
【Python】Pandas中的寶藏函數(shù)-apply
基本語法:
DataFrame.apply(func, axis=0, raw=False, result_type=None,args=(), **kwargs)
參 數(shù):
func : function 應(yīng)用到每行或每列的函數(shù)。
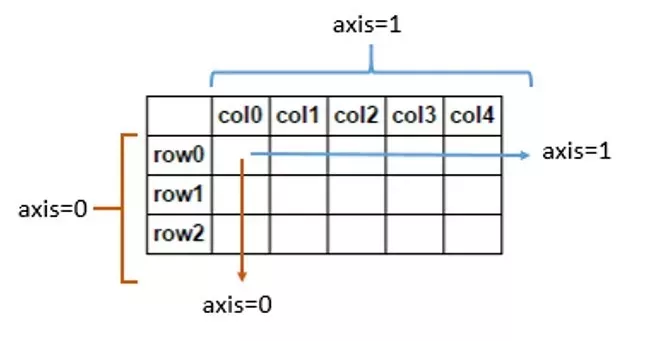
axis :{0 or 'index', 1 or 'columns'}, default 0 函數(shù)應(yīng)用所沿著的軸。
0 or index : 在每一列上應(yīng)用函數(shù)。
1 or columns : 在每一行上應(yīng)用函數(shù)。
raw : bool, default False 確定行或列以Series還是ndarray對象傳遞。
False : 將每一行或每一列作為一個Series傳遞給函數(shù)。
True : 傳遞的函數(shù)將接收ndarray 對象。如果你只是應(yīng)用一個 NumPy 還原函數(shù),這將獲得更好的性能。
result_type : {'expand', 'reduce', 'broadcast', None}, default None 只有在axis=1列時才會發(fā)揮作用。
expand : 列表式的結(jié)果將被轉(zhuǎn)化為列。
reduce : 如果可能的話,返回一個Series,而不是展開類似列表的結(jié)果。這與 expand 相反。
broadcast : 結(jié)果將被廣播到 DataFrame 的原始形狀,原始索引和列將被保留。
默認行為(None)取決于應(yīng)用函數(shù)的返回值:類似列表的結(jié)果將作為這些結(jié)果的 Series 返回。但是,如果應(yīng)用函數(shù)返回一個 Series ,這些結(jié)果將被擴展為列。
args : tuple 除了數(shù)組/序列之外,要傳遞給函數(shù)的位置參數(shù)。
**kwds: 作為關(guān)鍵字參數(shù)傳遞給函數(shù)的附加關(guān)鍵字參數(shù)。
官方:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html
先構(gòu)造一個數(shù)據(jù)集
data = pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":[25, 34, 49, 42, 28, 23, 45, 21, 34, 29]})dataname gender age0 Jack F 251 Alice M 342 Lily F 493 Mshis F 424 Gdli M 285 Agosh F 236 Filu M 457 Mack M 218 Lucy F 349 Pony F 29
1)單列數(shù)據(jù)
這里我們參照2.1向apply()中傳入lambda函數(shù):
x:'女性' if x is 'F' else '男性')0 女性1 男性2 女性3 女性4 男性5 女性6 男性7 男性8 女性9 女性
可以看到這里實現(xiàn)了跟map()一樣的功能。
2)輸入多列數(shù)據(jù)
def fun_all(name, gender, age):gender = '女性' if gender is 'F' else '男性'return '有個名字叫{}的人,性別為{},年齡為{}。'.format(name, gender, age)data.apply(lambda row:fun_all(row['name'],row['gender'],row['age']), axis = 1)0 有個名字叫Jack的人,性別為女性,年齡為25。1 有個名字叫Alice的人,性別為男性,年齡為34。2 有個名字叫Lily的人,性別為女性,年齡為49。3 有個名字叫Mshis的人,性別為女性,年齡為42。4 有個名字叫Gdli的人,性別為男性,年齡為28。5 有個名字叫Agosh的人,性別為女性,年齡為23。6 有個名字叫Filu的人,性別為男性,年齡為45。7 有個名字叫Mack的人,性別為男性,年齡為21。8 有個名字叫Lucy的人,性別為女性,年齡為34。9 有個名字叫Pony的人,性別為女性,年齡為29。
