
人類(lèi)專(zhuān)業(yè)玩家水平!自動(dòng)化所研發(fā)輕量型德州撲克AI程序AlphaHoldem

新智元報(bào)道
新智元報(bào)道
來(lái)源:中科院自動(dòng)化所
【新智元導(dǎo)讀】中科院自動(dòng)化所興軍亮研究員領(lǐng)導(dǎo)的博弈學(xué)習(xí)研究組提出了一種高水平輕量化的兩人無(wú)限注德州撲克AI程序——AlphaHoldem。其決策速度較DeepStack速度提升超1000倍,與高水平德州撲克選手對(duì)抗的結(jié)果表明其已經(jīng)達(dá)到了人類(lèi)專(zhuān)業(yè)玩家水平,相關(guān)工作被AAAI 2022接收。
從人工智能學(xué)科誕生伊始,智能博弈研究就是人工智能技術(shù)發(fā)展創(chuàng)新的沃土,并且一直都是衡量人工智能發(fā)展水平的重要評(píng)價(jià)準(zhǔn)則[1][2][3][4]。
2016年,AlphaGo[2]以4:1的成績(jī)戰(zhàn)勝?lài)迨澜绻谲娎钍朗@一事件被認(rèn)為是智能博弈技術(shù)發(fā)展的一個(gè)重要里程碑。不同于完美信息的圍棋博弈,現(xiàn)實(shí)世界博弈的一個(gè)顯著特點(diǎn)是由于信息不完備性造成的對(duì)手不確定。
以德州撲克為代表的大規(guī)模不完美信息博弈問(wèn)題很好地集中了這一難題,是進(jìn)一步深入研究智能博弈理論與技術(shù)的極佳平臺(tái)。
近年來(lái),國(guó)際上圍繞德州撲克這一大規(guī)模不完美信息博弈問(wèn)題的優(yōu)化求解取得了長(zhǎng)足進(jìn)步,來(lái)自加拿大阿爾伯特大學(xué)和美國(guó)卡內(nèi)基梅隆大學(xué)的研究者設(shè)計(jì)的AI程序DeepStack[3]和Libratus[4]先后在兩人無(wú)限注德州撲克中均戰(zhàn)勝了人類(lèi)專(zhuān)業(yè)選手,隨后卡內(nèi)基梅隆大學(xué)設(shè)計(jì)的AI程序Pluribus[5]又在六人無(wú)限注德州撲克中戰(zhàn)勝了人類(lèi)專(zhuān)業(yè)選手。
上述具有里程碑意義的德州撲克AI都依賴(lài)一種迭代式的反事實(shí)遺憾最小化(Counterfactual Regret Minimization,CFR)[6]算法。該算法在訓(xùn)練過(guò)程中不僅需要耗費(fèi)大量的計(jì)算資源,同時(shí)需要很多德州撲克游戲的領(lǐng)域知識(shí)。
近日,中國(guó)科學(xué)院自動(dòng)化研究所興軍亮研究員領(lǐng)導(dǎo)的博弈學(xué)習(xí)研究組在德州撲克AI方面取得了重要進(jìn)展,提出了一種高水平輕量化的兩人無(wú)限注德州撲克AI程序AlphaHoldem。
