
3萬字聊聊什么是RocketMQ(三)
大家好,我是Leo。
上一篇我們介紹了
- MQ分布式事務的相關實現(xiàn)
- MQ消息丟失,一致性問題在生產(chǎn),存儲,消費階段如何解決
- 消息重發(fā)之后,如何避免重復消費
繼上篇RocketMQ技術總結二,這篇主要介紹一下
- 消息積壓問題如何處理
- 閱讀源碼的小技巧
- 異步方案提升系統(tǒng)性能
- MQ的緩存策略

基礎知識系列
大廠面試系列
本章概括
異步方案那里可以暫時一筆帶過,后續(xù)寫實戰(zhàn)的時候會詳細深入的
入手源碼那里,根據(jù)自己對未來的發(fā)展規(guī)劃選擇性翻閱吧。
消息積壓問題
什么是消息積壓
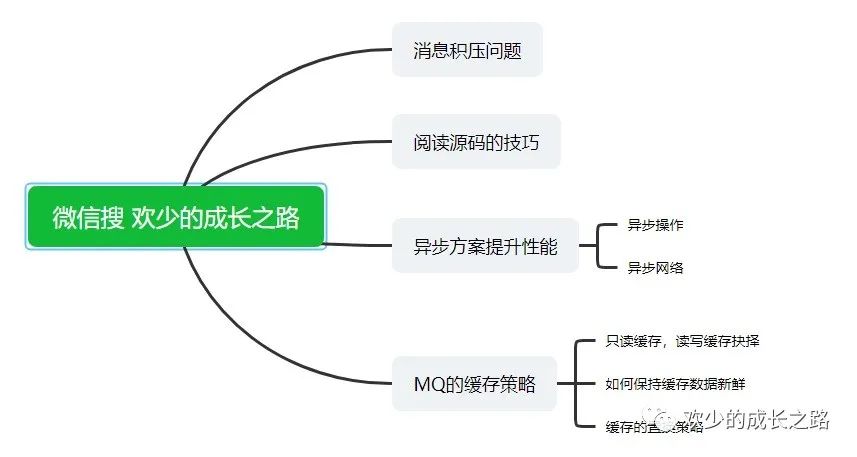
消息積壓是使用MQ消息隊列系統(tǒng)中,最常見的一種性能問題。如下圖所示,當生產(chǎn)端的生產(chǎn)效率大于消費端的消費效率就會造成消息處理不完的情況,也就叫 “消息積壓”。

消息積壓應對方案(一)
第一種方案主要是優(yōu)化生產(chǎn)端,消費端的處理能力。(消息隊列你就別優(yōu)化了,那么牛逼的團隊設計出那么好的產(chǎn)品不會出問題的)
所以?我們只需要處理如何與消息隊列配合,達到一個最佳的性能就夠了。
對于生產(chǎn)端來說,并不會影響性能。因為一般生產(chǎn)端都是先執(zhí)行自己的業(yè)務程序之后,再生產(chǎn)消息到MQ的。如果說,你的代碼發(fā)送消息的性能上不去,你需要優(yōu)先檢查一下,是不是發(fā)消息之前的業(yè)務邏輯耗時太多導致的。
我們之前在講生產(chǎn)端發(fā)送消息的過程中,假設這一次交互的平均耗時1ms,我們把這1ms的時間分解開,主要包括下列幾項
- 發(fā)送前的準備數(shù)據(jù),序列化數(shù)據(jù),構造請求等耗時。也就是生產(chǎn)端在發(fā)送網(wǎng)絡請求之間的耗時
- 發(fā)送消息和返回響應在網(wǎng)絡傳輸中的耗時
- Broker處理消息的耗時
如果是單線程發(fā)送,每次只發(fā)送 1 條消息,那么每秒只能發(fā)送 1000ms / 1ms * 1 條 /ms = 1000 條 消息,這種情況下并不能發(fā)揮出消息隊列的全部實力。
無論是增加每次發(fā)送消息的批量大小,還是增加并發(fā),都能成倍地提升發(fā)送性能。至于到底是選擇批量發(fā)送還是增加并發(fā),主要取決于生產(chǎn)端程序的業(yè)務性質(zhì)。
復習鏈接?生產(chǎn)端發(fā)送消息過程
對于消費端來說,大部分的問題應該都是出在這里的。主要的調(diào)優(yōu)點也是在這個位置。
如果消費端的性能延時只是暫時的,那問題不大,只要消費端的性能恢復之后,超過生產(chǎn)端的性能,那積壓的消息是可以逐漸被消化掉的。
