
HBase 探索 | ZGC 和 G1 在 HBase 集群的 GC 性能對比
1. 前言
2. GC 之痛
3. CMS 和 G1 停頓時間瓶頸
4. ZGC 原理
4.1 全并發(fā)的 ZGC
4.2 ZGC 中的關(guān)鍵技術(shù)
5. 初探 ZGC 在 HBase 中的 GC 表現(xiàn)
6. ZGC 與 G1 GC 的數(shù)據(jù)統(tǒng)計(jì)對比
6.1 G1
6.2 ZGC
6.3 G1 與 ZGC 吞吐量相關(guān)指標(biāo)比較
7. 總結(jié)
8. 參考鏈接
1. 前言
本文為了銜接公眾號中的前幾篇 ZGC 相關(guān)的文章,繼續(xù)探索 ZGC 在 HBase 集群中真實(shí)的 GC 表現(xiàn)能力,并把其與 G1 GC 做一個簡單的對比,驗(yàn)證 ZGC 是否真如傳言中的那般,令人嘆為觀止。
在前幾篇文章中,我為大家分享了使用 JDK15 編譯 HBase(和 CDH HBase)的踩坑記錄和 ZGC 在 HBase 集群中的配置方法,有對 ZGC 感興趣的小伙伴,也可以親自動手嘗試一下,體驗(yàn)體驗(yàn)這個來自未來的技術(shù)。
2. GC 之痛
很多低延遲高可用的 Java 服務(wù)的系統(tǒng)可用性飽受 GC 停頓的困擾,例如:HBase,GC 停頓是影響 HBase 讀寫延時的一大元兇。GC 停頓是指垃圾回收期間的 STW(Stop The World),當(dāng) STW 發(fā)生的時候,所有應(yīng)用線程停止活動,等待 GC 停頓的結(jié)束。
我們線上 HBase 集群的 GC 優(yōu)化經(jīng)歷過 CMS 和 G1,G1 GC 調(diào)優(yōu)之后,在很長的一段時間之內(nèi),是可以滿足我們線上接口對 HBase 查詢延時的需求。但更高敏感的業(yè)務(wù)上線之后,我們的集群便立馬捉襟見肘,例如:我們的某些核心業(yè)務(wù)要求 100ms 內(nèi)返回結(jié)果,并且可用性要達(dá)到 99.9%甚至 99.99%,但在各種各樣因素的綜合影響之下,我們的集群一直無法滿足業(yè)務(wù)方的要求。
我們做過數(shù)據(jù)請求測試,持續(xù)用一個 rowKey 來循環(huán)請求 HBase 集群,統(tǒng)計(jì)查詢耗時,一直無法滿足 99.9%的查詢目標(biāo),而且,在耗時查詢發(fā)生的相同時間點(diǎn),也伴隨著 GC 的發(fā)生。單次 GC 的停頓,可能是導(dǎo)致我們在這種查詢場景下,出現(xiàn)耗時查詢的最大元兇。
降低單次 GC 的時間和降低 GC 發(fā)生的頻率,可能會進(jìn)一步提升我們集群的查詢性能,出于這個目標(biāo),我們才開始了對 ZGC 的探索之路。
3. CMS 和 G1 停頓時間瓶頸
介紹 ZGC 之前,先簡單回顧下 CMS 和 G1 的 GC 過程,以及停頓時間的瓶頸。CMS 新生代的 Young GC、G1 和 ZGC 都基于標(biāo)記-復(fù)制算法,但算法具體實(shí)現(xiàn)的不同就導(dǎo)致了巨大的性能差異。
標(biāo)記-復(fù)制算法應(yīng)用在 CMS 新生代(ParNew 是 CMS 默認(rèn)的新生代垃圾回收器)和 G1 垃圾回收器中。標(biāo)記-復(fù)制算法可以分為三個階段:
標(biāo)記階段,即從 GC Roots 集合開始,標(biāo)記活躍對象; 轉(zhuǎn)移階段,即把活躍對象復(fù)制到新的內(nèi)存地址上; 重定位階段,因?yàn)檗D(zhuǎn)移導(dǎo)致對象的地址發(fā)生了變化,在重定位階段,所有指向?qū)ο笈f地址的指針都要調(diào)整到對象新的地址上。
下面以 G1 為例,通過 G1 中標(biāo)記-復(fù)制算法過程(G1 的 Young GC 和 Mixed GC 均采用該算法),分析 G1 停頓耗時的主要瓶頸。G1 垃圾回收周期如下圖所示:
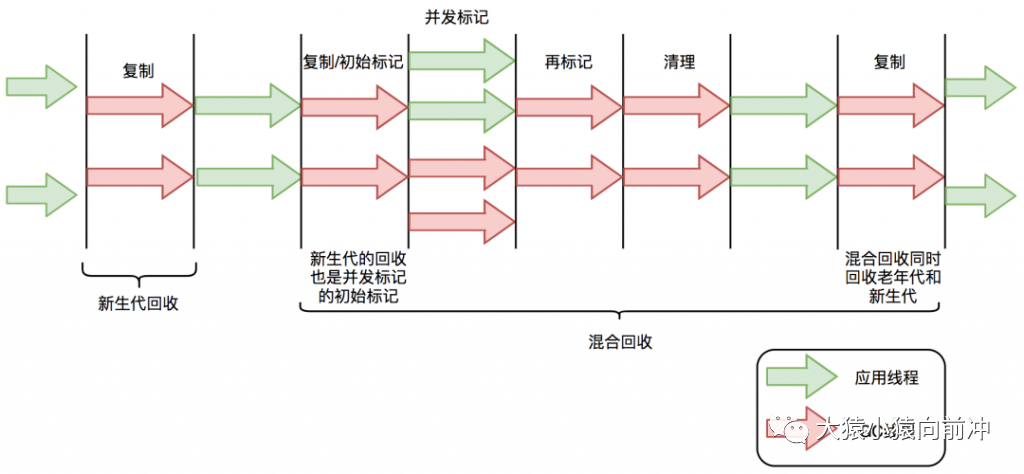
G1 的混合回收過程可以分為標(biāo)記階段、清理階段和復(fù)制階段。
標(biāo)記階段停頓分析
初始標(biāo)記階段:初始標(biāo)記階段是指從 GC Roots 出發(fā)標(biāo)記全部直接子節(jié)點(diǎn)的過程,該階段是 STW 的。由于 GC Roots 數(shù)量不多,通常該階段耗時非常短。 并發(fā)標(biāo)記階段:并發(fā)標(biāo)記階段是指從 GC Roots 開始對堆中對象進(jìn)行可達(dá)性分析,找出存活對象。該階段是并發(fā)的,即應(yīng)用線程和 GC 線程可以同時活動。并發(fā)標(biāo)記耗時相對長很多,但因?yàn)椴皇?STW,所以我們不太關(guān)心該階段耗時的長短。 再標(biāo)記階段:重新標(biāo)記那些在并發(fā)標(biāo)記階段發(fā)生變化的對象。該階段是 STW 的。
清理階段停頓分析
清理階段清點(diǎn)出有存活對象的分區(qū)和沒有存活對象的分區(qū),該階段不會清理垃圾對象,也不會執(zhí)行存活對象的復(fù)制。該階段是 STW 的。
復(fù)制階段停頓分析
復(fù)制算法中的轉(zhuǎn)移階段需要分配新內(nèi)存和復(fù)制對象的成員變量。轉(zhuǎn)移階段是 STW 的,其中內(nèi)存分配通常耗時非常短,但對象成員變量的復(fù)制耗時有可能較長,這是因?yàn)閺?fù)制耗時與存活對象數(shù)量與對象復(fù)雜度成正比。對象越復(fù)雜,復(fù)制耗時越長。
四個 STW 過程中,初始標(biāo)記因?yàn)橹粯?biāo)記 GC Roots,耗時較短。再標(biāo)記因?yàn)閷ο髷?shù)少,耗時也較短。清理階段因?yàn)閮?nèi)存分區(qū)數(shù)量少,耗時也較短。轉(zhuǎn)移階段要處理所有存活的對象,耗時會較長。因此,G1 停頓時間的瓶頸主要是標(biāo)記-復(fù)制中的轉(zhuǎn)移階段 STW。為什么轉(zhuǎn)移階段不能和標(biāo)記階段一樣并發(fā)執(zhí)行呢?主要是 G1 未能解決轉(zhuǎn)移過程中準(zhǔn)確定位對象地址的問題。
G1 的 Young GC 和 CMS 的 Young GC,其標(biāo)記-復(fù)制全過程 STW,不再詳細(xì)闡述,這里列舉幾篇范欣欣大神寫的文章。
HBase GC 的前生今世 – 身世篇
HBase GC 的前生今世 – 演進(jìn)篇
HBase 最佳實(shí)踐-CMS GC 調(diào)優(yōu)
4. ZGC 原理
4.1 全并發(fā)的 ZGC
與 CMS 中的 ParNew 和 G1 類似,ZGC 也采用標(biāo)記-復(fù)制算法,不過 ZGC 對該算法做了重大改進(jìn):ZGC 在標(biāo)記、轉(zhuǎn)移和重定位階段幾乎都是并發(fā)的,這是 ZGC 實(shí)現(xiàn)停頓時間小于 10ms 目標(biāo)的最關(guān)鍵原因。
ZGC 垃圾回收周期如下圖所示:
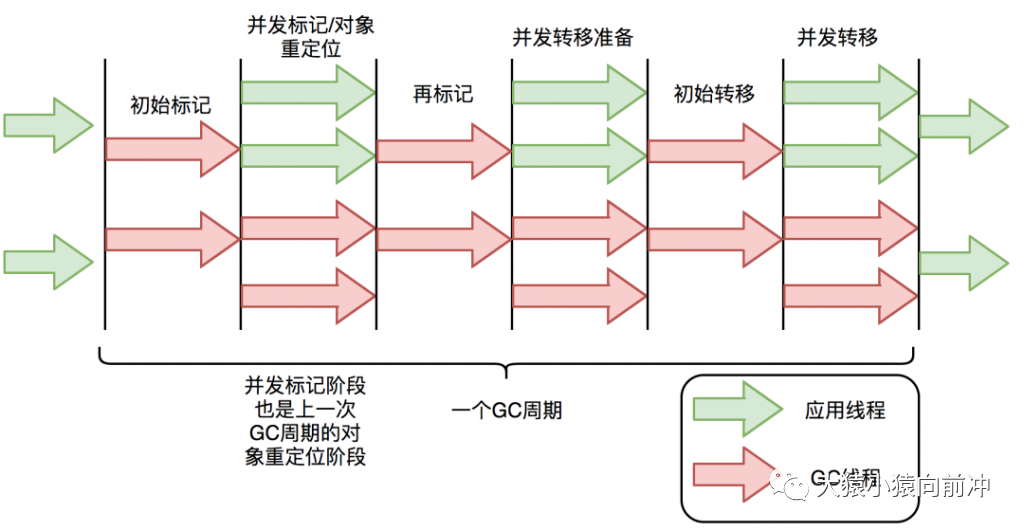
ZGC 只有三個 STW 階段:初始標(biāo)記,再標(biāo)記,初始轉(zhuǎn)移。其中,初始標(biāo)記和初始轉(zhuǎn)移分別都只需要掃描所有 GC Roots,其處理時間和 GC Roots 的數(shù)量成正比,一般情況耗時非常短;再標(biāo)記階段 STW 時間很短,最多 1ms,超過 1ms 則再次進(jìn)入并發(fā)標(biāo)記階段。即,ZGC 幾乎所有暫停都只依賴于 GC Roots 集合大小,停頓時間不會隨著堆的大小或者活躍對象的大小而增加。與 ZGC 對比,G1 的轉(zhuǎn)移階段完全 STW 的,且停頓時間隨存活對象的大小增加而增加。
4.2 ZGC 中的關(guān)鍵技術(shù)
ZGC 通過著色指針和讀屏障技術(shù),解決了轉(zhuǎn)移過程中準(zhǔn)確訪問對象的問題,實(shí)現(xiàn)了并發(fā)轉(zhuǎn)移。大致原理描述如下:并發(fā)轉(zhuǎn)移中“并發(fā)”意味著 GC 線程在轉(zhuǎn)移對象的過程中,應(yīng)用線程也在不停地訪問對象。假設(shè)對象發(fā)生轉(zhuǎn)移,但對象地址未及時更新,那么應(yīng)用線程可能訪問到舊地址,從而造成錯誤。而在 ZGC 中,應(yīng)用線程訪問對象將觸發(fā)“讀屏障”,如果發(fā)現(xiàn)對象被移動了,那么“讀屏障”會把讀出來的指針更新到對象的新地址上,這樣應(yīng)用線程始終訪問的都是對象的新地址。那么,JVM 是如何判斷對象被移動過呢?就是利用對象引用的地址,即著色指針。下面介紹著色指針和讀屏障技術(shù)細(xì)節(jié)。
著色指針
**|**著色指針是一種將信息存儲在指針中的技術(shù)。
ZGC 僅支持 64 位系統(tǒng),它把 64 位虛擬地址空間劃分為多個子空間,如下圖所示:
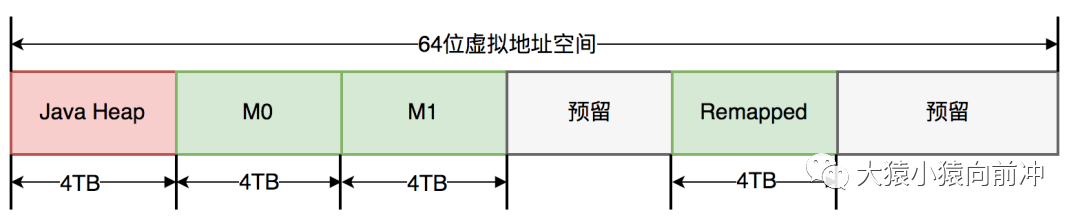
其中,[0~4TB) 對應(yīng) Java 堆,[4TB ~ 8TB) 稱為 M0 地址空間,[8TB ~ 12TB) 稱為 M1 地址空間,[12TB ~ 16TB) 預(yù)留未使用,[16TB ~ 20TB) 稱為 Remapped 空間。
當(dāng)應(yīng)用程序創(chuàng)建對象時,首先在堆空間申請一個虛擬地址,但該虛擬地址并不會映射到真正的物理地址。ZGC 同時會為該對象在 M0、M1 和 Remapped 地址空間分別申請一個虛擬地址,且這三個虛擬地址對應(yīng)同一個物理地址,但這三個空間在同一時間有且只有一個空間有效。ZGC 之所以設(shè)置三個虛擬地址空間,是因?yàn)樗褂谩翱臻g換時間”思想,去降低 GC 停頓時間。“空間換時間”中的空間是虛擬空間,而不是真正的物理空間。后續(xù)章節(jié)將詳細(xì)介紹這三個空間的切換過程。
