
面試官:說說kafka、activemq、rabbitmq、rocketmq都有什么優(yōu)缺點(diǎn)和使用場景
為什么使用消息隊(duì)列?消息隊(duì)列的優(yōu)點(diǎn)和缺點(diǎn)?kafka、activemq、rabbitmq、rocketmq都有什么優(yōu)缺點(diǎn)?
面試官角度分析:
(1)你知不知道你們系統(tǒng)里為什么要用消息隊(duì)列這個(gè)東西?
(2)既然用了消息隊(duì)列這個(gè)東西,你知不知道用了有什么好處?
(3)既然你用了MQ,那么當(dāng)時(shí)為什么選用這一款MQ?
1. 為什么使用消息隊(duì)列?
面試官問這個(gè)問題的期望之一的回答是,你們公司有什么業(yè)務(wù)場景,這個(gè)業(yè)務(wù)場景有什么技術(shù)挑戰(zhàn),如果不用MQ可能會(huì)很麻煩,但是再用了之后帶來了很多好處。
消息隊(duì)列的常見使用場景有很多但是核心的有三個(gè):解耦、異步、削峰
解耦
場景描述:A系統(tǒng)發(fā)送個(gè)數(shù)據(jù)到BCD三個(gè)系統(tǒng),接口調(diào)用發(fā)送,那如果E系統(tǒng)也要這個(gè)數(shù)據(jù)呢?那如果C系統(tǒng)現(xiàn)在不需要了呢?現(xiàn)在A系統(tǒng)又要發(fā)送第二種數(shù)據(jù)了呢?A系統(tǒng)負(fù)責(zé)人崩潰中...再來點(diǎn)崩潰的事兒,A系統(tǒng)要時(shí)時(shí)刻刻考慮BCDE四個(gè)系統(tǒng)如果掛了怎么辦?那我要不要重發(fā)?我要不要把消息存起來?頭發(fā)都白了啊...

使用了MQ之后的解耦場景
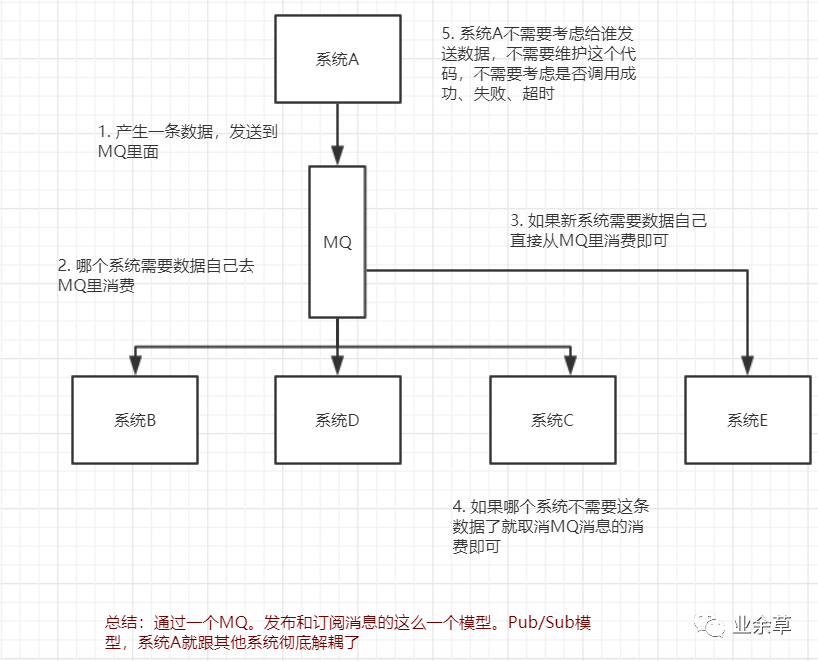
面試技巧:你需要考慮下,你負(fù)責(zé)的系統(tǒng)中是否有類似的場景,就是一個(gè)系統(tǒng)或者一個(gè)模塊,調(diào)用了多個(gè)系統(tǒng)或者模塊,相互之間的調(diào)用很復(fù)雜,維護(hù)起來很麻煩。但是其實(shí)這個(gè)調(diào)用是不需要直接同步調(diào)用接口的,如果MQ給他異步化解耦也是可以的,你就需要去考慮在你的項(xiàng)目里是不是可以運(yùn)用這個(gè)MQ去進(jìn)行系統(tǒng)解耦 。
異步
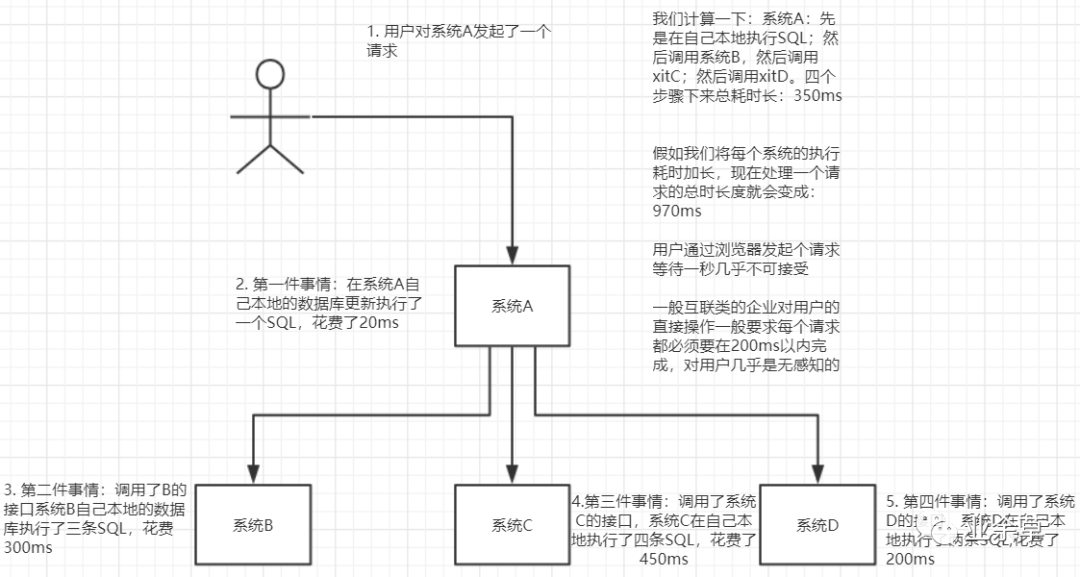
場景描述:系統(tǒng)A接受一個(gè)請(qǐng)求,需要在自己本地寫庫,還需要在系統(tǒng)BCD三個(gè)系統(tǒng)寫庫,自己本地寫庫需要3ms。BCD分別需要300ms、450ms、200ms。最終總好時(shí)長:953ms,接近1s。給用戶的體驗(yàn)感覺一點(diǎn)也不好。
