道大部分是由于GC堆本身造成的,所以這就是你應(yīng)該關(guān)注的地方。如果你觀察到一個明顯的差異,這時你應(yīng)該開始擔(dān)心查看進(jìn)程中的其他內(nèi)存使用情況。
GC是按進(jìn)程進(jìn)行的,但它知道機(jī)器上的物理內(nèi)存負(fù)載
GC是一個按進(jìn)程的組件(自從CLR誕生以來一直如此)。大多數(shù)GC的啟發(fā)式方法都是基于每個進(jìn)程的測量,但GC也知道機(jī)器上的全局物理內(nèi)存負(fù)載。我們這樣做是因為我們想避免陷入分頁的情況。GC將一定的內(nèi)存負(fù)載百分比識別為 "高內(nèi)存負(fù)載情況"。當(dāng)內(nèi)存負(fù)載百分比超過這個百分比時,GC就會進(jìn)入一個更積極的模式,也就是說,如果它認(rèn)為有成效的話,它會選擇做更多的完全阻塞的GC,因為它想減少堆的大小。
目前,在較小的機(jī)器上(即內(nèi)存小于80GiB),默認(rèn)情況下GC將90%視為高內(nèi)存負(fù)荷。在有更多內(nèi)存的機(jī)器上,這是在90%到97%之間。這個閾值可以通過COMPLEX_GCHighMemPercent環(huán)境變量(或者從.NET 5開始在runtimeconfig.json中配置System.GC.HighMemoryPercent)來調(diào)整。你想調(diào)整這個的主要原因是為了控制堆的大小。例如,在一臺有64GB內(nèi)存的機(jī)器上,對于主要的主導(dǎo)進(jìn)程,當(dāng)有10%的內(nèi)存可用時,GC開始反應(yīng)是合理的。但是對于較小的進(jìn)程(例如,如果一個進(jìn)程只消耗1GB的內(nèi)存),GC可以在<10%的可用內(nèi)存下舒適地運(yùn)行,所以你可能想對這些進(jìn)程設(shè)置得更高。另一方面,如果你想讓較大的進(jìn)程擁有較小的堆大小(即使機(jī)器上有大量可用的物理內(nèi)存),把這個值調(diào)低將是一個有效的方法,讓GC更快地做出反應(yīng),壓縮堆的大小。
對于在容器中運(yùn)行的進(jìn)程,GC會根據(jù)容器的限制來考慮物理內(nèi)存。
本節(jié)描述了如何找出每個GC觀察到的內(nèi)存負(fù)載。
了解GC是如何被觸發(fā)的
到目前為止,我們用GC來指代組件。下面我將用GC來指代組件,或者指代一個或多個在堆上進(jìn)行內(nèi)存回收的集合行為,即GC或GCs。
觸發(fā)GC的主要原因是分配
由于GC是用來管理內(nèi)存分配的,自然觸發(fā)GC的最主要因素是由于分配。隨著進(jìn)程的運(yùn)行和分配的發(fā)生,GC將不斷被觸發(fā)。我們有一個 "分配預(yù)算 "的概念,它是決定何時觸發(fā)GC的主導(dǎo)因素。我們將在下面非常詳細(xì)地討論分配預(yù)算
觸發(fā)GC的其他因素
GC也可以由于機(jī)器運(yùn)行到高物理內(nèi)存壓力而被觸發(fā),或者如果用戶通過調(diào)用
GC.Collect而自己誘發(fā)GC。
了解分配內(nèi)存的成本
由于大多數(shù)GC是由于分配而觸發(fā)的,所以值得了解分配的成本。首先,當(dāng)分配沒有觸發(fā)GC時,它是否有成本?答案是絕對的。有一些代碼需要運(yùn)行來提供分配--只要你必須運(yùn)行代碼來做一些事情,就會有成本。這只是一個多少的問題。
分配中開銷最大的部分(沒有觸發(fā)GC)是內(nèi)存清除。GC有一個契約,即它所有分配的內(nèi)存會用零填充。我們這樣做是為了安全、保障和可靠性的原因。
我們經(jīng)常聽到人們談?wù)摐y量GC成本,但卻不怎么談?wù)摐y量分配成本。一個明顯的原因是由于GC干擾了你的線程。還有一種情況是,監(jiān)測GC發(fā)生的時間是非常輕量的 - 我們提供了輕量級的工具,可以告訴你這個。但是分配一直在發(fā)生,而且很難在每次分配發(fā)生時都進(jìn)行監(jiān)控 - 會占用很多性能資源,很可能使你的進(jìn)程不再以有意義的狀態(tài)運(yùn)行。我們可以通過以下適當(dāng)?shù)姆绞絹頊y量分配成本,在工具部分,我們將看到如何用各種工具技術(shù)來做這些事情--
監(jiān)控內(nèi)存分配的3種方法
1)我們還可以測量GC的發(fā)生頻率,這告訴我們發(fā)生了多少分配。畢竟,大多數(shù)GC是由于分配而被觸發(fā)的。
2)對非常頻繁發(fā)生的事情進(jìn)行分析的方法之一是抽樣。
3)當(dāng)你有了CPU使用信息,你可以在GC方法中查看內(nèi)存清除的成本。實際上,通過GC方法名稱來查找東西顯然是非常內(nèi)部且專業(yè)的,并受制于實現(xiàn)的變化。但由于本文檔的目標(biāo)是大眾,包括有經(jīng)驗的性能工程師,我將提到幾個具體的方法(其名稱往往不會有太大的變化),作為進(jìn)行性能測量的一種方式。
如何正確看待GC堆的大小
這聽起來是一個簡單的問題。通過測量,對嗎?是的,但是當(dāng)你測量GC堆的時候,就很重要了。
看一下GC堆的大小與GC發(fā)生的時間關(guān)系
這到底是什么意思?假設(shè)我們不考慮GC發(fā)生的時間,只是每秒鐘測量一次堆的大小。請看下面這個(編造的)例子
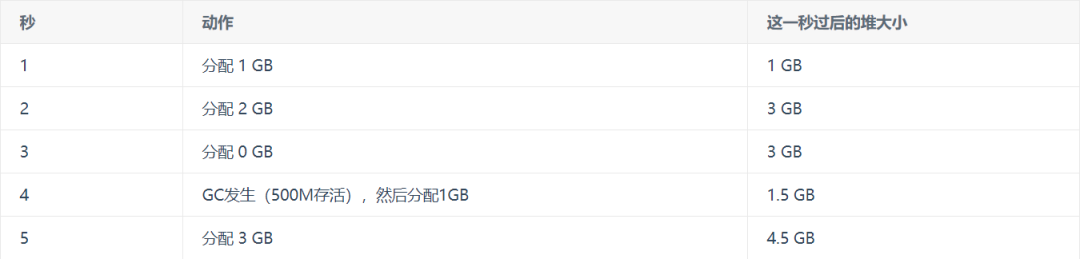
我們可以說,是的,有一個GC發(fā)生在第4秒,因為堆的大小比第3秒小。但我們再看看另一種可能性-

如果我們只有堆的大小數(shù)據(jù),我們就不能說GC是否已經(jīng)發(fā)生。
這就是為什么測量GC發(fā)生時的堆大小是很重要的。自然,GC本身提供的部分性能測量數(shù)據(jù)正是如此 - 每次GC前后的堆大小,也就是說,每次GC的進(jìn)入和退出(以及其他大量的數(shù)據(jù),我們將在本文的后面看到)。不幸的是,許多內(nèi)存工具,或者我經(jīng)常看到人們采取的診斷方法,都沒有考慮到這一點。他們做內(nèi)存診斷的方式是 "讓我給你看看在你碰巧問起的時候堆是什么樣子的"。這通常是沒有幫助的,有時甚至是完全誤導(dǎo)的。這并不是說像這樣的工具完全沒有幫助 - 當(dāng)問題很簡單的時候,它們可能會有幫助。如果你有一個已經(jīng)持續(xù)了一段時間的戲劇性的內(nèi)存泄漏,并且你使用了一個工具來顯示你在那個時候的堆(要么通過采取進(jìn)程轉(zhuǎn)儲和使用SoS,要么通過另一個工具來轉(zhuǎn)儲堆),那可能真的很明顯泄漏是什么。這是性能分析中的一個常見模式--問題越嚴(yán)重,就越容易找出問題。但是,當(dāng)你遇到的性能問題不是這種低垂的果實時,這些工具就顯得不足了。
分配預(yù)算
看完上一段,思考分配預(yù)算的一個簡單方法是上一次GC退出時的堆大小和這次GC進(jìn)入時的堆大小之間的差異。因此,分配預(yù)算是指在觸發(fā)下一次GC之前,GC允許多少分配。在表1和表2中,分配預(yù)算是一樣的 - 3GB。
然而,由于.NET GC支持釘住對象(防止GC移動被釘住的對象)以及釘住的復(fù)雜情況,分配預(yù)算往往不是2個堆大小之間的區(qū)別。然而,預(yù)算是 "在觸發(fā)下一次GC之前的分配量 "的想法仍然成立。我們將在本文檔的后面討論更多關(guān)于釘住的問題( 后面的內(nèi)容.)。
當(dāng)試圖提高內(nèi)存性能時,我看到人們經(jīng)常做的一件事(或只做一件事)是減少分配。如果你真的可以在性能關(guān)鍵路徑開始之前預(yù)先分配所有的東西,我說你更有更多的權(quán)利!但是,這有時是非常不實際的。例如,如果你使用的是庫,你并不能完全控制它們的分配(當(dāng)然,你可以嘗試找到一種無分配的方式來調(diào)用API,但并不保證有這樣的方式,而且它們的實現(xiàn)可能會改變)。
那么,減少分配是一件好事嗎?是的,只要它確實會對你的應(yīng)用程序的性能產(chǎn)生影響,并且不會使你的代碼中的邏輯變得非常笨拙或復(fù)雜,從而使它成為一個值得的優(yōu)化。減少分配實際上會降低性能嗎?這完全取決于你是如何減少分配的。你是在消除分配還是用其他東西來代替它們?因為用其他東西代替分配可能不會減少GC所要做的工作。
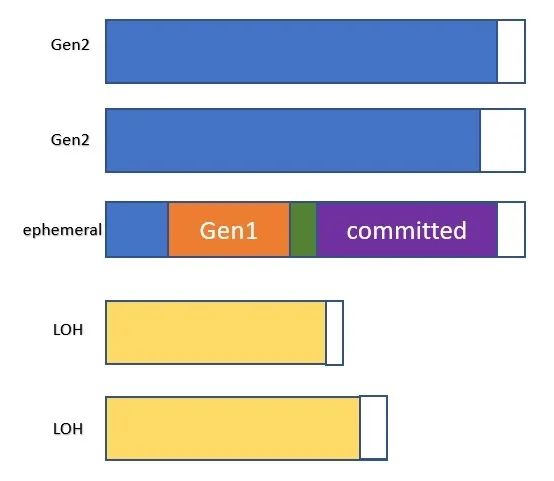
分代GC的影響
.NET的GC是分代的,有3代,IOW,GC堆中的對象被分為3代;gen0是最年輕的一代,gen2是老一代。gen1作為一個緩沖區(qū),通常是為了在觸發(fā)GC時仍在請求中的數(shù)據(jù)(所以我們希望在我們做gen1時,這些數(shù)據(jù)不會被你的代碼所引用)。
根據(jù)設(shè)計,分代GC不會在每次觸發(fā)GC時收集整個堆。他們嘗試做年輕一代的GC,比老一代的GC更頻繁。老一代的GC通常成本更高,因為它們收集的堆更多。
你很可能曾經(jīng)聽說過 "GC暫停 "這個術(shù)語。GC暫停是指GC以STW(Stop-The-World)的方式執(zhí)行其工作時。對于并發(fā)GC來說,它與用戶線程同時進(jìn)行大部分的GC工作,GC暫停的時間并不長,但是GC仍然需要花費(fèi)CPU周期來完成它的工作。年輕的gen GCs,即gen0和gen1 GC,被稱為短暫的GC,而老的gen GC,即gen2 GC,也被稱為full GC,因為它們收集整個堆。當(dāng)genX GC發(fā)生時,它收集了genX和它所有的年輕世代。因此,gen1 GC同時收集了堆中的gen0和gen1部分。
這也使得看堆變得更加復(fù)雜,因為如果你剛從一個老一代的GC中出來,特別是一個正在整理的GC,你的堆的大小顯然比你在該GC被觸發(fā)之前要小得多;但如果你看一下年輕一代的GC,它們可能正在被整理,但堆的大小差異沒有那么大,這就是設(shè)計。
上面提到的分配預(yù)算概念實際上是每一代的,所以gen0、gen1和gen2都有自己的分配預(yù)算。用戶的分配將發(fā)生在gen0,并消耗gen0的分配預(yù)算。當(dāng)分配消耗了gen0的所有預(yù)算時,GC將被觸發(fā),gen0的幸存者將消耗gen1的分配預(yù)算。同樣地,gen1的幸存者將消耗gen2的預(yù)算。
圖1 - 經(jīng)過不同代GC的對象

一個對象 "死了 "和它被清理掉之間的區(qū)別可能會讓人困惑。我收到的一個常見問題是:"我不再保留我的對象了,而且我看到GC正在發(fā)生,為什么我的對象還在那里?"。請注意,一個對象不再被用戶代碼持有的事實(在本文中,用戶代碼包括框架/庫代碼,即不是GC代碼)需要被GC掃描到。要記住的一個重要規(guī)則是:"如果一個對象在genX中,這意味著它只可能在genX GC發(fā)生時被回收",因為這時GC會真正去檢查genX中的對象是否還活著。如果一個對象在gen2中,不管發(fā)生了多少次短暫的GC(即0代和1代GC),這個對象仍然會在那里,因為GC根本沒有收集gen2。另一種思考方式是,一個對象所處的代數(shù)越高,GC需要收集的工作就越多。
大對象堆
現(xiàn)在是談?wù)摯髮ο蟮暮脮r機(jī),也就是LOH(大對象堆)。到目前為止,我們已經(jīng)提到了gen0、gen1和gen2,以及用戶代碼總是在gen0中分配對象。實際上,如果對象太大,這并不正確 - 它們會被分配到堆的另一個部分,即LOH。而gen0、gen1和gen2組成了SOH(小對象堆)。
在某種程度上,你可以認(rèn)為LOH是一種阻止用戶不小心分配大對象的方式,因為大對象比小對象更容易引入性能挑戰(zhàn)。例如,當(dāng)運(yùn)行時默認(rèn)發(fā)放一個對象時,它保證內(nèi)存被清空。內(nèi)存清空是一個昂貴的操作,如果我們需要清空更多的內(nèi)存,它的成本會更高。也更難找到空間來容納一個更大的對象。
LOH在內(nèi)部是作為gen3被跟蹤的,但在邏輯上它是gen2的一部分,這意味著LOH只在gen2的GC中被收集。這意味著,如果你代碼經(jīng)常會使用LOH,你就會經(jīng)常觸發(fā)gen2的GC,如果你的gen2也很大,這意味著GC將不得不做大量的工作來執(zhí)行g(shù)en2的GC。
和其他gen一樣,LOH也有它的分配預(yù)算,當(dāng)它用完時,與gen0不同,gen2 GC將被觸發(fā),因為LOH只在gen2 GC期間被清理。
默認(rèn)情況下,一個對象進(jìn)入LOH的閾值是>=85000字節(jié)。這可以通過使用GCLOHThreshold配置來調(diào)整更高。LOH也默認(rèn)不壓縮,除非它在有內(nèi)存限制的容器中運(yùn)行(容器行為在.NET Core 3.0中引入)。
碎片化(自由對象)是堆大小的一部分
另一個常見問題是 "我看到gen2有很多自由空間,為什么GC沒有使用這些空間?"。
答案是,GC正在使用這個空間。我們必須再次回到何時測量堆的大小,但現(xiàn)在我們需要增加另一個維度 - 整理GC vs 清掃GC。
.NET GC可以執(zhí)行整理或清掃GC。整理是開銷更大的操作,因為GC會移動對象(會發(fā)生內(nèi)存復(fù)制),這意味著它必須更新堆上這些對象的所有引用,但整理可以大大減少堆的大小。清掃GC不進(jìn)行壓縮,而是將相鄰的死對象凝聚成一個空閑對象,并將這些空閑對象穿到該代的空閑列表中。空閑列表占據(jù)的大小,我們稱之為碎片,也是gen的一部分,因此在我們報告gen和堆的大小時也包括在內(nèi)。雖然在這種情況下,堆的大小并沒有什么變化,但重要的是要明白這個空閑列表是用來容納年輕一代的幸存者的,所以我們要使用空閑空間。
這里我們將介紹GC的另一個概念 - 并發(fā)的GC與阻塞的GC。
并發(fā)GC/后臺GC
我們知道,如果我們以停止托管線程的方式進(jìn)行GC,可能需要很長的時間,也就是我們所說的完全阻塞式GC。我們不想讓用戶線程暫停那么久,所以大多數(shù)時候,一個完整的GC是并發(fā)進(jìn)行的,這意味著GC線程與用戶線程同時運(yùn)行,在GC的大部分時間里(一個并發(fā)的GC仍然需要暫停用戶線程,但只是短暫的暫停)。目前.NET中的并發(fā)GC風(fēng)格被稱為后臺GC,或簡稱BGC。BGC只進(jìn)行清掃。也就是說,BGC的工作是建立一個第二代自由列表來容納第一代的幸存者。短暫的GC總是作為阻塞的GC來做,因為它們足夠短。
現(xiàn)在我們再來思考一下 "何時測量 "的問題。當(dāng)我們做一個BGC時,在該GC結(jié)束時,一個新的自由列表被建立起來。隨著第一代GC的運(yùn)行,他們將使用這個自由列表的一部分來容納他們的幸存者,所以列表的大小將變得越來越小。因此,當(dāng)你說 "我看到gen2有很多空閑空間 "時,如果那是在BGC剛剛發(fā)生的時候,或者剛剛發(fā)生不久的時候,那是正常的。如果到了我們做下一次BGC的時候,gen2中總是有很多空閑空間,這意味著我們做了那么多工作來建立一個空閑列表,但它并沒有被使用多少,這就是一個真正的性能問題。我已經(jīng)在一些場景中看到了這種情況,我們正在建立一個解決方案,使我們能夠進(jìn)行最佳的BGC觸發(fā)。
Pinning 再次增加了碎片的復(fù)雜性,我們將在釘住章節(jié)中談及。
GC堆的物理表示
我們一直在討論如何正確地測量GC堆的大小,但是GC堆在內(nèi)存中到底是什么樣子的,也就是說,GC堆是如何物理組織的?
