點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
來自 | 知乎? 作者 |?yanwan
鏈接 |?https://zhuanlan.zhihu.com/p/150332784
本文僅作學術(shù)交流,如有侵權(quán),請后臺聯(lián)系刪除
也許你正在學習計算機視覺的路上,并且已經(jīng)深入研究了圖像分類和滑動窗口檢測器。在掌握了這些概念之后,了解最新技術(shù)(SOTA)目標檢測,往往會變得令人望而生畏和晦澀難懂,尤其是在理解Anchor時。毋庸諱言,深入大量流行的YOLO、SSD、R-CNN、Fast RCNN、Faster RCNN、Mask RCNN和RetinaNet,了解Anchor是一項艱巨的工作,尤其是在您對實際代碼了解有限時。如果我告訴你,你可以利用今天深入學習目標檢測背后的Anchor呢?本文目標是幫助讀者梳理Anchor的以下內(nèi)容:- Where:如何以及在何處對圖像生成anchor以用于目標檢測訓練?
- How:如何在訓練過程中修正選定的anchor以實現(xiàn)訓練對象檢測模型?
anchor是指預(yù)定義的框集合,其寬度和高度與數(shù)據(jù)集中對象的寬度和高度相匹配。預(yù)置的anchor包含在數(shù)據(jù)集中存在的對象大小的組合,這自然包括數(shù)據(jù)中存在的不同長寬比和比例。通常在圖像中的每一個位置預(yù)置4-10個anchor。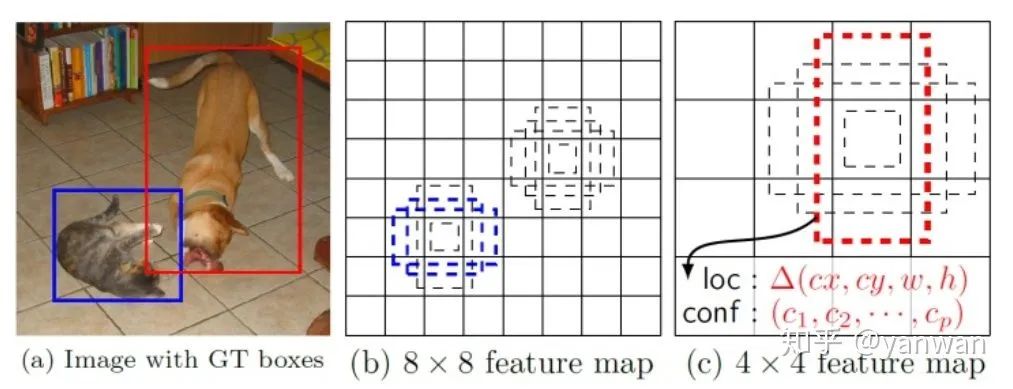 訓練目標檢測網(wǎng)絡(luò)的典型任務(wù)包括:生成anchor,搜索潛在anchor,將生成的anchor與可能的ground truth配對,將其余anchor分配給背景類別,然后進行sampling和訓練。而推理過程就是對anchor的分類和回歸,score大于閾值的anchor進一步做回歸,小于閾值的作為背景舍棄,這樣就得到了目標檢測的結(jié)果。
訓練目標檢測網(wǎng)絡(luò)的典型任務(wù)包括:生成anchor,搜索潛在anchor,將生成的anchor與可能的ground truth配對,將其余anchor分配給背景類別,然后進行sampling和訓練。而推理過程就是對anchor的分類和回歸,score大于閾值的anchor進一步做回歸,小于閾值的作為背景舍棄,這樣就得到了目標檢測的結(jié)果。
?2、Where:如何以及在何處對圖像生成anchor,以用于目標檢測訓練
本質(zhì)上,生成anchor是為了確定一組合適的框,這些框可以適合數(shù)據(jù)中的大多數(shù)對象,將假設(shè)的、均勻分布的框放置在圖像上,并創(chuàng)建一個規(guī)則,將卷積特征映射的輸出映射到圖像中的每個位置。為了理解錨定框是如何被生成的,假設(shè)有一個包含小目標的256px x* 256px圖像,其中大多數(shù)目標尺度位于40px * 40px或80px * x 40px之間。下面從兩個方面考量anchor:a、aspect ratios(橫縱比):因為假設(shè)的ground turth寬高比在1:1和2:1之間。因此,應(yīng)至少考慮兩個縱橫比(1:1和2:1),用來生成此示例數(shù)據(jù)集的anchor。b、scales?(尺度):指對象的長度或?qū)挾日计浒瑘D像的總長度或?qū)挾鹊谋壤?/span>例如,假設(shè)一個圖像的寬度=256px=1個單位,那么一個40px寬的對象占據(jù)40px/256px=0.15625個單位的寬度,即這個對象占據(jù)整個圖像寬度的15.62%。為了選擇一組最能代表數(shù)據(jù)的尺度,我們可以考慮具有最極端值的對象側(cè)度量,即數(shù)據(jù)集中所有對象的所有寬度和高度之間的最小值和最大值。如果我們的示例數(shù)據(jù)集中最大和最小的比例是0.15625和0.3125,并且我們要為anchor選擇三個比例,那么三個潛在的比例可能是0.15625、0.3125和0.234375(前面兩個尺度的均值)。如果使用上面提到的兩個縱橫比(1:1和2:1)和這三個比例(0.15625、0.234375和0.3125)來建議此示例數(shù)據(jù)集的錨定框,那么我們將總共有六個錨定框來建議輸入圖像中的任何一個位置。目標檢測器采用這樣的規(guī)則來生成anchor,假設(shè)檢測器網(wǎng)絡(luò)輸入的特征圖是4-channel 8*8,然后可以在每個單元格中心上生成6個不同aspect ratios和scales的anchor,那么總共384個,這樣就盡可能的涵蓋所有可能性。?? 3、When:什么時候在圖像上生成anchor?
檢測器不預(yù)測anchor,而是為每個anchor預(yù)測一組值:a、anchor坐標偏移(offset),b、每個類別的置信度得分。這意味著在每次圖像推理過程中都將始終使用相同的anchor,并且將使用網(wǎng)絡(luò)預(yù)測的偏移(offset)來更正該anchor。知道了這一點,就很容易理解ancor需要初始化,并將此數(shù)據(jù)結(jié)構(gòu)存儲在內(nèi)存中,以供實際使用時,如:在訓練中與ground ruth匹配,在推斷時將預(yù)測的偏移量應(yīng)用于anchor。在這些點上,anchor的實際生成其實都已經(jīng)生成了。理論上,如果CNN接收同一類型的物體兩次,那么不管CNN在圖像中的哪個位置接收到物體,CNN都應(yīng)該輸出大致相同的值兩次。這意味著,如果一幅圖像包含兩輛車,而輸出結(jié)果是絕對坐標,那么網(wǎng)絡(luò)將預(yù)測兩輛車大致相同的坐標。而學習anchor偏移,允許這兩輛車具有相似偏移輸出,但偏移應(yīng)用于錨定,錨定可映射到輸入圖像中的不同位置。這是在anchor回歸過程中學習錨定盒偏移的主要原因。
?? 5、How:如何在訓練過程中修正選定的anchor以實現(xiàn)訓練對象檢測模型?
(1)回歸任務(wù):訓練過程中,網(wǎng)絡(luò)回歸任務(wù)學習的target并不是feature map上每個位置的所有anchor的offset,而是與ground truth匹配的anchor的實際偏移,背景框的anchor偏移保持為零。這意味著,一旦anchor內(nèi)的像素空間被完全視為背景,則anchor不需要調(diào)整坐標。換言之,由于分配給背景類別的anchor根本不應(yīng)該移動或更正,因此沒有要預(yù)測的偏移量。(2)分類任務(wù):分類損失通常是使用在總背景框的子集來處理類不平衡。還記得在我們的示例中,每個位置有6個框,總共有384個建議嗎?好吧,大多數(shù)都是背景框,這就造成了一個嚴重的階級不平衡。 解決這類不平衡問題的一個流行的解決方案是所謂的 hard negative mining ——根據(jù)預(yù)先確定的比率(通常為1:3;foreground:background)選擇一些高權(quán)重背景框。在分類損失中處理類不平衡的另一個流行方法是降低易分類實例的權(quán)重損失貢獻,這就是RetinaNet的focal loss情況。(3)推理過程:為了獲得最終的一組目標檢測,網(wǎng)絡(luò)的預(yù)測偏移量被應(yīng)用到相應(yīng)的anchor中,可能會有成百上千個候選框,但最終,測器會忽略所有被預(yù)測為背景的盒子,保留通過某些標準的前景檢測結(jié)果,并應(yīng)用NMS糾正同一對象的重疊預(yù)測。
解決這類不平衡問題的一個流行的解決方案是所謂的 hard negative mining ——根據(jù)預(yù)先確定的比率(通常為1:3;foreground:background)選擇一些高權(quán)重背景框。在分類損失中處理類不平衡的另一個流行方法是降低易分類實例的權(quán)重損失貢獻,這就是RetinaNet的focal loss情況。(3)推理過程:為了獲得最終的一組目標檢測,網(wǎng)絡(luò)的預(yù)測偏移量被應(yīng)用到相應(yīng)的anchor中,可能會有成百上千個候選框,但最終,測器會忽略所有被預(yù)測為背景的盒子,保留通過某些標準的前景檢測結(jié)果,并應(yīng)用NMS糾正同一對象的重疊預(yù)測。小白團隊出品:零基礎(chǔ)精通語義分割↓↓↓

下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。下載2:Python視覺實戰(zhàn)項目52講在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~


