
DeepMind丟掉了歸一化,讓圖像識別訓(xùn)練速度提升了8.7倍 | 已開源
金磊 發(fā)自 凹非寺
量子位 報道 | 公眾號 QbitAI
在大規(guī)模圖像識別任務(wù)上,DeepMind的新方法火了。
不僅拿到了SOTA,訓(xùn)練速度還提升了8.7倍之多!

方法關(guān)鍵:去“批處理歸一化”
對于大多數(shù)圖像識別模型來說,批處理歸一化(batch normalization)是非常重要的組成部分。
但與此同時,這樣的方式也存在一定的局限性,那就是它存在許多并不重要的特征。
雖然近期的一些研究在沒有歸一化的情況下,成功訓(xùn)練了深度ResNet,但這些模型與最佳批處理歸一化網(wǎng)絡(luò)的測試精度不相匹配。
而這便是DeepMind此次研究所要解決的問題——提出了一種自適應(yīng)梯度剪裁 (AGC) 技術(shù)。
具體而言,這是一種叫做Normalizer-Free ResNet (NFNet)的新網(wǎng)絡(luò)。
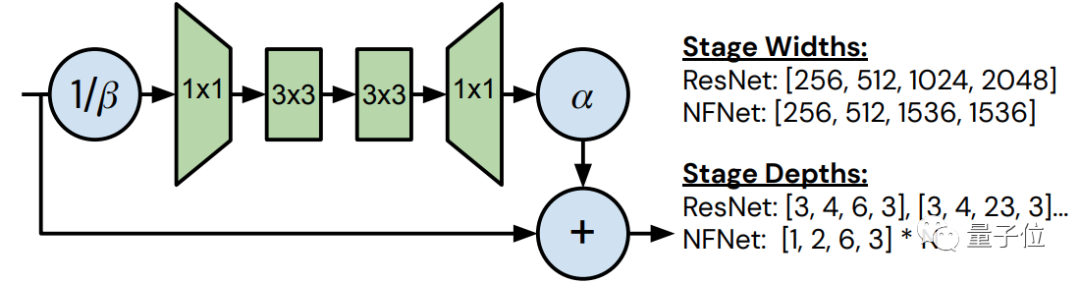
整體來看,NFNet的整體結(jié)構(gòu)如上圖所示。
以有無“transition塊”來劃分,可以再細(xì)分為2種情況。
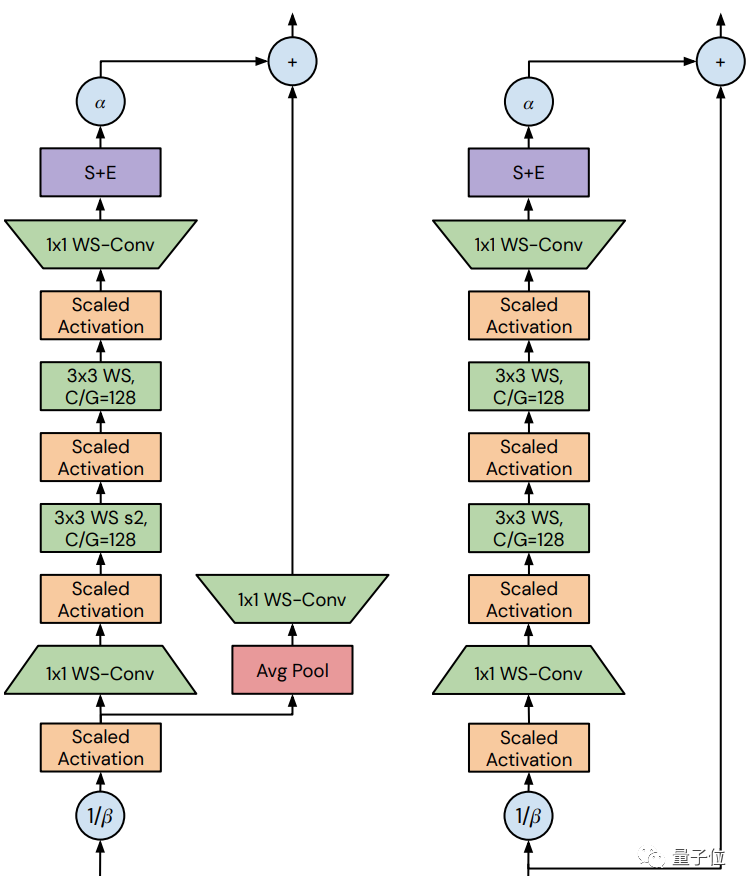
其中,它們的bottleneck ratio均設(shè)置為0.5,且在3 x 3的卷積中,無論信道的數(shù)量為多少,組寬都固定為128。
二者的區(qū)別在于skip path接收信號的方式,左側(cè)的是在用β進(jìn)行variance downscaling和縮放非線性之后;而右側(cè)則是在用β進(jìn)行variance downscaling之前完成。
實驗結(jié)果
在實驗部分,DeepMind的研究人員,采用了與NFNet相關(guān)的7個模型做了對比實驗,分別是NFNet-F0至NFNet-F6。
不難看出,在各個模型的對比過程中,在Top-1精度方面均取得了最好結(jié)果。
值得一提的是,與EfficientNet-B7相比,訓(xùn)練速度方面提升了8.7倍之多。
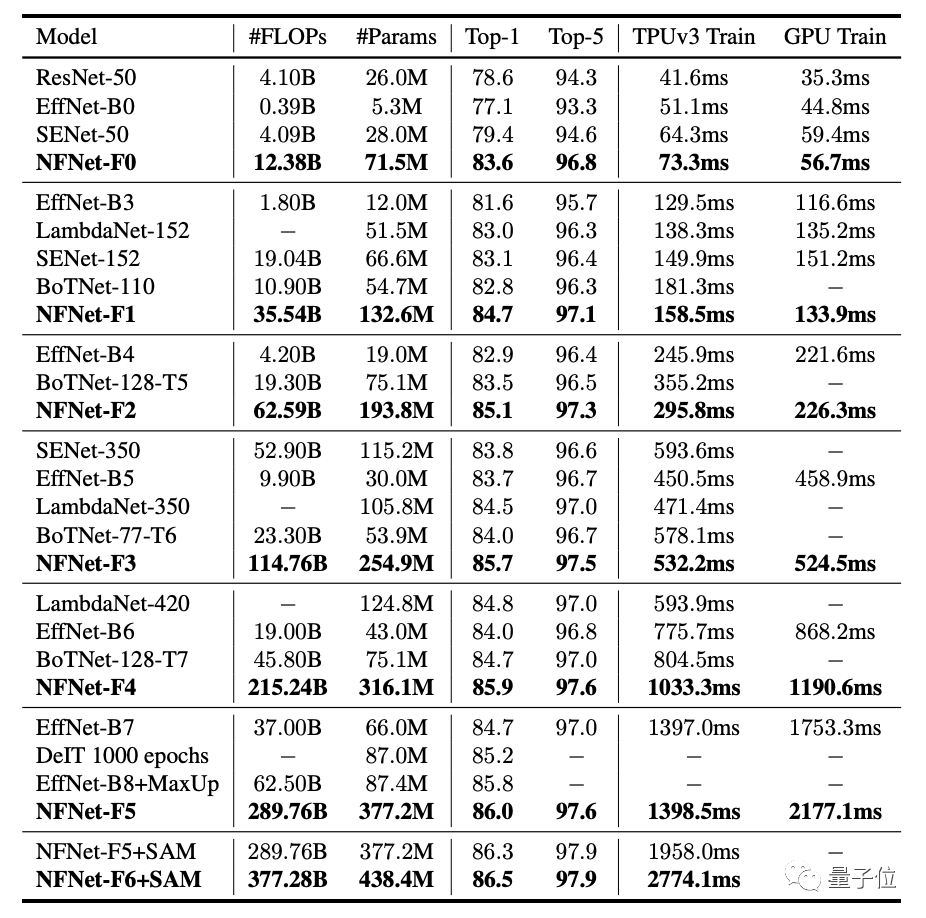
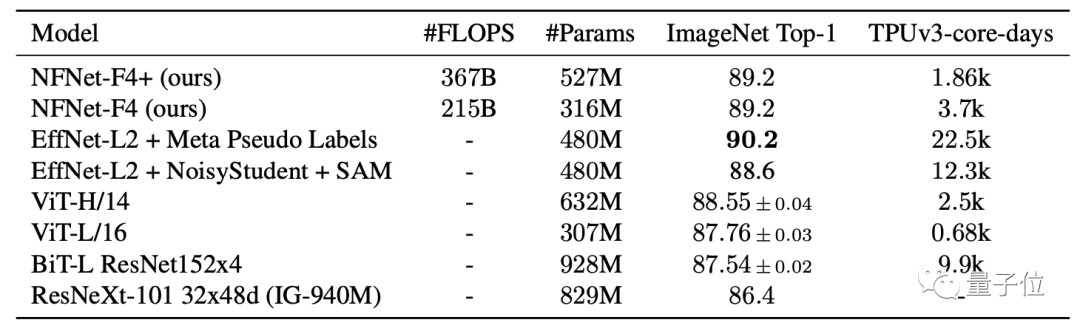
此外,在對3億張標(biāo)記圖像進(jìn)行大規(guī)模預(yù)訓(xùn)練后,在ImageNet上還取得了89.2%的Top-1精度。
最后,對于這項研究的代碼,也已在GitHub上開源。
傳送門
論文地址:
https://arxiv.org/abs/2102.06171
代碼地址:
https://github.com/deepmind/
— 完 —
本文系網(wǎng)易新聞?網(wǎng)易號特色內(nèi)容激勵計劃簽約賬號【量子位】原創(chuàng)內(nèi)容,未經(jīng)賬號授權(quán),禁止隨意轉(zhuǎn)載。
推薦閱讀


加入AI社群,拓展你的AI行業(yè)人脈
量子位?QbitAI · 頭條號簽約作者
?\\'?\\' ? 追蹤AI技術(shù)和產(chǎn)品新動態(tài)
一鍵三連「分享」、「點贊」和「在看」
科技前沿進(jìn)展日日相見~