
帶你看看從輸入U(xiǎn)RL到頁面顯示背后的故事
說一說從在瀏覽器輸入U(xiǎn)RL到整個(gè)頁面顯示這個(gè)過程經(jīng)歷了什么?這個(gè)問題應(yīng)該是目前大廠必問的一個(gè)面試題,是一個(gè)非常綜合性的問題,可以考查我們對如HTTP協(xié)議的了解,瀏覽器相關(guān)知識的基礎(chǔ)如,對html,css文件解析,瀏覽器如何渲染等,所以如果我們可以把這一題回答的非常清楚一定是非常加分的,并且作為一個(gè)前端,如果可以很深入的了解這些知識對自己的專業(yè)能力提升也時(shí)常非常大的,我們可以直接應(yīng)用到自己的工作中,如之前文章中說的性能優(yōu)化等,這是邁向高級前端非常重要的一步。
本文會介紹瀏覽器從發(fā)送請求開始,到接受到服務(wù)器響應(yīng),到解析文件,之后調(diào)用GPU來渲染到界面上的整個(gè)過程。過程中如遇到像HTTP協(xié)議需要掌握的知識,TCP協(xié)議等我都會提出,可能有些不會講的那么深,但作為一個(gè)前端我認(rèn)為都需要了解的知識我都會提出來,如果你有興趣還是希望你可以查查其他的文章,盡力把他們學(xué)懂。本文我會盡可能的查找多的文章,來讓確保每一個(gè)知識點(diǎn)的正確度。
本文的特點(diǎn)有兩點(diǎn):一定要好懂,一定要深入。好懂我希望這個(gè)不是在我的角度來說一個(gè)知識是怎么樣的,我希望的是站在一個(gè)讀者的角度,可以用更多常見的例子來說明,但又不喪失深度,深入是我之前聽winter老師說的一句話,如果我們想再前端,其實(shí)其他工作也是一樣的,如果我們想走的更遠(yuǎn),我們一定要更深入的學(xué)習(xí),必挖原理,必學(xué)底層,所以這篇文章也是這樣,有些部分我直接會涉及到chrome的源碼,來看其解析過程是怎么樣的,我將我知道的盡可能深的知識說出來,還是看讀者能理解到什么程度,取法乎上,僅得其中。
最后說一點(diǎn)學(xué)習(xí)的建議,希望大家在看文章的時(shí)候可以認(rèn)真去理解,怎么樣判斷自己是否理解了呢?可以自己在心里對自己說出來,如果很熟的話可以寫一篇文章來總結(jié),然后遇到自己不熟的名詞一定要查資料,一定要查,一定要查,不要覺得自己可能知道這個(gè)東西,其實(shí)其背后代表的知識也許是很深的。現(xiàn)在開始正題。這篇文章主要會按照順序分為三大部分:網(wǎng)絡(luò)部分,瀏覽器解析部分,瀏覽器渲染部分。
網(wǎng)絡(luò)部分:
我們想要訪問騰訊的官網(wǎng),我們需要知道這個(gè)網(wǎng)頁的URL地址,首先我們會在chrome瀏覽器的地址輸入www.tencent.com這個(gè)域名。

之后瀏覽器會幫我們自動(dòng)補(bǔ)全一些內(nèi)容,如http協(xié)議還是https協(xié)議。這里有兩個(gè)地方需要注意:一個(gè)是這里的想訪問的默認(rèn)是80端口,訪問的是這個(gè)域名下的根路徑“/”。所以首先瀏覽器會根據(jù)我們請求的URL地址生成請求行。有興趣的同學(xué)還可以看一下到底什么是URL,URL與URI是什么關(guān)系等。
1.生成請求行:
請求行由三部分組成分別是:請求方式,請求路徑,協(xié)議版本號。這里如果要再細(xì)一點(diǎn)的話,我們可以深入的去看看還有哪些HTTP請求方式,如我們常用的GET,POST,還有沒用過的HEAD,PUT,OPTIONS,CONNECT,DELETE,TRACE等他們的作用。請求路徑默認(rèn)是根路徑"/",協(xié)議版本號有HTTP/1.0,HTTP/1.1,還有最新的HTTP/2.0。
GET / HTTP/1.12.查找強(qiáng)緩存:
查找強(qiáng)緩存是非常重要的知識點(diǎn),引申出來的問題如請你說說你對瀏覽器緩存的認(rèn)識。
這里就會涉及到強(qiáng)緩存與協(xié)商緩存,強(qiáng)緩存就是瀏覽器保存之前服務(wù)器發(fā)送過來的數(shù)據(jù),保存我們訪問的歷史記錄下次再想訪問這個(gè)網(wǎng)頁直接使用緩存就好了,但這個(gè)數(shù)據(jù)會有過期時(shí)間,如果過期了瀏覽器還是要再向服務(wù)器發(fā)送請求來獲取新的數(shù)據(jù)。
所以當(dāng)緩存的數(shù)據(jù)過期了我們就需要協(xié)商緩存了,我們需要問一下服務(wù)器看看服務(wù)器的數(shù)據(jù)更新了沒,如果服務(wù)器的數(shù)據(jù)也沒有更新那么就會給我們返回一個(gè)304代表,我們我們可以繼續(xù)使用之前的緩存。如果想更細(xì)節(jié)的了解強(qiáng)緩存與協(xié)商緩存的知識,可以去我的語雀中看,我在文章的后面會寫地址。
好我們接著說,如果發(fā)現(xiàn)強(qiáng)緩存過期了我們就需要進(jìn)入下一步了。
3.DNS域名解析:
當(dāng)發(fā)現(xiàn)我們的強(qiáng)緩存過期,或者瀏覽器里還沒有緩存的時(shí)候,我們首先就需要將我們輸入的域名轉(zhuǎn)換為對應(yīng)的IP地址了,因?yàn)榉?wù)器要和客戶端是通過IP地址來確認(rèn)彼此的身份的。那為什么不能通過域名來確認(rèn)彼此的身份呢?因?yàn)閷τ谖覀冇脩魜碚f我們更容易記住一段域名,而對于計(jì)算機(jī)來說他們更適合識別IP地址。
根據(jù)域名來查找IP地址的過程就是域名解析,DNS系統(tǒng)就可以理解為存儲許多IP地址與域名的哈希表,里面存儲的便是域名與IP地址的映射,具體解析過程大概是這樣:
首先會去我們的系統(tǒng)中一個(gè)叫hosts的文件中去查看有沒有對應(yīng)的IP地址,這hosts文件是在我們的系統(tǒng)中可以找到的,我們可以自己添加和修改的,自己寫一些域名和IP地址進(jìn)去。一般里面默認(rèn)會寫localhosts對應(yīng)127.0.0.1等們,一般情況下我們不會去添加。如果文件中沒有找到我們就需要去本地DNS域名服務(wù)器發(fā)送請求(本地DNS域名服務(wù)器一般是由電信公司等保管),來獲取相應(yīng)的IP地址,如果本地沒有找到而且本地服務(wù)器也沒有之前的緩存,那么就要向更下層的服務(wù)器去查找了,后面還要根服務(wù)器,域服務(wù)器,這些不是我們的重點(diǎn),有興趣的同學(xué)可以看一下。
在這里我們只需要知道我們輸入的URL地址會通過DNS域名系統(tǒng)將域名轉(zhuǎn)化為對應(yīng)的IP地址便好,還需要知道的是瀏覽器會對我們之前解析過的域名進(jìn)行緩存,下次使用時(shí)如果這個(gè)域名之前解析過就可以直接使用了就不需要再進(jìn)行解析了。
4.建立TCP連接
這里會涉及到TCP三次握手以及四次揮手由于時(shí)間原因,這一部分我就先不細(xì)講了大家如果想深入了解可以看看TCP協(xié)議靈魂之問,鞏固你的網(wǎng)路底層基礎(chǔ)。
5.發(fā)送HTTP請求
等建立好TCP連接后我們便需要發(fā)送HTTP請求了,我們知道對GET請求我們會發(fā)送一個(gè)數(shù)據(jù)包,也就是請求報(bào)文頭部(包含請求行與請求頭),而對于POST請求會發(fā)送兩個(gè)數(shù)據(jù)包,先發(fā)送請求首部,等待服務(wù)器返回100狀態(tài)碼再發(fā)送請求實(shí)體body。
請求行之前已經(jīng)建立好了,接下來我們來看一個(gè)請求請求頭:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3Accept-Encoding: gzip, deflate, brAccept-Language: zh-CN,zh;q=0.9Cache-Control: no-cacheConnection: keep-aliveCookie: /* 省略cookie信息 */Host: www.baidu.comPragma: no-cacheUpgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
Accept首部字段:
大致可分為四個(gè)大類,數(shù)據(jù)類型、壓縮方式、語言類型、字符集,客戶端請求報(bào)文對應(yīng)的首部字段為:Accept,Accept-Encoding、Accept-Language,Accept,服務(wù)器響應(yīng)對應(yīng)的首部字段為:Content-Type、Content-Encoding、Content-Language、Content-Charset。
Cache-Control:
這個(gè)首部字段主要用于強(qiáng)緩存,屬于通用首部字段,其值主要用來告訴通信雙方,什么數(shù)據(jù)可以緩存,緩存完多久過期,緩存服務(wù)器可以緩存嗎?等等
Cookie:
這個(gè)大家應(yīng)該都很熟悉了,就不多做介紹了
User-Agent:
這個(gè)做過移動(dòng)端適配的同學(xué)應(yīng)該清楚,值是客戶端的一些信息,如操作系統(tǒng)等
請求與響應(yīng)報(bào)文的首部字段有很多很多,可能會涉及強(qiáng)緩存,協(xié)商緩存,Cookie,HTTP如何處理定長不定長數(shù)據(jù)等,大家有時(shí)間還是要好好了解了解。
5.接收HTTP響應(yīng):
服務(wù)器在接收到客戶端的請求之后便會向客戶端發(fā)送響應(yīng)啦,響應(yīng)報(bào)文與請求報(bào)文一樣都是由頭部與實(shí)體組成,關(guān)于HTTP更多的知識這里就不介紹了,這篇文章主要將重點(diǎn)放在瀏覽器接收到服務(wù)器發(fā)送過來的數(shù)據(jù)之后如何對報(bào)文進(jìn)行解析,如何渲染到頁面上的過程,想了解更多的同學(xué)可以去看我語雀的文章,或者我會在文章后放幾篇比較優(yōu)秀的文章大家可以去看。
6.總結(jié)
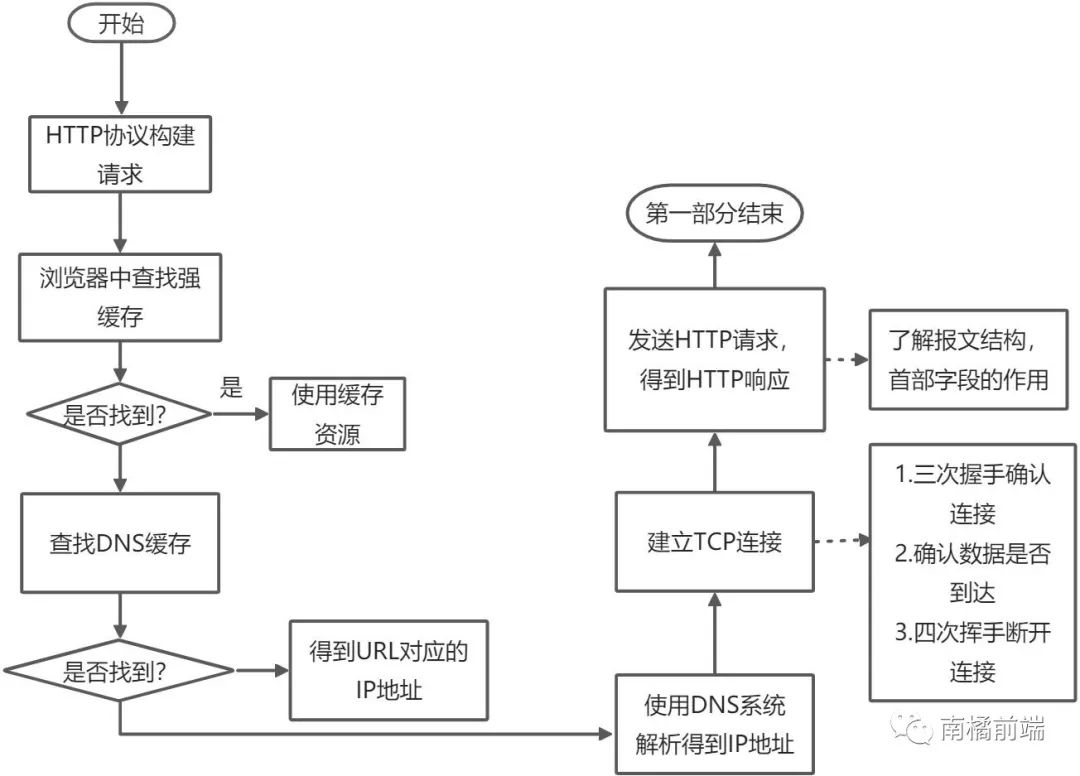
第一部分重點(diǎn)需要掌握的知識是:
瀏覽器的緩存,什么是強(qiáng)緩存,什么是協(xié)商緩存,緩存的存放地點(diǎn)
TCP連接,如何保證數(shù)據(jù)高效可靠的傳輸,三次握手,四次揮手
HTTP協(xié)議,報(bào)文結(jié)構(gòu),首部字段內(nèi)容等
瀏覽器解析:
首先我們可以經(jīng)常聽到說JS是一種單線程的語言,但是我們也知道JS中還是有異步任務(wù)的,如異步宏任務(wù),異步微任務(wù),而這些任務(wù)是怎么執(zhí)行的呢?其實(shí)本質(zhì)上是瀏覽器在接收到服務(wù)器響應(yīng)過來的文本文件后,如HTML文件,只會分配一個(gè)線程來進(jìn)行解析執(zhí)行,如果遇見文件里像<link href="xxxxx">,<script src="xxxxx">這樣還需要獲取其他文件的依賴時(shí),我們解析執(zhí)行代碼的主線程并不會停止,而是瀏覽器會調(diào)用一個(gè)新的線程去向服務(wù)器發(fā)送請求,來獲取文件,客戶端接收到響應(yīng)后的文件后會放在一個(gè)任務(wù)隊(duì)列里,等主線程的任務(wù)執(zhí)行完之后我們再處理任務(wù)隊(duì)列里的東西。從始至終解析執(zhí)行代碼的線程只有一個(gè),這就是單線程的本質(zhì)原因。(如果有人問這里說的是執(zhí)行的HTML文件啊和JS有什么關(guān)系?????HTML文件中不是也有JS要執(zhí)行嘛。。。)
說到這里我們來看一下我們對騰訊域名發(fā)送請求后到底給我們返回了什么東西?我們可以在我們的控制臺Sources中看到。看到的是漂亮的版面以及圖片嗎?...不是,是一堆的字符串。。。。。。