GC像其他Win32程序一樣通過
VirtualAlloc和VirtualFreeAPI來獲取和釋放虛擬內(nèi)存(在Linux上通過mmap/munmap完成)。GC對虛擬內(nèi)存進(jìn)行的操作有以下幾點當(dāng)GC堆被初始化時,它為SOH保留了一個初始段,為LOH保留了另一個初始段,并且只在每個段的開頭提交幾個頁面來存儲一些初始信息。
當(dāng)分配發(fā)生在這個段上時,內(nèi)存會根據(jù)需要被提交。對于SOH來說,由于只有一個段,gen0、gen1和gen2此時都在這個段上。要記住的一個不變因素是,兩個短暫的gen,即gen0和gen1,總是生活在同一個段上,這個段被稱為短暫段,這意味著合并的短暫gen永遠(yuǎn)不會比一個段大。如果SOH的增長超過了一個段的容量,在GC期間將獲得一個新的段。gen0和gen1所在的段是新的短暫段,另一個段現(xiàn)在變成了gen2段。這是在GC期間完成的。LOH是不同的,因為用戶的分配會進(jìn)入LOH,新的段是在分配時間內(nèi)獲得的。因此,GC堆可能看起來像這樣(在段的末尾可能有未使用的空間,用白色空間表示):
圖. 2 - GC堆的段
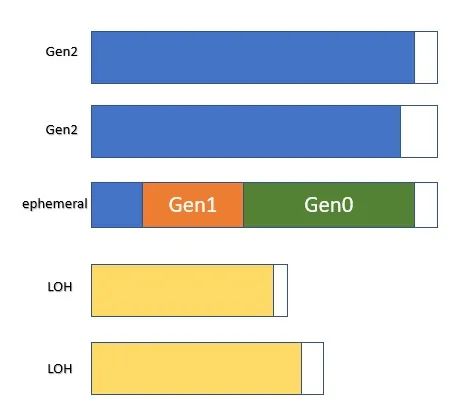
隨著GC的發(fā)生和內(nèi)存回收,當(dāng)段上沒有發(fā)現(xiàn)活對象時,段就會被釋放;段空間的末端(即段上最后一個活對象的末端,直到段的末端)被取消提交,除了短暫的段。
對短暫段的特殊處理
對于短暫段,我們保留GC后提交的最后一個實時對象之后的空間,因為我們知道gen0分配將立即使用這個空間。因為我們要分配的內(nèi)存量是gen0的預(yù)算,所以提交的空間量就是gen0的預(yù)算。這回答了另一個常見問題 - "為什么GC提交的內(nèi)存比堆的大小多?"。這是因為提交的字節(jié)包括gen0預(yù)算部分,而如果你碰巧在GC發(fā)生后不久看一下堆,它還沒有消耗大部分的空間。特別是當(dāng)你有服務(wù)器GC時,它可能有相當(dāng)大的gen0預(yù)算;這意味著這個差異可能很大,例如,如果有32個堆,每個堆有50MB的gen0預(yù)算,你在GC后馬上看堆的大小,你看到的大小會比提交的字節(jié)少(32 * 50 = 1.6 GB)。
請注意,在.NET 5中,取消提交的行為發(fā)生了變化,我們可以留下更多的內(nèi)存,因為我們想把gen1也納入GC的考慮。另外,服務(wù)器GC的取消提交現(xiàn)在是在GC暫停之外完成的,所以GC結(jié)束時報告的部分內(nèi)容可能會被取消提交。這是一個實現(xiàn)細(xì)節(jié)--使用gen0的預(yù)算通常仍然是一個非常好的近似值,可以確定投入的部分是多少。
按照上面的例子,在gen2 GC之后,堆可能看起來是這樣的(注意這只是一個例子說明)。
圖3 - gen2 GC后的GC堆段
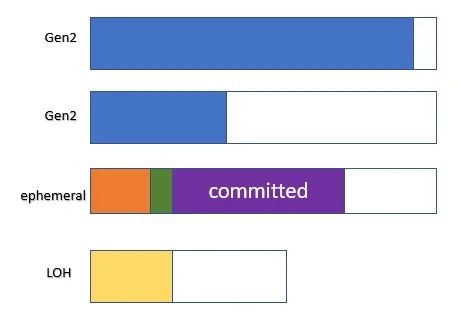
在gen0的GC之后,由于它只能收集gen0的空間,我們可能會看到這個:
圖4 - gen0 GC后的GC堆段
大多數(shù)時候,你不必關(guān)心GC堆被組織成段的事實,除了在32位上,因為虛擬地址空間很小(總共2-4GB),而且可能是碎片化的,甚至當(dāng)你要求分配一個小對象時,你可能得到一個OOM,因為我們需要保留一個新的段。在64位平臺上,也就是我們大多數(shù)客戶現(xiàn)在使用的平臺上,有大量的虛擬地址空間,所以預(yù)留空間不是一個問題。而且在64位平臺上,段的大小要大得多。
GC自己的記賬
很明顯,GC也需要做自己的記賬工作,這就需要消耗內(nèi)存 - 這大約是GC堆大小的1%。最大的消耗是由于啟用了并行GC,這是默認(rèn)的。準(zhǔn)確地說,并發(fā)的GC記賬與堆的儲備大小成正比,但其余的記賬實際上與堆的范圍成正比。由于這是1%,你需要關(guān)心它的可能性極低。
什么時候GC會拋出一個OOM異常?
幾乎所有人都聽說過或遇到過OOM異常。GC究竟什么時候會拋出一個OOM異常呢?在拋出OOM之前,GC確實非常努力。因為GC大多做短暫的GC,這意味著堆的大小往往不是最小的,這是設(shè)計上的。然而,GC通常會嘗試一個完全阻塞的GC,并在拋出OOM之前驗證它是否仍然不能滿足分配請求。但也有一個例外,那就是GC有一個調(diào)整啟發(fā)式,說它不會繼續(xù)嘗試完全阻塞的GC,如果它們不能有效地縮小堆的大小。它將嘗試一些gen1 GCs和完全阻塞的GCs混合在一起。所以你可能會看到一個OOM拋出,但拋出它的GC并不是一個完全阻塞的GC。
了解GC暫停,即何時觸發(fā)GC以及GC持續(xù)多長時間
當(dāng)人們研究 GC 暫停問題時,我總是問他們是否關(guān)心總暫停和/或單個暫停。總暫停是由 "GC中的%暫停時間 "來表示的,每次GC被觸發(fā),暫停都會被加到總暫停中。通常情況下,你關(guān)心這個是出于吞吐量的原因,因為你不希望GC過多地暫停你的代碼,以至于把吞吐量降低到可接受的程度。單個暫停表示單個GC持續(xù)的時間。除了作為總暫停的一部分,你關(guān)心單個暫停的一個原因通常是為了請求的尾部延遲--你想減少長的GC以消除或減少它們對尾部延遲的影響。
單個GC的持續(xù)時間
.NET的GC是一個引用追蹤式GC,這意味著GC需要通過各種根(例如,堆棧定位,GC處理表)去追蹤,以找出哪些對象應(yīng)該是活的。因此,GC的工作量與有多少對象在內(nèi)存中存活成正比。一個GC持續(xù)的時間與GC的工作量大致成正比。我們將在本文檔的后面更多地討論根的問題。
對于阻塞式GC來說,由于它們在整個GC期間暫停用戶線程,所以GC持續(xù)的時間與GC暫停的時間相同。對于BGC,它們可以持續(xù)相當(dāng)長的時間,但暫停時間要小得多,因為GC主要是以并發(fā)的方式工作。
注意,我說過GC的持續(xù)時間與GC的工作量大致成正比。為什么是大致?GC需要像其他東西一樣分享機(jī)器上的核心。對于阻塞式GC,當(dāng)我們說 "GC暫停用戶線程 "時,我們實際上是指 "執(zhí)行托管代碼的線程"。執(zhí)行本地代碼的線程可以自由運(yùn)行(盡管需要等待GC結(jié)束,如果它們需要在GC仍在進(jìn)行的時候返回到托管代碼)。最后,不要忘了,在線程運(yùn)行時,其他進(jìn)程由于GC的原因暫停了你的進(jìn)程。
這就是我們引入的另一個概念,即GC的不同主要類型--工作站GC vs 服務(wù)器GC(簡稱WKS GC vs SVR GC)。
服務(wù)器GC
顧名思義,它們分別用于工作站(即客戶端)和服務(wù)器的工作負(fù)載。工作站工作負(fù)載意味著你與許多其他進(jìn)程共享機(jī)器,而服務(wù)器工作負(fù)載通常意味著它是機(jī)器上的主導(dǎo)進(jìn)程,并傾向于有許多用戶線程在這個進(jìn)程中工作。這兩種GC的主要區(qū)別在于,WKS GC只有一個堆,SVR GC有多少個堆取決于機(jī)器上有多少邏輯核心,也就有和邏輯核心相同數(shù)量的GC線程進(jìn)行GC工作。到目前為止,我們介紹的所有概念都適用于每個堆,例如,分配預(yù)算現(xiàn)在是每代每堆,所以每個堆都有自己的gen0預(yù)算。當(dāng)任何一個堆的gen0分配預(yù)算用完后,就會觸發(fā)GC。上圖中的GC堆段將在每個堆上重復(fù)出現(xiàn)(盡管它們可能包含不同數(shù)量的內(nèi)存)。
由于2種工作負(fù)載的性質(zhì)不同,SVR GC有2個明顯不同的屬性,而WKS GC則沒有。
SVR GC線程的優(yōu)先級被設(shè)置為 "THREAD_PRIORITY_HIGHEST",這意味著如果其他線程的優(yōu)先級較低,它就會搶占這些線程,而大多數(shù)線程都是如此。相比之下,WKS GC在觸發(fā)GC的用戶線程上運(yùn)行GC工作,所以它的優(yōu)先級是該線程運(yùn)行的任何優(yōu)先級,通常是正常的優(yōu)先級。
SVR GC線程與邏輯核心硬性綁定。
參見MSDN文檔中關(guān)于SVR GC的圖解。既然我們現(xiàn)在談到了服務(wù)器和并發(fā)/后臺GC,你可能會問服務(wù)器GC也有并發(fā)的嗎?答案是肯定的。我再次向你推薦MSDN doc,因為它對Background WKS GC與Background SVR GC有一個明確的說明。
我們這樣做的原因是,當(dāng)SVR GC發(fā)生時,我們希望它能夠盡可能快地完成它的工作。雖然這在大多數(shù)情況下確實達(dá)到了這個目標(biāo),但是它可能會帶來一個你應(yīng)該注意的復(fù)雜情況 - 如果在SVR GC發(fā)生的同時,有其他線程也以
THREAD_PRIORITY_HIGHEST或更高的速度運(yùn)行,它們會導(dǎo)致SVR GC花費(fèi)更長的時間,因為每個GC線程只在其各自的核心上運(yùn)行(我們將在后面的章節(jié))看到如何診斷長GC的問題。而這種情況通常非常罕見,但是有一個注意事項,那就是當(dāng)你在同一臺機(jī)器上有多個使用SVR GC的進(jìn)程時。在運(yùn)行時的早期,這種情況很少見,但是隨著這種情況越來越少,我們創(chuàng)建了一些配置,允許你為使用SVR GC的進(jìn)程指定更少的GC堆/線程。這些配置的解釋是這里。我見過一些人故意把一個大的服務(wù)器進(jìn)程分成多個小的進(jìn)程,這樣每個進(jìn)程都會有一個較小的堆,通過使用堆數(shù)較少的服務(wù)器GC。他們用這種方式取得了更好的效果(更小的堆意味著更短的暫停時間,如果它確實需要做完全阻塞的GC的話)。這是一個有效的方法,但當(dāng)然只能在有意義的情況下使用它 - 對于某些應(yīng)用來說,將一個進(jìn)程分成多個進(jìn)程是非常尷尬的。
多長時間觸發(fā)一次GC?
如前所述,當(dāng)gen0的分配預(yù)算用完時,就會觸發(fā)GC。當(dāng)一個GC被觸發(fā)時,發(fā)生的第一步是我們決定這個GC將是哪一代。在工具那一章節(jié),我們將看到哪些原因會導(dǎo)致GC從gen0升級到可能的gen1或gen2,但其中的一個主要因素是gen1和gen2的分配預(yù)算。如果我們檢測到gen2的分配預(yù)算已經(jīng)用完,我們就會把這個GC升級到完全的GC。
因此,"多長時間觸發(fā)一次GC "的答案是由gen0/LOH預(yù)算耗盡的頻率決定的,而gen1或gen2的GC被觸發(fā)的頻率主要由gen1和gen2的預(yù)算耗盡的頻率決定。你自然會問 "那么預(yù)算是如何計算的?"。預(yù)算主要是根據(jù)我們看到的那一代的存活率來計算的。存活率越高,預(yù)算就越大。如果GC收集了一代對象并發(fā)現(xiàn)大多數(shù)對象都存活了,那么這么快再收集它就沒有意義了,因為GC的目標(biāo)是回收內(nèi)存。如果GC做了所有這些工作,而能回收的內(nèi)存卻很少,那么它的效率就會非常低。
這如何轉(zhuǎn)化為觸發(fā)GC的頻率是,如果一個代被頻繁地使用(即,它的存活率很低),它將被更頻繁地收集。這就解釋了為什么我們最頻繁地收集gen0,因為gen0是用于非常臨時的對象,其存活率非常低。根據(jù)代際假說,對象要么活得很久,要么很臨時,gen2持有長壽的對象,所以它們被收集的次數(shù)最少。
如前所述,在高內(nèi)存負(fù)載情況下,我們會更積極地觸發(fā)gen2阻塞式GC。當(dāng)內(nèi)存負(fù)載很高的時候,我們傾向于做完全阻塞的GC,這樣我們就可以進(jìn)行整理。雖然BGC對暫停時間有好處,但它對縮小堆沒有好處,而當(dāng)GC認(rèn)為它的內(nèi)存不足時,縮小堆就更重要了。
當(dāng)內(nèi)存負(fù)載不高時,我們做完全阻塞的GC的另一個原因是當(dāng)gen2碎片非常高時,GC認(rèn)為大幅減少堆的大小是有成效的。如果這對你來說是不必要的(即你有足夠的可用內(nèi)存),而且你寧愿避免長時間的停頓,你可以將延遲模式設(shè)置為SustainedLowLatency,告訴GC只在必須的時候做全阻塞的GC。
要記住的一條規(guī)則
那是很多材料,但如果我們把它總結(jié)為一條規(guī)則,這就是我在談?wù)揋C被觸發(fā)的頻率和單個GC持續(xù)的時間時總是告訴人們的事情。
存活的對象數(shù)量通常決定了GC需要做多少工作;不存活的對象數(shù)量通常決定了GC被觸發(fā)的頻率下面是一些極端的例子,當(dāng)我們應(yīng)用這一規(guī)則時-
情況1 - gen0根本沒有任何存活對象。這意味著gen0的GC被頻繁地觸發(fā)。但是單次gen0的暫停時間非常短,因為基本上沒有工作要做。
情況2 - 大部分gen2對象都存活。這意味著gen2的GC被觸發(fā)的頻率很低。對于單個gen2的暫停,如果GC作為阻塞GC進(jìn)行,那暫停時間會非常長;如果作為BGC進(jìn)行,會持續(xù)很長時間(但暫停時間仍然很短)。
你不能處于分配率和生存率都很高的情況下 - 你會很快耗盡內(nèi)存。
是什么使一個對象得以存活
從GC的角度來看,它被各種運(yùn)行時組件告知哪些對象應(yīng)該存活。它并不關(guān)心這些對象是什么類型;它只關(guān)心有多少內(nèi)存可以存活,以及這些對象是否有引用,因為它需要通過這些引用來追蹤那些也應(yīng)該存活的子對象。我們一直在對GC本身進(jìn)行改進(jìn),以改善GC暫停,但作為一個寫托管代碼的人,知道是什么讓對象存活下來是一個重要的方法,你可以通過它來改善你這邊的個別GC暫停。
1. 分代方面
我們已經(jīng)談到了分代GC的效果,所以第一條規(guī)則是當(dāng)一個代沒有被回收,這意味著該代的所有對象都是活的。
因此,如果我們正在收集gen2,代數(shù)方面是不相關(guān)的,因為所有的代數(shù)都會被收集。我收到的一個常見問題是:"我已經(jīng)多次調(diào)用GC.Collect()了,對象還在那里,為什么GC不把它處理掉呢?"。這是因為當(dāng)你誘導(dǎo)一個完全阻塞的GC時,GC并不參與決定哪些對象應(yīng)該是活的 - 它只會由我們將在下面討論的用戶根(堆棧/GC句柄/等等)告知是否存活,我們將在下面談?wù)摗R虼耍@意味著無論什么東西還活著,都是因為它需要活著,而GC根本無法回收它。