要是消費速度一直比生產(chǎn)速度慢,時間長了,整個系統(tǒng)就會出現(xiàn)問題,要么,消息隊列的存儲被填滿無法提供服務,要么消息丟失,這對于整個系統(tǒng)來說都是嚴重故障。所以,我們在設計系統(tǒng)的時候,一定要保證消費端的消費性能要高于生產(chǎn)端的發(fā)送性能,這樣的系統(tǒng)才能健康的持續(xù)運行。
除了優(yōu)化業(yè)務性能,也可以對消費端進行水平擴容,增加消費端的并發(fā)數(shù)從而達到總體的消費性能。在擴容 Consumer 的實例數(shù)量的同時, 必須同步擴容主題中的分區(qū)(也叫隊列)數(shù)量,確保 Consumer 的實例數(shù)和分區(qū)數(shù)量是相等的。?如下圖所示。
如果 Consumer 的實例數(shù)量超過分區(qū)數(shù)量,這樣的擴容實際上是沒有效果的。原因 我們之前講過,因為對于消費者來說,在每個分區(qū)上實際上只能支持單線程消費
消息積壓應對方案(二)
第二種方案應對的業(yè)務場景是,系統(tǒng)正常運轉時,不會出現(xiàn)消息積壓問題。但是某一時刻,突然就開始積壓并且持續(xù)上漲。
這種問題還是比較糾結的,擴容的話,一般情況下是不需要的,不擴容的話某一刻又擋不住。。。。
遇到這樣的場景無需就是兩種原因,要不生產(chǎn)變快了,要不消費變慢了。我們可以通過監(jiān)控程序觀察一下數(shù)據(jù)情況再定位某種原因。
最后實在沒辦法可以將系統(tǒng)進行降級,通過關閉一些不重要的業(yè)務,減少生產(chǎn)方發(fā)送的數(shù)據(jù)量,最低限度的讓系統(tǒng)的熱賣業(yè)務還能正常運轉。
重復消費也會拖慢整個系統(tǒng)的消費速度。
關于重復消費可以參考?重復消費解決方案
如何入手學習源碼
最核心的一點就是查看?官方文檔
官方文檔是所有技術中 最權威,最齊全的一個資料聚集地
有些翻譯中文的網(wǎng)站,可能會做到更新不及時,所以還是建議直接看英文文檔,借助翻譯即可。也可以鍛煉英文水平
首先要?掌握這個技術的整體結構,有哪些功能特性,涉及到的關鍵技術、實現(xiàn)原理和生態(tài)系統(tǒng)?等等。掌握了這些,對它的整體有了一定了解,然后再去看它的源代碼,就會非常通暢了。比如我之前做的MySQL技術分享如下圖。
Redis的技術分享如下圖

RocketMQ的技術分享還沒畫,可以暫時參考一下官方
我覺得學習這個東西最好的老師是興趣。所以一定要帶著問題去讀源碼。比如
- RocketMQ的消息是怎么寫到文件中的?(肯定不會像我們業(yè)務程序那樣直接寫的)
- RocketMQ的重發(fā)機制是怎么實現(xiàn)的?
- RocketMQ的確認機制是怎么實現(xiàn)的?
- RocketMQ的分布式的實現(xiàn)源碼是怎么樣的?
- RocketMQ的消息不丟失是否和MySQL那樣有binlog,redo log,是否和Redis那樣有RDB,AOF呢?
