
TF-IDF算法:用 Python 提煉財經(jīng)新聞

所有的字都用小寫。 刪除數(shù)字和首字母。 刪除停頓詞。 刪除標點符號。 詞義化。這意味著將該詞還原為一個詞的詞根同義詞。由于de輸入 "pos",可以確定詞根是來自形容詞、動詞還是名詞。 刪除常見的詞,如“wall street”, “market”, “stock”, “share”, …
import nltk
from nltk.stem importWordNetLemmatizer
import re
stopwords = nltk.corpus.words('english')
lemmatizer = WordNetLemmatizer()
processed_text = re.sub('[^a-zA-Z]', ' ',original_text)
processed_text = processed_text.lower()
processed_text = processed_text.split()
processed_text = [lemmatizer.lemmatize(word, pos='a') for word in processed_text if word notin set(stopwords)]
processed_text = [lemmatizer.lemmatize(word, pos='v') for word in processed_text if word notin set(stopwords)]
processed_text = [lemmatizer.lemmatize(word, pos='n') for word in processed_text if word notin set(stopwords)]
processed_text = ' '.join(processed_text)
processed_text = re.sub('stock', '', processed_text)
TfidfVectorizer模型。這允許我們設置關鍵特征的數(shù)量,我們將其設置為8個最大特征。
from sklearn.feature_extraction.text importTfidfVectorizer
tf_idf_model = TfidfVectorizer(max_features=8)
processed_text_tf = tf_idf_model.fit_transform(preprocessed_texts)
tf_idf_values = tf_idf_model.idf_
tf_idf_names = tf_idf_model.get_feature_names()
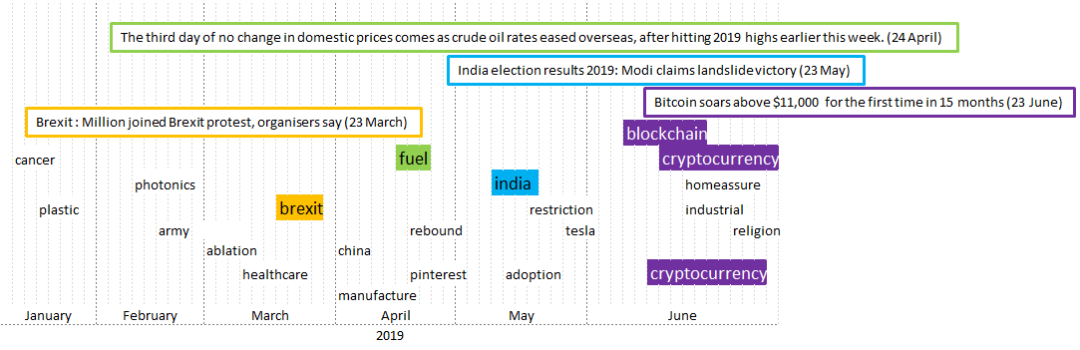
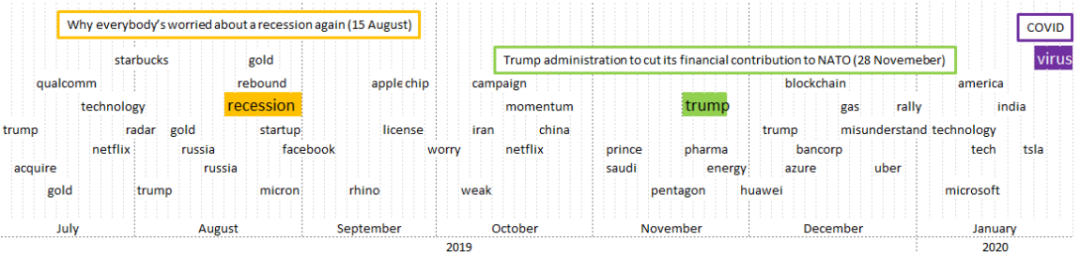
- 點擊下方閱讀原文加入社區(qū)會員 -