def intro(r):#r代指dataframe中的任意行,是series類型數(shù)據(jù),擁有類似字典的使用方法。return '大家好,我是{name},性別是{gender},今年{age}歲了!'.format(name=r['name'], gender=r['gender'],age=r['age'])axis=1):0 大家好,我是Jack,性別是F,今年25歲了!1 大家好,我是Alice,性別是M,今年34歲了!2 大家好,我是Lily,性別是F,今年49歲了!3 大家好,我是Mshis,性別是F,今年42歲了!4 大家好,我是Gdli,性別是M,今年28歲了!5 大家好,我是Agosh,性別是F,今年23歲了!6 大家好,我是Filu,性別是M,今年45歲了!7 大家好,我是Mack,性別是M,今年21歲了!8 大家好,我是Lucy,性別是F,今年34歲了!9 大家好,我是Pony,性別是F,今年29歲了!dtype: object#其實這樣寫也是可以的,更簡單些def intro(r):return '大家好,我是{},性別是{},今年{}歲了!'.format(r['name'], r['gender'],r['age'])=1)
3)輸出多列數(shù)據(jù)
data.apply(lambda row: (row['name'][0], row['name'][1:]), axis=1)0 (J, ack)1 (A, lice)2 (L, ily)3 (M, shis)4 (G, dli)5 (A, gosh)6 (F, ilu)7 (M, ack)8 (L, ucy)9 (P, ony)
可以看到,這里返回的是單列結(jié)果,每個元素是返回值組成的元組,這時若想直接得到各列分開的結(jié)果,需要用到zip(*zipped)來解開元組序列,從而得到分離的多列返回值:
a, b = zip(*data.apply(lambda row: (row['name'][0], row['name'][1:]), axis=1))a('J', 'A', 'L', 'M', 'G', 'A', 'F', 'M', 'L', 'P')b('ack', 'lice', 'ily', 'shis', 'dli', 'gosh', 'ilu', 'ack', 'ucy', 'ony')
4)結(jié)合tqdm給apply()過程添加進度條
tqdm:用于添加代碼進度條的第三方庫
from tqdm import tqdmdef fun_all(name, gender, age):gender = '女性' if gender is 'F' else '男性'return '有個名字叫{}的人,性別為{},年齡為{}。'.format(name, gender, age)#啟動對緊跟著的apply過程的監(jiān)視from tqdm import tqdmtqdm.pandas(desc='apply')data.progress_apply(lambda row:fun_all(row['name'],row['gender'],row['age']), axis = 1)apply: 100%|██████████| 10/10 [00:00<00:00, 5011.71it/s]0 有個名字叫Jack的人,性別為女性,年齡為25。1 有個名字叫Alice的人,性別為男性,年齡為34。2 有個名字叫Lily的人,性別為女性,年齡為49。3 有個名字叫Mshis的人,性別為女性,年齡為42。4 有個名字叫Gdli的人,性別為男性,年齡為28。5 有個名字叫Agosh的人,性別為女性,年齡為23。6 有個名字叫Filu的人,性別為男性,年齡為45。7 有個名字叫Mack的人,性別為男性,年齡為21。8 有個名字叫Lucy的人,性別為女性,年齡為34。9 有個名字叫Pony的人,性別為女性,年齡為2
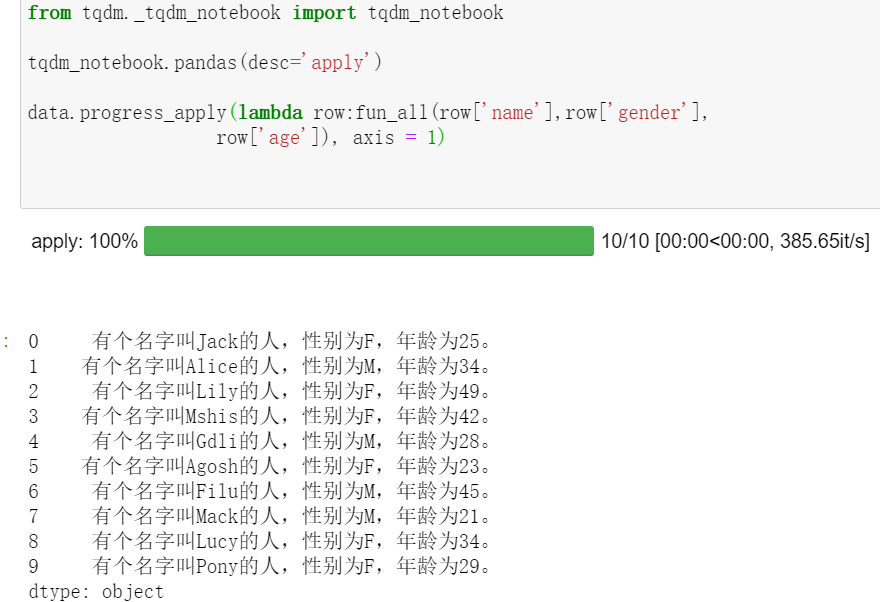
import pandas as pddata = pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":[25, 34, 49, 42, 28, 23, 45, 21, 34, 29]})def fun_all(name, gender, age):gender == '女性' if gender == 'F' else '男性'return '有個名字叫{}的人,性別為{},年齡為{}。'.format(name, gender, age)from tqdm._tqdm_notebook import tqdm_notebooktqdm_notebook.pandas(desc='apply')data.progress_apply(lambda row:fun_all(row['name'],row['gender'],row['age']), axis = 1)
往期精彩回顧 本站qq群851320808,加入微信群請掃碼: