
啥?我寫(xiě)的一條SQL讓公司網(wǎng)站癱瘓了...
一條慢查詢(xún)會(huì)造成什么后果?之前我一直覺(jué)得不就是返回?cái)?shù)據(jù)會(huì)慢一些么,用戶(hù)體驗(yàn)變差?

其實(shí)遠(yuǎn)遠(yuǎn)不止,我經(jīng)歷過(guò)幾次線上事故,有一次就是由一條 SQL 慢查詢(xún)導(dǎo)致的。

那次是一條 SQL 查詢(xún)耗時(shí)達(dá)到 2-3 秒「沒(méi)有命中索引,導(dǎo)致全表掃描」,由于是高頻查詢(xún),并發(fā)一起來(lái)很快就把 DB 線程池打滿(mǎn)了,導(dǎo)致大量查詢(xún)請(qǐng)求堆積,DB 服務(wù)器 CPU 長(zhǎng)時(shí)間 100%+,大量請(qǐng)求 timeout...
最終系統(tǒng)崩潰,老板登場(chǎng)!可見(jiàn),團(tuán)隊(duì)如果對(duì)慢查詢(xún)不引起足夠的重視,風(fēng)險(xiǎn)是很大的。

慢查詢(xún),顧名思義,執(zhí)行很慢的查詢(xún)。有多慢?超過(guò) long_query_time 參數(shù)設(shè)定的時(shí)間閾值(默認(rèn) 10s),就被認(rèn)為是慢的,是需要優(yōu)化的。慢查詢(xún)被記錄在慢查詢(xún)?nèi)罩纠铩?/span>
慢查詢(xún)?nèi)罩灸J(rèn)是不開(kāi)啟的,如果你需要優(yōu)化 SQL 語(yǔ)句,就可以開(kāi)啟這個(gè)功能,它可以讓你很容易地知道哪些語(yǔ)句是需要優(yōu)化的(想想一個(gè) SQL 要 10s 就可怕)。好了,下面我們就一起來(lái)看看怎么處理慢查詢(xún)。
慢查詢(xún)配置
開(kāi)啟慢查詢(xún)
MySQL 支持通過(guò)以下方式開(kāi)啟慢查詢(xún):
輸入命令開(kāi)啟慢查詢(xún)(臨時(shí)),在 MySQL 服務(wù)重啟后會(huì)自動(dòng)關(guān)閉。
配置 my.cnf(Windows 是 my.ini)系統(tǒng)文件開(kāi)啟,修改配置文件是持久化開(kāi)啟慢查詢(xún)的方式。
方式一:通過(guò)命令開(kāi)啟慢查詢(xún)
show?variables?like?'%slow_query_log%';
mysql>?show?variables?like?'%slow_query_log%';
+---------------------+-----------------------------------+
|?Variable_name???????|?Value?????????????????????????????|
+---------------------+-----------------------------------+
|?slow_query_log??????|?OFF???????????????????????????????|
|?slow_query_log_file?|?/var/lib/mysql/localhost-slow.log?|
+---------------------+-----------------------------------+
2?rows?in?set?(0.01?sec)
set?global?slow_query_log='ON';
步驟 3:指定記錄慢查詢(xún)?nèi)罩?SQL 執(zhí)行時(shí)間得閾值(long_query_time 單位:秒,默認(rèn) 10 秒)。
如下我設(shè)置成了 1 秒,執(zhí)行時(shí)間超過(guò) 1 秒的 SQL 將記錄到慢查詢(xún)?nèi)罩局校?br>
set?global?long_query_time=1;
show?variables?like?'%slow_query_log_file%';
mysql>?show?variables?like?'%slow_query_log_file%';
+---------------------+-----------------------------------+
|?Variable_name???????|?Value?????????????????????????????|
+---------------------+-----------------------------------+
|?slow_query_log_file?|?/var/lib/mysql/localhost-slow.log?|
+---------------------+-----------------------------------+
1?row?in?set?(0.01?sec)
slow_query_log_file 指定慢查詢(xún)?nèi)罩镜拇鎯?chǔ)路徑及文件(默認(rèn)和數(shù)據(jù)文件放一起)。
步驟 5:核對(duì)慢查詢(xún)開(kāi)啟狀態(tài),需要退出當(dāng)前 MySQL 終端,重新登錄即可刷新。
配置了慢查詢(xún)后,它會(huì)記錄以下符合條件的 SQL:
查詢(xún)語(yǔ)句
數(shù)據(jù)修改語(yǔ)句
已經(jīng)回滾的 SQL
方式二:通過(guò)配置 my.cnf(Windows 是 my.ini)系統(tǒng)文件開(kāi)啟(版本:MySQL 5.5 及以上)。
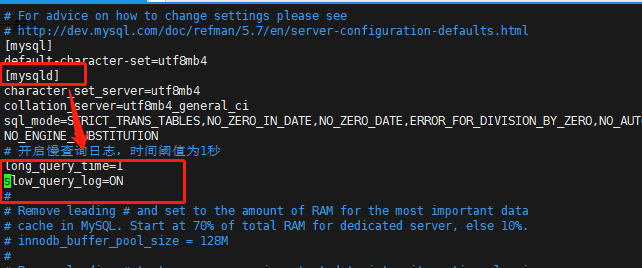
#?開(kāi)啟慢查詢(xún)功能
slow_query_log=ON
#?指定記錄慢查詢(xún)?nèi)罩維QL執(zhí)行時(shí)間得閾值
long_query_time=1
#?選填,默認(rèn)數(shù)據(jù)文件路徑
#?slow_query_log_file=/var/lib/mysql/localhost-slow.log
mysql>?show?variables?like?'%_query_%';
+------------------------------+-----------------------------------+
|?Variable_name????????????????|?Value?????????????????????????????|
+------------------------------+-----------------------------------+
|?have_query_cache?????????????|?YES???????????????????????????????|
|?long_query_time??????????????|?1.000000??????????????????????????|
|?slow_query_log???????????????|?ON????????????????????????????????|
|?slow_query_log_file??????????|?/var/lib/mysql/localhost-slow.log?|
+------------------------------+-----------------------------------+
6?rows?in?set?(0.01?sec)
慢查詢(xún)?nèi)罩窘榻B
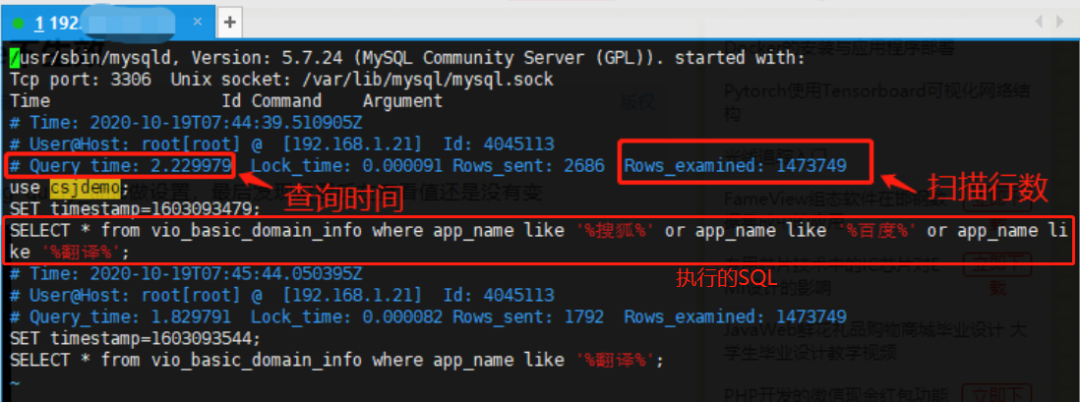
如上圖,是執(zhí)行時(shí)間超過(guò) 1 秒的 SQL 語(yǔ)句(測(cè)試):
第一行:記錄時(shí)間。
第二行:用戶(hù)名 、用戶(hù)的 IP 信息、線程 ID 號(hào)。
第三行:執(zhí)行花費(fèi)的時(shí)間【單位:秒】、執(zhí)行獲得鎖的時(shí)間、獲得的結(jié)果行數(shù)、掃描的數(shù)據(jù)行數(shù)。
第四行:這 SQL 執(zhí)行的時(shí)間戳。
第五行:具體的 SQL 語(yǔ)句。
Explain 分析慢查詢(xún) SQL
分析 MySQL 慢查詢(xún)?nèi)罩荆?Explain 關(guān)鍵字可以模擬優(yōu)化器執(zhí)行 SQL 查詢(xún)語(yǔ)句,來(lái)分析 SQL 慢查詢(xún)語(yǔ)句。
下面我們的測(cè)試表是一張 137w 數(shù)據(jù)的 app 信息表,我們來(lái)舉例分析一下。
SQL 示例如下:
--?1.185s
SELECT?*?from?vio_basic_domain_info?where?app_name?like?'%翻譯%'?;
我們用 Explain 分析結(jié)果如下表,根據(jù)表信息可知:該 SQL 沒(méi)有用到字段 app_name 上的索引,查詢(xún)類(lèi)型是全表掃描,掃描行數(shù) 137w。
mysql>?EXPLAIN?SELECT?*?from?vio_basic_domain_info?where?app_name?like?'%翻譯%'?;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type?|?possible_keys?|?key??|?key_len?|?ref??|?rows????|?filtered?|?Extra???????|
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
|??1?|?SIMPLE??????|?vio_basic_domain_info?|?NULL???????|?ALL??|?NULL??????????|?NULL?|?NULL????|?NULL?|?1377809?|????11.11?|?Using?where?|
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1?row?in?set,?1?warning?(0.00?sec)
當(dāng)這條 SQL 使用到索引時(shí),SQL 如下:查詢(xún)耗時(shí):0.156s,查到 141 條數(shù)據(jù):
--?0.156s
SELECT?*?from?vio_basic_domain_info?where?app_name?like?'翻譯%'?;
由于查詢(xún)的列不全在索引中(select *),因此回表了一次,取了其他列的數(shù)據(jù)。
mysql>?EXPLAIN?SELECT?*?from?vio_basic_domain_info?where?app_name?like?'翻譯%'?;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type??|?possible_keys?|?key??????????|?key_len?|?ref??|?rows?|?filtered?|?Extra?????????????????|
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
|??1?|?SIMPLE??????|?vio_basic_domain_info?|?NULL???????|?range?|?idx_app_name??|?idx_app_name?|?515?????|?NULL?|??141?|???100.00?|?Using?index?condition?|
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
1?row?in?set,?1?warning?(0.00?sec)
當(dāng)這條 SQL 使用到覆蓋索引時(shí),SQL 如下:查詢(xún)耗時(shí):0.091s,查到 141 條數(shù)據(jù)。
--?0.091s
SELECT?app_name?from?vio_basic_domain_info?where?app_name?like?'翻譯%'?;
Explain 分析結(jié)果如下表;根據(jù)表信息可知:和上面的 SQL 一樣使用到了索引,由于查詢(xún)列就包含在索引列中,又省去了 0.06s 的回表時(shí)間。
mysql>?EXPLAIN?SELECT?app_name?from?vio_basic_domain_info?where?app_name?like?'翻譯%'?;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type??|?possible_keys?|?key??????????|?key_len?|?ref??|?rows?|?filtered?|?Extra????????????????????|
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|??1?|?SIMPLE??????|?vio_basic_domain_info?|?NULL???????|?range?|?idx_app_name??|?idx_app_name?|?515?????|?NULL?|??141?|???100.00?|?Using?where;?Using?index?|
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
1?row?in?set,?1?warning?(0.00?sec)
各列屬性的簡(jiǎn)介
各列屬性的簡(jiǎn)介如下:
id:SELECT 的查詢(xún)序列號(hào),體現(xiàn)執(zhí)行優(yōu)先級(jí),如果是子查詢(xún),id的序號(hào)會(huì)遞增,id 值越大優(yōu)先級(jí)越高,越先被執(zhí)行。
select_type:表示查詢(xún)的類(lèi)型。
table:輸出結(jié)果集的表,如設(shè)置了別名,也會(huì)顯示。
partitions:匹配的分區(qū)。
type:對(duì)表的訪問(wèn)方式。
possible_keys:表示查詢(xún)時(shí),可能使用的索引。
key:表示實(shí)際使用的索引。
key_len:索引字段的長(zhǎng)度。
ref:列與索引的比較。
rows:掃描出的行數(shù)(估算的行數(shù))。
filtered:按表?xiàng)l件過(guò)濾的行百分比。
Extra:執(zhí)行情況的描述和說(shuō)明。
以上標(biāo)星的幾類(lèi)是我們優(yōu)化慢查詢(xún)時(shí)常用到的。
慢查詢(xún)分析常用到的屬性
①type
對(duì)表訪問(wèn)方式,表示 MySQL 在表中找到所需行的方式,又稱(chēng)“訪問(wèn)類(lèi)型”。
存在的類(lèi)型有:ALL、index、range、ref、eq_ref、const、system、NULL(從左到右,性能從低到高)。
ALL:(Full Table Scan)MySQL 將遍歷全表以找到匹配的行,常說(shuō)的全表掃描。
Index:(Full Index Scan)Index 與 ALL 區(qū)別為 Index 類(lèi)型只遍歷索引樹(shù)。
Range:只檢索給定范圍的行,使用一個(gè)索引來(lái)選擇行。
②key
強(qiáng)制使用一個(gè)索引:FORCE INDEX (index_name)、USE INDEX (index_name)。
強(qiáng)制忽略一個(gè)索引:IGNORE INDEX (index_name)。
③rows
④Extra
Using index:查詢(xún)的列被索引覆蓋,并且 where 篩選條件是索引的是前導(dǎo)列,Extra 中為 Using index。意味著通過(guò)索引查找就能直接找到符合條件的數(shù)據(jù),無(wú)須回表。
注:前導(dǎo)列一般指聯(lián)合索引中的第一列或“前幾列”,以及單列索引的情況;這里為了方便理解我統(tǒng)稱(chēng)為前導(dǎo)列。
Using where:說(shuō)明 MySQL 服務(wù)器將在存儲(chǔ)引擎檢索行后再進(jìn)行過(guò)濾;即沒(méi)有用到索引,回表查詢(xún)。
可能的原因:
查詢(xún)的列未被索引覆蓋。
where 篩選條件非索引的前導(dǎo)列或無(wú)法正確使用到索引。
一些慢查詢(xún)優(yōu)化經(jīng)驗(yàn)分享
優(yōu)化 LIMIT 分頁(yè)
如果有對(duì)應(yīng)的索引,通常效率會(huì)不錯(cuò),否則 MySQL 需要做大量的文件排序操作。
一個(gè)非常令人頭疼問(wèn)題就是當(dāng)偏移量非常大的時(shí)候,例如可能是 limit 1000000,10 這樣的查詢(xún)。
這是 MySQL 需要查詢(xún) 1000000 條然后只返回最后 10 條,前面的 1000000 條記錄都將被舍棄,這樣的代價(jià)很高,會(huì)造成慢查詢(xún)。
對(duì)于下面的查詢(xún):
--?執(zhí)行耗時(shí):1.379s
SELECT?*?from?vio_basic_domain_info?LIMIT?1000000,10;
Explain 分析結(jié)果:
mysql>?EXPLAIN?SELECT?*?from?vio_basic_domain_info?LIMIT?1000000,10;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type?|?possible_keys?|?key??|?key_len?|?ref??|?rows????|?filtered?|?Extra?|
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
|??1?|?SIMPLE??????|?vio_basic_domain_info?|?NULL???????|?ALL??|?NULL??????????|?NULL?|?NULL????|?NULL?|?1377809?|???100.00?|?NULL??|
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+---------+----------+-------+
1?row?in?set,?1?warning?(0.00?sec)
那么如果我們下一次的查詢(xún)能從前一次查詢(xún)結(jié)束后標(biāo)記的位置開(kāi)始查找,找到滿(mǎn)足條件的 10 條記錄,并記下下一次查詢(xún)應(yīng)該開(kāi)始的位置,以便于下一次查詢(xún)能直接從該位置開(kāi)始。
這樣就不必每次查詢(xún)都先從整個(gè)表中先找到滿(mǎn)足條件的前 M 條記錄,舍棄掉,再?gòu)?M+1 開(kāi)始再找到 10 條滿(mǎn)足條件的記錄了。
思路一:構(gòu)造覆蓋索引
通過(guò)修改 SQL,使用上覆蓋索引,比如我需要只查詢(xún)表中的 app_name、createTime 等少量字段,那么我秩序在 app_name、createTime 字段設(shè)置聯(lián)合索引,即可實(shí)現(xiàn)覆蓋索引,無(wú)需全表掃描。
適用于查詢(xún)列較少的場(chǎng)景,查詢(xún)列數(shù)過(guò)多的不推薦,耗時(shí):0.390s。
mysql>?EXPLAIN?SELECT?app_name,createTime?from?vio_basic_domain_info?LIMIT?1000000,10;
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type??|?possible_keys?|?key??????????|?key_len?|?ref??|?rows????|?filtered?|?Extra???????|
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
|??1?|?SIMPLE??????|?vio_basic_domain_info?|?NULL???????|?index?|?NULL??????????|?idx_app_name?|?515?????|?NULL?|?1377809?|???100.00?|?Using?index?|
+----+-------------+-----------------------+------------+-------+---------------+--------------+---------+------+---------+----------+-------------+
1?row?in?set,?1?warning?(0.00?sec)
思路二:優(yōu)化 offset
無(wú)法用上覆蓋索引,那么重點(diǎn)是想辦法快速過(guò)濾掉前 100w 條數(shù)據(jù)。我們可以利用自增主鍵有序的條件,先查詢(xún)出第 1000001 條數(shù)據(jù)的 id 值,再往后查 10 行。
SELECT?*?from?vio_basic_domain_info?where?
??id?>=(SELECT?id?from?vio_basic_domain_info?ORDER?BY?id?limit?1000000,1)?limit?10;
原理:先基于索引查詢(xún)出第 1000001 條數(shù)據(jù)對(duì)應(yīng)的主鍵 id 的值,然后直接通過(guò)該 id 的值直接查詢(xún)?cè)?id 后面的 10 條數(shù)據(jù)。
mysql>?EXPLAIN?SELECT?*?from?vio_basic_domain_info?where?id?>=(SELECT?id?from?vio_basic_domain_info?ORDER?BY?id?limit?1000000,1)?limit?10;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type??|?possible_keys?|?key?????|?key_len?|?ref??|?rows????|?filtered?|?Extra???????|
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
|??1?|?PRIMARY?????|?vio_basic_domain_info?|?NULL???????|?range?|?PRIMARY???????|?PRIMARY?|?8???????|?NULL?|??????10?|???100.00?|?Using?where?|
|??2?|?SUBQUERY????|?vio_basic_domain_info?|?NULL???????|?index?|?NULL??????????|?PRIMARY?|?8???????|?NULL?|?1000001?|???100.00?|?Using?index?|
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
2?rows?in?set,?1?warning?(0.40?sec)
方法三:“延遲關(guān)聯(lián)”
耗時(shí):0.439s,延遲關(guān)聯(lián)適用于數(shù)量級(jí)較大的表。
SELECT?*?from?vio_basic_domain_info?inner?join?(select?id?from?vio_basic_domain_info?order?by?id?limit?1000000,10)?as?myNew?using(id);
這里我們利用到了覆蓋索引+延遲關(guān)聯(lián)查詢(xún),相當(dāng)于先只查詢(xún) id 列,利用覆蓋索引快速查到該頁(yè)的 10 條數(shù)據(jù) id,然后再把返回的 10 條 id 拿到表中通過(guò)主鍵索引二次查詢(xún)。(表數(shù)據(jù)增速快的情況對(duì)該方法影響較小)
mysql>?EXPLAIN?SELECT?*?from?vio_basic_domain_info?inner?join?(select?id?from?vio_basic_domain_info?order?by?id?limit?1000000,10)?as?myNew?using(id);
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
|?id?|?select_type?|?table?????????????????|?partitions?|?type???|?possible_keys?|?key?????|?key_len?|?ref??????|?rows????|?filtered?|?Extra???????|
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
|??1?|?PRIMARY?????|?????????????|?NULL???????|?ALL????|?NULL??????????|?NULL????|?NULL????|?NULL?????|?1000010?|???100.00?|?NULL????????|
|??1?|?PRIMARY?????|?vio_basic_domain_info?|?NULL???????|?eq_ref?|?PRIMARY???????|?PRIMARY?|?8???????|?myNew.id?|???????1?|???100.00?|?NULL????????|
|??2?|?DERIVED?????|?vio_basic_domain_info?|?NULL???????|?index??|?NULL??????????|?PRIMARY?|?8???????|?NULL?????|?1000010?|???100.00?|?Using?index?|
+----+-------------+-----------------------+------------+--------+---------------+---------+---------+----------+---------+----------+-------------+
3?rows?in?set,?1?warning?(0.00?sec)
排查索引沒(méi)起作用的情況
如下:
SELECT?*?FROM?t?WHERE?username?LIKE?'%陳%'
優(yōu)化方式:盡量在字段后面使用模糊查詢(xún)。如下:
SELECT?*?FROM?t?WHERE?username?LIKE?'陳%'
使用 MySQL 內(nèi)置函數(shù) INSTR(str,substr)來(lái)匹配,作用類(lèi)似于 Java 中的 indexOf(),查詢(xún)字符串出現(xiàn)的角標(biāo)位置。
使用 FullText 全文索引,用 match against 檢索。
數(shù)據(jù)量較大的情況,建議引用 ElasticSearch、Solr,億級(jí)數(shù)據(jù)量檢索速度秒級(jí)。
當(dāng)表數(shù)據(jù)量較少(幾千條兒那種),別整花里胡哨的,直接用 like '%xx%'。
②盡量避免使用 not in,會(huì)導(dǎo)致引擎走全表掃描。建議用 not exists 代替
--?不走索引
SELECT?*?FROM?t?WHERE?name?not?IN?('提莫','隊(duì)長(zhǎng)');
--?走索引
select?*?from?t?as?t1?where?not?exists?(select?*?from?t?as?t2?where?name?IN?('提莫','隊(duì)長(zhǎng)')?and?t1.id?=?t2.id);
③盡量避免使用 or,會(huì)導(dǎo)致數(shù)據(jù)庫(kù)引擎放棄索引進(jìn)行全表掃描
SELECT?*?FROM?t?WHERE?id?=?1?OR?id?=?3
SELECT?*?FROM?t?WHERE?id?=?1
???UNION
SELECT?*?FROM?t?WHERE?id?=?3
④盡量避免進(jìn)行 null 值的判斷,會(huì)導(dǎo)致數(shù)據(jù)庫(kù)引擎放棄索引進(jìn)行全表掃描
SELECT?*?FROM?t?WHERE?score?IS?NULL
SELECT?*?FROM?t?WHERE?score?=?0
⑤盡量避免在 where 條件中等號(hào)的左側(cè)進(jìn)行表達(dá)式、函數(shù)操作,會(huì)導(dǎo)致數(shù)據(jù)庫(kù)引擎放棄索引進(jìn)行全表掃描
可以將表達(dá)式、函數(shù)操作移動(dòng)到等號(hào)右側(cè)。如下:
--?全表掃描
SELECT?*?FROM?T?WHERE?score/10?=?9
--?走索引
SELECT?*?FROM?T?WHERE?score?=?10*9
⑥當(dāng)數(shù)據(jù)量大時(shí),避免使用 where 1=1 的條件。通常為了方便拼裝查詢(xún)條件,我們會(huì)默認(rèn)使用該條件,數(shù)據(jù)庫(kù)引擎會(huì)放棄索引進(jìn)行全表掃描
SELECT?username,?age,?sex?FROM?T?WHERE?1=1
優(yōu)化方式:用代碼拼裝 SQL 時(shí)進(jìn)行判斷,沒(méi) where 條件就去掉 where,有 where 條件就加 and。
⑦查詢(xún)條件不能用 <> 或者 !=
使用索引列作為條件進(jìn)行查詢(xún)時(shí),需要避免使用<>或者!=等判斷條件。
如確實(shí)業(yè)務(wù)需要,使用到不等于符號(hào),需要在重新評(píng)估索引建立,避免在此字段上建立索引,改由查詢(xún)條件中其他索引字段代替。
⑧where 條件僅包含復(fù)合索引非前導(dǎo)列
如:復(fù)合(聯(lián)合)索引包含 key_part1,key_part2,key_part3 三列,但 SQL 語(yǔ)句沒(méi)有包含索引前置列"key_part1",按照 MySQL 聯(lián)合索引的最左匹配原則,不會(huì)走聯(lián)合索引。
--?不走索引
select?col1?from?table?where?key_part2=1?and?key_part3=2
--?走索引
select?col1?from?table?where?key_part1?=1?and?key_part2=1?and?key_part3=2
⑨隱式類(lèi)型轉(zhuǎn)換造成不使用索引
select?col1?from?table?where?col_varchar=123;
結(jié)語(yǔ)
好了,通過(guò)這篇文章,希望你 Get 到了一些分析 MySQL 慢查詢(xún)的方法和心得,如果你覺(jué)得這篇文章不錯(cuò),記得分享給朋友或同事,讓大家少踩點(diǎn)坑。
作者:陳哈哈
簡(jiǎn)介:MySQL 社區(qū)的非著名貢獻(xiàn)者,善于白嫖知識(shí);陪伴 MySQL 五年,致力于高性能 SQL、事務(wù)鎖優(yōu)化方面的研究;長(zhǎng)路漫漫,希望通過(guò)自己的分享讓大家少踩一些坑。我是陳哈哈,一個(gè)愛(ài)笑的程序員。
編輯:陶家龍
后臺(tái)回復(fù)?學(xué)習(xí)資料?領(lǐng)取學(xué)習(xí)視頻
如有收獲,點(diǎn)個(gè)在看,誠(chéng)摯感謝