我們可以看一個(gè)比較簡單的HTML文件:
<html><head><meta charset="utf-8"></head><body><div><h1 class="title">demo</h1><input value="hello"></div></body></html>
其是由許多的字符串組成,根據(jù)編譯原理,對于任意一種編程語言在計(jì)算機(jī)編譯其之前都是一堆的字符串,編譯器要做的就是根據(jù)這些字符串生成對應(yīng)的語句然后根據(jù)語句生成邏輯,根據(jù)邏輯 再執(zhí)行對應(yīng)的任務(wù)。這個(gè)過程離不開三個(gè)階段:詞法分析,語法分析,語意分析。
詞法分析:
逐句的讀取每個(gè)字符,根據(jù)構(gòu)詞規(guī)則生成對應(yīng)的單詞或符號
語法分析:
在詞法分析的基礎(chǔ)上,根據(jù)生成的單詞或符號,使用邏輯處理,得到對應(yīng)的語句,函數(shù),表達(dá)式等,這一步會判斷我們寫的代碼在結(jié)構(gòu)上是否正確。如我們使用if語句沒有寫括號呀等
語義分析:
語義分析就是判斷我們寫的代碼是否符合邏輯,如我們的變量是const聲明的,結(jié)果我們要修改變量值,在這一步就會報(bào)錯(cuò)
說這些是為了方便理解接下來,根據(jù)HTML字符生成Tokens序列,以及生成DOM樹的過程,其是就是詞法分析,與語法分析的過程。
生成Takens序列(DOM):
在服務(wù)器返回?cái)?shù)據(jù)以后便需要使用Chrome的Blink內(nèi)核進(jìn)行解析了,我們得到的是一個(gè)bytes字符串,將這個(gè)字符串作為一個(gè)參數(shù)傳遞給一個(gè)方法,這個(gè)方法便可以對字符串進(jìn)行就解析了,那么如何進(jìn)行解析呢?解析之后是什么樣呢?
我們可以觀察一下我們的HTML標(biāo)簽,其都是以<來開頭,以>來結(jié)束,有些標(biāo)簽是單標(biāo)簽,有些是雙標(biāo)簽,遇見雙標(biāo)簽的話,有一個(gè)開標(biāo)簽就一定要有一個(gè)閉標(biāo)簽。所以我們的解析器就根據(jù)這些尖括號,來對我們的標(biāo)簽名,標(biāo)簽的屬性,標(biāo)簽里面的文本這些進(jìn)行標(biāo)記并生成序列來記錄他們,我們可以看一個(gè)簡單的例子:
<p>hahaha</p>如何解析:如我們看見一個(gè)P標(biāo)簽,當(dāng)我們遇見第一個(gè)<括號的時(shí)候我們知道是標(biāo)簽名了,當(dāng)我們遇見第二個(gè)>括號時(shí)我們知道標(biāo)簽名結(jié)束了,之后便是標(biāo)簽的文本了,但要注意的是目前還只是對每一個(gè)標(biāo)簽進(jìn)行標(biāo)記,我們得到的只是一些單詞字符,沒有任何邏輯關(guān)系。
解析結(jié)果:那么在Chrome瀏覽器中生成的Tokens序列究竟長啥樣呢?我們可以看一下對于上面的HTML文件它的Tokens是什么樣的:
tagName: html |type: DOCTYPE |attr: |text: "tagName: |type: Character |attr: |text: \n"tagName: html |type: startTag |attr: |text: "tagName: |type: Character |attr: |text: \n"tagName: head |type: startTag |attr: |text: "tagName: |type: Character |attr: |text: \n "tagName: meta |type: startTag |attr:charset=utf-8 |text: "tagName: |type: Character |attr: |text: \n"tagName: head |type: EndTag |attr: |text: "tagName: |type: Character |attr: |text: \n"tagName: body |type: startTag |attr: |text: "tagName: |type: Character |attr: |text: \n "tagName: div |type: startTag |attr: |text: "tagName: |type: Character |attr: |text: \n "tagName: h1 |type: startTag |attr:class=title |text: "tagName: |type: Character |attr: |text: demo"tagName: h1 |type: EndTag |attr: |text: "tagName: |type: Character |attr: |text: \n "tagName: input |type: startTag |attr:value=hello |text: "tagName: |type: Character |attr: |text: \n "tagName: div |type: EndTag |attr: |text: "tagName: |type: Character |attr: |text: \n"tagName: body |type: EndTag |attr: |text: "tagName: |type: Character |attr: |text: \n"tagName: html |type: EndTag |attr: |text: "tagName: |type: Character |attr: |text: \n"tagName: |type: EndOfFile |attr: |text: "
和我們說的幾乎一樣,有標(biāo)簽名tagName,標(biāo)簽的類型type,標(biāo)簽的屬性attr,標(biāo)簽的文本text。但這里要注意的是標(biāo)簽之間的文本,空格或換行也會被當(dāng)做是一個(gè)標(biāo)簽,有了這個(gè)序列之后我們就可以正式構(gòu)建DOM樹啦。
構(gòu)建DOM樹:
首先我先從大體上說一下什么是DOM樹,樹大家應(yīng)該都知道是一種分層數(shù)據(jù)結(jié)構(gòu),我們最常見的應(yīng)該是二叉樹,其每一個(gè)節(jié)點(diǎn)最多有兩個(gè)子節(jié)點(diǎn),而DOM樹是一種多叉樹,而這課樹的每一個(gè)節(jié)點(diǎn)就是DOM節(jié)點(diǎn)。
接下來大家可以思考一下對于每一個(gè)DOM節(jié)點(diǎn)來說最重要的應(yīng)該是什么?我們可以想想我們是不是需要使用JS來操作DOM,使用parentNode來讀取他的父節(jié)點(diǎn),使用childern來獲取它的子節(jié)點(diǎn),甚至我們還需要獲取它的兄弟節(jié)點(diǎn),獲取它的第一個(gè)子節(jié)點(diǎn),獲取其的最后一個(gè)子節(jié)點(diǎn),通過innerHTML獲取它的內(nèi)容。我們需要讀取它的屬性,我們需要修改它的屬性,有些時(shí)候還要將其插入到其他的節(jié)點(diǎn)之中。這些所有的操作都是瀏覽器在內(nèi)部使用C++語言封裝的方法來,根據(jù)我們之前傳入的Tokens序列做到的。大家可以想一想如果是你,你怎么樣根據(jù)之前的序列來生成這樣的一個(gè)DOM節(jié)點(diǎn),如果你做到了。。。。你可以去寫一個(gè)全新的瀏覽器內(nèi)核,不同瀏覽器之間不同的內(nèi)核本質(zhì)上就是使用不同的方法來實(shí)現(xiàn)DOM節(jié)點(diǎn)的結(jié)構(gòu)以及操作DOM節(jié)點(diǎn)的功能。
說完了大體我們來看一下構(gòu)建一個(gè)DOM節(jié)點(diǎn)的具體過程,我們首先來看一下DOM節(jié)點(diǎn)的結(jié)構(gòu):

