
實戰(zhàn):Python 輕松實現(xiàn)自動化谷歌翻譯!
背景
這個功能是在工作時,上級有個需求是讓我將json文件中指定字段的英文翻譯成中文,并且指定要使用谷歌翻譯,理由是翻譯的結果可能會比較準確。
過程
因為之前寫過用python實現(xiàn)有道翻譯,是在ajax中找到它的翻譯接口的,所以我以為谷歌應該也差不多,于是我就打開 “開發(fā)者工具”,拼命地尋找它的翻譯接口,果然讓我發(fā)現(xiàn)了,哈哈哈哈~~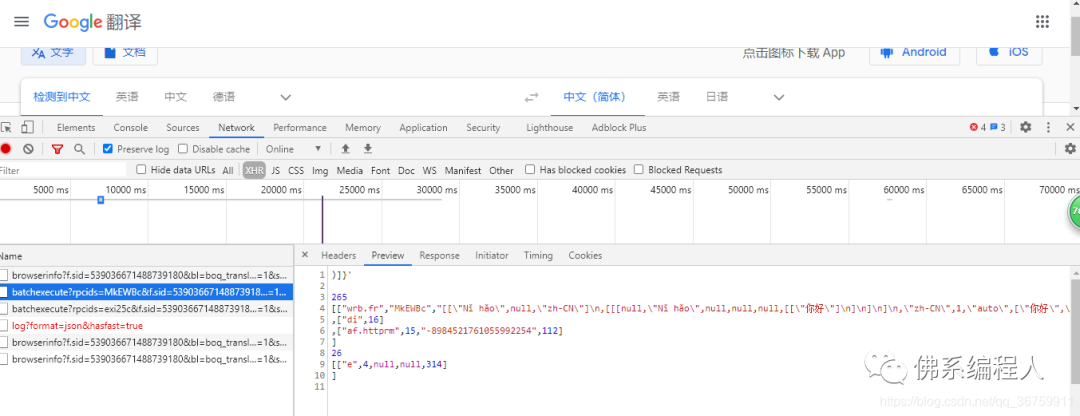
然而我發(fā)現(xiàn)我高興地太早了,這TMD是個啥東西,為啥不是json啊,崩潰!!!
算了,你牛,我放棄~
于是我就面向度娘,尋求幫助,搜索關鍵詞 “python實現(xiàn)谷歌翻譯”,哦吼~ 結果還挺多
哈哈又草率了(欲哭無淚),隨緣選中一個后,大致看了一下(好復雜555~),它們的思路大致是用PyExecJS庫模擬js代碼獲取結果,我才不管這些,能用就行,然后一頓ctrl c/ctrl v 代碼到本地后,修改一些數(shù)據(jù),開始運行。
接下來就一頓報錯,我就一頓臥槽。好的,沒安裝庫…安裝不成功,和一些莫名的其他原因。這能忍?于是我決定自己動手,豐衣足食,大不了就爬網(wǎng)頁嘛,然后打開網(wǎng)頁源代碼,MD又草率了,并沒有需要的內(nèi)容,忘記結果是用js生成的,唉,怎么辦?只好從最開始的那個ajax的接口下手了
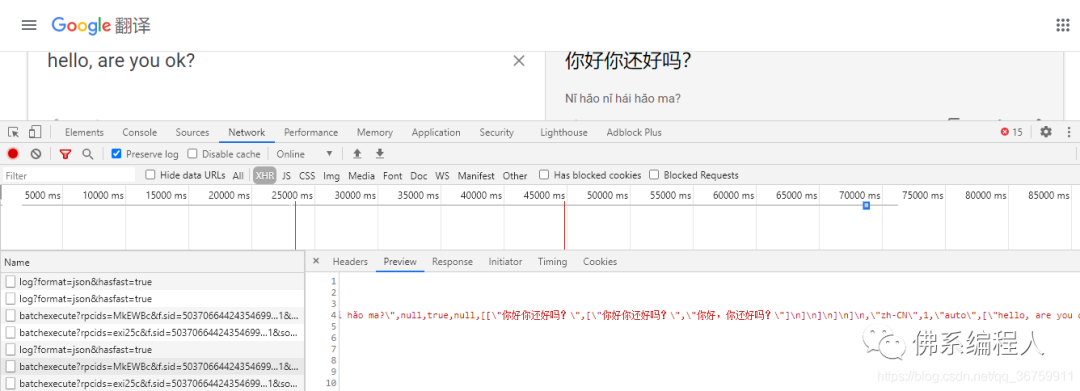
內(nèi)容里有很多重復的內(nèi)容并且感覺毫無規(guī)則…我硬著頭皮嘗試用正則把內(nèi)容提取出來,代碼我就不貼,因為…
我花了好長好長時間,瘋狂改正則表達式…啊哈!的確可以得出結果,超開心的~ 但是后面翻譯的過程發(fā)現(xiàn),這只適合翻譯一句話,多一點都不行,它會漏掉…頭又炸了!!!
我又放棄了,已經(jīng)束手無策了…第二天,看到一篇文章,里面寫的是 “ 字符串轉(zhuǎn)為列表”的知識點,然后我靈光一現(xiàn),想到了用正則和列表相結合,將內(nèi)容提取出來,于是我看到了奧特曼(光)哈哈哈,這次真的可以!!!!不說了上代碼
代碼

import requestsimport jsonimport reimport timedef googleTranslate(text):"""用谷歌翻譯內(nèi)容,返回翻譯結果params: text 翻譯的內(nèi)容return: str s 翻譯結果"""url = 'https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute?rpcids=MkEWBc&f.sid=-2984828793698248690&bl=boq_translate-webserver_20201221.17_p0&hl=zh-CN&soc-app=1&soc-platform=1&soc-device=1&_reqid=5445720&rt=c'headers = {'origin': 'https://translate.google.cn','referer': 'https://translate.google.cn/','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36','x-client-data': 'CIW2yQEIpbbJAQjEtskBCKmdygEIrMfKAQj2x8oBCPfHygEItMvKAQihz8oBCNzVygEIi5nLAQjBnMsB','Decoded':'message ClientVariations {repeated int32 variation_id = [3300101, 3300133, 3300164, 3313321, 3318700, 3318774, 3318775, 3319220, 3319713, 3320540, 3329163, 3329601];}','x-same-domain': '1'} # 以防萬一,我全加上了,可能有些不寫也可以data = {'f.req': f'[[["MkEWBc","[[\\"{text}\\",\\"auto\\",\\"zh-CN\\",true],[null]]",null,"generic"]]]'} # text則是你要翻譯的內(nèi)容res = requests.post(url, headers=headers, data=data).text # 獲取返回的結果pattern = '\)\]\}\'\s*\d{3,4}\s*\[(.*)\s*' # 提取需要的部分part1 = re.findall(pattern, res)part1_list = json.loads(part1[0]) # 字符串轉(zhuǎn)列表if part1_list[2] is None: # 如果返回的結果中沒有需要的數(shù)據(jù),則返回輸入的內(nèi)容print(text)return textcontent1 = part1_list[2].replace('\n', '')part2_list = json.loads(content1)[1][0][0][5:][0] # 過濾結果中重復的部分s = ''for i in part2_list: # 遍歷結果中的每一句話,并進行拼接s += i[0]print(s)return stext = 'friend. Let us look back on 2020 and look forward to 2021.'print(text)googleTranslate(text)
效果
效果如何?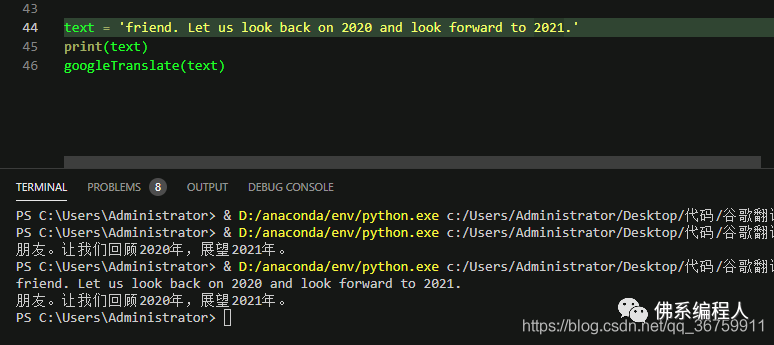
如何翻譯成其他語言?
當然,這僅僅是實現(xiàn)了任何語言轉(zhuǎn)為中文,要轉(zhuǎn)為別的語言,你可以通過執(zhí)行js,獲取所有語言對應的英文字母,以字典的形式存儲,最后保存為json文件
然后執(zhí)行程序時,動態(tài)地輸入翻譯后的語言,去json文件中獲取對應的英文代表,然后替換data中的"zh-CN"即可。比如我想翻譯成日語,我就將“zh-CN”替換成 “ja”,這樣,翻譯出來的結果就是日語了
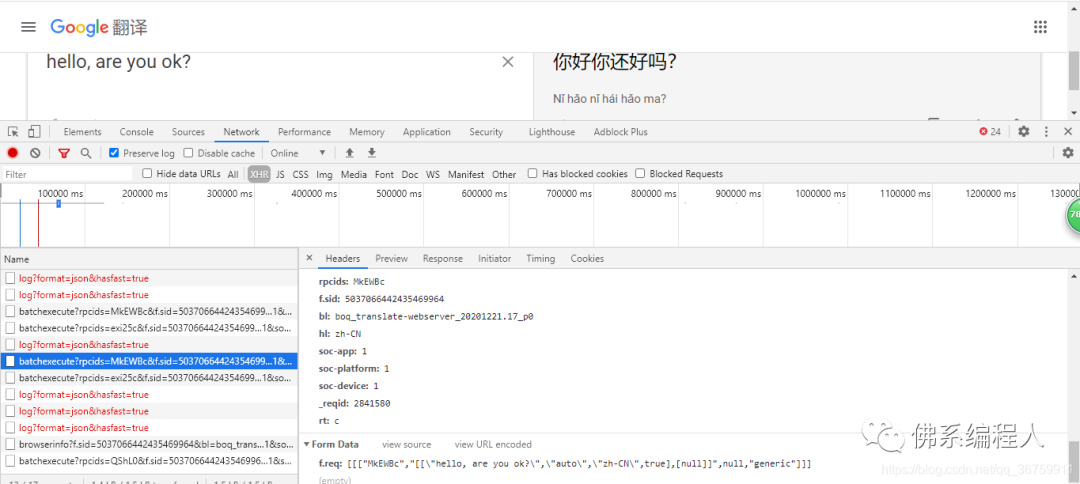
修改data數(shù)據(jù)

翻譯結果
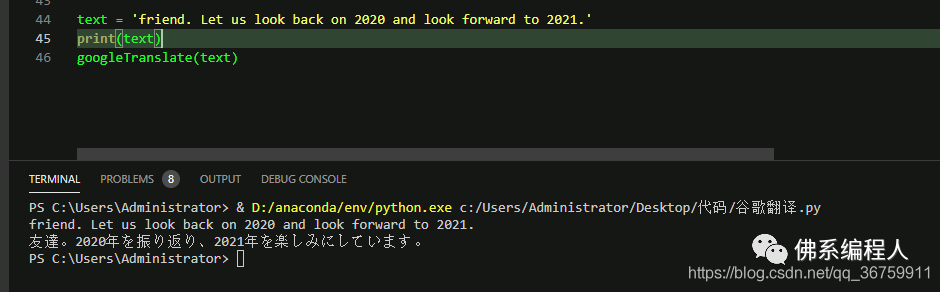
好了,今天的分享就到這了,奧里給~

各位伙伴們好,詹帥本帥搭建了一個個人博客和小程序,匯集各種干貨和資源,也方便大家閱讀,感興趣的小伙伴請移步小程序體驗一下哦!(歡迎提建議)
推薦閱讀
牛逼!Python常用數(shù)據(jù)類型的基本操作(長文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達式(長文系列第②篇)
推薦閱讀
牛逼!Python常用數(shù)據(jù)類型的基本操作(長文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達式(長文系列第②篇)