不用MQ的同步高延時(shí)請(qǐng)求場景
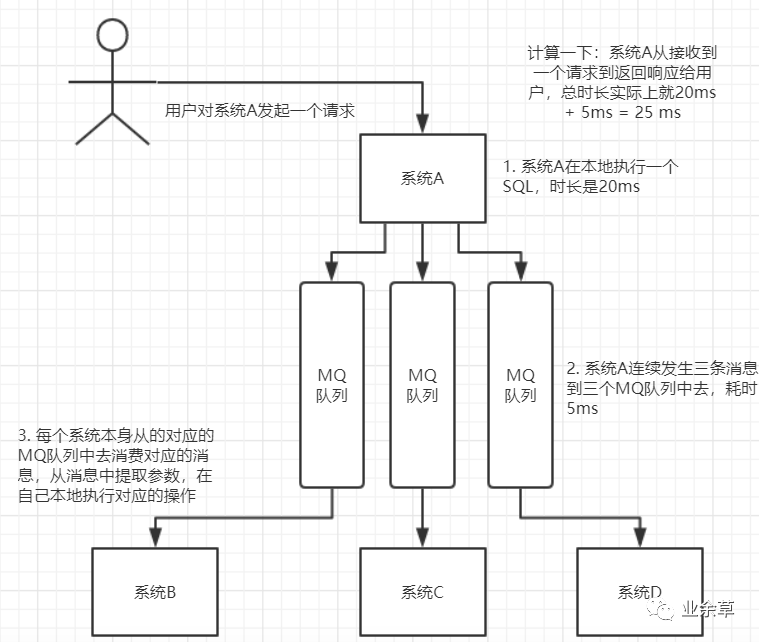
使用MQ異步化之后的接口性能優(yōu)化
削峰
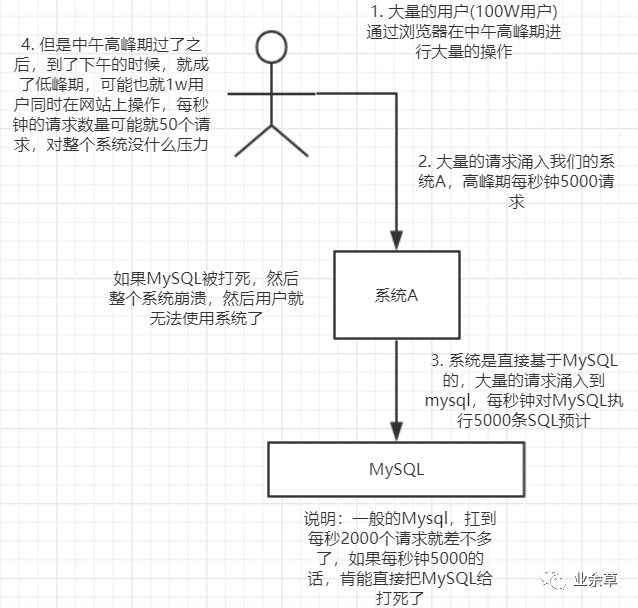
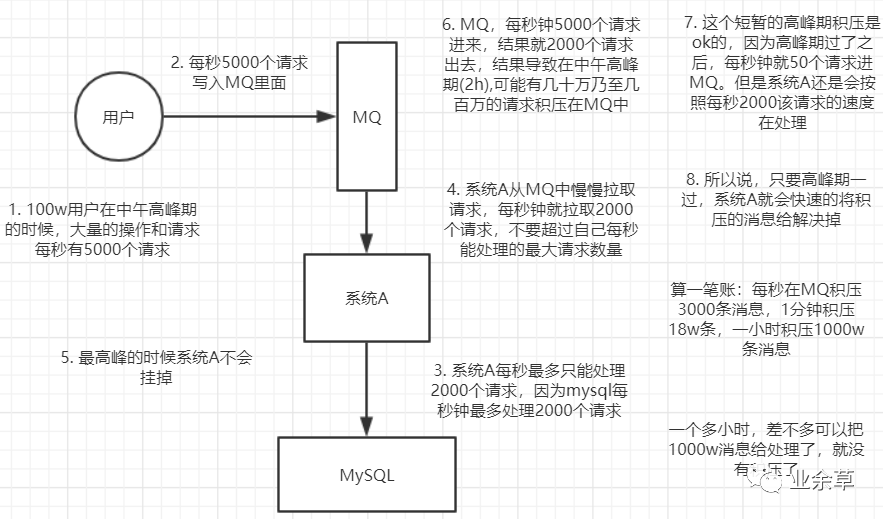
場景描述:每天 0 點(diǎn)到 11 點(diǎn),系統(tǒng)A風(fēng)平浪靜,每秒并發(fā)請(qǐng)求數(shù)量就 100 個(gè)。結(jié)果每一一到11點(diǎn)到1點(diǎn),每秒并發(fā)請(qǐng)求數(shù)量就會(huì)暴增大1萬條 。但是系統(tǒng)最大的處理能力就只能每秒鐘處理1000個(gè)請(qǐng)求。
沒有用MQ的時(shí)候高峰期系統(tǒng)被打死的場景
使用MQ來進(jìn)行削峰的場景
2. 消息隊(duì)列的有點(diǎn)和缺點(diǎn)?
優(yōu)點(diǎn):特殊場景下解耦、異步、削峰。
缺點(diǎn):
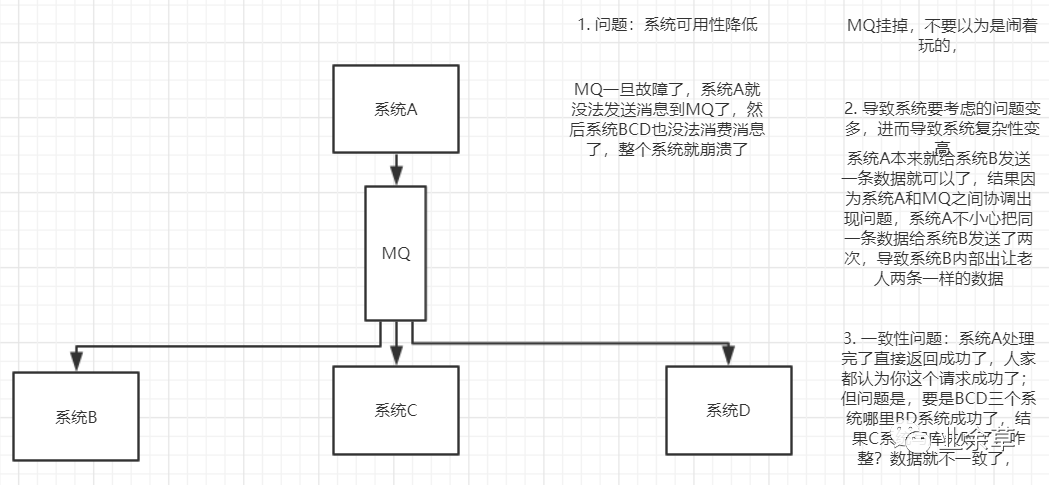
系統(tǒng)可用性降低:系統(tǒng)引入的外部依賴越多,越容易掛掉,本來你就是A系統(tǒng)調(diào)用BCD三個(gè)系統(tǒng)的接口就好了,人ABCD四個(gè)系統(tǒng)好好的沒什么問題,你偏加個(gè)MQ進(jìn)來,萬一MQ掛了怎么辦,整套系統(tǒng)崩潰了,就完蛋了
系統(tǒng)復(fù)雜性提高:硬生生加個(gè)MQ進(jìn)來,你怎么保證消息沒有重復(fù)消費(fèi)?怎么處理消息丟失的情況?怎么保證消息傳遞的順序性?
一致性問題:系統(tǒng)A處理完了直接返回成功了,人家都認(rèn)為你這個(gè)請(qǐng)求成功了;但問題是,要是BCD三個(gè)系統(tǒng)哪里BD系統(tǒng)成功了,結(jié)果C系統(tǒng)寫庫失敗了,咋整?數(shù)據(jù)就不一致了,
所以消息隊(duì)列是一種非常復(fù)雜的架構(gòu),引入它有很多好處,但是也得針對(duì)他帶來的壞處做各種額外的技術(shù)方案和架構(gòu)來規(guī)避掉。做好之后你會(huì)發(fā)現(xiàn)系統(tǒng)復(fù)雜度提升了一個(gè)數(shù)量積,但是關(guān)鍵時(shí)刻,用,還是要用的。
3. kafka、activemq、rabbitmq、rocketmq都有什么優(yōu)缺點(diǎn)?
1. 引入消息隊(duì)列之后如何保證其高可用性?
(1)RabbitMQ的高可用性
RabbitMQ是比較有代表性的,因?yàn)槭腔谥鲝淖龈呖捎眯缘模覀兙鸵运麨槔又v解第一種MQ的高可用性怎么實(shí)現(xiàn)。
rabbitmq有三種模式:單機(jī)模式,普通集群模式,鏡像集群模式
(1.1) 單機(jī)模式
就是demo級(jí)別的,一般就是你本地啟動(dòng)了玩玩兒的,沒人生產(chǎn)用單機(jī)模式
(1.2)普通集群模式
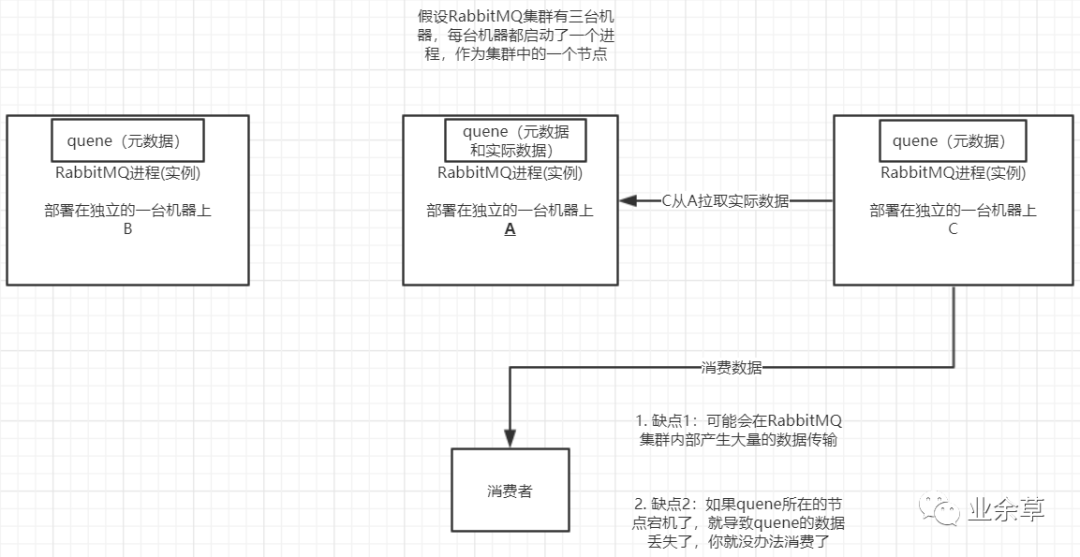
意思就是在多臺(tái)機(jī)器上啟動(dòng)多個(gè)rabbitmq實(shí)例,每個(gè)機(jī)器啟動(dòng)一個(gè)。但是你創(chuàng)建的queue,只會(huì)放在一個(gè)rabbtimq實(shí)例上,但是每個(gè)實(shí)例都同步queue的元數(shù)據(jù)。完了你消費(fèi)的時(shí)候,實(shí)際上如果連接到了另外一個(gè)實(shí)例,那么那個(gè)實(shí)例會(huì)從queue所在實(shí)例上拉取數(shù)據(jù)過來。
這種方式確實(shí)很麻煩,也不怎么好,沒做到所謂的分布式,就是個(gè)普通集群。因?yàn)檫@導(dǎo)致你要么消費(fèi)者每次隨機(jī)連接一個(gè)實(shí)例然后拉取數(shù)據(jù),要么固定連接那個(gè)queue所在實(shí)例消費(fèi)數(shù)據(jù),前者有數(shù)據(jù)拉取的開銷,后者導(dǎo)致單實(shí)例性能瓶頸。
而且如果那個(gè)放queue的實(shí)例宕機(jī)了,會(huì)導(dǎo)致接下來其他實(shí)例就無法從那個(gè)實(shí)例拉取,如果你開啟了消息持久化,讓rabbitmq落地存儲(chǔ)消息的話,消息不一定會(huì)丟,得等這個(gè)實(shí)例恢復(fù)了,然后才可以繼續(xù)從這個(gè)queue拉取數(shù)據(jù)。
所以這個(gè)事兒就比較尷尬了,這就沒有什么所謂的高可用性可言了,這方案主要是提高吞吐量的,就是說讓集群中多個(gè)節(jié)點(diǎn)來服務(wù)某個(gè)queue的讀寫操作。
(1.3)鏡像集群模式
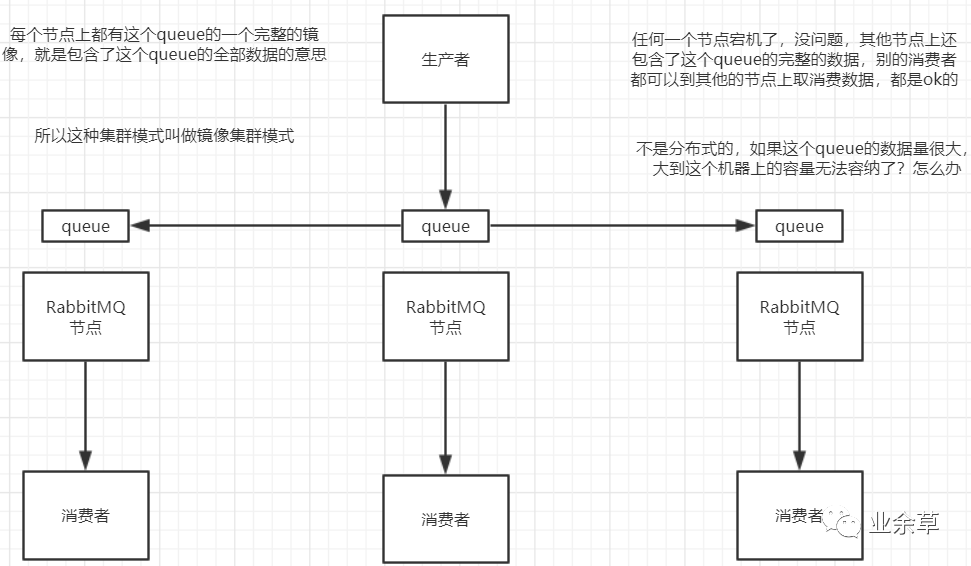
這種模式,才是所謂的rabbitmq的高可用模式,跟普通集群模式不一樣的是,你創(chuàng)建的queue,無論元數(shù)據(jù)還是queue里的消息都會(huì)存在于多個(gè)實(shí)例上,然后每次你寫消息到queue的時(shí)候,都會(huì)自動(dòng)把消息到多個(gè)實(shí)例的queue里進(jìn)行消息同步。
這樣的話,好處在于,你任何一個(gè)機(jī)器宕機(jī)了,沒事兒,別的機(jī)器都可以用。壞處在于,第一,這個(gè)性能開銷也太大了吧,消息同步所有機(jī)器,導(dǎo)致網(wǎng)絡(luò)帶寬壓力和消耗很重!第二,這么玩兒,就沒有擴(kuò)展性可言了,如果某個(gè)queue負(fù)載很重,你加機(jī)器,新增的機(jī)器也包含了這個(gè)queue的所有數(shù)據(jù),并沒有辦法線性擴(kuò)展你的queue
那么怎么開啟這個(gè)鏡像集群模式呢?我這里簡單說一下,避免面試人家問你你不知道,其實(shí)很簡單rabbitmq有很好的管理控制臺(tái),就是在后臺(tái)新增一個(gè)策略,這個(gè)策略是鏡像集群模式的策略,指定的時(shí)候可以要求數(shù)據(jù)同步到所有節(jié)點(diǎn)的,也可以要求就同步到指定數(shù)量的節(jié)點(diǎn),然后你再次創(chuàng)建queue的時(shí)候,應(yīng)用這個(gè)策略,就會(huì)自動(dòng)將數(shù)據(jù)同步到其他的節(jié)點(diǎn)上去了。
(2)kafka的高可用性
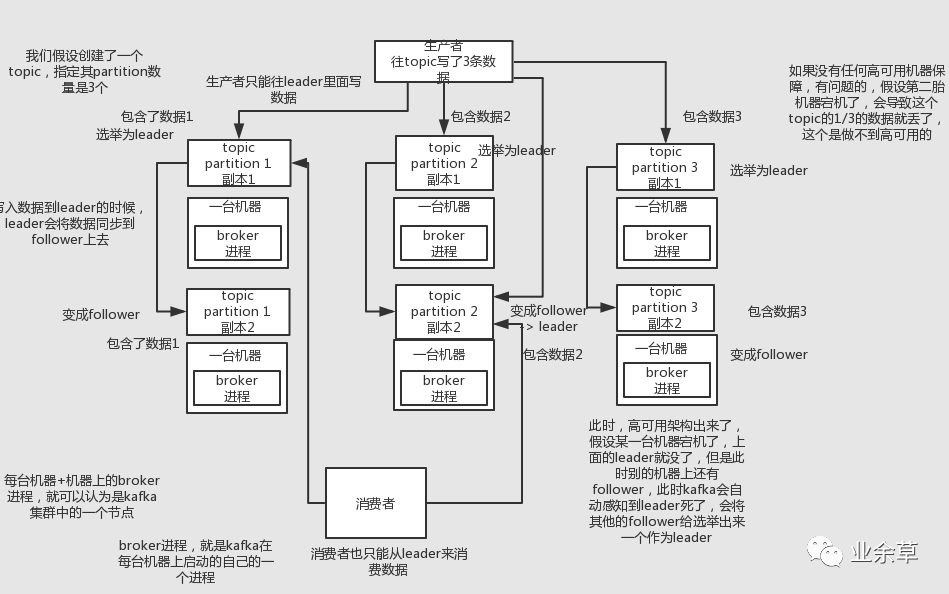
kafka一個(gè)最基本的架構(gòu)認(rèn)識(shí):多個(gè)broker組成,每個(gè)broker是一個(gè)節(jié)點(diǎn);你創(chuàng)建一個(gè)topic,這個(gè)topic可以劃分為多個(gè)partition,每個(gè)partition可以存在于不同的broker上,每個(gè)partition就放一部分?jǐn)?shù)據(jù)。
這就是天然的分布式消息隊(duì)列,就是說一個(gè)topic的數(shù)據(jù),是分散放在多個(gè)機(jī)器上的,每個(gè)機(jī)器就放一部分?jǐn)?shù)據(jù)。
實(shí)際上rabbitmq之類的,并不是分布式消息隊(duì)列,他就是傳統(tǒng)的消息隊(duì)列,只不過提供了一些集群、HA的機(jī)制而已,因?yàn)闊o論怎么玩兒,rabbitmq一個(gè)queue的數(shù)據(jù)都是放在一個(gè)節(jié)點(diǎn)里的,鏡像集群下,也是每個(gè)節(jié)點(diǎn)都放這個(gè)queue的完整數(shù)據(jù)。
kafka 0.8以前,是沒有HA機(jī)制的,就是任何一個(gè)broker宕機(jī)了,那個(gè)broker上的partition就廢了,沒法寫也沒法讀,沒有什么高可用性可言。
kafka 0.8以后,提供了HA機(jī)制,就是replica副本機(jī)制。每個(gè)partition的數(shù)據(jù)都會(huì)同步到吉他機(jī)器上,形成自己的多個(gè)replica副本。然后所有replica會(huì)選舉一個(gè)leader出來,那么生產(chǎn)和消費(fèi)都跟這個(gè)leader打交道,然后其他replica就是follower。寫的時(shí)候,leader會(huì)負(fù)責(zé)把數(shù)據(jù)同步到所有follower上去,讀的時(shí)候就直接讀leader上數(shù)據(jù)即可。只能讀寫leader?很簡單,要是你可以隨意讀寫每個(gè)follower,那么就要care數(shù)據(jù)一致性的問題,系統(tǒng)復(fù)雜度太高,很容易出問題。kafka會(huì)均勻的將一個(gè)partition的所有replica分布在不同的機(jī)器上,這樣才可以提高容錯(cuò)性。
這么搞,就有所謂的高可用性了,因?yàn)槿绻硞€(gè)broker宕機(jī)了,沒事兒,那個(gè)broker上面的partition在其他機(jī)器上都有副本的,如果這上面有某個(gè)partition的leader,那么此時(shí)會(huì)重新選舉一個(gè)新的leader出來,大家繼續(xù)讀寫那個(gè)新的leader即可。這就有所謂的高可用性了。
寫數(shù)據(jù)的時(shí)候,生產(chǎn)者就寫leader,然后leader將數(shù)據(jù)落地寫本地磁盤,接著其他follower自己主動(dòng)從leader來pull數(shù)據(jù)。一旦所有follower同步好數(shù)據(jù)了,就會(huì)發(fā)送ack給leader,leader收到所有follower的ack之后,就會(huì)返回寫成功的消息給生產(chǎn)者。(當(dāng)然,這只是其中一種模式,還可以適當(dāng)調(diào)整這個(gè)行為)
消費(fèi)的時(shí)候,只會(huì)從leader去讀,但是只有一個(gè)消息已經(jīng)被所有follower都同步成功返回ack的時(shí)候,這個(gè)消息才會(huì)被消費(fèi)者讀到。
實(shí)際上這塊機(jī)制,講深了,是可以非常之深入的,但是我還是回到我們這個(gè)課程的主題和定位,聚焦面試,至少你聽到這里大致明白了kafka是如何保證高可用機(jī)制的了,對(duì)吧?不至于一無所知,現(xiàn)場還能給面試官畫畫圖。要遇上面試官確實(shí)是kafka高手,深挖了問,那你只能說不好意思,太深入的你沒研究過。
但是大家一定要明白,這個(gè)事情是要權(quán)衡的,你現(xiàn)在是要快速突擊常見面試題體系,而不是要深入學(xué)習(xí)kafka,要深入學(xué)習(xí)kafka,你是沒那么多時(shí)間的。你只能確保,你之前也許壓根兒不知道這塊,但是現(xiàn)在你知道了,面試被問到,你大概可以說一說。然后很多其他的候選人,也許還不如你,沒看過這個(gè),被問到了壓根兒答不出來,相比之下,你還能說點(diǎn)出來,大概就是這個(gè)意思了。
2. 如何保證消息不被重復(fù)消費(fèi)(如何保證消息消費(fèi)時(shí)的冪等性)?
其實(shí)這個(gè)很常見的一個(gè)問題,這倆問題基本可以連起來問。既然是消費(fèi)消息,那肯定要考慮考慮會(huì)不會(huì)重復(fù)消費(fèi)?能不能避免重復(fù)消費(fèi)?或者重復(fù)消費(fèi)了也別造成系統(tǒng)異常可以嗎?這個(gè)是MQ領(lǐng)域的基本問題,其實(shí)本質(zhì)上還是問你使用消息隊(duì)列如何保證冪等性,這個(gè)是你架構(gòu)里要考慮的一個(gè)問題。
首先就是比如rabbitmq、rocketmq、kafka,都有可能會(huì)出現(xiàn)消費(fèi)重復(fù)消費(fèi)的問題,正常。因?yàn)檫@問題通常不是mq自己保證的,是給你保證的。然后我們挑一個(gè)kafka來舉個(gè)例子,說說怎么重復(fù)消費(fèi)吧。
kafka實(shí)際上有個(gè)offset的概念,就是每個(gè)消息寫進(jìn)去,都有一個(gè)offset,代表他的序號(hào),然后consumer消費(fèi)了數(shù)據(jù)之后,每隔一段時(shí)間,會(huì)把自己消費(fèi)過的消息的offset提交一下,代表我已經(jīng)消費(fèi)過了,下次我要是重啟啥的,你就讓我繼續(xù)從上次消費(fèi)到的offset來繼續(xù)消費(fèi)吧。
但是凡事總有意外,比如我們之前生產(chǎn)經(jīng)常遇到的,就是你有時(shí)候重啟系統(tǒng),看你怎么重啟了,如果碰到點(diǎn)著急的,直接kill進(jìn)程了,再重啟。這會(huì)導(dǎo)致consumer有些消息處理了,但是沒來得及提交offset,尷尬了。重啟之后,少數(shù)消息會(huì)再次消費(fèi)一次。
其實(shí)重復(fù)消費(fèi)不可怕,可怕的是你沒考慮到重復(fù)消費(fèi)之后,怎么保證冪等性。
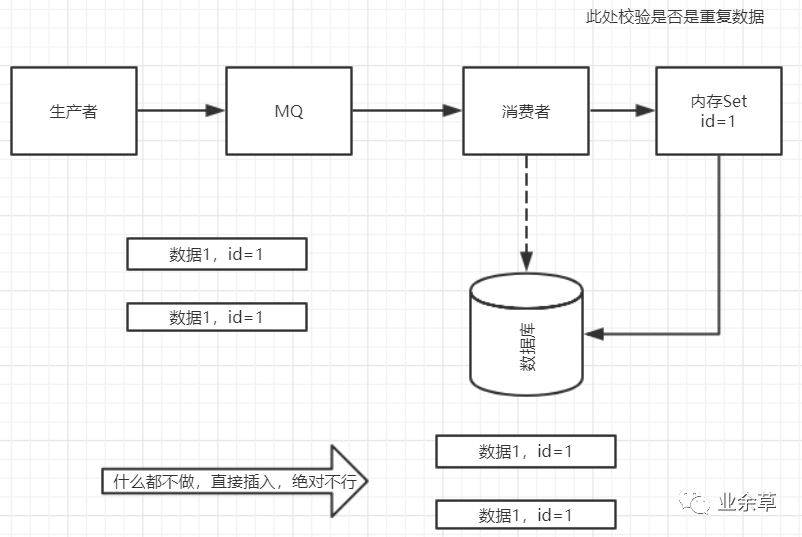
給你舉個(gè)例子吧。假設(shè)你有個(gè)系統(tǒng),消費(fèi)一條往數(shù)據(jù)庫里插入一條,要是你一個(gè)消息重復(fù)兩次,你不就插入了兩條,這數(shù)據(jù)不就錯(cuò)了?但是你要是消費(fèi)到第二次的時(shí)候,自己判斷一下已經(jīng)消費(fèi)過了,直接扔了,不就保留了一條數(shù)據(jù)?
一條數(shù)據(jù)重復(fù)出現(xiàn)兩次,數(shù)據(jù)庫里就只有一條數(shù)據(jù),這就保證了系統(tǒng)的冪等性
冪等性,我通俗點(diǎn)說,就一個(gè)數(shù)據(jù),或者一個(gè)請(qǐng)求,給你重復(fù)來多次,你得確保對(duì)應(yīng)的數(shù)據(jù)是不會(huì)改變的,不能出錯(cuò)。
那所以第二個(gè)問題來了,怎么保證消息隊(duì)列消費(fèi)的冪等性?
其實(shí)還是得結(jié)合業(yè)務(wù)來思考,我這里給幾個(gè)思路:
(1)比如你拿個(gè)數(shù)據(jù)要寫庫,你先根據(jù)主鍵查一下,如果這數(shù)據(jù)都有了,你就別插入了,update一下好吧
(2)比如你是寫redis,那沒問題了,反正每次都是set,天然冪等性
(3)比如你不是上面兩個(gè)場景,那做的稍微復(fù)雜一點(diǎn),你需要讓生產(chǎn)者發(fā)送每條數(shù)據(jù)的時(shí)候,里面加一個(gè)全局唯一的id,類似訂單id之類的東西,然后你這里消費(fèi)到了之后,先根據(jù)這個(gè)id去比如redis里查一下,之前消費(fèi)過嗎?如果沒有消費(fèi)過,你就處理,然后這個(gè)id寫redis。如果消費(fèi)過了,那你就別處理了,保證別重復(fù)處理相同的消息即可。
還有比如基于數(shù)據(jù)庫的唯一鍵來保證重復(fù)數(shù)據(jù)不會(huì)重復(fù)插入多條,我們之前線上系統(tǒng)就有這個(gè)問題,就是拿到數(shù)據(jù)的時(shí)候,每次重啟可能會(huì)有重復(fù),因?yàn)閗afka消費(fèi)者還沒來得及提交offset,重復(fù)數(shù)據(jù)拿到了以后我們插入的時(shí)候,因?yàn)橛形ㄒ绘I約束了,所以重復(fù)數(shù)據(jù)只會(huì)插入報(bào)錯(cuò),不會(huì)導(dǎo)致數(shù)據(jù)庫中出現(xiàn)臟數(shù)據(jù)
如何保證MQ的消費(fèi)是冪等性的,需要結(jié)合具體的業(yè)務(wù)來看

如何保證消息的冪等性
3. 如何保證消息的可靠傳輸(如何處理消息丟失的問題)?
這個(gè)是肯定的,用mq有個(gè)基本原則,就是數(shù)據(jù)不能多一條,也不能少一條,不能多,就是剛才說的重復(fù)消費(fèi)和冪等性問題。不能少,就是說這數(shù)據(jù)別搞丟了。那這個(gè)問題你必須得考慮一下。
如果說你這個(gè)是用mq來傳遞非常核心的消息,比如說計(jì)費(fèi),扣費(fèi)的一些消息,因?yàn)槲乙郧霸O(shè)計(jì)和研發(fā)過一個(gè)公司非常核心的廣告平臺(tái),計(jì)費(fèi)系統(tǒng),計(jì)費(fèi)系統(tǒng)是很重的一個(gè)業(yè)務(wù),操作是很耗時(shí)的。所以說廣告系統(tǒng)整體的架構(gòu)里面,實(shí)際上是將計(jì)費(fèi)做成異步化的,然后中間就是加了一個(gè)MQ。
我們當(dāng)時(shí)為了確保說這個(gè)MQ傳遞過程中絕對(duì)不會(huì)把計(jì)費(fèi)消息給弄丟,花了很多的精力。廣告主投放了一個(gè)廣告,明明說好了,用戶點(diǎn)擊一次扣費(fèi)1塊錢。結(jié)果要是用戶動(dòng)不動(dòng)點(diǎn)擊了一次,扣費(fèi)的時(shí)候搞的消息丟了,我們公司就會(huì)不斷的少幾塊錢,幾塊錢,積少成多,這個(gè)就對(duì)公司是一個(gè)很大的損失。
面試題剖析
這個(gè)丟數(shù)據(jù),mq一般分為兩種,要么是mq自己弄丟了,要么是我們消費(fèi)的時(shí)候弄丟了。咱們從rabbitmq和kafka分別來分析一下
rabbitmq這種mq,一般來說都是承載公司的核心業(yè)務(wù)的,數(shù)據(jù)是絕對(duì)不能弄丟的
RabbitMQ可能存在的數(shù)據(jù)丟失問題。
(1)rabbitmq
1)生產(chǎn)者弄丟了數(shù)據(jù)
生產(chǎn)者將數(shù)據(jù)發(fā)送到rabbitmq的時(shí)候,可能數(shù)據(jù)就在半路給搞丟了,因?yàn)榫W(wǎng)絡(luò)啥的問題,都有可能。
此時(shí)可以選擇用rabbitmq提供的事務(wù)功能,就是生產(chǎn)者發(fā)送數(shù)據(jù)之前開啟rabbitmq事務(wù)(channel.txSelect),然后發(fā)送消息,如果消息沒有成功被rabbitmq接收到,那么生產(chǎn)者會(huì)收到異常報(bào)錯(cuò),此時(shí)就可以回滾事務(wù)(channel.txRollback),然后重試發(fā)送消息;如果收到了消息,那么可以提交事務(wù)(channel.txCommit)。但是問題是,rabbitmq事務(wù)機(jī)制一搞,基本上吞吐量會(huì)下來,因?yàn)樘男阅堋?/p>
所以一般來說,如果你要確保說寫rabbitmq的消息別丟,可以開啟confirm模式,在生產(chǎn)者那里設(shè)置開啟confirm模式之后,你每次寫的消息都會(huì)分配一個(gè)唯一的id,然后如果寫入了rabbitmq中,rabbitmq會(huì)給你回傳一個(gè)ack消息,告訴你說這個(gè)消息ok了。如果rabbitmq沒能處理這個(gè)消息,會(huì)回調(diào)你一個(gè)nack接口,告訴你這個(gè)消息接收失敗,你可以重試。而且你可以結(jié)合這個(gè)機(jī)制自己在內(nèi)存里維護(hù)每個(gè)消息id的狀態(tài),如果超過一定時(shí)間還沒接收到這個(gè)消息的回調(diào),那么你可以重發(fā)。
事務(wù)機(jī)制和cnofirm機(jī)制最大的不同在于,事務(wù)機(jī)制是同步的,你提交一個(gè)事務(wù)之后會(huì)阻塞在那兒,但是confirm機(jī)制是異步的,你發(fā)送個(gè)消息之后就可以發(fā)送下一個(gè)消息,然后那個(gè)消息rabbitmq接收了之后會(huì)異步回調(diào)你一個(gè)接口通知你這個(gè)消息接收到了。
所以一般在生產(chǎn)者這塊避免數(shù)據(jù)丟失,都是用confirm機(jī)制的。
2)rabbitmq弄丟了數(shù)據(jù)
就是rabbitmq自己弄丟了數(shù)據(jù),這個(gè)你必須開啟rabbitmq的持久化,就是消息寫入之后會(huì)持久化到磁盤,哪怕是rabbitmq自己掛了,恢復(fù)之后會(huì)自動(dòng)讀取之前存儲(chǔ)的數(shù)據(jù),一般數(shù)據(jù)不會(huì)丟。除非極其罕見的是,rabbitmq還沒持久化,自己就掛了,可能導(dǎo)致少量數(shù)據(jù)會(huì)丟失的,但是這個(gè)概率較小。
設(shè)置持久化有兩個(gè)步驟,第一個(gè)是創(chuàng)建queue的時(shí)候?qū)⑵湓O(shè)置為持久化的,這樣就可以保證rabbitmq持久化queue的元數(shù)據(jù),但是不會(huì)持久化queue里的數(shù)據(jù);第二個(gè)是發(fā)送消息的時(shí)候?qū)⑾⒌膁eliveryMode設(shè)置為2,就是將消息設(shè)置為持久化的,此時(shí)rabbitmq就會(huì)將消息持久化到磁盤上去。必須要同時(shí)設(shè)置這兩個(gè)持久化才行,rabbitmq哪怕是掛了,再次重啟,也會(huì)從磁盤上重啟恢復(fù)queue,恢復(fù)這個(gè)queue里的數(shù)據(jù)。
而且持久化可以跟生產(chǎn)者那邊的confirm機(jī)制配合起來,只有消息被持久化到磁盤之后,才會(huì)通知生產(chǎn)者ack了,所以哪怕是在持久化到磁盤之前,rabbitmq掛了,數(shù)據(jù)丟了,生產(chǎn)者收不到ack,你也是可以自己重發(fā)的。
哪怕是你給rabbitmq開啟了持久化機(jī)制,也有一種可能,就是這個(gè)消息寫到了rabbitmq中,但是還沒來得及持久化到磁盤上,結(jié)果不巧,此時(shí)rabbitmq掛了,就會(huì)導(dǎo)致內(nèi)存里的一點(diǎn)點(diǎn)數(shù)據(jù)會(huì)丟失。
3)消費(fèi)端弄丟了數(shù)據(jù)
rabbitmq如果丟失了數(shù)據(jù),主要是因?yàn)槟阆M(fèi)的時(shí)候,剛消費(fèi)到,還沒處理,結(jié)果進(jìn)程掛了,比如重啟了,那么就尷尬了,rabbitmq認(rèn)為你都消費(fèi)了,這數(shù)據(jù)就丟了。
這個(gè)時(shí)候得用rabbitmq提供的ack機(jī)制,簡單來說,就是你關(guān)閉rabbitmq自動(dòng)ack,可以通過一個(gè)api來調(diào)用就行,然后每次你自己代碼里確保處理完的時(shí)候,再程序里ack一把。這樣的話,如果你還沒處理完,不就沒有ack?那rabbitmq就認(rèn)為你還沒處理完,這個(gè)時(shí)候rabbitmq會(huì)把這個(gè)消費(fèi)分配給別的consumer去處理,消息是不會(huì)丟的。

(2)kafka
1)消費(fèi)端弄丟了數(shù)據(jù)
唯一可能導(dǎo)致消費(fèi)者弄丟數(shù)據(jù)的情況,就是說,你那個(gè)消費(fèi)到了這個(gè)消息,然后消費(fèi)者那邊自動(dòng)提交了offset,讓kafka以為你已經(jīng)消費(fèi)好了這個(gè)消息,其實(shí)你剛準(zhǔn)備處理這個(gè)消息,你還沒處理,你自己就掛了,此時(shí)這條消息就丟咯。
這不是一樣么,大家都知道kafka會(huì)自動(dòng)提交offset,那么只要關(guān)閉自動(dòng)提交offset,在處理完之后自己手動(dòng)提交offset,就可以保證數(shù)據(jù)不會(huì)丟。但是此時(shí)確實(shí)還是會(huì)重復(fù)消費(fèi),比如你剛處理完,還沒提交offset,結(jié)果自己掛了,此時(shí)肯定會(huì)重復(fù)消費(fèi)一次,自己保證冪等性就好了。
生產(chǎn)環(huán)境碰到的一個(gè)問題,就是說我們的kafka消費(fèi)者消費(fèi)到了數(shù)據(jù)之后是寫到一個(gè)內(nèi)存的queue里先緩沖一下,結(jié)果有的時(shí)候,你剛把消息寫入內(nèi)存queue,然后消費(fèi)者會(huì)自動(dòng)提交offset。
然后此時(shí)我們重啟了系統(tǒng),就會(huì)導(dǎo)致內(nèi)存queue里還沒來得及處理的數(shù)據(jù)就丟失了
2)kafka弄丟了數(shù)據(jù)
這塊比較常見的一個(gè)場景,就是kafka某個(gè)broker宕機(jī),然后重新選舉partiton的leader時(shí)。大家想想,要是此時(shí)其他的follower剛好還有些數(shù)據(jù)沒有同步,結(jié)果此時(shí)leader掛了,然后選舉某個(gè)follower成leader之后,他不就少了一些數(shù)據(jù)?這就丟了一些數(shù)據(jù)啊。
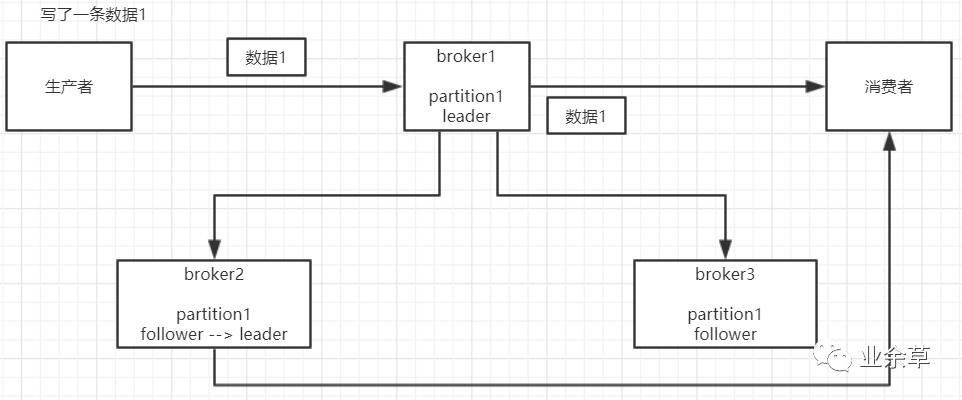
生產(chǎn)環(huán)境也遇到過,我們也是,之前kafka的leader機(jī)器宕機(jī)了,將follower切換為leader之后,就會(huì)發(fā)現(xiàn)說這個(gè)數(shù)據(jù)就丟了
所以此時(shí)一般是要求起碼設(shè)置如下4個(gè)參數(shù):
給這個(gè)topic設(shè)置replication.factor參數(shù):這個(gè)值必須大于1,要求每個(gè)partition必須有至少2個(gè)副本
在kafka服務(wù)端設(shè)置min.insync.replicas參數(shù):這個(gè)值必須大于1,這個(gè)是要求一個(gè)leader至少感知到有至少一個(gè)follower還跟自己保持聯(lián)系,沒掉隊(duì),這樣才能確保leader掛了還有一個(gè)follower吧
在producer端設(shè)置acks=all:這個(gè)是要求每條數(shù)據(jù),必須是寫入所有replica之后,才能認(rèn)為是寫成功了
在producer端設(shè)置retries=MAX(很大很大很大的一個(gè)值,無限次重試的意思):這個(gè)是要求一旦寫入失敗,就無限重試,卡在這里了
我們生產(chǎn)環(huán)境就是按照上述要求配置的,這樣配置之后,至少在kafka broker端就可以保證在leader所在broker發(fā)生故障,進(jìn)行l(wèi)eader切換時(shí),數(shù)據(jù)不會(huì)丟失
3)生產(chǎn)者會(huì)不會(huì)弄丟數(shù)據(jù)
如果按照上述的思路設(shè)置了ack=all,一定不會(huì)丟,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才認(rèn)為本次寫成功了。如果沒滿足這個(gè)條件,生產(chǎn)者會(huì)自動(dòng)不斷的重試,重試無限次。
1. 如何保證消息的順序性?
其實(shí)這個(gè)也是用MQ的時(shí)候必問的話題,第一看看你了解不了解順序這個(gè)事兒?第二看看你有沒有辦法保證消息是有順序的?這個(gè)生產(chǎn)系統(tǒng)中常見的問題。
我舉個(gè)例子,我們以前做過一個(gè)mysql binlog同步的系統(tǒng),壓力還是非常大的,日同步數(shù)據(jù)要達(dá)到上億。mysql -> mysql,常見的一點(diǎn)在于說大數(shù)據(jù)team,就需要同步一個(gè)mysql庫過來,對(duì)公司的業(yè)務(wù)系統(tǒng)的數(shù)據(jù)做各種復(fù)雜的操作。
你在mysql里增刪改一條數(shù)據(jù),對(duì)應(yīng)出來了增刪改3條binlog,接著這三條binlog發(fā)送到MQ里面,到消費(fèi)出來依次執(zhí)行,起碼得保證人家是按照順序來的吧?不然本來是:增加、修改、刪除;你楞是換了順序給執(zhí)行成刪除、修改、增加,不全錯(cuò)了么。
本來這個(gè)數(shù)據(jù)同步過來,應(yīng)該最后這個(gè)數(shù)據(jù)被刪除了;結(jié)果你搞錯(cuò)了這個(gè)順序,最后這個(gè)數(shù)據(jù)保留下來了,數(shù)據(jù)同步就出錯(cuò)了。
先看看順序會(huì)錯(cuò)亂的倆場景
(1)rabbitmq:一個(gè)queue,多個(gè)consumer,這不明顯亂了

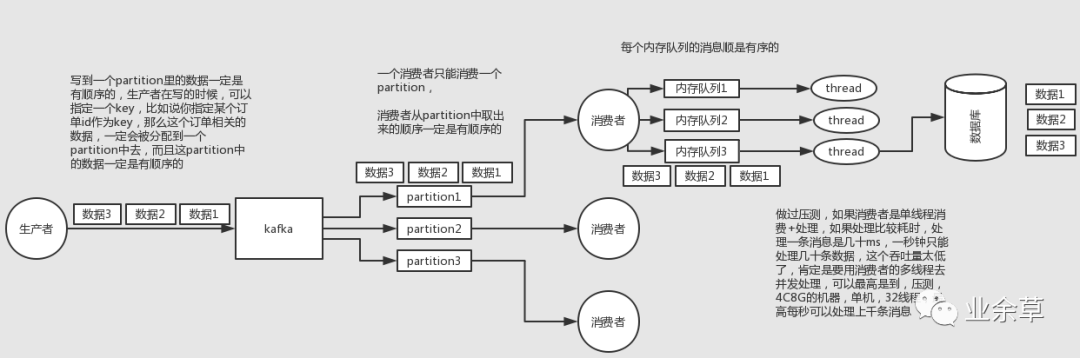
(2)kafka:一個(gè)topic,一個(gè)partition,一個(gè)consumer,內(nèi)部多線程,這不也明顯亂了

那如何保證消息的順序性呢?簡單簡單
(1)rabbitmq:拆分多個(gè)queue,每個(gè)queue一個(gè)consumer,就是多一些queue而已,確實(shí)是麻煩點(diǎn);
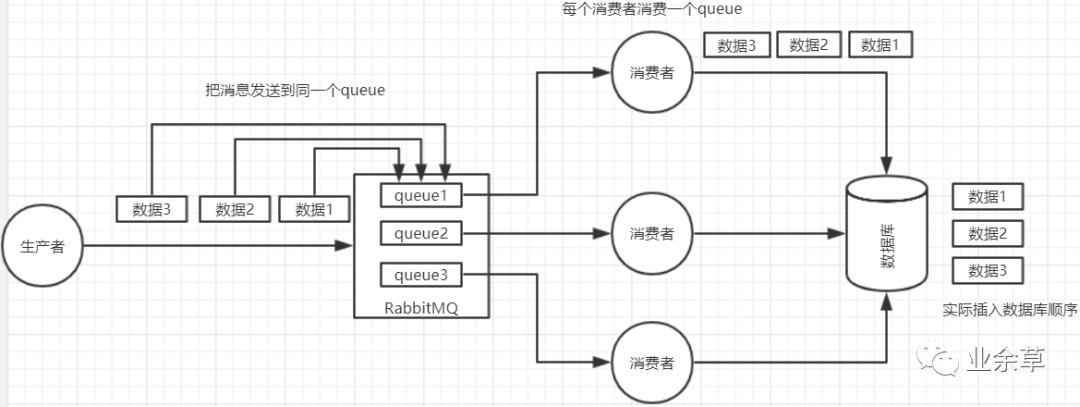
或者就一個(gè)queue但是對(duì)應(yīng)一個(gè)consumer,然后這個(gè)consumer內(nèi)部用內(nèi)存隊(duì)列做排隊(duì),然后分發(fā)給底層不同的worker來處理
(2)kafka:一個(gè)topic,一個(gè)partition,一個(gè)consumer,內(nèi)部單線程消費(fèi),寫N個(gè)內(nèi)存queue,然后N個(gè)線程分別消費(fèi)一個(gè)內(nèi)存queue即可
如何解決消息隊(duì)列的延時(shí)以及過期失效問題?消息隊(duì)列滿了以后該怎么處理?有幾百萬消息持續(xù)積壓幾小時(shí),說說怎么解決?
你看這問法,其實(shí)本質(zhì)針對(duì)的場景,都是說,可能你的消費(fèi)端出了問題,不消費(fèi)了,或者消費(fèi)的極其極其慢。接著就坑爹了,可能你的消息隊(duì)列集群的磁盤都快寫滿了,都沒人消費(fèi),這個(gè)時(shí)候怎么辦?或者是整個(gè)這就積壓了幾個(gè)小時(shí),你這個(gè)時(shí)候怎么辦?或者是你積壓的時(shí)間太長了,導(dǎo)致比如rabbitmq設(shè)置了消息過期時(shí)間后就沒了怎么辦?
所以就這事兒,其實(shí)線上挺常見的,一般不出,一出就是大case,一般常見于,舉個(gè)例子,消費(fèi)端每次消費(fèi)之后要寫mysql,結(jié)果mysql掛了,消費(fèi)端hang那兒了,不動(dòng)了。或者是消費(fèi)端出了個(gè)什么叉子,導(dǎo)致消費(fèi)速度極其慢。
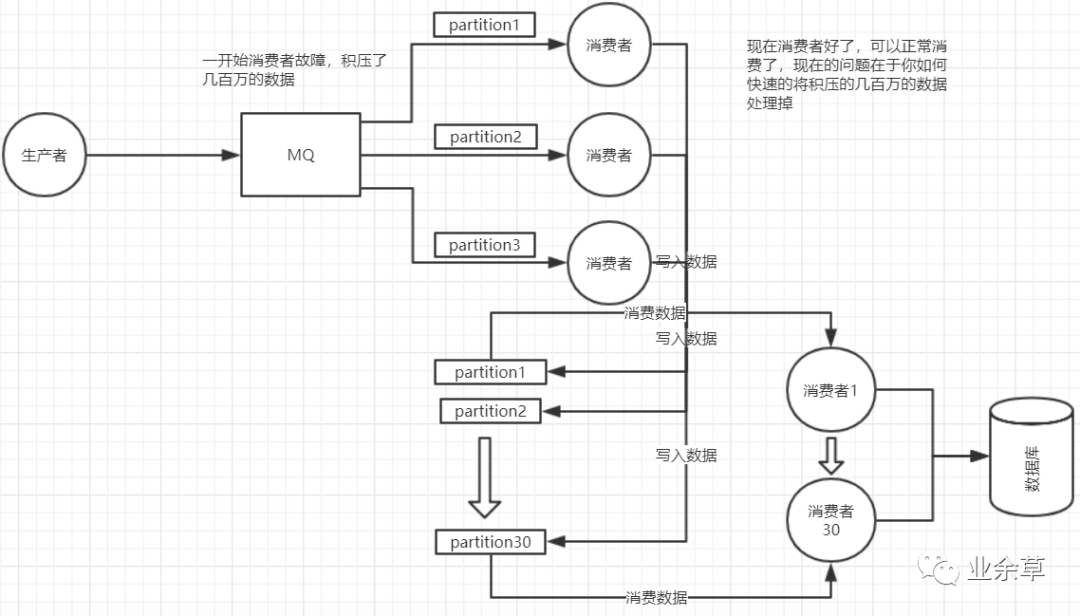
關(guān)于這個(gè)事兒,我們一個(gè)一個(gè)來梳理吧,先假設(shè)一個(gè)場景,我們現(xiàn)在消費(fèi)端出故障了,然后大量消息在mq里積壓,現(xiàn)在事故了,慌了
(1)大量消息在mq里積壓了幾個(gè)小時(shí)了還沒解決
幾千萬條數(shù)據(jù)在MQ里積壓了七八個(gè)小時(shí),從下午4點(diǎn)多,積壓到了晚上很晚,10點(diǎn)多,11點(diǎn)多
這個(gè)是我們真實(shí)遇到過的一個(gè)場景,確實(shí)是線上故障了,這個(gè)時(shí)候要不然就是修復(fù)consumer的問題,讓他恢復(fù)消費(fèi)速度,然后傻傻的等待幾個(gè)小時(shí)消費(fèi)完畢。這個(gè)肯定不能在面試的時(shí)候說吧。
一個(gè)消費(fèi)者一秒是1000條,一秒3個(gè)消費(fèi)者是3000條,一分鐘是18萬條,1000多萬條
所以如果你積壓了幾百萬到上千萬的數(shù)據(jù),即使消費(fèi)者恢復(fù)了,也需要大概1小時(shí)的時(shí)間才能恢復(fù)過來
一般這個(gè)時(shí)候,只能操作臨時(shí)緊急擴(kuò)容了,具體操作步驟和思路如下:
1)先修復(fù)consumer的問題,確保其恢復(fù)消費(fèi)速度,然后將現(xiàn)有cnosumer都停掉
2)新建一個(gè)topic,partition是原來的10倍,臨時(shí)建立好原先10倍或者20倍的queue數(shù)量
3)然后寫一個(gè)臨時(shí)的分發(fā)數(shù)據(jù)的consumer程序,這個(gè)程序部署上去消費(fèi)積壓的數(shù)據(jù),消費(fèi)之后不做耗時(shí)的處理,直接均勻輪詢寫入臨時(shí)建立好的10倍數(shù)量的queue
4)接著臨時(shí)征用10倍的機(jī)器來部署consumer,每一批consumer消費(fèi)一個(gè)臨時(shí)queue的數(shù)據(jù)
5)這種做法相當(dāng)于是臨時(shí)將queue資源和consumer資源擴(kuò)大10倍,以正常的10倍速度來消費(fèi)數(shù)據(jù)
6)等快速消費(fèi)完積壓數(shù)據(jù)之后,得恢復(fù)原先部署架構(gòu),重新用原先的consumer機(jī)器來消費(fèi)消息
(2)這里我們假設(shè)再來第二個(gè)坑
假設(shè)你用的是rabbitmq,rabbitmq是可以設(shè)置過期時(shí)間的,就是TTL,如果消息在queue中積壓超過一定的時(shí)間就會(huì)被rabbitmq給清理掉,這個(gè)數(shù)據(jù)就沒了。那這就是第二個(gè)坑了。這就不是說數(shù)據(jù)會(huì)大量積壓在mq里,而是大量的數(shù)據(jù)會(huì)直接搞丟。
這個(gè)情況下,就不是說要增加consumer消費(fèi)積壓的消息,因?yàn)閷?shí)際上沒啥積壓,而是丟了大量的消息。我們可以采取一個(gè)方案,就是批量重導(dǎo),這個(gè)我們之前線上也有類似的場景干過。就是大量積壓的時(shí)候,我們當(dāng)時(shí)就直接丟棄數(shù)據(jù)了,然后等過了高峰期以后,比如大家一起喝咖啡熬夜到晚上12點(diǎn)以后,用戶都睡覺了。
這個(gè)時(shí)候我們就開始寫程序,將丟失的那批數(shù)據(jù),寫個(gè)臨時(shí)程序,一點(diǎn)一點(diǎn)的查出來,然后重新灌入mq里面去,把白天丟的數(shù)據(jù)給他補(bǔ)回來。也只能是這樣了。
假設(shè)1萬個(gè)訂單積壓在mq里面,沒有處理,其中1000個(gè)訂單都丟了,你只能手動(dòng)寫程序把那1000個(gè)訂單給查出來,手動(dòng)發(fā)到mq里去再補(bǔ)一次
(3)然后我們?cè)賮砑僭O(shè)第三個(gè)坑
如果走的方式是消息積壓在mq里,那么如果你很長時(shí)間都沒處理掉,此時(shí)導(dǎo)致mq都快寫滿了,咋辦?這個(gè)還有別的辦法嗎?沒有,誰讓你第一個(gè)方案執(zhí)行的太慢了,你臨時(shí)寫程序,接入數(shù)據(jù)來消費(fèi),消費(fèi)一個(gè)丟棄一個(gè),都不要了,快速消費(fèi)掉所有的消息。然后走第二個(gè)方案,到了晚上再補(bǔ)數(shù)據(jù)吧。
1. 如果讓你寫一個(gè)消息隊(duì)列,該如何進(jìn)行架構(gòu)設(shè)計(jì)啊?說一下你的思路
其實(shí)聊到這個(gè)問題,一般面試官要考察兩塊:
(1)你有沒有對(duì)某一個(gè)消息隊(duì)列做過較為深入的原理的了解,或者從整體了解把握住一個(gè)mq的架構(gòu)原理
(2)看看你的設(shè)計(jì)能力,給你一個(gè)常見的系統(tǒng),就是消息隊(duì)列系統(tǒng),看看你能不能從全局把握一下整體架構(gòu)設(shè)計(jì),給出一些關(guān)鍵點(diǎn)出來
其實(shí)回答這類問題,說白了,起碼不求你看過那技術(shù)的源碼,起碼你大概知道那個(gè)技術(shù)的基本原理,核心組成部分,基本架構(gòu)構(gòu)成,然后參照一些開源的技術(shù)把一個(gè)系統(tǒng)設(shè)計(jì)出來的思路說一下就好
比如說這個(gè)消息隊(duì)列系統(tǒng),我們來從以下幾個(gè)角度來考慮一下
說實(shí)話,我一般面類似問題的時(shí)候,大部分人基本都會(huì)蒙,因?yàn)槠綍r(shí)從來沒有思考過類似的問題,大多數(shù)人就是平時(shí)埋頭用,從來不去思考背后的一些東西。類似的問題,我經(jīng)常問的還有,如果讓你來設(shè)計(jì)一個(gè)spring框架你會(huì)怎么做?如果讓你來設(shè)計(jì)一個(gè)dubbo框架你會(huì)怎么做?如果讓你來設(shè)計(jì)一個(gè)mybatis框架你會(huì)怎么做?
其實(shí)回答這類問題,說白了,起碼不求你看過那技術(shù)的源碼,起碼你大概知道那個(gè)技術(shù)的基本原理,核心組成部分,基本架構(gòu)構(gòu)成,然后參照一些開源的技術(shù)把一個(gè)系統(tǒng)設(shè)計(jì)出來的思路說一下就好
比如說這個(gè)消息隊(duì)列系統(tǒng),我們來從以下幾個(gè)角度來考慮一下
(1)首先這個(gè)mq得支持可伸縮性吧,就是需要的時(shí)候快速擴(kuò)容,就可以增加吞吐量和容量,那怎么搞?設(shè)計(jì)個(gè)分布式的系統(tǒng)唄,參照一下kafka的設(shè)計(jì)理念,broker -> topic -> partition,每個(gè)partition放一個(gè)機(jī)器,就存一部分?jǐn)?shù)據(jù)。如果現(xiàn)在資源不夠了,簡單啊,給topic增加partition,然后做數(shù)據(jù)遷移,增加機(jī)器,不就可以存放更多數(shù)據(jù),提供更高的吞吐量了?
(2)其次你得考慮一下這個(gè)mq的數(shù)據(jù)要不要落地磁盤吧?那肯定要了,落磁盤,才能保證別進(jìn)程掛了數(shù)據(jù)就丟了。那落磁盤的時(shí)候怎么落啊?順序?qū)懀@樣就沒有磁盤隨機(jī)讀寫的尋址開銷,磁盤順序讀寫的性能是很高的,這就是kafka的思路。
2.其次你考慮一下你的mq的可用性啊?
這個(gè)事兒,具體參考我們之前可用性那個(gè)環(huán)節(jié)講解的kafka的高可用保障機(jī)制。多副本 -> leader & follower -> broker掛了重新選舉leader即可對(duì)外服務(wù)。
(4)能不能支持?jǐn)?shù)據(jù)0丟失啊?可以的,參考我們之前說的那個(gè)kafka數(shù)據(jù)零丟失方案
其實(shí)一個(gè)mq肯定是很復(fù)雜的,面試官問你這個(gè)問題,其實(shí)是個(gè)開放題,他就是看看你有沒有從架構(gòu)角度整體構(gòu)思和設(shè)計(jì)的思維以及能力。確實(shí)這個(gè)問題可以刷掉一大批人,因?yàn)榇蟛糠秩似綍r(shí)不思考這些東西。