AlphaHoldem整體上采用一種精心設(shè)計(jì)的偽孿生網(wǎng)絡(luò)架構(gòu),并將一種改進(jìn)的深度強(qiáng)化學(xué)習(xí)算法與一種新型的自博弈學(xué)習(xí)算法相結(jié)合,在不借助任何領(lǐng)域知識(shí)的情況下,直接從牌面信息端到端地學(xué)習(xí)候選動(dòng)作進(jìn)行決策。
AlphaHoldem使用了1臺(tái)包含8塊GPU卡的服務(wù)器,經(jīng)過(guò)三天的自博弈學(xué)習(xí)后,戰(zhàn)勝了Slumbot[7]和DeepStack[3]。
在每次決策時(shí),AlphaHoldem僅需不到3毫秒,比DeepStack速度提升超過(guò)了1000倍。同時(shí),AlphaHoldem與四位高水平德州撲克選手對(duì)抗1萬(wàn)局的結(jié)果表明其已經(jīng)達(dá)到了人類(lèi)專(zhuān)業(yè)玩家水平。
背景介紹
德州撲克是國(guó)際上最為流行的撲克游戲,由于最早起源于20世紀(jì)初美國(guó)德克薩斯州而得名。德州撲克的規(guī)則是使用去掉王牌的一副撲克牌,共52張牌,至少2人參與,至多22人,一般參與人數(shù)為兩人和十人之間。
游戲開(kāi)始時(shí),首先為每個(gè)玩家發(fā)兩張私有牌作為各自的「底牌」,隨后將五張公共牌依次按三張、一張、一張朝上發(fā)出。在發(fā)完兩張私有牌、三張共有牌、第四張公共牌、第五張公共牌后玩家都可以多次無(wú)限制押注,這四輪押注分別稱(chēng)為「翻牌前」、「翻牌」、「轉(zhuǎn)牌」、「河牌」。
圖1展示了一場(chǎng)德州撲克游戲的完整流程示意。經(jīng)過(guò)四輪押注之后,若仍不能分出勝負(fù),游戲進(jìn)入「攤牌」階段,所有玩家亮出各自底牌并與公共牌組合成五張牌,成牌最大者獲勝。圖2給出了德州撲克不同組合的牌型解釋和大小。
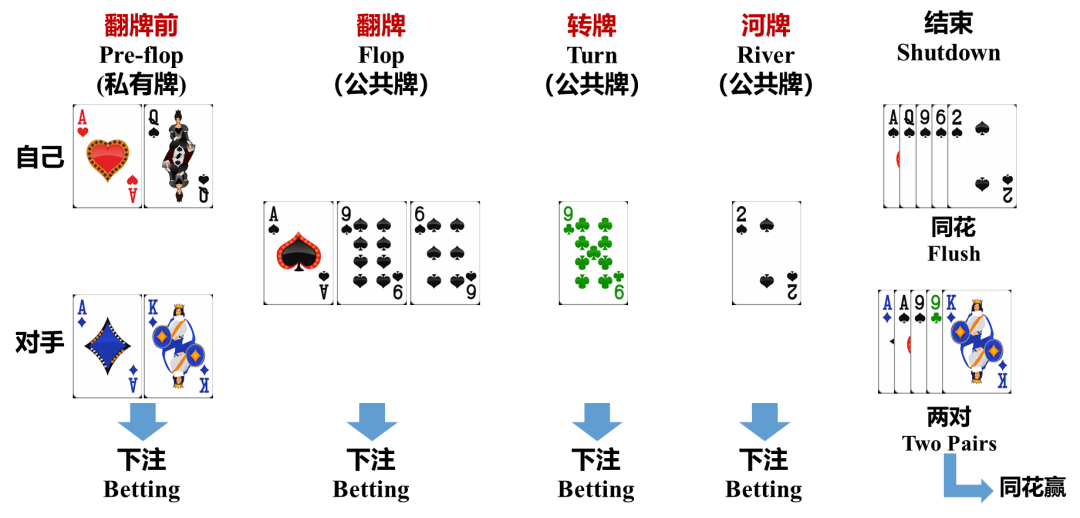
圖1:兩人無(wú)限注德州撲克一次游戲過(guò)程示意

圖2:德州撲克不同牌型大小說(shuō)明和比較
德州撲克不僅是最流行的撲克類(lèi)游戲,而且也為研究智能博弈基礎(chǔ)理論和方法提供了一個(gè)絕佳試驗(yàn)和測(cè)試平臺(tái)。
首先,德州撲克博弈的問(wèn)題復(fù)雜度很大,兩人無(wú)限注德州撲克的決策空間復(fù)雜度超過(guò)10的161次方[3];其次,德州撲克博弈過(guò)程屬于典型的回合制動(dòng)態(tài)博弈過(guò)程,游戲參與者每一步?jīng)Q策都依賴(lài)于上一步的決策結(jié)果,同時(shí)對(duì)后面的決策步驟產(chǎn)生影響;另外,德州撲克博弈屬于典型的不完美信息博弈,博弈過(guò)程中玩家各自底牌信息不公開(kāi)使得每個(gè)玩家信息都不完備,玩家在每一步?jīng)Q策時(shí)都要充分考慮對(duì)手的各種可能情況,這就涉及到對(duì)手行為與心理建模、欺詐與反欺詐等諸多問(wèn)題。
此外,由于德州撲克游戲規(guī)則又非常簡(jiǎn)單且邊界確定,特別適合作為一個(gè)虛擬實(shí)驗(yàn)環(huán)境對(duì)博弈的相關(guān)基礎(chǔ)理論方法和核心技術(shù)算法進(jìn)行深入探究。
目前主流德州撲克AI背后的核心思想是利用反事實(shí)遺憾最小化(Counterfactual Regret Minimization, CFR)算法[6]逼近納什均衡策略。具體來(lái)說(shuō),首先利用抽象(Abstraction)技術(shù)[3][7]壓縮德?lián)涞臓顟B(tài)和動(dòng)作空間,從而減小博弈樹(shù)的規(guī)模,然后在縮減過(guò)的博弈樹(shù)上進(jìn)行CFR算法迭代。
這些方法嚴(yán)重依賴(lài)于人類(lèi)專(zhuān)家知識(shí)進(jìn)行博弈樹(shù)抽象,并且CFR算法需要對(duì)博弈樹(shù)的狀態(tài)結(jié)點(diǎn)進(jìn)行不斷地采樣遍歷和迭代優(yōu)化,即使經(jīng)過(guò)模型縮減后仍需要耗費(fèi)大量的計(jì)算和存儲(chǔ)資源。
例如,DeepStack使用了153萬(wàn)的CPU時(shí)以及1.3萬(wàn)的GPU時(shí)訓(xùn)練最終AI,在對(duì)局階段需要一個(gè)GPU進(jìn)行1000次CFR的迭代過(guò)程,平均每個(gè)動(dòng)作的計(jì)算需耗時(shí)3秒。
Libratus消耗了大于300萬(wàn)的CPU時(shí)生成初始策略,每次決策需要搜索4秒以上。這樣大量的計(jì)算和存儲(chǔ)資源的消耗嚴(yán)重阻礙了德?lián)銩I的進(jìn)一步研究和發(fā)展;同時(shí),CFR框架很難直接拓展到多人德?lián)洵h(huán)境中,增加玩家數(shù)量將導(dǎo)致博弈樹(shù)規(guī)模呈指數(shù)增長(zhǎng)。
另外,博弈樹(shù)抽象不僅需要大量的領(lǐng)域知識(shí)而且會(huì)不可避免地丟失一些對(duì)決策起到至關(guān)作用的信息。
 表1:不同算法的訓(xùn)練測(cè)試資源對(duì)比
表1:不同算法的訓(xùn)練測(cè)試資源對(duì)比
方法介紹
不同于已有的基于CFR算法的德州撲克AI,中國(guó)科學(xué)院自動(dòng)化研究所博弈學(xué)習(xí)研究組基于端到端的深度強(qiáng)化學(xué)習(xí)算法研發(fā)了一款高水平輕量型的德州撲克AI程序AlphaHoldem,其整體架構(gòu)如圖4所示。
AlphaHoldem采用Actor-Critic學(xué)習(xí)框架[8],其輸入是卡牌和動(dòng)作的編碼,然后通過(guò)偽孿生卷積網(wǎng)絡(luò)(結(jié)構(gòu)相同參數(shù)不共享)提取特征,接下來(lái)通過(guò)兩個(gè)全連接層得到狀態(tài)的高層特征,最終輸出動(dòng)作概率和價(jià)值估計(jì)。
AlphaHoldem的成功得益于其采用了一種高效的狀態(tài)編碼來(lái)完整地描述當(dāng)前及歷史狀態(tài)信息、一種基于Trinal-Clip PPO損失的深度強(qiáng)化學(xué)習(xí)算法來(lái)大幅提高訓(xùn)練過(guò)程的穩(wěn)定性和收斂速度、以及一種新型的Best-K自博弈方式來(lái)有效地緩解德?lián)洳┺闹写嬖诘牟呗钥酥茊?wèn)題。
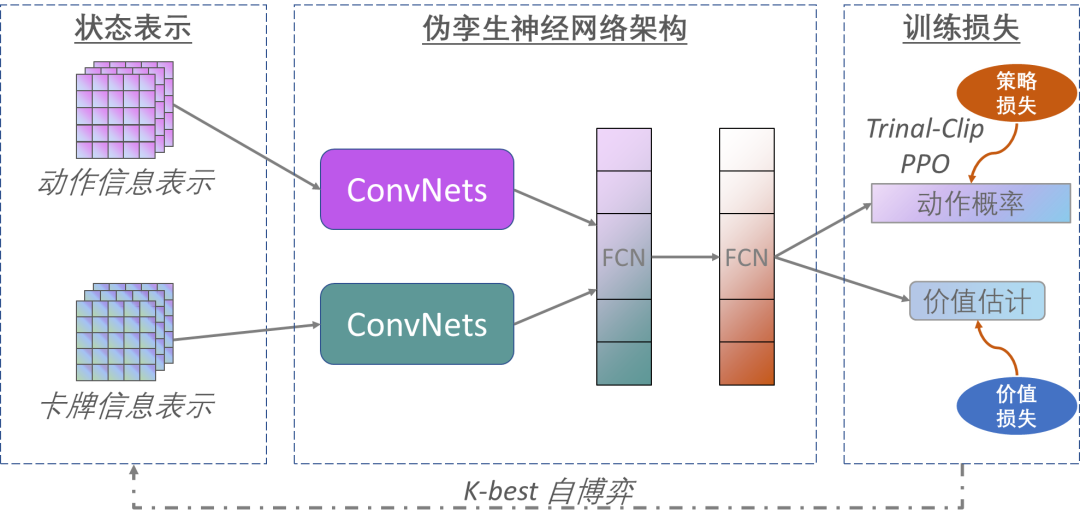
圖4:端到端學(xué)習(xí)德州撲克AI學(xué)習(xí)框架
高效的全狀態(tài)空間編碼:
已有德州撲克AI受限于CFR算法的處理能力,均需要對(duì)牌面狀態(tài)和動(dòng)作信息進(jìn)行壓縮,壓縮的好壞完全取決于對(duì)德?lián)漕I(lǐng)域知識(shí)的掌握程度,而且不可避免地造成信息的損失。AlphaHoldem對(duì)整個(gè)狀態(tài)空間進(jìn)行高效編碼,不利用德?lián)漕I(lǐng)域知識(shí)進(jìn)行信息壓縮。
對(duì)于卡牌信息,將其編碼成包含多個(gè)通道的張量,用來(lái)表示私有牌、公共牌等信息。對(duì)于動(dòng)作信息,AlphaHoldem同樣將其編碼為多通道張量,用來(lái)表示各玩家當(dāng)前及歷史的動(dòng)作信息。AlphaHoldem的多維張量狀態(tài)表示方法不僅完整地編碼了當(dāng)前及歷史的狀態(tài)信息,而且非常適合作為卷積神經(jīng)網(wǎng)絡(luò)的輸入進(jìn)行特征的學(xué)習(xí)。
Trinal-Clip PPO強(qiáng)化學(xué)習(xí):
由于信息不完美及不同對(duì)手的各種「詐唬」欺騙行為,使得德州撲克成為一種結(jié)果具有很強(qiáng)隨機(jī)性的游戲,這導(dǎo)致常見(jiàn)的強(qiáng)化學(xué)習(xí)算法(如PPO[9]等)訓(xùn)練過(guò)程很不穩(wěn)定且難以收斂。
AlphaHoldem提出了一種新型的Trinal-Clip PPO損失用于改進(jìn)深度強(qiáng)化學(xué)習(xí)過(guò)程的穩(wěn)定性,通過(guò)引入3個(gè)截?cái)鄥?shù)解決了PPO算法在優(yōu)勢(shì)函數(shù)小于零時(shí)損失值方差過(guò)大的問(wèn)題以及「全壓」等動(dòng)作造成的價(jià)值函數(shù)難估計(jì)的問(wèn)題。
整體上來(lái)說(shuō),Trinal-clip PPO損失有效緩解了德?lián)洳┺牡膹?qiáng)隨機(jī)性造成的策略訓(xùn)練不穩(wěn)定問(wèn)題,使AlphaHoldem訓(xùn)練得又快又好。
Best-K自博弈訓(xùn)練方法:
德?lián)溆螒虿煌呗灾g存在復(fù)雜的克制關(guān)系,這使得Naive自博弈方法[10]或是AlphaGo采用的Best-Win自博弈方法[3]很難在德?lián)溆螒蛑惺諗俊?/span>
然而使用AlphaStar的群體博弈PBT[11],神經(jīng)虛擬自博弈NFSP[12]等方法來(lái)訓(xùn)練德?lián)銩I會(huì)消耗比傳統(tǒng)CFR算法更多的計(jì)算資源。
為了有效地平衡訓(xùn)練效率和模型性能,AlphaHoldem采用了一種新型的Best-K自博弈方法。該方法通過(guò)在訓(xùn)練過(guò)程中測(cè)試歷史模型的性能,挑選出K個(gè)最好的模型與現(xiàn)在最新的模型對(duì)打,不斷通過(guò)強(qiáng)化學(xué)習(xí)提升自身性能。
性能測(cè)試
AlphaHoldem到底能達(dá)到什么水平呢?
我們將AlphaHoldem與當(dāng)前的高水平德?lián)銩I進(jìn)行了比較,發(fā)現(xiàn)AlphaHoldem都有明顯優(yōu)勢(shì)。經(jīng)過(guò)10萬(wàn)局的對(duì)抗,AlphaHoldem平均贏Slumbot[7](2018年世界計(jì)算機(jī)撲克大賽ACPC冠軍,現(xiàn)在還在進(jìn)化)111.56 mbb/局(每1000手牌贏多少個(gè)大盲注),贏DeepStack(課題組使用120 GPU卡訓(xùn)練3周復(fù)現(xiàn)的版本)16.91 mbb/局。
同時(shí),它可以達(dá)到人類(lèi)專(zhuān)業(yè)玩家水平,通過(guò)和4位專(zhuān)業(yè)玩家對(duì)抗1萬(wàn)局,AlphaHoldem平均贏專(zhuān)業(yè)玩家10.27 mbb/局。另外,AlphaHoldem在一臺(tái)包含1個(gè)AMD 2.00GHz CPU(64個(gè)核心)、8個(gè)NVIDIA TITAN V GPU的服務(wù)器上僅訓(xùn)練三天,在一個(gè)CPU核心下每次決策僅需4毫秒,做到了真正的又快又好。
AlphaHoldem接下來(lái)會(huì)接入到課題組自研的人機(jī)對(duì)抗平臺(tái)OpenHoldem[13](http://holdem.ia.ac.cn/)中供研究者開(kāi)放測(cè)試(圖5)。
OpenHoldem是學(xué)術(shù)界第一個(gè)開(kāi)放的大規(guī)模不完美信息博弈研究平臺(tái),包含了多維度評(píng)測(cè)指標(biāo)、高性能基準(zhǔn)AI以及公開(kāi)的在線(xiàn)測(cè)試環(huán)境。平臺(tái)支持人人對(duì)抗、機(jī)機(jī)對(duì)抗以及人機(jī)對(duì)抗等多種模式、支持AI分布式并行對(duì)抗、支持動(dòng)態(tài)測(cè)試請(qǐng)求響應(yīng)及資源分配、支持多用戶(hù)并發(fā)訪(fǎng)問(wèn)和跨終端統(tǒng)一登錄。
平臺(tái)目前已經(jīng)吸引了來(lái)自高校、研究所、互聯(lián)網(wǎng)企業(yè)等200余家單位的近500名注冊(cè)用戶(hù),并受到了國(guó)內(nèi)多家權(quán)威機(jī)構(gòu)和主流媒體的轉(zhuǎn)發(fā)報(bào)道。
 圖5:OpenHoldem在線(xiàn)不完美信息博弈對(duì)抗平臺(tái)首頁(yè)
圖5:OpenHoldem在線(xiàn)不完美信息博弈對(duì)抗平臺(tái)首頁(yè)
后續(xù)計(jì)劃
AlphaHoldem采用了端到端強(qiáng)化學(xué)習(xí)的框架,大大降低了現(xiàn)有德?lián)銩I所需的領(lǐng)域知識(shí)以及計(jì)算存儲(chǔ)資源消耗,并達(dá)到了人類(lèi)專(zhuān)業(yè)選手的水平。
該框架是一個(gè)通用的端到端學(xué)習(xí)框架,我們已經(jīng)在多人無(wú)限注德?lián)渖向?yàn)證了該框架的適用性,目前正在提升多人模型訓(xùn)練過(guò)程的學(xué)習(xí)性能。
我們還準(zhǔn)備將AlphaHoldem背后的技術(shù)應(yīng)用到更多不完美信息博弈問(wèn)題中,比如麻將、斗地主、橋牌等,同時(shí)也計(jì)劃進(jìn)行多人博弈策略空間的均衡結(jié)構(gòu)分析等研究?jī)?nèi)容。
相關(guān)論文信息
博弈學(xué)習(xí)研究組介紹
博弈學(xué)習(xí)研究組是中科院自動(dòng)化所下屬科研團(tuán)隊(duì),是中科院人工智能創(chuàng)新研究院的骨干研究力量。課題組負(fù)責(zé)人為興軍亮研究員。課題組現(xiàn)有正式員工9人,博士研究生7人,碩士研究生9人,形成了一支以青年科研骨干為主體的高水平、高素質(zhì)的科研隊(duì)伍。
研究組以計(jì)算機(jī)博弈為研究切入點(diǎn),通過(guò)將最新的機(jī)器學(xué)習(xí)技術(shù)引入到經(jīng)典博弈理論和模型之中,同時(shí)借鑒運(yùn)籌學(xué)、最優(yōu)化、算法設(shè)計(jì)等學(xué)科的研究方法和算法,形成具有鮮明交叉特點(diǎn)的技術(shù)研究體系;通過(guò)使用經(jīng)典博弈理論對(duì)博弈過(guò)程進(jìn)行建模,然后利用最新機(jī)器學(xué)習(xí)技術(shù)對(duì)模型的參數(shù)進(jìn)行學(xué)習(xí)更新,從而實(shí)現(xiàn)對(duì)復(fù)雜人機(jī)博弈問(wèn)題的可建模性、可計(jì)算性和可解釋性的結(jié)合。
課題組從2018年底開(kāi)始研究以德州撲克為代表的大規(guī)模不完美信息博弈問(wèn)題,在2020年公開(kāi)了學(xué)界首個(gè)大規(guī)模不完美信息博弈對(duì)抗平臺(tái)OpenHoldem,集成了高性能基準(zhǔn)AI、多維度評(píng)測(cè)協(xié)議、在線(xiàn)對(duì)抗評(píng)估等完整功能,支持人機(jī)、機(jī)機(jī)、人人、人機(jī)混合等對(duì)抗模式。相關(guān)研發(fā)工作的主要完成人員包括興軍亮研究員,李凱副研究員,博士生趙恩民、徐航、李金秋,碩士生閆仁業(yè)、吳哲等。
參考資料:
