30 分鐘學(xué)會(huì) XGBoost
一,xgboost和GBDT
xgboost是一種集成學(xué)習(xí)算法,屬于3類常用的集成方法(bagging,boosting,stacking)中的boosting算法類別。它是一個(gè)加法模型,基模型一般選擇樹模型,但也可以選擇其它類型的模型如邏輯回歸等。
xgboost屬于梯度提升樹(GBDT)模型這個(gè)范疇,GBDT的基本想法是讓新的基模型(GBDT以CART分類回歸樹為基模型)去擬合前面模型的偏差,從而不斷將加法模型的偏差降低。
相比于經(jīng)典的GBDT,xgboost做了一些改進(jìn),從而在效果和性能上有明顯的提升(劃重點(diǎn)面試常考)。
第一,GBDT將目標(biāo)函數(shù)泰勒展開到一階,而xgboost將目標(biāo)函數(shù)泰勒展開到了二階。保留了更多有關(guān)目標(biāo)函數(shù)的信息,對(duì)提升效果有幫助。
第二,GBDT是給新的基模型尋找新的擬合標(biāo)簽(前面加法模型的負(fù)梯度),而xgboost是給新的基模型尋找新的目標(biāo)函數(shù)(目標(biāo)函數(shù)關(guān)于新的基模型的二階泰勒展開)。
第三,xgboost加入了和葉子權(quán)重的L2正則化項(xiàng),因而有利于模型獲得更低的方差。
第四,xgboost增加了自動(dòng)處理缺失值特征的策略。通過(guò)把帶缺失值樣本分別劃分到左子樹或者右子樹,比較兩種方案下目標(biāo)函數(shù)的優(yōu)劣,從而自動(dòng)對(duì)有缺失值的樣本進(jìn)行劃分,無(wú)需對(duì)缺失特征進(jìn)行填充預(yù)處理。
此外,xgboost還支持候選分位點(diǎn)切割,特征并行等,可以提升性能。
二,xgboost基本原理
下面從假設(shè)空間,目標(biāo)函數(shù),優(yōu)化算法3個(gè)角度對(duì)xgboost的原理進(jìn)行概括性的介紹。
1,假設(shè)空間
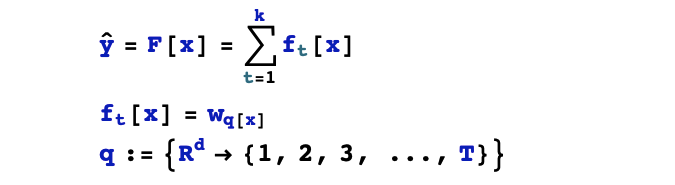


2,目標(biāo)函數(shù)

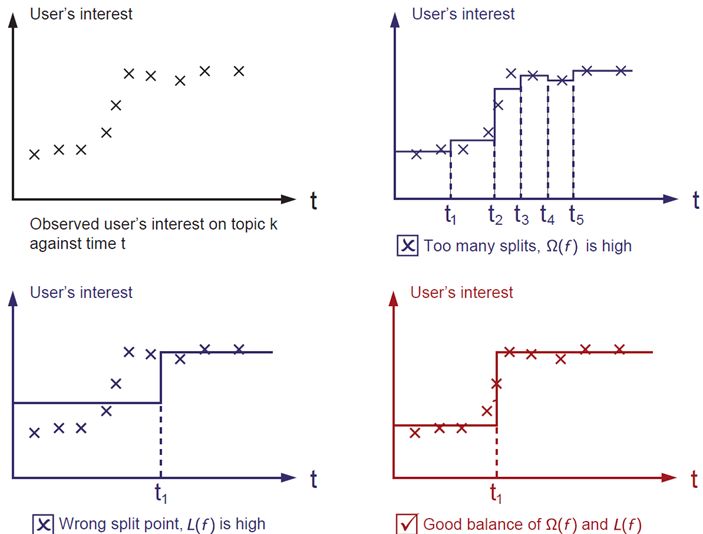
3,優(yōu)化算法
基本思想:貪心法,逐棵樹進(jìn)行學(xué)習(xí),每棵樹擬合之前模型的偏差。
三,第t棵樹學(xué)什么?
要完成構(gòu)建xgboost模型,我們需要確定以下一些事情。
1,如何boost? 如果已經(jīng)得到了前面t-1棵樹構(gòu)成的加法模型,如何確定第t棵樹的學(xué)習(xí)目標(biāo)?
2,如何生成樹?已知第t棵樹的學(xué)習(xí)目標(biāo)的前提下,如何學(xué)習(xí)這棵樹?具體又包括是否進(jìn)行分裂?選擇哪個(gè)特征進(jìn)行分裂?選擇什么分裂點(diǎn)位?分裂的葉子節(jié)點(diǎn)如何取值?
我們首先考慮如何boost的問(wèn)題,順便解決分裂的葉子節(jié)點(diǎn)如何取值的問(wèn)題。
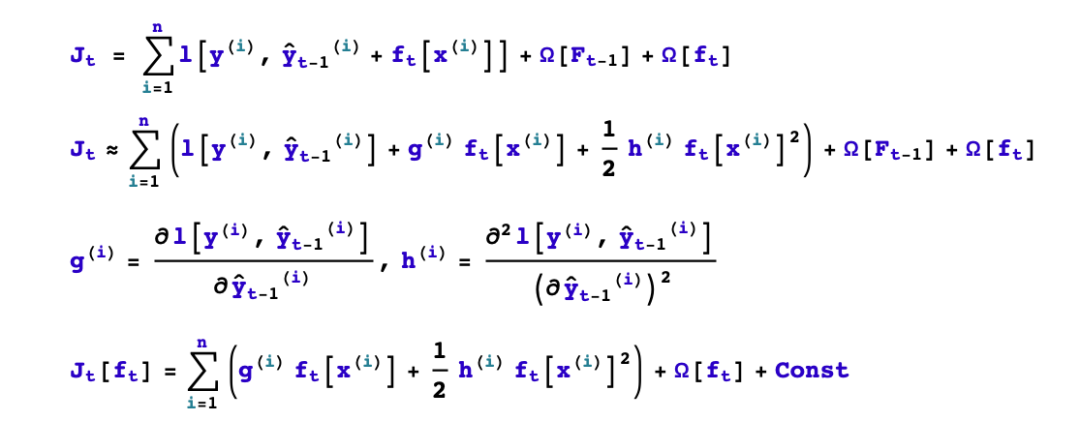


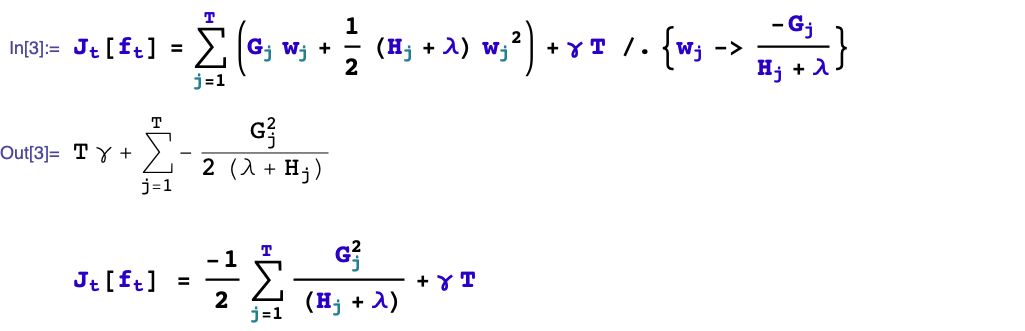
四,如何生成第t棵樹?
xgboost采用二叉樹,開始的時(shí)候,全部樣本都在一個(gè)葉子節(jié)點(diǎn)上。然后葉子節(jié)點(diǎn)不斷通過(guò)二分裂,逐漸生成一棵樹。
xgboost使用levelwise的生成策略,即每次對(duì)同一層級(jí)的全部葉子節(jié)點(diǎn)嘗試進(jìn)行分裂。
對(duì)葉子節(jié)點(diǎn)分裂生成樹的過(guò)程有幾個(gè)基本的問(wèn)題:是否要進(jìn)行分裂?選擇哪個(gè)特征進(jìn)行分裂?在特征的什么點(diǎn)位進(jìn)行分裂?以及分裂后新的葉子上取什么值?
葉子節(jié)點(diǎn)的取值問(wèn)題前面已經(jīng)解決了。我們重點(diǎn)討論幾個(gè)剩下的問(wèn)題。
1,是否要進(jìn)行分裂?
根據(jù)樹的剪枝策略的不同,這個(gè)問(wèn)題有兩種不同的處理。如果是預(yù)剪枝策略,那么只有當(dāng)存在某種分裂方式使得分裂后目標(biāo)函數(shù)發(fā)生下降,才會(huì)進(jìn)行分裂。
但如果是后剪枝策略,則會(huì)無(wú)條件進(jìn)行分裂,等樹生成完成后,再?gòu)纳隙聶z查樹的各個(gè)分枝是否對(duì)目標(biāo)函數(shù)下降產(chǎn)生正向貢獻(xiàn)從而進(jìn)行剪枝。
xgboost采用預(yù)剪枝策略,只有分裂后的增益大于0才會(huì)進(jìn)行分裂。
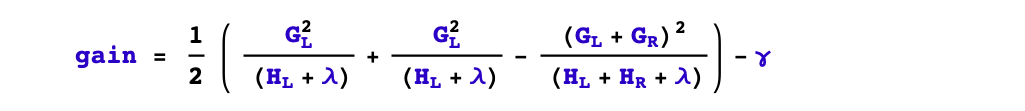
2,選擇什么特征進(jìn)行分裂?
xgboost采用特征并行的方法進(jìn)行計(jì)算選擇要分裂的特征,即用多個(gè)線程,嘗試把各個(gè)特征都作為分裂的特征,找到各個(gè)特征的最優(yōu)分割點(diǎn),計(jì)算根據(jù)它們分裂后產(chǎn)生的增益,選擇增益最大的那個(gè)特征作為分裂的特征。
3,選擇什么分裂點(diǎn)位?
xgboost選擇某個(gè)特征的分裂點(diǎn)位的方法有兩種,一種是全局掃描法,另一種是候選分位點(diǎn)法。
全局掃描法將所有樣本該特征的取值按從小到大排列,將所有可能的分裂位置都試一遍,找到其中增益最大的那個(gè)分裂點(diǎn),其計(jì)算復(fù)雜度和葉子節(jié)點(diǎn)上的樣本特征不同的取值個(gè)數(shù)成正比。
而候選分位點(diǎn)法是一種近似算法,僅選擇常數(shù)個(gè)(如256個(gè))候選分裂位置,然后從候選分裂位置中找出最優(yōu)的那個(gè)。
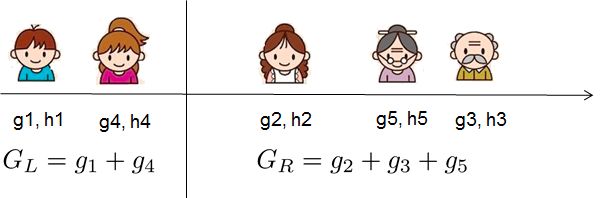
五,xgboost使用范例
可以使用pip 安裝xgboost
pip?install?xgboost
以下為xgboost的使用范例,可以參照修改使用。
import?numpy?as?np
import?pandas?as?pd
import?xgboost?as?xgb
import?datetime
from?sklearn?import?datasets
from?sklearn.model_selection?import?train_test_split
from?sklearn.metrics?import?accuracy_score
def?printlog(info):
????nowtime?=?datetime.datetime.now().strftime('%Y-%m-%d?%H:%M:%S')
????print("\n"+"=========="*8?+?"%s"%nowtime)
????print(info+'...\n\n')
????
????
#================================================================================
#?一,讀取數(shù)據(jù)
#================================================================================
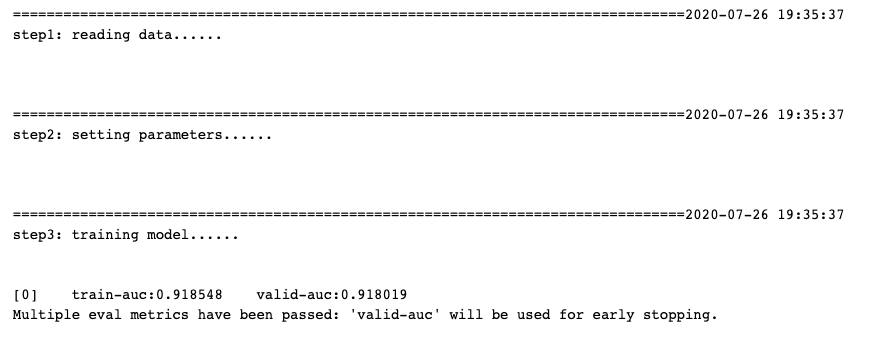
printlog("step1:?reading?data...")
#?讀取dftrain,dftest
breast?=?datasets.load_breast_cancer()
df?=?pd.DataFrame(breast.data,columns?=?[x.replace('?','_')?for?x?in?breast.feature_names])
df['label']?=?breast.target
dftrain,dftest?=?train_test_split(df)
xgb_train?=?xgb.DMatrix(dftrain.drop("label",axis?=?1),dftrain[["label"]])
xgb_valid?=?xgb.DMatrix(dftest.drop("label",axis?=?1),dftest[["label"]])
#================================================================================
#?二,設(shè)置參數(shù)
#================================================================================
printlog("step2:?setting?parameters...")
???????????????????????????????
num_boost_round?=?100???????????????????
early_stopping_rounds?=?20
#?配置xgboost模型參數(shù)
params_dict?=?dict()
#?booster參數(shù)
params_dict['learning_rate']?=?0.05??????#?學(xué)習(xí)率,通常越小越好。
params_dict['objective']?=?'binary:logistic'
#?tree參數(shù)
params_dict['max_depth']?=?3??????????????#?樹的深度,通常取值在[3,10]之間
params_dict['min_child_weight']=?30???????#?最小葉子節(jié)點(diǎn)樣本權(quán)重和,越大模型越保守。
params_dict['gamma']=?0???????????????????#?節(jié)點(diǎn)分裂所需的最小損失函數(shù)下降值,越大模型越保守。
params_dict['subsample']=?0.8?????????????#?橫向采樣,樣本采樣比例,通常取值在?[0.5,1]之間?
params_dict['colsample_bytree']?=?1.0?????#?縱向采樣,特征采樣比例,通常取值在?[0.5,1]之間?
params_dict['tree_method']?=?'hist'???????#?構(gòu)建樹的策略,可以是auto,?exact,?approx,?hist
#?regulazation參數(shù)?
#?Omega(f)?=?gamma*T?+?reg_alpha*?sum(abs(wj))?+?reg_lambda*?sum(wj**2)??
params_dict['reg_alpha']?=?0.0????????????#L1 正則化項(xiàng)的權(quán)重系數(shù),越大模型越保守,通常取值在[0,1]之間。
params_dict['reg_lambda']?=?1.0???????????#L2 正則化項(xiàng)的權(quán)重系數(shù),越大模型越保守,通常取值在[1,100]之間。
#?其他參數(shù)
params_dict['eval_metric']?=?'auc'
params_dict['silent']?=?1
params_dict['nthread']?=?2
params_dict['scale_pos_weight']?=?1???????#不平衡樣本時(shí)設(shè)定為正值可以使算法更快收斂。
params_dict['seed']?=?0
#================================================================================
#?三,訓(xùn)練模型
#================================================================================
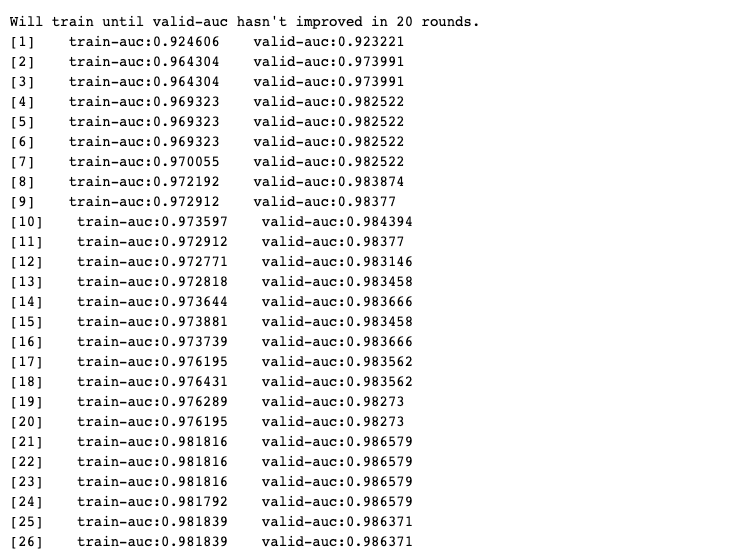
printlog("step3:?training?model...")
result?=?{}
watchlist?=?[(xgb_train,?'train'),(xgb_valid,'valid')]?
bst?=?xgb.train(params?=?params_dict,?dtrain?=?xgb_train,?
????????????????num_boost_round?=?num_boost_round,?
????????????????verbose_eval=?1,
????????????????evals?=?watchlist,
????????????????early_stopping_rounds=early_stopping_rounds,
????????????????evals_result?=?result)
#================================================================================
#?四,評(píng)估模型
#================================================================================
printlog("step4:?evaluating?model?...")
y_pred_train?=?bst.predict(xgb_train,?ntree_limit=bst.best_iteration)
y_pred_test?=?bst.predict(xgb_valid,?ntree_limit=bst.best_iteration)
print('train?accuracy:?{:.5}?'.format(accuracy_score(dftrain['label'],?y_pred_train>0.5)))
print('valid?accuracy:?{:.5}?\n'.format(accuracy_score(dftest['label'],?y_pred_test>0.5)))
%matplotlib?inline
%config?InlineBackend.figure_format?=?'svg'
dfresult?=?pd.DataFrame({(dataset+'_'+feval):?result[dataset][feval]?
???????????????for?dataset?in?["train","valid"]?for?feval?in?['auc']})
dfresult.index?=?range(1,len(dfresult)+1)?
ax?=?dfresult.plot(kind='line',figsize=(8,6),fontsize?=?12,grid?=?True)?
ax.set_title("Metric?During?Training",fontsize?=?12)
ax.set_xlabel("Iterations",fontsize?=?12)
ax.set_ylabel("auc",fontsize?=?12)
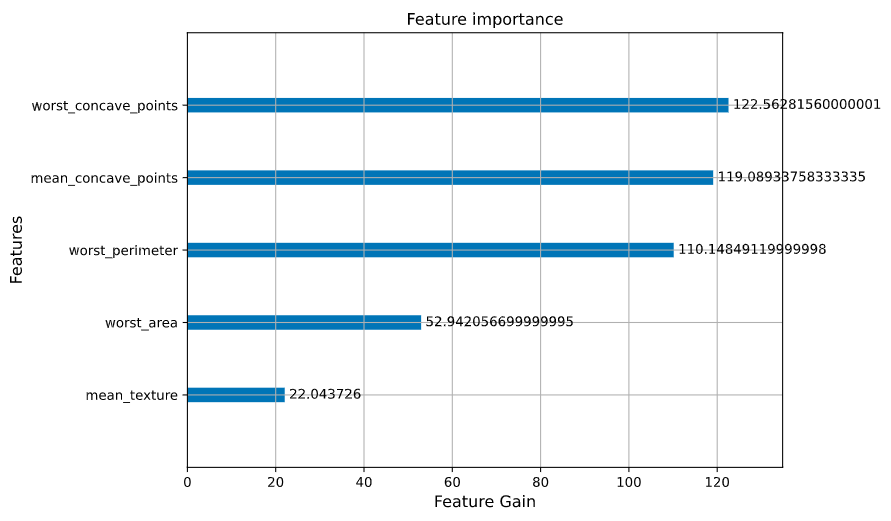
ax?=?xgb.plot_importance(bst,importance_type?=?"gain",xlabel='Feature?Gain')
ax.set_xlabel("Feature?Gain",fontsize?=?12)
ax.set_ylabel("Features",fontsize?=?12)
fig?=?ax.get_figure()?
fig.set_figwidth(8)
fig.set_figheight(6)
#================================================================================
#?五,保存模型
#================================================================================
printlog("step5:?saving?model?...")
model_dir?=?"data/bst.model"
print("model_dir:?%s"%model_dir)
bst.save_model(model_dir)
bst_loaded?=?xgb.Booster(model_file=model_dir)
printlog("task?end...")