與上述地址空間劃分相對應(yīng),ZGC 實(shí)際僅使用 64 位地址空間的第 0~41 位,而第 42~45 位存儲元數(shù)據(jù),第 47~63 位固定為 0。
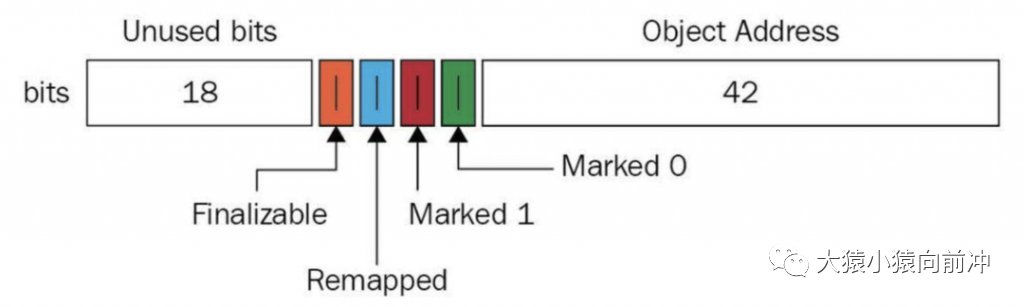
ZGC 將對象存活信息存儲在 42~45 位中,這與傳統(tǒng)的垃圾回收并將對象存活信息放在對象頭中完全不同。
讀屏障
| 讀屏障是 JVM 向應(yīng)用代碼插入一小段代碼的技術(shù)。當(dāng)應(yīng)用線程從堆中讀取對象引用時,就會執(zhí)行這段代碼。需要注意的是,僅“從堆中讀取對象引用”才會觸發(fā)這段代碼。
讀屏障示例:

ZGC 中讀屏障的代碼作用:在對象標(biāo)記和轉(zhuǎn)移過程中,用于確定對象的引用地址是否滿足條件,并作出相應(yīng)動作。
ZGC 并發(fā)處理演示
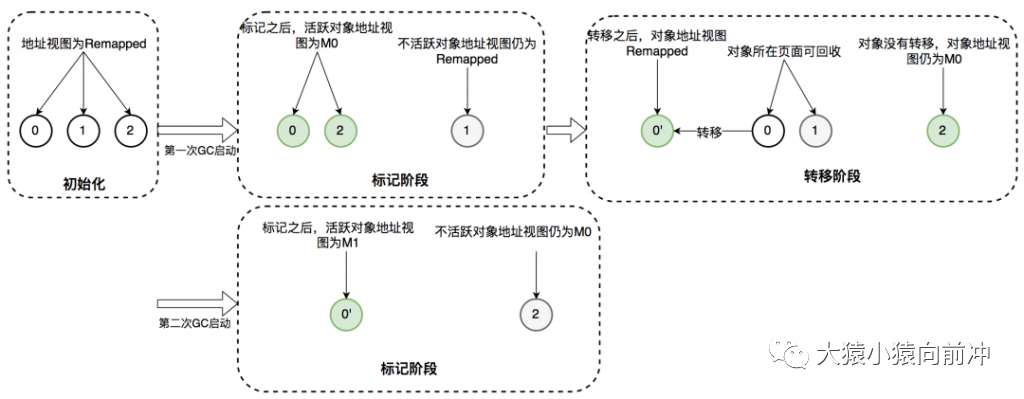
接下來詳細(xì)介紹 ZGC 一次垃圾回收周期中地址視圖的切換過程:
初始化:ZGC 初始化之后,整個內(nèi)存空間的地址視圖被設(shè)置為 Remapped。程序正常運(yùn)行,在內(nèi)存中分配對象,滿足一定條件后垃圾回收啟動,此時進(jìn)入標(biāo)記階段。 并發(fā)標(biāo)記階段:第一次進(jìn)入標(biāo)記階段時視圖為 M0,如果對象被 GC 標(biāo)記線程或者應(yīng)用線程訪問過,那么就將對象的地址視圖從 Remapped 調(diào)整為 M0。所以,在標(biāo)記階段結(jié)束之后,對象的地址要么是 M0 視圖,要么是 Remapped。如果對象的地址是 M0 視圖,那么說明對象是活躍的;如果對象的地址是 Remapped 視圖,說明對象是不活躍的。 并發(fā)轉(zhuǎn)移階段:標(biāo)記結(jié)束后就進(jìn)入轉(zhuǎn)移階段,此時地址視圖再次被設(shè)置為 Remapped。如果對象被 GC 轉(zhuǎn)移線程或者應(yīng)用線程訪問過,那么就將對象的地址視圖從 M0 調(diào)整為 Remapped。
其實(shí),在標(biāo)記階段存在兩個地址視圖 M0 和 M1,上面的過程顯示只用了一個地址視圖。之所以設(shè)計(jì)成兩個,是為了區(qū)別前一次標(biāo)記和當(dāng)前標(biāo)記。即第二次進(jìn)入并發(fā)標(biāo)記階段后,地址視圖調(diào)整為 M1,而非 M0。
著色指針和讀屏障技術(shù)不僅應(yīng)用在并發(fā)轉(zhuǎn)移階段,還應(yīng)用在并發(fā)標(biāo)記階段:將對象設(shè)置為已標(biāo)記,傳統(tǒng)的垃圾回收器需要進(jìn)行一次內(nèi)存訪問,并將對象存活信息放在對象頭中;而在 ZGC 中,只需要設(shè)置指針地址的第 42~45 位即可,并且因?yàn)槭羌拇嫫髟L問,所以速度比訪問內(nèi)存更快。
5. 初探 ZGC 在 HBase 中的 GC 表現(xiàn)
ZGC 相關(guān)的調(diào)優(yōu)參數(shù)究竟該如何配置,實(shí)在無法提供出來一個標(biāo)準(zhǔn)的答案。我們參考美團(tuán) ZGC 實(shí)踐中的一個案例,來針對我所用的 HBase 集群來進(jìn)行 ZGC 相關(guān)參數(shù)的設(shè)置,然后在 YCSB 的壓測場景下,收集、分析 ZGC 的 GC 日志。
參考的文章鏈接是,其中上文有關(guān) G1 和 ZGC 的理論知識剖析也是摘選自這篇文章。
https://www.secpulse.com/archives/137305.html
新一代垃圾回收器ZGC的探索與實(shí)踐——美團(tuán)
https://www.secpulse.com/archives/137305.html
此次測試使用的 HBase 集群由三個節(jié)點(diǎn)組成,物理機(jī)配置:24 核,內(nèi)存 370G,其中為 HBase 分配了 31G 的堆內(nèi)存。HBase 的版本是 cdh-6.3.2-hbase2.1.0。壓測時使用的工具是阿里的 AHBench(基于 YCSB 包裝了一層,方便對 YCSB 測試結(jié)果數(shù)據(jù)的收集和匯總),并保證在測試期間,唯一的變量是 GC 的使用方式。
YCSB 壓測的場景是:數(shù)據(jù)量一個億,分別在使用 G1 和 ZGC 的場景下跑 AHBench 的 full_test,然后對測試期間 G1 和 ZGC 的詳細(xì) gc 日志生成 GC 指標(biāo)分析報(bào)告。
RegionServer 重要配置參數(shù)示例:
-Xms31G -Xmx31G
-XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
-XX:ConcGCThreads=2 -XX:ParallelGCThreads=6
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/var/log/hbase/region-server-zgc-%t.log:time,tid,tags:filecount=5,filesize=500m
--illegal-access=deny
--add-exports=java.base/jdk.internal.access=ALL-UNNAMED
--add-exports=java.base/jdk.internal=ALL-UNNAMED
--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED
--add-exports=java.base/sun.security.pkcs=ALL-UNNAMED
--add-exports=java.base/sun.nio.ch=ALL-UNNAMED
--add-opens=java.base/java.nio=ALL-UNNAMED
--add-opens java.base/jdk.internal.misc=ALL-UNNAMED
-Dorg.apache.hbase.thirdparty.io.netty.tryReflectionSetAccessible=true
-Xms -Xmx:堆的最大內(nèi)存和最小內(nèi)存,這里都設(shè)置為 31G,程序的堆內(nèi)存將保持 31G 不變。
-XX:ReservedCodeCacheSize -XX:InitialCodeCacheSize: 設(shè)置 CodeCache 的大小, JIT 編譯的代碼都放在 CodeCache 中,一般服務(wù) 64m 或 128m 就已經(jīng)足夠。這里設(shè)置的數(shù)值也只是參考了美團(tuán) ZGC 實(shí)踐示例。
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC:啟用 ZGC 的配置。
-XX:ConcGCThreads:并發(fā)回收垃圾的線程。默認(rèn)是總核數(shù)的 12.5%,8 核 CPU 默認(rèn)是 1。調(diào)大后 GC 變快,但會占用程序運(yùn)行時的 CPU 資源,吞吐會受到影響。
這個參數(shù)的設(shè)置效果,在 CDH 的 CPU 指標(biāo)監(jiān)控圖例中就可以明顯看得到。
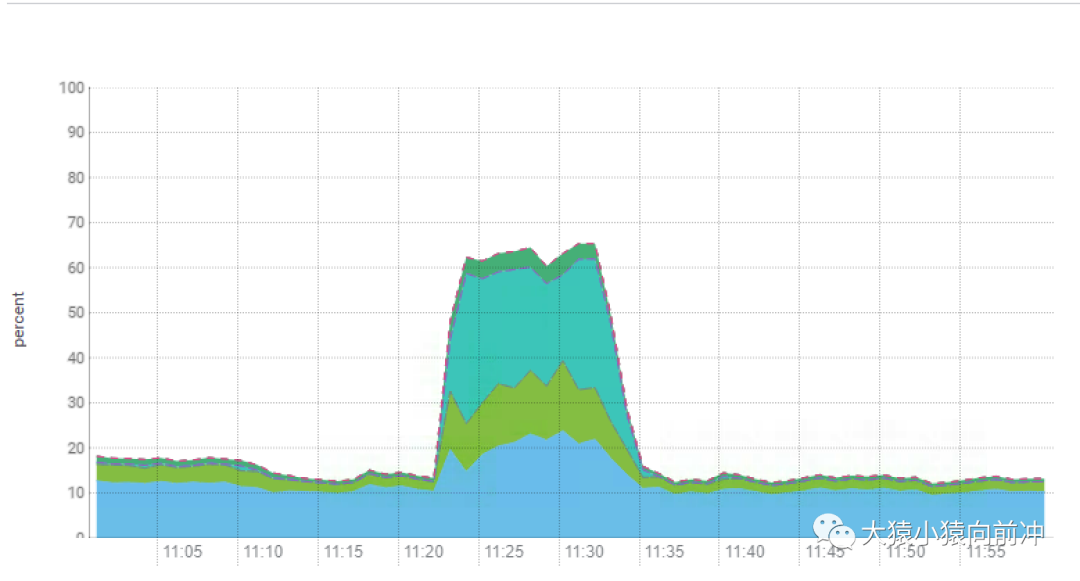
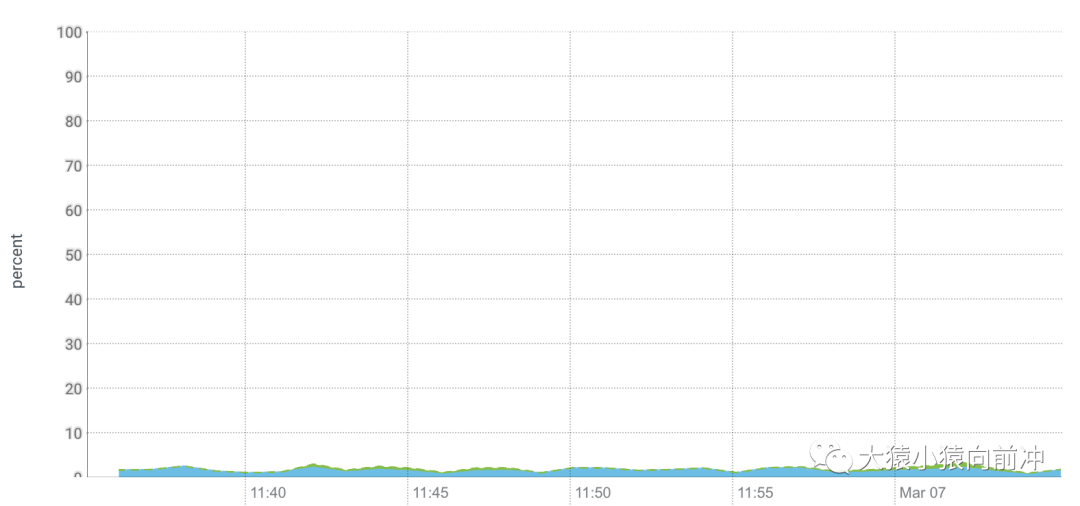
在 ZGC 測試期間,我們觀察到 CPU 的消耗較以往顯著增加,尤其是在集群高負(fù)載的情況下格外明顯,而其他使用 G1 GC 的 HBase 集群中的 CPU 負(fù)載趨勢則如下圖所示:
-XX:ParallelGCThreads:STW 階段使用線程數(shù),默認(rèn)是總核數(shù)的 60%。
-XX:ZCollectionInterval:ZGC 發(fā)生的最小時間間隔,單位秒,該參數(shù)的設(shè)置效果在 CDH 中的 GC 時間監(jiān)控圖例中得到體現(xiàn)。
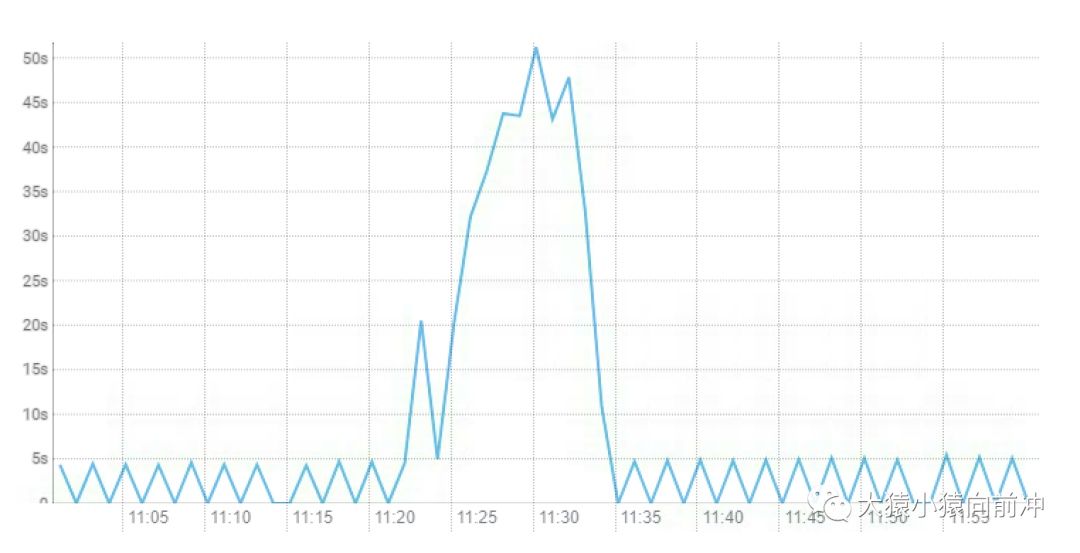
正常情況下 GC 發(fā)生的頻次,時間間隔均勻,正是兩分鐘(120s)。-XX:ZCollectionInterval=120。而且,在集群高負(fù)載的情況下,ZGC 的 GC 時間可以達(dá)到分鐘級別,這也正印證了,ZGC 全程并發(fā),不會影響到你的應(yīng)用進(jìn)程。因?yàn)椋绻敲爰墑e甚至分鐘級別的 STW,你的業(yè)務(wù)方早已提刀而來。G1 GC 場景下,GC 的消耗時間趨勢如下圖:

我們在進(jìn)行 G1 GC 調(diào)優(yōu)設(shè)置參數(shù)的時候,期望的 GC 時間是在 100ms,但真實(shí)的情況是不管如何調(diào)整,GC 的耗時遠(yuǎn)超 100ms。
200ms GC 耗時均值中的 STW 的時間占比,將直接影響著 HBase 集群查詢延時的占比。
-XX:ZAllocationSpikeTolerance:ZGC 觸發(fā)自適應(yīng)算法的修正系數(shù),默認(rèn) 2,數(shù)值越大,越早的觸發(fā) ZGC。
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive:是否啟用主動回收,默認(rèn)開啟,這里的配置表示關(guān)閉。
-Xlog:設(shè)置 GC 日志中的內(nèi)容、格式、位置以及每個日志的大小。
理解 ZGC 的觸發(fā)時機(jī)
相比于 CMS 和 G1 的 GC 觸發(fā)機(jī)制,ZGC 的 GC 觸發(fā)機(jī)制有很大不同。ZGC 的核心特點(diǎn)是并發(fā),GC 過程中一直有新的對象產(chǎn)生。如何保證在 GC 完成之前,新產(chǎn)生的對象不會將堆占滿,是 ZGC 參數(shù)調(diào)優(yōu)的第一大目標(biāo)。因?yàn)樵?ZGC 中,當(dāng)垃圾來不及回收將堆占滿時,會導(dǎo)致正在運(yùn)行的線程停頓,持續(xù)時間可能長達(dá)秒級之久。
ZGC 有多種 GC 觸發(fā)機(jī)制,總結(jié)如下:
阻塞內(nèi)存分配請求觸發(fā):當(dāng)垃圾來不及回收,垃圾將堆占滿時,會導(dǎo)致部分線程阻塞。我們應(yīng)當(dāng)避免出現(xiàn)這種觸發(fā)方式。日志中關(guān)鍵字是“Allocation Stall”。 基于分配速率的自適應(yīng)算法:最主要的 GC 觸發(fā)方式,其算法原理可簡單描述為”ZGC 根據(jù)近期的對象分配速率以及 GC 時間,計(jì)算出當(dāng)內(nèi)存占用達(dá)到什么閾值時觸發(fā)下一次 GC”。自適應(yīng)算法的詳細(xì)理論可參考彭成寒《新一代垃圾回收器 ZGC 設(shè)計(jì)與實(shí)現(xiàn)》一書中的內(nèi)容。通過 ZAllocationSpikeTolerance 參數(shù)控制閾值大小,該參數(shù)默認(rèn) 2,數(shù)值越大,越早的觸發(fā) GC。我們通過調(diào)整此參數(shù)解決了一些問題。日志中關(guān)鍵字是“Allocation Rate”。 基于固定時間間隔:通過 ZCollectionInterval 控制,適合應(yīng)對突增流量場景。流量平穩(wěn)變化時,自適應(yīng)算法可能在堆使用率達(dá)到 95%以上才觸發(fā) GC。流量突增時,自適應(yīng)算法觸發(fā)的時機(jī)可能會過晚,導(dǎo)致部分線程阻塞。我們通過調(diào)整此參數(shù)解決流量突增場景的問題,比如定時活動、秒殺等場景。日志中關(guān)鍵字是“Timer”。 主動觸發(fā)規(guī)則:類似于固定間隔規(guī)則,但時間間隔不固定,是 ZGC 自行算出來的時機(jī),我們的服務(wù)因?yàn)橐呀?jīng)加了基于固定時間間隔的觸發(fā)機(jī)制,所以通過-ZProactive 參數(shù)將該功能關(guān)閉,以免 GC 頻繁,影響服務(wù)可用性。日志中關(guān)鍵字是“Proactive”。 預(yù)熱規(guī)則:服務(wù)剛啟動時出現(xiàn),一般不需要關(guān)注。日志中關(guān)鍵字是“Warmup”。 外部觸發(fā):代碼中顯式調(diào)用 System.gc()觸發(fā)。日志中關(guān)鍵字是“System.gc()”。 元數(shù)據(jù)分配觸發(fā):元數(shù)據(jù)區(qū)不足時導(dǎo)致,一般不需要關(guān)注。日志中關(guān)鍵字是“Metadata GC Threshold”。
更細(xì)致的 GC 日志分析,可以參考美團(tuán) ZGC 實(shí)踐那篇文章中的分析思路。
6. ZGC 與 G1 GC 的數(shù)據(jù)統(tǒng)計(jì)對比
我們收集 ZGC 與 G1 GC 在相同壓測場景下生成的詳細(xì) gc 日志,上傳到https://gceasy.io/之后,分別得出的GC報(bào)告如下圖所示:
6.1 G1
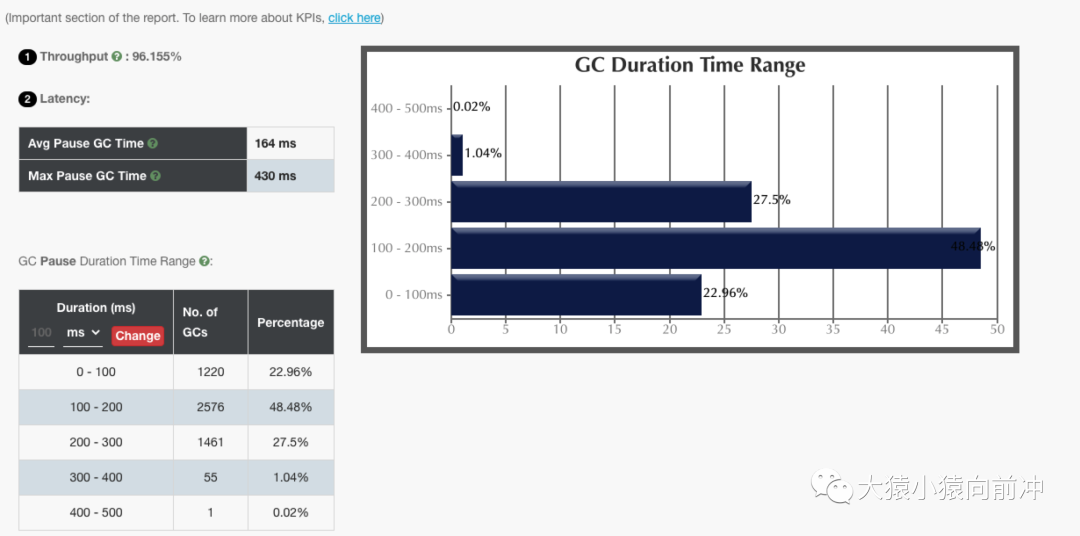
6.2 ZGC
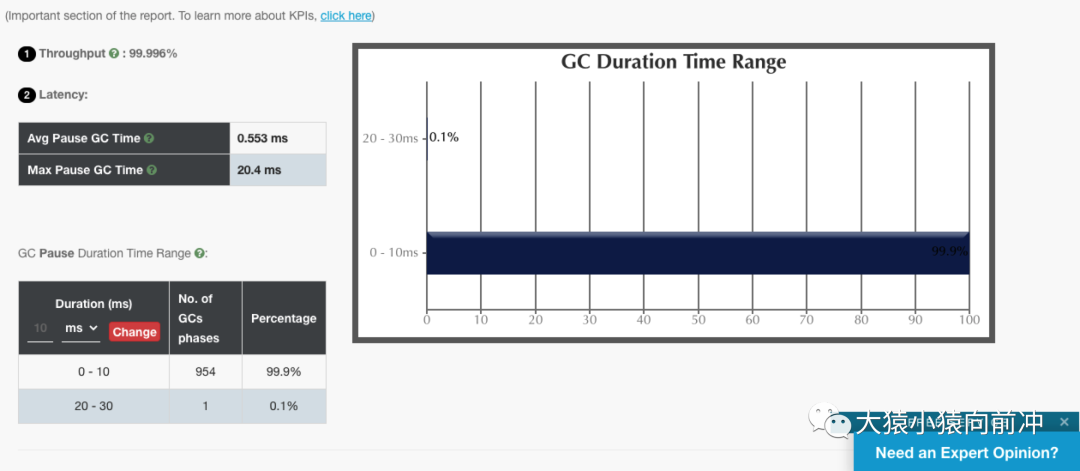
僅從這兩個 GC 報(bào)告對比來看,ZGC 確實(shí)做到了幾乎百分之百的 GC 時間在 10ms 內(nèi)。
6.3 G1 與 ZGC 吞吐量相關(guān)指標(biāo)比較
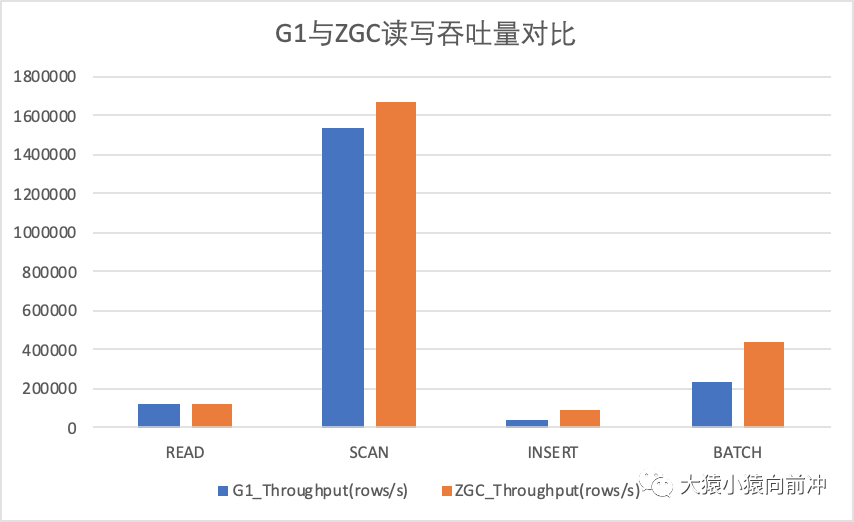
以下圖例記錄了相同 YCSB 壓測場景下,G1 與 ZGC 各項(xiàng)指標(biāo)比較。
讀寫吞吐量指標(biāo)比較
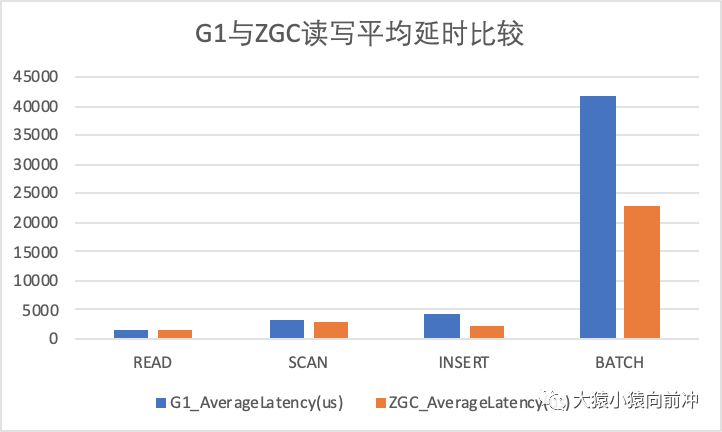
讀寫平均延時指標(biāo)比較
G1 與 ZGCp999 延時指標(biāo)比較
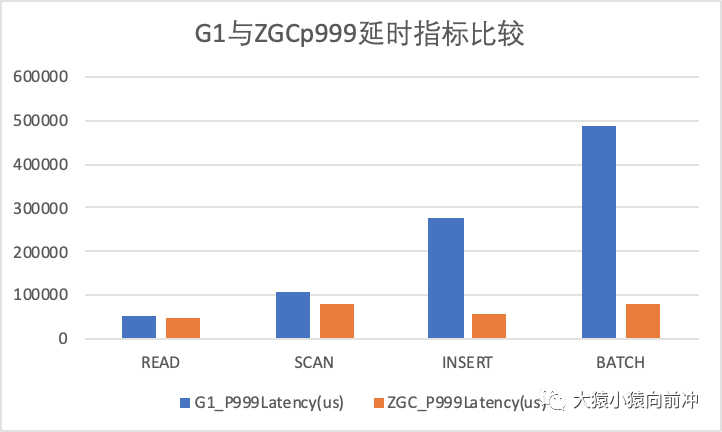
以上指標(biāo)對比,在不同的壓測場景,不同的集群環(huán)境之下的結(jié)果可能會有所不同,不能代表線上真正的表現(xiàn)情況,希望大家如感興趣,可以親自嘗試測試一波。
7. 總結(jié)
本篇文章為大家分享了 ZGC 的特點(diǎn),簡單記錄了 ZGC 的一些核心技術(shù),如著色指針、讀屏障等。并在相同的 YCSB 壓測場景下,分別測試了 G1 和 ZGC 在真實(shí)的應(yīng)用環(huán)境中的 GC 的表現(xiàn)能力,并得出 GC 分析報(bào)告,從 GC 停頓時間和讀寫吞吐、延遲等方面,做了比較詳細(xì)的對比,然后初步驗(yàn)證了以下幾個觀點(diǎn):
ZGC 可以達(dá)到幾乎百分百 GC 耗時在 10ms 內(nèi)的目標(biāo) 通過設(shè)置參數(shù),可以主動控制 ZGC 的 GC 發(fā)生頻率 與 G1 相比,ZGC 在 GC 過程中會消耗更多的 CPU
有關(guān) GC 更深入的理解和使用,甚至進(jìn)一步調(diào)優(yōu) ZGC 的表現(xiàn)能力,這將在后續(xù)的文章中繼續(xù)和大家探討。同時,本人對 GC 的認(rèn)知有限,文中個別地方描述不恰當(dāng),或?qū)?shí)驗(yàn)數(shù)據(jù)心存異議的伙伴,還請及時告知。
8. 參考鏈接
https://www.secpulse.com/archives/137305.html
http://hbasefly.com/2016/05/21/hbase-gc-1/
http://hbasefly.com/2016/05/29/hbase-gc-2/
http://hbasefly.com/2016/08/09/hbase-cms-gc/