Node是最頂層的父類,它有三個(gè)指針,兩個(gè)指針分別指向它的前一個(gè)結(jié)點(diǎn)和后一個(gè)結(jié)點(diǎn),一個(gè)指針指向它的父結(jié)點(diǎn);
ContainerNode繼承于Node,添加了兩個(gè)指針,一個(gè)指向第一個(gè)子元素,另一個(gè)指向最后一個(gè)子元素;
Element又添加了獲取dom結(jié)點(diǎn)屬性、clientWidth、scrollTop等函數(shù)
HTMLElement又繼續(xù)添加了Translate等控制,最后一級的子類HTMLParagraphElement只有一個(gè)創(chuàng)建的函數(shù),但是它繼承了所有父類的屬性。
需要提到的是每個(gè)Node都組合了一個(gè)treeScope,這個(gè)treeScope記錄了它屬于哪個(gè)document(一個(gè)頁面可能會嵌入iframe)。
我相信作為一個(gè)正常人,應(yīng)該還是很難記住上面的內(nèi)容的,所以總結(jié)一句話就是構(gòu)建DOM最關(guān)鍵的步驟便是是建立起每個(gè)結(jié)點(diǎn)的父子兄弟關(guān)系,即上面提到的成員指針的指向。
接下來首先我們要處理的第一條便是<DOCTYPE html>這個(gè)節(jié)點(diǎn)代表的token:
tagName: html |type: DOCTYPE |attr: |text: "我們的Blink內(nèi)核中會有一個(gè)Parser任務(wù)來會調(diào)用一個(gè)TreeBuilder方法,這個(gè)方法會對不同的標(biāo)簽類型進(jìn)行不同的處理:
void HTMLTreeBuilder::processToken(AtomicHTMLToken* token) {if (token->type() == HTMLToken::Character) {processCharacter(token);return;}switch (token->type()) {case HTMLToken::DOCTYPE:processDoctypeToken(token);break;case HTMLToken::StartTag:processStartTag(token);break;case HTMLToken::EndTag:processEndTag(token);break;//othercode}}
對于DOCTYPE這個(gè)類型比較特殊要特別處理,具體過程就不說了,我們只需要知道的是,會創(chuàng)建一個(gè)DOCTYPE節(jié)點(diǎn),并確定文件的類型,文件的類型會影響到后面的CSS解析工作。
兩種怪異模式:
接下來構(gòu)建DOM樹正式開始:
首先我們遇見的是開標(biāo)簽<html>,在這里會做如下幾件事:
創(chuàng)建一個(gè)html節(jié)點(diǎn)
將其放入到一個(gè)任務(wù)隊(duì)列Task里,進(jìn)行存放,這里是通過一個(gè)方法存放到任務(wù)隊(duì)列里
將其壓入到一個(gè)只存放開標(biāo)簽的棧里
執(zhí)行任務(wù)隊(duì)列里的代碼
具體源碼如下對應(yīng)的第二行,第三行,第四行,第五行:
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomicHTMLToken* token) {HTMLHtmlElement* element = HTMLHtmlElement::create(*m_document);attachLater(m_attachmentRoot, element); // 這里有兩個(gè)參數(shù),一個(gè)是父節(jié)點(diǎn),一個(gè)是當(dāng)前節(jié)點(diǎn)m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element, token));executeQueuedTasks();}
我們可以看見要存入任務(wù)隊(duì)列需要經(jīng)過attachLater方法,其接收兩個(gè)參數(shù),一個(gè)是父節(jié)點(diǎn)也就是這里的m_attachmentRoot,另一個(gè)是剛剛創(chuàng)建好的當(dāng)前節(jié)點(diǎn)。
那么m_attachmentRoot是什么呢?
HTMLConstructionSite::HTMLConstructionSite(Document& document): m_document(&document),m_attachmentRoot(document)) {}
之前在創(chuàng)建DOCTYPE這個(gè)節(jié)點(diǎn)的時(shí)候便會初始化HTMLConstructionSite我將其稱之為HTML建立函數(shù)??,同時(shí)也就初始化了這個(gè)變量,而這個(gè)變量的值便是document,也就是我們DOM樹的根節(jié)點(diǎn),第一次執(zhí)行時(shí)我們將這個(gè)變量作為html標(biāo)簽的父節(jié)點(diǎn)傳入了進(jìn)去。這里大家先留意一下,后面還會提到。。。。。
而對于這個(gè)html節(jié)點(diǎn)來說,Task任務(wù)隊(duì)列里面要做的是便是確定這個(gè)節(jié)點(diǎn)的父子兄弟關(guān)系。
那么這里為什么要使用一個(gè)任務(wù)隊(duì)列先將節(jié)點(diǎn)存放起來然后再插入(建立父子兄弟關(guān)系)呢?因?yàn)橛行┕?jié)點(diǎn)并不是一下子就插入的,比如遇見一個(gè)link語句,比如在我們的form表單節(jié)點(diǎn)里又有一個(gè)表單節(jié)點(diǎn)form呢?這就有許多的變化了,并不是插入到DOM樹里,而是有不同的操作。
我們可以看一下執(zhí)行任務(wù)隊(duì)列的具體過程,這里執(zhí)行的是任務(wù)隊(duì)列里的insert方法,有些標(biāo)簽可能是獲取資源呀等(我真的看不懂):
這個(gè)還比較好理解,在插入里面它會先去檢查父元素是否支持子元素,如果不支持,則直接返回,就像video標(biāo)簽不支持子元素。然后再去調(diào)具體的插入:
void ContainerNode::parserAppendChild(Node* newChild) {if (!checkParserAcceptChild(*newChild))return;AdoptAndAppendChild()(*this, *newChild, nullptr);}notifyNodeInserted(*newChild, ChildrenChangeSourceParser);}
之后是這樣:
void ContainerNode::appendChildCommon(Node& child) {child.setParentOrShadowHostNode(this);if (m_lastChild) {child.setPreviousSibling(m_lastChild);m_lastChild->setNextSibling(&child);} else {setFirstChild(&child);}setLastChild(&child);}
上面代碼第二行,設(shè)置子元素的父結(jié)點(diǎn),也就是會把html結(jié)點(diǎn)的父結(jié)點(diǎn)指向document,然后如果沒有l(wèi)astChild,會將這個(gè)子元素作為firstChild,由于上面已經(jīng)有一個(gè)docype的子結(jié)點(diǎn)了,所以已經(jīng)有l(wèi)astChild了,因此會把這個(gè)子元素的previousSibling指向老的lastChild,老的lastChild的nexSibling指向它。最后倒數(shù)第二行再把子元素設(shè)置為當(dāng)前ContainerNode(即document)的lastChild。這樣就建立起了html結(jié)點(diǎn)的父子兄弟關(guān)系。
能看懂的兄弟們就看吧,看不懂的就理解這里會確定一個(gè)節(jié)點(diǎn)的父子兄弟關(guān)系。我們之前向attachLater方法傳入了當(dāng)前節(jié)點(diǎn)的父節(jié)點(diǎn),與當(dāng)前節(jié)點(diǎn),所以無非就是讓當(dāng)前節(jié)點(diǎn)通過指針指向他的父節(jié)點(diǎn)罷了。
這是對于html標(biāo)簽來說的那么對于后面的<body>標(biāo)簽又是怎么處理呢?我們將其放入到一個(gè)只存放開標(biāo)簽的棧里的作用是什么呢?
我們接著看:
遇到<head>標(biāo)簽的token時(shí),也是先創(chuàng)建一個(gè)head結(jié)點(diǎn),然后再創(chuàng)建一個(gè)task,插到隊(duì)列里面:
void HTMLConstructionSite::insertHTMLHeadElement(AtomicHTMLToken* token) {m_head = HTMLStackItem::create(createHTMLElement(token), token);attachLater(currentNode(), m_head->element());m_openElements.pushHTMLHeadElement(m_head);}
這里我們會發(fā)現(xiàn)attachLater方法傳入的參數(shù)不一樣了,這個(gè)currentNode()是什么呢?
ContainerNode* currentNode() const {return m_openElements.topNode();}
根據(jù)這段代碼,我們可以看到其是來自于m_openElements,且調(diào)用了他的topNode()方法,我們可以看看之前我們創(chuàng)建html節(jié)點(diǎn)時(shí)的代碼,我們會創(chuàng)建一個(gè)節(jié)點(diǎn),并且將其與其父節(jié)點(diǎn)作為參數(shù)傳遞給attachLater方法,之后我們還要將創(chuàng)建出的節(jié)點(diǎn)放入棧里面,所以這里的m_openElements.topNode()語句應(yīng)該就是調(diào)用棧頂節(jié)點(diǎn)為父元素,也就是之前創(chuàng)建的<html>節(jié)點(diǎn)。
通過這個(gè)棧我們便可以很容易的得到當(dāng)前節(jié)點(diǎn)的父元素,頂?shù)脑乇闶钱?dāng)前創(chuàng)建出來節(jié)點(diǎn)的父節(jié)點(diǎn),因?yàn)槲覀冎粫验_標(biāo)簽放入棧中,那么如果遇見閉標(biāo)簽?zāi)兀?/p>
如果遇見閉標(biāo)簽我們就會將棧頂?shù)墓?jié)點(diǎn)pop出來,直到遇見和當(dāng)前標(biāo)簽一樣的開標(biāo)簽。
m_tree.openElements()->popUntilPopped(token->name());我們將我們的head節(jié)點(diǎn)pop出來之后,棧頂就是html元素了,這下如果再遇見body標(biāo)簽,那么html節(jié)點(diǎn)就是body節(jié)點(diǎn)的父節(jié)點(diǎn)了。
<html><head><meta charset="utf-8"></meta></head><body><div><p><b>hello</b></p><p>demo</p></div></body></html>
我們可以將pop與push的過程打印出來:
push "HTML" m_stackDepth = 1push "HEAD" m_stackDepth = 2pop "HEAD" m_stackDepth = 1push "BODY" m_stackDepth = 2push "DIV" m_stackDepth = 3push "P" m_stackDepth = 4push "B" m_stackDepth = 5pop "B" m_stackDepth = 4pop "P" m_stackDepth = 3push "P" m_stackDepth = 4pop "P" m_stackDepth = 3pop "DIV" m_stackDepth = 2"tagName: body |type: EndTag |attr: |text: ""tagName: html |type: EndTag |attr: |text: "
與我們所說的結(jié)果是一樣的,遇見開標(biāo)簽就入棧,遇見閉標(biāo)簽就出棧。
這就是棧的一個(gè)典型的應(yīng)用,讓我想起之前l(fā)eetCode上一個(gè)題,有效的括號,也就是關(guān)于棧的一個(gè)應(yīng)用。
但是如果有些時(shí)候我們寫的HTML格式不正確呢?我們的瀏覽器也應(yīng)該是有容錯(cuò)機(jī)制的。這里還要補(bǔ)充一個(gè)有意思的地方,就是我們的棧最大的深度是512,也就是說如果深度超過了512那么當(dāng)前節(jié)點(diǎn)便是上一個(gè)節(jié)點(diǎn)的兄弟節(jié)點(diǎn)并不會一直深入下去。
容錯(cuò)機(jī)制:
在某些時(shí)候我們要對棧里的元素進(jìn)行特別處理,因?yàn)楹芏鄷r(shí)候可能我們寫的HTML代碼的結(jié)構(gòu)是不正確的,但是總不能因?yàn)橐粋€(gè)一個(gè)標(biāo)簽的錯(cuò)誤而整個(gè)頁面的不進(jìn)行解析吧,所以我們的Chrome要進(jìn)行特別的處理。
1.如果我們遇見了body標(biāo)簽的閉標(biāo)簽,body的開標(biāo)簽也不會出棧,因?yàn)槲覀儗懺赽ody標(biāo)簽后的元素還是會被自動(dòng)當(dāng)成body標(biāo)簽的子元素。
2.如果有些時(shí)候使用的是</br>標(biāo)簽,解析出來的還是正常的<br>
3.如果我們的<form>標(biāo)簽里面還有一個(gè)form標(biāo)簽,那么會忽略里面的那個(gè)form標(biāo)簽
4.如果我們在HTML頁面里寫了一個(gè)不認(rèn)識的標(biāo)簽,那么瀏覽器本質(zhì)上會將其當(dāng)做一個(gè)span標(biāo)簽來處理,之后我們可以通過display:block將其轉(zhuǎn)換為塊元素
生成DOM樹的過程總結(jié)就是生成網(wǎng)頁總體結(jié)構(gòu)的過程,這一部分我們結(jié)合了Chrome源碼來探究了一個(gè)節(jié)點(diǎn)究竟是如何生成的,我們首先需要掃描每一個(gè)字符來生成Tokens序列,之后我們通過Tokens序列來生成節(jié)點(diǎn)。
最重要的是我們需要建立起每一個(gè)節(jié)點(diǎn)的父子兄弟關(guān)系,這一過程我們利用了棧的后進(jìn)先出的特征來實(shí)現(xiàn)。如果遇見開標(biāo)簽我們就入棧,如果遇見閉標(biāo)簽我們就出棧,這樣我們棧頂?shù)脑匾欢ㄊ钱?dāng)前元素的父節(jié)點(diǎn)。當(dāng)然很多時(shí)候我們寫的HTML頁面的結(jié)構(gòu)并不是那么的正確,所以在插入節(jié)點(diǎn)的時(shí)候我們還是要考慮一些錯(cuò)誤的情況,做一下容錯(cuò)機(jī)制。
在構(gòu)建DOM樹時(shí),我們同樣需要處理如<link>標(biāo)簽這樣需要獲取其他資源的標(biāo)簽,當(dāng)生成<link>節(jié)點(diǎn)在插入DOM樹之后便會自動(dòng)觸發(fā)資源加載機(jī)制,瀏覽器需要發(fā)送請求向服務(wù)器來獲取相應(yīng)的資源,這個(gè)過程是異步的不會影響我們DOM樹的解析工作,當(dāng)DOM樹構(gòu)建好之后我們便需要來處理CSS文件啦,所以接下來我們來看看CSS解析是什么樣的。

生成Tokens序列(CSS):
這里還是和解析HTML一樣的,需要先生成CSS的Tokens序列,但是解析字符的規(guī)則是不一樣的,還是和上面一樣我們先來看看生成的Tokens序列是什么樣的。
CSS的token是有多種類型的,我們可以看一張圖,這樣的一個(gè)CSS被劃分成了多個(gè)類型:

同樣是設(shè)置顏色,如果我們使用的rgb的格式,token的類型將是一個(gè)函數(shù),也就是說我們需要多調(diào)用一個(gè)函數(shù)來轉(zhuǎn)換rgb格式的顏色,所以從性能優(yōu)化的角度這里我們更提倡使用16進(jìn)制代表顏色。

將Tokens轉(zhuǎn)換為cssRule:
做完詞法分析,生成Tokens之后我們需要進(jìn)行語法分析了。這里我們不需要關(guān)注將Tokens序列轉(zhuǎn)換為cssRule的規(guī)則,但我們可以了解一下cssRule,其分為兩部分,對應(yīng)的是CSS的選擇器selectors與屬性值properties集合,每一個(gè)CSS的選擇器與屬性集構(gòu)成一條rule我們以以下例子來看看:
.text .hello{color: rgb(200, 200, 200);width: calc(100% - 20px);}#world{margin: 20px;}
打印出來的cssRule是這樣的:
selector text = “.text .hello”value = “hello” matchType = “Class” relation = “Descendant”tag history selector text = “.text”value = “text” matchType = “Class” relation = “SubSelector”selector text = “#world”value = “world” matchType = “Id” relation = “SubSelector”
我們可以發(fā)現(xiàn)其是從右到左進(jìn)行解析的,這樣可能在匹配標(biāo)簽的時(shí)候比較方便一些。blink定義了一下幾種matchType:
enum MatchType {Unknown,Tag, // Example: divId, // Example: #idClass, // example: .classPseudoClass, // Example: :nth-child(2)PseudoElement, // Example: ::first-linePagePseudoClass, // ??AttributeExact, // Example: E[foo="bar"]AttributeSet, // Example: E[foo]AttributeHyphen, // Example: E[foo|="bar"]AttributeList, // Example: E[foo~="bar"]AttributeContain, // css3: E[foo*="bar"]AttributeBegin, // css3: E[foo^="bar"]AttributeEnd, // css3: E[foo$="bar"]FirstAttributeSelectorMatch = AttributeExact,};
還定義了一些選擇器的類型:
enum RelationType {SubSelector, // No combinatorDescendant, // "Space" combinatorChild, // > combinatorDirectAdjacent, // + combinatorIndirectAdjacent, // ~ combinator// Special cases for shadow DOM related selectors.ShadowPiercingDescendant, // >>> combinatorShadowDeep, // /deep/ combinatorShadowPseudo, // ::shadow pseudo elementShadowSlot // ::slotted() pseudo element};
Descendant便指的是后代選擇器.hello,選擇器的類型幫助我們快速匹配到這個(gè)元素的樣式,如.hello的類型是后代,那么從右往左,下一步判斷當(dāng)前元素父類是否匹配.text這個(gè)選擇器。接下了便是屬性值的集合了。
我們將其打印出來:
selector text = “.text .hello”perperty id = 15 value = “rgb(200, 200, 200)”perperty id = 316 value = “calc(100% – 20px)”selector text = “#world”perperty id = 147 value = “20px”perperty id = 146 value = “20px”perperty id = 144 value = “20px”perperty id = 145 value = “20px”
id對應(yīng)的是不同的屬性名:
enum CSSPropertyID {CSSPropertyColor = 15,CSSPropertyWidth = 316,CSSPropertyMarginLeft = 145,CSSPropertyMarginRight = 146,CSSPropertyMarginTop = 147,CSSPropertyMarkerEnd = 148,}
這里有一個(gè)小知識:
設(shè)置了margin: 20px,會轉(zhuǎn)化成四個(gè)屬性。從這里可以看出CSS提倡屬性合并,但是最后還是會被拆成各個(gè)小屬性。所以屬性合并最大的作用應(yīng)該在于減少CSS的代碼量。
由cssRule生成styleSheet:
每一個(gè)CSS的選擇器與屬性集都會構(gòu)成一個(gè)cssRule,同一個(gè)css表的所有rule會被放到styleSheet對象里,blink會把用戶的樣式存放到一個(gè)m_authorStyleSheets的向量里面,如下圖示意:

這里面還有瀏覽器默認(rèn)的樣式DefaultStyleSheet,這里面就包括像a標(biāo)簽的默認(rèn)樣式,h1-h5標(biāo)簽的margin指等。
最后會把生成的rule放到一個(gè)哈希map之中:
CompactRuleMap m_idRules;CompactRuleMap m_classRules;CompactRuleMap m_tagRules;CompactRuleMap m_shadowPseudoElementRules;
哈希map根據(jù)右邊第一個(gè)選擇器的類型進(jìn)行分類存放rule,一共有四種類型ID,類名,標(biāo)簽,偽類,這樣將rule分類的原因是我們可以先快速的找到最外層選擇器相同的rule,之后我們再去尋找這個(gè)rule的下一個(gè)選擇器來匹配到當(dāng)前元素。
命中選擇器:
在解析好CSS樣式的時(shí)候我們需要根據(jù)每一個(gè)可視的Node節(jié)點(diǎn)來生成Layout節(jié)點(diǎn),由Layout節(jié)點(diǎn)再生成我們需要的Layout tree。這個(gè)過程其實(shí)就是確定整個(gè)頁面布局每一個(gè)可視節(jié)點(diǎn)樣式的過程,在生成Layout 節(jié)點(diǎn)的時(shí)候我們需要計(jì)算一下每一個(gè)節(jié)點(diǎn)的CSS樣式,而這個(gè)過程其實(shí)可以分為兩部分:根據(jù)當(dāng)前節(jié)點(diǎn)的選擇器匹配到對應(yīng)的樣式,設(shè)置這個(gè)節(jié)點(diǎn)的CSS樣式。
首先是根據(jù)當(dāng)前節(jié)點(diǎn)的選擇器匹配到對應(yīng)的樣式,我們一個(gè)DOM樹上有那么多的節(jié)點(diǎn),我們?nèi)绾慰焖俑咝У恼业矫恳粋€(gè)節(jié)點(diǎn)對應(yīng)的CSS樣式呢?首先我們需要遍歷每一個(gè)可視節(jié)點(diǎn),將按照id、class、偽元素、標(biāo)簽的順序取出所有的selector,之前說過我們會把每一條rule放入到一個(gè)哈希map中,我們可以根據(jù)遍歷到的這個(gè)節(jié)點(diǎn)的選擇器快速的和哈希map的鍵進(jìn)行配對,找到保存的rule。
我們還是以這個(gè)demo為例:
<style>.text{font-size: 22em;}.text p{color: #505050;}</style><div class="text"><p>hello, world</p></div>
其會生成兩個(gè)rule,在map表中通過classRule與tagRuled對應(yīng),我們在遇到<div class="text">的時(shí)候會對應(yīng)到哈希map里的classRule,首先與.text進(jìn)行配對,如果成功就判斷其父選擇器是否匹配,這個(gè)樣式?jīng)]有用父選擇器所以就成功返回了,如果失敗就直接退出。
第二個(gè)我們遇見了.text p,還是一樣的我們會由tagRuled先匹配P標(biāo)簽,因?yàn)檫x擇器的類型是后代選擇器,所以我們會對當(dāng)前節(jié)點(diǎn)的所有父節(jié)點(diǎn)進(jìn)行遍歷,查看是否可以匹配到.text如果命中就再查看其左邊再有沒有其他的選擇器了,如果沒有就可以成功返回了。
這里需要注意的是我們在查找完右邊第一個(gè)選擇器后如果左邊還有其他的選擇器我們需要使用之前的方法遞歸判斷當(dāng)前節(jié)點(diǎn)的父節(jié)點(diǎn)或者其他情況,我們知道使用遞歸往往是比較消耗性能的,所以我們不應(yīng)將復(fù)合選擇器寫的過長,最好不要超過三層。
設(shè)置Style:
當(dāng)節(jié)點(diǎn)匹配到對應(yīng)的rule的時(shí)候我們對將其保存在該元素的m_matchedRules的向量里面從而生成Layout Tree,之后我們需要去計(jì)算選擇器的優(yōu)先級,得出的結(jié)果保存在m_specificity變量。這里重點(diǎn)就來了,我們可以在網(wǎng)上看到許多關(guān)于優(yōu)先級的文章,那么Chrome的本質(zhì)到底是怎么樣去計(jì)算優(yōu)先級的呢?
for (const CSSSelector* selector = this; selector;selector = selector->tagHistory()) {temp = total + selector->specificityForOneSelector();}return total;
首先從右往左取各個(gè)選擇器的優(yōu)先級之和,不同類型的選擇器優(yōu)先級定義如下:
switch (m_match) {case Id:return 0x010000;case PseudoClass:return 0x000100;case Class:case PseudoElement:case AttributeExact:case AttributeSet:case AttributeList:case AttributeHyphen:case AttributeContain:case AttributeBegin:case AttributeEnd:return 0x000100;case Tag:return 0x000001;case Unknown:return 0;}return 0;}
從中我們可以看到ID選擇器的優(yōu)先級最高是16進(jìn)制的0x010000=65536,類、屬性、偽類的優(yōu)先級是0x100 = 256,標(biāo)簽選擇器的優(yōu)先級是1,其他如通配符就是0了。將我們案例中的選擇器的優(yōu)先級計(jì)算如下:
/*優(yōu)先級為257 = 265 + 1*/.text h1{font-size: 8em;}/*優(yōu)先級為65537 = 65536 + 1*/#text h1{font-size: 16em;}
當(dāng)所有的優(yōu)先級都放在m_matchedRules這個(gè)向量里面之后我們需要對所有的向量按照優(yōu)先級的大小進(jìn)行排序,排序規(guī)則就是如果優(yōu)先級相同我們就比較其先后位置。這就是css的層疊性。
之后我們需要去處理內(nèi)聯(lián)式樣式表,這在我們構(gòu)建DOM樹的時(shí)候已經(jīng)保存起來了,我們將其放在按照優(yōu)先級排序好的裝向量容器的頂部,這樣無論之前的樣式的優(yōu)先級有多高內(nèi)聯(lián)式一定是最大的。
collector.addElementStyleProperties(state.element()->inlineStyle(),isInlineStyleCacheable);
最后我們便需要根據(jù)優(yōu)先級來設(shè)置元素的Style了,我們先設(shè)置正常的最后再設(shè)置!important的規(guī)則,后面設(shè)置的會覆蓋前面設(shè)置的。
接下來我們可以大概看一下計(jì)算出來的style是什么樣的,按優(yōu)先級計(jì)算出來的Style會被放在一個(gè)ComputedStyle的對象里面,這個(gè)style里面的規(guī)則分成了幾類,通過檢查style對象可以一窺:

把它畫成一張圖表:

主要有幾類,box是長寬,surround是margin/padding,還有不可繼承的nonInheritedData和可繼承的styleIneritedData一些屬性。Blink還把很多比較少用的屬性放到rareData的結(jié)構(gòu)里面,為避免實(shí)例化這些不常用的屬性占了太多的空間。
具體來說,上面設(shè)置的font-size為:22em * 16px = 352px:

關(guān)于顏色的屬性值會被轉(zhuǎn)換為16進(jìn)制整數(shù):
static const RGBA32 lightenedBlack = 0xFF545454;static const RGBA32 darkenedWhite = 0xFFABABAB;
調(diào)整Style樣式:
最后我們需要對我們計(jì)算出的CSS樣式進(jìn)行一些調(diào)整,如將absoluet、fixed定位,float的元素轉(zhuǎn)化為block
// Absolute/fixed positioned elements, floating elements and the document// element need block-like outside display.if (style.hasOutOfFlowPosition() || style.isFloating() ||(element && element->document().documentElement() == element))style.setDisplay(equivalentBlockDisplay(style.display()));
最后還會對表格元素做一些調(diào)整。
最后當(dāng)所有的樣式都計(jì)算完之后我們會將其掛載到window.getComputedStyle上來供之后的JS訪問
總結(jié):
講到這里CSS的解析與計(jì)算的部分就說完了,瀏覽器的解析部分也就完結(jié)了,可能過程有些復(fù)雜但是我們?nèi)绻垡晦圻€是很明確的。我們可以大致分為四部分,我們來一個(gè)個(gè)的總結(jié)一下:
1.解析HTML
這一部分其實(shí)就做了一件事,掃描每個(gè)字符構(gòu)建出Tokens 序列,Tokens 序列中的內(nèi)容標(biāo)簽的類型、標(biāo)簽名、文本內(nèi)容、屬性等
2.構(gòu)建DOM樹
之后我們需要根據(jù)生成好的Tokens 序列來生成DOM節(jié)點(diǎn),從而構(gòu)建DOM樹,這里比較重要的部分就是我們需要建立每一個(gè)節(jié)點(diǎn)的父子兄弟關(guān)系,DOM樹的根節(jié)點(diǎn)就是document。
1.最開始我們會根據(jù)<DOCType html>確定文檔的類型。
2.對于<html>標(biāo)簽我們首先會創(chuàng)建節(jié)點(diǎn),然后讓其父指針指向document,讓開標(biāo)簽入棧
3.對于其他的標(biāo)簽我們創(chuàng)建節(jié)點(diǎn)的過程也是非常相似的,首先我們會創(chuàng)建節(jié)點(diǎn),通過任務(wù)隊(duì)列來建立起其父子兄弟關(guān)系,這里其父節(jié)點(diǎn)就是棧頂?shù)脑兀髸岄_標(biāo)簽入棧
4.如果遇見閉標(biāo)簽就出棧
5.還有一些特殊功能需要完成,如容錯(cuò)機(jī)制,異步加載的處理等
3.計(jì)算CSS樣式
這個(gè)部分其實(shí)就是對CSS文件的解析,還是一樣先生成Tokens序列,但是CSS的Token類型是非常多的,比如我們設(shè)置背景顏色時(shí)rgb格式我會將其標(biāo)記成一個(gè)函數(shù),方便后序轉(zhuǎn)化。
生成CSS Tokens之后解析工作還沒有完成,我們還需要將選擇器與屬性值分開生成CSSRule,每一個(gè)選擇器與屬性集共同組成了一個(gè)rule,我們將生成的rule放在stylesheet這個(gè)對象里保存。
最后我們還需要將生成的rule集放在一個(gè)哈希map里,根據(jù)右邊第一個(gè)選擇器的類型分類進(jìn)行存放。
4.生成Layout tree
這一部分我們通過遍歷DOM樹中的可視節(jié)點(diǎn)來生成布局樹。
命中選擇器:首先我們會先去遍歷dom樹中每一個(gè)可視節(jié)點(diǎn)來快速匹配哈希map里的鍵,然后找到該節(jié)點(diǎn)對應(yīng)的rule,將該rule保存在該節(jié)點(diǎn)上。
計(jì)算優(yōu)先級:計(jì)算出所有選擇器的優(yōu)先級保存在一個(gè)向量中。這里著重要注意一下選擇器的優(yōu)先級,對于ID選擇器其優(yōu)先級是最高的0x010000,之后是類,偽類,屬性選擇器為0x0100,最后是標(biāo)簽選擇器為1,剩下的通配符等都是0。保存在向量中之后我們需要對所有的向量按照優(yōu)先級的大小進(jìn)行排序,放在一個(gè)容器里,容器的頂部優(yōu)先級最高,之后我們需要去處理內(nèi)聯(lián)式,處理完之后放在我們的容器頂部。
生成Style樣式:最后就是根據(jù)我們保存的優(yōu)先級來設(shè)置每一個(gè)元素的CSS樣式,這個(gè)過程需要運(yùn)算與轉(zhuǎn)化,先設(shè)置正常的最后再設(shè)置!important,在這里我們會將rgb格式的顏色轉(zhuǎn)換為16位的數(shù)字,我們會對樣子做最后的調(diào)整,為absolute/fixed元素轉(zhuǎn)換為block等。
最后將所有計(jì)算完的CSS樣式掛載到window.getComputerStyle上。
瀏覽器渲染部分
構(gòu)建圖層樹:
在解析完HTML與CSS文件之后我們有了DOM樹與Layout樹,這時(shí)還不能直接渲染到頁面上,因?yàn)槲覀冞€需要考慮一些特殊的情況,如我們使用CSS3D效果這時(shí)可能不止是一個(gè)圖層,還有有些時(shí)候可能會有層疊上下文的情況。所以在構(gòu)建完布局樹之后,來確定每一個(gè)節(jié)點(diǎn)的疊放順序,所以我們還需要構(gòu)建一棵圖層樹(Layer Tree)來解決這些問題。
那么如何構(gòu)建圖層樹呢?一般情況下該節(jié)點(diǎn)的圖層默認(rèn)是父節(jié)點(diǎn)的圖層,有兩種情況需要單獨(dú)合成圖層(也稱為合成層),一種是顯式合成,一種是隱式合成。接下來我們一一介紹:
顯式合成:
顯式合成有兩種情況,一種是具有層疊上下文的節(jié)點(diǎn),用CSS的屬性就可以控制,下面羅列了幾種,這些情況我們需要單獨(dú)創(chuàng)建圖層,如果有些同學(xué)想要多了解層疊上下文的概念可以看看這篇文章:
首先是HTML的根元素本身就是層疊上下文的情況
我們經(jīng)常使用的absolute/fixed/sticky定位,并且我們需要設(shè)置z-index的屬性,這些定位是脫離普通文檔流的
我們使用的透明度opacity,其值不能為1
相同的還有filter ,其值不是none
之前在性能優(yōu)化的文章中提到的transform,其值不是none
元素的 isolation 值是isolate
will-change指定的屬性值為上面任意一個(gè)。(will-change的作用后面會詳細(xì)介紹)
在這里要說一下的是像opacity,filter,transform屬性雖然是要構(gòu)建出一個(gè)單獨(dú)的圖層,但是這些CSS3的屬性會調(diào)用硬件加速GPU,并不會引起后面說的回流與重繪。

還有一種就是需要剪裁的地方,當(dāng)然如我們一個(gè)塊元素內(nèi)容溢出需要使用滾動(dòng)條,這個(gè)滾動(dòng)條就是在一個(gè)單獨(dú)的圖層上。
隱式合成:
這個(gè)特點(diǎn)總結(jié)就是一句話,層疊等級低的節(jié)點(diǎn)如果被提升為一個(gè)單獨(dú)的圖層,那么所有層疊等級比他高的節(jié)點(diǎn)都會成為一個(gè)單獨(dú)的圖層。
大家可以想想如果一個(gè)層疊等級比較低的節(jié)點(diǎn),上面有幾百個(gè)節(jié)點(diǎn),如果其成為了一個(gè)單獨(dú)圖層,一下子要生成幾百個(gè)圖層,這樣大大增加了內(nèi)存的壓力,可能會讓頁面崩潰,這就是層爆炸。
生成繪制列表:
有了圖層樹之后我們渲染的準(zhǔn)備工作基本上就做完了,接下來我們需要做的就是將我們的渲染工作分成一個(gè)個(gè)的指令,由這些指令來指導(dǎo)計(jì)算機(jī)來繪制,所以我們會生成一個(gè)繪制列表,繪制列表來決定先繪制背景還是先繪制邊框呀這些。
我們可以在Chrome瀏覽器的開發(fā)者工具里看到這些繪制列表,在開發(fā)者工具里找到more tools,然后找到Layers面板,就能看到繪制列表了。還是我們熟悉的騰訊官網(wǎng),我們可以來看看:

分割圖塊、生成位圖:
在渲染進(jìn)程生成繪制列表后便會開一個(gè)線程來專門處理繪制工作,這個(gè)線程叫做合成線程,通過commit消息將之前生成的繪制列表提交給合成線程。
分割圖塊:我們知道很多情況下包含滾動(dòng)條的頁面是非常大的,如果一次性渲染出來是非常消耗性能的,所以我們合成線程需要做的第一件事便是將圖層進(jìn)行分塊處理,這里有一個(gè)需要注意的地方,我們分割成的圖塊在后續(xù)是需要上傳到GPU處理的,而從瀏覽器內(nèi)存上傳到GPU內(nèi)存的速度是非常慢的,即使是一小塊圖塊的繪制也是非常緩慢的,所以我們的Chrome瀏覽器為了提高顯示的性能,會在第一次繪制圖塊時(shí)先采用低分辨率的圖片進(jìn)行繪制,之后等所有圖塊繪制完成之后然后在用高分辨的率的圖片將其進(jìn)行替代。這也是Chrome優(yōu)化首屏加載速度的一種方法。
生成位圖:在合成線程完成分割圖塊之后,我們的渲染進(jìn)程會優(yōu)先把位于視口附加的圖塊,發(fā)送給自己控制的一個(gè)叫柵格化線程池的東西,由其將圖塊轉(zhuǎn)換為位圖數(shù)據(jù),轉(zhuǎn)化完之后再發(fā)送給合成線程。這里還需要知道的是這里將圖塊轉(zhuǎn)化為位圖數(shù)據(jù)的過程會調(diào)用硬件GPU來進(jìn)行加速。
在位圖數(shù)據(jù)生成完之后我們最后需要做的就是將其通過顯卡來渲染出來。