不幸的是,很少有性能工具會強(qiáng)調(diào)生成效應(yīng),盡管這是.NET GC的一個基石。許多性能工具會給你一個堆轉(zhuǎn)儲--有些會告訴你哪些堆棧變量或哪些GC句柄持有對象。你可以擺脫很大比例的GC句柄,但你的GC暫停時間幾乎沒有改善。為什么呢?如果你的大部分GC暫停是由于gen0的GC被gen2中的一些對象持有而造成的,那么如果你設(shè)法擺脫一些gen2的對象,而這些對象并不持有這些gen0的對象,那也是沒有用的。是的,這將減少gen2的工作,但是如果gen2的GC發(fā)生的頻率很低,那就不會有太大的區(qū)別,如果你的目標(biāo)是減少gen2的GC的數(shù)量,你就不會有什么進(jìn)展。
2. 用戶根
你最有可能聽到的常見類型的根是指向?qū)ο蟮亩褩W兞俊C句柄和終結(jié)器隊列。我把這些稱為用戶根,因為它們來自用戶代碼。由于這些是用戶代碼可以直接影響的東西,所以我將詳細(xì)地討論它們。
堆棧變量
堆棧變量,特別是對于C#程序來說,實際上并沒有被談及很多。原因是JIT也能很好地意識到堆棧變量何時不再被使用。當(dāng)一個方法完成后,堆棧根保證會消失。但即使在這之前,JIT也能知道什么時候不再需要一個堆棧變量,所以不會向GC報告,即使GC發(fā)生在一個方法的中間。請注意,在DEBUG構(gòu)建中不是這種情況。
GC句柄
GC句柄是一種方式,用戶代碼可以持有一個對象,或者檢查一個對象而不持有它。前者被稱為強(qiáng)柄,后者被稱為弱柄。強(qiáng)句柄需要被釋放,以使它不再保留一個對象,也就是說,你需要在句柄上調(diào)用Free。有一些人給我看了!gcroot(SoS調(diào)試器的一個擴(kuò)展命令,可以顯示一個對象的根部)的輸出,說有一個強(qiáng)句柄指向一個對象,問我為什么GC還沒有回收這個對象。根據(jù)設(shè)計,這個句柄告訴GC這個對象需要是活的,所以GC不能回收它。目前,以下用戶暴露的句柄類型是強(qiáng)句柄。Strong和Pinned;而弱柄是Weak和WeakTrackResurrection。但是如果你看過SoS的 !gchandles輸出,Pinned句柄也可以包括AsyncPinned。
釘住
我在上面提到過幾次釘住。大多數(shù)人都知道釘住是什么 - 它向GC表示一個對象不能被移動。但從GC的角度來看,釘住的意義是什么呢?由于GC不能移動這些被釘住的對象,它使被釘住的對象之前的死角變成了一個自由對象,這個自由對象可以用來容納年輕一代的生存者。但這里有一個問題 - 正如我們從上面的代際討論中看到的,如果我們簡單地將這些被釘住的對象提升到老一代,就意味著這些自由空間也是老一代的一部分,要用它們來容納年輕一代的幸存者,唯一的辦法就是我們真的對年輕一代做一次GC(否則我們甚至沒有 "年輕一代的幸存者")。然而,如果我們能在gen0中保留這些自由空間,它們就可以被用戶分配使用。這就是為什么GC有一個叫做降代的功能,我們將把這些被釘住的對象降代到gen0,這意味著它們之間的空閑空間將是gen0的一部分,當(dāng)用戶代碼分配時,我們可以立即使用它們。
圖5 - 降代(我從一張舊的幻燈片上取下來的,所以這看起來與之前的片段圖片有些不同。)
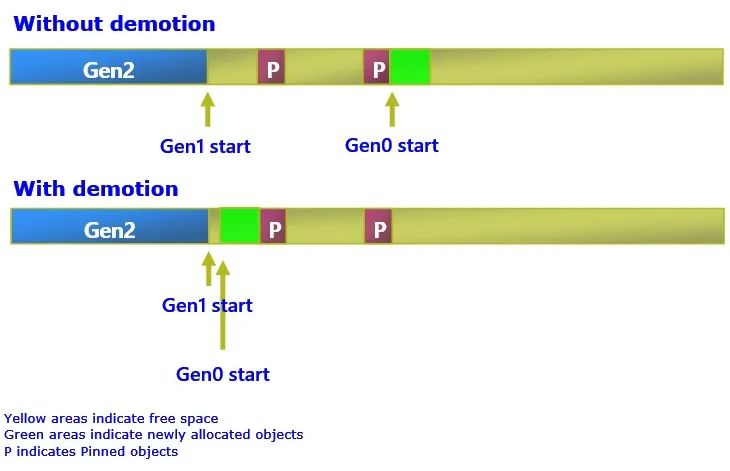
由于gen0分配可以發(fā)生在這些自由空間中,這意味著它們將消耗gen0預(yù)算而不增加gen0的大小(除非自由空間不能滿足所有的gen0預(yù)算,在這種情況下它將需要增長gen0)。
然而,GC 不會無條件地降代,因為我們不想在 gen0 中留下許多固定對象,這意味著我們必須在每次 GC 中再次查看它們,可能會有很多次 GC(因為它們是 gen0 的一部分,每當(dāng)我們執(zhí)行 gen0 GC 我們需要查看它們)。這意味著如果您遇到嚴(yán)重的固定情況,它仍然會導(dǎo)致 gen2 中的碎片問題。同樣,GC 確實有機(jī)制來應(yīng)對這些情況。但是如果你想對 GC 施加更少的壓力,你可以從用戶的 POV 中遵循這個規(guī)則—
早點釘住對象,分批釘住對象
我們的想法是,如果你把對象釘在已經(jīng)整理的那部分堆里,意味著這些對象已經(jīng)不需要移動了,所以碎片化就不是問題。如果你以后確實需要釘住,通常的做法是分配一批緩沖區(qū),然后把它們釘在一起,而不是每次都分配一個并釘住它。在.NET 5中,我們引入了一個名為POH(Pinned Object Heap(固定堆))的新特性,允許你告訴GC在分配時將釘住的對象放在一個特定的堆上。因此,如果你有這樣的控制權(quán),在POH上分配它們將有助于緩解碎片化問題,因為它們不再散落在普通堆上。
終結(jié)器
終結(jié)隊列是另一個根來源。如果你已經(jīng)寫了一段時間的.NET應(yīng)用程序,你有可能聽說過終結(jié)器是你需要避免的東西。然而,有時終結(jié)器并不是你的代碼,而是來自你所使用的庫。由于這是一個非常面向用戶的特性,我們來詳細(xì)了解一下。下面是終結(jié)器的基本性能含義 -
分配
· 如果你分配了一個可終結(jié)的對象(意味著它的類型有一個終結(jié)器),就在GC返回到VM端的分配助手之前,它將把這個對象的地址記錄在終結(jié)隊列中。
· 有一個終結(jié)者意味著你不能再使用快速分配器進(jìn)行分配,因為每個可終結(jié)的對象的分配都要到GC去注冊。
然而,這種成本通常是不明顯的,因為你不太可能分配大部分可終結(jié)的對象。更重要的成本通常來自于GC實際發(fā)生的時間,以及在GC期間如何處理可終結(jié)的對象。
回收
當(dāng)GC發(fā)生時,它將發(fā)現(xiàn)那些仍然活著的對象,并對它們升代。然后它將檢查終結(jié)隊列中的對象,看它們是否被升代 - 如果一個對象沒有被升代,就意味著它已經(jīng)死了,盡管它不能被回收(見下一段的原因)。如果你在被收集的幾代中有成噸的可終結(jié)的對象,僅這一成本就可能是明顯的。比方說,你有一大堆被提升到gen2的可終結(jié)對象(只是因為它們一直在存活),而你正在做大量的gen2 GC,在每個gen2 GC中,我們需要花時間來掃描所有的可終結(jié)對象。如果你很不頻繁地做gen2 GC,你就不需要支付這個成本。
這里就是你聽到 "終結(jié)器不好 "的原因了 - 為了運(yùn)行GC已經(jīng)發(fā)現(xiàn)的這個對象的終結(jié)器,這個對象需要是存活的。由于我們的GC是一代一代的,這意味著它將被提升到更高的一代,正如我們上面所談到的,這反過來意味著它將需要一個更高的一代GC,也就是說,一個更昂貴的GC來收集這個對象。因此,如果一個可終結(jié)的對象在第一代GC中被發(fā)現(xiàn)死亡,它將需要等到下一次做第二代GC時才會被收集,而這可能是相當(dāng)長的一段時間。也就是說,這個對象的內(nèi)存的回收可能會被推遲很多。
然而,如果你用GC.SuppressFinalize來抑制終結(jié)器,你告訴GC的是你不需要運(yùn)行這個對象的終結(jié)器。所以GC就沒有理由去提升(升代)它。當(dāng)GC發(fā)現(xiàn)它死亡時,它將被回收。
運(yùn)行終結(jié)器
這是由終結(jié)器線程處理的。在GC發(fā)現(xiàn)死的、可終結(jié)的對象(然后被升代)后,它將其移至終結(jié)隊列的一部分,告訴終結(jié)者線程何時向GC請求運(yùn)行終結(jié)者,并向終結(jié)者線程發(fā)出信號,表示有工作要做。在GC完成后,終結(jié)器線程將運(yùn)行這些終結(jié)器。被移到終結(jié)隊列這一部分的對象被說成是 "準(zhǔn)備好終結(jié)了"。你可能已經(jīng)看到各種工具提到了這個術(shù)語,例如,sos的 !finalizequeue命令告訴你finalize隊列的哪一部分儲存了準(zhǔn)備好的對象,像這樣:
Ready?for?finalization?0?objects?(000002E092FD9920->000002E092FD9920)
您經(jīng)常會看到這是 0,因為終結(jié)器線程以高優(yōu)先級運(yùn)行,因此終結(jié)器將快速運(yùn)行(除非它們被某些東西阻塞)。
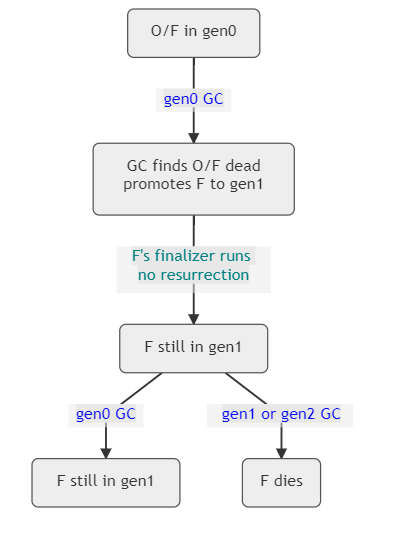
下圖說明了2個對象以及可最終確定的對象F是如何演變的。正如你所看到的,在它被提升到gen1之后,如果有一個gen0的GC,F(xiàn)仍然是活的,因為gen1沒有被收集;只有當(dāng)我們做一個gen1的GC時,F(xiàn)才能真正成為死的,我們看一下F所處的代。
圖 6 - O 是不可終結(jié)的,F(xiàn) 是可終結(jié)的
現(xiàn)在我們了解了不同類別的根,我們可以談?wù)劰芾硇詢?nèi)存泄漏的定義了
托管內(nèi)存泄漏意味著你至少有一個用戶根,隨著進(jìn)程的運(yùn)行,直接或間接地引用了越來越多的對象。這是一個泄漏,因為根據(jù)定義,GC不能回收這些對象的內(nèi)存,所以即使GC盡了最大努力(即做一個完全阻塞的GC),堆的大小最終還是會增長。
所以最簡單的方法,如果可行的話,識別你是否有托管內(nèi)存泄漏,就是在你知道你應(yīng)該有相同的內(nèi)存使用量的時候,簡單地誘導(dǎo)全阻塞GC(例如,在每個請求結(jié)束時),并驗證堆的大小沒有增長。顯然,這只是一種幫助調(diào)查內(nèi)存泄漏的方法--當(dāng)你在生產(chǎn)中運(yùn)行你的應(yīng)用程序時,你通常不希望誘發(fā)全阻塞的GCs。
“主線GC場景” vs “非主線”
如果你有一個程序只是使用堆棧并創(chuàng)建一些對象來使用,GC已經(jīng)優(yōu)化了很多年了。基本上是 "掃描堆棧以獲得根部,并從那里處理對象"。這就是許多GC論文所假設(shè)的主線GC方案,也是唯一的方案。當(dāng)然,作為一個已經(jīng)存在了幾十年的商業(yè)產(chǎn)品,并且必須滿足各種客戶的要求,我們還有一堆其他的東西,比如GC句柄和終結(jié)器。需要了解的是,雖然多年來我們也對這些東西進(jìn)行了優(yōu)化,但我們的操作是基于 "這些東西不多 "的假設(shè),這顯然不是對每個人都是如此。因此,如果你確實有很多這樣的東西,那么如果你在診斷內(nèi)存問題時,就值得關(guān)注了。換句話說,如果你沒有任何內(nèi)存問題,你不需要關(guān)心;但如果你有(例如,在GC時間百分比高),它們是值得懷疑的好東西。
完全不做 GC 的部分 GC 暫停—線程掛起?
我們沒有提到的GC暫停的最后一個部分是根本不做GC工作的部分--我指的是運(yùn)行時中的線程暫停機(jī)制。GC調(diào)用暫停機(jī)制,讓進(jìn)程中的線程在GC工作開始前停止。我們調(diào)用這個機(jī)制是為了讓線程到達(dá)它們的安全點。因為GC可能會移動對象,所以線程不能在隨機(jī)的點上停止;它們需要在運(yùn)行時知道如何向GC報告對GC堆對象的引用的點上停止,這樣GC才能在必要時更新它們。這是一個常見的誤解,認(rèn)為GC在做暫停工作--GC只是調(diào)用暫停機(jī)制來讓你的線程停止。然而暫停被報告為GC暫停的一部分,因為GC是使用它的主要組件。
我們談到了并發(fā)與阻塞的GC,所以我們知道阻塞的GC會讓你的線程在GC期間保持暫停狀態(tài),而BGC(并發(fā)的味道)會讓它們在短時間內(nèi)暫停,并在用戶線程運(yùn)行時做大部分的GC工作。不太常見的是,讓線程進(jìn)入暫停狀態(tài)可能需要一段時間。大多數(shù)情況下這是非常快的,但是緩慢的暫停是一類與管理內(nèi)存相關(guān)的性能問題,我們將專門討論如何診斷這些問題。
注意,在GC的暫停部分,只有運(yùn)行托管代碼的線程被暫停。運(yùn)行本地代碼的線程可以自由運(yùn)行。然而,如果它們需要在這樣的暫停部分返回到托管代碼,它們將需要等待,直到暫停部分結(jié)束。
知道什么時候該擔(dān)心
與任何性能調(diào)查一樣,首要的是弄清楚你是否應(yīng)該擔(dān)心這個問題。
頂層應(yīng)用指標(biāo)
如上所述,關(guān)鍵是要有性能目標(biāo) - 這些應(yīng)該由一個或多個頂級應(yīng)用指標(biāo)來表示。它們是應(yīng)用指標(biāo),因為它們直接告訴你應(yīng)用的性能方面的數(shù)據(jù),例如,你處理的并發(fā)請求數(shù),平均、最大和/或P95請求延遲。
使用頂級應(yīng)用指標(biāo)來表明你在開發(fā)產(chǎn)品時是否有性能退步或改進(jìn),這是相對容易理解的,所以我們不會在這里花太多時間。但有一點值得指出的是,有時要讓這些指標(biāo)穩(wěn)定到有一個月到一個月的趨勢,甚至一天到一天的趨勢并不容易,原因很簡單,因為工作負(fù)載并不是每天都保持不變,特別是對尾部延遲的測量。我們?nèi)绾谓鉀Q這個問題呢?
· 這正是衡量能影響它們的因素的重要原因之一。當(dāng)然,你很可能在前期不知道所有的因素。當(dāng)你知道得越多,你就可以把它們加入到你要測量的東西的范圍內(nèi)。
· 有一些頂級的組件指標(biāo),幫助你決定工作負(fù)載中有多少變化。對于內(nèi)存,一個簡單的指標(biāo)是做了多少分配。如果在今天的高峰時段,你的分配量是昨天的兩倍,你就知道這表明今天的工作負(fù)荷也許給GC帶來了更大的壓力(分配量絕對不是影響GC暫停的唯一因素,見上面的GC暫停一節(jié))。然而,有一個原因使得這成為一個受歡迎的追蹤對象,因為它與用戶代碼直接相關(guān)--你可以在一行代碼中看到分配何時發(fā)生,而將GC與一行代碼關(guān)聯(lián)起來則比較困難。
頂層的GC指標(biāo)
既然你在閱讀本文檔,顯然你關(guān)心的組件之一就是GC。那么,你應(yīng)該跟蹤哪些頂層的GC指標(biāo),以及如何決定何時應(yīng)該擔(dān)心?
我們提供了許多不同的GC指標(biāo),你可以測量 - 顯然你不需要關(guān)心所有的指標(biāo)。事實上,要確定你是否/何時應(yīng)該開始擔(dān)心GC,你只需要一到兩個頂級的GC指標(biāo)。表3列出了哪些頂級GC指標(biāo)是基于你的性能目標(biāo)相關(guān)的。如何收集這些指標(biāo)將在[后面的章節(jié)]中描述(#如何收集頂層的GC指標(biāo))。

應(yīng)擔(dān)心GC
如果你理解了GC基本原理,那么GC行為是由應(yīng)用行為驅(qū)動的,這一點應(yīng)該是非常明顯的。頂層的應(yīng)用指標(biāo)應(yīng)該告訴你什么時候出現(xiàn)了性能問題。而GC指標(biāo)可以幫助你對這些性能問題進(jìn)行調(diào)查。例如,如果你知道你的工作負(fù)載在一天中長時間處于休眠狀態(tài),那么你看一天中 "GC中暫停時間百分比 "指標(biāo)的平均值是沒有意義的,因為 "GC中暫停時間百分比 "的平均值會非常小。看這些GC指標(biāo)的一個更合理的方法是:"我們在X點左右發(fā)生了故障,讓我們看一下那段時間的GC指標(biāo),看看GC是否可能是故障的原因"。
當(dāng)相關(guān)的GC指標(biāo)顯示GC的影響很小的時候,把你的精力放在其他地方會更有成效。如果它們表明GC確實有很大的影響,這時你應(yīng)該開始擔(dān)心如何進(jìn)行內(nèi)存管理分析,這就是本文檔的大部分內(nèi)容。
讓我們詳細(xì)看看每個目標(biāo),以了解為什么你應(yīng)該看他們相應(yīng)的GC指標(biāo) -
吞吐量
為了提高你的吞吐量,你希望GC盡可能少地干擾你的線程。GC會在以下兩個方面進(jìn)行干擾
· GC可以暫停你的線程 - 阻塞的GC會在整個GC期間暫停它們,BGC會暫停一小段時間。這種暫停由 "GC中的%暫停時間(% Pause time in GC)"來表示。
· GC線程會消耗CPU來完成工作,雖然BGC不會讓你的線程暫停太多,但它確實會與你的線程競爭CPU。所以還有一個指標(biāo)叫做 "GC花費(fèi)的CPU時間%(% CPU time in GC)"。
這兩個數(shù)字可能有很大差別。"GC中的暫停時間百分比 "的計算方法是
線程被GC暫停時的耗時/進(jìn)程的總耗時
因此,如果從進(jìn)程開始到現(xiàn)在已經(jīng)10s了,線程由于GC而暫停了1s,那么GC中的暫停時間百分比就是10%。
即使BGC不在其中,GC中的CPU時間百分比也可能多于或少于GC中的暫停時間百分比,因為這取決于CPU在進(jìn)程中被其他事物使用的情況。當(dāng)GC正在進(jìn)行時,我們希望看到它盡可能快地完成;所以我們希望看到它在執(zhí)行期間有盡可能高的CPU使用率。這曾經(jīng)是一個非常令人困惑的概念,但現(xiàn)在似乎發(fā)生得更少了。我曾經(jīng)收到過一些擔(dān)心的人的報告,說 "當(dāng)我看到一個服務(wù)器GC時,它使用了100%的CPU! 我需要減少這個!"。我向他們解釋說,這實際上正是我們希望看到的--當(dāng)GC暫停了你的線程時,我們希望能使用所有的CPU,這樣我們就能更快地完成GC工作。假設(shè)GC的暫停時間為10%,在GC暫停期間,CPU使用率為100%(例如,如果你有8個核心,GC會完全使用所有8個核心),在GC之外,你的線程的CPU使用率為50%,并且沒有BGC發(fā)生(意味著GC只在你的線程暫停時做工作),那么GC的CPU時間將為
(100%?*?10%)?/?(100%?*?10%?+?50%?*?90%)?=?18%
我建議首先監(jiān)測GC中的%暫停時間,因為它的監(jiān)測開銷很低,而且是一個很好的衡量標(biāo)準(zhǔn),可以確定你是否應(yīng)該把GC作為一個最高級別的指標(biāo)來關(guān)注。監(jiān)測GC中的CPU時間百分比的成本較高(需要實際收集CPU樣本),而且通常沒有那么關(guān)鍵,除非你的應(yīng)用程序正在做大量的BGC,而且CPU真的飽和了。
通常情況下,一個行為良好的應(yīng)用程序在GC中的暫停時間小于5%,而它正在積極處理工作負(fù)載。如果你的應(yīng)用程序的暫停時間是3%,那么你把精力放在GC上就沒有什么成效了--即使你能去掉一半的暫停時間(這很困難),你也不會使總的性能提高多少。
尾部延時
之前我們討論了如何考慮測量導(dǎo)致你的尾部延遲的因素。如果尾部延遲是你的目標(biāo),除了其他因素外,GC或最長的GC可能發(fā)生在那些最長的請求中。因此,測量這些單獨(dú)的GC暫停是很重要的,看看它們是否/在多大程度上導(dǎo)致了你的延遲。有一些輕量級的方法可以知道一個單獨(dú)的GC暫停何時開始和結(jié)束,我們會看到在本文檔后面。
內(nèi)存占用率
如果你還沒有正確閱讀GC堆只是你進(jìn)程中的一種內(nèi)存使用情況,以及如何測量GC heap size,我強(qiáng)烈建議你現(xiàn)在就去做。實際上,一個被管理的進(jìn)程在GC堆之外還有明顯的甚至是大量的內(nèi)存使用,這并不罕見,所以了解是否是這樣的情況很重要。如果GC堆在整個進(jìn)程的內(nèi)存使用中只占很小的比例,那么你專注于減少GC堆的大小就沒有意義了。
挑選正確的工具和解釋數(shù)據(jù)
性能工具一覽
我怎么強(qiáng)調(diào)挑選正確工具的重要性都不為過。我經(jīng)常看到一些人花了很多時間(有時是幾個月)試圖弄清一個問題,因為他們沒有發(fā)現(xiàn)正確的工具和/或如何使用它。這并不是說即使有了正確的工具,你也不需要花費(fèi)一些精力--有時只需要一分鐘,但其他時候可能需要許多分鐘或幾個小時。
挑選合適的工具的另一個挑戰(zhàn)是,除非你在做一個基本的分析,否則根本沒有很多工具可以選擇。也就是說,有更多的工具能夠解決簡單的問題,所以如果你正在解決其中的一個問題,你選擇哪一個并不那么重要。例如,如果你有一個嚴(yán)重的托管內(nèi)存泄漏,你可以在你的開發(fā)環(huán)境中重現(xiàn),你將能夠很容易地找到一個能夠比較堆快照的工具,這樣你就可以看到哪些對象存活了,而不應(yīng)該。你很有可能通過這種方式來解決你的問題。你不需要關(guān)心像何時測量堆的大小這樣的事情,就像我們在"如何正確測量GC堆的大小 "部分廣泛談?wù)摰哪菢印?/p>
我們使用的工具以及它是如何完成工作的
運(yùn)行時團(tuán)隊制作的、我經(jīng)常使用的工具是PerfView - 你們中的很多人可能都聽說過它。但我還沒有看到很多人充分使用它。PerfView的核心是使用TraceEvent,這是一個解碼ETW(Event Tracing for Windows)事件的庫,它來自運(yùn)行時提供者、內(nèi)核提供者和其他一些提供者。如果你以前沒有接觸過ETW事件,你可以把它們看作是各種組件隨著時間的推移所發(fā)出的數(shù)據(jù)。它們具有相同的格式,所以來自不同組件的事件可以被那些知道如何解釋ETW事件的工具放在一起看。這對香水調(diào)查來說是一個非常強(qiáng)大的東西。在ETW術(shù)語中,事件按提供者(例如,運(yùn)行時提供者)、關(guān)鍵字(例如,GC)和粗略程度(例如,通常意味著輕量級的Informational和通常更重的Verbose)進(jìn)行分類。使用ETW的成本與你所收集的事件量成正比。在GC信息級別,開銷非常小,如果你需要,你可以一直收集這些事件。
由于.NET Core是跨平臺的,而ETW在Linux上并不存在,我們有其他的事件機(jī)制,旨在使這個過程透明,如LTTng或EventPipe。因此,如果你使用TraceEvent庫,你可以在Linux上獲得這些事件的信息,就像你在Windows上使用ETW事件那樣。然而,有不同的工具可以在Linux上收集這些事件。
PerfView中的另一個功能,我不太經(jīng)常使用,但作為GC的用戶,你可能更經(jīng)常使用,那就是堆快照,即顯示堆上有哪些對象,它們之間是如何連接的。我不經(jīng)常使用它的原因是,GC并不關(guān)心對象的類型。
你可能也用過我們的調(diào)試器擴(kuò)展SoS。我很少用SoS來分析性能,因為它更像是一個調(diào)試工具,而不是剖析工具。它也不怎么看GCs,主要是看堆,即堆統(tǒng)計和轉(zhuǎn)儲單個對象。
在本節(jié)的其余部分,我將向你展示如何用PerfView的正確方式進(jìn)行內(nèi)存分析。我將多次引用內(nèi)存基礎(chǔ)來解釋為什么要用這種方式進(jìn)行分析,這樣做是有意義的,而不是讓你記住我們在這里做什么。
如何開始進(jìn)行內(nèi)存性能分析
當(dāng)你開始進(jìn)行內(nèi)存性能分析時,這些步驟是否聽起來很熟悉?
捕獲一個CPU采樣文件,看看你是否可以減少任何高開銷的方法的CPU 在一個工具中打開一個堆快照,看看你能擺脫什么? 捕獲內(nèi)存分配,看看你能擺脫什么?
根據(jù)你要解決的問題,這些可能是有缺陷的。比方說,你有一個尾部延遲的問題,你正在做1)。你可能正在尋找是否可以減少你的代碼中的CPU使用率,或者是一些庫代碼。但是,如果你的尾部延遲受到長GC的影響,減少這些就不太可能影響你的長GC情況。
處理問題的有效方法是推理出有助于實現(xiàn)性能目標(biāo)的因素,然后從那里開始。我們談到了對不同性能目標(biāo)有貢獻(xiàn)的頂級GC指標(biāo)。我們將討論如何收集它們,并看看我們?nèi)绾畏治雒恳粋€指標(biāo)。
本文檔的大多數(shù)讀者已經(jīng)知道如何收集與內(nèi)存有關(guān)的一般指標(biāo),所以我將簡要介紹一下。由于我們知道GC堆只是進(jìn)程中內(nèi)存使用的一部分,但GC知道物理內(nèi)存負(fù)載,我們想測量進(jìn)程的內(nèi)存使用和機(jī)器的物理內(nèi)存負(fù)載。在Windows上,你可以通過收集以下性能計數(shù)器來實現(xiàn)這一目標(biāo)。
Memory\Available?MBytes(內(nèi)存\可用內(nèi)存?單位MB)`
`Process\Private?Bytes(進(jìn)程\私有內(nèi)存占用?單位MB)
對于一般的CPU使用率,你可以監(jiān)控
Process\%?Processor?time(進(jìn)程\占用處理器時間百分比)
計數(shù)器。調(diào)查CPU時間的一個常見做法是,每隔一段時間就進(jìn)行一次CPU抽樣調(diào)查(例如,有些人可能每小時做一次,每次一分鐘),并查看匯總的CPU堆棧。
如何收集頂層的GC指標(biāo)
GC發(fā)出輕量級的信息級事件,你可以收集(如果你愿意,可以一直開著),涵蓋所有頂級的GC指標(biāo)。使用PerfView的命令行來收集這些事件 -
perfview?/GCCollectOnly?/AcceptEULA?/nogui?collect
完成后,在perfview cmd窗口中按下s來停止它。
這應(yīng)該運(yùn)行足夠長的時間來捕獲足夠多的GC活動,例如,如果你知道問題發(fā)生的時間,這應(yīng)該涵蓋問題發(fā)生前的時間(不僅僅是在問題發(fā)生的時間)。如果你不確定問題何時開始發(fā)生,你可以讓它開很長時間。
如果你知道要運(yùn)行多長時間的集合,可以使用下面的方法(實際上這個方法用得更多)。
perfview?/GCCollectOnly?/AcceptEULA?/nogui?/MaxCollectSec:1800?collect
并將1800(半小時)替換為你需要的任何秒數(shù)。當(dāng)然,你也可以將這個參數(shù)應(yīng)用于其他命令行。這將產(chǎn)生一個名為PerfViewGCCollectOnly.etl.zip的文件。用PerfView的話來說,我們稱之為GCCollectOnly跟蹤。
在Linux上,有一種類似的方法,就是這個dotnet trace命令行:
dotnet?trace?collect?-p??-o??--profile?gc-collect?--duration?<in?hh:mm:ss?format>
這算是一種等價的方法,因為它收集了同樣的GC事件,但只針對已經(jīng)啟動的一個進(jìn)程,而perfview命令行收集的是整個機(jī)器的ETW,即該機(jī)器上每個進(jìn)程的GC事件,在收集開始后啟動的進(jìn)程也會收集到。
還有其他方法來收集頂級的GC指標(biāo),例如,在.NET Framework上,我們有GC perf計數(shù)器;在.NET Core上,也增加了一些GC計數(shù)器。計數(shù)器和事件之間最重要的區(qū)別是,計數(shù)器是抽樣的,而事件則捕獲所有的GC,但抽樣也足夠好。在.NET 5中,我們還添加了一個GC采樣API--
public?static?GCMemoryInfo?GetGCMemoryInfo(GCKind?kind);
它返回的GCMemoryInfo是基于 "GCKind "的,在GCMemoryInfo.cs中做了解釋。
///?
///?
///?GC可以是3種類型中的一種--短暫的、完全阻塞的或后臺的。
///?它們的發(fā)生頻率是非常不同的。短暫的GC比其他兩種GC發(fā)生的頻率高得多。
///?其他兩種類型。后臺GC通常不經(jīng)常發(fā)生,而
///?完全阻塞的GC通常發(fā)生的頻率很低。為了對那些非常
///?不經(jīng)常發(fā)生的GC,集合被分成不同的種類,因此調(diào)用者可以要求所有三種GC?
///?同時保持
///?合理的采樣率,例如,如果你每秒鐘采樣一次,如果沒有這個
///?區(qū)分,你可能永遠(yuǎn)不會觀察到一個后臺GC。有了這個區(qū)別,你可以
///?總是能得到你指定的最后一個GC的信息。
///?
public?enum?GCKind
{
????///?
????Any?=?0,
????///?
????Ephemeral?=?1,
????///?
????FullBlocking?=?2,
????///?
????///?
????Background?=?3
};
GCMemoryInfo提供了與這個GC相關(guān)的各種信息,比如它的暫停時間、提交的字節(jié)數(shù)、提升的字節(jié)數(shù)、它是壓縮的還是并發(fā)的,以及每一代被收集的信息。請參閱GCMemoryInfo.cs了解完整的列表。你可以調(diào)用這個API,在過程中以你希望的頻率對GCs進(jìn)行采樣。