上述問題反正是我當下最想知道的,但是不要操之過急,學懂整體后再深入。
一定不要直接從main里看,程序跟書是不一樣的,書是由人學懂之后,整理的一個先后學習順序。而程序是一個網(wǎng)狀結構,是一個功能一個功能的實現(xiàn)
這上述也是我接下來學習源碼的方法。源碼分析的話,我的想法是等我學完RocketMQ的基礎原理,我會從第一篇文章涉及到的知識點,進入源碼閱讀分析整理
MySQL,Redis就算了,打算發(fā)力MQ
異步方案提升系統(tǒng)性能
這里先簡單聊一下思想,后續(xù)會用代碼案例實現(xiàn)。
異步執(zhí)行
簡單的說,異步思想就是,當我們要執(zhí)行一項比較耗時的操作時,不去等待操作結束,而是給這個操作一個命令:“當操作完成后,接下來去執(zhí)行什么。”
使用異步編程模型,雖然并不能加快程序本身的速度,但可以減少或者避免線程等待,只用很少的線程就可以達到超高的吞吐能力。
同時我們也需要注意到異步模型的問題:相比于同步實現(xiàn),異步實現(xiàn)的復雜度要大很多,代 碼的可讀性和可維護性都會顯著的下降。雖然使用一些異步編程框架會在一定程度上簡化異 步開發(fā),但是并不能解決異步模型高復雜度的問題。
異步性能雖好,但一定不要濫用,只有類似在像消息隊列這種業(yè)務邏輯簡單并且需要超高吞 吐量的場景下,或者必須長時間等待資源的地方,才考慮使用異步模型。如果系統(tǒng)的業(yè)務邏 輯比較復雜,在性能足夠滿足業(yè)務需求的情況下,采用符合人類自然的思路且易于開發(fā)和維 護的同步模型是更加明智的選擇。
異步網(wǎng)絡
傳統(tǒng)的同步網(wǎng)絡 IO,一般采用的都是一個線程對應一個 Channel 接收數(shù)據(jù),很難支持高并 發(fā)和高吞吐量。這個時候,我們需要使用異步的網(wǎng)絡 IO 框架來解決問題。
Netty 和 NIO 是兩種異步網(wǎng)絡框架。
Netty 自動地解決了線程控制、緩存管理、連接管理這些問題,用戶只需要實現(xiàn)對應的 Handler 來處理收到的數(shù)據(jù)即可。
NIO 是更加底層的 API,它提供了 Selector 機制,用單個線程同時管理多個連接,解決了多路 復用這個異步網(wǎng)絡通信的核心問題。
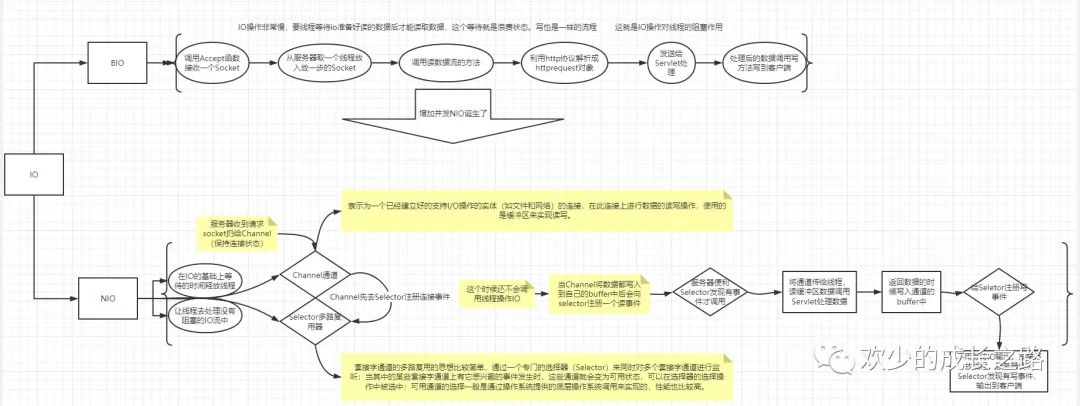
以上是 IO、BIO、NIO的發(fā)展,流程圖
緩存策略
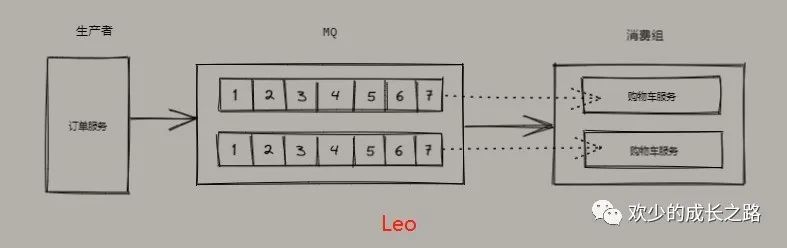
緩存策略的出現(xiàn),主要解決的就是如何減少與磁盤IO交互,提升系統(tǒng)性能。對于持久化來說,肯定還是要存磁盤的。所以我們必須保證最大的幾率命中緩存,同時也要減少與磁盤IO的交互。
一般來說 SSD 每秒鐘可以讀寫幾千次,如果說我們的程序在處理業(yè)務請求的時候直接來讀寫磁盤,假設處理每次請求需要讀寫 3~5 次,即使每次請求的數(shù)據(jù)量不大,你的程序最多每秒也就 能處理 1000 次左右的請求。而內(nèi)存的隨機讀寫速度是磁盤的 10 萬倍!所以,使用內(nèi)存作為緩存來加速應用程序的訪問速度,是幾乎所有高性能系統(tǒng)都會采用的方法。
只讀與讀寫緩存的抉擇
使用緩存,首先你就會面臨選擇讀緩存還是讀寫緩存的問題。他們唯一的區(qū)別就是,在更新數(shù)據(jù)的時候,是否經(jīng)過緩存
讀寫緩存:?它是一種犧牲數(shù)據(jù)一致性換取性能的設計,天然是不可靠的。
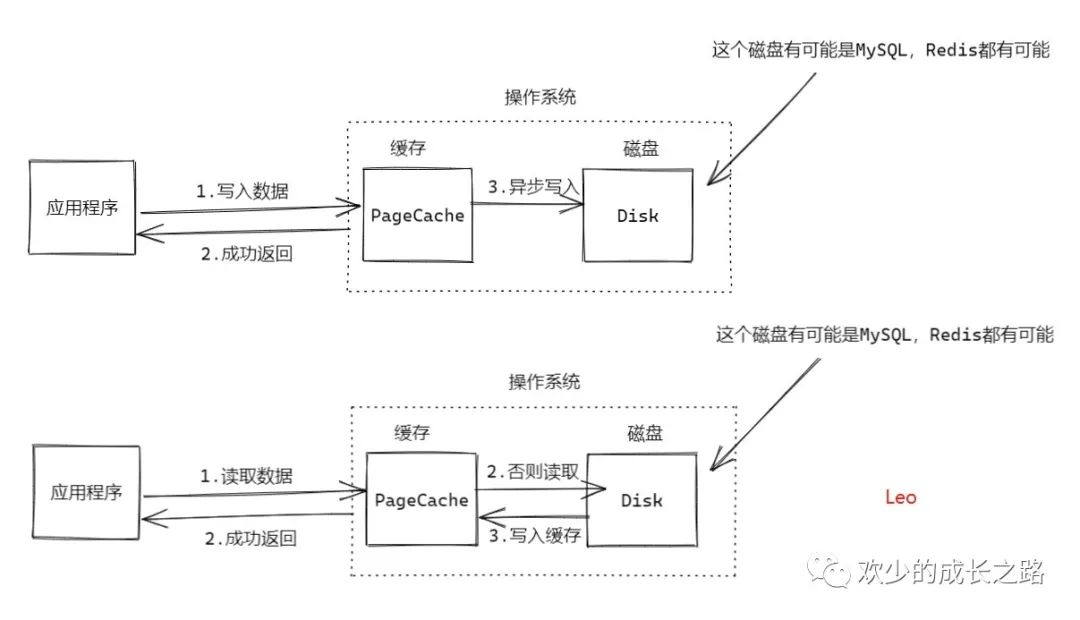
為什么說他是不可靠的呢?可以從上圖中看出,寫入數(shù)據(jù)到PageCache時,并不是同步寫入的,而是異步,如果在這段期間,還沒開始異步寫入時,服務器直接宕機了,就丟失了數(shù)據(jù)。
如果說我們?nèi)斯げ僮鳎瑘?zhí)行一次sync。這樣也就失去了緩存的意義
緩存的意義不就是減少與磁盤IO的交互嘛
寫緩存的實現(xiàn)是非常復雜的。應用程序不停地更新 PageCache 中的數(shù)據(jù),操作系統(tǒng) 需要記錄哪些數(shù)據(jù)有變化,同時還要在另外一個線程中,把緩存中變化的數(shù)據(jù)更新到磁盤文 件中。在提供并發(fā)讀寫的同時來異步更新數(shù)據(jù),這個過程中要保證數(shù)據(jù)的一致性,并且有非常好的性能,實現(xiàn)這些真不是一件容易的事兒。
所以一般?推薦使用只讀緩存。
如何保持緩存數(shù)據(jù)新鮮
上面提到了推薦使用只讀緩存,對于只讀緩存來說,緩存中的數(shù)據(jù)來源只有一個途徑,就是從磁盤上來。當數(shù)據(jù)需要更新的時候,磁盤中的數(shù)據(jù)和緩存中的副本都需要進行更新。我們知道在分布式系統(tǒng)中,除非是使用事務或者一些分布式一致性算法來保證數(shù)據(jù)一致性,否則,由于節(jié)點宕機、網(wǎng)絡傳輸故 障等情況的存在,我們是無法保證緩存中的數(shù)據(jù)和磁盤中的數(shù)據(jù)是完全一致的。
我們要做的就是盡可能最大的保證數(shù)據(jù)同步。最省心,代價最大的就是采用分布式事務來解決了。
另一種簡單的方式就是采用Redis那種過期key的方式實現(xiàn),數(shù)據(jù)過期以后即使它還存在緩存中,我們也認為它不再有效,需要從 磁盤上再次加載這條數(shù)據(jù),這樣就變相地實現(xiàn)了數(shù)據(jù)更新。
還是根據(jù)業(yè)務吧。比如微信頭像修改后的實時顯示,郵件的延遲幾秒鐘接收都可以采用過期key的方式
如果是那種交易類系統(tǒng),對數(shù)據(jù)一致性比較敏感的可以采用犧牲性能來決定一致性。
緩存的置換策略
在使用緩存的過程中,除了要考慮數(shù)據(jù)一致性的問題,你還需要關注的另一個重要的問題是,在內(nèi)存有限的情況下,要優(yōu)先緩存哪些數(shù)據(jù),讓緩存的命中率最高。
當應用程序要訪問某些數(shù)據(jù)的時候,如果這些數(shù)據(jù)在緩存中,那直接訪問緩存中的數(shù)據(jù)就可以了,這次訪問的速度是很快的,這種情況我們稱為一次緩存命中;如果這些數(shù)據(jù)不在緩存中,那只能去磁盤中訪問數(shù)據(jù),就會比較慢。這種情況我們稱為“緩存穿透”。顯然,緩存的命中率越高,應用程序的總體性能就越好。
那用什么樣的策略來選擇緩存的數(shù)據(jù),能使得緩存的命中率盡量高一些呢?
如果你的系統(tǒng)是那種可以預測未來訪問哪些數(shù)據(jù)的系統(tǒng),比如說,有的系統(tǒng)它會定期做數(shù)據(jù)同步,每次同步的數(shù)據(jù)范圍都是一樣的,像這樣的系統(tǒng),緩存策略很簡單,就是你要訪問什么數(shù)據(jù),就緩存什么數(shù)據(jù),甚至可以做到百分之百的命中。
但是,大部分系統(tǒng),它并沒有辦法準確地預測未來會有哪些數(shù)據(jù)會被訪問到,所以只能使用一些策略來盡可能地提高緩存命中率。
一般來說,我們都會在數(shù)據(jù)首次被訪問的時候,順便把這條數(shù)據(jù)放到緩存中。隨著訪問的數(shù)據(jù)越來越多,總有把緩存占滿的時刻,這個時候就需要把緩存中的一些數(shù)據(jù)刪除掉,以便存放新的數(shù)據(jù),這個過程稱為緩存置換。
到這里,問題就變成了:當緩存滿了的時候,刪除哪些數(shù)據(jù),才能會使緩存的命中率更高一 些,也就是采用什么置換策略的問題。
命中率最高的置換策略,一定是根據(jù)你的業(yè)務邏輯,定制化的策略。比如,你如果知道某些數(shù)據(jù)已經(jīng)刪除了,永遠不會再被訪問到,那優(yōu)先置換這些數(shù)據(jù)肯定是沒問題的。再比如,你的系統(tǒng)是一個有會話的系統(tǒng),你知道現(xiàn)在哪些用戶是在線的,哪些用戶已經(jīng)離線,那優(yōu)先置換那些已經(jīng)離線用戶的數(shù)據(jù),盡量保留在線用戶的數(shù)據(jù)也是一個非常好的策略。
另外一個選擇,就是?使用通用的置換算法。一個最經(jīng)典也是最實用的算法就是 LRU 算法, 也叫最近最少使用算法。這個算法它的思想是,最近剛剛被訪問的數(shù)據(jù),它在將來被訪問的 可能性也很大,而很久都沒被訪問過的數(shù)據(jù),未來再被訪問的幾率也不大。
基于這個思想,LRU 的算法原理非常簡單,它總是把最長時間未被訪問的數(shù)據(jù)置換出去。你別看這個 LRU 算法這么簡單,它的效果是非常非常好的。
可以參考Redis的的LRU文章,實現(xiàn)原理都是差不多的?LRU算法的實現(xiàn)
充電分享
少年有夢,不應止于心動,更應付出行動,用自己的關,照亮自己的路,努力追上那個曾經(jīng)被賦予厚望的自己
—— 致自己,致各位追夢的你們

結尾
有些不懂的地方或者不對的地方,麻煩各位指出,一定修改優(yōu)化!
非常歡迎大家加我個人微信有關后端方面的問題我們在群內(nèi)一起討論!?我們下l,。;期再見!
長按上方掃碼二維碼,加我微信,拉你進群