通過顯卡顯示頁面:
當(dāng)合成線程接收到柵格化線程池發(fā)送過來的位圖數(shù)據(jù)后會生成一個(gè)命令,隨后將這個(gè)命令發(fā)送給瀏覽器進(jìn)程,瀏覽器進(jìn)程中的viz組件接收到這個(gè)命令之后,會根據(jù)這個(gè)命令將生成好的柵格化后的內(nèi)容保存到內(nèi)存中,也就是頁面,然后將內(nèi)存中保存的頁面發(fā)送給顯卡的后緩沖區(qū),由顯卡通過顯示器來顯示出來。
這里還需要了解一下顯示器屏幕顯示的原理:我們屏幕顯示圖像的本質(zhì)就像小時(shí)候玩快速翻動(dòng)的那種小人書一樣,當(dāng)我們快速翻頁的時(shí)候就可以看見類似于動(dòng)畫一樣的效果。而這里屏幕翻動(dòng)的速度就叫做固定刷新率,一般情況下是一秒60幀,可以理解為一秒翻動(dòng)60頁。我們的顯卡擁有前緩沖區(qū)與后緩沖區(qū)兩部分,每次翻動(dòng)時(shí)相當(dāng)于前緩沖區(qū)與后緩沖區(qū)對調(diào),循環(huán)執(zhí)行,這樣我們的圖像就可以被顯示出來了。
有些時(shí)候如果某個(gè)動(dòng)畫比較復(fù)雜的時(shí)候,從圖塊生成位圖的過程就會非常緩慢,這樣瀏覽器發(fā)送給顯卡不及時(shí),而顯卡還是以60幀的速度進(jìn)行刷新,所以就會出現(xiàn)頁面卡頓的現(xiàn)象,也稱為掉幀。

到這里瀏覽器渲染部分就講完了我們從輸入U(xiǎn)RL到頁面顯示部分也就基本講完了,但為了面試后面我們還會補(bǔ)充兩個(gè)相關(guān)知識,回流與重繪。接下來我們將渲染部分總結(jié)一下,大家可以根據(jù)上面的文字,再理清一下整個(gè)過程。
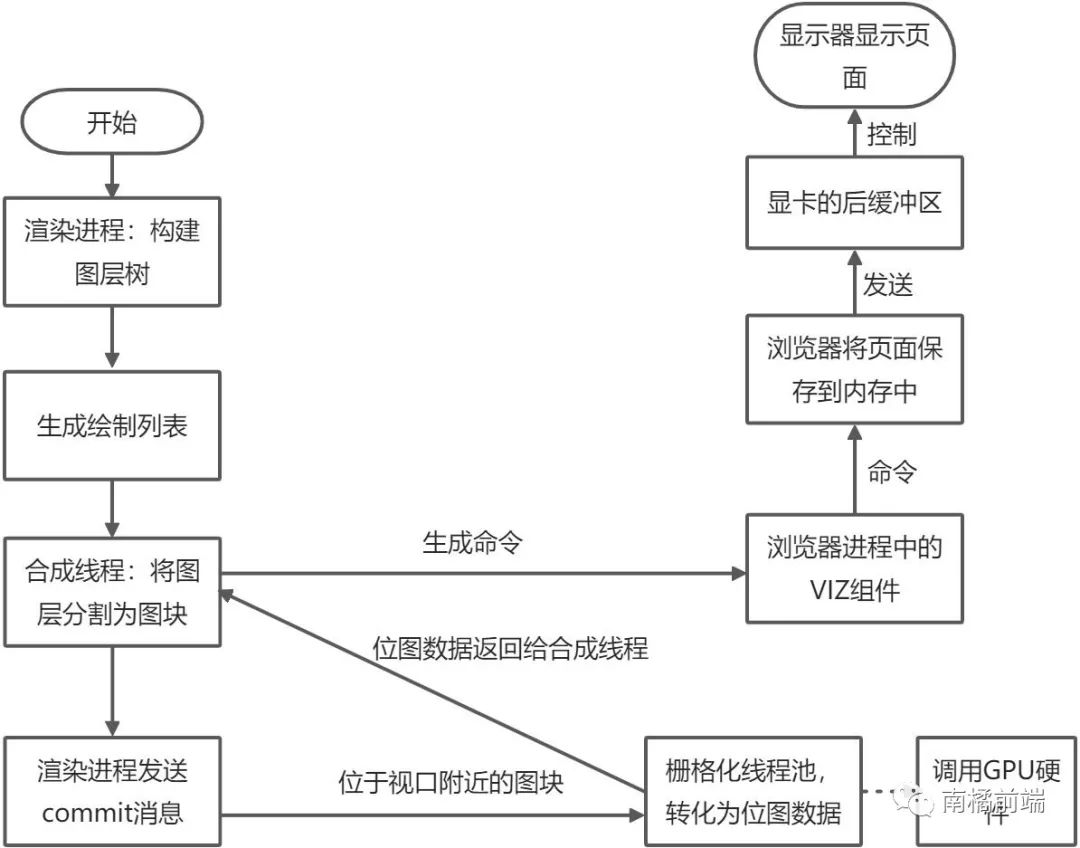
我們還可以看一下整個(gè)渲染過程的步驟,這里要注意在生成圖塊之前所有的操作基本上都是在渲染進(jìn)程的主線程中進(jìn)行的,之后分圖塊是在合成線程中進(jìn)行的,通過柵格化線程池轉(zhuǎn)化為位圖數(shù)據(jù)再返回到合成線程,合成線程給瀏覽器進(jìn)程發(fā)送命令,瀏覽器將頁面保存到內(nèi)存,然后再發(fā)送到顯卡,通過顯示器顯示出來:

從我們輸入U(xiǎn)RL開始,到經(jīng)過計(jì)算機(jī)復(fù)雜的處理,最終在顯示器上顯示出來美輪美奐的頁面,對于我們來說一切都是那么簡單,一切都是那么自然這背后所凝結(jié)的技術(shù)卻是多少IT人技術(shù)的積累。。。上頭了上頭了
回流:
我們的頁面通常是很多個(gè)元素組成的,如果我們修改了頁面中一個(gè)元素的大小,可能整個(gè)頁面所有元素的位置都會發(fā)生改變,這個(gè)時(shí)候我們就要從生成DOM樹開始重新計(jì)算一下頁面中所有元素的位置,樣式等。就相當(dāng)于從構(gòu)建DOM開始包括解析合成所有的流程再來一遍,這個(gè)過程就叫做回流(reflow),也叫做重排(當(dāng)然也包括生成圖塊,柵格化等后續(xù)處理)。可見其是非常消耗性能的,所以我們在使用JS的時(shí)候應(yīng)盡量避免直接操作DOM,具體避免回流的方法還有很多在我的上一篇文章淺談前端性能優(yōu)化中有講。

重繪:
重繪就簡單多了,如果我們改變了頁面中一個(gè)元素的樣式,并沒有修改其幾何屬性,那我們只需要重新計(jì)算一下這個(gè)元素的樣式,然后直接生成繪制列表,然后分割圖塊,柵格化等便好了,省略了生成DOM樹,布局樹,建立圖層這些過程。

可見回流是包含重繪的,回流一定引起重繪,重繪不一定引起回流。所以從前端性能優(yōu)化的角度我們一定要避免造成回流。
合成:
最后就是我們GPU硬件加速,我們CSS3的一些屬性,如transform,filter,scale,opacity這些會直接使用GPU合成,不會經(jīng)歷回流以及重繪,所以我們做動(dòng)畫時(shí)一般會采用這些方法,但也要謹(jǐn)慎使用避免過度的消耗內(nèi)存。
好了以上就是所有內(nèi)容,還是有許多不夠完善的地方,希望大家可以多提寶貴意見,祝大家在學(xué)習(xí)前端的路上越走越好??????????????????
知乎:
Paula Hu《深入理解層疊上下文》
李銀城 《從Chrome源碼看瀏覽器如何構(gòu)建DOM樹》、《從Chrome源碼看瀏覽器如何計(jì)算CSS》
掘金:
神三元《瀏覽器靈魂之問,請問你能接得住幾個(gè)?》、《HTTP靈魂之問,鞏固你的 HTTP 知識體系》
騰訊云:
《瀏覽器渲染(線程視角1)》
小獅子有話說
你好,我是 Chocolate,一個(gè)獅子座的前端攻城獅,希望成為優(yōu)秀的前端博主,每周都會更新文章,與你一起變優(yōu)秀~
關(guān)注 小獅子前端,回復(fù)【小獅子】獲取為大家整理好的文章、資源合集我的博客地址: yangchaoyi.vip歡迎收藏,可在博客留言板留下你的足跡,一起交流~覺得文章不錯(cuò),【 點(diǎn)贊】【在看】支持一波 ??ヽ(°▽°)ノ?
叮咚~ 可以給小獅子加
星標(biāo),便于查找。感謝加入小獅子前端,最好的我們最美的遇見,我們下期再見~