顯示頂級的GC指標(biāo)
在PerfView的 "GCStats "視圖中,這些數(shù)據(jù)與你剛剛收集的軌跡一起被方便地顯示。
在PerfView中打開PerfViewGCCollectOnly.etl.zip文件,即通過運(yùn)行PerfView并瀏覽到該目錄,雙擊該文件;或者運(yùn)行 "PerfView PerfViewGCCollectOnly.etl.zip "命令行。你會看到該文件名下有多個節(jié)點。我們感興趣的是 "Memory Group"節(jié)點下的 "GCStats "視圖。雙擊它來打開它。在頂部,我們有這樣的內(nèi)容
我運(yùn)行了Visual Studio,它是一個托管應(yīng)用程序--這就是頂部的devenv進(jìn)程。
對于每一個進(jìn)程,你都會得到以下細(xì)節(jié)--我對那些命令行的進(jìn)程添加了注釋。
Summary – 這包括像命令行、CLR啟動標(biāo)志、GC的%暫停時間等。
GC stats rollup by generation – 對于gen0/1/2,它有一些東西,如該gen的多少個GCs被完成,它們的平均/平均停頓,等等。
GC stats for GCs whose pause time was > 200ms 暫停時間大于200ms的GC的統(tǒng)計數(shù)字
LOH Allocation Pause (due to background GC) > 200 Msec for this process - Gen2 GC stats該進(jìn)程的LOH分配暫停(由于后臺GC)>200Msec 對于大型對象的分配,有一個注意事項,即在BGC進(jìn)行時,我們不允許過多的LOH分配。如果你在BGC期間分配了太多的對象,你會看到一個表格出現(xiàn)在這里,告訴你哪些線程在BGC期間被阻塞了(以及多久),因為有太多的LOH分配。這通常是一個信號,告訴你減少LOH分配將有助于不使你的線程被阻塞。
All GC stats 所有GC統(tǒng)計資料
Condemned reasons for GCsGC被觸發(fā)的原因
Finalized Object Counts 終結(jié)器對象數(shù)量
Summary explanation "摘要 "解釋
· Commandline self-explanatory. 命令行
· Runtime version運(yùn)行時版本是相當(dāng)無用的,因為我們只是顯示一些通用版本。然而,你可以使用事件視圖中的FileVersion事件來獲得你所使用的運(yùn)行時的確切版本。
· CLR Startup FlagsGC啟動標(biāo)志, 在GC調(diào)查中,主要是尋找CONCURRENT_GC和SERVER_GC。如果你沒有這兩個標(biāo)志,通常意味著你使用的是工作站GC,并且禁用了并發(fā)的GC。不幸的是,這不是絕對的,因為在我們捕獲這個事件之后,它可能會被改變。你可以用其他東西來驗證這一點。注意:請注意,目前.NET Core/.NET 5沒有這些標(biāo)志,所以你在這里不會看到任何東西。
· Total CPU Time and Total GC CPU Time總的CPU時間和總的GC CPU時間這些總是0,除非你真的在收集CPU樣本。
· Total Allocs你在這次追蹤中為這個進(jìn)程所做的總分配。
· MSec/MB Alloc 是0,除非你收集CPU樣本(它將是GC CPU總時間/分配的總字節(jié)數(shù))。
· Total GC pause被GC停頓的總時間。注意,這包括暫停時間,即在GC開始之前暫停被管理的線程所需的時間。
· % Time paused for Garbage Collection 暫停垃圾收集的時間這是 "GC中暫停時間的%"指標(biāo)。
· % CPU Time spent Garbage Collecting 花在垃圾收集上的CPU時間%這是 "GC中的CPU時間%"指標(biāo)。它是NaN%,除非你收集CPU樣本。
· Max GC Heap Size在本次跟蹤過程中,該進(jìn)程的最大托管堆尺寸。
· 其余的都是鏈接,我們將在本文件中介紹其中一些。
所有 All GC stats表 中顯示了在跟蹤收集過程中發(fā)生的每一個GC(如果有太多的話,它會有一個鏈接到?jīng)]有顯示的GC)。在這個表中有很多列。由于這是一個非常廣泛的表格,我將只顯示這個表格中與每個主題有關(guān)的列。
其他頂級的GC指標(biāo),個別暫停和堆大小,作為這個表格的一部分被顯示出來,就像這樣(Peak MB指的是該GC進(jìn)入時的GC堆大小,After是退出時的大小)。
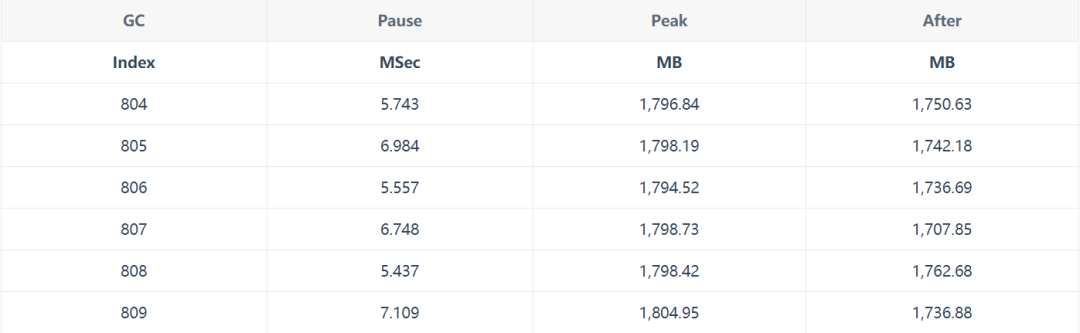
現(xiàn)在,這是一個html表格,你不能進(jìn)行排序,所以如果你確實想進(jìn)行排序(例如,找出最長的單個GC停頓),你可以點擊每個過程開始時的 "在Excel中查看 "鏈接 --
· Individual GC Events
o View in Excel
這將在Excel中打開上面的表格,所以你可以對你喜歡的任何一列進(jìn)行排序。在GC團(tuán)隊中,由于我們需要對數(shù)據(jù)進(jìn)行更多的切分,我們有自己的性能基礎(chǔ)設(shè)施 ,直接使用TraceEvent。
PerfView中的其他相關(guān)視圖
除了GCStats視圖之外,介紹PerfView中的其他幾個視圖也很有用,因為我們會用到它們。
CPU Stacks是你所期望的--如果你在追蹤中收集了CPU的樣本事件,這個視圖就會亮起來。有一點值得一提的是,我總是先清除3個高亮的文本框--在你這樣做之后,你需要點擊更新來刷新。
我很少發(fā)現(xiàn)這3個文本框有用。偶爾我會想按模塊分組,你可以閱讀PerfView的幫助文檔,看看如何做到這一點。
Events就是我們上面提到的 - 原始事件視圖。由于是原始的,它可能聽起來很不友好,但它有一些功能,使它相當(dāng)方便。你可以通過 "過濾器 "文本框過濾事件。如果你需要用多個字符串進(jìn)行過濾,你可以使用"|"。如果我想獲得所有名稱中帶有file的事件和GC/Start事件,我使用file|GC/Start(沒有空格)。
雙擊一個事件的名稱會顯示該事件的所有發(fā)生情況,你可以搜索具體細(xì)節(jié)。例如,如果我想找出coreclr.dll的確切版本,我可以在查找文本框中輸入coreclr。
然后你可以看到你正在使用的coreclr.dll的確切版本信息。
我還經(jīng)常使用 "開始/結(jié)束 "來限制事件的時間范圍,使用 "進(jìn)程過濾器 "將其限制在某個進(jìn)程中,使用 "顯示列 "來限制要顯示的事件字段(這使我能夠?qū)κ录哪硞€字段進(jìn)行排序)。
內(nèi)存組下的GC Heap Alloc Ignore Free是我們要用來查看分配的東西。
Any Stacks顯示所有的事件和它們的堆棧(如果堆棧被收集)。如果我想看一個特定的事件,但還沒有一個既定的視圖,或者既定的視圖沒有提供我所要的東西,我覺得這很方便。
對比堆棧視圖
像CPU堆棧視圖一樣的視圖(即堆快照視圖或GC堆分配視圖)提供了一個Diff-ing功能。如果你在同一個PerfView實例中打開2個跟蹤,當(dāng)你為每個跟蹤打開一個堆棧視圖時,并且Diff菜單提供了一個 "with Baseline "選項(在Help/Users Guide中搜索 "Diffing Two Traces")。
關(guān)于對比2個運(yùn)行的問題--當(dāng)你對比2個運(yùn)行以查看什么是退步時,最好是讓工作負(fù)載盡可能的相似。比方說,你做了一個改變以減少分配,與其在相同的時間內(nèi)運(yùn)行2個運(yùn)行,不如用相同數(shù)量的請求來運(yùn)行它們,因為你知道你的新構(gòu)建正在處理相同數(shù)量的工作。否則,一個運(yùn)行可能運(yùn)行得更快,因此處理更多的請求,這本來就意味著它已經(jīng)需要做不同數(shù)量的分配。這只是意味著它更難做比較。
GC暫停時間百分比高
如果你不知道如何收集GC暫停時間數(shù)據(jù),請按照"如何收集頂級GC指標(biāo)"中的說明進(jìn)行。
如果總的暫停時間很高,可能是由于GC太多(即GC觸發(fā)太頻繁),GC暫停時間太長或兩者都有。
太多的停頓,即太多的GC
根據(jù)我們的一條規(guī)則的一部分,觸發(fā)GC的頻率是由不存活的東西決定的。因此,如果你正在做大量的臨時對象分配(意味著它們不能存活),這意味著你將觸發(fā)大量的GC。在這種情況下,看一下這些分配是有意義的。如果你能消除一些,那就太好了,但有時這并不實際。我們提到了3種方法來剖析分配。讓我們看看如何進(jìn)行每個分析。
測量分配
獲得分配的字節(jié)數(shù)
我們已經(jīng)知道,你可以在摘要中得到分配字節(jié)的總數(shù)。在GCStats視圖中,你還可以得到每個GC的分配字節(jié)數(shù)gen0。
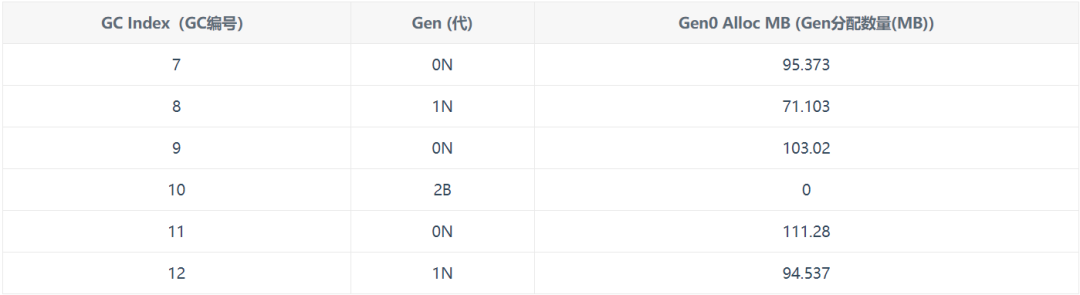
在Gen一欄中,'N'表示Nonconcurrent GC,'B'表示Background。所以完全阻塞的GC顯示為2N。因為只有g(shù)en2的GC可以是后臺,所以你只能看到2B,而不是0B或1B。你也可能看到'F',這意味著前景GC--當(dāng)BGC正在進(jìn)行時發(fā)生的短暫GC。
注意,對于2B來說是0,因為如果gen0或gen1的分配預(yù)算被超過,我們會在BGC的開始做一個gen0或gen1的GC,所以gen0分配的字節(jié)數(shù)會顯示在gen0或gen1的GC上。
我們知道,當(dāng)gen0的分配預(yù)算被超過時,就會觸發(fā)GC。這個數(shù)據(jù)在GCStats中默認(rèn)是不顯示的(只是因為表格中已經(jīng)有很多列了)。但你可以通過點擊GCStats中表格前的**Raw Data XML file(用于調(diào)試)**鏈接來獲得。一個xml文件將被生成并包含更詳細(xì)的數(shù)據(jù)。對于每個GC,你會看到這個(我把它修剪了一下,所以不會太寬)-
FinalYoungestDesired是為這個GC計算的最終gen0預(yù)算。由于我們對所有堆的預(yù)算進(jìn)行了均衡,這意味著每個堆都有這個相同的預(yù)算。由于有12個堆,任何一個堆用完它的gen0預(yù)算都會導(dǎo)致下一次GC被觸發(fā)。所以在這種情況下,這意味著最多只有12*9,830,400=117MB的分配,直到下一次GC被觸發(fā)。我們可以看到下一個GC是一個BGC,它的Gen0 Alloc MB是0,因為我們把這個BGC開始時做的短暫GC歸結(jié)為GC#11,它在GC#9結(jié)束后在Gen0中分配了111.28 MB。
查看帶有堆棧信息的采樣分配
當(dāng)然,你會想知道這些分配的情況。GC提供了一個叫做AllocationTick的事件,大約每100KB的分配就會被觸發(fā)。對于小對象堆來說,100KB意味著很多對象(這意味著對于SOH來說是采樣),但對于LOH來說,這實際上是準(zhǔn)確的,因為每個對象至少有85000字節(jié)大。這個事件有一個叫做AllocationKind的字段--small意味著它是由分配為SOH而觸發(fā)的,而這個分配恰好使該SOH上的累積分配量超過了100KB(那么這個量會被重置)。所以你實際上不知道最后的分配量是多大。但是根據(jù)這個事件的頻率,看看哪些類型被分配的最多,以及分配它們的調(diào)用棧,仍然是一個非常好的近似值。
很明顯,與只收集GCCollectOnly跟蹤相比,收集這個會增加明顯的開銷,但這仍然是可以容忍的。
PerfView.exe?/nogui?/accepteula?/KernelEvents=Process+Thread+ImageLoad?/ClrEvents:GC+Stack?/BufferSize:3000?/CircularMB:3000?collect
這將收集AllocationTick事件及其分配被采樣對象的調(diào)用棧。然后你可以在內(nèi)存組下的 "GC Heap Alloc Ignore Free (Coarse Sampling) "視圖中打開它。
點擊一個類型,你就可以看到分配該類型實例的堆棧。
注意,當(dāng)你在同一個PerfView實例中打開兩個追蹤時,你可以比較兩個GC對的分配視圖
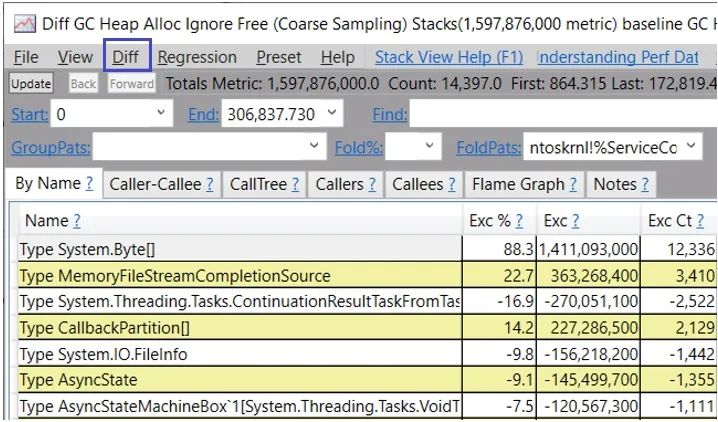
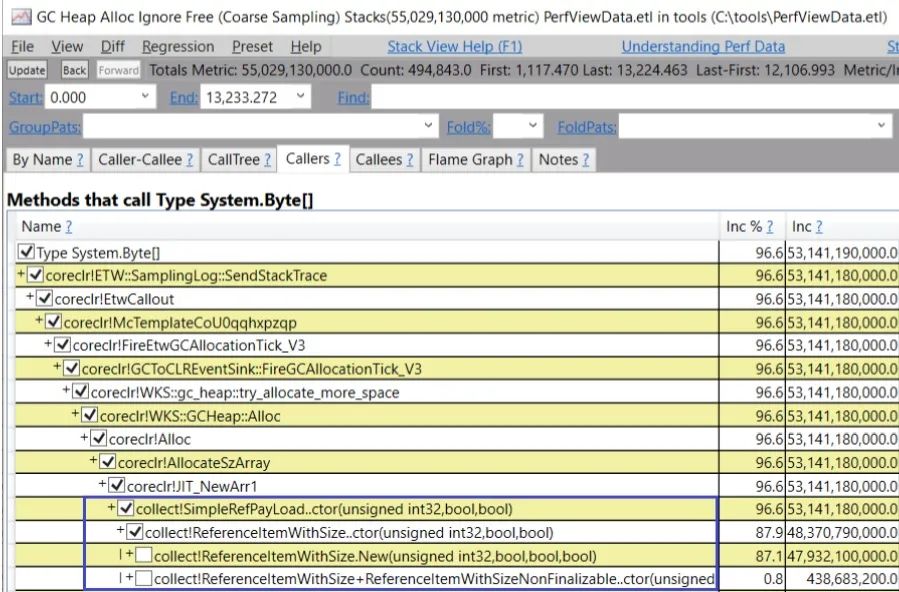
而且你可以雙擊每一種類型來查看分配給它們的調(diào)用棧。
查看AllocationTick事件的另一種方法是使用Any Stacks視圖,因為它按大小分組。例如,這是我從一個客戶的跟蹤中看到的情況(類型名稱已匿名或縮短)。
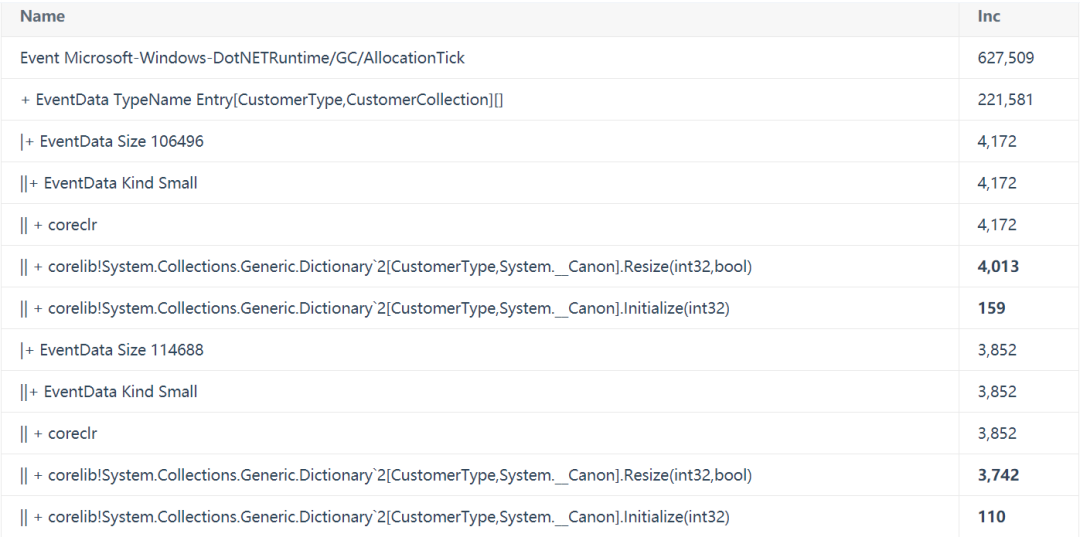
這說明大部分分配來自于字典的重新調(diào)整,你也可以從 GC Heap Alloc 視圖中看到,但樣本計數(shù)信息給了你更多的線索(Resize 有 4013 次,而 Initialize 有 159 次)。所以,如果你能更好地預(yù)測字典會有多大,你可以把初始容量設(shè)置得更大,以大大減少這些分配。
**使用 CPU 樣本查看內(nèi)存清理成本 **
如果你沒有這些AllocationTick事件的跟蹤,但有CPU樣本(這很常見),你也可以看一下內(nèi)存清除的成本-
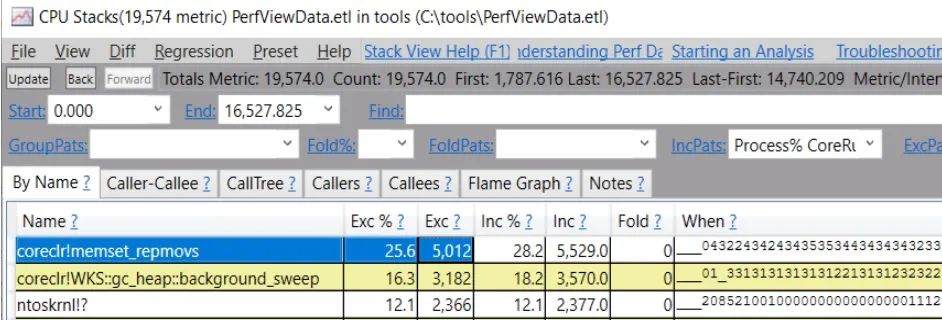
如果你看一下memset_repmovs的調(diào)用者,突出顯示的2個調(diào)用者來自GC在把新對象遞出之前的內(nèi)存清除:
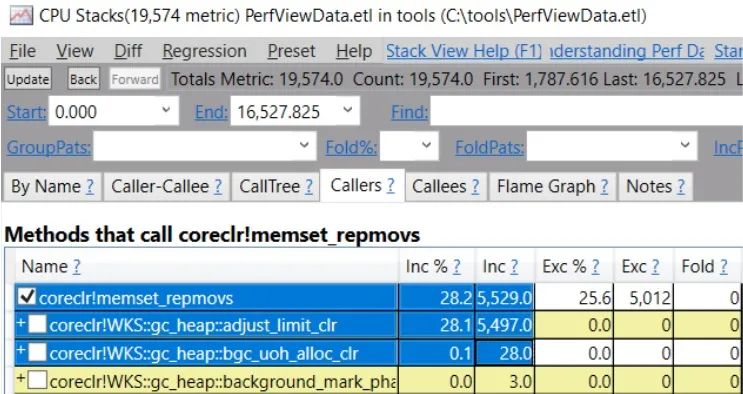
(這是在.NET 5下,如果你有舊版本,你會看到WKS::gc_heap::bgc_loh_alloc_clr而不是WKS::gc_heap::bgc_uoh_alloc_clr)。
在我的例子中,因為分配幾乎是測試的全部內(nèi)容,所以分配成本非常高--占CPU總使用量的25.6%
理解為什么GC決定收集這一代
在GCStats中,每個GC都有一列叫做 "Trigger Reason"。這告訴你這個GC是如何被觸發(fā)的。可能的觸發(fā)原因在PerfView repo的ClrTraceEventParser.cs中定義為GCReason。
public?enum?GCReason
{
??AllocSmall?=?0x0,
??Induced?=?0x1,
??LowMemory?=?0x2,
??Empty?=?0x3,
??AllocLarge?=?0x4,
??OutOfSpaceSOH?=?0x5,
??OutOfSpaceLOH?=?0x6,
??InducedNotForced?=?0x7,
??Internal?=?0x8,
??InducedLowMemory?=?0x9,
??InducedCompacting?=?0xa,
??LowMemoryHost?=?0xb,
??PMFullGC?=?0xc,
??LowMemoryHostBlocking?=?0xd
}
在這些原因中,最常見的是AllocSmall - 這是說gen0的預(yù)算被超過了。如果你看到的最常見的是AllocLarge,那么它很可能表明了一個問題--它是說你的GC被觸發(fā)了,因為你分配了大的對象,超過了LOH預(yù)算。正如我們所知,這意味著它將觸發(fā)gen2 GC
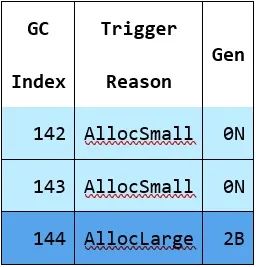
而我們知道,觸發(fā)頻繁的完全GC通常是性能問題的秘訣。其他由于分配引起的觸發(fā)原因是OutOfSpaceSOH和OutOfSpaceLOH - 你看到這些比AllocSmall和AllocLarge要少得多--這些是為你接近物理空間極限時準(zhǔn)備的(例如,如果我們內(nèi)存分配正在接近短暫段的終點)。
那些幾乎總是引起危險信號的事件是 "Induced",因為它們意味著一些代碼實際上是自己觸發(fā)了GC。我們有一個GCTriggered事件,專門用于發(fā)現(xiàn)什么代碼用其調(diào)用棧觸發(fā)了GC。你可以用堆棧和最小的內(nèi)核事件收集一個非常輕量級的GC信息級別的跟蹤:
PerfView.exe?/nogui?/accepteula?/KernelEvents=Process+Thread+ImageLoad?/ClrEvents:GC+Stack?/ClrEventLevel=Informational?/BufferSize:3000?/CircularMB:3000?collect
然后在任意堆棧視圖中查看GCTriggered事件的堆棧:
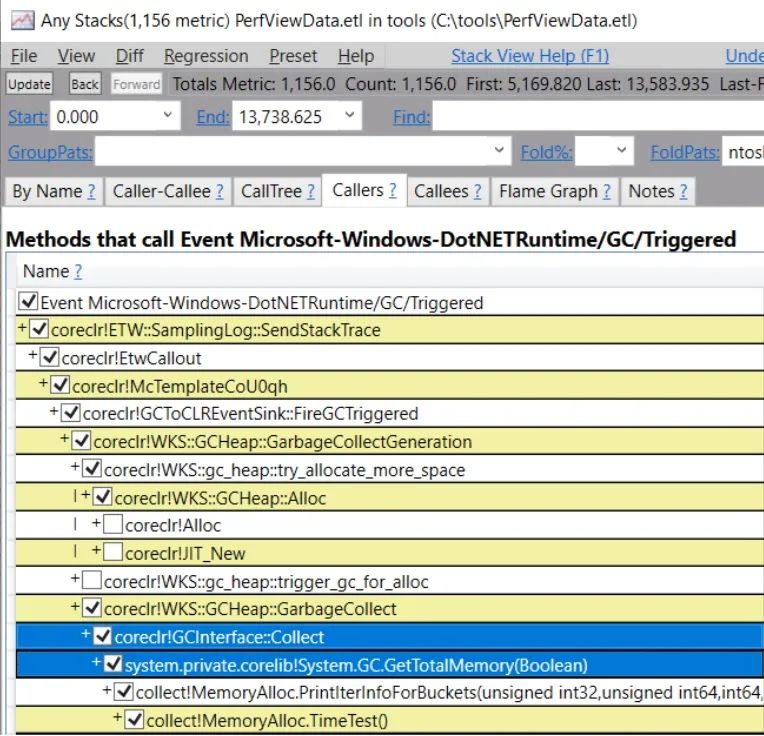
因此,"觸發(fā)原因 "是指GC是如何開始或產(chǎn)生的。如果一個GC開始的最常見原因是由于在SOH上分配,那么這個GC將作為一個gen0的GC開始(因為gen0的預(yù)算被超過了)。現(xiàn)在在GC開始之后,我們再決定我們實際上會收集哪一代。它可能保持為0代GC,或者升級為1代甚至2代GC-這是我們在GC中最先決定的事情之一。導(dǎo)致我們升級到更高世代的GC的因素就是我們所說的 "派遣的原因"(所以對于一個GC來說,只有一個觸發(fā)的原因,但可以有多個派遣的原因)。
以下是出現(xiàn)在表格本身之前的 "GC的派遣理由 "部分的解釋文本
本表更詳細(xì)地說明了GC決定收集那一代的確切原因。將鼠標(biāo)懸停在各列標(biāo)題上,以獲得更多信息。
我不會在這里重復(fù)這些信息。最有趣的是那些升級到gen2的GC - 通常這些是由gen2的高內(nèi)存負(fù)載或高碎片引起的。
個別的長時間停頓
如果你不知道如何收集GC暫停時間數(shù)據(jù),請按照"如何收集頂級GC指標(biāo)"中的說明進(jìn)行。
如果你不熟悉是什么導(dǎo)致了單個GC暫停,請先閱讀GC暫停部分,它解釋了哪些因素導(dǎo)致了GC暫停時間。
我們知道,所有短暫的GCs都是阻塞的,而gen2 GC可以是阻塞的,也可以是背景的(BGC)。短暫的GC和BGC應(yīng)該會產(chǎn)生短暫的停頓。但是事情可能出錯,我們將展示如何分析這些情況。
如果堆的大小很大,我們知道一個阻塞的gen2 GC會產(chǎn)生一個很長的停頓。但是當(dāng)我們需要做gen2 GC的時候,我們一般傾向于BGC。所以長的GC暫停是由于阻塞的gen2 GC造成的,我們會想弄清楚為什么我們要做這些阻塞的gen2 GC。
如此長時間的個別停頓可能是由以下因素或它們的組合造成的—
· 在暫停期間有很多GC工作要做。
· GC正在嘗試執(zhí)行工作,但無法執(zhí)行,因為CPU被占用
讓我們看看如何分析每個場景。
首先,您是否存在托管內(nèi)存泄漏?
如果你不知道什么是管理型內(nèi)存泄露,請先回顧一下那一節(jié)。根據(jù)定義,這不是GC能幫你解決的問題。如果你有一個托管的內(nèi)存泄漏,保證GC會有越來越多的工作要做。
在生產(chǎn)中觸發(fā)完全阻塞的GC可能是非常不可取的,所以在開發(fā)階段做盡職調(diào)查很重要。例如,如果你的產(chǎn)品處理請求,你可以在每個請求或每N個請求結(jié)束時觸發(fā)一個完全阻塞的GC。如果你認(rèn)為內(nèi)存使用量應(yīng)該是相同的,你應(yīng)該能夠用工具來驗證。在這種情況下可以使用很多工具,因為這是一個簡單的場景。所以PerfView當(dāng)然也有這個功能。你可以通過Memory/Take Heap Snapshot來獲取堆快照。它確實有一些不完全直截了當(dāng)?shù)倪x項-
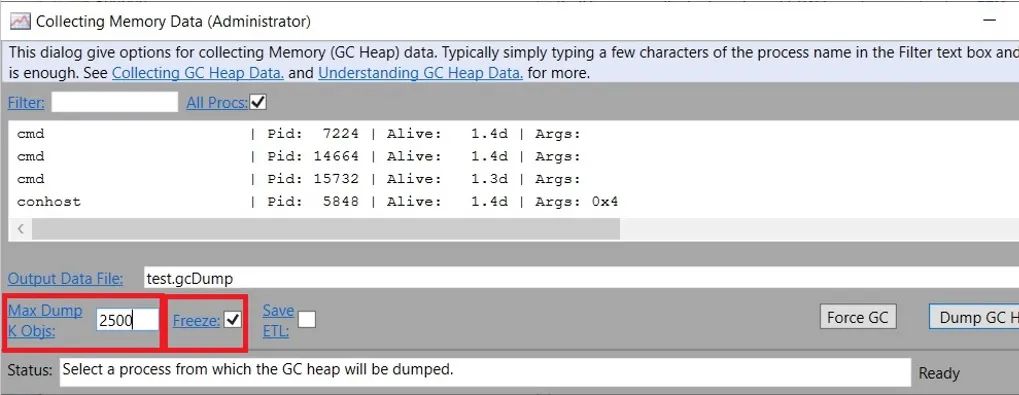
"Max Dump K Objs "是一個 "聰明 "的嘗試,所以它不會轉(zhuǎn)儲每一個對象。我總是把它增加到至少是默認(rèn)值(250)的10倍。凍結(jié)選項是為生產(chǎn)診斷而設(shè)的,當(dāng)你不想招致完全阻塞的GC暫停時。但是,如果你在開發(fā)過程中這樣做,并試圖了解你的應(yīng)用程序的基本行為,你沒有理由不檢查它,這樣你就能得到一個準(zhǔn)確的圖片,而不是用非Freeze選項試圖 "盡最大努力來跟蹤對象圖"。
然后在PerfView中打開生成的.gcDump文件,它有一個類似堆棧的視圖,顯示根信息(例如,GC句柄持有這個對象)和轉(zhuǎn)儲中的類型實例的聚合信息。由于這是一個類似于堆棧的視圖,它提供了差分功能,所以你可以在PerfView中取兩個gcDump文件并進(jìn)行差分。
當(dāng)你在生產(chǎn)中這樣做時,你可以先嘗試不使用凍結(jié)。
長時間的停頓是由于短暫的GCs、完全阻塞的GCs還是BGCs?
GCStats視圖在每個進(jìn)程的頂部都有一個方便的滾動表,顯示了各代的最大/平均/總停頓時間(我確實應(yīng)該把全阻塞的GC和BGC分開,但現(xiàn)在你可以參考Gen2的表格)。一個例子。
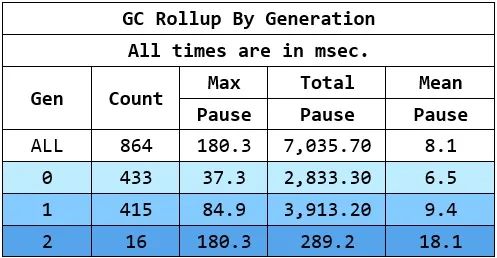
對于gen2 GCs,我們希望看到大部分或所有的GC都以BGC的形式完成。但是如果你看到一個完全阻塞的GC(在GCStats中表示為2N),如果你的堆很大的話,它的暫停時間有可能很長(你會看到gen2 GCs有非常高的升代內(nèi)存數(shù)量 MB,與短暫的GC相比)。通常人們在這個時候要做的是進(jìn)行堆快照,看看堆上有什么東西,并嘗試減少這些東西。然而,首先要弄清楚的是,為什么你首先要做完全阻塞的GCs。你可以查看Condemned Reasons表來了解這個問題。最常見的原因是高內(nèi)存負(fù)載和gen2碎片化。要想知道每個GC觀察到的內(nèi)存負(fù)載,點擊GCStats中 "GC Rollup By Generation "表格上方的 "Raw Data XML file (for debugging) "鏈接,它將生成一個xml文件,其中包括內(nèi)存負(fù)載等額外信息。一個例子是(我剪掉了大部分的信息)-
<GCEvent?GCNumber=??????"45"?GCGeneration="2"?>
??????<GlobalHeapHistory?FinalYoungestDesired="69,835,328"?NumHeaps="32"/>
??????<PerHeapHistories?Count="32"?MemoryLoad="47">
??????PerHeapHistory>
???GCEvent>
這說明當(dāng)GC#45發(fā)生時,它觀察到的內(nèi)存負(fù)載為47%。
由于bug導(dǎo)致的長時間停頓
通常BGC的停頓都很小。唯一的一次是由于運(yùn)行時的一個罕見的bug(例如,我們修復(fù)了一個bug,即模塊迭代器占用了一個鎖,當(dāng)過程中有很多很多模塊時,這種鎖的爭奪意味著每個GC線程需要很長時間來迭代這些模塊),或者你正在做一些只在BGC的STW標(biāo)記部分做的工作。由于這可能是由于非GC工作造成的,我們將在 "弄清長時間的GC是否是由于GC工作 "中討論如何診斷這個問題。
計算出短暫GC的工作量
GC的工作量大致與幸存者成正比,這由 "Promoted Bytes "指標(biāo)表示,該指標(biāo)是GCStats表格中的一列 -
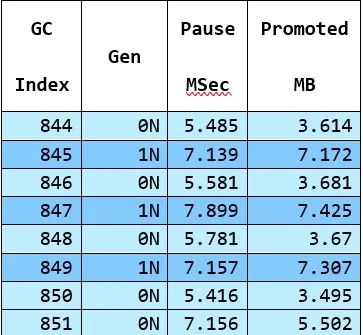
這是有道理的--gen1 GCs比gen0 GCs升代的對象更多,因此它們需要更長的時間。而且它們不會進(jìn)行太多升代,因為它們只收集(通常是一小部分)堆。
如果你看到短暫的GCs突然增加了很多,那么估計暫停時間會長很多。我所看到的一個原因是,它進(jìn)入了一個不經(jīng)常被調(diào)用的代碼路徑,對象存活下來,而這些對象是不應(yīng)該存活的。不幸的是,我們用于找出導(dǎo)致短暫對象存活的原因的工具不是很好--我們已經(jīng)在.NET 5中添加了運(yùn)行時支持,你可以使用PerfView中一個特殊的視圖,稱為 "Generational Aware "視圖,以查看哪些老年代對象導(dǎo)致年輕代對象存活--我將很快寫出更多細(xì)節(jié)。你將看到的是這樣的情況:
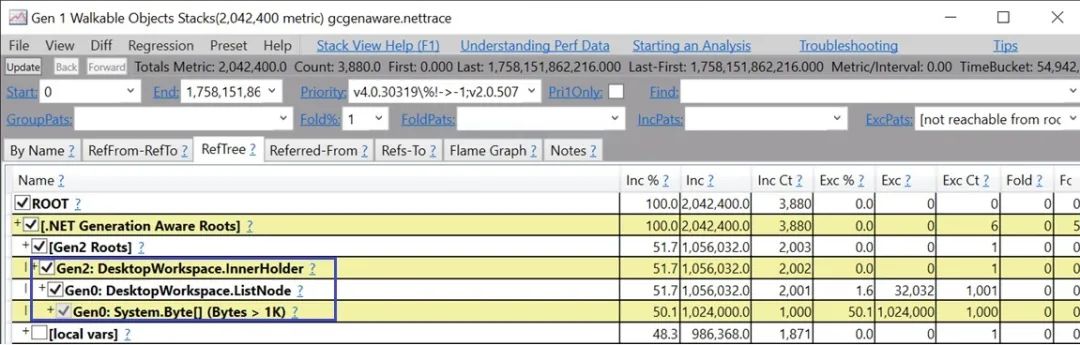
我不知道有什么其他工具可以方便地告訴你這些信息(如果你知道有什么工具可以告訴你老一代的對象在年輕一代的對象上保持著什么,使它們在GC期間存活,請好心地告訴我!)。
請注意,如果你在gen2/LOH中有一個對象持有年輕gen對象的引用,如果你不再需要它們引用那些對象,你需要手動將這些引用字段設(shè)置為null。否則,它們將繼續(xù)持有那些對象的引用,并導(dǎo)致它們被升代。對于C#程序來說,這是導(dǎo)致短暫對象存活的一個主要原因(對于F#程序來說,就不是這樣了)。你可以從GCStats視圖生成的Raw XML中看到這一點(點擊 "Raw Data XML file (for debugging) "鏈接,就在 "GC Rollup By Generation "表的上方),我把大部分屬性從xml中修剪掉了 -
<GCEvent?GCNumber="9"?GCGeneration="0">
??<PerHeapHistories?Count="12"?MemoryLoad="20">
??<PerHeapHistory?MarkStack="0.145(10430)"?MarkFQ="0.001(0)"?
??????????????????MarkHandles="0.005(296)"?MarkOldGen="2.373(755538)">
??<PerHeapHistory?MarkStack="0.175(14492)"?MarkFQ="0.001(0)"?
??????????????????MarkHandles="0.003(72)"?MarkOldGen="2.335(518580)">
每個GC線程由于各種根而升代的字節(jié)數(shù)是PerHeapHistory數(shù)據(jù)的一部分-MarkStack/FQ/Handles分別是標(biāo)記堆棧變量、終結(jié)隊列和GC句柄,MarkOldGen表示由于來自老一代的引用而升代的字節(jié)數(shù)量。因此,舉例來說,如果你正在做一個gen1的GC,這就是gen2對象對gen0/gen1對象的持有數(shù)量,以使其存活。我們在.NET 5中對服務(wù)器GC所做的一個改進(jìn)是,當(dāng)我們標(biāo)記OldGen根時,平衡GC線程的工作,因為這通常會導(dǎo)致最大的升代數(shù)量。因此,如果你在你的應(yīng)用程序中看到這個數(shù)字非常不平衡,升級到.NET 5會有幫助。
弄清楚長的GC是否是由于GC工作造成的
如果一個GC很長,但卻不符合上述任何一種情況,也就是說,沒有很多工作需要GC去做,但還是會造成長時間的停頓,這意味著我們需要弄清楚為什么GC在它想做工作的時候卻沒有做到。而通常當(dāng)這種情況發(fā)生時,它似乎是隨機(jī)發(fā)生的。
偶爾長停的一個例子 -
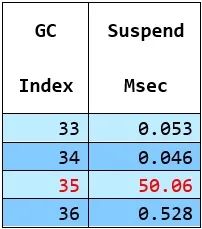
我們在PerfView中做了一個非常方便的功能,叫做停止觸發(fā)器,意思是 "當(dāng)觀察到某些條件滿足時,盡快停止跟蹤,這樣我們就能捕捉到最相關(guān)的最后部分"。它已經(jīng)有一些專門用于GC目的的內(nèi)置停止觸發(fā)器。
GC事件發(fā)生的順序
為了了解它們是如何工作的,我們首先需要簡要地看一下GC的事件序列。這里有6個相關(guān)的事件-
Microsoft-Windows-DotNETRuntime/GC/SuspendEEStart?//開始暫停托管線程運(yùn)行
Microsoft-Windows-DotNETRuntime/GC/SuspendEEStop?//暫停托管線程完成
Microsoft-Windows-DotNETRuntime/GC/Start?//?GC開始回收
Microsoft-Windows-DotNETRuntime/GC/Stop??//?GC回收結(jié)束
Microsoft-Windows-DotNETRuntime/GC/RestartEEStart?//恢復(fù)之前暫停的托管線程
Microsoft-Windows-DotNETRuntime/GC/RestartEEStop?//恢復(fù)托管線程運(yùn)行完成
(你可以在事件視圖中看到這些內(nèi)容)
在一個典型的阻塞式GC中(這意味著所有短暫的GC和完全阻塞的GC),事件發(fā)生順序非常簡單:
GC/SuspendEEStart
GC/SuspendEEEnd?<–?暫停托管線程完成
GC/Start?
GC/End?<–?actual?GC?is?done?
GC/RestartEEStart
GC/RestartEEEnd?<–?恢復(fù)托管線程運(yùn)行完成
GC/SuspendEEStart和GC/SuspendEEEnd是用于暫停;GC/RestartStart和GC/RestartEEEnd是用于恢復(fù)。恢復(fù)只需要很少的時間,所以我們不需要討論它。暫停是可能需要很長時間的。
BGC要復(fù)雜得多,一個完整的BGC事件序列看起來是這樣的
1)?GC/SuspendEEStart
2)?GC/SuspendEEStop
3)?GC/Start?<–?BGC/?starts
<-?there?might?be?an?ephemeral?GC?happen?here,?if?so?you'd?see(這里可能有一個短暫的GC發(fā)生,如果是這樣,你會看到)
GC/Start
GC/Stop
4)?GC/RestartEEStart
5)?GC/RestartEEStop?<–?done?with?the?initial?suspension?(完成了最初的暫停)
<-?there?might?be?0?or?more?foreground?ephemeral?GC/s?here,?an?example?would?be?(這里可能有0個或更多的前臺瞬時的GC/s,一個例子是)
GC/SuspendEEStart
GC/SuspendEEStop
GC/Start
GC/Stop
GC/RestartEEStart
GC/RestartEEStop
6)?GC/SuspendEEStart
7)?GC/SuspendEEStop?
8)?GC/RestartEEStart?
9)?GC/RestartEEStop?<–?done?with?BGC/'s?2nd?suspension?(完成了BGC/的第二次停牌)
<-?there?might?be?0?or?more?foreground?ephemeral?GC/s?here?(這里可能有0個或更多的前臺短暫GC/s)
10)?GC/Stop?<–?BGC/?Stops
所以BGC在它的中間有兩對暫停/重啟。目前在GCStats視圖中,我們實際上是將這兩個暫停合并在一起(我正計劃將它們分開),但如果你確實看到一個長的BGC暫停,你總是可以使用事件視圖來找出哪個暫停是長的。在下面的例子中,我從事件視圖中復(fù)制并粘貼了一個客戶跟蹤的事件序列,它遇到了我提到的bug導(dǎo)致長時間暫停。
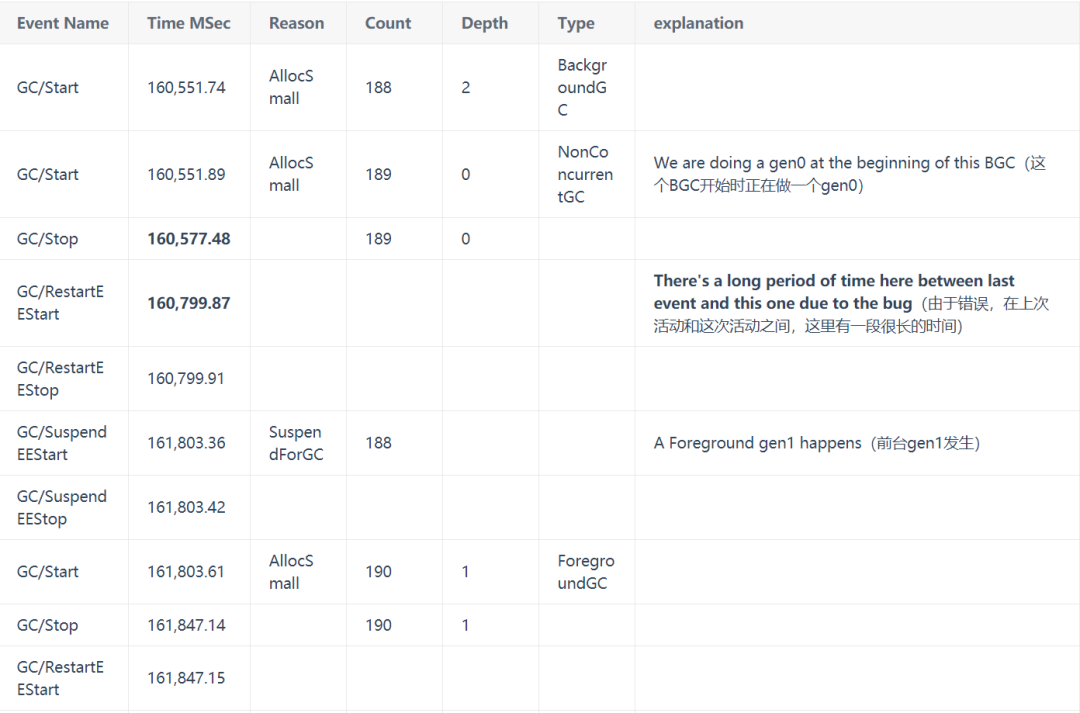

我所做的是在CPU堆棧視圖中查找那些長時間停頓的時間范圍(160,577.482-160,799.868和161,988.57-162,239.94),發(fā)現(xiàn)了這個錯誤。
PerfView GC停止觸發(fā)器
有3個GC特定的停止觸發(fā)器 -
我通常與/StopOnGCOverMSec和/StopOnBGCFinalPauseOverMSec一起使用的命令行是 --
PerfView.exe?/nogui?/accepteula?/StopOnGCOverMSec:15?/Process:A?/DelayAfterTriggerSec:0?/CollectMultiple:3?/KernelEvents=default?/ClrEvents:GC+Stack?/BufferSize:3000?/CircularMB:3000?/Merge:TRUE?/ZIP:True?collect
如果你的進(jìn)程被稱為A.exe,你會想指定/Process:A。我在這篇博客中對每個參數(shù)都有詳細(xì)解釋。
調(diào)試一個隨機(jī)的長GC
這里有一個例子,演示了如何調(diào)試一個突然比其他升代了類似數(shù)量的GC要長很多的GC。我用上面的命令行收集了一個跟蹤,我可以在GCStats中看到有一個GC比15個長 - 它是GC#4022,是20.963ms,而且它沒有比正常情況下更多的升代(你可以看到在它上面的gen0,升代的數(shù)量非常相似,但花的時間卻少很多)。
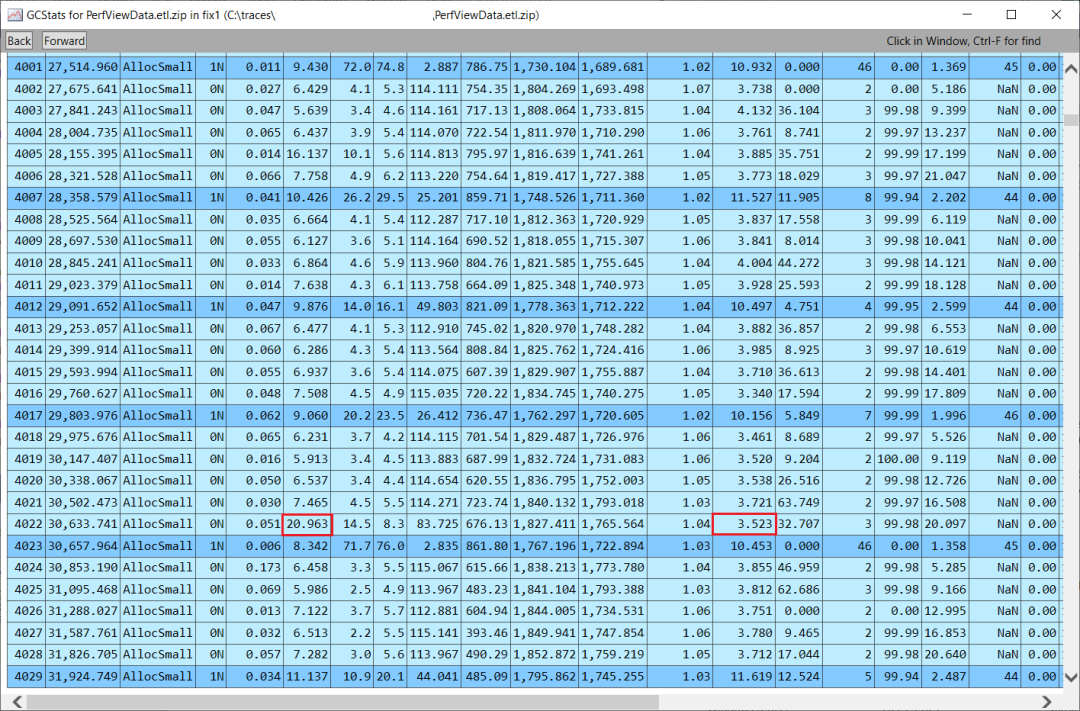
所以我在CPU堆棧視圖中輸入GC#4022的開始和結(jié)束時間戳(30633.741到30654.704),我看到對于執(zhí)行實際GC工作的coreclr!SVR::gc_heap::gc_thread_function,有兩部分沒有CPU占用,而應(yīng)該有很多--____ 部分意味著沒有CPU占用。
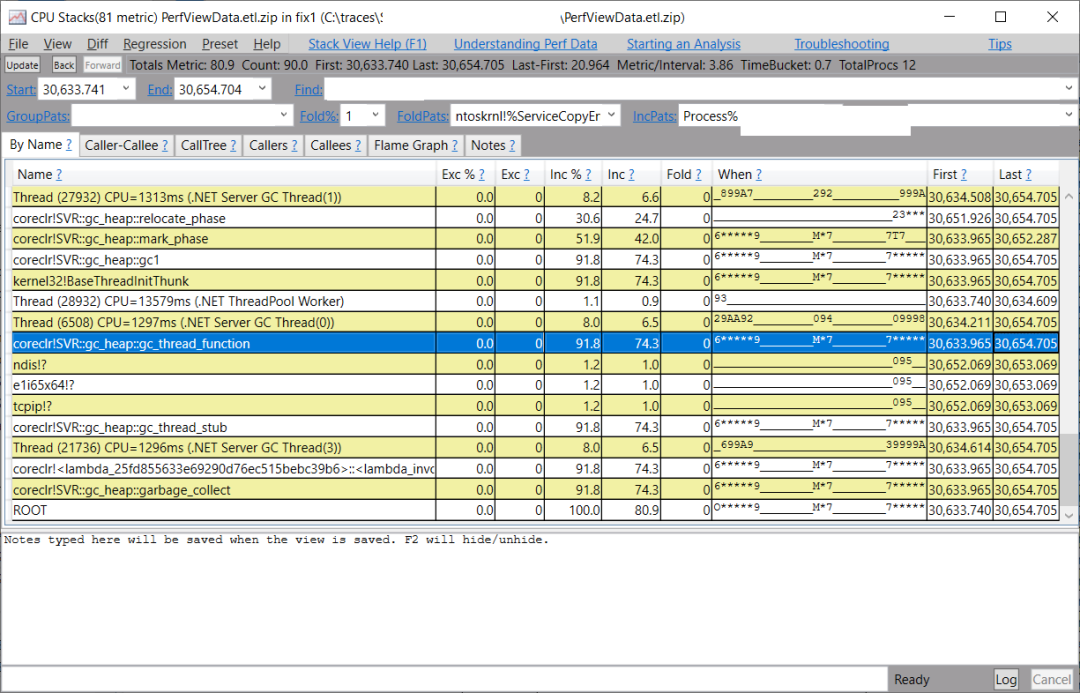
此,我們可以在CPU堆棧視圖中突出顯示第一個平面部分,右擊它并選擇 "設(shè)置時間范圍"。這將向我們顯示這個進(jìn)程在這段時間內(nèi)的CPU樣本,當(dāng)然我們將看到?jīng)]有。
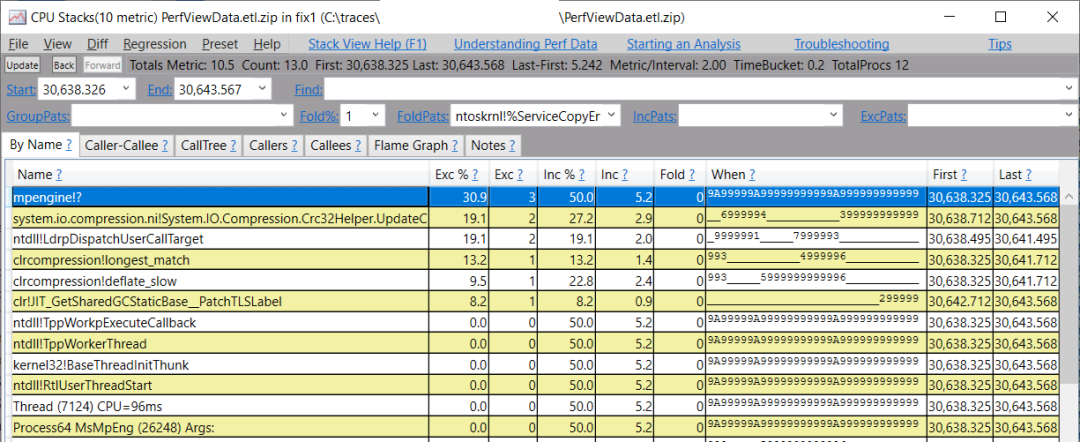
我們看到mpengine模塊,它來自MsMpEng.exe進(jìn)程(雙擊mpengine單元會告訴你它屬于哪個進(jìn)程)。要確認(rèn)這個進(jìn)程干擾了我們的進(jìn)程,就是在Events中輸入開始和結(jié)束的時間戳,然后看一下原始的CPU樣本事件(如果你不知道如何使用這個視圖,請看PerfView中的其他相關(guān)視圖部分) -
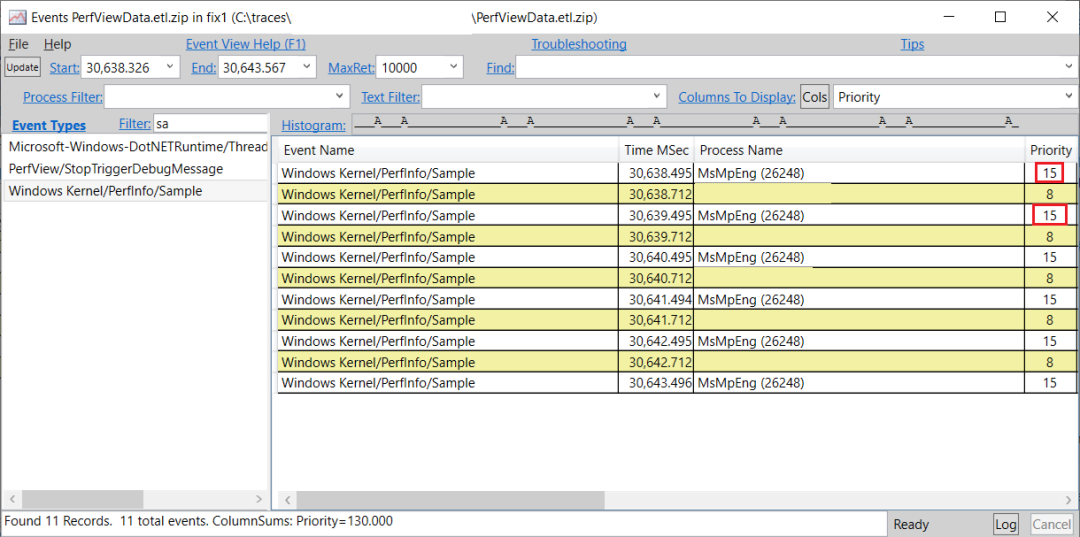
你可以看到MsMpEng.exe進(jìn)程的樣本的優(yōu)先級非常高--15。服務(wù)器GC線程運(yùn)行的優(yōu)先級是11左右。
為了調(diào)試長時間的暫停,我通常采取ThreadTime跟蹤,其中包括ContextSwitch和ReadyThread事件--它們是大量的,但應(yīng)該準(zhǔn)確地告訴我們GC線程在調(diào)用SuspendEE時正在等待什么-
PerfView.exe?/nogui?/accepteula?/StopOnGCSuspendOverMSec:200?/Process:A?/DelayAfterTriggerSec:0?/CollectMultiple:3?/KernelEvents=ThreadTime?/ClrEvents:GC+Stack?/BufferSize:3000?/CircularMB:3000?/Merge:TRUE?/ZIP:True?collect
然而,ThreadTime追蹤可能太多,可能會導(dǎo)致你的應(yīng)用程序運(yùn)行得不夠 "正常",無法表現(xiàn)出你所調(diào)試的行為。在這種情況下,我會從默認(rèn)的內(nèi)核事件開始追蹤,這通常會揭示問題或給你足夠的線索。你可以簡單地把ThreadTime替換成Default -
PerfView.exe?/nogui?/accepteula?/StopOnGCSuspendOverMSec:200?/Process:A?/DelayAfterTriggerSec:0?/CollectMultiple:3?/KernelEvents=Default?/ClrEvents:GC+Stack?/BufferSize:3000?/CircularMB:3000?/Merge:TRUE?/ZIP:True?collect
我在這篇博客中有一個詳細(xì)的調(diào)試長懸掛問題的例子。
大尺寸的GC堆
如果你不知道如何收集GC堆大小數(shù)據(jù),請按照"如何收集頂級GC指標(biāo)"中的說明進(jìn)行操作。
調(diào)試OOM
在我們談?wù)摯蟮腉C堆大小作為一個一般的問題類別之前,我想特別提到調(diào)試OOM,因為這是一個大多數(shù)讀者都熟悉的例外。而且有些人可能已經(jīng)使用了SoS !"AnalyzeOOM "命令,它可以顯示2個方面--1)是否確實存在一個托管堆的OOM。因為GC堆只是你進(jìn)程中的一種內(nèi)存使用,OOM不一定是GC堆造成的;2)如果是托管堆OOM,什么操作造成的,例如,GC試圖保留一個新段,但做不到(你在64位上永遠(yuǎn)不會真正看到這個)或在試圖做分配時無法提交。
在不使用SoS的情況下,你也可以通過簡單地查看GC堆使用多少內(nèi)存與進(jìn)程使用多少內(nèi)存來驗證GC堆是否是OOM的罪魁禍?zhǔn)住N覀儗⒃谙旅嬗懻摱汛笮〉姆治觥H绻愦_認(rèn)GC堆占用了大部分的內(nèi)存,而且我們知道OOM只是在GC非常努力地減少堆的大小,但是不能之后才被拋出,這意味著有大量的內(nèi)存由于用戶根而幸存下來,這意味著GC無法回收它。而你可以按照管理性內(nèi)存泄露調(diào)查來弄清楚哪些內(nèi)存幸存下來。
現(xiàn)在讓我們來談?wù)勥@樣的情況:你沒有得到OOM,但需要看一下堆的大小,看看是否可以或如何優(yōu)化它。在"如何正確看待GC堆的大小 "一節(jié)中,我們談到了堆的大小以及如何廣泛地測量。所以我們知道,堆的大小在很大程度上取決于你在GC發(fā)生時的測量和分配預(yù)算。GCStats視圖顯示了GC進(jìn)入和退出時的大小,即峰值和后值。
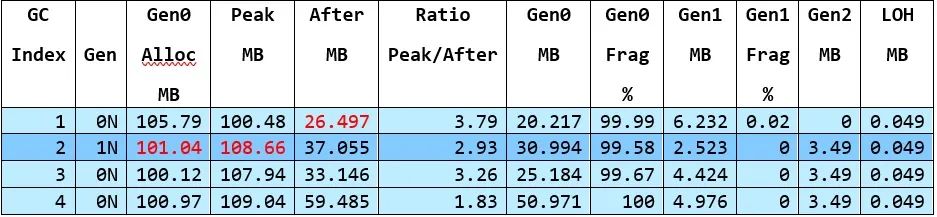
剖析一下這些尺寸是有幫助的。After MB這一欄是以下的總和
Gen0 MB + Gen1 MB + Gen2 MB + LOH MB
還注意到Gen0 Frag %說的是99.99%。我們知道這是由于pinning。因此,部分gen0分配將適合于這種碎片化。所以對于GC #2來說,在GC #1結(jié)束時以26.497 MB開始,然后分配了101.04 MB,在GC #2開始時以108.659 MB的大小結(jié)束。
峰值尺寸太大,但GC后尺寸不大?
如果是這種情況,這通常意味著在觸發(fā)下一次GC之前有太多的gen0分配。在.NET Core 3.0中,我們啟用了一個限制這種情況的配置,叫做GCGen0MaxBudget--我通常不建議人們設(shè)置這個配置,因為你可能會把它設(shè)置得太小,從而導(dǎo)致GC過于頻繁。這是為了限制gen0的最大分配預(yù)算。當(dāng)你使用Server GC時,GC在設(shè)置gen0預(yù)算時相當(dāng)積極,因為它認(rèn)為進(jìn)程使用機(jī)器上的大量資源是可以的。這通常是可以的,因為如果一個進(jìn)程使用了服務(wù)器GC,往往意味著它可以負(fù)擔(dān)得起使用大量的資源。但是,如果你確實有這樣的情況,你對更頻繁地觸發(fā)GC以交換到更小的堆大小沒有意見,你可以用這種配置來做。我的希望是,在未來,我們將使這成為一些高級配置的一部分,允許你向我們傳達(dá)你想做這種交換,這樣GC就可以為你自動調(diào)整,而不是你自己使用一個非常低級的配置。
在過去使用GC性能計數(shù)器的人認(rèn)識到 "#Total Committed Bytes "計數(shù)器,他們問如何在.NET Core中獲得這個計數(shù)器。首先,如果你用這種方式測量已提交的字節(jié),你可能會看到它更接近峰值大小,而不是之后的大小,這是因為在短暫段上對已提交的特殊處理。因為 "After size "沒有報告我們將要使用但還沒有使用的gen0預(yù)算部分。所以你可以直接使用GCStats中報告的峰值大小作為你的近似的總投入。但如果你使用的是.NET 5,你可以通過調(diào)用我們前面提到的GetGCMemoryInfoAPI得到這個數(shù)字--它是GCMemoryInfo結(jié)構(gòu)上返回的屬性之一。
有一個不太方便的方法,就是每堆歷史事件中的ExtraGen0Commit字段。你可以在你已經(jīng)得到的堆大小信息(即在GCHeapStats事件中)的基礎(chǔ)上添加這個字段(如果你使用的是服務(wù)器GC,它將是所有堆的ExtraGen0Commit之和)。但是我們沒有在PerfView的用戶界面中公開這一點,所以你需要自己去使用TraceEvent庫來獲得這些信息。
GC后尺寸很大?
如果是這樣,大部分的尺寸是在gen2/LOH中嗎?你是否主要在做后臺GC(不壓縮)?如果你已經(jīng)在做完全阻塞的GC,而After的大小還是太大,這僅僅意味著你有太多的數(shù)據(jù)存活下來。你可以按照管理性內(nèi)存泄露調(diào)查來弄清楚存活的數(shù)據(jù)。
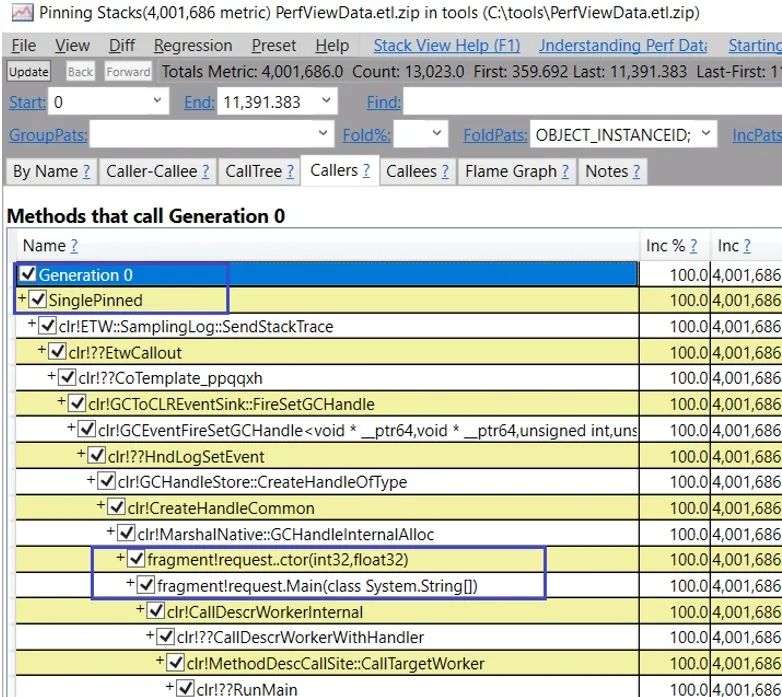
另一種可能的情況是有很大比例的堆在gen0中,但大部分是碎片。這種情況會發(fā)生,特別是當(dāng)你把一些對象釘住了很久,而且它們在堆上足夠分散時。所以即使GC已經(jīng)降代它們到了gen0,只要這些引腳沒有消失,堆的那一部分仍然不能被回收。你可以收集GCHandle事件來計算它們何時被釘住。PerfView的命令行是
perfview?/nogui?/KernelEvents=Process+Thread+ImageLoad?/ClrEvents:GC+Stack+GCHandle?/clrEventLevel=Informational?collect
 ](
](
gen2 GC是否主要為后臺GC?
如果GC主要是后臺GC,那么需要看看碎片的使用是否高效,也就是說,當(dāng)后臺GC開始時,gen2 Frag %是否非常大?如果不是非常大,這意味著它的工作是最優(yōu)化的。否則這表明后臺GC的調(diào)度問題--請讓我知道。要看后臺GC開始時的碎片情況,你可以使用GCStats視圖中的Raw XML鏈接來查看它。我已經(jīng)把數(shù)據(jù)修剪成只有相關(guān)的部分-
<GCEvent?GCNumber=??"1174"?GCGeneration="2"?Type=?"BackgroundGC"?Reason=?"AllocSmall">
??<PerHeapHistory>
????<GenData?Name="Gen2"?SizeBefore="187,338,680"?SizeAfter="187,338,680"?ObjSpaceBefore="177,064,416"?FreeListSpaceBefore="10,200,120"?FreeObjSpaceBefore="74,144"/>
????<GenData?Name="GenLargeObj"?SizeBefore="134,424,656"?SizeAfter="131,069,928"?ObjSpaceBefore="132,977,592"?FreeListSpaceBefore="1,435,640"?FreeObjSpaceBefore="11,424"/>
SizeBefore = ObjSpaceBefore + FreeListSpaceBefore + FreeObjSpaceBefore
SizeBefore` 這一代的總規(guī)模
ObjSpaceBefore 這一代的有效對象所占的大小
FreeListSpaceBefore 這一代的自由列表所占的大小
FreeObjSpaceBefore 在這一代中,太小的自由對象所占用的大小,不能進(jìn)入自由列表。
(FreeListSpaceBefore + FreeObjSpaceBefore) 就是我們所說的碎片化
在這種情況下,我們看到((FreeListSpaceBefore + FreeObjSpaceBefore)/ SizeBefore)是5%,這是相當(dāng)小的,這意味著我們已經(jīng)用掉了大部分BGC建立好的自由空間。當(dāng)然,我們希望看到這個比例越小越好,但如果自由空間太小,就意味著GC可能無法使用它們。一般來說,如果這個比例是15%或更小,我不會擔(dān)心,除非我們看到自由空間足夠大但沒有被使用。
你也可以從我們前面提到的GetGCMemoryInfoAPI中獲得這些數(shù)據(jù)。
你看到的堆的大小從GC的角度來看是合理的,但仍然希望有一個更小的堆?
在你經(jīng)歷了上述情況后,你可能會發(fā)現(xiàn),從GC的角度來看,這一切都可以解釋。但如果你仍然希望堆的大小更小呢?
你可以把你的進(jìn)程放在一個內(nèi)存受限的環(huán)境中,也就是說,一個有內(nèi)存限制的容器,這意味著GC會自動識別為它可以使用的內(nèi)存。然而,如果你使用的是Server GC,你至少要升級到.NET Core 3.0,它對容器的支持更加強(qiáng)大。在該版本中,我們還添加了2個新的配置,允許你指定GC堆的內(nèi)存限制 - GCHeapHardLimit和GCHeapHardLimitPercent。它們在本博客文章中得到了解釋。
當(dāng)你的進(jìn)程運(yùn)行在有其他進(jìn)程的機(jī)器上時,GC開始反應(yīng)的默認(rèn)內(nèi)存負(fù)載可能不是每個進(jìn)程都想要的。你可以考慮使用GCHighMemPercent配置,并將該閾值設(shè)置得更低--這將使GC更積極地進(jìn)行完全阻塞的GC,所以即使有內(nèi)存可用,它也不會使你的堆增長得那么多。
GC是否為自己的記賬工作使用了太多的內(nèi)存?
偶爾我也收到一些人的報告,他們確實觀察到有一大塊內(nèi)存被用于GC記賬。你可以通過GC的gc_heap::grow_brick_card_tables的VirtualAlloc調(diào)用看到。這是因為,由于在地址空間中保留了一些意想不到的區(qū)域,堆的范圍被拉得太長了。如果你確實遇到了這個問題,并且無法防止意外的保留,你可以考慮用GCHeapHardLimit/GCHeapHardLimitPercent指定一個內(nèi)存限制,那么整個限制將被提前保留,這樣你就不會遇到這個問題了。
性能問題的明確跡象
如果你看到以下任何情況,毫無疑問你有性能問題。與任何性能問題一樣,正確確定優(yōu)先次序總是很重要的。例如,你可能有很長的GC暫停,但如果它們不影響你所關(guān)心的性能指標(biāo),你把時間花在其他地方會更有成效。
我使用PerfView中的GCStats視圖來顯示這些癥狀。如果你不熟悉這個視圖,請看本節(jié)。你不一定要使用PerfView,只要能夠顯示下面的數(shù)據(jù),使用任何工具都可以。
暫停時間太長
暫停通常在每次發(fā)生時都會少于1ms。如果你看到的是10秒或100秒的東西,你不需要懷疑你是否有寧問題--這是一個明確的信號,說明你有。
如果你看到你的大部分GC暫停都被暫停占用了,尤其是持續(xù)的暫停,而且你的總GC暫停太多,你肯定應(yīng)該調(diào)試它。我在這篇博客中有一個詳細(xì)的調(diào)試長暫停問題的例子。
這可以通過GCStats視圖中的 "Suspend Msec "和 "Pause Msec "列來表示。我模擬了一個例子 --

兩個GCs的大部分停頓時間都是在暫停中度過的。
隨機(jī)的長時間GC停頓
"隨機(jī)長的GC停頓 "意味著你突然看到一個GC并沒有比平時升代更多,但卻需要更長的時間。下面是一個模擬的例子

所有的GCs都升代了~2MB,但是GC#10和#12花了幾毫秒,而GC#11花了200。這就說明在GC#11期間出了問題。有時你可能會看到突然花了很長時間的GC也招致了很長時間的暫停,因為導(dǎo)致長時間暫停的原因也影響了GC的工作。
我已經(jīng)給出了一個例子上面如何調(diào)試這個問題。
大多數(shù)GC是完全阻塞的GC
如果你看到大多數(shù)GC是完全阻塞的,如果你有一個大的堆,這通常需要相當(dāng)長的時間,這就是一個性能問題。我們不應(yīng)該一直做完全阻塞的GCs,就是這樣。即使你處于高內(nèi)存負(fù)載的情況下,做完全阻塞GC的目的是為了減少堆的大小,這樣內(nèi)存負(fù)載就不再高了。而GC有辦法在有挑戰(zhàn)的情況下進(jìn)行對抗,比如針對高內(nèi)存負(fù)載的臨時模式+沉重的固定,以避免做更多的完全阻塞GC,而不是必要。我見過的最常見的原因?qū)嶋H上是誘導(dǎo)的完全阻塞的GCs,這對調(diào)試來說是很容易的,因為GCStats會告訴你觸發(fā)原因是誘導(dǎo)的。下面是一個模擬的例子

本節(jié)講述了如何找出誘發(fā)GC的原因。
有助于我們幫助你調(diào)試性能問題的信息
在某些時候,在你遵循本文件中的建議并做了詳盡的調(diào)查后,你仍然發(fā)現(xiàn)你的性能問題沒有得到解決。我們很愿意幫助你! 為了節(jié)省你和我們的時間,我們建議你準(zhǔn)備以下信息 -
運(yùn)行時的文件版本
每個版本都會有新的GC變化,所以我們很自然地想知道你使用的是哪個版本的運(yùn)行時,以便我們知道該版本的運(yùn)行時有哪些GC變化。所以提供這些信息是非常必要的。版本如何映射到 "公共名稱",如.NET 4.7,是不容易追蹤的,所以提供dll的 "FileVersion "屬性會對我們有很大幫助,它可以告訴我們版本號與分支名稱(對于.NET Framework)或?qū)嶋H提交(對于.NET Core)。你可以通過像這樣的powerhell命令來獲得這些信息:
PS C:\Windows\Microsoft.NET\Framework64\v4.0.30319> (Get-Item C:\Windows\Microsoft.NET\Framework64\v4.0.30319\clr.dll).VersionInfo.FileVersion
4.8.4250.0 built by: NET48REL1LAST_C
PS C:\> (Get-Item C:\temp\coreclr.dll).VersionInfo.FileVersion
42,42,42,42424 @Commit: a545d13cef55534995115eb5f761fd0cecf66fc1
獲得這些信息的另一個方法是通過調(diào)試器通過lmvm命令(部分省略)-
0:000>?lmvm?coreclr
Browse?full?module?list
start?????????????end?????????????????module?name
00007ff8`f1ec0000?00007ff8`f4397000???CoreCLR????(deferred)?????????????
????Image?path:?C:\runtime-reg\artifacts\tests\coreclr\windows.x64.Debug\Tests\Core_Root\CoreCLR.dll
????Image?name:?CoreCLR.dll
????Information?from?resource?tables:
????????FileVersion:??????42,42,42,42424?@Commit:?a545d13cef55534995115eb5f761fd0cecf66fc1
如果你捕捉到ETW跟蹤,你也可以找到KernelTraceControl/ImageID/FileVersion事件。它看起來像這樣(部分省略)。
ThreadID="-1"?ProcessorNumber="2"?ImageSize="10,412,032"?TimeDateStamp="1,565,068,727"?BuildTime="8/5/2019?10:18:47?PM"?OrigFileName="clr.dll"?FileVersion="4.7.3468.0?built?by:?NET472REL1LAST_C"
你已經(jīng)進(jìn)行了哪些診斷
如果你已經(jīng)按照本文件中的技術(shù),自己做了一些診斷,這是強(qiáng)烈建議的,請與我們分享你做了什么,得出了什么結(jié)論。這不僅可以節(jié)省我們的工作,還可以告訴我們我們提供的信息對你的診斷有什么幫助或沒有幫助,這樣我們就可以對我們提供給客戶的信息進(jìn)行調(diào)整,使他們的生活更輕松。
性能數(shù)據(jù)
就像任何性能問題一樣,在沒有任何性能跟蹤數(shù)據(jù)的情況下,我們真的只能給出一些一般性的指導(dǎo)和建議。要真正找出問題所在,我們需要性能跟蹤數(shù)據(jù)。
正如本文檔中多次提到的,性能跟蹤是我們調(diào)試性能問題的主要方法,除非你已經(jīng)進(jìn)行了診斷,表明不需要頂級GC跟蹤,否則我們總是要求你收集這樣的跟蹤來開始。我通常也會要求你提供帶有CPU樣本的追蹤,特別是當(dāng)我們要診斷長時間的GC暫停時。我們可能會要求你根據(jù)我們從最初的追蹤中得到的線索,收集更多的追蹤信息。
一般來說,轉(zhuǎn)儲不太適合調(diào)查性能問題。但是,我們了解有時可能無法獲得跟蹤,而您所擁有的只是轉(zhuǎn)儲(dump)。如果情況確實如此,請盡可能與我們分享(即,在沒有隱私問題的情況下,因為dump可能會泄漏源碼和內(nèi)存數(shù)據(jù))。
轉(zhuǎn)自:InCerry
鏈接:cnblogs.com/InCerry/p/maoni-mem-doc.html